2.1. Convolutional Neural Networks
Convolutional Neural Networks (CNNs) have emerged as a cornerstone in the realm of deep learning [
19,
20,
21]. Their prowess lies in processing data with a grid-like structure. A quintessential example of this would be images, where data can be visualized as a two-dimensional grid made up of pixels. One of the core processes in a CNN is the convolution operation, designed to automatically extract a range of features from the input data [
22]. The design of a CNN as a spatial stream is geared towards capturing spatial features within images, especially those pertinent to human dynamics and postures. The localized nature of convolutional operations allows for the detection of localized features in images, such as edges, textures, and shapes, which are instrumental in recognizing human postures. Through pooling operations, CNNs exhibit spatial invariance, ensuring that humans can be detected regardless of their position in an image. Multiple convolutional and pooling layers in CNNs facilitate multilevel feature extraction, ranging from rudimentary edges and textures to intricate human body parts and postures.
Convolutional Neural Networks (CNNs) primarily comprise two processing stages: the feature learning phase and the classification phase. The feature learning phase is realized through a combination of convolutional and pooling layers. This phase is dedicated to extracting the most salient features from training examples. Subsequently, these extracted features are fed into fully connected layers. The final layer of a deep neural network typically consists of a fully connected layer combined with a Softmax classification network, producing a classifier with a number of classes equivalent to the requirements of the project.
(1) This operation involves moving through the input data using a convolution kernel, based on a predefined step size, known as the “Stride”. Each of these movements entails a convolution operation. To grasp this concept in a more mathematical sense, consider the following formula: In this paper, the VGG 16 model is selected in the spatial flow. The model uses a 16-layer deep network, including 13 convolutional layers and 3 fully connected layers. The convolution kernel is 3 × 3, and the step size is 1.
(2) The input layer serves as the initial layer in the CNN architecture, facilitating the introduction of data into the neural network. In Convolutional Neural Networks (CNNs), the primary role of the input layer is to receive and prepare raw grid-structured data, such as images. For colored images, the input layer typically handles a three-dimensional array with dimensions (height, width, and channel count). In the case of RGB images, there are three channels, representing red, green, and blue, respectively, while grayscale images consist of a single channel. Prior to propagation through the network, image data are commonly normalized, converting each pixel value to a range between [0, 1], which aids in expediting the model’s convergence.
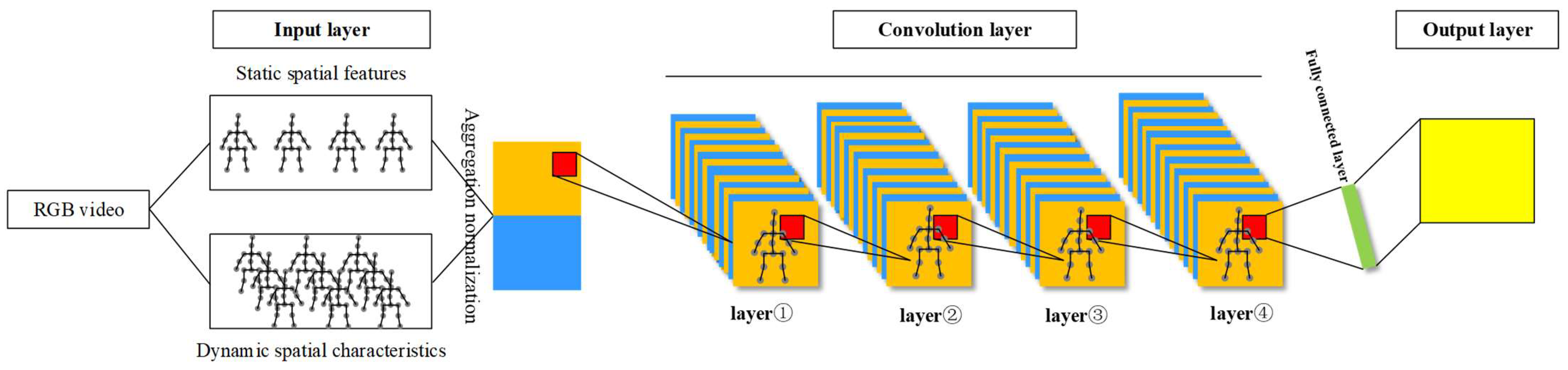
The input of the network layer is video frame data with helmet feature point information. Firstly, the static feature of the human motion space attitude is extracted from the image containing feature points, and then, the hidden dynamic feature is obtained by the position transformation of the same joint point of two video frames under Δt time difference. The network diagram of the process is shown in
Figure 1.
Specifically, the spatial flow defines a single action as p in the process of extracting information, the total number of action sequences is
T, the individual time is
t (
t ∈ T), and its action feature is
. Now, the information obtained by the network layer in the feature extraction process is integrated, and the sequence values of each frame of action are aggregated and normalized; that is, the maximum and minimum values obtained during the change of the joint vector i of the action are integrated.
The set of all static features is represented as
where
denotes the static feature of the video sequence.
The dynamic features of human spatial pose motion are represented by the sequence difference of joint point data in adjacent video frames. Let the difference between adjacent intervals be
, then
, which can be integrated into
m − 1 corresponding data values in
m video frames as hidden features to enhance the static spatial pose data. The process can be expressed as
(3) The pooling layer is designed to reduce the dimensionality of the output from the convolutional step (feature maps), both diminishing the size of the model and retaining crucial information within this reduced model. Pooling layers are typically situated between two convolutional layers, with each pooling layer’s feature map connected to its preceding convolutional layer’s feature map, hence maintaining an equivalent number of feature maps. The primary pooling operations are max pooling and average pooling, with max pooling being more prevalently utilized.
(4) The fully connected layer abstracts image data into a one-dimensional array. After undergoing processes through two rounds of convolutional and pooling layers, the final classification result in a Convolutional Neural Network is delivered by three fully connected layers. The transition from either a convolutional or pooling layer to a fully connected layer necessitates a “Flatten” layer that linearizes multidimensional inputs. The first fully connected layer, denoted as “fullc-1”, receives its input from the output of the “pooling-2” layer, transforming this node matrix into a vector. The purpose of the dense layer is to take the previously extracted features and, through nonlinear transformations in the dense layer, capture the relationships among these features, eventually mapping them onto the output space.
2.2. TS-LSTM
In real-world action detection, relying solely on the spatial flow convolution to extract human body information often falls short in accurately representing the entirety of the action features. This limitation becomes particularly evident when trying to differentiate actions that are similar in nature. To overcome this, we introduce a temporal layer network that meticulously extracts the temporal dynamics present within the motion. This is achieved by combining the features derived from both the spatial and temporal flows, providing a more comprehensive understanding of the action.
The long short-term Memory (LSTM) network, an advanced variant of the recurrent neural network, has gained traction for modeling time series data, especially in the domain of human behavior recognition [
23,
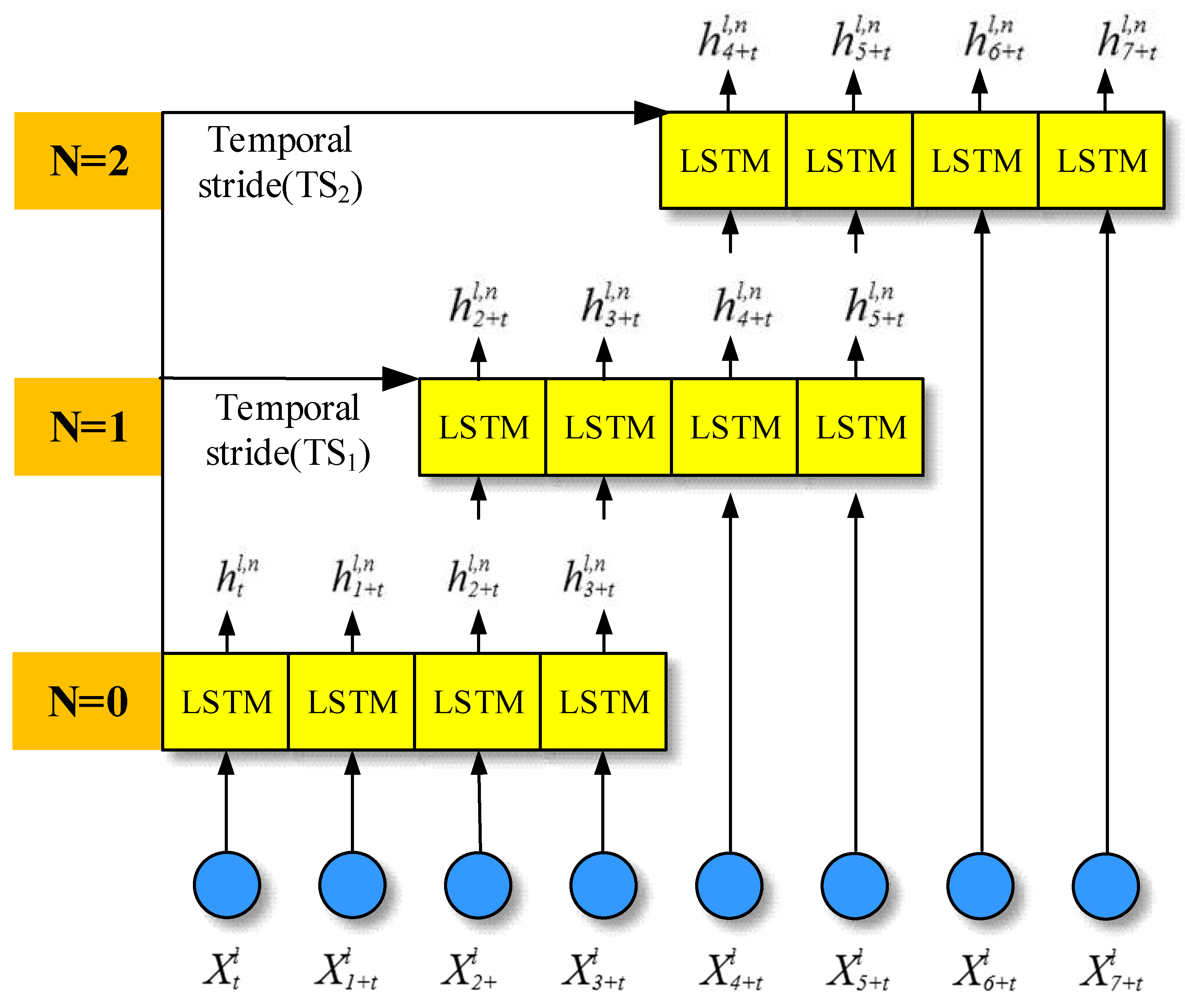
24]. Traditional LSTM networks, while effective, primarily capture global time dynamics. This overarching approach often overlooks intricate temporal nuances, sidelining potentially crucial details pivotal for precise action recognition. Recognizing this gap, our research innovates upon the conventional LSTM. We introduce an enhanced time stream sliding LSTM mechanism, complete with three cyclic modules catering to long-term, medium-term, and short-term memory. This design emphasizes capturing local joint information with heightened precision. Utilizing a sliding window mechanism, our model sequentially extracts skeletal timing data, effectively synthesizing it into the action’s attribute profile. A visual representation detailing the sliding operation process is elucidated in
Figure 2.
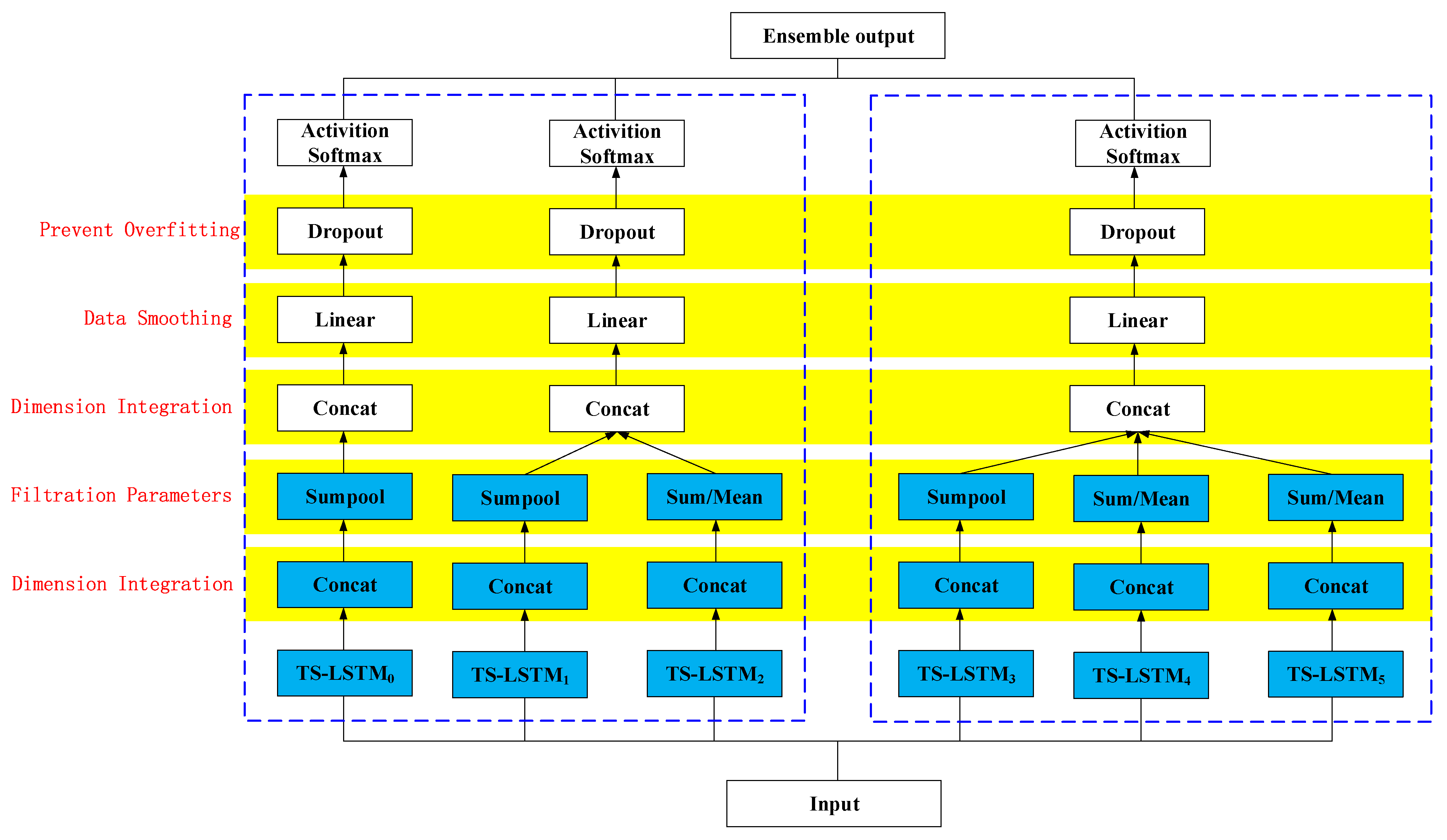
The improved TS-LSTM module is shown in
Figure 3. The model is composed of three modules in the long and short term and adds a Concat layer, Sumpool layer, Linear layer, and Dropout layer to enhance the ability of feature extraction. The function of the Concat layer is to integrate the dimensions of the output data of the TS-LSTM layer, the Sumpool layer and the Meanpool layer are used to filter irrelevant parameters to prevent the network from overfitting during training, and the Linear layer is a fully connected layer that is used to smooth the data and integrate the local features extracted by different neurons into complete human skeleton motion information. The Dropout layer is used to prevent the parameters of the previous layer from overfitting and stop the invalid part of the neurons from working. The parameters of the three cycles of the network in this paper are determined by the proportion of the number of channels and one in the TS-LSTM unit in each module. Because there is only one channel in the first module, the number of cycles is one, the period of each channel in the second module is 0.5, and the period of each channel in the third module is 0.33.
The number of LSTM is set to
Nl, its sliding window is set to
Wl, and the time step is set to
TSl. Different LSTM units form different sliding windows, and more efficient feature extraction is achieved by adjusting the size of the sliding window and the time step. Assuming that
is the output of the
lth unit layer at time
t, the output and three gates of the LSTM unit can be expressed as
In the formula,
is the input gate,
is the forgetting gate,
is the output gate,
is the activation unit,
is the output of the unit,
is the connection weight matrix of the
nth unit to the
mth unit in the
l-layer TS LSTM, and the update formula of each LSTM unit is:
Next, let the
mth time series input be
, which is expressed as
and substituted into Formulas (6)–(9). Similarly,
is expressed as
and substituted into Formula (10).
Expressions (11) and (12) represent the MeanPool value and the SumPool value of the
nth unit in the
l layer under the n time sequence, respectively. Then, it is connected in a series to obtain
The linear activation algorithm of the TS-LSTM module is given by Expressions (13)–(15).
In the formula,
w and
b represent the weight and deviation of the linear layer, respectively. After activation, the
kth action values of
,
, and
are set to
,
, and
, respectively, and finally, they are normalized.
Nc and
c represent the number of action types and the index of the corresponding class, respectively. The maximum likelihood estimation of the sample using the cross-entropy function is shown in Equation (20).
In the formula, NM−1 and represent the total number of training samples and the actual action labels, respectively. In order to highlight the interclass gap caused by the different motion amplitudes of the same action, the minimum objective function is used to train it again, and the average value of the results of the three activation functions (16)–(18) is taken in the final test.
2.3. Fusion Strategy
Cross-entropy serves as a metric to gauge the discrepancy between two probability distributions. Given a true distribution
P and a predicted distribution
Q from the model, cross-entropy is defined as
where
i refers to each potential category. In the realm of classification tasks, the genuine distribution
P is often represented in a one-hot encoded fashion, implying that the probability for a singular category is 1, while it remains 0 for others.
Considering the mean squared error (
MSE) loss function, it is defined as
where
n denotes the number of categories. In comparison with cross-entropy, when the predictive values deviate substantially from the genuine labels, the growth rate of the
MSE is relatively more gradual. Contrarily, cross-entropy penalizes misclassifications more heavily.
Delving into the dual-stream network,
and
respectively represent the predicted probabilities from the spatial and temporal streams. The objective of the fusion strategy is to identify an optimal weight
λ that amalgamates these predictions, aiming for the best comprehensive prediction
. Employing cross-entropy, the fusion loss can be articulated as
Before obtaining the final output, it is necessary to perform spatiotemporal fusion on the two-stream network. The loss function uses the cross-entropy function to obtain the probability that the current prediction sample belongs to all categories. The specific calculation method is
In the formula, and are the prediction probability vectors of the space flow and the time flow for the current input, respectively, and λ is a constant of (0–1). In order to find a more appropriate λ value, the problem is described as a simple optimal solution value problem. The particle swarm optimization algorithm is used to obtain the most suitable solution to the problem by using different λ values.
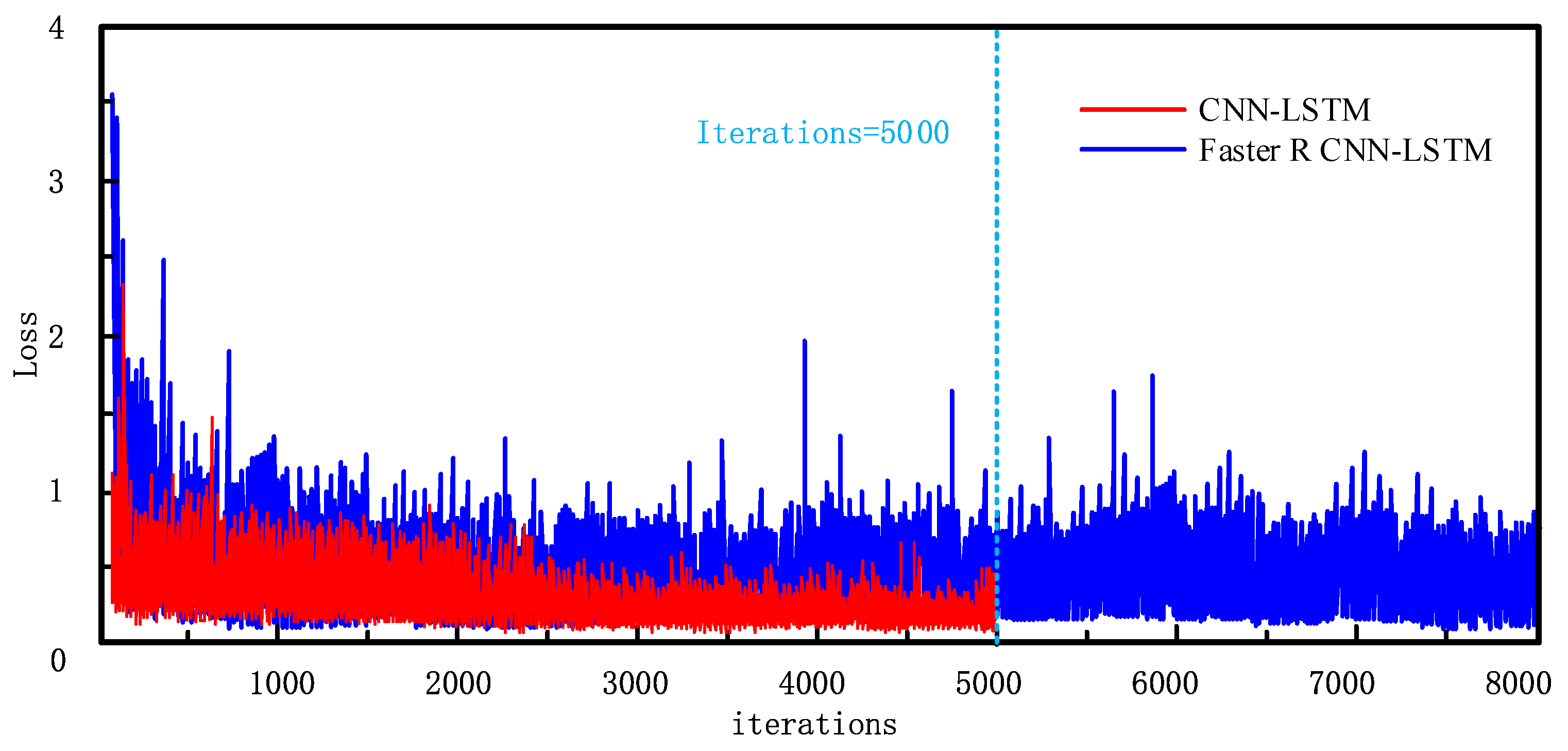
2.5. Loss Function
In complex operational scenarios, the primary objective of the loss function is to address the imbalance between positive and negative samples in the safety helmet dataset. To tackle this challenge, during the training process, samples are assigned varying weights based on their level of difficulty. Weights of simpler samples are reduced, while those of more challenging samples are increased, thereby enhancing the model’s discriminative capability.
In the formula,
L is the cross-entropy loss function,
p is the probability that the predicted sample belongs to 1, and
y is the label, such as [−1, 1]. The Focal loss function is as follows. To further address the imbalance between the positive and negative samples, the Focal loss function was employed. This loss function is an evolution of the cross-entropy loss function, incorporating modulating coefficients and balancing factors to better handle challenging samples. It is defined as follows:
Lf is the Focal loss functio, γ is the adjustment coefficient, and α is the balance factor.
The Focal loss function adds an adjustment coefficient compared to the cross-entropy loss function, which reduces the loss of a large number of simple samples by making γ > 0, so the model is more focused on the mining of difficult samples. In addition, the balance factor α is added to solve the problem of class imbalance in the dataset.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}