1. Introduction
Artificial intelligence (AI) and machine learning (ML) have emerged as key technologies in information security due to their ability to rapidly analyse millions of events and identify a wide range of threats. Blockchain is distinguished by its advantages of decentralised data storage and program execution, as well as the immutability of the data. Blockchain and AI can work together to provide secure data storage and data sharing, and to analyse the blockchain audit trail to more accurately understand relationships of data changes. Combining the two technologies will give blockchain-based business networks a new level of intelligence by allowing them to read, understand, and connect data at lightning speed [
1].
ML has been established as the most promising way to learn patterns from data. Its applications can be found in the data processing of web browsing, financial data, health care, autonomous automobiles, and almost every other data-driven industry around us [
2]. Because of the vast range of applications, ML models are now being run on a wide range of devices, from low-end IoT and mobile devices to high-performance clouds and data centres, to offer both training and inference services [
3].
Especially in industrial production, machine downtimes are costly for companies and can have a significant impact on the entire company [
4]. Therefore, AI applications used in the business world must be fail-safe, secure, and reliable. Trust in AI applications that are used in industrial production can only be built if they meet the requirements for information security [
5]. Next to the typical cybersecurity threats, the ML-based threats must be added to these requirements, which are threats against ML data, ML models, the entire ML pipelines, etc. [
6]. To build trust, all actors must make sure they are following the rules, and their actions must be verifiable and believable to their partners. For accountability, the goals of security protection are for the assets to be available, safe, private, and handled in a way that obeys the law (e.g., privacy).
Machine learning applications are, in fact, pipelines that link several parts and rely on large amounts of data for training and testing [
7]. Data are also required for maintaining and upgrading machine learning models, since they take user data as input and use it to come up with insights. The importance of data in machine learning cannot be overstated, as data flows across the whole machine learning process.
Widespread attacks threaten ML security and privacy, these range from ML model stealing [
8], “model inversion” [
9], “model poisoning” [
10], “data poisoning” [
11], “data inference” [
12] to “membership/attribute inference” [
13] as well as other attacks. In ML, security and privacy problems are caused by complex pipelines that use multiple system and software stacks to offer current features such as acceleration. A full ML pipeline includes collecting raw data, training, inference, prediction, and possibly retraining and reusing the ML model. The pipeline may be segmented since data owners, ML computation hosts, model owners, and output recipients are likely separate businesses [
14]. As a result, ML models frequently have weak resilience, as shown in adversarial cases or poisoning assaults. A small change in the way training is conducted could have huge negative effects that are hard to spot.
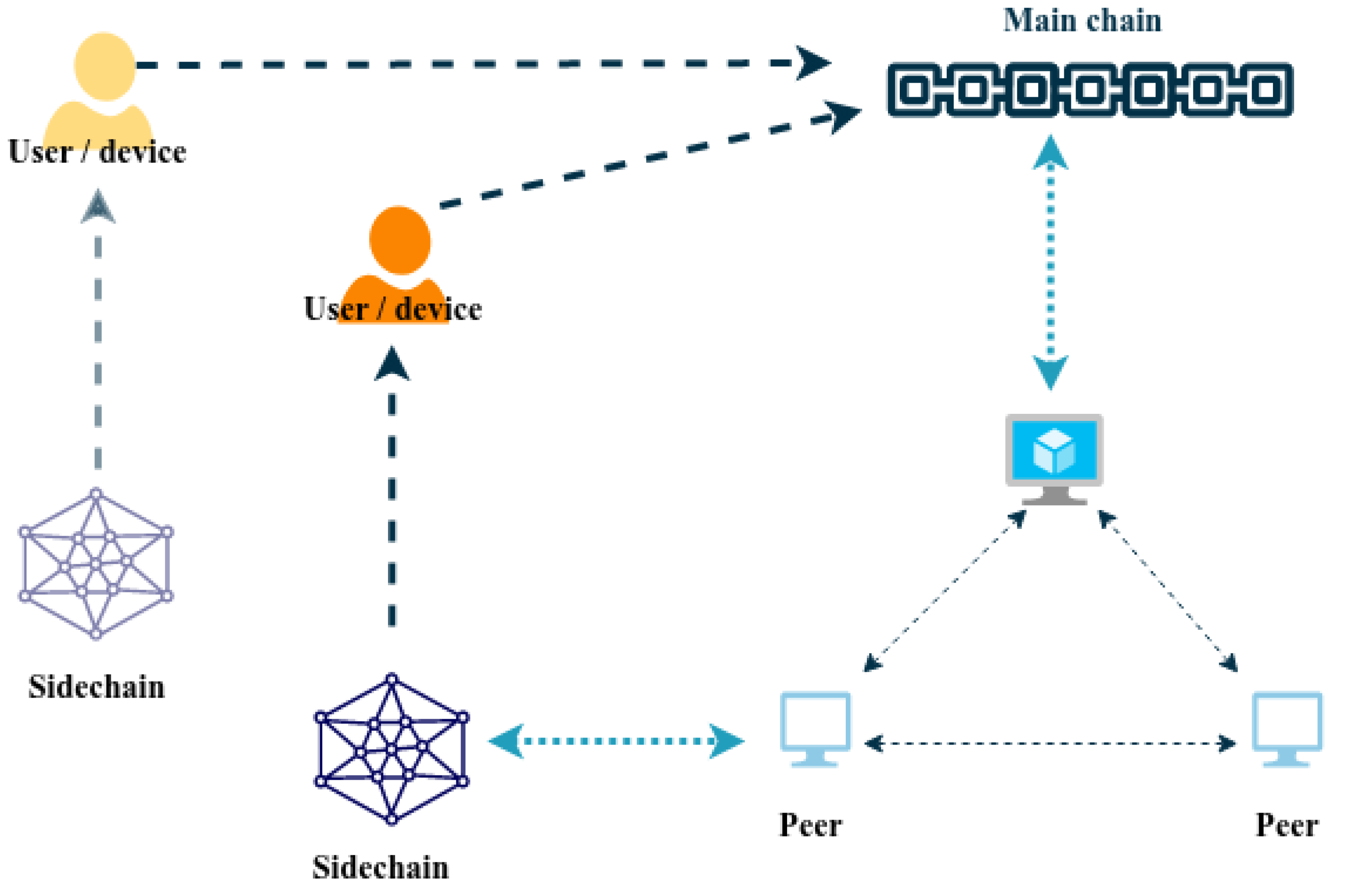
In comparison, blockchain has an entirely different purpose and characteristics. Blockchain is a technology to store data, immutable and decentralised. The data are distributed across a large network of nodes so that it is available even if some nodes fail. Once a block has been added by agreement among participants, it cannot be deleted or changed, even by the original authors. The data are publicly available but not publicly readable without a digital key [
15]. One obvious use is to save records of success and credit, such as any entity credentials and trust amounts related to it [
16]. The granting institution would upload the certificate data to the blockchain, which the member may view or connect from web pages [
17].
Some research has looked at solutions for attacks on ML models or pipelines [
14], but these solutions are applied to the central system. But as communication and distributed systems improve, different companies or developers can now work on platforms that use distributed systems. However, the question is how they can trust each other’s output when there is no central authority.
In this study, we present a blockchain-based framework to help find answers to ML’s security, traceability, and privacy problems. In manufacturing, this framework is used to keep data private and accessible for quality control and to explain those ideas. The proposed solution has several key benefits, such as a data history that can’t be changed, which provides accountability and makes quality checks possible. By making a protocol for the ML pipeline that is used, rating the experts who are part of the ML pipeline, and making sure that they are legitimate, trust is increased. In addition, pipeline architecture and the machine learning with its tasks of model data gathering, and labelling are certified. After the details of the framework are explained, it will be shown how to stop the security attacks that have already been made public.
The article is structured as follows:
Section 2 describes the utilised research methodology. The method follows the “Systematic Literature Review” to detect research gaps and research objectives.
Section 3 describes the current state of the art in focusing on ML pipelines and how blockchain could help secure ML use cases.
Section 4 discusses the security challenges of machine learning models and pipelines, which frequently have the potential to destroy the output result of the model. In
Section 5, we describe the new approach to maintain the security of the model. For this purpose, certificates are introduced which can be evaluated by a trust mechanism within the blockchain.
Section 6 explains a typical use case of visual quality inspection. We provide security analyses and evaluation in
Section 7 and the last section,
Section 8, concludes the paper.
3. State of the Art
A machine learning pipeline is an approach to making machine learning models and all the processes behind them more productive. The pipeline is for large-scale learning environments that can store and work on data or models better with data parallelism or model parallelism [
23]. As a backbone for distributed processing, ML Pipeline has a lot of benefits, such as being easy to scale and letting to debug data distribution in ways that local computers cannot [
24,
25].
A significant point in the design and implementation of the ML pipeline is the ability to use the ML models in manufacturing [
26]. It is important to pay attention to the sensitivity and security of the ML pipeline in industry. ML-based communications and networking systems demand security and privacy. Most ML systems have a centralised architecture that is prone to hacking since a malicious node only has to access one system to modify instructions. Training data typically incorporates personal information, and therefore data breaches may affect privacy. Hackers must be kept away from ML training data [
14].
When training an ML model, a lot of data from many different places is often needed, which raises privacy concerns. To prevent identity exposure, each node in a blockchain system communicates using a created pseudonymous address. By using pseudonyms, blockchain may offer pseudonymity and be acceptable for specific use cases that demand strong privacy [
27]. Furthermore, the privacy of data/model owners is protected by cryptographic techniques, and the confidentiality of data/model sharing across numerous service providers is assured [
28].
Blockchain qualities such as decentralisation, immutability, and transparency open up new opportunities for ML algorithms employed in communications and networking systems [
29,
30,
31]. Discuss blockchain for ML in this area, including data and model sharing, security and privacy, decentralised intelligence, and trustful decision-making.
Ref. [
32] envisions a permissionless blockchain-based marketplace for ML professionals to acquire or rent high-quality data. As part of sharding, the network is split into several Interest Groups (IG) to make data exchange more scalable. Users are encouraged to gather helpful knowledge regarding a subject of interest to them. Each IG has its own dataset that incorporates data from all of its nodes. IG members might be recognised for the quantity and quality of their data. Ref. [
33] presents ADVOCATE to manage personal data in IoT situations. The proposed framework collects and analyses policy data to make decisions and produce user-centric ML solutions. Blockchain technology is used in the suggested architecture so that data controllers and processors can handle data in a way that is clear and can be checked. All consents would be digitally signed by the parties to the contract to make sure they couldn’t be revoked, and the hashed version would be sent to a blockchain infrastructure to protect the data’s integrity and keep users’ identities secret.
On the other hand, data dependability is crucial to ML algorithms. For ML approaches to solve problems more effectively, they need more data sources to train their models on during the analysis of data resources. However, in today’s sophisticated and trustless networks, the goal of high accuracy and privacy-aware data sharing for ML algorithms remains problematic. Because of privacy and reputation concerns, most users are hesitant to share their data with the public.
The authors of [
34] describe a crowdsourced blockchain-based solution to enable decentralised ML without a trusted third party. A non-cooperative game theoretic strategy with two workers auditing each other and a cryptographic commitment instrument are presented to tackle employee interaction (blockchain nodes) and free-riding difficulties in crowdsourcing systems. The expensive and randomised computation is crowdsourced via the application layer and “asynchronously” executed. Full nodes/miners may insert the output into the next block as soon as the result is submitted, rather than waiting for mining to finish.
In [
35], the authors suggest a reputation-based worker selection strategy for assessing the dependability and trustworthiness of mobile devices in mobile networks. They employ a multi-weight subjective logic model and consortium blockchain to store and maintain worker reputation in a decentralised way in order to deliver trustworthy federated learning. For collaborative federated learning, to enable mobile devices to share high-quality data, we present an effective incentive system that combines reputation with contract theory.
The study discussed above has the potential to serve as the foundation for developing decentralised, transparent, secure, and trustworthy ML-based communications and networking systems. They are still being discussed based on plausible ideas, but they are still in their early stages. Some technical concerns, such as scalability and incentive issues, need more research.
6. Case Study: Machine Learning Application in Manufacturing
This section talks about a typical application of machine learning in a manufacturing SME, as well as the ML pipeline and the people who are involved.
6.1. Use Case: Visual Metal Surface Quality Inspection
As an example use case for the presented concept of the “Blockchain Secured Dynamic Machine Learning Pipeline” (Blockchain Secured Dynamic Machine Learning Pipeline (bcmlp)), the application of machine learning for visual metal surface quality inspection is presented, as seen in
Figure 4.
Figure 4 shows the input parameters that influence the quality inspection process for the machine learning model. They are: process data (process parameter, tool parameter) of the
machine,
workpiece data (surface image),
order data (quality requirements, material, etc.). From the collected data in the
history data base, a data scientist trains a machine learning model, which afterwards is used for
model inference. The model is always being trained and updated to take into account changes in parameters and the quality changes that come from them. The results of the
model inference are visualised for the machine operator, and workpieces that do not meet the required quality requirements are sorted out.
6.2. ML Pipeline and Stakeholders
Typically, a machine learning pipeline consists of five components that build on each other, are continuously monitored by a monitoring system, and are based on CRISP-DM (CRoss-Industry Standard Process for Data Mining) [
52]. Through a series of intermediate steps and components, the raw data that comes in (process parameters, workpiece data, and order data) is turned into a quality index.
Step 1 “Data collection” (see
Figure 5), where the data to be processed is collected, is the entry point into the ML pipeline. Step 2 “Data preprocessing”, the collected data are preprocessed based on methods and rules. Step 3 “Model training” the existing model is retrained based on the preprocessed data and historical data; this step takes place in parallel with the other steps. Step 4 “ML usage” the model that was trained in step 3 is used on the data that has already been cleaned up. Step 5 “Result” is the end of the pipeline. It shows the quality index that the machine learning model came up with.
Figure 5 depicts four stakeholders who are often from different companies and are typically involved in the development and operation of a machine learning application for a SME as well as blockchain nodes (e.g., manufacturer, ML consultant, machine manufacturer, condition monitoring service provider, quality check auditor, etc.). For the goals to be met, the stakeholders must work together to manage their parts of the machine learning pipeline and affect the outcome. In the use case presented in
Section 6.1, the actors are each from a different company. The actors are the company that is using ML, the company that is modelling training, the company that is conditioning monitoring, and the company that is quality control. However, stakeholders do not just influence parts of the pipeline; they influence each other by their reactions and also rate each other for trust value. A company that uses machine learning has control over and manages the following parts: data collection, data preprocessing, ML use, and results. So, these are the parts that make up the processing of data and the use of the ML model.
Company Model Training controls and manages the Model Training component and the certificate, which use machine learning and historical data to create a model from the company’s collected and preprocessed data. This is where the first mutual influence between stakeholders can be found: Company using ML and Company Model Training.
Company Quality Control checks the history data to see which of the recorded images of the workpiece show a good surface. Quality control checks output data and assigns a trust level rating to it. This is the second mutual influence that can be found among the actors: Company Quality Control, Company Model Training, Company using ML.
Company Condition Monitoring manages and affects the monitoring of the following parts: data collection, data preprocessing, model usage, results of company ML use, and model training for company model training. This is the third mutual influence between stakeholders that can be found: Company using ML, Company Model Training and Company Condition Monitoring.
Lastly, it can be said that the people who have a stake in this pipeline can make decisions that affect the quality of the ML model, whether they are aware of it or not. Because of this, it is important that all stakeholders, all parts, and all data used to train the model can be tracked.
7. Evaluation
It is vital to construct the ML such that it is aware of the intricacies of the computing environment. To do this, ML frameworks will identify the maximum workload to be executed, which will require certain information such as memory capacity, processor speed, secured storage, and maybe additional capabilities such as multi-threading and secure communication channels. Then, from the most sensitive to the least sensitive, ML calculations are deployed into a pipeline that must be secure and specified as transparent to other stakeholders.
One essential trust increasing component is the “trust evaluation”. This component allows to make overall decisions based on the trust level of the entity involved.
Protecting the whole pipeline is impossible without the engagement of many stakeholders in a trusting atmosphere. The proposed system can provide numerous trusted zones for more devices and, as a result, additional pipeline parts. To establish such “multiparty computation” based on blockchain, one must offer a verification mechanism for numerous participants, allowing stakeholders from other organisations to participate. For example, one certified pipeline might help in confirming the specifics and right setup, allowing stakeholders to cover many sites of the ML pipeline.
In addition to the pipeline workflow, selecting the most vulnerable areas of ML for security is not easy. On the most basic level, the proposed architecture provides a more trustworthy area in the ML pipeline, such as an additional trust base for experts or a model certificate. Furthermore, research on the privacy or integrity of pipeline components other than training and inference protection, such as data preparation, are very missing. Similar to training stage protection, such protection on a specific component of the pipeline will include threat (privacy and integrity) characterization, dataset certificate protection design, and performance evaluation. Following such work on future levels of the pipeline, full ML pipeline protection will be concretely developed and deployed to a greater degree and on a bigger scale.
Table 11 lists countermeasures for potential ML pipeline attacks.
8. Conclusions
The safeguarding of AI-based solutions for the industry is essential to enabling trust in this new technology and allowing certification of products in the future, especially in sensitive manufacturing where ML is somehow involved in the producing process.
The use of blockchain as a framework to facilitate collaboration and authenticate and authorise stakeholders in the ML pipeline process is proposed in this paper. At the moment, changing the training data or the ML model to change the output or steal the ML model poses a security risk. By implementing our proposal for collaboratively registered stakeholders and using trust value for ML products and ML creators, we can reduce the risk of malicious data or codes when using a blockchain community certificate. A trust management system also aids in deterring malicious behaviour and encouraging more honest and qualified work from stakeholders. It can be shown that the proposed framework based on blockchain ensures data security and transparency in manufacturing for quality control and elaborates on the major benefits of the proposed approach, which are:
a tamper-proof data history, which achieves accountability and supports quality audits;
increases the trust by protocolling the used ML pipeline, by rating the experts involved in the ML pipeline and certifies for legitimacy for participation;
certifies the pipeline infrastructure, ML model, data collection, and labeling.
In the evaluation section the mitigation of the security attacks threaten the framework have been demonstrated.
In future work, it can be possible to use benchmarking to evaluate by experts additionally on our proposal to improve the quality of ML certificates.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}