


Navigating through Noise Comparative Analysis of Using Convolutional Codes vs. Other Coding Methods in GPS Systems



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
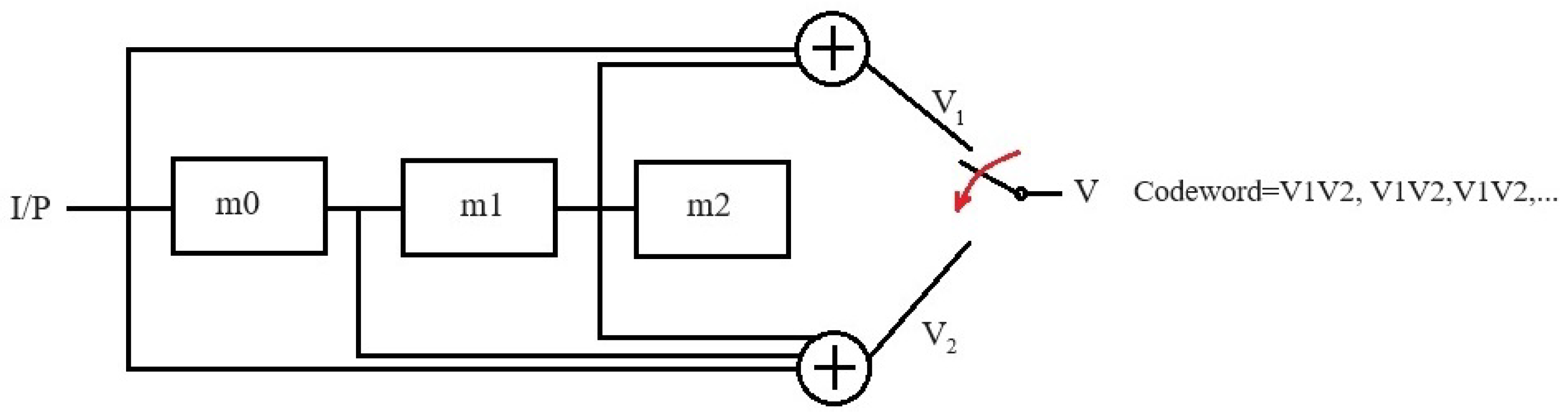
3. General Encoding and Decoding Algorithm
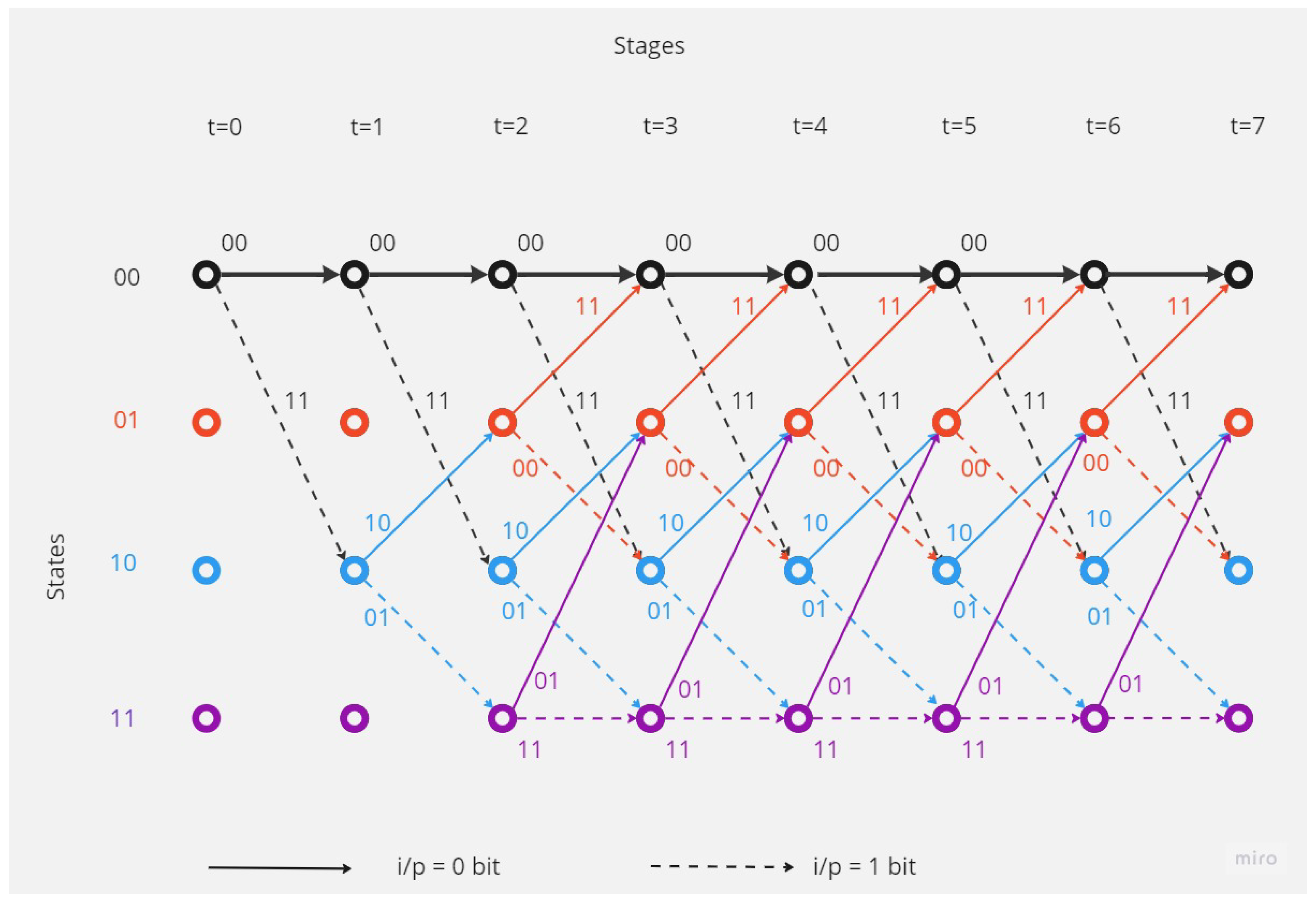
- Trellis Diagram
- Viterbi Algorithm
- PM [s, i + 1] is the new path metric for state (s) at time i + 1. It represents the likelihood of the most likely path through the trellis diagram that ends in state (s) at time i + 1.
- PM [, i] is the previous path metric for state at time i. It represents the likelihood of the most likely path through the trellis diagram that ends in state at time i.
- B [, i] is the branch metric for transitioning from state at time i to state (s) at time i + 1. It represents the similarity between the received signal and the expected signal for this state transition.
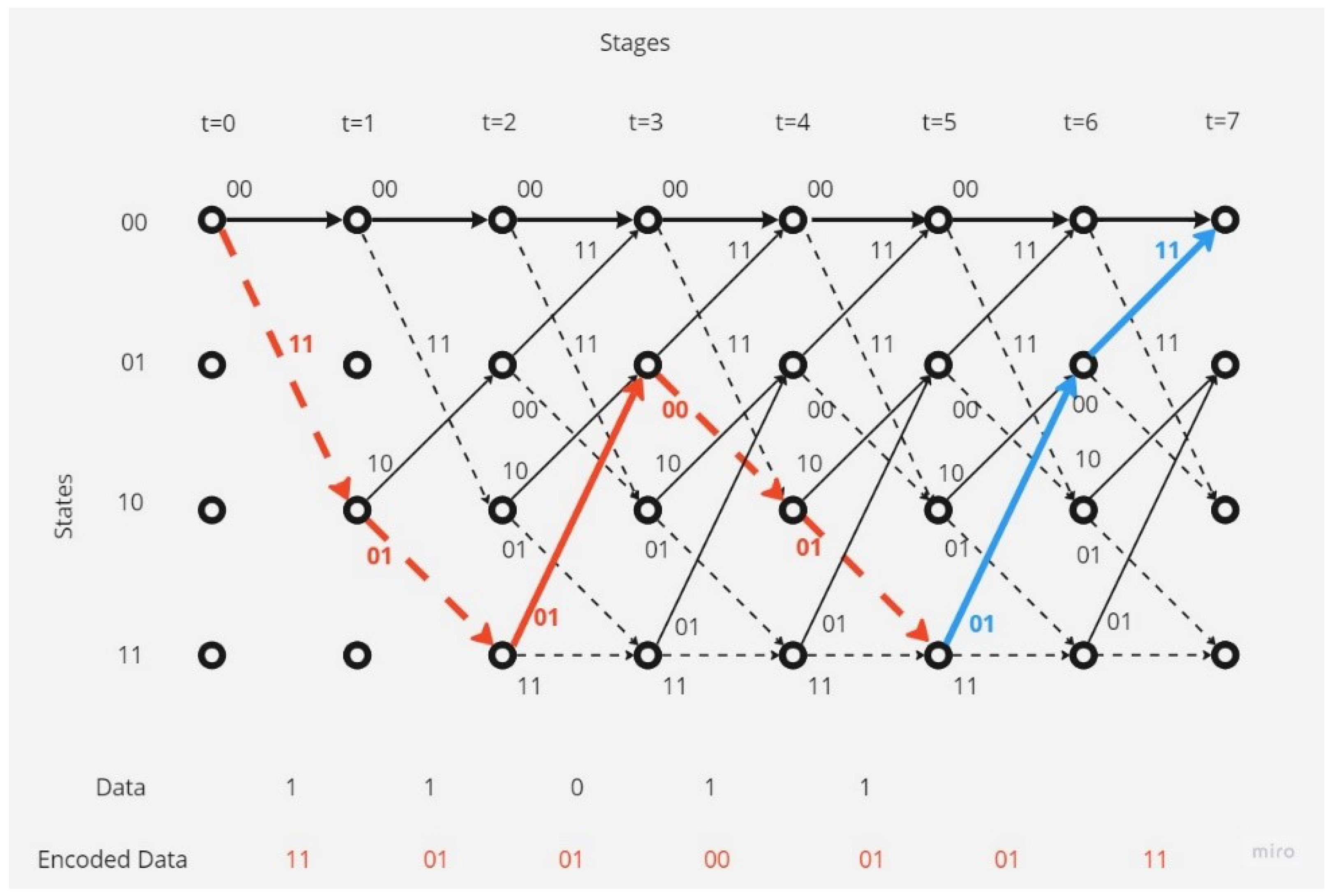
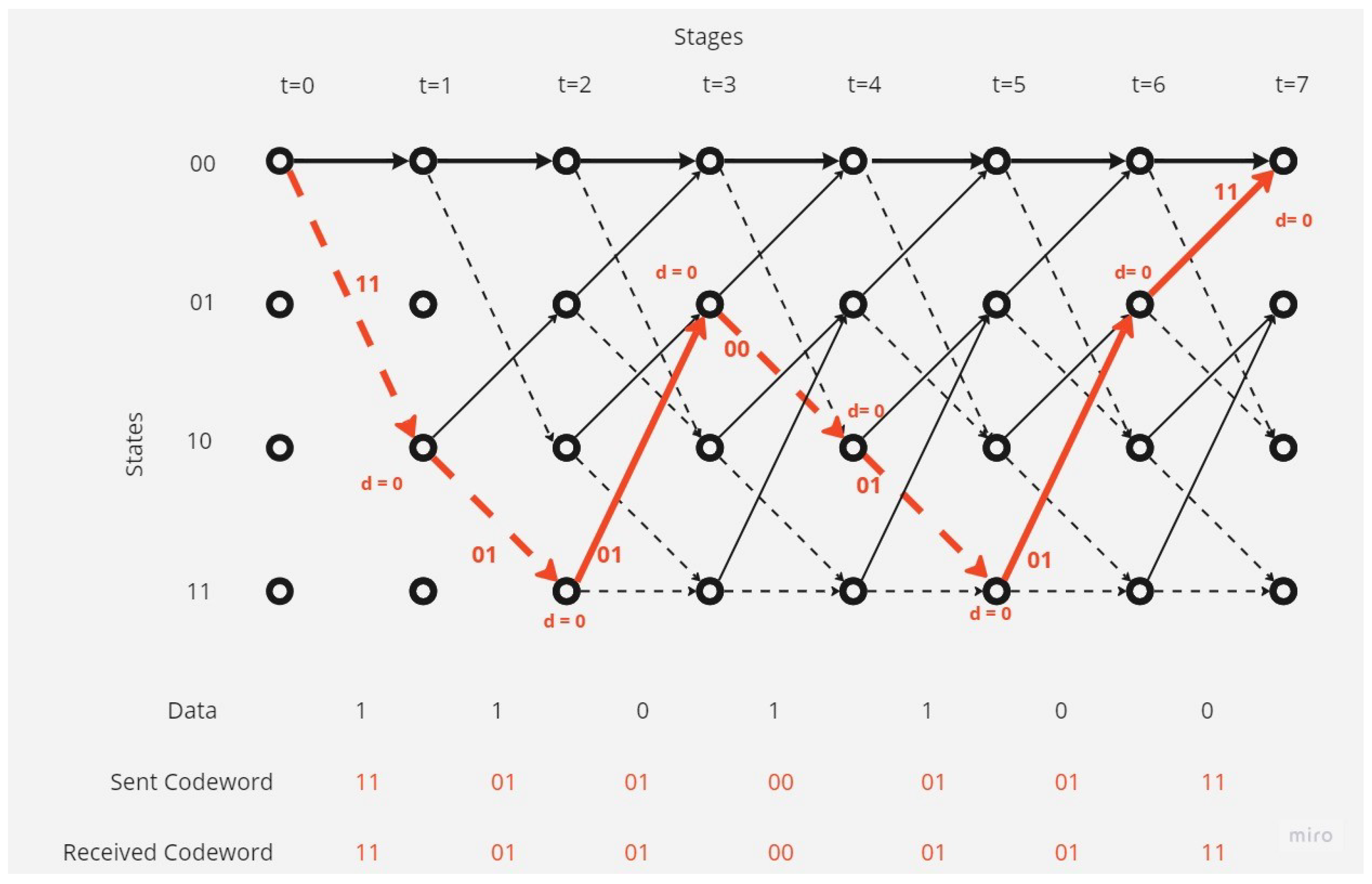
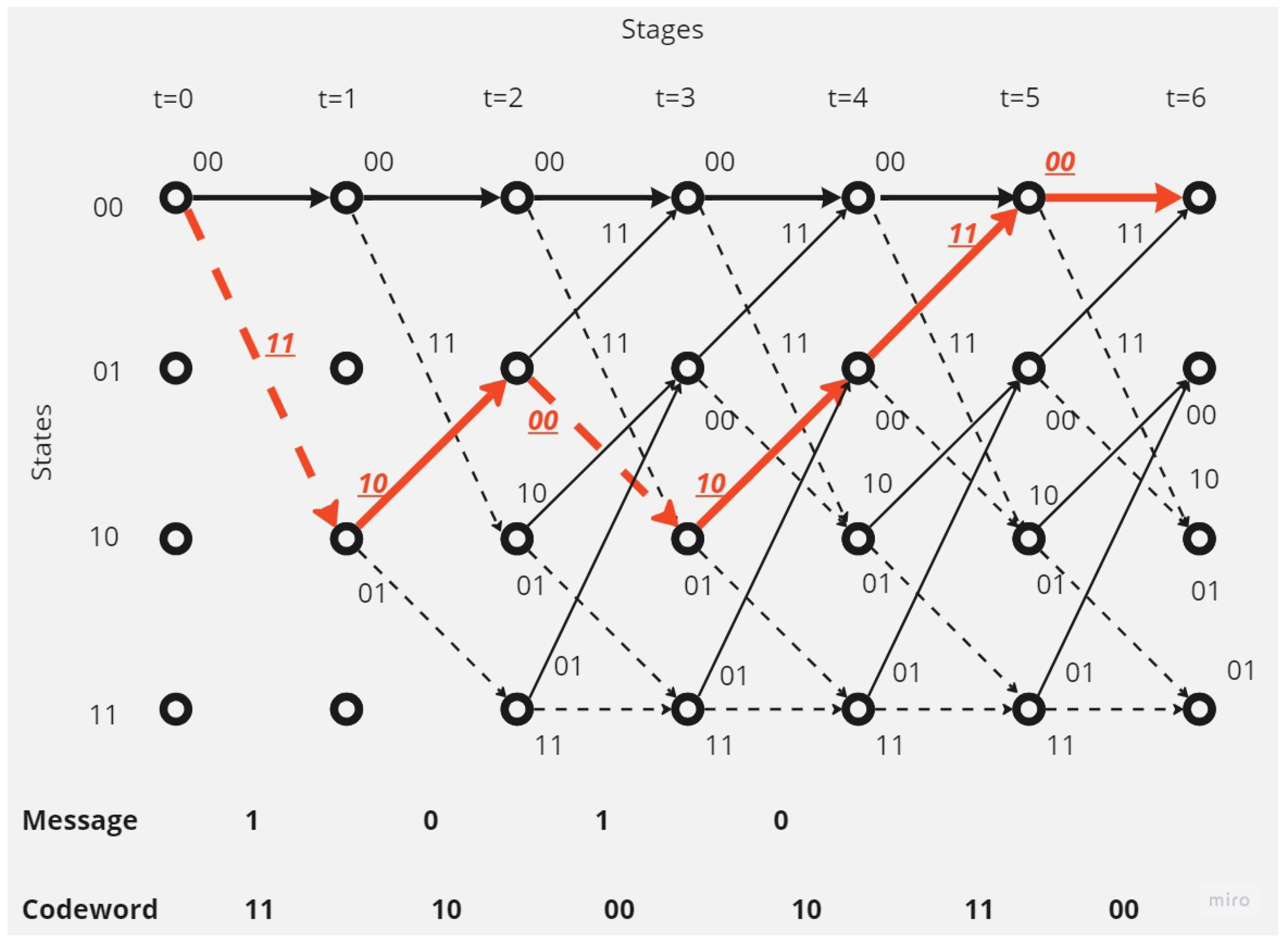
- There is no error in the received codeword.In this case, the decoding operation at the receiver point will be as shown in the Figure 5.The receiver, depending on Viterbi algorithm, found the correct code depending on the survival path (the path with the minimum hamming distance value; here, it is equal to 0).
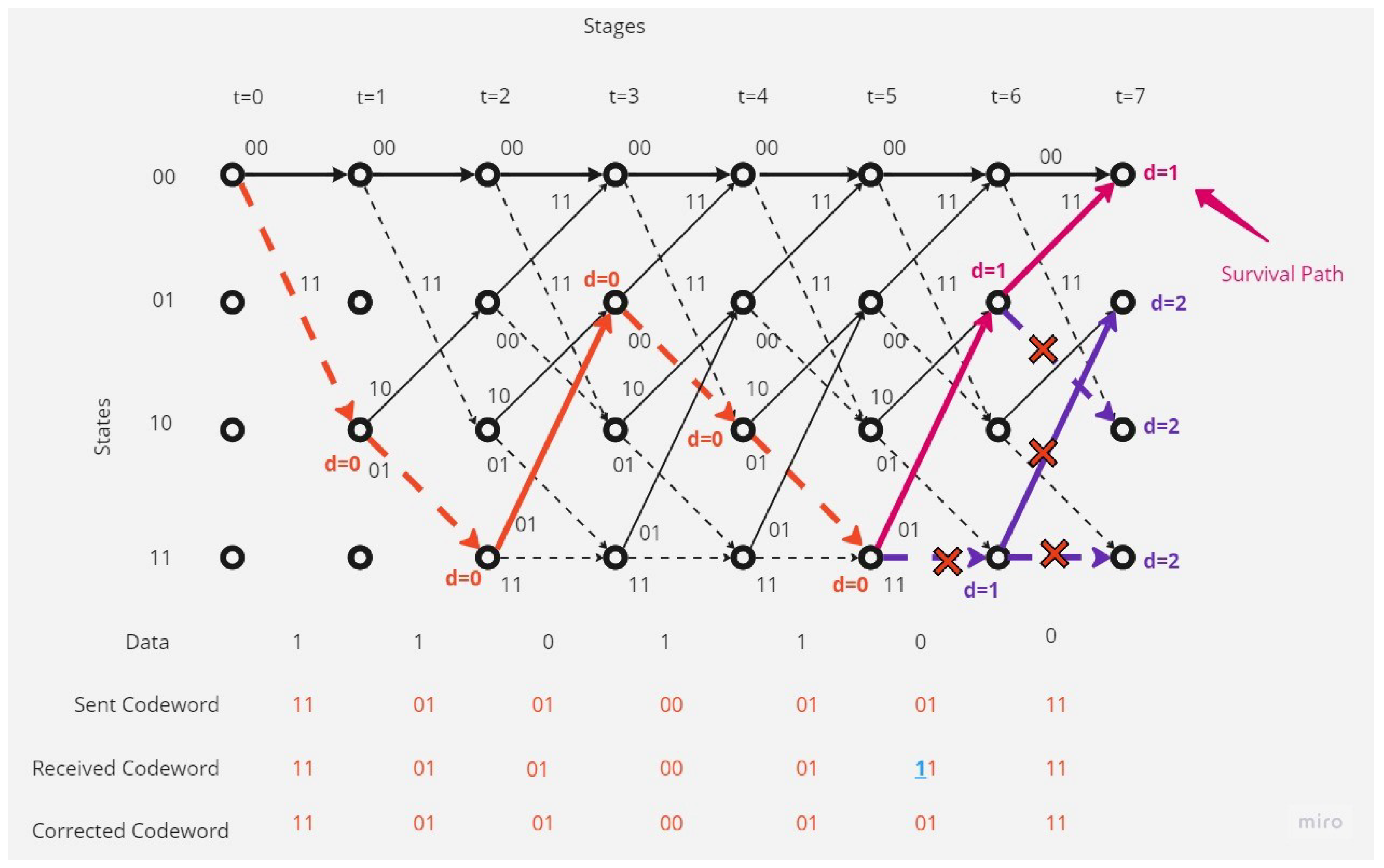
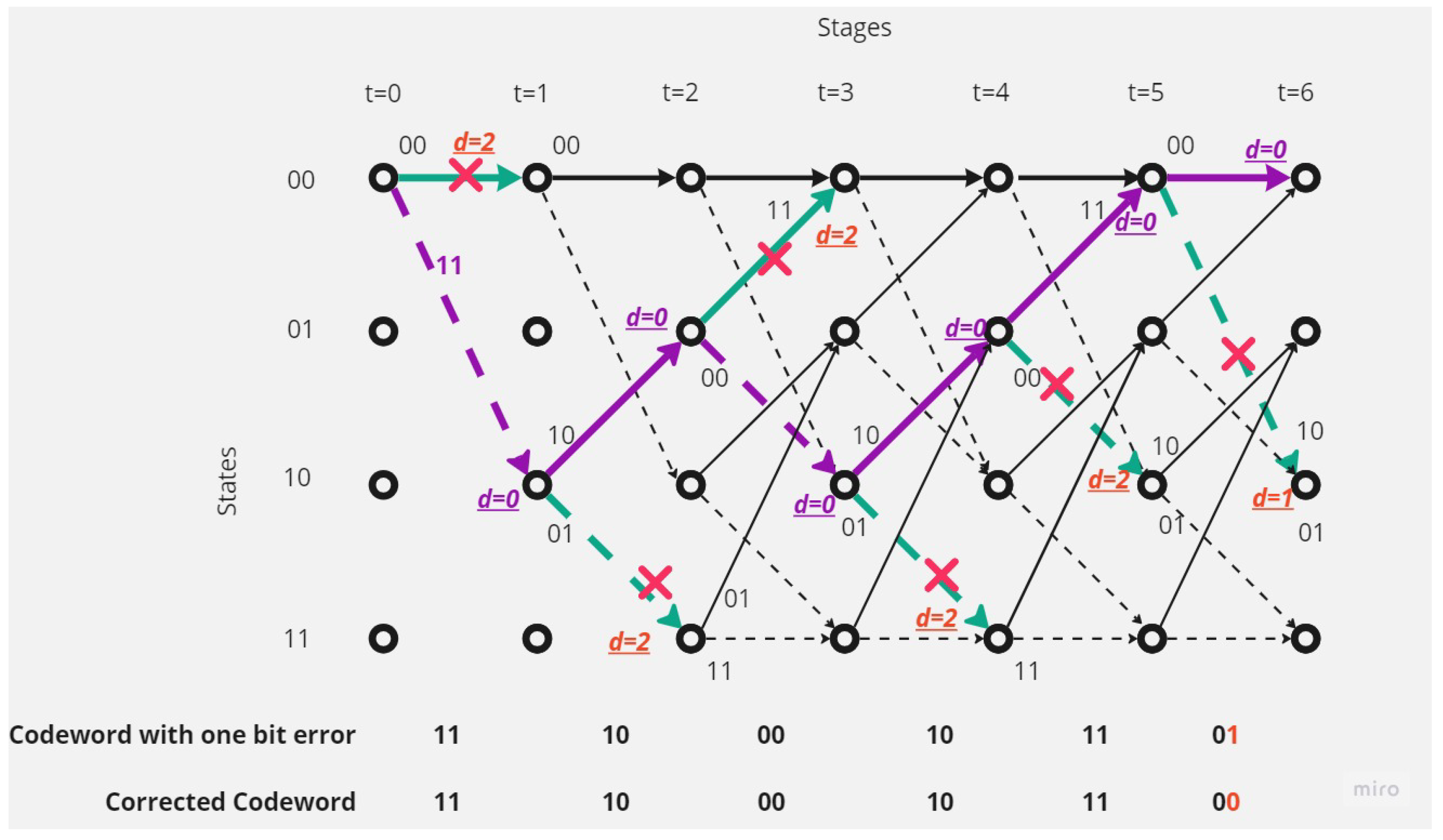
- There is one error in the received codeword.Figure 6 shows that the receiver received a codeword with a one-bit error.The receiver, depending on Viterbi algorithm, found the error bit and corrected the code depending on the survival path (the path with the minimum hamming distance value; here, it is 1).
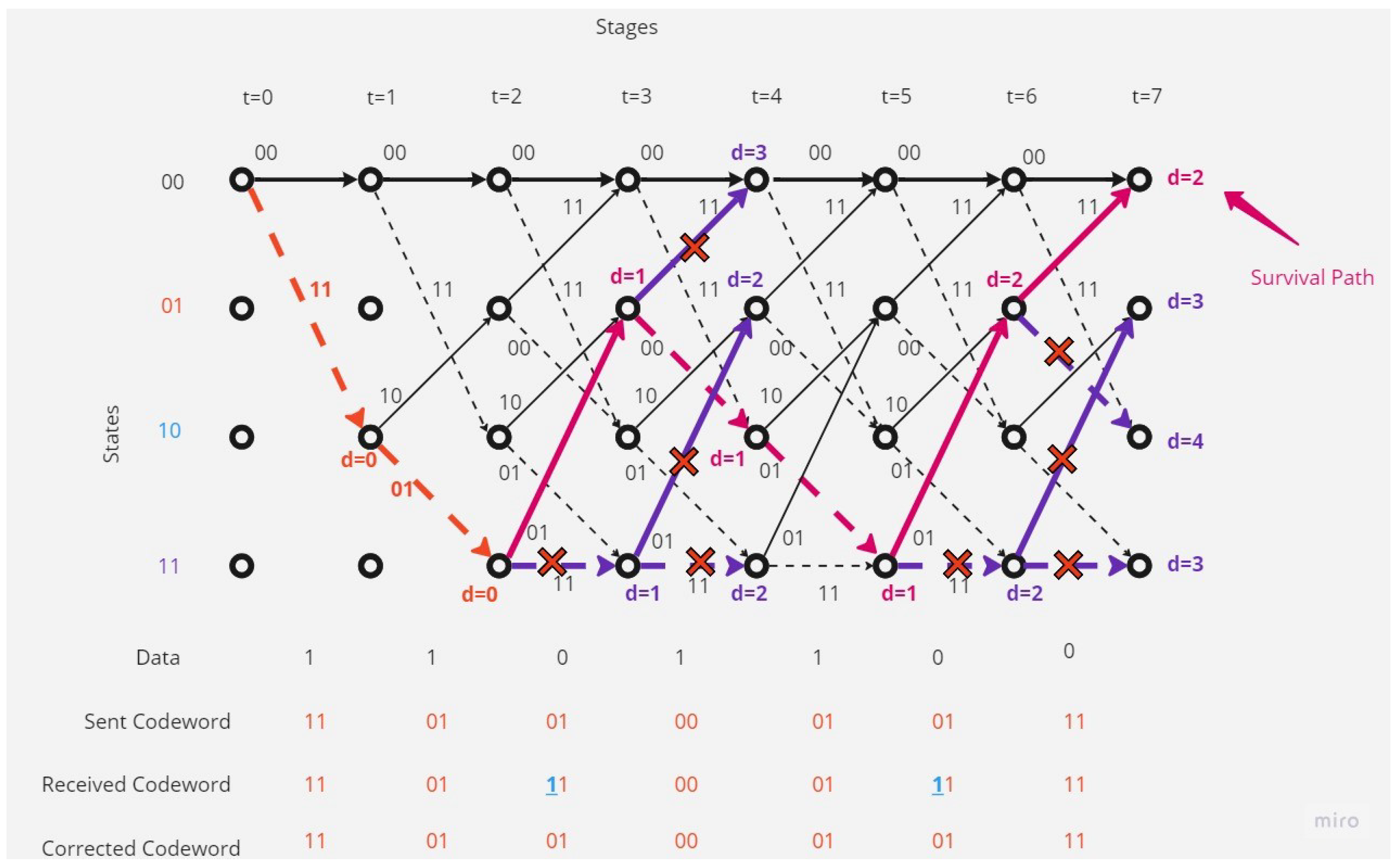
- There are separated errors in the received codeword.Figure 7 shows that the receiver received a codeword with a separated two-bit error.The receiver, depending on Viterbi algorithm, found the error bit and corrected the code depending on the survival path (the path with the minimum hamming distance value; here, it is 2).
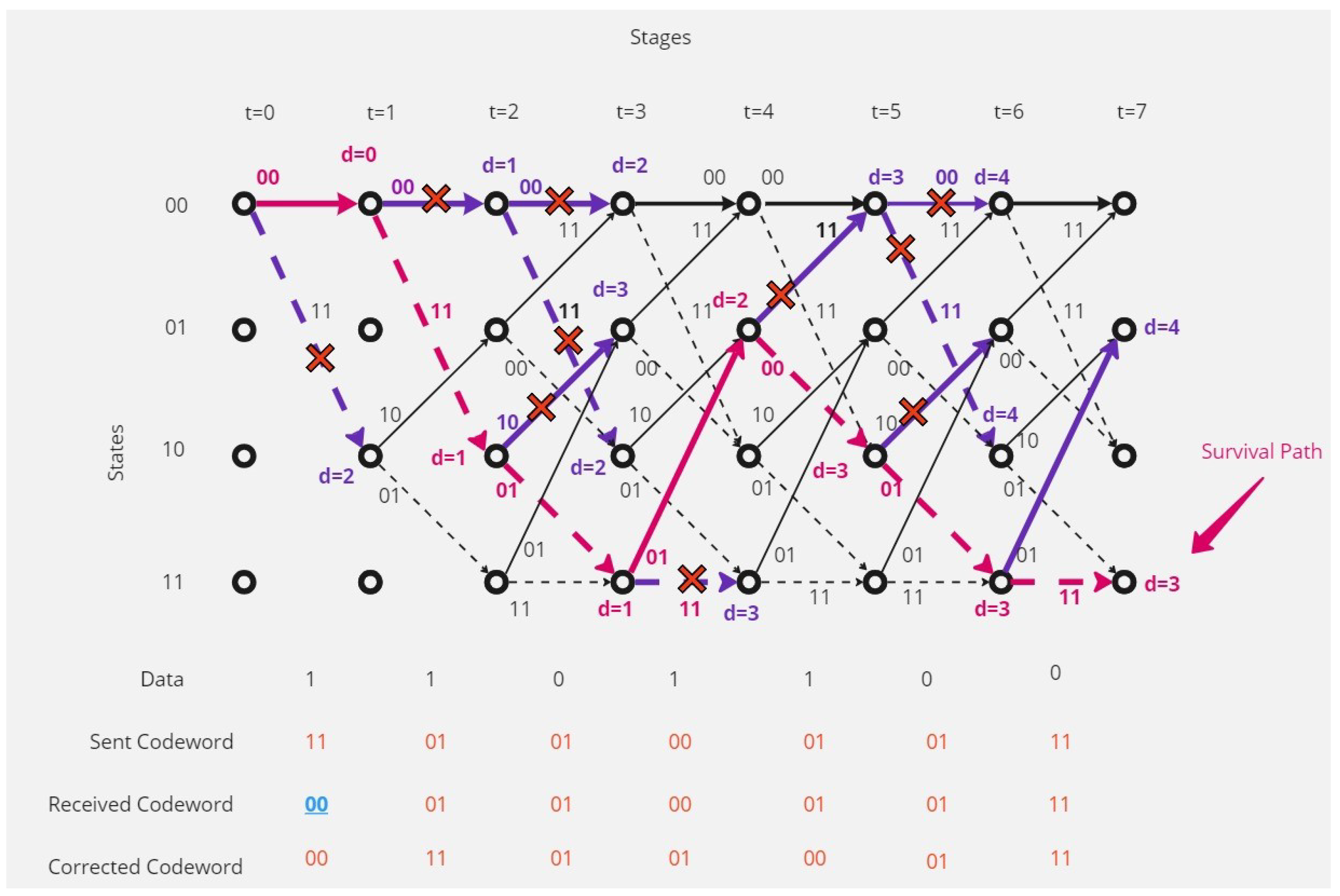
- There are continuous (contiguous) errors in the received codeword.Figure 8 show that the receiver received a codeword with continuous errors.The receiver in this situation could not detect the errors and the receiver could correct only 64.29% of the received codeword, and 35.71% of the received codeword could not be corrected, and this shows the disadvantages of this type of coding and decoding method.
- Reflection Errors: Convolutional codes work by introducing redundancy into the transmitted signal. By adding extra bits to the original data stream, the receiver can detect and correct errors caused by reflection. When the reflected signal arrives at the receiver, the redundancy introduced by convolutional coding enables the receiver to differentiate between the original and reflected signals and correct any bit errors that may have occurred due to reflections.
- Attenuation or Signal Loss: When signals are weakened or lost due to attenuation or signal loss, convolutional codes help in recovering the original data. By adding redundancy in the form of additional bits, convolutional codes allow the receiver to reconstruct the original signal, even if some bits are missing or corrupted. These codes use mathematical techniques to reconstruct the most likely sequence of bits, ensuring accurate and reliable data reception despite signal attenuation or loss.
4. Comparative Analysis Convolutional Codes with LDPC Codes, BCH Codes, and Turbo Codes
- High data rate: Satellite communication systems typically need to transmit high volumes of data over long distances. Convolutional codes are efficient error-correcting codes that can operate at high data rates. They can be implemented in hardware or software and enable the reliable transmission of large amounts of data.
- Channel characteristics: Satellite communication channels often suffer from fading and interference, which can cause errors and the degradation of the transmitted signal. Convolutional codes and the Viterbi algorithm are designed to deal with such channel impairments. Convolutional codes are powerful because their encoding and decoding processes involve comparing the received signal with the expected signal. The Viterbi algorithm can estimate the most likely transmission sequence from a received signal in spite of channel distortions.
- Low computational complexity: Satellite communication systems often have limited computational resources due to power and size constraints. Convolutional codes and the Viterbi algorithm are computationally efficient and require relatively few resources, making them suitable for use in satellite communication systems.
- Real-time processing: Satellite signals must be processed in real-time to provide real-time communication services. The algorithm used for the decoding needs to be fast and efficient, which is another reason why the Viterbi algorithm is often used. The algorithm has been proven to decode signals in real-time, making it a good fit for satellite communication systems.
- Compatibility with modulation schemes: Convolutional codes can be used with a variety of modulation schemes, including phase-shift keying (PSK) and quadrature amplitude modulation (QAM). This makes them a versatile choice for satellite communication systems, where different modulation schemes may be used depending on the specific requirements of the system.
4.1. Convolutional Codes vs. LDPC Codes
4.2. Convolutional Codes vs. BCH Codes
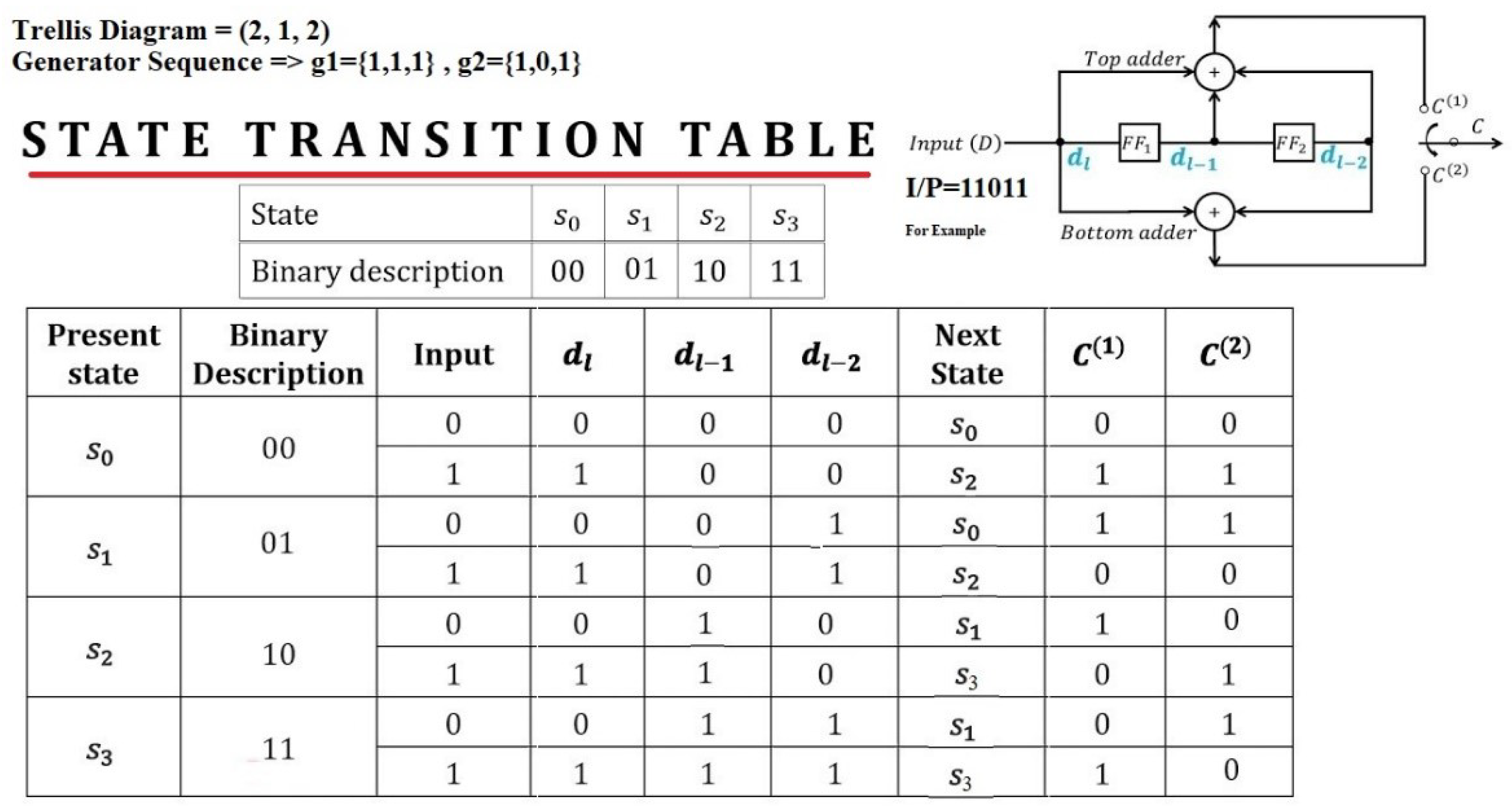
- Set all memory registers to zero.
- Feed the input bits one by one and shift the register values to the right.
- Calculate the output bits using the generator polynomials = (1,1,1) and = (1,0,1).
- Append two zero bits at the end of the message to flush the encoder.
4.3. Convolutional Codes vs. Turbo Codes
- Block codes require larger block sizes to achieve the same level of error protection as convolutional codes. The larger block size means more bits need to be processed, which can slow down the system.
- Block codes require more complex encoding and decoding algorithms than Convolutional codes, which can also slow down the system. Convolutional codes use a shift register and some XOR gates to generate the parity bits, which is a simpler process than the matrix multiplication required for block codes.
- Error detection and correction are more efficient in Convolutional codes than block codes. Convolutional codes can detect and correct errors in real-time, while block codes require the entire block to be received before errors can be corrected.
- More memory to store the parity check matrix used for decoding;
- Significant processing power, which can be problematic for low-power and low-cost GPS devices that are commonly used in commercial applications;
- Slow encoding and decoding operation.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| LDPC codes | Low-Density Parity Check (LDPC) codes |
| BCH codes | The Bose, Chaudhuri, and Hocquenghem (BCH) codes |
| EUMETSAT | European Organisation for the Exploitation of Meteorological Satellites (EUMETSAT) |
References
- Ripa, H.; Larsson, M. A Software Implemented Receiver for Satellite Based Augmentation Systems. Master’s Thesis, Luleå University of Technology, Luleå, Sweden, 2005. [Google Scholar]
- Wikipedia Contributors. GPS Signals—Wikipedia, The Free Encyclopedia. 2023. Available online: https://en.wikipedia.org/wiki/GPSsignals (accessed on 30 August 2023).
- Gao, Y.; Cui, X.; Lu, M.; Li, H.; Feng, Z. The analysis and simulation of multipath error fading characterization in different satellite orbits. In Proceedings of the China Satellite Navigation Conference (CSNC), Guangzhou, China, 15–19 May 2012; pp. 297–308. [Google Scholar]
- Gao, Y.; Yao, Z.; Cui, X.; Lu, M. Analysing the orbit influence on multipath fading in global navigation satellite systems. IET Radar Sonar Navig. 2014, 8, 65–70. [Google Scholar] [CrossRef]
- Morakis, J. A comparison of modified convolutional codes with sequential decoding and turbo codes. In Proceedings of the 1998 IEEE Aerospace Conference Proceedings (Cat. No.98TH8339), Snowmass, CO, USA, 28 March 1998; Volume 4, pp. 435–439. [Google Scholar] [CrossRef]
- Chopra, S.R.; Kaur, J.; Monga, H. Comparative Performance Analysis of Block and Convolution Codes. Indian J. Sci. Technol. 2016, 9, 1–6. [Google Scholar] [CrossRef]
- Wang, J.; Tang, C.; Huang, H.; Wang, H.; Li, J. Blind identification of convolutional codes based on deep learning. Digit. Signal Process. 2021, 115, 103086. [Google Scholar] [CrossRef]
- Pandey, M.; Pandey, V.K. Comparative Performance Analysis of Block and Convolution Codes. Int. J. Comput. Appl. 2015, 119, 43–47. [Google Scholar] [CrossRef]
- Benjamin, A.K.; Ouserigha, C.E. Implementation of Convolutional Codes with Viterbi Decoding in Satellite Communication Link using Matlab Computational Software. Eur. Sci. J. 2021, 17, 1. [Google Scholar] [CrossRef]
- Huang, F.H. Convolutional Codes; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Thamer. Convolution Codes. Available online: https://uotechnology.edu.iq/dep-eee/lectures/4th/Communication/Information%20theory/4.pdf (accessed on 9 June 2023).
- David, G.; Forney, J. The Viterbi Algorithm. PDF File. 1973. Available online: https://members.cbio.mines-paristech.fr/~jvert/svn/bibli/local/Forney1973Viterbi.pdf (accessed on 11 June 2023).
- Ivaniš, P.; Drajić, D. Information Theory and Coding-Solved Problems; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Dafesh, P.; Valles, E.; Hsu, J.; Sklar, D.; Zapanta, L.; Cahn, C. Data message performance for the future L1C GPS signal. In Proceedings of the 20th International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GNSS 2007), Fort Worth, TX, USA, 25–28 September 2007; pp. 2519–2528. [Google Scholar]
- Corraro, F.; Ciniglio, U.; Canzolino, P.; Garbarino, L.; Gaglione, S.; Nastro, V. An EGNOS Based Navigation System for Highly Reliable Aircraft Automatic Landing. In Conference Proceedings of the European Navigation Conference (ENC); University of Naples: Naples, Italy, 2009. [Google Scholar]
- Wikipedia Contributors. Convolutional Code—Wikipedia, The Free Encyclopedia. 2023. Available online: https://en.wikipedia.org/wiki/Convolutional_code (accessed on 31 July 2023).
- Dalal, D. Convolutional Coding and Viterbi Decoding Algorithm. Available online: https://www.academia.edu/6174160/Convolutional_Coding_And_Viterbi_Decoding_Algorithm (accessed on 1 June 2023).
- Wikipedia Contributors. BCH Code—Wikipedia, The Free Encyclopedia. 2023. Available online: https://en.wikipedia.org/wiki/BCH_code (accessed on 31 July 2023).
- Wikipedia Contributors. Turbo Code—Wikipedia, The Free Encyclopedia. 2022. Available online: https://en.wikipedia.org/w/index.php?title=Turbo_code&oldid=1106388136 (accessed on 31 July 2023).
- Al-Hraishawi, H.; Chatzinotas, S.; Ottersten, B. Broadband non-geostationary satellite communication systems: Research challenges and key opportunities. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Chen, C.L.; Rutledge, R.A. Error Correcting Codes for Satellite Communication Channels. IBM J. Res. Dev. 1976, 20, 168–175. [Google Scholar] [CrossRef]
- Lee, J.S.; Thorpe, J. Memory-efficient decoding of LDPC codes. In Proceedings of the International Symposium on Information Theory, ISIT 2005, Adelaide, Australia, 4–9 September 2005; pp. 459–463. [Google Scholar] [CrossRef]
- Wikipedia Contributors. Low-Density Parity-Check Code—Wikipedia, The Free Encyclopedia. 2023. Available online: https://en.wikipedia.org/wiki/Low-density_parity-check_code (accessed on 3 September 2023).
- Lahtonen, J. Convolutional Codes. 2004. Available online: https://www.karlin.mff.cuni.cz/~holub/soubory/ConvolutionalCodesJyrkiLahtonen.pdf (accessed on 3 September 2023).
- Petac, E.; Alzoubaidi, A.R. Convolutional codes simulation using Matlab. In Proceedings of the 2004 IEEE International Symposium on Signal Processing and Information Technology, Rome, Italy, 18–21 December 2004; pp. 573–576. [Google Scholar]
- Kurkoski, B. Introduction to Low-Density Parity Check Codes. 2005. Available online: http://www.jaist.ac.jp/~kurkoski/teaching/portfolio/uec_s05/S05-LDPC%20Lecture%201.pdf (accessed on 5 July 2023).
- Tahir, B.; Schwarz, S.; Rupp, M. BER comparison between Convolutional, Turbo, LDPC, and Polar codes. In Proceedings of the 2017 24th International Conference on teLecommunications (ICT), Limassol, Cyprus, 3–5 May 2017; pp. 1–7. [Google Scholar]
- Jiang, Y. Analysis of Bit Error Rate Between BCH Code and Convolutional Code in Picture Transmission. In Proceedings of the 2022 3rd International Conference on Electronic Communication and Artificial Intelligence (IWECAI), Zhuhai, China, 14–16 January 2022; pp. 77–80. [Google Scholar] [CrossRef]
- FEC Codes bch Code. 2023. Available online: https://atlantarf.com/Error_Control.php (accessed on 3 September 2023).
- Hrishikesan, S. Error Detecting and Correcting Codes in Digital Electronics. 2023. Available online: https://www.electronicsandcommunications.com/2018/11/error-detecting-and-correcting-codes-in.html (accessed on 15 September 2023).
- Leung, O.H.; Yue, C.W.; Tsui, C.Y.; Cheng, R. Reducing power consumption of turbo code decoder using adaptive iteration with variable supply voltage. In Proceedings of the 1999 International Symposium on Low Power Electronics and Design (Cat. No.99TH8477), San Diego, CA, USA, 16–17 August 1999; pp. 36–41. [Google Scholar] [CrossRef]
- MacKay, D.J. Information Theory, Inference, and Learning Algorithms. 2003. Available online: http://www.inference.org.uk/itprnn/book.pdf (accessed on 8 August 2023).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sabbry, N.H.; Levina, A. Navigating through Noise Comparative Analysis of Using Convolutional Codes vs. Other Coding Methods in GPS Systems. Appl. Sci. 2023, 13, 11164. https://doi.org/10.3390/app132011164
Sabbry NH, Levina A. Navigating through Noise Comparative Analysis of Using Convolutional Codes vs. Other Coding Methods in GPS Systems. Applied Sciences. 2023; 13(20):11164. https://doi.org/10.3390/app132011164
Chicago/Turabian StyleSabbry, Nawras H., and Alla Levina. 2023. "Navigating through Noise Comparative Analysis of Using Convolutional Codes vs. Other Coding Methods in GPS Systems" Applied Sciences 13, no. 20: 11164. https://doi.org/10.3390/app132011164
APA StyleSabbry, N. H., & Levina, A. (2023). Navigating through Noise Comparative Analysis of Using Convolutional Codes vs. Other Coding Methods in GPS Systems. Applied Sciences, 13(20), 11164. https://doi.org/10.3390/app132011164