Vision Transformers and Transfer Learning Approaches for Arabic Sign Language Recognition


Abstract
:1. Introduction
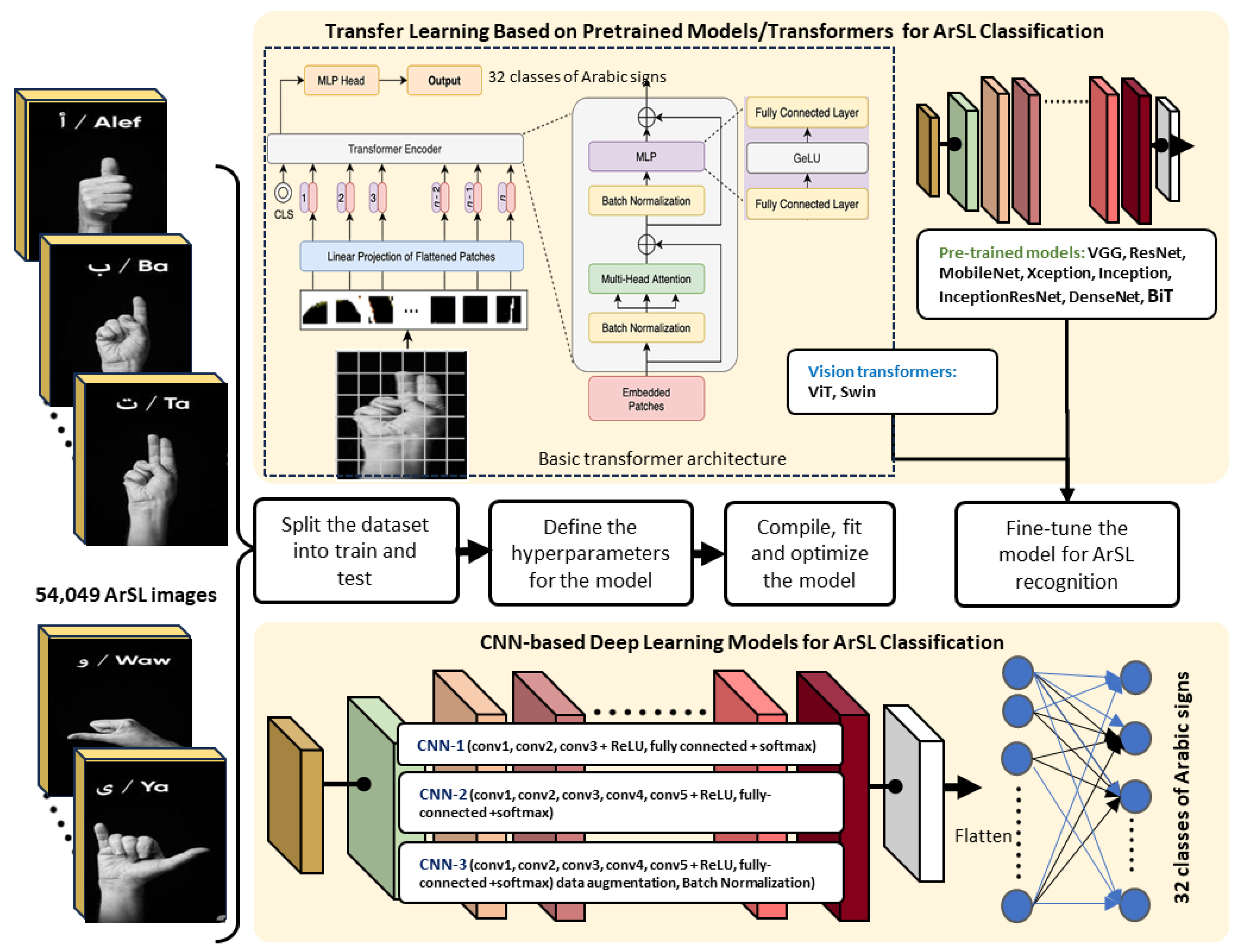
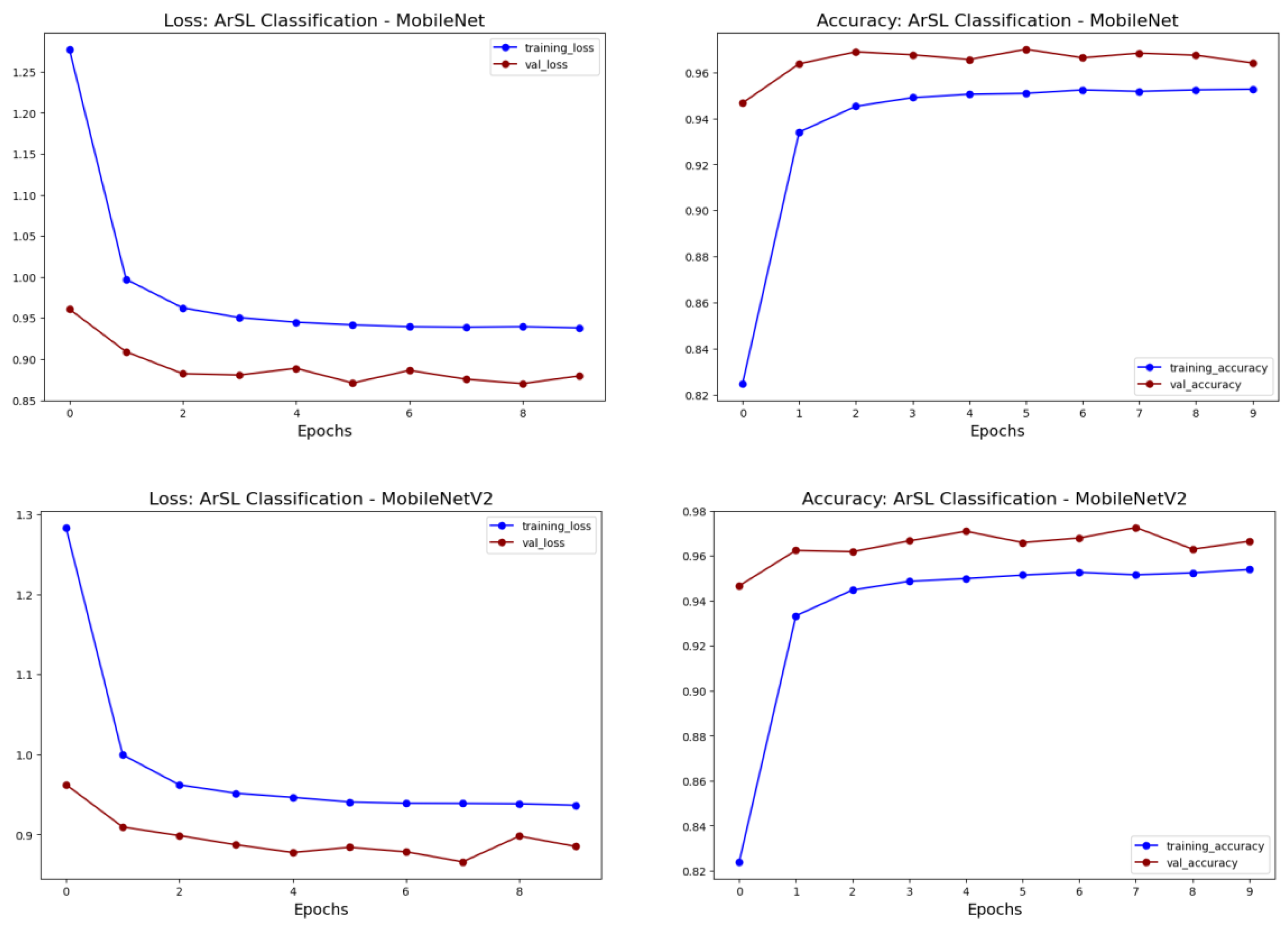
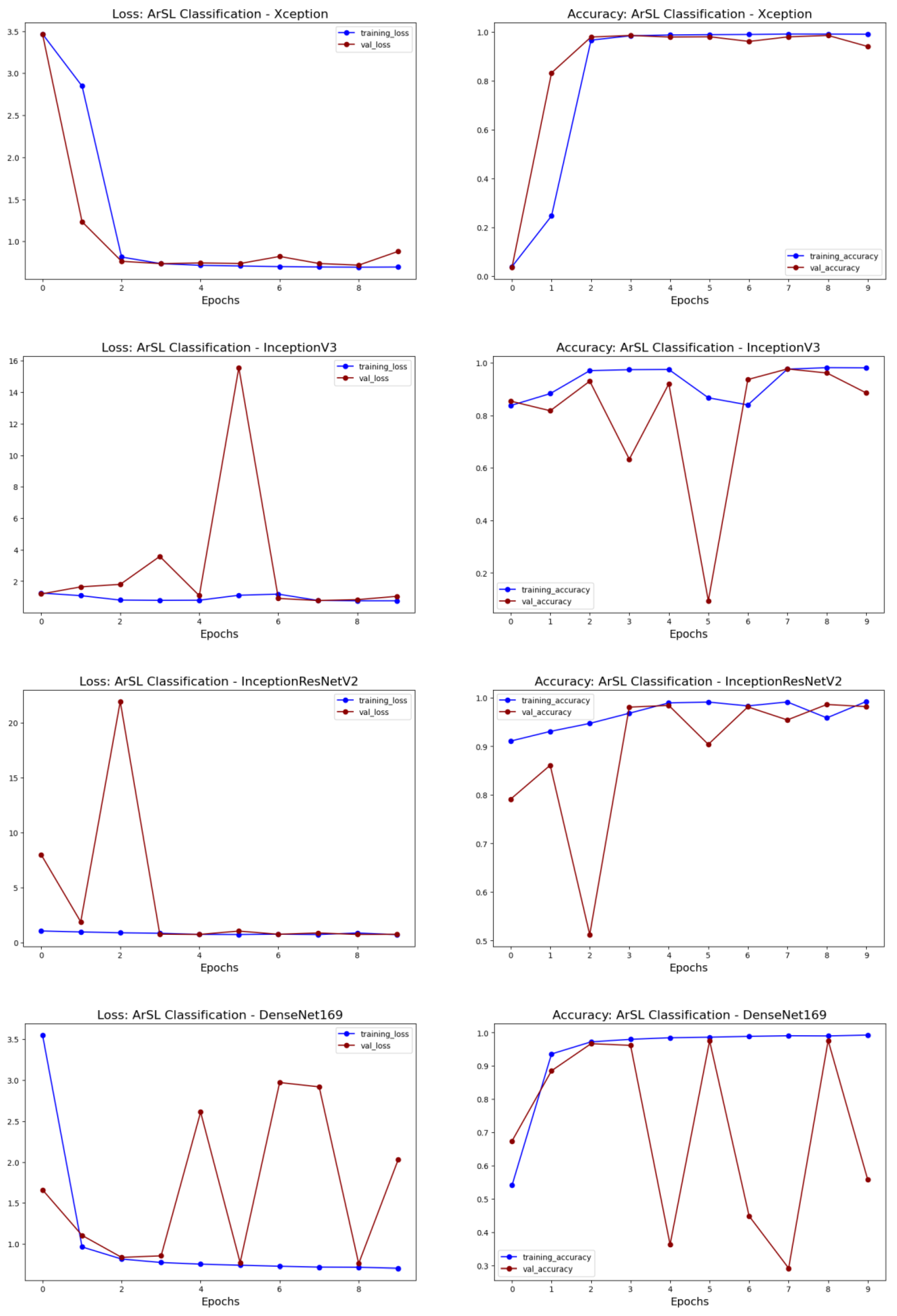
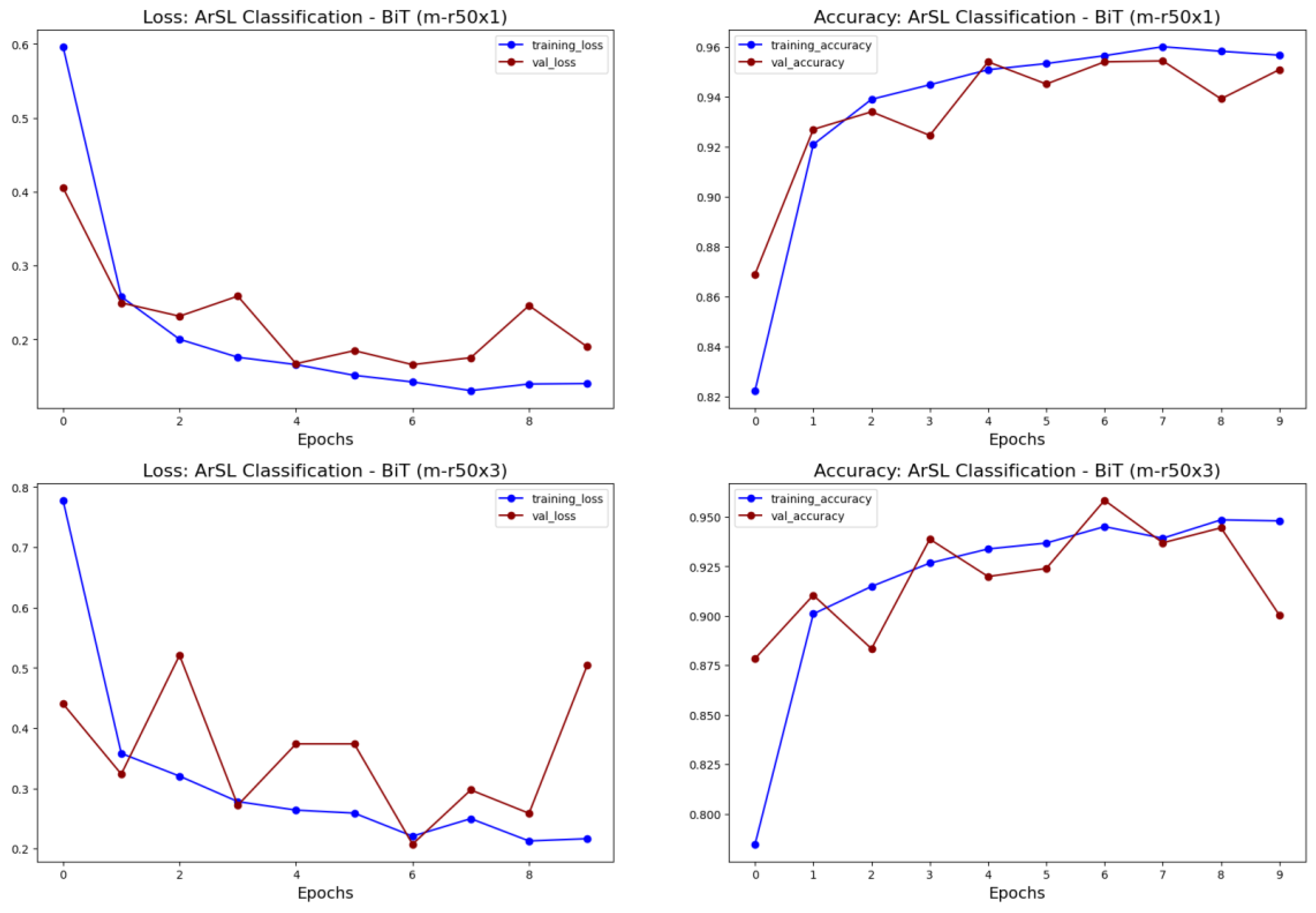
- This study explores the use of transfer learning approach using pretrained deep learning models such as VGG, ResNet, MobileNet, Inception, Xception, DenseNet, and InceptionResNet for ArSL classification using a large-size dataset. Additionally, a state-of-the-art pretrained model, BiT (Big Transfer), by Google Research, was evaluated for ArSL classification.
- This study investigates the use of vision transformers namely ViT and Swin, with the transfer learning approach for ArSL classification. Since the literature review studies have shown successful vision-based transformer models applied to other sign languages, these vision transformers are also investigated and evaluated for ArSL classification.
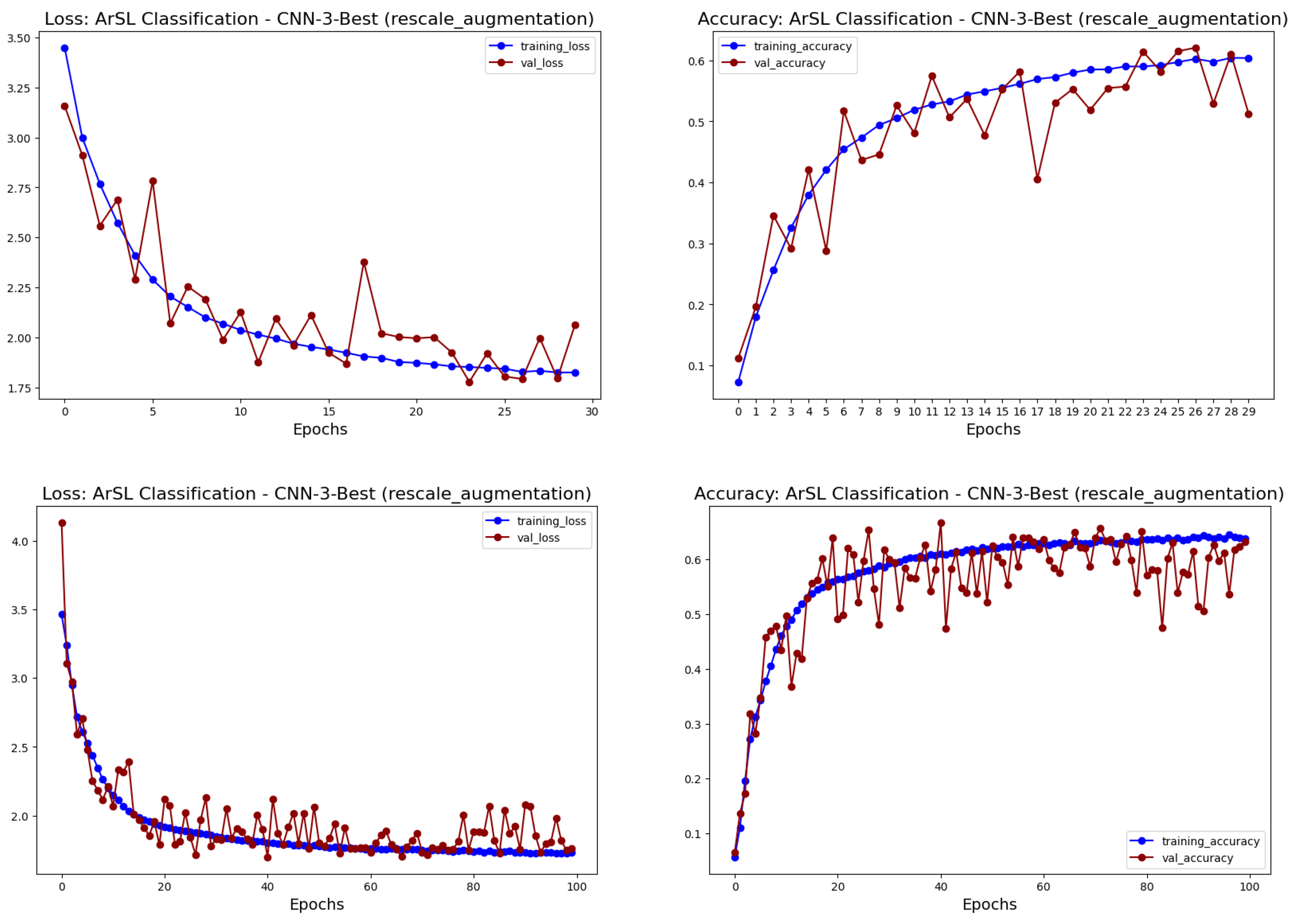
- Finally, this research work investigates several deep learning convolutional neural network (CNN) architectures trained from scratch for ArSL classification and compares their results with the proposed transfer learning models for ArSL classification. An ablation study was conducted to compare different architectural models of CNN for the classification of Arabic sign language alphabets.
2. Related Works
2.1. Overview of SL Classification Research Based on Methods
2.2. Overview of SL Classification Research Based on Languages
2.3. Overview of SL Classification Research Based on Arabic Language
2.4. Overview of SL Classification Research Based on Datasets
3. Methodology
3.1. General Framework
3.2. Transfer Learning for ArSL Classification
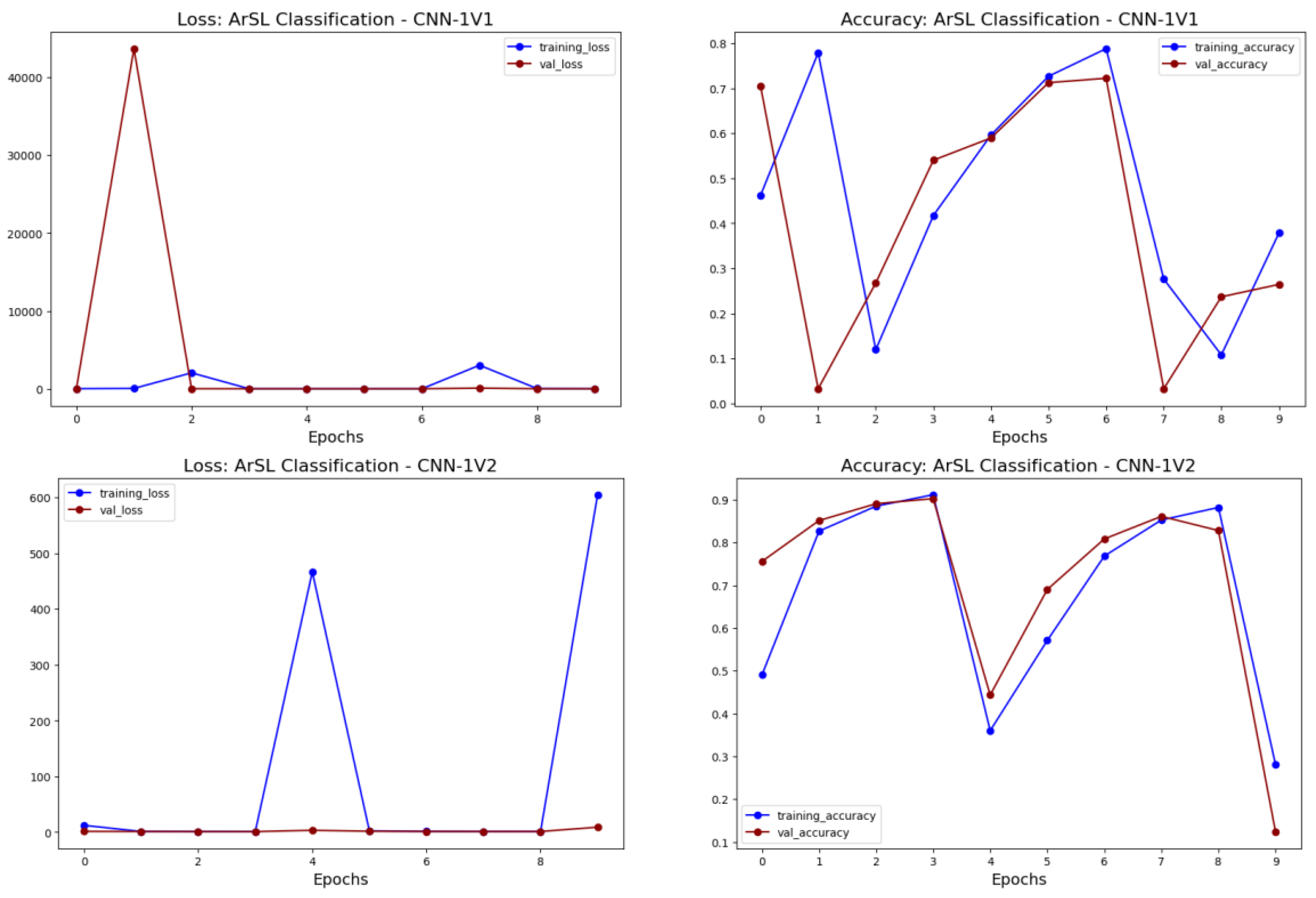
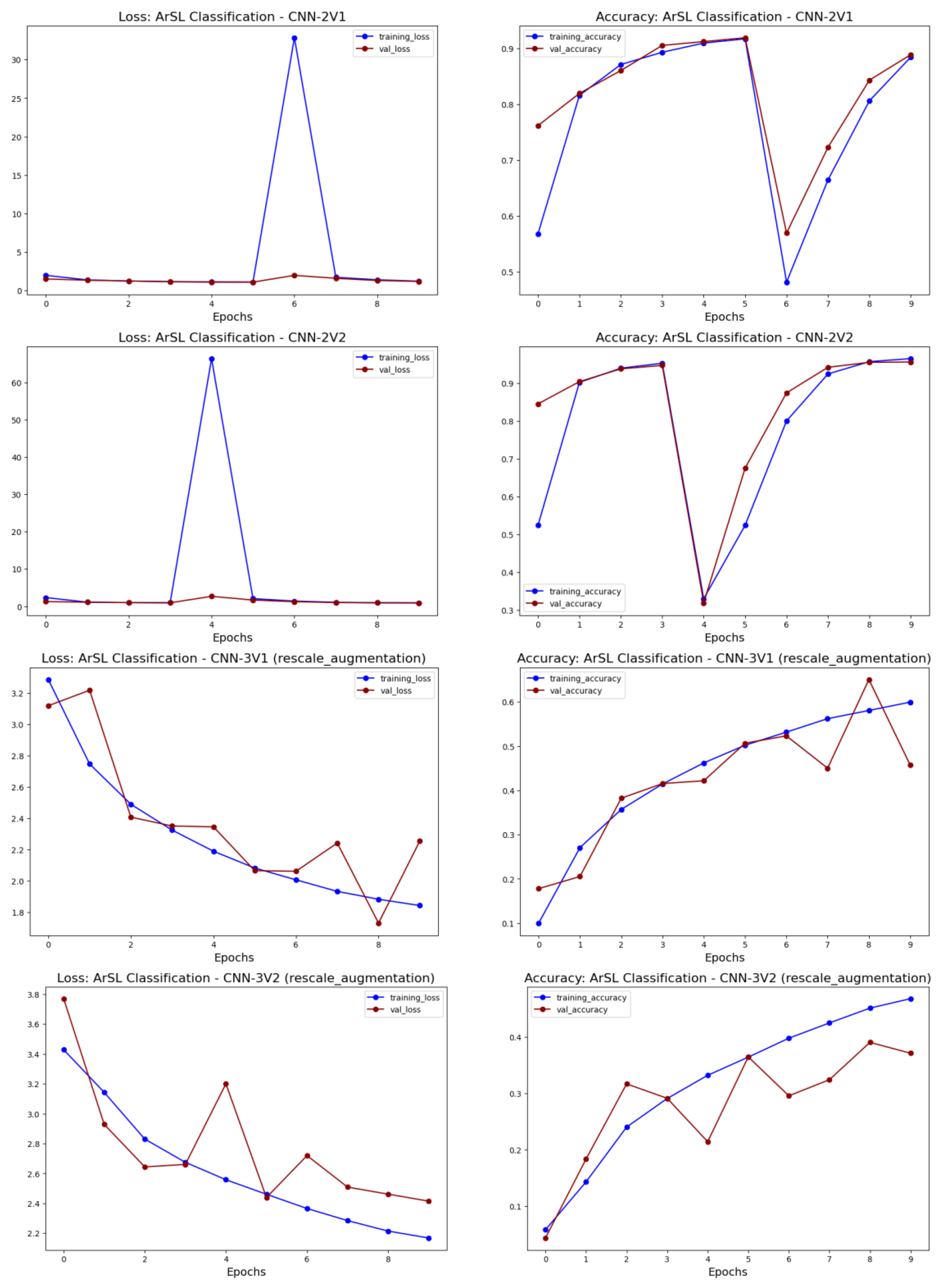
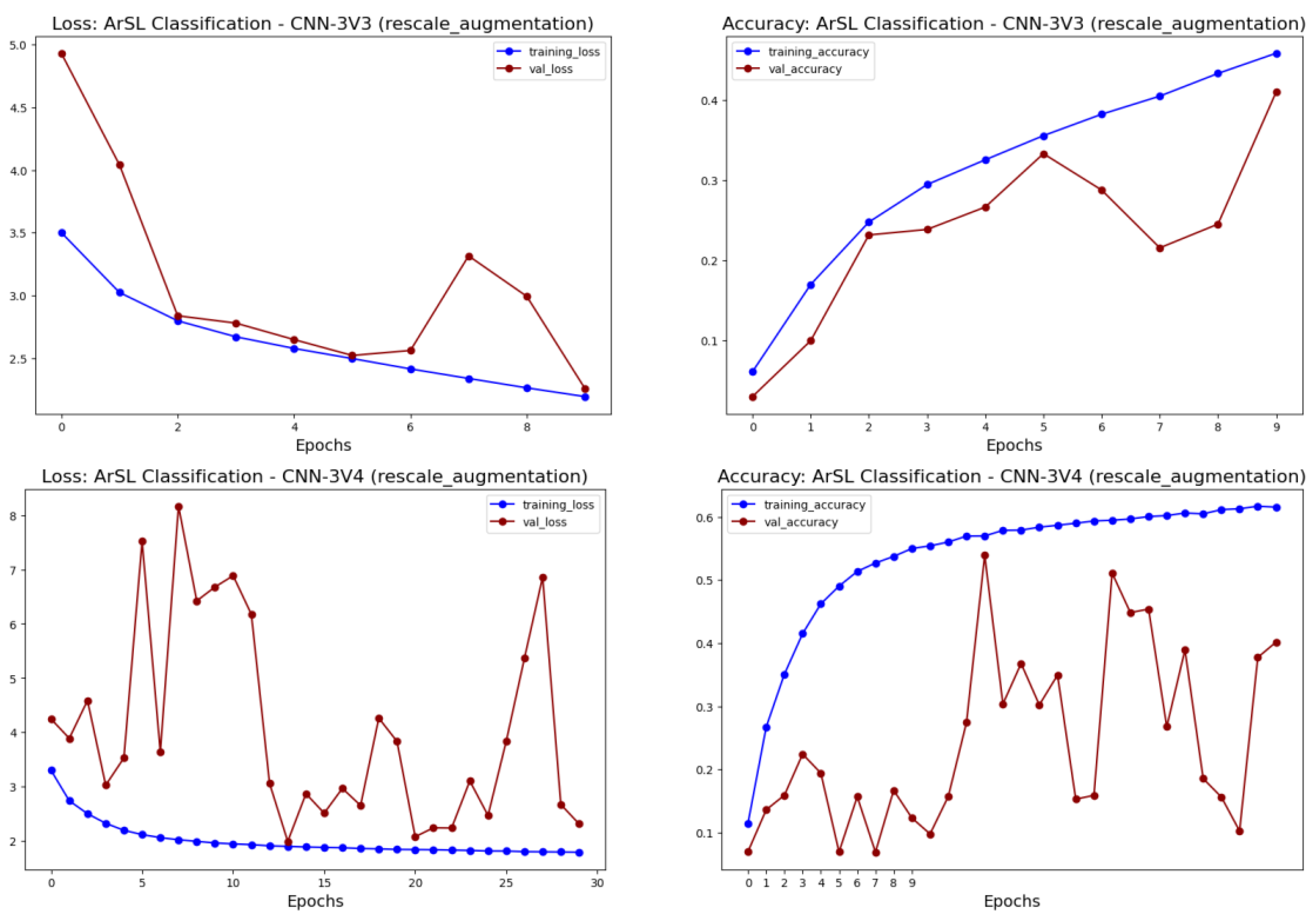
3.3. CNN for ArSL Classification: An Ablation Study
4. Experimental Setup
4.1. Dataset
4.2. Baselines
4.3. Resources and Tools
4.4. Evaluation
5. Experimental Results
5.1. Experimental Results from the CNN Approach
5.2. Experimental Results from the Transfer Learning Approach
6. Conclusions and Future Works
- Address the imbalance in datasets: Imbalanced datasets can affect the performance of deep learning models. Future work can focus on handling the class imbalance present in ArSL datasets to ensure a fair representation and improve the accuracy of minority classes.
- Extend the research to video-based ArSL recognition: The paper focused on ArSL recognition in images, but future work can expand the research to video-based ArSL recognition. This would involve considering temporal information and exploring techniques such as 3D convolutional networks or temporal transformers to capture motion and dynamic features in sign language videos.
- Investigate hybrid approaches: Explore hybrid approaches that combine both pretrained models and vision transformers. Investigate ways to leverage the strengths of both architectures to achieve an even higher accuracy and stability in ArSL recognition tasks. This could involve combining features from pretrained models with the attention mechanisms of vision transformers.
- Further investigate the fine-tuning strategies and optimization techniques for transfer learning with pretrained models and vision transformers. Explore different hyperparameter settings, learning rate schedules, and regularization methods to improve the performance and stability of the models.
- Explore techniques for data augmentation and generation specifically tailored for ArSL recognition. This can help overcome the challenge of limited data and enhance the performance and generalization of the models. Techniques such as generative adversarial networks (GANs) or domain adaptation can be investigated.
- Investigate cross-language transfer learning: Explore how pretrained models and vision transformers trained on one sign language can be used to improve the performance of models on another sign language with limited resources. This can help address the challenges faced by sign languages with limited data availability.
- Finally, continue benchmarking and comparing different architectures, pretrained models, and vision transformers on ArSL recognition tasks. Evaluate their performance on larger and more diverse datasets to gain a deeper understanding of their capabilities and limitations. This can help identify the most effective models for specific ArSL recognition scenarios.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- May, J.J. Occupational hearing loss. Am. J. Ind. Med. 2000, 37, 112–120. [Google Scholar] [CrossRef]
- Areeb, Q.M.; Maryam; Nadeem, M.; Alroobaea, R.; Anwer, F. Helping Hearing-Impaired in Emergency Situations: A Deep Learning-Based Approach. IEEE Access 2022, 10, 8502–8517. [Google Scholar] [CrossRef]
- Tharwat, G.; Ahmed, A.M.; Bouallegue, B. Arabic Sign Language Recognition System for Alphabets Using Machine Learning Techniques. J. Electr. Comput. Eng. 2021, 2021, 2995851. [Google Scholar] [CrossRef]
- Pan, T.Y.; Lo, L.Y.; Yeh, C.W.; Li, J.W.; Liu, H.T.; Hu, M.C. Real-Time Sign Language Recognition in Complex Background Scene Based on a Hierarchical Clustering Classification Method. In Proceedings of the IEEE Second International Conference on Multimedia Big Data (BigMM), Taipei, Taiwan, 20–22 April 2016; pp. 64–67. [Google Scholar]
- Mohammed, R.M.; Kadhem, S.M. A review on Arabic sign language translator systems. J. Phys. Conf. Ser. 2021, 1818, 012033. [Google Scholar] [CrossRef]
- Al-Obodi, A.H.; Al-Hanine, A.M.; Al-Harbi, K.N.; Al-Dawas, M.S.; Al-Shargabi, A.A. A Saudi Sign Language recognition system based on convolutional neural networks. Build. Serv. Eng. Res. Technol. 2020, 13, 3328–3334. [Google Scholar] [CrossRef]
- ElBadawy, M.; Elons, A.S.; Shedeed, H.A.; Tolba, M.F. Arabic sign language recognition with 3D convolutional neural networks. In Proceedings of the 8th International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 66–71. [Google Scholar]
- Baktash, A.Q.; Mohammed, S.L.; Jameel, H.F. Multi-sign language glove based hand talking system. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1105, 012078. [Google Scholar] [CrossRef]
- Sadek, M.I.; Mikhael, M.N.; Mansour, H.A. A new approach for designing a smart glove for Arabic Sign Language Recognition system based on the statistical analysis of the Sign Language. In Proceedings of the 34th National Radio Science Conference (NRSC), Port Said, Egypt, 13–16 March 2017; pp. 380–388. [Google Scholar]
- Alsaadi, Z.; Alshamani, E.; Alrehaili, M.; Alrashdi, A.A.D.; Albelwi, S.; Elfaki, A.O. A real time Arabic sign language alphabets (ArSLA) recognition model using deep learning architecture. Computers 2022, 11, 78. [Google Scholar] [CrossRef]
- Kamruzzaman, M.M.; Zhang, Y. Arabic Sign Language Recognition and Generating Arabic Speech Using Convolutional Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 3685614. [Google Scholar] [CrossRef]
- Latif, G.; Mohammad, N.; Alghazo, J.; AlKhalaf, R.; AlKhalaf, R. ArASL: Arabic Alphabets Sign Language Dataset. Data Brief 2019, 23, 103777. [Google Scholar] [CrossRef]
- Areeb, Q.M.; Nadeem, M. Deep Learning Based Hand Gesture Recognition for Emergency Situation: A Study on Indian Sign Language. In Proceedings of the International Conference on Data Analytics for Business and Industry (ICDABI), Online, 25–26 October 2021; pp. 33–36. [Google Scholar]
- Rajan, R.G.; Leo, M.J. American Sign Language Alphabets Recognition using Hand Crafted and Deep Learning Features. In Proceedings of the International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 430–434. [Google Scholar]
- Aich, D.; Zubair, A.A.; Hasan, K.M.Z.; Nath, A.D.; Hasan, Z. A Deep Learning Approach for Recognizing Bengali Character Sign Langauage. In Proceedings of the 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar]
- Chong, T.W.; Lee, B.G. American Sign Language Recognition Using Leap Motion Controller with Machine Learning Approach. Sensors 2018, 18, 3554. [Google Scholar] [CrossRef]
- Rosero-Montalvo, P.D.; Godoy-Trujillo, P.; Flores-Bosmediano, E.; Carrascal-García, J.; Otero-Potosi, S.; Benitez-Pereira, H.; Peluffo-Ordóñez, D.H. Sign Language Recognition Based on Intelligent Glove Using Machine Learning Techniques. In Proceedings of the IEEE Third Ecuador Technical Chapters Meeting (ETCM), Cuenca, Ecuador, 15–19 October 2018; pp. 1–5. [Google Scholar]
- Mustafa, M. A study on Arabic sign language recognition for differently abled using advanced machine learning classifiers. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4101–4115. [Google Scholar] [CrossRef]
- Chaikaew, A. An Applied Holistic Landmark with Deep Learning for Thai Sign Language Recognition. In Proceedings of the 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; pp. 1046–1049. [Google Scholar]
- Bhadra, R.; Kar, S. Sign Language Detection from Hand Gesture Images using Deep Multi-layered Convolution Neural Network. In Proceedings of the IEEE Second International Conference on Control, Measurement and Instrumentation (CMI), Kolkata, India, 8–10 January 2021; pp. 196–200. [Google Scholar]
- Htet, S.M.; Aye, B.; Hein, M.M. Myanmar Sign Language Classification using Deep Learning. In Proceedings of the International Conference on Advanced Information Technologies (ICAIT), Yangon, Myanmar, 4–5 November 2020; pp. 200–205. [Google Scholar]
- Kasapbaşi, A.; Elbushra, A.E.A.; Al-Hardanee, O.; Yilmaz, A. DeepASLR: A CNN based human computer interface for American Sign Language recognition for hearing-impaired individuals. Comput. Methods Programs Biomed. Update 2022, 2, 100048. [Google Scholar] [CrossRef]
- Schmalz, V.J. Real-time Italian Sign Language Recognition with Deep Learning. In Proceedings of the AIxIA Italian Association for Artificial Intelligence, Milan, Italy, 12 March 2021; pp. 45–57. [Google Scholar]
- Zahid, H.; Rashid, M.; Hussain, S.; Azim, F.; Syed, S.A.; Saad, A. Recognition of Urdu sign language: A systematic review of the machine learning classification. PeerJ. Comput. Sci. 2022, 8, e883. [Google Scholar] [CrossRef] [PubMed]
- Tolentino, L.K.; Serfa Juan, R.; Thio-ac, A.; Pamahoy, M.; Forteza, J.; Garcia, X. Static Sign Language Recognition Using Deep Learning. Int. J. Mach. Learn. Comput. 2019, 9, 821–827. [Google Scholar] [CrossRef]
- De Coster, M.; Van Herreweghe, M.; Dambre, J. Sign Language Recognition with Transformer Networks. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6018–6024. [Google Scholar]
- Attar, R.K.; Goyal, V.; Goyal, L. State of the Art of Automation in Sign Language: A Systematic Review. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 94. [Google Scholar] [CrossRef]
- Adeyanju, I.A.; Bello, O.O.; Adegboye, M.A. Machine learning methods for sign language recognition: A critical review and analysis. Intell. Syst. Appl. 2021, 12, 200056. [Google Scholar] [CrossRef]
- Joshi, G.; Singh, S.; Vig, R. Taguchi-TOPSIS based HOG parameter selection for complex background sign language recognition. J. Vis. Commun. Image Represent. 2020, 71, 102834. [Google Scholar] [CrossRef]
- Barbhuiya, A.A.; Karsh, R.K.; Jain, R. CNN based feature extraction and classification for sign language. Multimed. Tools Appl. 2021, 80, 3051–3069. [Google Scholar] [CrossRef]
- Suriya, M.; Sathyapriya, N.; Srinithi, M.; Yesodha, V. Survey on real time sign language recognition system: An LDA approach. In Proceedings of the International Conference on Exploration and Innovations in Engineering and Technology, ICEIET, Wuhan, China, 26–27 March 2016; pp. 219–225. [Google Scholar]
- Mittal, A.; Kumar, P.; Roy, P.P.; Balasubramanian, R.; Chaudhuri, B.B. A Modified LSTM Model for Continuous Sign Language Recognition Using Leap Motion. IEEE Sens. J. 2019, 19, 7056–7063. [Google Scholar] [CrossRef]
- Luqman, H.; El-Alfy, E.-S.M. Towards Hybrid Multimodal Manual and Non-Manual Arabic Sign Language Recognition: mArSL Database and Pilot Study. Electronics 2021, 10, 1739. [Google Scholar] [CrossRef]
- Sincan, O.M.; Keles, H.Y. AUTSL: A Large Scale Multi-Modal Turkish Sign Language Dataset and Baseline Methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Bencherif, M.A.; Algabri, M.; Mekhtiche, M.A.; Faisal, M.; Alsulaiman, M.; Mathkour, H.; Al-Hammadi, M.; Ghaleb, H. Arabic Sign Language Recognition System Using 2D Hands and Body Skeleton Data. IEEE Access 2021, 9, 59612–59627. [Google Scholar] [CrossRef]
- Kumar, K. DEAF-BSL: Deep lEArning Framework for British Sign Language recognition. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 101. [Google Scholar] [CrossRef]
- Maraqa, M.; Abu-Zaiter, R. Recognition of Arabic Sign Language (ArSL) using recurrent neural networks. In Proceedings of the 1st International Conference on the Applications of Digital Information and Web Technologies (ICADIWT), Ostrava, Czech Republic, 4–6 August 2008; pp. 478–481. [Google Scholar]
- Lee, C.K.M.; Ng, K.K.H.; Chen, C.-H.; Lau, H.C.W.; Chung, S.Y.; Tsoi, T. American sign language recognition and training method with recurrent neural network. Expert Syst. Appl. 2021, 167, 114403. [Google Scholar] [CrossRef]
- Al-Barham, M.; Sa’Aleek, A.A.; Al-Odat, M.; Hamad, G.; Al-Yaman, M.; Elnagar, A. Arabic Sign Language Recognition Using Deep Learning Models. In Proceedings of the 13th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 21–23 June 2022; pp. 226–231. [Google Scholar]
- Saleh, Y.; Issa, G.F. Arabic Sign Language Recognition through Deep Neural Networks Fine-Tuning. Int. J. Online Biomed. Eng. Ijoe 2020, 16, 71–83. [Google Scholar] [CrossRef]
- Aly, W.; Aly, S.; Almotairi, S. User-Independent American Sign Language Alphabet Recognition Based on Depth Image and PCANet Features. IEEE Access 2019, 7, 123138–123150. [Google Scholar] [CrossRef]
- Abdullahi, S.B.; Chamnongthai, K. American Sign Language Words Recognition Using Spatio-Temporal Prosodic and Angle Features: A Sequential Learning Approach. IEEE Access 2022, 10, 15911–15923. [Google Scholar] [CrossRef]
- Wu, J.; Sun, L.; Jafari, R. A Wearable System for Recognizing American Sign Language in Real-Time Using IMU and Surface EMG Sensors. IEEE J. Biomed. Health Inform. 2016, 20, 1281–1290. [Google Scholar] [CrossRef]
- Lee, B.G.; Lee, S.M. Smart Wearable Hand Device for Sign Language Interpretation System with Sensors Fusion. IEEE Sens. J. 2018, 18, 1224–1232. [Google Scholar] [CrossRef]
- Li, L.; Jiang, S.; Shull, P.B.; Gu, G. SkinGest: Artificial skin for gesture recognition via filmy stretchable strain sensors. Adv. Robot. 2018, 32, 1112–1121. [Google Scholar] [CrossRef]
- Al Khalissi, R.; Khamess, M. A Real-Time American Sign Language Recognition System Using Convolutional Neural Network for Real Datasets; ResearchGate: Berlin, Germany, 2020; Volume 9. [Google Scholar]
- Trujillo-Romero, F.; García-Bautista, G. Mexican Sign Language Corpus: Towards an automatic translator. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 212. [Google Scholar] [CrossRef]
- Al-Shamayleh, A.S.; Ahmad, R.; Jomhari, N.; Abushariah, M.A.M. Automatic Arabic sign language recognition: A review, taxonomy, open challenges, research roadmap and future directions. Malays. J. Comput. Sci. 2020, 33, 306–343. [Google Scholar] [CrossRef]
- Podder, K.K.; Ezeddin, M.; Chowdhury, M.E.H.; Sumon, M.S.I.; Tahir, A.M.; Ayari, M.A.; Dutta, P.; Khandakar, A.; Mahbub, Z.B.; Kadir, M.A. Signer-Independent Arabic Sign Language Recognition System Using Deep Learning Model. Sensors 2023, 23, 7156. [Google Scholar] [CrossRef] [PubMed]
- Khellas, K.; Seghir, R. Alabib-65: A Realistic Dataset for Algerian Sign Language Recognition. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 178. [Google Scholar] [CrossRef]
- Mirza, M.S.; Munaf, S.M.; Azim, F.; Ali, S.; Khan, S.J. Vision-based Pakistani sign language recognition using bag-of-words and support vector machines. Sci. Rep. 2022, 12, 21325. [Google Scholar] [CrossRef] [PubMed]
- Adithya, V.; Vinod, P.R.; Gopalakrishnan, U. Artificial neural network based method for Indian sign language recognition. In Proceedings of the IEEE Conference on Information & Communication Technologies, Tamil Nadu, India, 11–12 April 2013; pp. 1080–1085. [Google Scholar]
- Dhivyasri, S.; KB, K.H.; Akash, M.; Sona, M.; Divyapriya, S.; Krishnaveni, V. An Efficient Approach for Interpretation of Indian Sign Language using Machine Learning. In Proceedings of the 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 130–133. [Google Scholar]
- Kumar, P.; Kaur, S. Sign Language Generation System Based on Indian Sign Language Grammar. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2020, 19, 54. [Google Scholar] [CrossRef]
- Islam, M.S.; Mousumi, S.S.S.; Jessan, N.A.; Rabby, A.S.A.; Hossain, S.A. Ishara-Lipi: The First Complete MultipurposeOpen Access Dataset of Isolated Characters for Bangla Sign Language. In Proceedings of the International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 21–22 September 2018; pp. 1–4. [Google Scholar]
- Kamal, S.M.; Chen, Y.; Li, S.; Shi, X.; Zheng, J. Technical Approaches to Chinese Sign Language Processing: A Review. IEEE Access 2019, 7, 96926–96935. [Google Scholar] [CrossRef]
- Jiang, X.; Satapathy, S.; Yang, L.; Wang, S.-H.; Zhang, Y. A Survey on Artificial Intelligence in Chinese Sign Language Recognition. Arab. J. Sci. Eng. 2020, 45, 9859–9894. [Google Scholar] [CrossRef]
- Daniels, S.; Suciati, N.; Fathichah, C. Indonesian Sign Language Recognition using YOLO Method. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1077, 012029. [Google Scholar] [CrossRef]
- Nureña-Jara, R.; Ramos-Carrión, C.; Shiguihara-Juárez, P. Data collection of 3D spatial features of gestures from static peruvian sign language alphabet for sign language recognition. In Proceedings of the IEEE Engineering International Research Conference (EIRCON), Lima, Peru, 21–23 October 2020; pp. 1–4. [Google Scholar]
- Al-Qurishi, M.; Khalid, T.; Souissi, R. Deep Learning for Sign Language Recognition: Current Techniques, Benchmarks, and Open Issues. IEEE Access 2021, 9, 126917–126951. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, K. ASL-3DCNN: American sign language recognition technique using 3-D convolutional neural networks. Multimed. Tools Appl. 2021, 80, 26319–26331. [Google Scholar] [CrossRef]
- Jain, V.; Jain, A.; Chauhan, A.; Kotla, S.S.; Gautam, A. American Sign Language recognition using Support Vector Machine and Convolutional Neural Network. Int. J. Inf. Technol. 2021, 13, 1193–1200. [Google Scholar] [CrossRef]
- Abdallah, M.; Hemayed, E. Dynamic Hand Gesture Recognition of Arabic Sign Language using Hand Motion Trajectory Features. Glob. J. Comput. Sci. Technol. Graph. Vis. 2013, 13, 26–33. [Google Scholar]
- Yuan, T.; Sah, S.; Ananthanarayana, T.; Zhang, C.; Bhat, A.; Gandhi, S.; Ptucha, R. Large Scale Sign Language Interpretation. In Proceedings of the 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Singh, D.K. 3D-CNN based Dynamic Gesture Recognition for Indian Sign Language Modeling. Procedia Comput. Sci. 2021, 189, 76–83. [Google Scholar] [CrossRef]
- Tampu, I.E.; Eklund, A.; Haj-Hosseini, N. Inflation of test accuracy due to data leakage in deep learning-based classification of OCT images. Sci. Data 2022, 9, 580. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:1610.02357. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Kolesnikov, A.; Beyer, L.; Zhai, X.; Puigcerver, J.; Yung, J.; Gelly, S.; Houlsby, N. Big Transfer (BiT): General Visual Representation Learning. arXiv 2020, arXiv:1912.11370. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SL | Feature Extraction/Characterization | Accuracy | Ref. |
|---|---|---|---|---|
| SVM | Indian | HOG based on Taguchi and TOPSIS | 92% for ISL and 99.2% for ASL | [29] |
| American | Used images captured in complex backgrounds | 99.80% | [4] | |
| KNN | Arabic | Classified 28-letter Arabic alphabet using 9240 images. | 90.25% | [3] |
| LDA | American | Used five classes with 50 input images. | 62% | [31] |
| MLP | American | Used static ASL gesture | 96.96% | [28] |
| CNN | Italian | Used multiangle images, frontal images only. | 99% with VGG19, 97% with CNN | [23] |
| American | CNN based on AlexNet and VGG16 for hand gestures | 99.82% | [30] | |
| British | 3D CNN for 26 BSL alphabets classification | 98.00% | [36] | |
| Turkish | Employed feature extraction module designed with parallel convolutions with different dilation rates | Best baseline model achieved a 62.02% accuracy. | [34] | |
| Indian | Used a 2D CNN for feature extraction, where twelve 3D features at time t were processed | 72.3% on signed sentences and 89.5% on isolated sign words. | [32] | |
| 3D CNN for videos for eight emergency situations | 82% | [2] | ||
| Arabic | Each captured sign was represented by five modalities: color, depth, joint points, face, and face-HD | MobileNet-LSTM 99.7% for signer dependent and 72.4% for signer-independent | [33] | |
| 3D CNN was used to recognize 25 gestures | 98% for observed data and 85% for new data | [7] | ||
| 3D CNN skeleton network and a 2D point convolution network using 80 static and dynamic signs that were repeated five times by 40 signers | In dependent mode: 98.39% for dynamic, 88.89% for static signs. In independent mode: 96.69% for dynamic, 86.34% for static. | [35] | ||
| RNN | American | Sphere radius, angles between fingers, and distance between finger positions using 2600 samples | 99.44% | [38] |
| Arabic | Recurrent neural networks (RNN) | 95.11%. | [37] | |
| LSTM | Indian | 942 signed sentences using 35 different sign words | 72.3% for signed sentences and 89.5% for isolated sign words | [32] |
| Recurrent neural network with long short-term memory (RNN-LSTM) | 98% | [2] | ||
| Transfer Learning | American | VGG-19 | 98.44% | [14] |
| Arabic | VGG-16 and ResNet152 with ArSL classification | 99% | [39,40] | |
| Indian | VGG-16 and YOLO (You Only Look Once) v5, for advanced object detection algorithm | 99.60% | [2] |
| Sign Language | Acronym | No of studies | Studies [2020–2023] |
|---|---|---|---|
| Arabic | ArSL | 7 | [3,7,10,11,39,40,48] |
| Algerian | AlSL | 1 | [50] |
| American | ASL | 11 | [16,22,38,41,42,43,44,45,46,61,62] |
| Bangla | BdSL | 1 | [55] |
| British | BSL | 1 | [36] |
| Chinese | CSL | 2 | [26,28,56,57] |
| Indian | ISL | 2 | [52,53,54] |
| Indonesian | ISINDO | 1 | [58] |
| Italian | LIS | 1 | [23] |
| Mexican | MSL | 1 | [47] |
| Pakistani | PKSL | 1 | [51] |
| Peruvian | PSL | 1 | [59] |
| Turkish | TSL | 1 | [28] |
| Urdu | USL | 1 | [24] |
| Ref. | Background Conditions | Hands | Signers | Signs | Acquisition Mode | Lexicon Size | Method | Dataset | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [23] | - | - | 11 | 22 signed letters | - | 11,008 | CNN | LIS | Static | Public | Isolated |
| [59] | - | Double-handed | - | 24 static gestures | HTC Vive, Vive Hand Tracking SDK 0.8.2. | 35,400 | MLP, SVM KNN, RF | PSL | |||
| [47] | - | - | 150 | 570 words and 30 phrases | Kinect sensor | 90,000 | MLP | MSL | |||
| [16] | Nonuniform background | Single-handed | - | 26 letters and 10 digits | - | - | LMC | ASL | Static + dynamic | ||
| [55] | White backgrounds | Double-handed | - | 50 sets of 36 Bangla basic sign characters | Camera | 1800-character images | CNN | BdSL | |||
| [3] | Uniform background + nonuniform background | Single-handed | 10 | 28-letter Arabic alphabet | Integrated laptop webcam, smart Huawei mobile camera | 9240 images | KNN classifier | ArSL | Self-built | ||
| [34] | Nonuniform background | Single + double | 43 | 226 signs | Microsoft Kinect v2 | 38,336 | CNN | TSL | |||
| [63] | Nonuniform background | Single + double | 4 | 20 meaningful words of Arabic signs | Microsoft Kinect v2 camera | 7350 RGB videos, 7350 depth videos | single deep networks | ArSL | dynamic | Self -built | Continuous |
| [49] | Uniform background | Both | 4 | Manual, nonmanual gestures for signs | Kinect V2 acquisition system | 6667 videos | MobileNetV2, ResNet18, CNN-LSTM-SelfMLP | ArSL | |||
| [33] | Nonuniform background | Single + double | 4 | 50 signs | Kinect V2 sensors | 6748 video samples | CNN | CSL | |||
| [64] | Nonuniform background | Single + double | 50 | 10,000 utterances each with 10–30 characters | Microsoft Kinect 2.0 | 50,000 videos | CNN | CSL | |||
| [50] | 22 background simple to cluttered | 41 | 65 sign classes | 6238 videos | SVM, VGG16-GRU, I3D, I3D-GRU-Attention | AlSL | |||||
| [51] | Uniform background | Single-handed | 10 | 36 static alphabet signs + 3 dynamic signs | 48MP smart phone camera | 5120 images, 353 videos | Bag of words + SVM | PKSL | Static dynamic | Self-built | Mixed |
| [65] | Uniform background | Single-handed | 40 | 80 signs | Kinect V1, V2, Sony cam | 16,000 × 3 | Concatenation of 3D and 2D CNN | ArSL | Static | Public | |
| Model | Input Shape | No Convolution Layers | Conv. Filters | Conv. Size | Max Pool | Trainable Params | ≈Time (s) | |
|---|---|---|---|---|---|---|---|---|
| CNN-1 | CNN-1V1 | 224 × 224 | conv1, conv2, conv3 + leaky ReLU, fully connected layer + softmax | 224, 112, 56 | 3 × 3 | 2 × 2 | 1,693,640 | 5646 |
| CNN-1V2 | 224 × 224 | 64, 64, 64 | 3 × 3 | 2 × 2 | 1,681,312 | 1499 | ||
| CNN-2 | CNN-2V1 | 224 × 224 | conv1, conv2, conv3, conv4, conv5 + leaky ReLU, fully connected layer + softmax | 224, 112, 56, 28, 14 | 3 × 3 | 2 × 2 | 328,346 | 4262 |
| CNN-2V2 | 224 × 224 | 64, 64, 64, 64, 64 | 3 × 3 | 2 × 2 | 249,888 | 1128 | ||
| CNN-3 | CNN-3V1 | 224 × 224 | conv1, conv2, conv3, conv4, conv5 + leaky ReLU, fully connected layer + softmax, data augmentation | 64, 64, 64, 64, 64 | 3 × 3 | 2 × 2 | 250,144 | 1793 |
| CNN-3V2 | 224 × 224 | 224, 112, 56, 28, 14 | 3 × 3 | 2 × 2 | 353,612 | 4306 | ||
| CNN-3V3 | 224 × 224 | +1 batch normalization, 1 dropout | 256, 126, 64, 62, 16 | 5 × 5, 3 × 3 | 2 × 2 | 430,798 | 3852 | |
| CNN-3V4 | 224 × 224 | +1 batch normalization, 1 dropout (30 epochs) | 256, 126, 64, 62, 16 | 3 × 3 | 2 × 2 | 431,146 | 11,322 |
| No | Letter in Arabic | Transliteration | No. of Images | No | Letter in Arabic | Transliteration | No. of Images |
|---|---|---|---|---|---|---|---|
| 1 | أ | aleff | 1672 | 17 | ظ | dha | 1723 |
| 2 | ب | bb | 1791 | 18 | ع | ain | 2114 |
| 3 | ت | taa | 1838 | 19 | غ | ghain | 1977 |
| 4 | ث | thaa | 1766 | 20 | ف | fa | 1955 |
| 5 | ج | jeem | 1552 | 21 | ق | gaaf | 1705 |
| 6 | ح | haa | 1526 | 22 | ك | kaaf | 1774 |
| 7 | خ | khaa | 1607 | 23 | ل | laam | 1832 |
| 8 | د | dal | 1634 | 24 | م | meem | 1765 |
| 9 | ذ | thal | 1582 | 25 | ن | nun | 1819 |
| 10 | ر | ra | 1659 | 26 | هـ | ha | 1592 |
| 11 | ز | zay | 1374 | 27 | و | waw | 1371 |
| 12 | س | seen | 1638 | 28 | ئ | ya | 1722 |
| 13 | ش | sheen | 1507 | 29 | ة | toot | 1791 |
| 14 | ص | saad | 1895 | 30 | ال | al | 1343 |
| 15 | ض | dhad | 1670 | 31 | لا | la | 1746 |
| 16 | ط | ta | 1816 | 32 | ي | yaa | 1293 |
| Model | One-Cycle | After Training/Fine-Tuning | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Loss | Recall | Precision | AUC | Accuracy | Loss | F1 | ||
| CNN-1 | CNN-1V1 (10 epochs) | 0.7048 | 1.6866 | 0.1995 | 0.3775 | 0.7975 | 0.2644 | 3.6616 | 0.2612 |
| CNN-1V2 (10 epochs) | 0.7557 | 1.5515 | 0.1208 | 0.1277 | 0.6039 | 0.1244 | 9.0458 | 0.1158 | |
| CNN-2 | CNN-2V1 (10 epochs) | 0.7618 | 1.4914 | 0.7578 | 0.9745 | 0.9936 | 0.8890 | 1.1705 | 0.8487 |
| CNN-2V2 (10 epochs) | 0.8447 | 1.2781 | 0.8929 | 0.9938 | 0.9982 | 0.9556 | 0.9266 | 0.9402 | |
| CNN-3 | CNN-3V1 (10 epochs) | 0.1778 | 3.1198 | 0.2759 | 0.6394 | 0.9375 | 0.4574 | 2.2542 | 0.3398 |
| CNN-3V2 (10 epochs) | 0.0433 | 3.7693 | 0.1356 | 0.6222 | 0.9163 | 0.3708 | 2.4147 | 0.1962 | |
| CNN-3V3 (10 epochs) | 0.0298 | 4.9315 | 0.1514 | 0.7491 | 0.9308 | 0.4099 | 2.2581 | 0.2104 | |
| CNN-3V4 (10 epochs) | 0.0696 | 4.2459 | 0.2097 | 0.6267 | 0.9258 | 0.4016 | 2.3162 | 0.2682 | |
| CNN-3 best (30 epochs) | 0.0744 | 3.3914 | 0.3932 | 0.8294 | 0.9748 | 0.6377 | 1.7238 | 0.5033 | |
| CNN-3 best (100 epochs) | 0.0653 | 4.1342 | 0.3819 | 0.8582 | 0.9734 | 0.6323 | 1.7599 | 0.4842 | |
| Method | Model | Variants | One-Cycle | After Training/Fine-Tuning | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Loss | Recall | Precision | AUC | Accuracy | Loss | F1 | |||
| Deep Learning | CNN-3 | - | 0.0653 | 4.1342 | 0.3819 | 0.8582 | 0.9734 | 0.6323 | 1.7599 | 0.4842 |
| Transfer Learning | MobileNet | MobileNet | 0.9467 | 0.9608 | 0.9145 | 0.9912 | 0.9992 | 0.9641 | 0.8794 | 0.9500 |
| MobileNetV2 | 0.9467 | 0.9624 | 0.9169 | 0.9898 | 0.9993 | 0.9665 | 0.8851 | 0.9510 | ||
| Xception | Xception | 0.0365 | 3.4626 | 0.8731 | 0.9778 | 0.9967 | 0.9408 | 0.8821 | 0.9205 | |
| Inception | InceptionV3 | 0.8542 | 1.1860 | 0.7661 | 0.9530 | 0.9953 | 0.8851 | 1.0381 | 0.8420 | |
| InceptionResNetV2 | 0.7913 | 7.9896 | 0.9700 | 0.9900 | 0.9995 | 0.9817 | 0.7415 | 0.9800 | ||
| DenseNet | DenseNet169 | 0.6743 | 1.6610 | 0.2889 | 0.8711 | 0.9276 | 0.5587 | 2.0299 | 0.3888 | |
| BiT | BiT-m-r50x1 | 0.8690 | 0.4054 | 0.9128 | 0.6505 | 0.9582 | 0.9508 | 0.1901 | 0.7749 | |
| BiT-m-r50x3 | 0.8784 | 0.4404 | 0.9510 | 0.4009 | 0.9570 | 0.9004 | 0.5046 | 0.6185 | ||
| ViT | ViT_b16 | 0.8919 | 3.4436 | 0.8414 | 0.9519 | 0.9961 | 0.8919 | 0.9930 | 0.8925 | |
| ViT_132 | 0.0883 | 3.2602 | 0.8457 | 0.9483 | 0.9934 | 0.8868 | 1.0146 | 0.8928 | ||
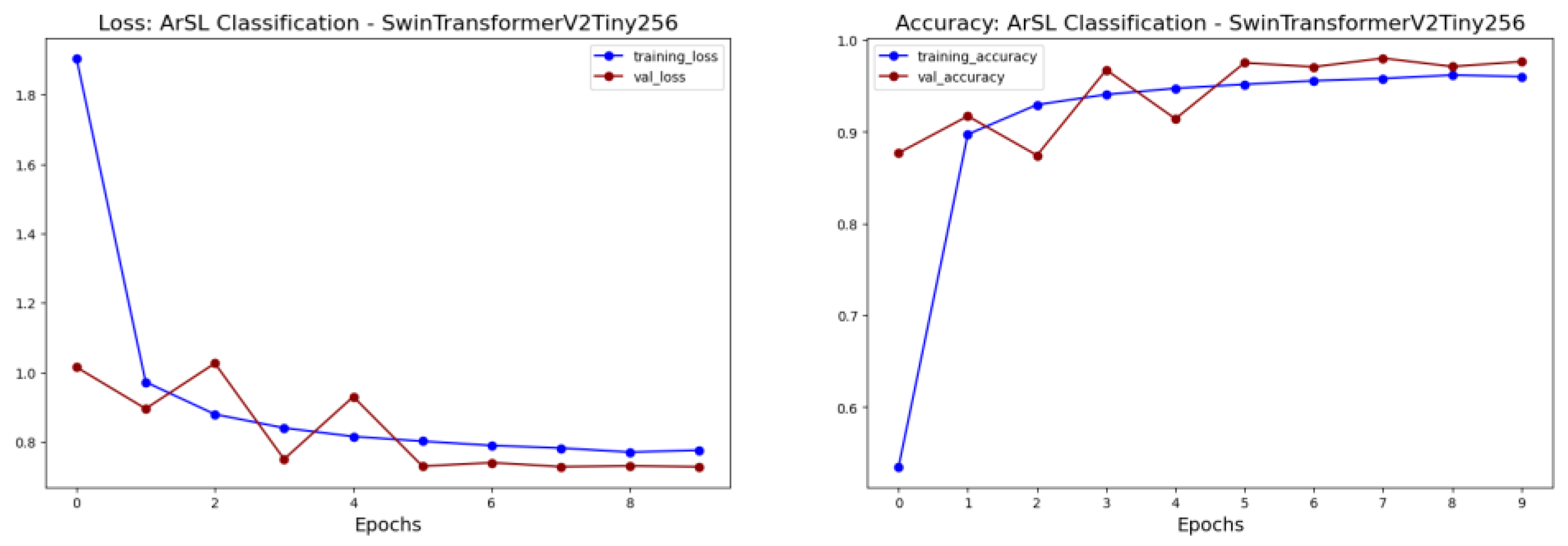
| Swin | SwinV2Tiny256 | 0.8769 | 1.0149 | 0.9713 | 0.9820 | 0.9993 | 0.9765 | 0.7284 | 0.9765 | |
| Baselines | VGG | VGG16 [39] | 0.8220 | 15.205 | 0.8621 | 0.8629 | 0.9413 | 0.8625 | 16.906 | 0.8641 |
| VGG19 | 0.8312 | 15.084 | 0.8558 | 0.8566 | 0.9380 | 0.8558 | 17.744 | 0.8558 | ||
| ResNet | ResNet50 | 0.9589 | 0.8674 | 0.9719 | 0.9904 | 0.9991 | 0.9824 | 0.7254 | 0.9808 | |
| ResNet152 [40] | 0.9702 | 0.8146 | 0.7948 | 0.9660 | 0.9933 | 0.9110 | 1.0331 | 0.8360 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alharthi, N.M.; Alzahrani, S.M. Vision Transformers and Transfer Learning Approaches for Arabic Sign Language Recognition. Appl. Sci. 2023, 13, 11625. https://doi.org/10.3390/app132111625
Alharthi NM, Alzahrani SM. Vision Transformers and Transfer Learning Approaches for Arabic Sign Language Recognition. Applied Sciences. 2023; 13(21):11625. https://doi.org/10.3390/app132111625
Chicago/Turabian StyleAlharthi, Nojood M., and Salha M. Alzahrani. 2023. "Vision Transformers and Transfer Learning Approaches for Arabic Sign Language Recognition" Applied Sciences 13, no. 21: 11625. https://doi.org/10.3390/app132111625
APA StyleAlharthi, N. M., & Alzahrani, S. M. (2023). Vision Transformers and Transfer Learning Approaches for Arabic Sign Language Recognition. Applied Sciences, 13(21), 11625. https://doi.org/10.3390/app132111625