
New Approach for Process Capability Analysis Using Multivariate Quality Characteristics




Abstract
:1. Introduction
2. Research Methodology
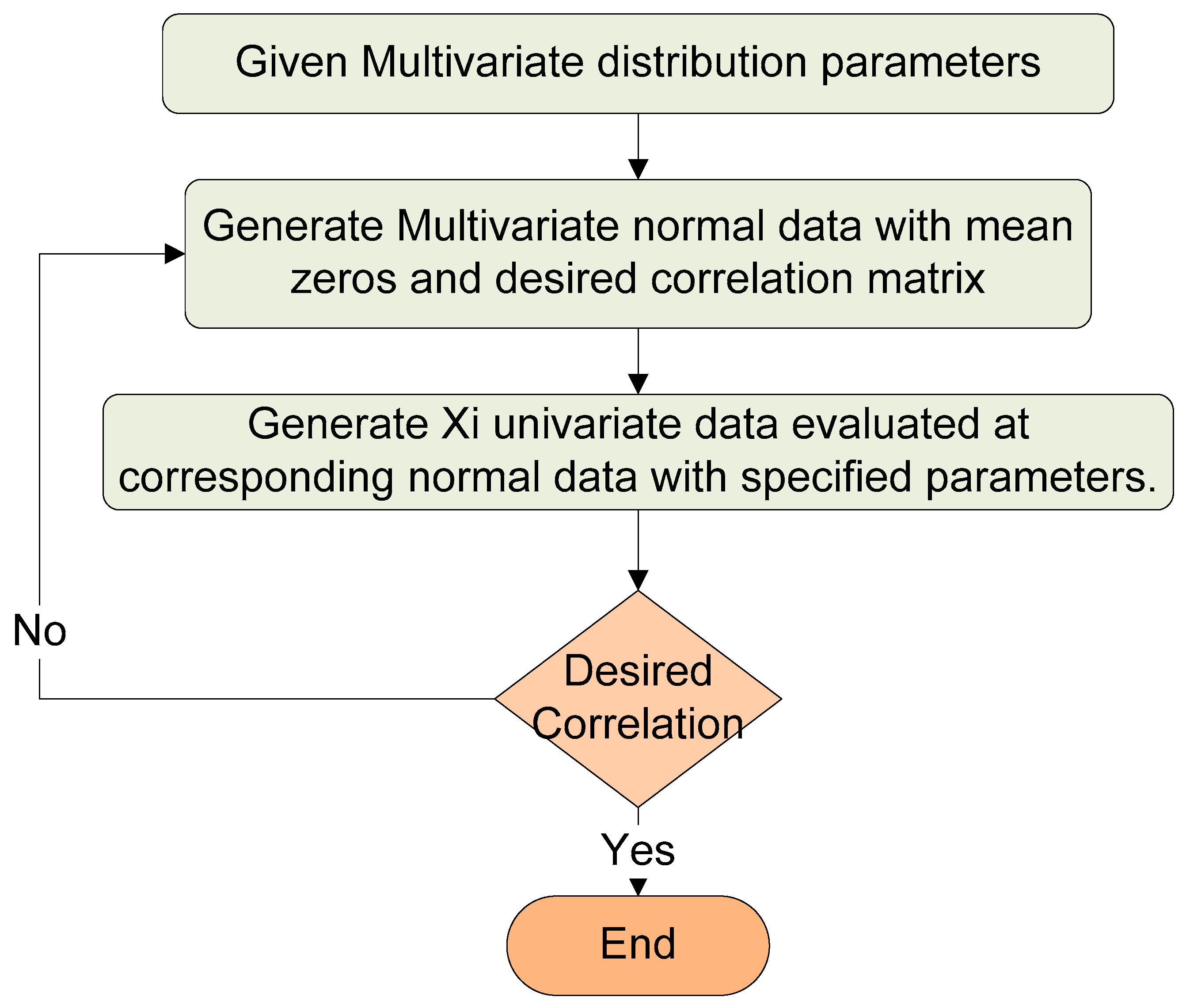
2.1. Proposed Methodology
- -
- First, the data should be normally distributed; thus, the proposed method consists of checking the normality assumption and transforming the nonnormal data into normal using the explained root transformation technique.
- -
- Second, the proposed multivariate process capability index is specific for correlated data. Consequently, unrelated multivariate variables could be individually investigated using a univariate capability index.
2.2. Evaluating the Proposed Methodology
3. Experiments
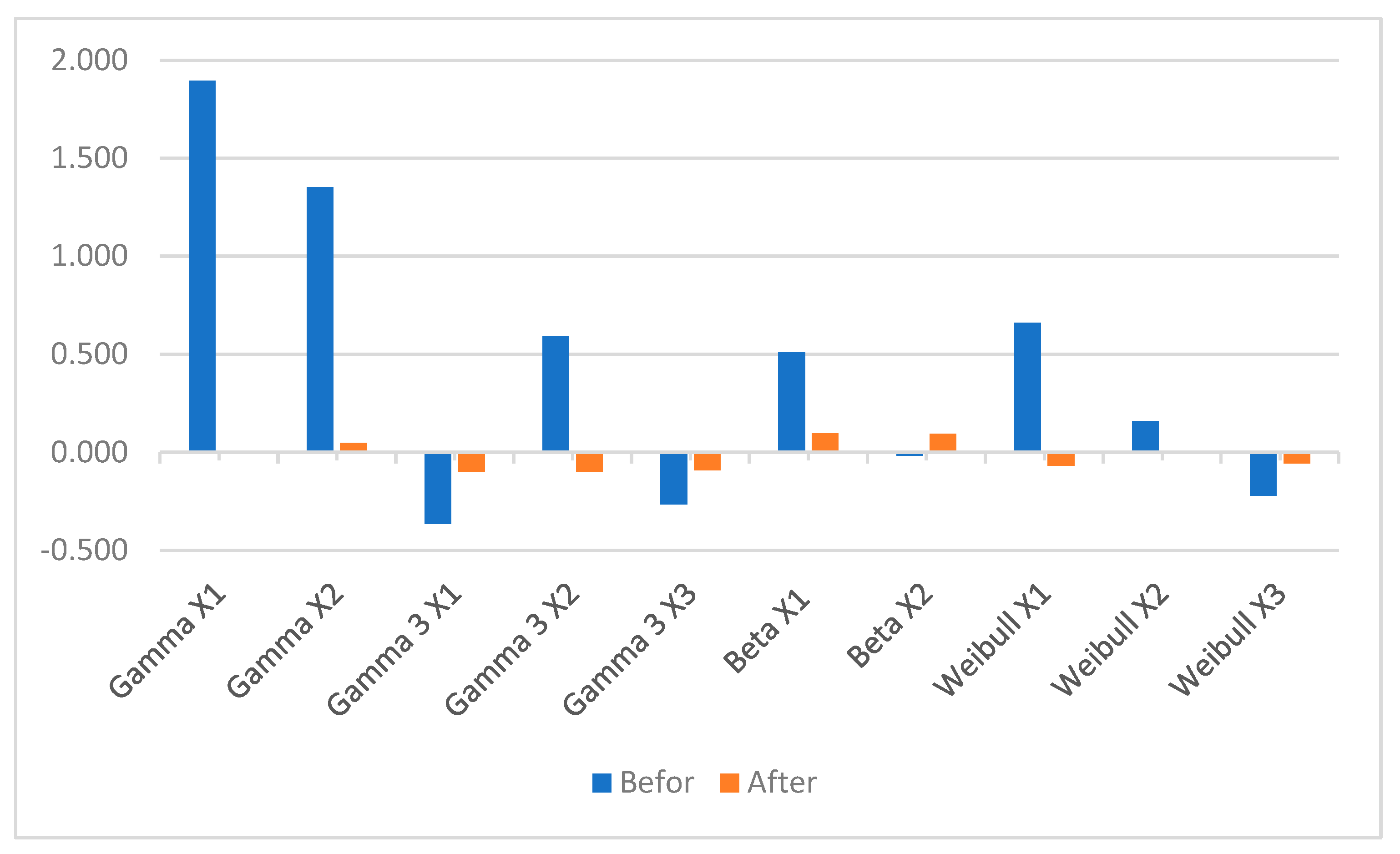
4. Results
5. Discussion
6. Managerial Insights
- Collecting and analyzing sufficient and representative data from the process. To calculate MPCI, one needs to have enough data from the process to estimate the parameters of the joint distribution and variation of the product characteristics. The data should also be representative of the normal operating conditions of the process, without any special causes of variation or outliers. Moreover, the data should be collected in a timely and efficient manner, using appropriate sampling techniques and measurement systems.
- Communicating and interpreting the results of MPCI to stakeholders. MPCIs are numerical measures that quantify the capability of a multivariate process, but they may not be easy to understand or communicate to stakeholders who are not familiar with statistics or quality engineering. Therefore, it is important to present and interpret the results of MPCI in a clear and meaningful way, using graphical displays, tables, or verbal descriptions. For example, one can use scatterplots or contour plots to visualize the joint distribution and variation of the product characteristics, as well as the tolerance region and the process region. One can also use tables to compare different MPCIs or different processes based on their values or rankings. One can also use verbal descriptions to explain what MPCI mean in terms of proportion of nonconforming units or customer satisfaction.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Refaie, A.; Bata, N. Evaluating measurement and process capabilities by GR&R with four quality measures. Measurement 2010, 43, 842–851. [Google Scholar]
- Wang, F.-K.; Du, T. Using principal component analysis in process performance for multivariate data. Omega 2000, 28, 185–194. [Google Scholar] [CrossRef]
- Hahn, G.J.; Hill, W.J.; Hoerl, R.W.; Zinkgraf, S.A. The impact of Six Sigma improvement—A glimpse into the future of statistics. Am. Stat. 1999, 53, 208–215. [Google Scholar]
- Wang, F. Quality evaluation of a manufactured product with multiple characteristics. Qual. Reliab. Eng. Int. 2006, 22, 225–236. [Google Scholar] [CrossRef]
- Taam, W.; Subbaiah, P.; Liddy, J.W. A note on multivariate capability indices. J. Appl. Stat. 1993, 20, 339–351. [Google Scholar] [CrossRef]
- Chen, H. A multivariate process capability index over a rectangular solid tolerance zone. Stat. Sin. 1994, 4, 749–758. [Google Scholar]
- Shahriari, H.; Hubele, N.; Lawrence, F. A multivariate process capability vector. In Proceedings of the 4th Industrial Engineering Research Conference, Institute of Industrial Engineers, Nashville, TN, USA, 24–25 May 1995. [Google Scholar]
- Braun, L.J. New Methods in Multivariate Statistical Process Control(MSPC). Diskuss. Des Fachgeb. Unternehm. 2001, 1–12. [Google Scholar]
- Castagliola, P.; Castellanos, J.-V.G. Capability indices dedicated to the two quality characteristics case. Qual. Technol. Quant. Manag. 2005, 2, 201–220. [Google Scholar] [CrossRef]
- Bothe, D.R. A capability index for multiple process streams. Qual. Eng. 1999, 11, 613–618. [Google Scholar] [CrossRef]
- Boyles, R.A. Process Capability With Asymmetric Tolerances. Commun. Stat.-Simul. Comput. 1994, 23, 615–643. [Google Scholar] [CrossRef]
- Davis, R.D.; Kaminsky, F.C.; Saboo, S.J. Process capability analysis for processes with either a circular or a spherical tolerance zone. Qual. Eng. 1992, 5, 41–54. [Google Scholar] [CrossRef]
- Yeh, A.B.; Bhattacharya, S. A robust process capability index. Commun. Stat.-Simul. Comput. 1998, 27, 565–589. [Google Scholar] [CrossRef]
- Veevers, A. Viability and capability indexes for multiresponse processes. J. Appl. Stat. 1998, 25, 545–558. [Google Scholar] [CrossRef]
- Dianda, D.F.; Quaglino, M.B.; Pagura, J.A. Impact of measurement errors on the performance and distributional properties of the multivariate capability index. AStA-Adv. Stat. Anal. 2018, 102, 117–143. [Google Scholar] [CrossRef]
- Peruchi, R.S.; Rotela Junior, P.; Brito, T.G.; Largo, J.J.J.; Balestrassi, P.P. Multivariate process capability analysis applied to AISI 52100 hardened steel turning. Int. J. Adv. Manuf. Technol. 2018, 95, 3513–3522. [Google Scholar] [CrossRef]
- Chatterjee, M.; Chakraborty, A.K. Unification of some multivariate process capability indices for asymmetric specification region. Stat. Neerl. 2017, 71, 286–306. [Google Scholar] [CrossRef]
- Dianda, D.F.; Quaglino, M.B.; Pagura, J.A. Distributional Properties of Multivariate Process Capability Indices under Normal and Non-normal Distributions. Qual. Reliab. Eng. Int. 2017, 33, 275–295. [Google Scholar] [CrossRef]
- Vasquez, M.; Ramirez, G.; Garcia, T. A multivariate process capability index based on non-conforming probability, an illustration about monitoring the quality of a clarified water loop. Ing. UC 2016, 23, 319–326. [Google Scholar]
- Pan, J.N.; Li, C.I.; Shih, W.C. New multivariate process capability indices for measuring the performance of multivariate processes subject to non-normal distributions. Int. J. Qual. Reliab. Manag. 2016, 33, 42–61. [Google Scholar] [CrossRef]
- Ciupke, K. Multivariate Process Capability Index Based on Data Depth Concept. Qual. Reliab. Eng. Int. 2016, 32, 2443–2453. [Google Scholar] [CrossRef]
- Ciupke, K. Multivariate Process Capability Vector Based on One-Sided Model. Qual. Reliab. Eng. Int. 2015, 31, 313–327. [Google Scholar] [CrossRef]
- Mondal, S.C. A study of multivariate process capability indices in manufacturing processes. In Proceedings of the 2015 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 6–9 December 2015; pp. 1382–1386. [Google Scholar]
- Pan, J.-N.; Huang, W.K.C. Developing New Multivariate Process Capability Indices for Autocorrelated Data. Qual. Reliab. Eng. Int. 2015, 31, 431–444. [Google Scholar] [CrossRef]
- Siman, M. Multivariate Process Capability Indices: A Directional Approach. Commun. Stat.-Theory Methods 2014, 43, 1949–1955. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, G.A.; He, S.G.; He, Z. Modified Multivariate Process Capability Index Using Principal Component Analysis. Chin. J. Mech. Eng. 2014, 27, 249–259. [Google Scholar] [CrossRef]
- Tano, I.; Vannman, K. A Multivariate Process Capability Index Based on the First Principal Component Only. Qual. Reliab. Eng. Int. 2013, 29, 987–1003. [Google Scholar] [CrossRef]
- Das, N.; Dwivedi, P.S. Multivariate Process Capability Index: A Review and Some Results. Econ. Qual. Control 2013, 28, 151–166. [Google Scholar] [CrossRef]
- Bashiri, M.J.M.; Amiri, A. A New Multivariate Process Capability Index under Both Unilateral and Bilateral Quality Characteristics. Qual. Reliab. Eng. Int. 2012, 28, 925–941. [Google Scholar] [CrossRef]
- Niavarani, M.R.; Noorossana, R.; Abbasi, B. Three New Multivariate Process Capability Indices. Commun. Stat.-Theory Methods 2012, 41, 341–356. [Google Scholar] [CrossRef]
- Scagliarini, M. Multivariate process capability using principal component analysis in the presence of measurement errors. AStA-Adv. Stat. Anal. 2011, 95, 113–128. [Google Scholar] [CrossRef]
- Pan, J.N.; Lee, C.Y. New capability indices for evaluating the performance of multivariate manufacturing processes. Qual. Reliab. Eng. Int. 2010, 26, 3–15. [Google Scholar] [CrossRef]
- Ahmad, S.; Abdollahian, M.; Zeephongsekul, P.; Abbasi, B. Multivariate nonnormal process capability analysis. Int. J. Adv. Manuf. Technol. 2009, 44, 757–765. [Google Scholar] [CrossRef]
- Wen, D.C.; Lv, H. Multivariate Process Capability Index Based on the Additivity of Normal Distribution. In Proceedings of the 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008. [Google Scholar]
- Pearn, W.L.; Wang, F.K.; Yen, C.H. Multivariate capability indices: Distributional and inferential properties. J. Appl. Stat. 2007, 34, 941–962. [Google Scholar] [CrossRef]
- Wang, C.H. Constructing multivariate process capability indices for short-run production. Int. J. Adv. Manuf. Technol. 2005, 26, 1306–1311. [Google Scholar] [CrossRef]
- Wang, F.; Chen, J.C. Capability index using principal components analysis. Qual. Eng. 1998, 11, 21–27. [Google Scholar] [CrossRef]
- Castagliola, P. Evaluation of non-normal process capability indices using Burr’s distributions. Qual. Eng. 1996, 8, 587–593. [Google Scholar] [CrossRef]
- Pearn, W.L.; Shiau, J.J.H.; Tai, Y.T.; Li, M.Y. Capability Assessment for Processes with Multiple Characteristics: A Generalization of the Popular Index C-pk. Qual. Reliab. Eng. Int. 2011, 27, 1119–1129. [Google Scholar] [CrossRef]
- Shiau, J.J.H.; Yen, C.L.; Pearn, W.; Lee, W.T. Yield-related process capability indices for processes of multiple quality characteristics. Qual. Reliab. Eng. Int. 2013, 29, 487–507. [Google Scholar] [CrossRef]
- Abbasi, B.; Akhavan Niaki, S.T. Estimating process capability indices of multivariate nonnormal processes. Int. J. Adv. Manuf. Technol. 2010, 50, 823–830. [Google Scholar] [CrossRef]
- Clements, J.A. Process Capability Calculations For Non-Normal Distributions. Qual. Prog. 1989, 22, 95–97. [Google Scholar]
- Somerville, S.E.; Montgomery, D.C.J. Process capability indices and non-normal distributions. Qual. Eng. 1996, 9, 305–316. [Google Scholar] [CrossRef]
- Zimmer, L. Process Capability Indices in Theory and Practice. Technometrics 2000, 42, 206–207. [Google Scholar] [CrossRef]
- Deleryd, M. On the gap between theory and practice of process capability studies. Int. J. Qual. Reliab. Manag. 1998, 15, 178–191. [Google Scholar] [CrossRef]
- Wu, H.; Wang, J.; Liu, T. Discussions of the Clements-based process capability indices. In Proceedings of the 1998 CIIE National Conference; pp. 561–566. Available online: https://www.ciie.org/zbh/en/activities/thirdciie/agenda/ (accessed on 8 September 2023).
- Kotz, S.; Johnson, N.L. Process capability indices—A review, 1992–2000. J. Qual. Technol. 2002, 34, 2–19. [Google Scholar] [CrossRef]
- Liu, P.-H.; Chen, F.-L. Process capability analysis of non-normal process data using the Burr XII distribution. Int. J. Adv. Manuf. Technol. 2006, 27, 975–984. [Google Scholar] [CrossRef]
- Piao, C.; Zhi-Sheng, Y. A systematic look at the gamma process capability indices. Eur. J. Oper. Res. 2018, 265, 589–597. [Google Scholar]
- Li, C.-J.; Deng, W.-P.; Cao, Y.-Y.; Bao, Y. Process capability analysis in non-normality based on Box-Cox transformation and Johnson transformation. J. Qiqihar Univ. Nat. Sci. Ed. 2015. Available online: https://www.scinapse.io/papers/2383696946 (accessed on 8 September 2023).
- Bernardo, J.M.; Irony, T.Z.J. A general multivariate Bayesian process capability index. J. R. Stat. Society. Ser. D 1996, 45, 487–502. [Google Scholar] [CrossRef]
- Wang, F.-K.; Hubele, N.F.J. Quality evaluation using geometric distance approach. Int. J. Reliab. Qual. Saf. Eng. 1999, 6, 139–153. [Google Scholar] [CrossRef]
- Pal, S.J. Evaluation of nonnormal process capability indices using generalized lambda distribution. Qual. Eng. 2004, 17, 77–85. [Google Scholar] [CrossRef]
- Chen, K.-S.; Hsu, C.-H.; Wu, C.-C. Process capability analysis for a multi-process product. Int. J. Adv. Manuf. Technol. 2006, 27, 1235–1241. [Google Scholar] [CrossRef]
- Niaki, S.T.A.; Abbasi, B.J. Skewness reduction approach in multi-attribute process monitoring. Commun. Stat.-Theory Methods 2007, 36, 2313–2325. [Google Scholar] [CrossRef]
- Perakis, M.; Xekalaki, E. On the Implementation of the Principal Component Analysis–Based Approach in Measuring Process Capability. Qual. Reliab. Eng. Int. 2012, 28, 467–480. [Google Scholar] [CrossRef]
- Dharmasena, L.; Zeephongsekul, P. A new process capability index for multiple quality characteristics based on principal components. Int. J. Prod. Res. 2016, 54, 4617–4633. [Google Scholar] [CrossRef]
- Wang, S.; Wang, M.; Fan, X.; Zhang, S.; Han, R. A multivariate process capability index with a spatial coefficient. J. Semicond. 2013, 34, 026001. [Google Scholar] [CrossRef]
- Gu, K.; Jia, X.; Liu, H.; You, H. Yield-based capability index for evaluating the performance of multivariate manufacturing process. Qual. Reliab. Eng. Int. 2015, 31, 419–430. [Google Scholar] [CrossRef]
- Tiwari, V.; Singh, N. Process capability index for bivariate exponentially distributed quality characteristics and its sampling properties. Commun. Stat.-Theory Methods 2017, 46, 11099–11109. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Steps | Descriptions | Comments |
|---|---|---|
| Step 1 | Collect the sample (X) by specifying the process, the number of its QCs (p), and the sample size (n). | X consists of p QCs, and p . Each QC consists of n sample size. |
| Step 2 | Compute transformed variable ) using appropriate transformation method. | . |
| Step 3 | Transform and standardize the specifications limits by the same parameters of step 2. | Compute . |
| Step 4 | Find relative variables by dividing each variable in by corresponding specification limit. | |
| Step 5 | Find the average of . | |
| Step 6 | Compute pooled standard deviation of ). | |
| Step 7 | Generate large (N) sample normal distribution with mean of and . | . |
| Step 8 | Estimate portion of nonconforming (PNC). | . |
| Step 9 | Estimate PCI using PNC. | =. |
| Distribution | Variable | USL | Correlation | Actual PCI | ||
|---|---|---|---|---|---|---|
| gamma | X1 | 13 | 1 | 2 | 1 0.49 | 0.89 |
| X2 | 26 | 2 | 3 | 0.49 1 | ||
| gamma | X1 | 130 | 5 | 7 | 1 −0.37 0.58 | 1.18 |
| X2 | 58 | 6 | 3 | −0.37 1 −0.28 | ||
| X3 | 150 | 2 | 8 | 0.58 −0.28 1 | ||
| Beta | X1 | 0.99 | 2 | 5 | 1 0.79 | 1.12 |
| X2 | 0.99 | 4 | 4 | 0.79 1 | ||
| Weibull | X1 | 7 | 2 | 2 | 1 0.28 0.58 | 1.28 |
| X2 | 9 | 4 | 3 | 0.28 1 0.49 | ||
| X3 | 10 | 6 | 6 | 0.58 0.49 1 |
| Distribution | Gamma | Gamma | Beta | Weibull | |||||
|---|---|---|---|---|---|---|---|---|---|
| Variables | X1, X2 | X1, X2 | X1, X3 | X2, X3 | X1, X2 | X1, X2 | X1, X3 | X2, X3 | |
| Sample size | n = 50 | 0.491 | −0.367 | 0.574 | −0.284 | 0.790 | 0.288 | 0.592 | 0.494 |
| n = 100 | 0.490 | −0.365 | 0.582 | −0.275 | 0.790 | 0.286 | 0.576 | 0.494 | |
| n = 500 | 0.491 | −0.368 | 0.584 | −0.281 | 0.790 | 0.293 | 0.576 | 0.487 | |
| n = 1000 | 0.491 | −0.366 | −0.366 | −0.265 | 0.792 | 0.293 | 0.580 | 0.494 | |
| Actual correlation | 0.49 | −0.37 | 0.58 | −0.28 | 0.79 | 0,29 | 0.58 | 0.49 | |
| Distribution | n | USL | Correlation | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | Std | Actual | ||||||
| gamma | 50 | 0.932 | 0.000 | 0.89 | ||||
| 100 | 13 | 1 | 2 | 1 0.49 | 0.895 | 0.000 | ||
| 500 | 26 | 2 | 3 | 0.49 1 | 0.872 | 0.006 | ||
| 1000 | 0.892 | 0.000 | ||||||
| gamma | 50 | 130 | 5 | 7 | 1 −0.37 0.58 | 1.155 | 0.001 | 1.18 |
| 100 | 58 | 6 | 3 | −0.37 1 −0.28 | 1.2117 | 0.001 | ||
| 500 | 150 | 2 | 8 | 0.58 −0.28 1 | 1.1806 | 0.001 | ||
| 1000 | 1.2050 | 0.000 | ||||||
| Beta | 50 | 0.957 | 0.000 | 1.12 | ||||
| 100 | 1 | 2 | 5 | 1 0.79 | 1.088 | 0.000 | ||
| 500 | 1 | 4 | 4 | 0.79 1 | 1.041 | 0.000 | ||
| 1000 | 1.102 | 0.001 | ||||||
| Weibull | 50 | 7 | 2 | 2 | 1 0.28 0.58 | 1.685 | 0.010 | 1.28 |
| 100 | 9 | 4 | 3 | 0.28 1 0.49 | 1.125 | 0.000 | ||
| 500 | 10 | 6 | 6 | 0.58 0.49 1 | 1.278 | 0.000 | ||
| 1000 | 1.284 | 0.000 | ||||||
| Sample | Results | [41] | Actual | ||
|---|---|---|---|---|---|
| Cp | MAPE | Cp | MAPE | ||
| 1 | 0.932 | 4.7% | 0.864 | 2.9% | 0.89 |
| 2 | 0.895 | 0.6% | 0.865 | 2.8% | 0.89 |
| 3 | 0.872 | 2.0% | 0.872 | 2.0% | 0.89 |
| 4 | 0.892 | 0.2% | 0.888 | 0.2% | 0.89 |
| 5 | 1.155 | 2.1% | 1.208 | 2.4% | 1.18 |
| 6 | 1.2117 | 2.7% | 1.258 | 6.6% | 1.18 |
| 7 | 1.1806 | 0.1% | 1.148 | 2.7% | 1.18 |
| 8 | 1.205 | 2.1% | 1.172 | 0.7% | 1.18 |
| 9 | 0.957 | 14.6% | 0.885 | 21.0% | 1.12 |
| 10 | 1.088 | 2.9% | 1 | 10.7% | 1.12 |
| 11 | 1.041 | 7.1% | 0.997 | 11.0% | 1.12 |
| 12 | 1.102 | 1.6% | 0.975 | 12.9% | 1.12 |
| 13 | 1.685 | 31.6% | 1.411 | 10.2% | 1.28 |
| 14 | 1.125 | 12.1% | 1.298 | 1.4% | 1.28 |
| 15 | 1.278 | 0.2% | 1.267 | 1.0% | 1.28 |
| 16 | 1.284 | 0.3% | 1.297 | 1.3% | 1.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alatefi, M.; Al-Ahmari, A.M.; AlFaify, A.Y. New Approach for Process Capability Analysis Using Multivariate Quality Characteristics. Appl. Sci. 2023, 13, 11616. https://doi.org/10.3390/app132111616
Alatefi M, Al-Ahmari AM, AlFaify AY. New Approach for Process Capability Analysis Using Multivariate Quality Characteristics. Applied Sciences. 2023; 13(21):11616. https://doi.org/10.3390/app132111616
Chicago/Turabian StyleAlatefi, Moath, Abdulrahman M. Al-Ahmari, and Abdullah Yahia AlFaify. 2023. "New Approach for Process Capability Analysis Using Multivariate Quality Characteristics" Applied Sciences 13, no. 21: 11616. https://doi.org/10.3390/app132111616
APA StyleAlatefi, M., Al-Ahmari, A. M., & AlFaify, A. Y. (2023). New Approach for Process Capability Analysis Using Multivariate Quality Characteristics. Applied Sciences, 13(21), 11616. https://doi.org/10.3390/app132111616