
Service Recommendation of Industrial Software Components Based on Explicit and Implicit Higher-Order Feature Interactions and Attentional Factorization Machines

Abstract
:1. Introduction
- The innovation of the EIAFM model lies in its integration of explicit and implicit higher-order feature interactions to accurately capture valuable information from complex data. Furthermore, the introduction of an attention mechanism enables precise measurement of the varying importance within feature interactions, endowing the model with both low-level memory capability and high-level generalization ability.
- An industrial software service component recommendation framework based on EIAFM is proposed, which is mainly applicable to typical industrial collaborative manufacturing systems; its application can obtain better service component recommendation results.
- Comprehensive experiments are conducted using a real dataset that fits the description of the Service Recommendation of Industrial Software Components problem; the experimental outcomes demonstrate the notable superiority of the proposed EIAFM model over several mainstream recommendation approaches.
2. Related Work
2.1. Traditional Recommendation Models
2.2. Deep Learning Recommendation Models
2.3. Factorization Machine-Based Models
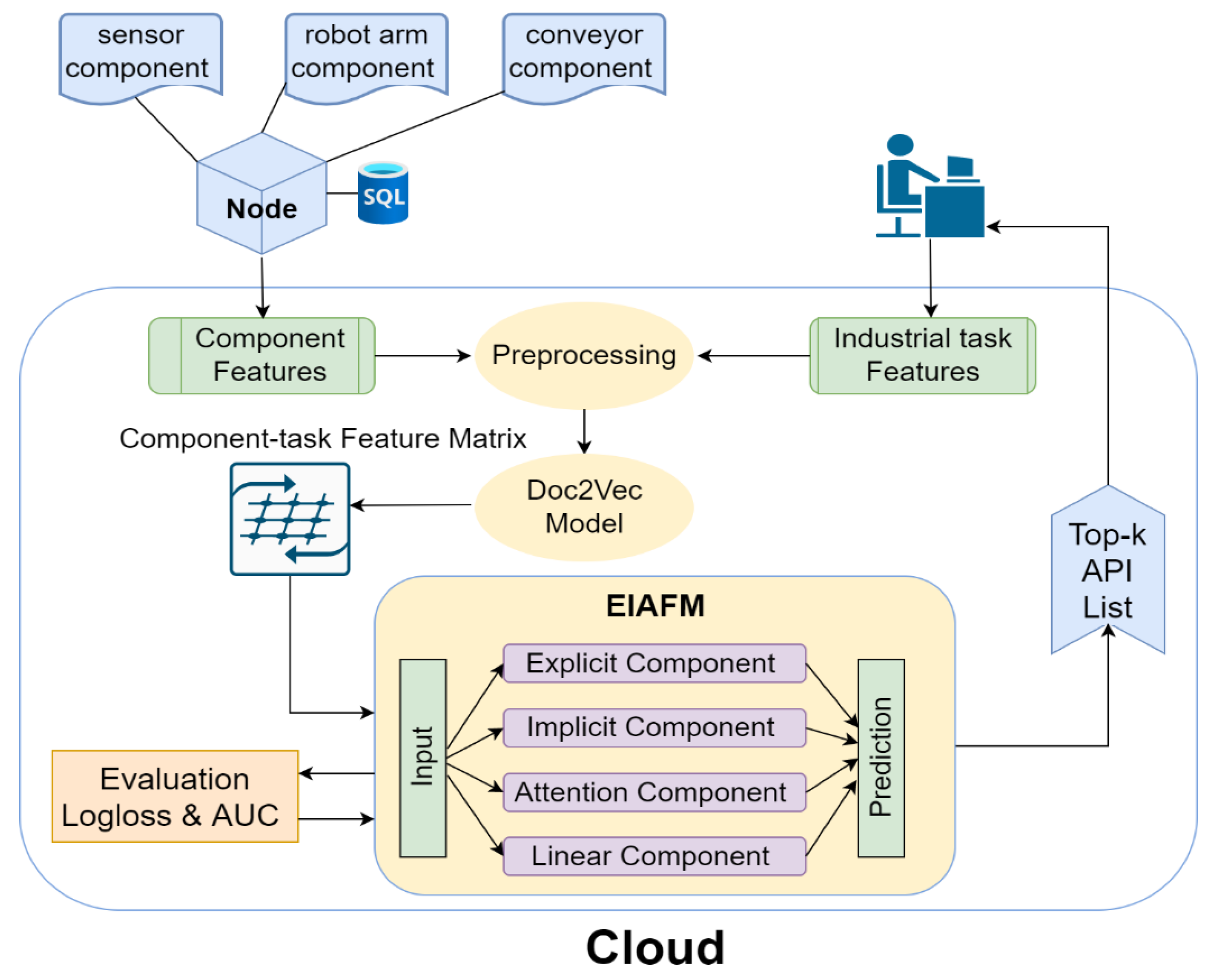
3. Recommended Architecture for Industrial Software Service Components
4. Combination of Explicit and Implicit Higher-Order Feature Interaction and Attentional Factorization Machines
4.1. Problem Definition
4.2. FM-Based Models for Service Recommendation
4.2.1. Introducing Hidden Vectors
4.2.2. Measuring Feature Importance
4.2.3. Explicit and Implicit Higher-Order Feature Interactions
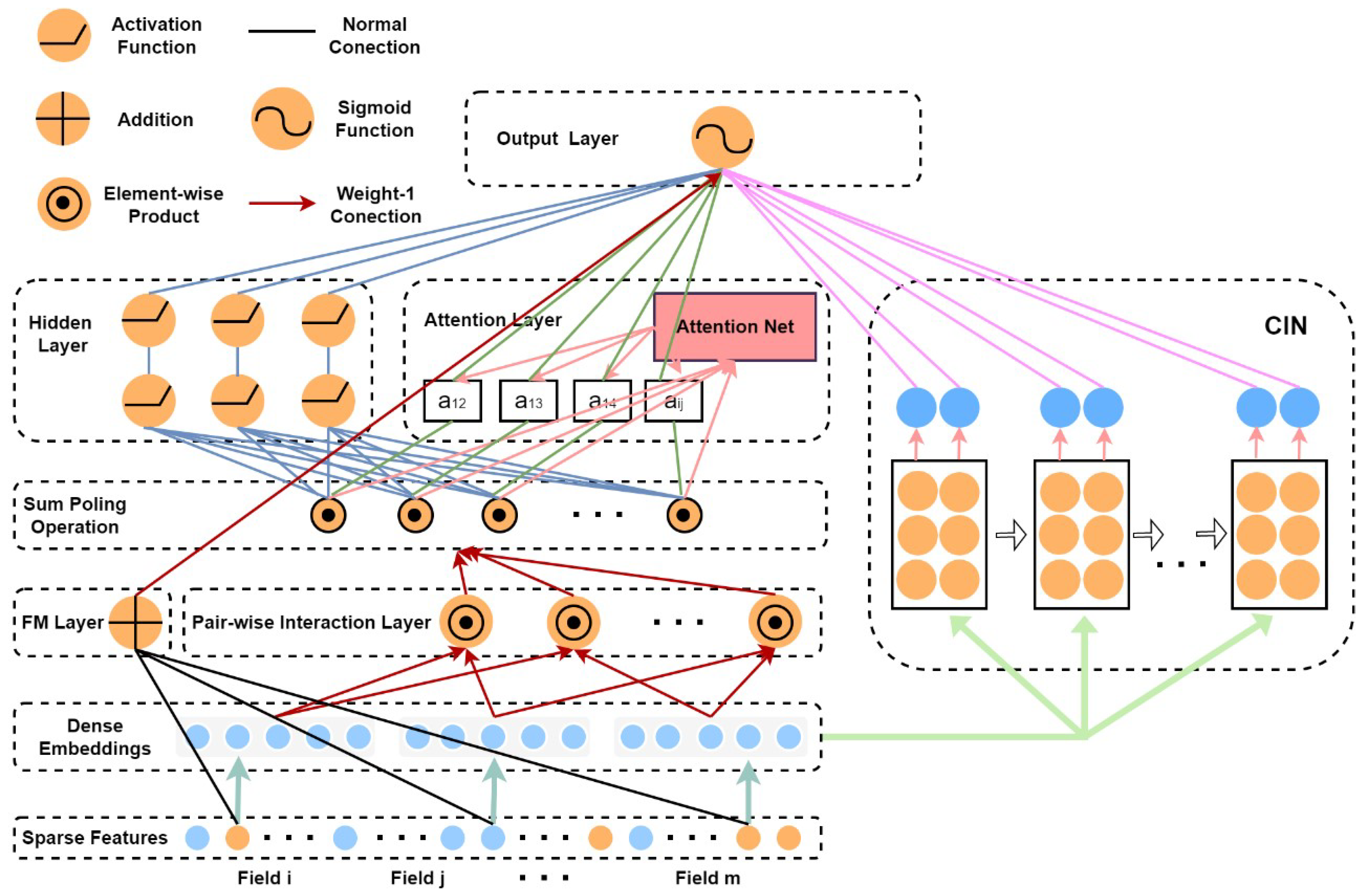
4.3. Explicit and Implicit Higher-Order Feature Interactions and Attention Factorization Machine for Service Component Recommendation
4.4. Relationship of EIAFM to Existing FM-Based Models
5. Experiments and Discussion
5.1. Dataset
5.2. Evaluation Metrics
5.3. Comparative Evaluation and Analysis of Performance
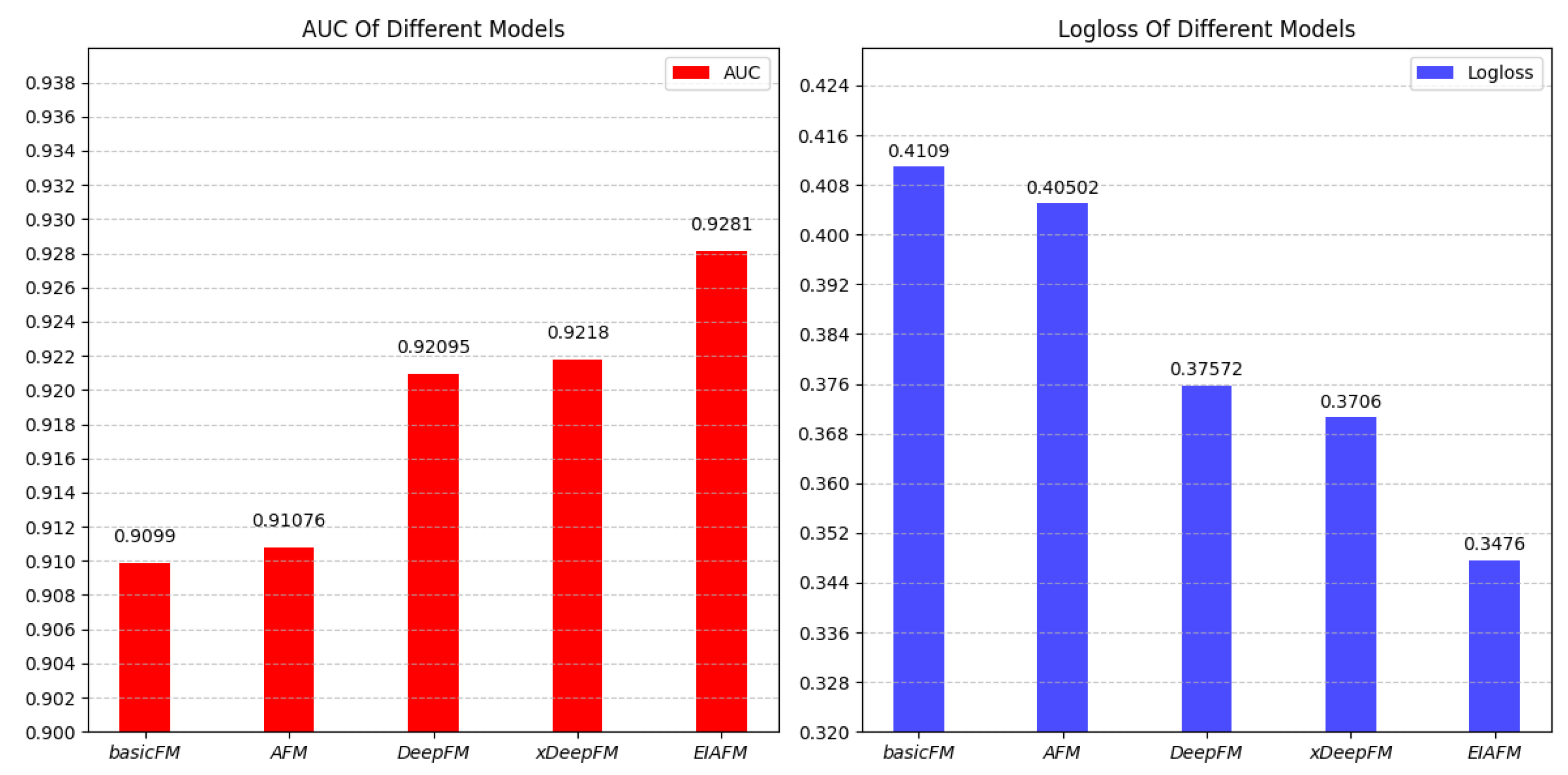
5.3.1. Recommended Performance Comparison
5.3.2. Analysis and Comparison of Model Complexity and Runtime
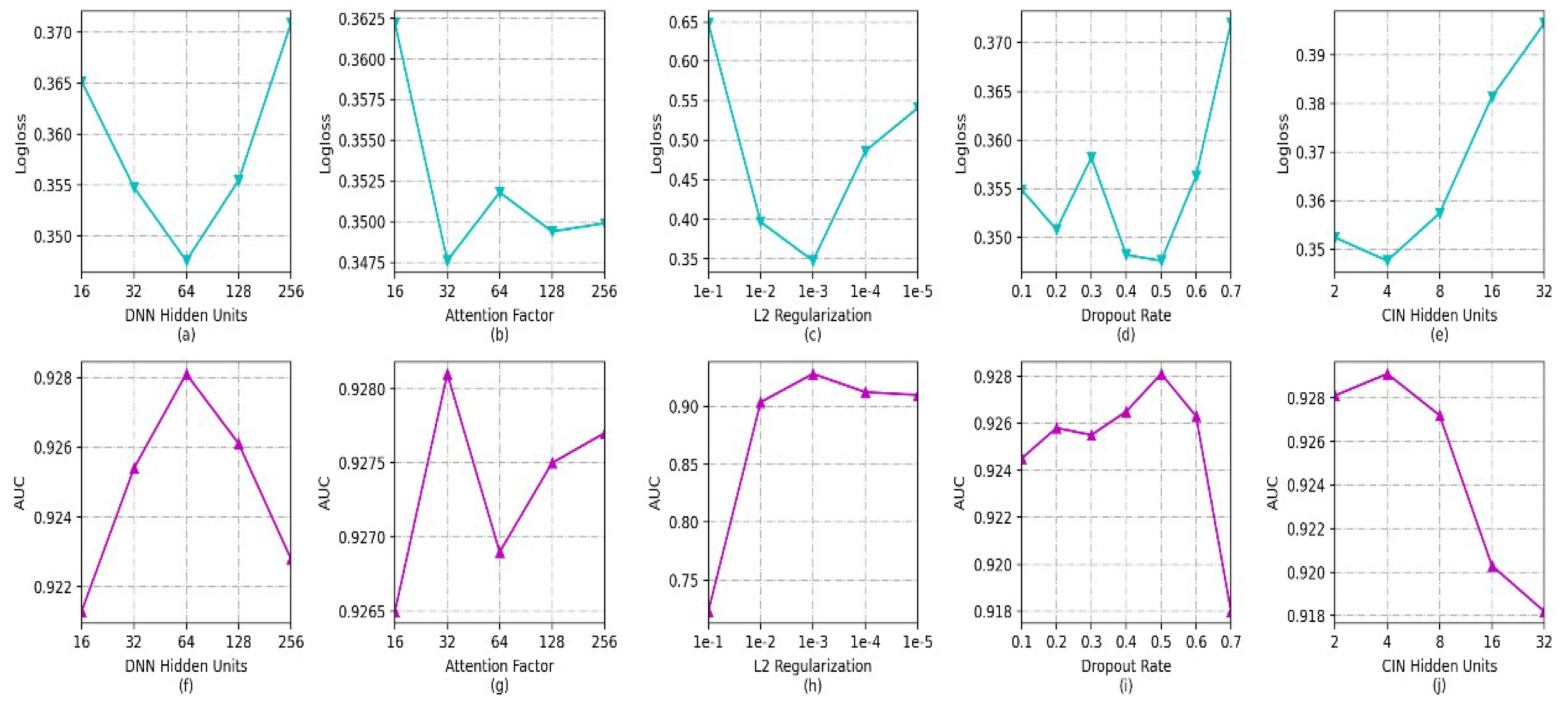
5.3.3. Influence of Hyperparameters
- The effect of the quantity of hidden units in the DNN: as observed in in Figure 4a,f, it can be seen that the log-loss value decreases sharply with the increase in the number of DNN hidden units; when the count of hidden units reaches 64, the log-loss value starts to rise sharply. The corresponding AUC value first rises sharply, then starts to fall when the count of hidden units reaches 64. More hidden units make the model more capable of nonlinear interactions. However, an excessive number of hidden units can lead to overfitting in the model. When the number of hidden units is in the range of [32,128], both the log-loss and AUC perform well.
- Effect of Attention Factor: from Figure 4b,g, it can be observed that the log-loss and AUC fluctuate slightly when the attention factor is greater than 32. This fluctuation is due to the fact that the role of the attention component is to use the attention weights to measure which feature interactions contribute more significantly to the prediction. For low attention factors, there exists only slight variability in the significance scores of various feature interactions. The log-loss and AUC fluctuate relatively little when the attention factor reaches 32, and overall the model works best at an attention factor of 32.
- Effect of L2 regularization and dropout rate: from Figure 4c,h, it can be observed that the log-loss decreases first and then increases, and the model achieves the best performance when the strength of L2 regularization is 1 × 10. The main purpose of L2 regularization is to avoid overfitting. The optimization of the loss function is affected when the L2 regularization reaches 1 × 10; the overall view is that the best results for both the log-loss and AUC are achieved when the strength of L2 regularization is 1 × 10. The effect of the dropout rate can be observed from Figure 4d,i; the effect of dropout rate is not very large for the model except for the setting of 0.7. The log-loss and AUC values perform poorly, as on average a larger dropout requires more iterations for the model training to converge for the experimental default number of iterations. The model exhibits peak performance when the dropout rate is configured as 0.5.
- The effect of the quantity of hidden layer units in CIN: as can be observed from Figure 4e,j, the log-loss first decreases and then grows drastically with the increase in the number of CIN hidden units. The reason for this is mainly that the increase in the quantity of neurons in each layer of the CIN results in an increase in the number of feature maps in the CIN. Though the model is better able to learn the information of feature interactions with different orders, too many of them increases the model’s complexity and produces overfitting. In addition, according to the experimental results, better results are obtained when the number of CIN hidden layers is 4. The main reason for this is that the CIN in the model design is a better complement to the DNN for high-order feature interactions, and does not need very many hidden layer units to achieve better training results. Another noteworthy observation is that the neural network-based model does not need a deeper network structure to obtain the best results; the best results can be obtained by setting the number of layers of both the CIN and DNN to 2 during the training process on this dataset.
5.3.4. Influence of Different Components in EIAFM
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, D.; Han, Q.L.; Wang, Z.; Ge, X. A survey on model-based distributed control and filtering for industrial cyber-physical systems. IEEE Trans. Ind. Inform. 2019, 15, 2483–2499. [Google Scholar] [CrossRef]
- Shmeleva, A.G.; Ladynin, A.I. Industrial management decision support system: From design to software. In Proceedings of the 2019 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Saint Petersburg and Moscow, Russia, 28–31 January 2019; pp. 1474–1477. [Google Scholar]
- Niknejad, N.; Ismail, W.; Ghani, I.; Nazari, B.; Bahari, M. Understanding Service-Oriented Architecture (SOA): A systematic literature review and directions for further investigation. Inf. Syst. 2020, 91, 101491. [Google Scholar] [CrossRef]
- Kutnjak, A.; Pihiri, I.; Furjan, M.T. Digital transformation case studies across industries–Literature review. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 1293–1298. [Google Scholar]
- Wu, L.; He, X.; Wang, X.; Zhang, K.; Wang, M. A survey on accuracy-oriented neural recommendation: From collaborative filtering to information-rich recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 4425–4445. [Google Scholar] [CrossRef]
- Cui, Z.; Xu, X.; Fei, X.; Cai, X.; Cao, Y.; Zhang, W.; Chen, J. Personalized recommendation system based on collaborative filtering for IoT scenarios. IEEE Trans. Serv. Comput. 2020, 13, 685–695. [Google Scholar]
- Wang, W.; Chen, J.; Wang, J.; Chen, J.; Liu, J.; Gong, Z. Trust-enhanced collaborative filtering for personalized point of interests recommendation. IEEE Trans. Ind. Inform. 2019, 16, 6124–6132. [Google Scholar] [CrossRef]
- Rahman, M.M.; Liu, X.; Cao, B. Web API recommendation for mashup development using matrix factorization on integrated content and network-based service clustering. In Proceedings of the 2017 IEEE international conference on services computing (SCC), Honolulu, HI, USA, 25–30 June 2017; pp. 225–232. [Google Scholar]
- Xu, W.; Cao, J.; Hu, L.; Wang, J.; Li, M. A social-aware service recommendation approach for mashup creation. In Proceedings of the 2013 Ieee 20th International Conference on Web Services, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 107–114. [Google Scholar]
- Yao, L.; Wang, X.; Sheng, Q.Z.; Benatallah, B.; Huang, C. Mashup recommendation by regularizing matrix factorization with API co-invocations. IEEE Trans. Serv. Comput. 2018, 14, 502–515. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, D.; Li, D.; Chen, X.; Zhao, Y.; Niu, X. A mobile recommendation system based on logistic regression and gradient boosting decision trees. In Proceedings of the 2016 international joint conference on neural networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1896–1902. [Google Scholar]
- Cao, B.; Liu, J.; Wen, Y.; Li, H.; Xiao, Q.; Chen, J. QoS-aware service recommendation based on relational topic model and factorization machines for IoT Mashup applications. J. Parallel Distrib. Comput. 2019, 132, 177–189. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, J.; Cao, B.; Xiao, Q.; Wen, Y. Web service recommendation via combining Doc2Vec-based functionality clustering and DeepFM-based score prediction. In Proceedings of the 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, VIC, Australia, 11–13 December 2018; pp. 509–516. [Google Scholar]
- Cao, B.; Li, B.; Liu, J.; Tang, M.; Liu, Y. Web apis recommendation for mashup development based on hierarchical dirichlet process and factorization machines. In Proceedings of the Collaborate Computing: Networking, Applications and Worksharing: 12th International Conference, CollaborateCom 2016, Beijing, China, 10–11 November 2016; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2017; pp. 3–15. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th international conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ƚ; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Wang, F.; Zhu, H.; Srivastava, G.; Li, S.; Khosravi, M.R.; Qi, L. Robust collaborative filtering recommendation with user-item-trust records. IEEE Trans. Comput. Soc. Syst. 2021, 9, 986–996. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Y.; Ma, C.; Coates, M.; Guo, H.; Tang, R.; He, X. Multi-graph convolution collaborative filtering. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1306–1311. [Google Scholar]
- Shen, D.; Liu, J.; Wu, Z.; Yang, J.; Xiao, L. ADMM-HFNet: A matrix decomposition-based deep approach for hyperspectral image fusion. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5513417. [Google Scholar] [CrossRef]
- Li, C.; Jiang, T.; Wu, S.; Xie, J. Single-channel speech enhancement based on adaptive low-rank matrix decomposition. IEEE Access 2020, 8, 37066–37076. [Google Scholar] [CrossRef]
- Yang, B. Application of Matrix Decomposition in Machine Learning. In Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 24–26 September 2021; pp. 133–137. [Google Scholar]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks: Estimating the click-through rate for new ads. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 521–530. [Google Scholar]
- Chang, Y.W.; Hsieh, C.J.; Chang, K.W.; Ringgaard, M.; Lin, C.J. Training and testing low-degree polynomial data mappings via linear SVM. J. Mach. Learn. Res. 2010, 11, 1471–1490. [Google Scholar]
- Juan, Y.; Zhuang, Y.; Chin, W.S.; Lin, C.J. Field-aware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 43–50. [Google Scholar]
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Yu, D.; Mao, J. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262. [Google Scholar]
- Qu, Y.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-based neural networks for user response prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1149–1154. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, 14 August 2017; pp. 1–7. [Google Scholar]
- Zhang, W.; Du, T.; Wang, J. Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction. In Proceedings of the Advances in Information Retrieval: 38th European Conference on IR Research, ECIR 2016, Padua, Italy, 20–23 March 2016; Proceedings 38. Springer: Berlin/Heidelberg, Germany, 2016; pp. 45–57. [Google Scholar]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617. [Google Scholar]
- Kang, G.; Liu, J.; Cao, B.; Cao, M. Nafm: Neural and attentional factorization machine for web api recommendation. In Proceedings of the 2020 IEEE international conference on web services (ICWS), Beijing, China, 19–23 October 2020; pp. 330–337. [Google Scholar]
- Kang, G.; Liu, J.; Xiao, Y.; Cao, B.; Xu, Y.; Cao, M. Neural and attentional factorization machine-based Web API recommendation for mashup development. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4183–4196. [Google Scholar] [CrossRef]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, PMLR, Montreal, QC, Canada, 8–13 December 2014; pp. 1188–1196. [Google Scholar]
- Huang, K.; Fan, Y.; Tan, W. An empirical study of programmable web: A network analysis on a service-mashup system. In Proceedings of the 2012 IEEE 19th International Conference on Web Services, Honolulu, HI, USA, 24–29 June 2012; pp. 552–559. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Order-One Features | Order-Two Features | Explicit High-Order Features | Implicit High-Order Features | Distinguish the Importance of Order-2 Feature Interation |
|---|---|---|---|---|---|
| basicFM | ✓ | ✓ | × | × | × |
| DeepFM | ✓ | ✓ | × | ✓ | × |
| AFM | ✓ | ✓ | × | × | ✓ |
| xDeepFM | ✓ | ✓ | ✓ | ✓ | × |
| EIAFM | ✓ | ✓ | ✓ | ✓ | ✓ |
| Items | Values |
|---|---|
| Quantity of Mashups | 6206 |
| Count of APIs | 12,919 |
| Invocations Quantity | 9297 |
| Count of invoked APIs | 940 |
| The quantity of APIs for each Mashup | 2.08 |
| Mean API description length | 76.84 |
| Mean Mashup description length | 36.57 |
| Proportion of Invoked APIs | 7.28% |
| Items | Values |
|---|---|
| Iteration count for the model | 100 |
| Training batch size per iteration | 128 |
| Size of the test dataset | 20% |
| Hidden units in a two-layer configuration | (64,64) |
| Factor of attention | 32 |
| Units in a two-layer CIN configuration | (4,4) |
| Strength of L2 regularization | 0.001 |
| Rate of dropout | 0.5 |
| Value of seed | 0 |
| Models | Complexity | Parameter Count | Runtime (Second) |
|---|---|---|---|
| basicFM | O(NE) | 1.0754 | |
| AFM | O(NE+N2E+EA) | 10.2260 | |
| DeepFM | O(NE+NEHU) | 2.5560 | |
| xDeepFM | O(NE+NEHU+NTF2) | 3.6041 | |
| EIAFM | O(NE+N2E+EHU+EA+NTF2) | 14.0392 |
| Mode With Varied Components | Logloss | AUC |
|---|---|---|
| LC | 0.413 | 0.9035 |
| AC | 0.4726 | 0.8933 |
| EC | 0.3897 | 0.918 |
| LC + AC | 0.4053 | 0.9106 |
| LC + EC | 0.3881 | 0.9104 |
| LC + IC | 0.3686 | 0.9187 |
| AC + EC | 0.3811 | 0.9138 |
| AC + IC | 0.3701 | 0.9165 |
| EC + IC | 0.3622 | 0.9211 |
| IC + EC + AC | 0.3501 | 0.9261 |
| IC + AC + LC | 0.3605 | 0.9239 |
| IC + EC + LC | 0.3595 | 0.9242 |
| AC + EC + LC | 0.3754 | 0.9155 |
| LC + AC + EC + IC | 0.3476 | 0.9281 |
| SOA | Service-oriented architecture |
| DM | The descriptive information of the industrial task |
| SIM | The similarity between the service component and the industrial task |
| POC | The prevalence of the service component |
| CC | The class of the service component |
| CM | The class of the industrial task |
| S | The final prediction score |
| LC | Linear component |
| AC | Attention component |
| EC | Explicit component |
| IC | Implicit component |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, K.; Wang, T.; Cheng, L. Service Recommendation of Industrial Software Components Based on Explicit and Implicit Higher-Order Feature Interactions and Attentional Factorization Machines. Appl. Sci. 2023, 13, 10746. https://doi.org/10.3390/app131910746
Xu K, Wang T, Cheng L. Service Recommendation of Industrial Software Components Based on Explicit and Implicit Higher-Order Feature Interactions and Attentional Factorization Machines. Applied Sciences. 2023; 13(19):10746. https://doi.org/10.3390/app131910746
Chicago/Turabian StyleXu, Ke, Tao Wang, and Lianglun Cheng. 2023. "Service Recommendation of Industrial Software Components Based on Explicit and Implicit Higher-Order Feature Interactions and Attentional Factorization Machines" Applied Sciences 13, no. 19: 10746. https://doi.org/10.3390/app131910746
APA StyleXu, K., Wang, T., & Cheng, L. (2023). Service Recommendation of Industrial Software Components Based on Explicit and Implicit Higher-Order Feature Interactions and Attentional Factorization Machines. Applied Sciences, 13(19), 10746. https://doi.org/10.3390/app131910746