1. Introduction
Given the abundance of visual information in the form of images and videos, image processing techniques are useful in automating tasks which would otherwise be very difficult for humans to carry out due to the sheer abundance of the visual information. Visual information understanding is a task that humans perform effortlessly. This is often manifested in our ability to capture visual information and express or communicate it through natural language.
In an effort to bridge the gap between image processing algorithms and natural language understanding, various visual understanding tasks have received significant attention in recent years. Image captioning is one such visual understanding task. Image captioning refers to the visual understanding task of expressing images using natural language. Similarly to other areas of machine learning, the major improvements in image captioning can, to a large extent, be attributed to the recent developments in deep learning—bigger and more refined datasets, faster hardware, especially graphical processing units, and better algorithms.
However, image captioning still remains a challenging task. Captioning in the wild and out-of-domain captioning are difficult tasks which show that the generated captions have a lot of room for improvement. Captioning, therefore, continues to receive a lot of research attention in a bid to refine the related algorithms. This is because image captioning has many potential applications such as in surveillance and security, robotics, self-driving cars, assistance to the visually impaired, etc.
Many of the earlier approaches to image captioning consisted of template-based methods [
1,
2,
3] and composition-based methods [
4,
5]. The template-based methods hinged on generating templates for captions. The slots of the templates were then completed based on the results of object detection, attribute classification and scene recognition. The composition-based methods employed existing image-caption databases to extract components of related captions and compose them together to come up with new descriptions. Advances in neural networks led to neural-based methods. These capitalized on the use of convolutional neural networks (CNN) to carry out the feature extraction. The use of CNNs was inspired by their success in the tasks of image classification [
6,
7,
8,
9,
10,
11,
12] and object detection [
13,
14,
15,
16]. The work of [
17] involved an early use of neural networks for caption generation, employing a feed-forward neural network that uses a given image and previous words to predict the following word. The feed-forward neural network was then replaced by a recurrent neural network (RNN) [
18] and later the limitations of the RNN in regard to gradient propagation led to the use of the LSTM RNN [
19] to decode the extracted image features into a string of words that form a caption [
20,
21].
In the neural-based methods, a common framework that emerged was the encoder-decoder framework. The encoder-decoder framework was born of language modeling [
22,
23,
24,
25]. Kiros et al. [
26] were among the first to employ the encoder-decoder framework in image captioning. They were soon followed by a number of other authors who used CNNs and LSTMs for encoding and decoding [
20,
21,
27]. The early use of the encoder-decoder framework in captioning consisted in encoding an image into an embedding space such that it could then be used as an input to downstream decoder to generate textual tokens. Many models used a variant of CNNs and LSTMs for encoding and decoding, respectively. This architecture has proven to be very powerful and many of the current captioning systems employ a variant of it.
A significant advancement in image captioning was the introduction of attention mechanisms to the encoder-decoder framework. The attention models drew inspiration from attention as used in machine translation [
22] and then object detection [
28,
29]. Through the attention mechanisms, captioning models learn to attend to various aspects of the input image as the captions are being generated. Attention mechanisms have been widely employed in a number of captioning models [
30,
31,
32,
33,
34,
35]. In the model of Lu et al. [
33], they develop an adaptive attention mechanism which learns whether or not to attend to the image depending on the context and word token being generated. Anderson et al. [
35] designed a bottom-up top-down design, which extracts visual features based on object detectors rather than the last convolutional layers of a CNN as in previous feature extractors. This model was influential for several other successive designs.
The initial attention mechanisms gave rise to self-attention, which was the underlying concept that was then employed in the development of multi-head attention in the transformer model [
36]. The transformer results from abstracting the multi-head self-attention operations into a self-contained unit. Stacking such units provides the necessary non-linearity and representational power to model complicated functions [
37]. These recent developments were initially applied to machine translation and were thereafter transferred to the visual domain. Since the initial presentation of the transformer model in 2017 [
36], it has proven to be a powerful basis on which many of the current state-of-the-art models have been designed [
38,
39,
40].
In this paper, we review a number of transformer-based image captioning models leading up to the current state-of-the-art. Other reviews of image captioning models have been completed previously [
41,
42,
43] but none of these have focused on transformers, which are a more recent invention. Many of the previous reviews have for instance focused on deep learning per se as applied to image captioning [
42] or on the prior concepts such as attention [
41,
43]. Khan et al. [
44] look broadly at transformers in vision but do not focus on the task of image captioning. Stefanini et al. [
45] also give a review that is closely related to our work. They explore a broad array of captioning methods. They deal with earlier approaches and as well as the more recent approaches in image captioning. Our review, in contrast, deals specifically with transformer-based approaches given that transformers have been the cornerstone of the current state-of-the-art in image captioning as well as other computer vision and NLP tasks. Furthermore, the earlier approaches have already been amply covered in previous surveys. Our focused approach, therefore, allows us to delve deeper into the more recent transformer-based approaches making up the current state-of-the-art in image captioning and assesses the challenges and possible future directions in this specific field. Compared to [
45], we offer a wider range of insights into future directions.
This paper is organized as follows: we first look at the common datasets and evaluation metrics that are relevant for image captioning. We then review the early vanilla transformer-based approaches that were used for image captioning. We then look at developments in vision-language pre-training and discuss how this approach has been used in the context of transformer models and image captioning. We then look at a number of specific transformer-based models involving vision-language pre-training. This is followed by a discussion and analysis that assesses the major contributions of the various methods studied as well as a comparison of those methods based on their performance results. The paper concludes with a discussion on the open challenges and future directions of the field. This organization helps appreciate the impact that transformers have had in image captioning as well as the effectiveness of vision-language pre-training.
3. Method Selection
In this section, we describe the strategy that we used to select the models reviewed. There have been many approaches to carrying out image captioning. However, in this review we are mainly interested in transformer-based approaches since these constitute the current state-of-the-art. We, therefore, do not include in our review models which were developed prior to the design of the transformer model in 2017 [
36]. Furthermore, there have already been other reviews which have amply studied the previous approaches of image captioning [
41,
42,
43].
We divide the transformer-based approaches into two broad categories: those prior to vision-language pre-training (vanilla transformer-based models) and those involving vision-language pre-training (VLP models). The former methods were developed earlier in time (shortly after the initial design of the transformer model). The latter models arose after the recent advancements in pre-training. Vision-language pre-training has had a significant impact on multi-modal models involving the visual and language domains and the current state-of-the-art models employ some form of vision-language pre-training. To illustrate this, we first study a number of vanilla transformer-based models and thereafter we assess a number of VLP models.
We are interested in models that employ publicly available datasets, especially MS COCO [
75], since this has for a long time served as a good basis for comparing various works. We are particularly interested in models that have performance metrics based on the online and public MS COCO leaderboard [
69] since this adds an additional level of objectivity. We are also interested in models that at least give performance using the CIDEr metric [
73], due to its high correlation with human judgements. Nocaps [
57] is a more recent dataset and interesting for out-of-domain captioning but we preferred to leave the study wider and include methods that do not necessarily report on Nocaps.
Given the plethora of models that have sprung up and the clear limitation of not being able to include them all in our review, we mainly focus on those with a significant design component over and above the initial design of the transformer. This means that we have not included models that have only very slight adjustments, for instance mere changes in the parameters such as size.
The selection strategy has resulted in the models reviewed being representative of the main recent approaches of transformer-based models used in image captioning.
4. Transformers in Captioning
Following the success of transformers in language modeling, they have been applied to several areas of computer vision. In image captioning, transformers are the backbone of the current high-performing models.
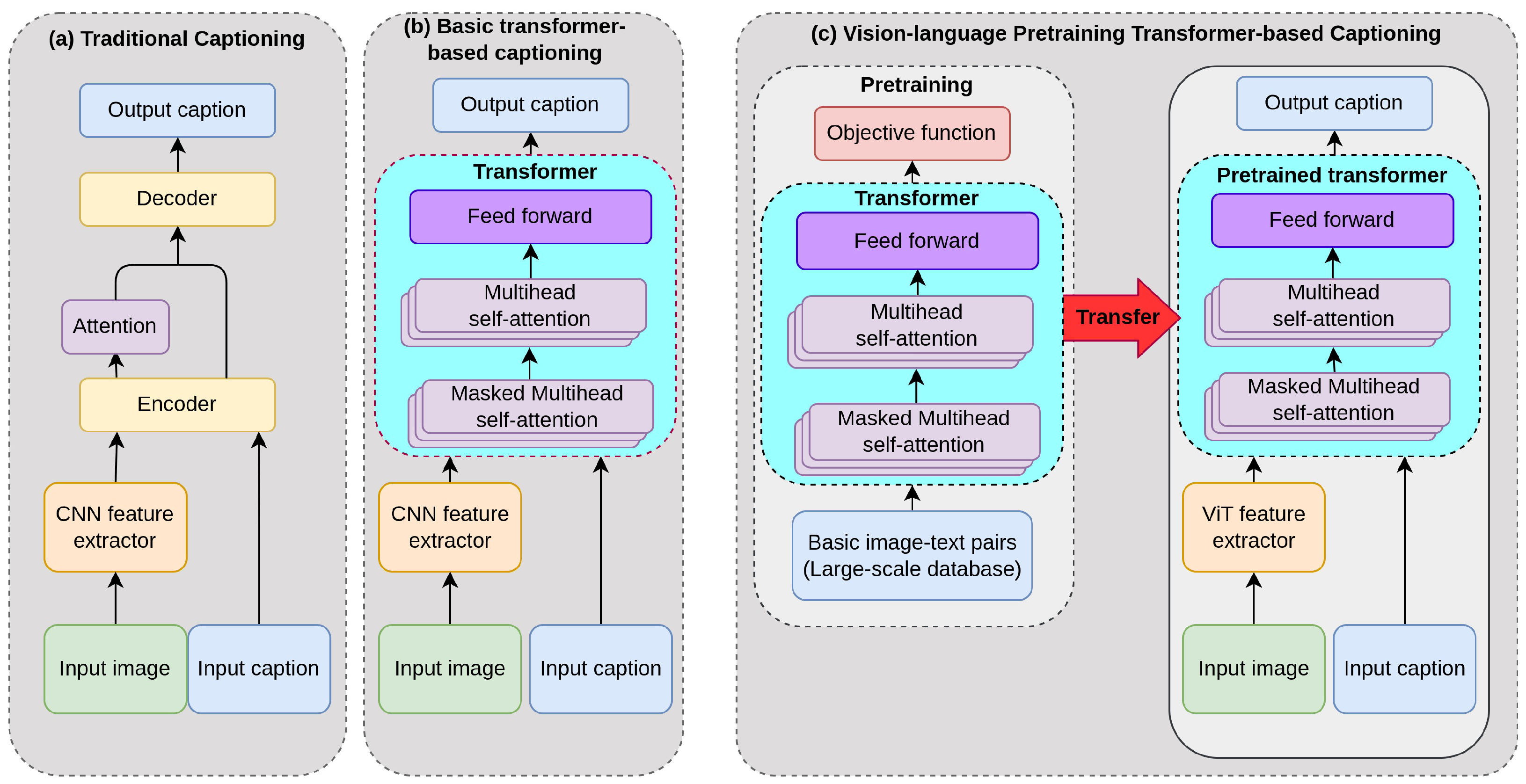
Figure 1 highlights the evolution of captioning systems from the traditional encoder-decoder models to the basic transformer-based captioning systems to the transformer-based captioning models that employ vision-language pre-training (VLP). The VLP transformer-based models are the basis for the current state-of-the-art models. The approach of vision-language pre-training is characterized by the use of large-scale automatically-annoteated datasets to pre-train the transformers prior to application in downstream vision-language tasks. It is interesting to note that the image feature extractor has been based on convolutional neural networks (CNN) for a long time, but recently there has been a shift towards Vision Transformers (ViT) for this function as well. This makes possible the realization of all-transformer models. The pipelines for each category shown in
Figure 1 are paradigmatic and as such, most of the models we look at in this paper follow a similar flow. However, different models have incorporated various other features as well as changes in the fundamental architecture, which have improved the performance.
In the rest of this section, we review the basic transformer-based captioning models and the models employing vision-language pre-training. We do not focus on the prior traditional captioning models (encoder-decoder-based), since those have been sufficiently reviewed in other works, such as [
41,
43].
4.1. Conceptual Captions
Sharma et al. [
59] present a novel dataset of image caption annotations called Conceptual Captions. It contains an order of magnitude more images than the MS-COCO dataset [
75], which has been a benchmark dataset for image captioning. The Conceptual Captions dataset is created using a pipeline that programmatically acquires images and captions from billions of internet web pages. In the modeling of the captioning system, they use a feature extractor based on Inception-ResNet-v2 [
76]. A transformer is used as the decoder and they show that the transformer model achieves better results than a Recurrent Neural Network, which was previously the dominant mode for caption generation. Their encoder and decoder essentially adhere to the generic pipeline shown in
Figure 1b. Whereas their main contribution is the Conceptual Captions dataset, they are among the first to employ the transformer model in image captioning.
4.2. Captioning Transformer with Stacked Attention Modules
Zhu et al. [
77] apply a standard transformer to perform image captioning. The encoder is a ResNext CNN [
78] and the image features are taken from the final layers. These are then used as the keys and values in the decoder. Thus, the encoder is a CNN and the decoder is a transformer, with a design and parameters closely following those used by Vaswani et al. [
36].
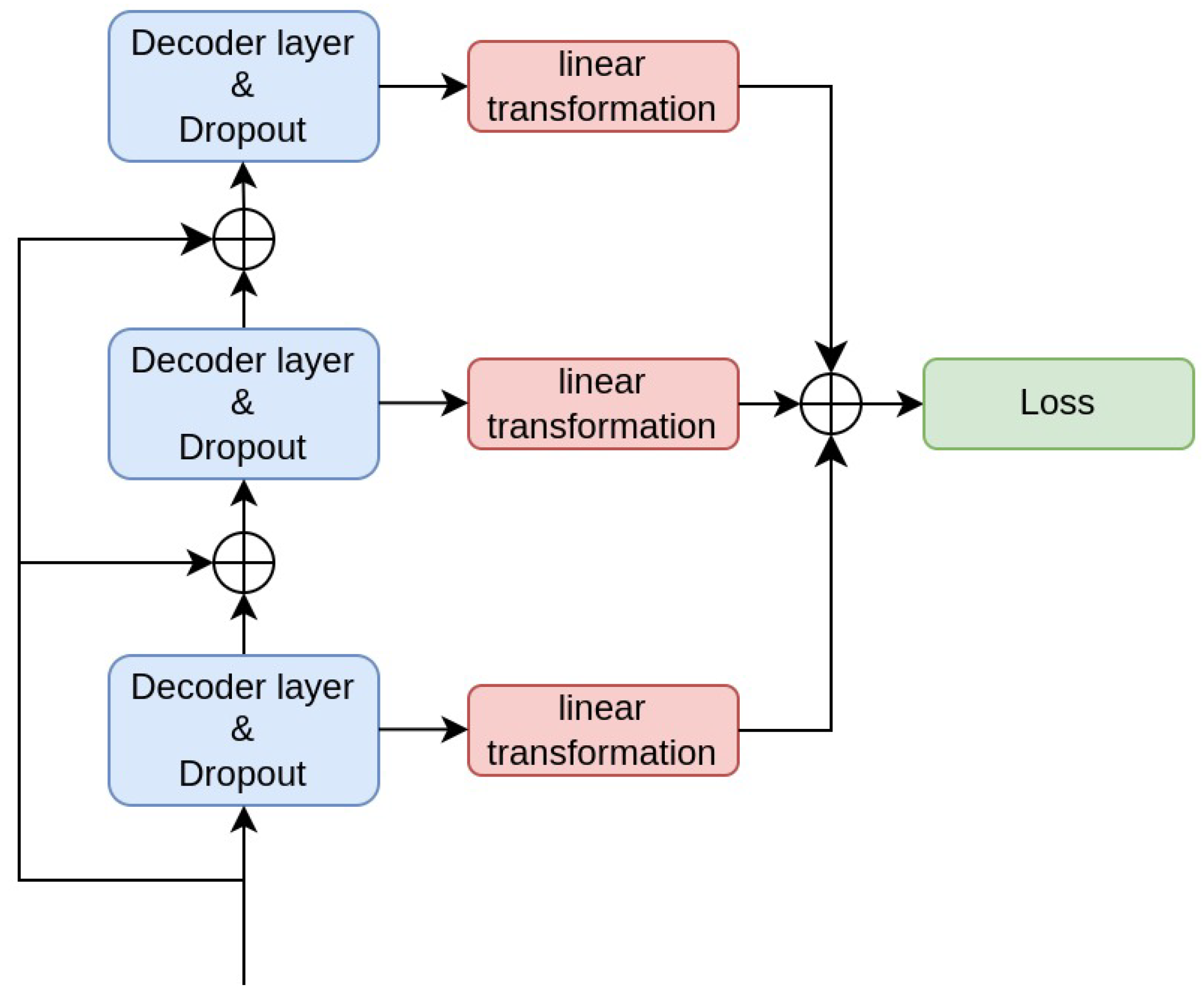
The decoder design envisions a stacking of several individual decoder layers; the overall output is taken as a combination of the outputs of the different layers. The decoder layers are separated by dropout layers to avoid overfitting.
Based on this stacking, they introduce multi-level supervision to take advantage of multi-layer outputs of the transformer. Every layer can be used to generate the current word. During training, the outputs of each layer are passed through a linear transformation and are then taken together to calculate the cross-entropy loss of the model as shown in
Figure 2. The training objective is to minimize the cross-entropy loss.
4.3. Image Captioning: Transforming Objects into Words
Herdade et al. [
79] introduce the object relation transformer. This transformer employs the concept of geometric attention to incorporate information about the spatial relationships between various objects in an image. Geometric attention had earlier been used for object detection [
80]. The approach of the authors involves utilizing the size ratio of the bounding boxes of different objects and the difference of the bounding box coordinates to deduce object relationship features. Their model is shown in
Figure 3.
The feature detector is a Faster R-CNN object detector [
15], which is used to extract appearance and geometry features, similar to the approach of Hu et al. [
80]. The transformer decoder is similar to that introduced by Vaswani et al. [
36]. However, for each encoding layer, the attention scores are modified by multiplying by the geometric attention weights,
where
and
are the queries and keys, respectively, and
is an
attention weight matrix, whose elements
are the appearance-based attention weights between the
and
token. Relative geometry is incorporated by multiplying the appearance-based attention weights by a learned function of their relative position and size. The geometric attention weights,
, are first calculated based on the geometric features of the bounding boxes (center coordinates, widths and heights). The combined attention weights are then given by
where
and
are the elements of the attention and geographic attention weights, respectively.
Yang et al. [
81], who followed a similar approach, used a scene graph representation for the encoding, which helps capture object relationships. Yao et al. [
82] introduced a Graph Convolutional Network plus LSTM (GCN-LSTM) architecture that incorporates semantic and spatial object relationships into the image encoder. Yao et al. [
83] develop a HIerarchy Parsing (HIP) architecture that parses images into multi-level structure consisting of the global level, regional level features and instance level features based on semantic segmentation. The hierarchical structure is fed into a Tree-LSTM to generate captions. However, none of these models ([
81,
82,
83]) make use of transformers.
Herdade et al. [
79] report better performance than Yang et al. [
81] and Yao et al. [
82] on the CIDEr-D metric. However, the Herdade et al. [
79] model uses a transformer whereas [
81] and [
82] do not. The use of a transformer is a significant factor contributing to the better performance. It is worth noting that [
83] outperforms [
79] on the CIDEr metric, which highlights the effectiveness of their hierarchical parsing approach.
4.4. Attention on Attention
Huang et al. [
84] introduce an attention on attention module (AoA) as illustrated in
Figure 4. In the encoder they extract feature vectors of objects in the image and apply self attention. The AoA module is then applied to determine how the objects are related to each other. Essentially, self-attention is used to model the relationships among objects in the input image. In the decoder, the AoA module helps determine to what extent the attention results are related to the queries. The model first generates an information vector and an attention gate by employing the attention result and the context vector. A second attention module is then added through an element-wise multiplication of the attention gate and the information vector to yield the final attended information. Thus, the irrelevant or misleading results are filtered out to keep only the useful ones.
The attention on attention mechanism is formulated as the element-wise multiplication of an attention gate
and an information vector
as shown in Equation (
3). The attention gate and information vector are results of two linear transformations, which are both conditioned on the context vector (the query) and the attention result. In the decoder, the AoA module is used, coupled to an LSTM module.
where
is an attention function that operates on the queries, keys and values, denoted by the matrices
and
, respectively;
and
are learnable weight matrices;
and
are bias vectors of the attention gate and information vector, respectively;
is the sigmoid activation function and ⊙ denotes element-wise multiplication.
4.5. Entangled Transformer
Li et al. [
85] introduce the Entangled Attention (ETA) transformer that tries to exploit the semantic and visual information simultaneously and thus bridge the semantic gap. The semantic gap arises due to difficulties in attention mechanisms identifying accurately the equivalent visual signals, especially when predicting highly abstract words. With their entangled attention, semantic information is injected into the visual attention process; similarly, visual information is injected into the semantic attention process, hence the name “entangled”.
They also presented the Gated Bilateral Controller (GBC) which is a gating mechanism that controls the path through which information flows. The GBC controls the interactions between the visual and semantic information. The overall attention model includes a visual sub-encoder and a semantic sub-encoder and a multimodal decoder, as shown in
Figure 5. Each sub-encoder consists of N identical blocks, each with a multi-head self-attention and feed-forward layer.
4.6. Meshed-Memory Transformer
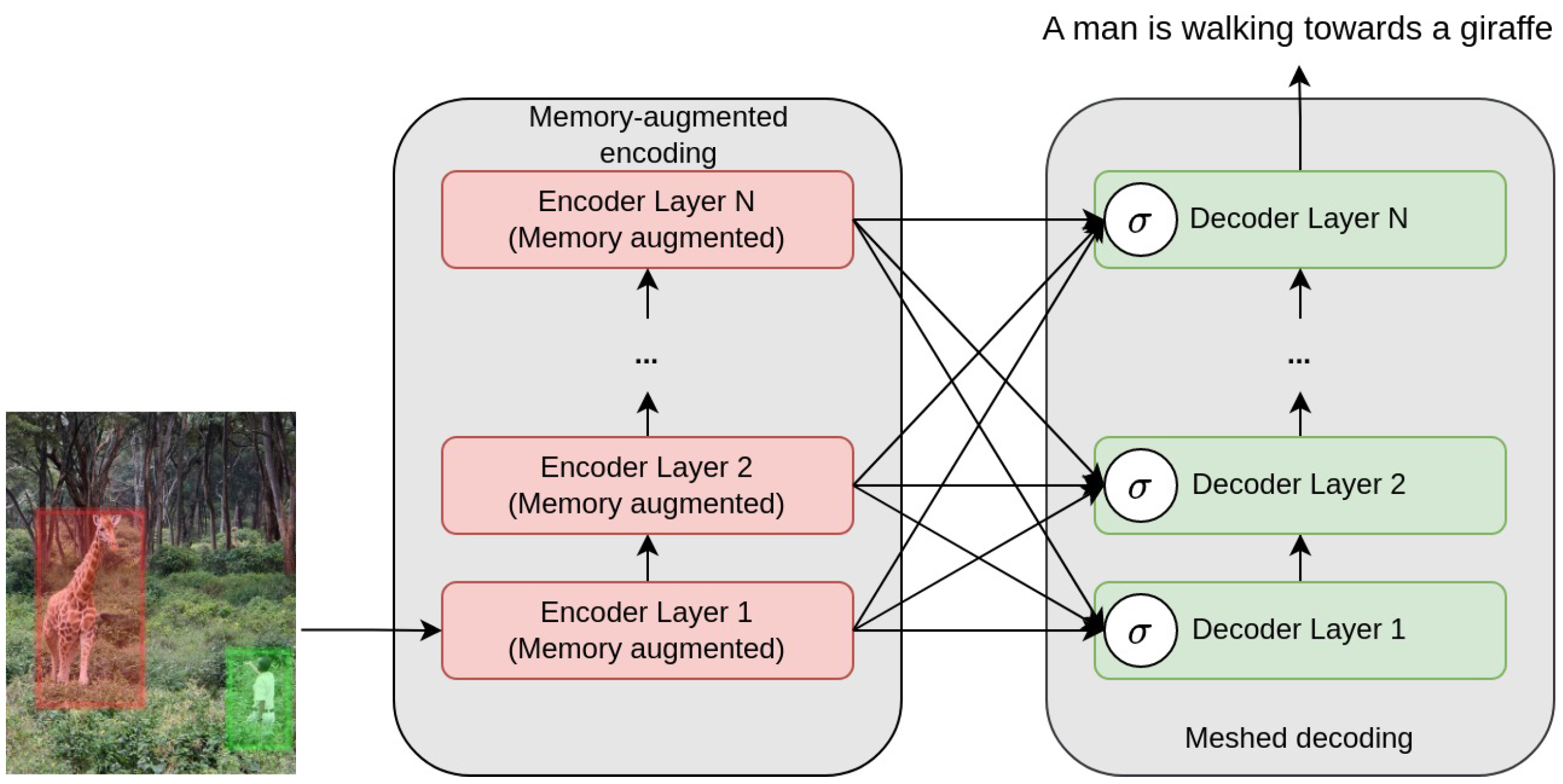
The model of Cornia et al. [
86] learns multi-level representations of the relationships between image regions such that low-level and high-level relations are represented. For this,
a priori knowledge on relationships between image regions is encoded using persistent memory vectors, which results in memory-augmented attention. During the decoding, the low-level and high-level relationships are used instead of employing a single visual mode representation. This is performed using a learned gating mechanism that weights the multi-level contributions at each stage.
Figure 6 shows the general flow of their model which they refer to as a meshed-memory transformer due to the mesh connectivity between the encoder and decoder layers. Apart from using the MS COCO dataset [
75], they validate the performance of their model on the novel object captioning using the Nocaps dataset [
57].
4.7. X-Linear Attention Networks
Pan et al. [
87] employ a method based on bilinear pooling [
88]. Bilinear pooling entails getting the outer product of two input vectors. It is employed in a bid to more fully capture the relationships between two vectors. However, it is computationally expensive since the resulting number of parameters is
. The approach can be made compact by dimensionality reduction. Bilinear pooling is an option to combine two vectors instead of other approaches such as concatenation, element-wise vector summing or element-wise vector multiplication.
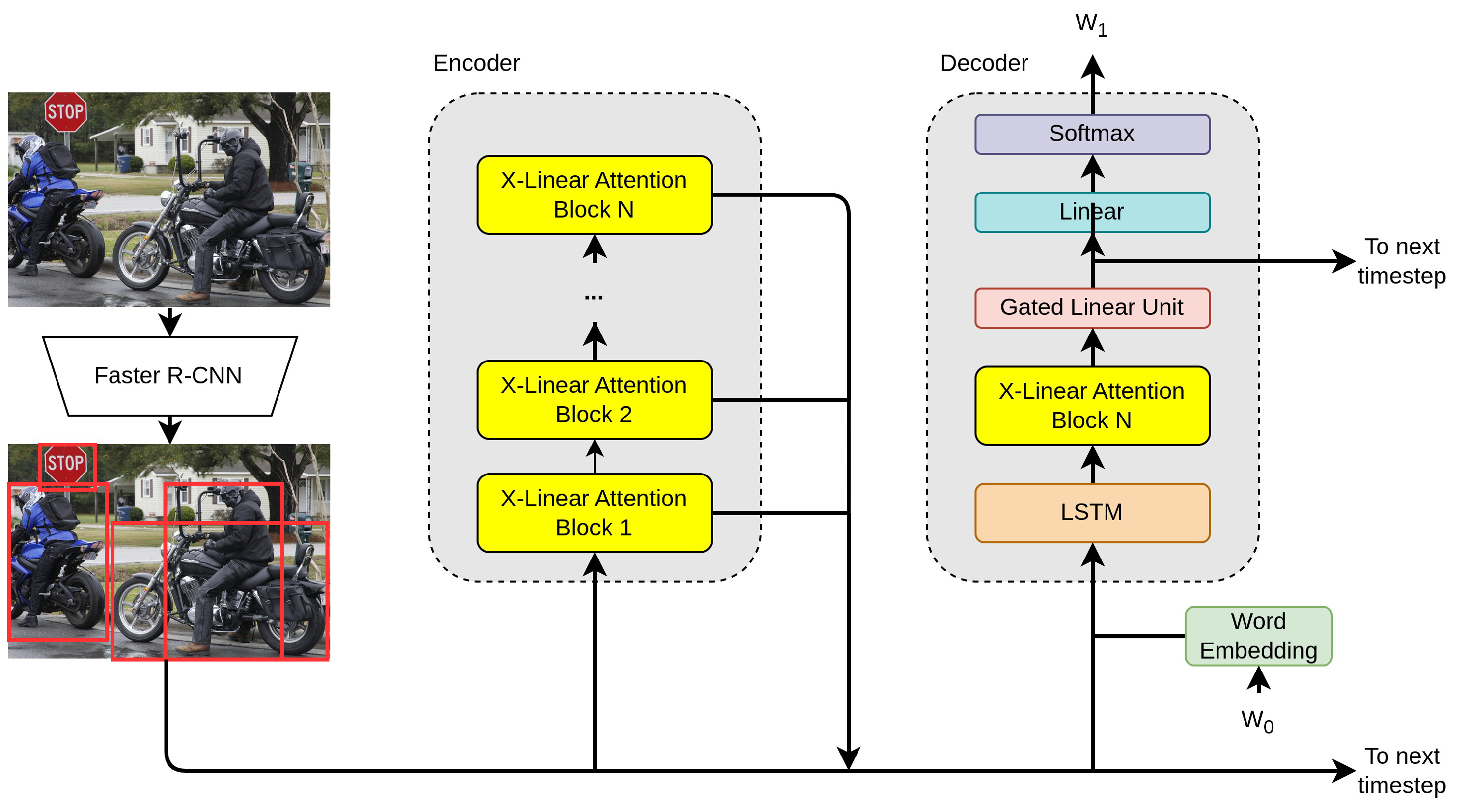
A problem of conventional attention mechanisms that Pan et al. [
87] try to overcome is the fact that the attention weights are essentially derived from the linear combination of the query and the key via an element-wise summation. This only exploits the first-order feature interactions between the textual domain and the visual domain. Whereas typical attention approaches are additive attention or dot-product attention, they propose a spatial and channel-wise attention mechanism based on bilinear pooling to exploit the higher order feature interactions. They package their attention mechanism into a block that they name X-linear attention block. The X-linear attention block uses a feature extraction backbone based on the Squeeze-and-Excitation Networks (SENet) of Hu et al. [
89]. The final model is the X-Linear Attention Network (X-LAN) shown in
Figure 7. It incorporates the X-linear attention block into the encoding and decoding operations.
Similar to AoANet, the authors confirm that improving attention measurement is an effective way of improving the interactions between the visual and textual domains. Exploiting rich semantic information in images (such as scene graphs and visual relations) leads to improved performance.
4.8. Image Transformer
He et al. [
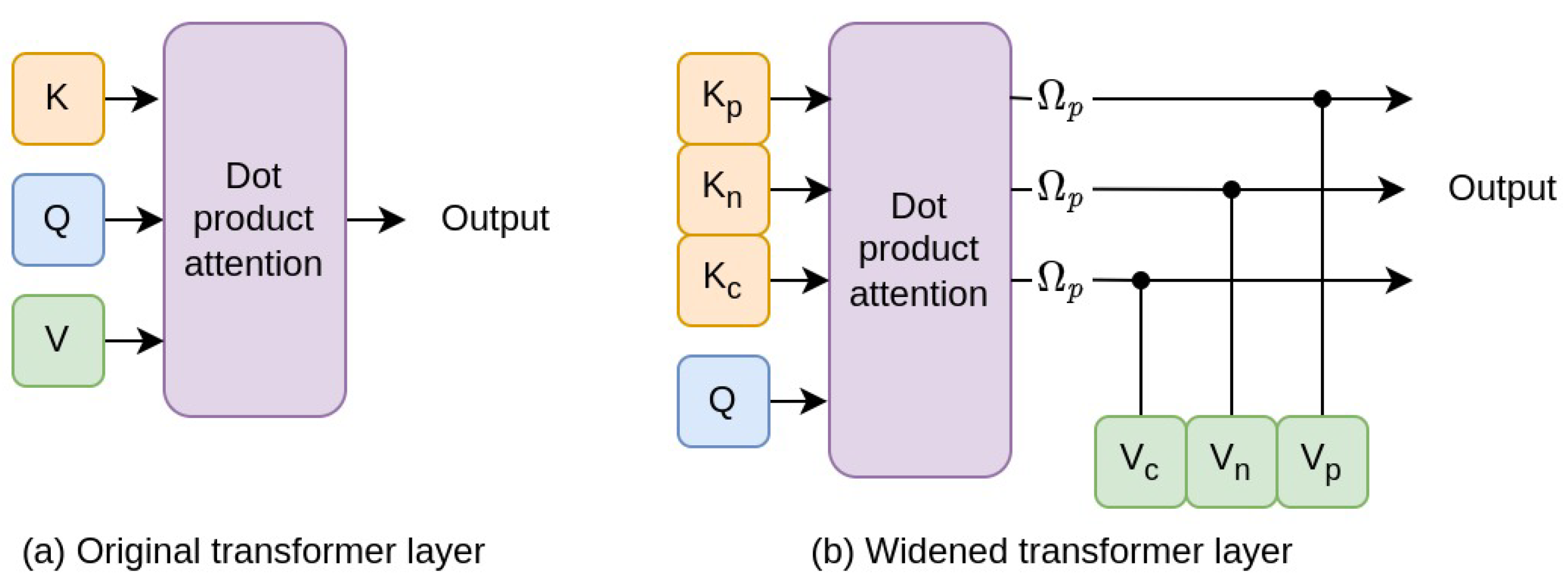
90] proposed an image transformer, whose core idea is to increase the width of the original transformer layer, designed for machine translation, and make it more suitable for the structure of images. In their image transformer, each layer has several sub-transformers that capture the spatial relationships between the image regions. The encoding method makes use of a visual semantic graph as well as a spatial graph. They use a transformer layer to combine them without external relationship or attribute detectors.
He et al. [
90] distinguish between single-stage and two-stage attention-based methods. The single-stage methods are those in which attention is only applied at the decoding step with the decoder attending to the most relevant regions. Two-stage methods use bottom-up attention and top-down attention [
35]. The bottom-up uses object detection based methods to select the most relevant regions; top-down attention then attends to those detected regions. Although the two-stage methods improve on the single-stage methods, they have the limitation that the detected regions are isolated and their relationships are not modeled. This limitation is tackled by scene graph based models. However, the scene graph models use auxiliary or external models to detect and build the scene graphs. He et al. [
90] introduce a spatial graph encoding transformer layer, which considers the spatial relationships between the various detected regions in an image.
The model considers three categories of spatial relationships, namely parent, neighbor and child relationships between the various regions of an image. These categories are based on the amount of overlap between the regions. Neighbors of a query region are those regions with no overlap or with overlap below a set threshold; a parent region contains a query region, whereas a child region is contained by the query region. The spatial relationships between region pairs are captured using graph adjacency matrices. For any two regions,
l and
m, the graph adjacency matrices are defined as represented in Equation (
4).
,
and
are the parent, neighbor and child node adjacency matrices, respectively, and
is a given threshold.
As shown in
Figure 8, the original transformer layer is widened by adding three parallel sub-transformer layers, each being responsible for a subcategory of spatial relationships. The decoder incorporates an LSTM and its structure is also widened to correspond to the encoder; its output is obtained via a gated linear unit.
Since they are incorporating graph information into the transformer, the model is similar to other graph-extraction techniques. However, they use a transformer, unlike other graph-extraction techniques [
81,
82]. The authors point out that their model is more computationally efficient since the other scene graph extracting models fuse semantic and spatial scene graphs, and require auxiliary models to first build the scene graph.
4.9. Comprehending and Ordering Semantics
Li et al. [
91] develop a model, called COS-Net, that aims at comprehending the rich semantics in images and ordering them in linguistic order so as to generate visually grounded and linguistically coherent captions for the images. Their architecture entails four primary components: cross-modal retrieval, a semantic comprehender, a semantic ranker and a sentence decoder. The cross-modal retrieval serves to generate semantic cues. The retrieval uses CLIP [
53] to search for all the relevant sentences related to images. The words of these sentences are then used as the semantic cues. The semantic comprehender filters out irrelevant semantic cues while at the same time inferring any missing and relevant semantic words grounded in the image. To carry out the filtering, the comprehender makes use of grid features derived from a visual encoder based on CLIP. The semantic ranker then determines a linguistic ordering for the semantic words. The output of the semantic ranker is used together with the visual tokens of images to auto-regressively generate the output captions. The implementation is conducted using the x-modaler codebase [
92]. The dataset used for training and testing is MS COCO.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}