
Exploration of Metrics and Datasets to Assess the Fidelity of Images Generated by Generative Adversarial Networks

 , and
, and 
Abstract
:1. Introduction
- Pixel Recurrent Neural Networks (Pixel RNNs): These models are based on recurrent neural networks that generate images iteratively, considering the spatial structure and the dependencies between pixels. They generate images pixel by pixel, in a specific order, using recurring units to model dependencies [2].
- Stable Diffusion: In the imaging context, stable diffusion is used to improve the quality and consistency of the generated images. It is based on the concept of iterating a generative model through a series of diffusion steps, gradually applying noise to the generated image so that it approaches a target distribution [3].
- Generative Adversarial Networks (GANs): Consisting of a generator and a discriminator, GANs are a type of generative model. The generator transforms random noise inputs into synthetic images, while the role of the discriminator is to differentiate between these synthesized images and real ones. These components engage in adversarial training, where the generator aims to fool the discriminator with its outputs while the discriminator strives to sharpen its discrimination skills to classify real and fake images accurately [4].
2. What Is a Generative Adversarial Network?
2.1. Exploring the Process
- The generator is a differentiable function that has latent variables taken from a known prior distribution and some parameters , and outputs a sample . Denote to the parameter generator .
- The discriminator is a differentiable function that takes a sample and some parameters and calculates a value that quantifies how real or synthetic the sample is. Denote to the discriminator parameter .
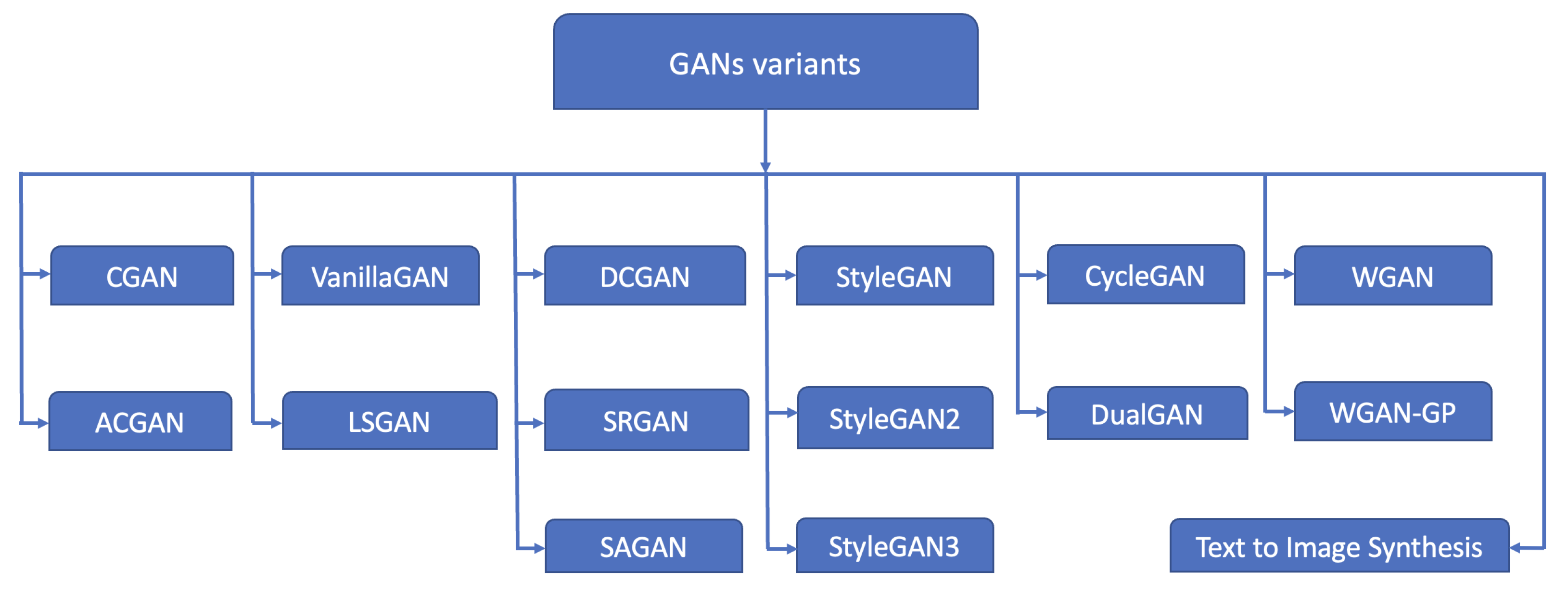
2.2. Types and Applications of Generative Adversarial Networks
2.2.1. Types of Generative Adversarial Networks
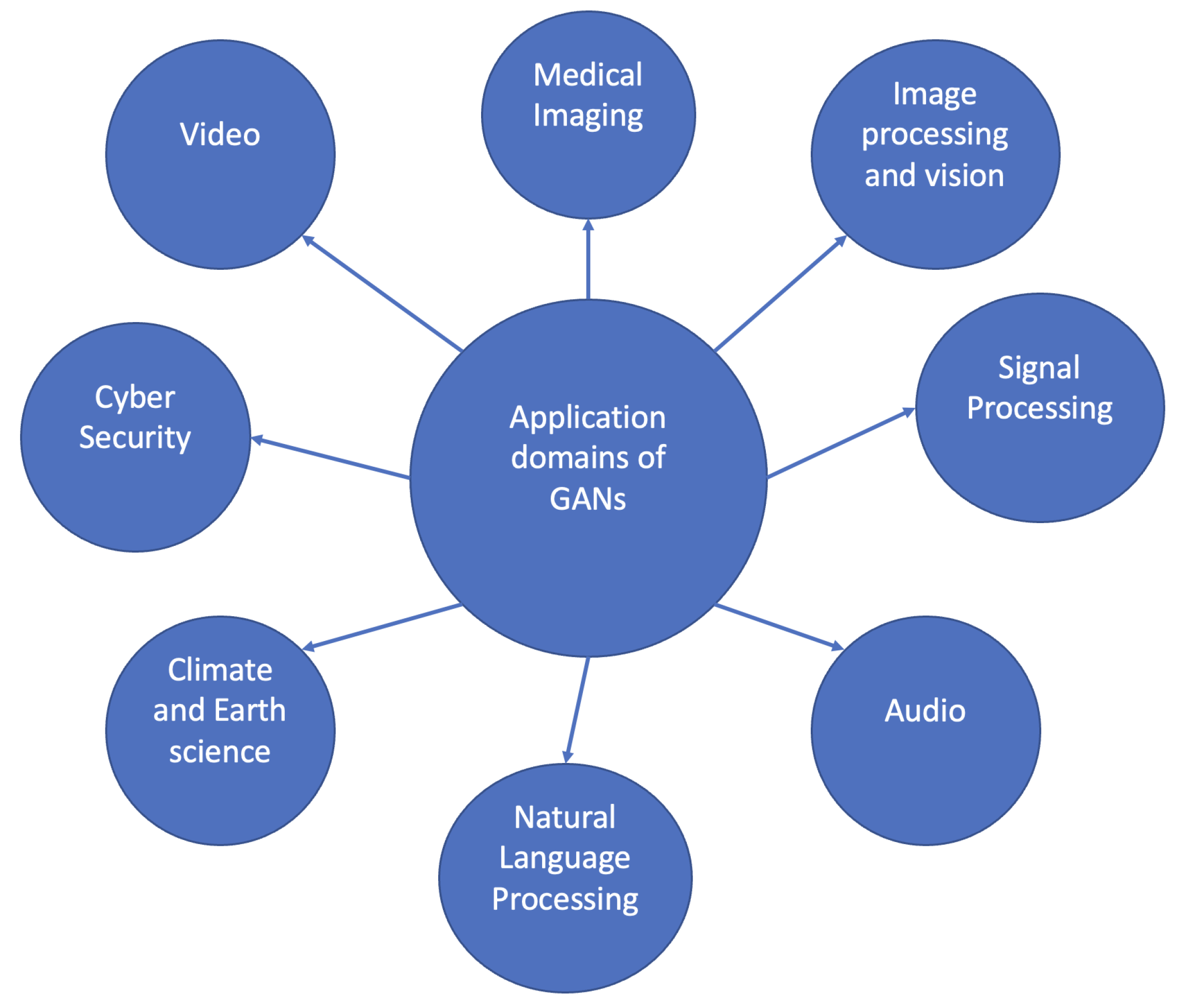
2.2.2. Applications of Generative Adversarial Networks for the Creation of Synthetic Images
2.3. Main Data Repositories Utilized
- Flickr Faces HQ (FFHQ): This collection of high-quality images featuring human faces is sourced from the photo-sharing platform Flickr. This dataset encompasses a substantial compilation of 70,000 human face images, each with a resolution of 1024 × 1024 pixels. FFHQ exhibits significant diversity in age, ethnicity, and image backgrounds, providing a rich and varied set of training data for GANs [39]. Researchers and practitioners often leverage the FFHQ dataset to train GAN models in face image generation and manipulation. Its extensive facial characteristics and high-resolution nature make it an ideal resource for training models that aim to generate realistic and diverse human face images. By utilizing datasets like FFHQ, GAN models can learn from a vast collection of human face images, capturing the nuances and complexities inherent in facial appearances. These datasets play a crucial role in advancing the capabilities of GANs and enabling their applications in various domains, including computer vision, graphics, and facial recognition systems [11]. In Ref. [40], the authors present a novel framework named AgeTransGAN for addressing facial age transformation across significant age differences, including progression and regression. The AgeTransGAN framework comprises two primary components: a generator and a conditional multitask discriminator with an embedded age classifier. The generator utilizes an encoder–decoder architecture to synthesize images, while the conditional multitask discriminator assesses the authenticity and age information of the generated images. The primary goal of AgeTransGAN is to disentangle the identity and age attributes during the training process. This disentanglement is achieved by incorporating various techniques, including cycle-generation consistency, age classification, and cross-age identity consistency. By effectively separating the identity and age characteristics, AgeTransGAN aims to enable more accurate and controllable age transformation across significant age gaps.
- CelebA: A unique dataset in face attribute analysis that encompasses a substantial collection of 200,000 celebrity images. Each image in the dataset is meticulously annotated with 40 attribute labels, making it a valuable resource for tasks related to face image generation and manipulation [43]. CelebA-HQ and CelebAMask-HQ developed as extensions of CelebA, are also extensively employed in similar applications.
- LSUN: An acronym for large-scale scene understanding, LSUN consists of an impressive assortment of approximately one million labeled images. This dataset is organized into ten distinct scene categories, including memorable scenes like bedrooms, churches, and towers. Moreover, LSUN encompasses twenty object classes, such as birds, cats, and buses. The images explicitly belonging to the church and bedroom scenes, as well as those representing cars and birds, are frequently employed in GAN inversion methods. In addition to the datasets mentioned above, several other resources are employed in GAN inversion studies. These include DeepFashion, Anime Faces, and StreetScapes. These datasets play a pivotal role in conducting comprehensive experiments to assess the efficacy of GAN inversion techniques [44].
- Flickr Diverse Faces (FDF): This comprises a vast collection of 1.47 million human faces with a resolution of 128 × 128 or higher. Each face in the dataset is accompanied by a bounding box and keypoint annotations, offering precise localization information. The dataset is designed to exhibit diversity in various aspects, including facial pose, occlusion, ethnicity, age, background, and scene type. The scenes captured in the dataset encompass a range of contexts, such as traffic, sports events, and outdoor activities. Regarding facial poses, the FDF dataset offers more diversity than the FFHQ and Celeb-A datasets, although its resolution is lower than that of the FFHQ dataset. The primary objective of the FDF dataset is to facilitate the advancement of face recognition algorithms by providing a publicly available resource that includes source code and pre-trained networks. The face images in the FDF dataset were extracted from a pool of 1.08 million images in the YFCC100-M dataset, and the annotations were generated using state-of-the-art models for accurate and reliable results [45]. The FDF dataset, with its high-quality annotations and diverse range of faces, provides a valuable resource for advancing face recognition algorithms.
2.4. Main Metrics Used
- Inception Score (IS): This measures the quality and diversity of generated images by using a pre-trained Inception-v3 classifier network to calculate the average probability distribution of classes for the generated images. The score is based on two factors: the quality of the generated images (measured using the entropy of the class distribution) and the diversity of the generated images (measured using the Kullback–Leibler divergence between the class distribution of the generated images and that of the training set). A higher IS indicates that the generated images are high quality and diverse [56].
- Fréchet Inception Distance(FID): The similarity between the feature distributions of real and generated images are quantified using a high-dimensional feature space. It uses a pre-trained Inception-v3 network to extract features from both sets of images and calculates the FID between their distributions. A lower value indicates that the generated images are more similar to the real images regarding their high-level features [47,57].
- Perceptual Image Patch Similarity (LPIPS): This is a metric that quantifies the perceptual similarity between image pairs by comparing their feature representations in a deep neural network. It calculates the distance between the feature representations of the two images at multiple layers of a pre-trained network and aggregates these distances to derive a similarity score. A lower score indicates a higher perceptual similarity between the generated and real images [58].
- Precision and Recall: These are standard measures used in machine learning to evaluate the performance of classifiers. They can also be used to evaluate the performance of GANs by comparing the generated images to real images and computing the precision and recall of the generated images for the real images [59]. An important comment concerning precision and recall is that they may not be the most appropriate metrics for evaluating the performance of GANs, as they only provide information about the ability of the models to identify positive samplings correctly and may not capture other aspects of the image quality, such as diversity, realism, and perceptual similarity.
- Structural Similarity Index (SSIM): This measures the similarity between pairs of images based on their luminance, contrast, and structural similarities. It compares the pixel values of the two images at each point in a local window, taking into account the contrast and structural similarities between the regions of the window. A higher value indicates that the developed images are more comparable to the real images regarding their structural properties [60].
- Mean Squared Error (MSE): This measures the average squared difference between the pixel values of the generated and real images. It is a simple and widely used metric but does not consider perceptual differences between the images [24].
- Kernel Inception Distance (KID): This measures the similarity between the feature distributions of the real and generated images using a kernel-based method. It calculates the squared distance between the kernel means embeddings of the two distributions, where the feature space of a pre-trained Inception-v3 network defines the kernel. A lower value indicates that the generated images are more similar to the real images regarding their high-level features [61].
2.5. Advantages and Constrains of Generative Adversarial Networks
2.5.1. Advantages
- GANs can generate visually realistic, high-quality images that resemble real images to human observers.
- Generating diverse data samplings by GANs is beneficial for training machine learning models.
- GANs exhibit relative ease of training and often achieve faster convergence than other generative models.
- GANs possess the potential to acquire knowledge from data lacking important label information, rendering them valuable for unsupervised learning endeavors.
2.5.2. Constraints
- Vanishing gradient: This problem can lead to the gradients of the generator, concerning weights in the early layers of the network, becoming so small that those layers stop learning, resulting in poor-quality image generation [80]. In addition, a well-trained discriminator network may confidently reject the generator-generated samplings due to this problem. The challenge of optimizing the generator is compounded by the fact that the discriminator does not share any information, which can damage the overall learning capacity model [81].
- Mode collapse: Mode collapse poses a critical challenge in GAN training, leading to the generator consistently producing identical outputs. This failure in GAN training is attributed to the generator exhibiting low diversity in its generated data or producing only a limited range of specific real samplings. Consequently, the utility of the learned GANs becomes restricted in numerous computer vision applications and computer graphics tasks [82].
- Shortcoming of accurate evaluation metrics: The lack of accurate evaluation metrics is a critical challenge in generative adversarial network (GAN) research. Evaluating the quality of images generated by GANs remains an active area of research, especially with regard to unstable training. Despite the demonstrated successes of GANs in a variety of applications, determining which method is superior to another in terms of evaluation remains a complex problem. Currently, there is no universally accepted standard for evaluation, and each paper introducing a new GAN proposes its own evaluation techniques. This results in a lack of agreed-upon parameters that make a fair comparison of models difficult [57,83,84]. One of the main challenges of current GAN evaluation metrics is to have a measure that assesses both diversity and visual fidelity simultaneously. Diversity implies that all modes are covered, while visual fidelity implies that the generated samples must have a high probability. Another challenge is that some measures are less practical to calculate for large sample sizes. Also, there is currently no powerful universal measure for assessing GANs, which may hinder progress in this field [83,85]. While various quantitative and qualitative metrics have been proposed to evaluate generative models, their complexity and limitations make the choice of a single metric a complicated process. This complexity is reflected in the fact that the precise evaluation of GANs remains an active and evolving research topic. Therefore, the criteria provided in this paper provide a suitable framework for evaluating and selecting appropriate metrics for the evaluation of generative models, taking into account quality, stability, global capturability, robustness, efficiency, interpretability, and relevance to the specific task [57]. Current metrics mainly focus on the comparison of feature distributions between real and GAN-generated data. In these cases, the visual quality is expected to be an indirect result of the evaluation and is not optimized or tested directly using these metrics. It is important to note that, despite the effectiveness of existing metrics in quantitatively assessing the statistical similarity between real and generated data, the assessment of visual quality remains an open challenge in the field of GANs. So far, no metric has been developed that can directly assess the perceptual quality of the generated images in an effective way [86]. Finally, it can be said that an effective evaluation metric for generative models, such as GANs, must meet several key criteria. It must be able to distinguish between models that generate high-quality samples and those that do not, as well as be robust to small perturbations in the input data. In addition, the measure must capture the overall structure of the generated samples, be sensitive to mode dropping to detect deficiencies in the generation of specific patterns and be computationally efficient for practical application. Interpretability is essential for understanding the results, and the choice of metric must be aligned with the specific task it seeks to address, ensuring its relevance in the context of the application [83,84].
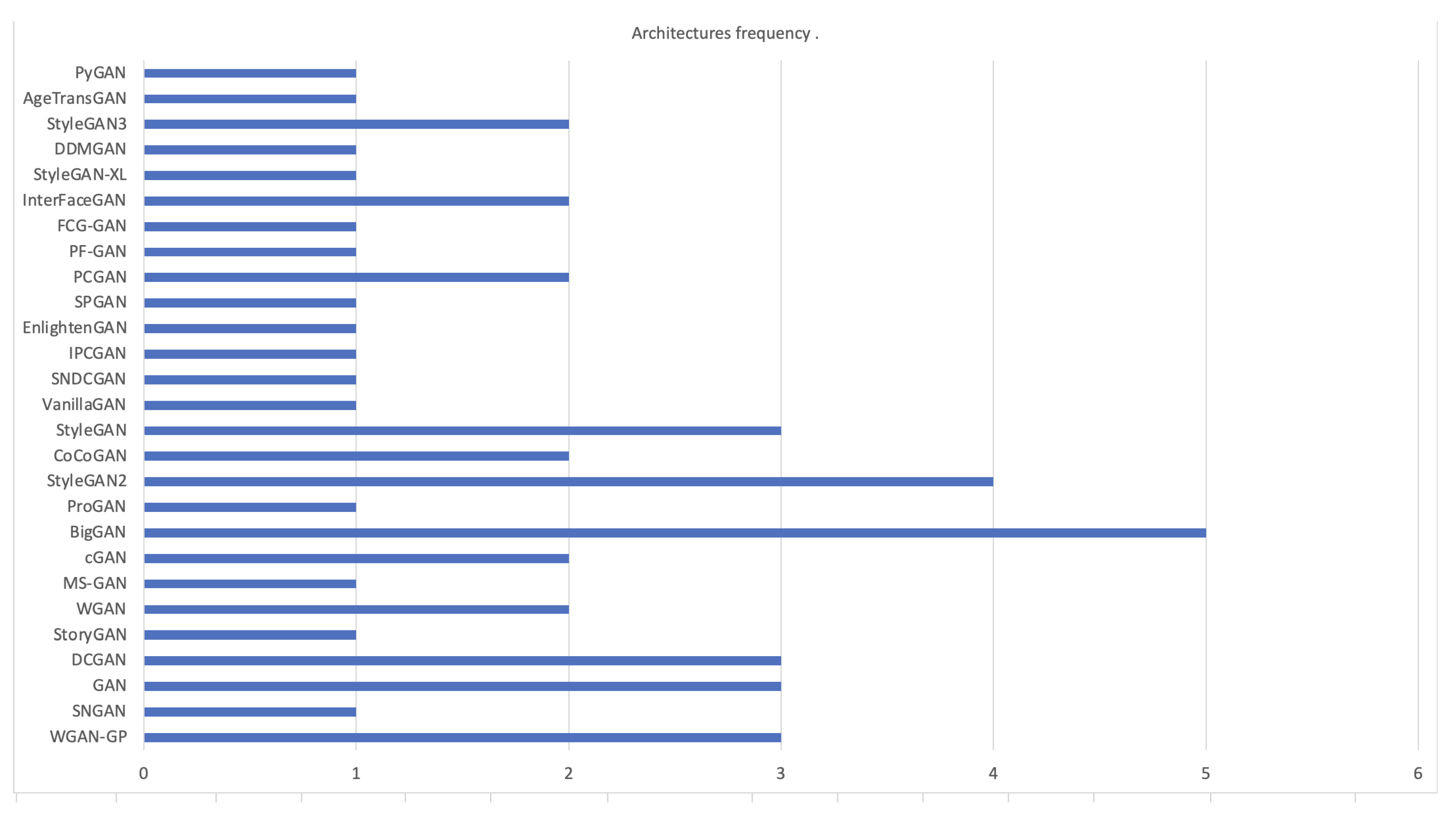
3. Advancements in Generative Adversarial Network Research
3.1. Unsupervised Generative Adversarial Networks
3.2. Semi-Supervised Generative Adversarial Networks
3.3. Supervised Generative Adversarial Networks
4. Experiments
5. Conclusions and Future Work
Future Work
- Define a way to use the most representative metrics. This is important because different metrics may have different strengths and weaknesses. It is crucial to select the appropriate metrics that can effectively capture the quality and diversity of the generated images. In addition, combining multiple metrics, such as FID, IS, and LPIPS, can provide a more comprehensive evaluation of the GAN models.
- Implement a new way to support the existing metrics with a VAE. This approach could improve the quality of synthetic images by incorporating additional information from a VAE, which can learn a better latent representation of the images and improve the diversity of the developed images.
- Define a standard dataset or the minimum features of a dataset like proper segmentation, resolution, etc. This can establish a benchmark for evaluating GAN models and enable more meaningful comparisons between different models. Having a standardized dataset with segmentation could also help to identify the strengths and weaknesses of different models in generating specific features of the images.
- Implement a framework that allows us to find the best way to evaluate synthetic images. This could involve exploring different combinations of metrics and comparing their performance on a standardized dataset. It could also include investigating the effectiveness of different preprocessing methods, such as data augmentation or normalization, in improving the quality of synthetic images.
- Defining a standard of minimum features and guidelines for creating a balanced dataset could also reduce the computational power used by GANs, which requires large amounts of data to generate synthetic data. Using a standardized dataset with balanced features, GANs may require less computational power to produce accurate results, which could reduce the costs and resources required for training and using these models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. arXiv 2014. [Google Scholar] [CrossRef]
- Van Den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1747–1756. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2017. [Google Scholar]
- Kim, C.I.; Kim, M.; Jung, S.; Hwang, E. Simplified Fréchet Distance for Generative Adversarial Nets. Sensors 2020, 20, 1548. [Google Scholar] [CrossRef]
- Fu, J.; Li, S.; Jiang, Y.; Lin, K.Y.; Qian, C.; Loy, C.C.; Wu, W.; Liu, Z. StyleGAN-Human: A Data-Centric Odyssey of Human Generation. In Computer Vision—ECCV 2022; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; pp. 1–19. [Google Scholar]
- Tian, H.; Zhu, T.; Zhou, W. Fairness and privacy preservation for facial images: GAN-based methods. Comput. Secur. 2022, 122, 102902. [Google Scholar] [CrossRef]
- Gangwar, A.; González-Castro, V.; Alegre, E.; Fidalgo, E. Triple-BigGAN: Semi-supervised generative adversarial networks for image synthesis and classification on sexual facial expression recognition. Neurocomputing 2023, 528, 200–216. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks with Limited Data. Adv. Neural Inf. Process. Syst. 2020, 33, 12104–12114. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. Adv. Neural Inf. Process. Syst. 2021, 34, 852–863. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Deng, J.; Pang, G.; Zhang, Z.; Pang, Z.; Yang, H.; Yang, G. cGAN Based Facial Expression Recognition for Human-Robot Interaction. IEEE Access 2019, 7, 9848–9859. [Google Scholar] [CrossRef]
- Zhao, Z.; Singh, S.; Lee, H.; Zhang, Z.; Odena, A.; Zhang, H. Improved Consistency Regularization for GANs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; pp. 11033–11041. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhou, R.; Jiang, C.; Xu, Q. A survey on generative adversarial network-based text-to-image synthesis. Neurocomputing 2021, 451, 316–336. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, G.; Lio, P. How can we make GAN perform better in single medical image super-resolution? A lesion focused multi-scale approach. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1669–1673. [Google Scholar]
- Gong, Y.; Liao, P.; Zhang, X.; Zhang, L.; Chen, G.; Zhu, K.; Tan, X.; Lv, Z. Enlighten-GAN for Super Resolution Reconstruction in Mid-Resolution Remote Sensing Images. Remote. Sens. 2021, 13, 1104. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 8–11 August 2017; pp. 2642–2651. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein GANs. arXiv 2017. [Google Scholar] [CrossRef]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- You, S.; Lei, B.; Wang, S.; Chui, C.K.; Cheung, A.C.; Liu, Y.; Gan, M.; Wu, G.; Shen, Y. Fine Perceptive GANs for Brain MR Image Super-Resolution in Wavelet Domain. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Kazeminia, S.; Baur, C.; Kuijper, A.; van Ginneken, B.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for medical image analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef] [PubMed]
- Lata, K.; Dave, M.; Nishanth, K.N. Image-to-Image Translation Using Generative Adversarial Network. In Proceedings of the 2019 3rd International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 12–14 June 2019. [Google Scholar]
- Skandarani, Y.; Jodoin, P.M.; Lalande, A. GANs for Medical Image Synthesis: An Empirical Study. J. Imaging 2023, 9, 69. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Wang, N.; Feng, F.; Zhang, G.; Wang, X. Exploring Global and Local Linguistic Representations for Text-to-Image Synthesis. IEEE Trans. Multimed. 2020, 22, 3075–3087. [Google Scholar] [CrossRef]
- Vougioukas, K.; Petridis, S.; Pantic, M. End-to-End Speech-Driven Facial Animation with Temporal GANs. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Saidia Fascí, L.; Fisichella, M.; Lax, G.; Qian, C. Disarming visualization-based approaches in malware detection systems. Comput. Secur. 2023, 126, 103062. [Google Scholar] [CrossRef]
- Perera, A.; Khayatian, F.; Eggimann, S.; Orehounig, K.; Halgamuge, S. Quantifying the climate and human-system-driven uncertainties in energy planning by using GANs. Appl. Energy 2022, 328, 120169. [Google Scholar] [CrossRef]
- Min, J.; Liu, Z.; Wang, L.; Li, D.; Zhang, M.; Huang, Y. Music Generation System for Adversarial Training Based on Deep Learning. Processes 2022, 10, 2515. [Google Scholar] [CrossRef]
- Sisman, B.; Vijayan, K.; Dong, M.; Li, H. SINGAN: Singing Voice Conversion with Generative Adversarial Networks. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019. [Google Scholar]
- Wen, S.; Liu, W.; Yang, Y.; Huang, T.; Zeng, Z. Generating Realistic Videos From Keyframes With Concatenated GANs. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2337–2348. [Google Scholar] [CrossRef]
- Lucas, A.; López-Tapia, S.; Molina, R.; Katsaggelos, A.K. Generative Adversarial Networks and Perceptual Losses for Video Super-Resolution. IEEE Trans. Image Process. 2019, 28, 3312–3327. [Google Scholar] [CrossRef]
- NvVLabs. GitHub–NVlabs/ffhq-dataset: Flickr-Faces-HQ Dataset (FFHQ). In FFHQ-Dataset; 2018; Available online: https://github.com/NVlabs/ffhq-dataset (accessed on 24 June 2023).
- Hsu, G.S.; Xie, R.C.; Chen, Z.T.; Lin, Y.H. AgeTransGAN for Facial Age Transformation with Rectified Performance Metrics. In Computer Vision—ECCV 2022; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2022; Volume 13672, pp. 580–595. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Hukkelås, H.; Mester, R.; Lindseth, F. DeepPrivacy: A Generative Adversarial Network for Face Anonymization. In ISVC 2019; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2019; pp. 565–578. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are GANs Created Equal? A Large-Scale Study. arXiv 2018. [Google Scholar] [CrossRef]
- Shmelkov, K.; Schmid, C.; Alahari, K. How Good Is My GAN? In ECCV2018; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2018; pp. 218–234. [Google Scholar]
- Kurach, K.; Lučić, M.; Zhai, X.; Michalski, M.; Gelly, S. A Large-Scale Study on Regularization and Normalization in GANs. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3581–3590. [Google Scholar]
- Matchev, K.; Roman, A.; Shyamsundar, P. Uncertainties associated with GAN-generated datasets in high energy physics. SciPost Phys. 2022, 12, 104. [Google Scholar] [CrossRef]
- Varkarakis, V.; Bazrafkan, S.; Corcoran, P. Re-Training StyleGAN-A First Step towards Building Large, Scalable Synthetic Facial Datasets. In Proceedings of the 2020 31st Irish Signals and Systems Conference, ISSC 2020, Letterkenny, Ireland, 11–12 June 2020. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A dataset for recognising faces across pose and age. In Proceedings of the 13th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2018, Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Bansal, A.; Nanduri, A.; Castillo, C.D.; Ranjan, R.; Chellappa, R. UMDFaces: An annotated face dataset for training deep networks. In Proceedings of the IEEE International Joint Conference on Biometrics, IJCB 2017, Denver, CO, USA, 1–4 October 2017; pp. 464–473. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-PIE. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2008, Amsterdam, The Netherlands, 17–19 September 2008. [Google Scholar]
- Chen, B.C.; Chen, C.S.; Hsu, W.H. Cross-age reference coding for age-invariant face recognition and retrieval. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014; Volume 8694, pp. 768–783. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Obukhov, A.; Krasnyanskiy, M. Quality Assessment Method for GAN Based on Modified Metrics Inception Score and Fréchet Inception Distance. Adv. Intell. Syst. Comput. 2020, 1294, 102–114. [Google Scholar]
- Borji, A. Pros and cons of GAN evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sajjadi, M.S.M.; Mario, B.; Google, L.; Olivier, B.; Sylvain, B.; Brain, G.G. Assessing Generative Models via Precision and Recall. arXiv 2018. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Binkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying MMD GANs. arXiv 2018. [Google Scholar] [CrossRef]
- Naeem, M.F.; Oh, S.J.; Uh, Y.; Choi, Y.; Yoo, J. Reliable Fidelity and Diversity Metrics for Generative Models. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7176–7185. [Google Scholar]
- Yates, M.; Hart, G.; Houghton, R.; Torres, M.T.; Pound, M. Evaluation of synthetic aerial imagery using unconditional generative adversarial networks. ISPRS J. Photogramm. Remote. Sens. 2022, 190, 231–251. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Smola, A.; Schölkopf, B.; GRETTON, A.S. A Kernel Two-Sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. arXiv. 2017. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved Techniques for Training GANs. arXiv 2016. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Nair, V.; Hinton, G. The CIFAR-10 Dataset. 2014. Available online: http://www.cs.Toronto.edu/kriz/cifar.html (accessed on 24 June 2023).
- Li, H.; Li, B.; Tan, S.; Huang, J. Identification of deep network generated images using disparities in color components. Signal Process. 2020, 174, 107616. [Google Scholar] [CrossRef]
- Tang, S. Lessons Learned from the Training of GANs on Artificial Datasets. IEEE Access 2020, 8, 165044–165055. [Google Scholar] [CrossRef]
- Pasquini, C.; Laiti, F.; Lobba, D.; Ambrosi, G.; Boato, G.; Natale, F.D. Identifying Synthetic Faces through GAN Inversion and Biometric Traits Analysis. Appl. Sci. 2023, 13, 816. [Google Scholar] [CrossRef]
- Wu, C.; Li, H. Conditional Transferring Features: Scaling GANs to Thousands of Classes with 30% Less High-Quality Data for Training. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Bermano, A.; Gal, R.; Alaluf, Y.; Mokady, R.; Nitzan, Y.; Tov, O.; Patashnik, O.; Cohen-Or, D. State-of-the-Art in the Architecture, Methods and Applications of StyleGAN. Comput. Graph. Forum 2022, 41, 591–611. [Google Scholar] [CrossRef]
- Yazıcı, Y.; Foo, C.S.; Winkler, S.; Yap, K.H.; Piliouras, G.; Chandrasekhar, V. The Unusual Effectiveness of Averaging in GAN Training. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Karim, A.A.; Saleh, S.M. Face Image Animation with Adversarial Learning and Motion Transfer. Int. J. Interact. Mob. Technol. (iJIM) 2022, 16, 109–121. [Google Scholar] [CrossRef]
- Dhirani, L.L.; Mukhtiar, N.; Chowdhry, B.S.; Newe, T. Ethical Dilemmas and Privacy Issues in Emerging Technologies: A Review. Sensors 2023, 23, 1151. [Google Scholar] [CrossRef]
- Voigt, P. The EU General Data Protection Regulation (GDPR): A Practical Guide (Article 32). GDPR 2018, 10, 10–5555. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Kora Venu, S.; Ravula, S. Evaluation of Deep Convolutional Generative Adversarial Networks for Data Augmentation of Chest X-ray Images. Future Internet 2021, 13, 8. [Google Scholar] [CrossRef]
- Feng, Q.; Guo, C.; Benitez-Quiroz, F.; Martinez, A.M. When do gans replicate? On the choice of dataset size. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6701–6710. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Fei, H.; Tan, F. Bidirectional Grid Long Short-Term Memory (BiGridLSTM): A Method to Address Context-Sensitivity and Vanishing Gradient. Algorithms 2018, 11, 172. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, M.; Yu, J. On the Convergence and Mode Collapse of GAN. In Proceedings of the SIGGRAPH Asia 2018 Technical Briefs, New York, NY, USA, 4–7 December 2018. [Google Scholar]
- Grnarova, P.; Levy, K.Y.; Lucchi, A.; Perraudin, N.; Goodfellow, I.; Hofmann, T.; Krause, A. A Domain Agnostic Measure for Monitoring and Evaluating GANs. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Xu, Q.; Huang, G.; Yuan, Y.; Guo, C.; Sun, Y.; Wu, F.; Weinberger, K. An empirical study on evaluation metrics of generative adversarial networks. arXiv 2018, arXiv:1806.07755. [Google Scholar]
- Alfarra, M.; Pérez, J.C.; Frühstück, A.; Torr, P.H.S.; Wonka, P.; Ghanem, B. On the Robustness of Quality Measures for GANs. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; pp. 18–33. [Google Scholar]
- Alaluf, Y.; Patashnik, O.; Cohen-Or, D. ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6711–6720. [Google Scholar]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised Deep Feature Learning for Aerial Scene Classification. IEEE Trans. Geosci. Remote. Sensing 2020, 58, 519–531. [Google Scholar] [CrossRef]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. ArtGAN: Artwork synthesis with conditional categorical GANs. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Sauer, A.; Schwarz, K.; Geiger, A. Stylegan-xl: Scaling StyleGAN to large diverse datasets. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Pranoto, H.; Heryadi, Y.; Warnars, H.L.H.S.; Budiharto, W. Enhanced IPCGAN-Alexnet model for new face image generating on age target. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 7236–7246. [Google Scholar] [CrossRef]
- Shen, Y.; Yang, C.; Tang, X.; Zhou, B. InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2004–2018. [Google Scholar] [CrossRef]
- Zuo, Z.; Zhao, L.; Li, A.; Wang, Z.; Chen, H.; Xing, W.; Lu, D. Dual distribution matching GAN. Neurocomputing 2022, 478, 37–48. [Google Scholar] [CrossRef]
- Son, C.H.; Jeong, D.H. Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component-Guided Adversarial Learning. Sensors 2022, 22, 5359. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Gan, Z.; Shen, Y.; Liu, J.; Cheng, Y.; Wu, Y.; Carin, L.; Carlson, D.; Gao, J. Storygan: A sequential conditional gan for story visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6329–6338. [Google Scholar]
- Zhang, M.; Ling, Q. Supervised Pixel-Wise GAN for Face Super-Resolution. IEEE Trans. Multimed. 2021, 23, 1938–1950. [Google Scholar] [CrossRef]
- Yao, X.; Newson, A.; Gousseau, Y.; Hellier, P. A Style-Based GAN Encoder for High Fidelity Reconstruction of Images and Videos. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 581–597. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset—Ref. | Number of Images | Res. (px) | Format | Classes |
|---|---|---|---|---|
| CelebA [43] | 202,599 | 178 × 218 | JPG | There are no categorical labels, but there are 40 binary attributes describing facial features. |
| FFHQ [9] | 70,000 | 1024 × 1024 | PNG | There are no categorical labels, but there are 10 continuous attributes describing facial features, such as age, gender, pose, expression, and others. |
| LSUN [44] | 10,000,000 | VR | JPG | There are several categories, including bedrooms, churches, kitchens, living rooms, and buildings. |
| VGGFace2 [51] | 3,321,053 | VR | JPG | There are over 8000 famous and non-famous people classes. |
| UMDFaces [52] | 367,888 | VR | JPG | There are several categories, including age, gender, race, and emotions. |
| Multi-PIE [53] | 750,000 | 640 × 490 | BMP | There are several categories, including lighting, poses, and facial expressions. |
| CACD [54] | 163,446 | VR | JPG | Age of people in the images. |
| CASI-WebFace [55] | 494,414 | VR | JPG | There are over 10,000 classes of famous and non-famous people. |
| LFW [50] | 13,233 | VR | JPG | There are over 5000 classes of famous and non-famous people. |
| Datasets | Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| References | Architecture | CIFAR-10 | CelebA | FFHQ | FID | IS | SSIM | PSNR |
| [8,14,68,69] | BigGAN | ✓ 1 | ✓ | ✓ | ✓ | ✓ | ||
| [50,63,68,70] | StyleGAN2 | ✓ | ✓ | ✓ | ✓ | |||
| [6,71,72] | StyleGAN | ✓ | ✓ | ✓ | ✓ | |||
| [48,68] | DCGAN | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| [56,73,74] | GAN | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| [17,47,69] | WGAN-GP | ✓ | ✓ | ✓ | ✓ | ✓ |
| Ref. | Architecture | Datasets | Metrics |
|---|---|---|---|
| [73] | GAN | ImageNet, CIFAR 10, STL 10 | FID, IS, MA, EMA |
| [47] | WGAN-GP | CIFAR 10, CIFAR 100, ImageNet, MNIST | FID, IS, GAN-Train, GAN-Test |
| [48] | DCGAN | CIFAR 10, CelebA-HQ, LSUN Bedroom | FID, IS, KID, MS-SSIM |
| [95] | StoryGAN | CIFAR 10, CelebA-HQ, LSUN Bedroom | MS-SSIM |
| [17] | WGAN, WPGAN, MSGAN | BraTS | SSIM, PSNR |
| [56] | GAN | MNIST, HAR, EST | FID, IS |
| [13] | WGAN, cGAN | AffectNet, RAF-DB | W-DISTANCE |
| [69] | WGAN-GP, BigGAN | CIFAR 10 | FID, IS, W-DISTANCE |
| [68] | DCGAN, WGAN, ProGAN, StyleGAN2, BigGAN, CoCoGAN | FFHQ, CelebA, LSUN | RGB, HSV, YCbCr |
| [50] | StyleGAN2 | CelebA, CASIA WebFace | FID, IS |
| [71] | StyleGAN | CIFAR 10, STL 10, ImageNet, CASIA HWDB1.0 | FID, IS |
| [14] | VanillaGAN, SNDCGAN, BigGAN | CIFAR 10 | FID |
| [18] | Enlighten-GAN | Sentinel-2 | GSM, PI, PSNR, LPIPS |
| [96] | SPGAN | VGGFace2, CelebA, Helen, LFW, CFP-FP, AgeDB-30 | FID, PSNR, SSIM |
| [63] | PCGAN, StyleGAN2, CoCoGAN | Inria Aerial | FID, KID |
| [7] | PF-GAN | Celeb-HD | Similarity Score |
| [74] | GAN | VoxCeleb | PSNR, SSIM |
| [6] | StyleGAN | SHHQ | FID |
| [94] | FCG-GAN | CelebA | PSNR, SSIM |
| [90] | StyleGAN-XL | FFHQ, Pokemon | FID, IS |
| [93] | DDM-GAN | MNIST | FID, KL-divergence |
| [97] | StyleGAN3 | CelebA-HQ | FID, LPIPS, SSIM, PSNR, MSE |
| [70] | StyleGAN2 | CelebA, LFW, FFHQ, Caltech | LPIPS, MSE |
| [8] | Triple-BigGAN, BIG | SEA Faces | LPIPS, MSE |
| [72] | StyleGAN | FFHQ | FID, IS, LPIPS, MS-SSIM |
| [49] | InterFaceGAN | CelebA | KL-divergence |
| [92] | PCGAN, InterFaceGAN | CelebA-HD | ACRD, ACSD, SBC |
| [40] | AgeTransGAN | FFHQ-Aging | FID |
| Segment | Size | Average FID ↓ 2 | Min FID | ±% FID |
|---|---|---|---|---|
| 0–2 | 2492 | 27.64 | 14.81 | 0 |
| 70+ | 1812 | 22.30 | 15.47 | 19.32 |
| 10–14 | 2235 | 19.94 | 16.09 | 10.61 |
| 3–6 | 4523 | 18.85 | 13.00 | 5.46 |
| 7–9 | 2858 | 18.30 | 14.51 | 2.90 |
| 15–19 | 4022 | 13.51 | 11.89 | 26.18 |
| 50–69 | 7726 | 9.62 | 6.83 | 28.79 |
| 40–49 | 9678 | 8.58 | 7.02 | 10.80 |
| 20–29 | 19,511 | 8.13 | 6.56 | 5.25 |
| 30–39 | 15,143 | 7.73 | 6.35 | 4.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valdebenito Maturana, C.N.; Sandoval Orozco, A.L.; García Villalba, L.J. Exploration of Metrics and Datasets to Assess the Fidelity of Images Generated by Generative Adversarial Networks. Appl. Sci. 2023, 13, 10637. https://doi.org/10.3390/app131910637
Valdebenito Maturana CN, Sandoval Orozco AL, García Villalba LJ. Exploration of Metrics and Datasets to Assess the Fidelity of Images Generated by Generative Adversarial Networks. Applied Sciences. 2023; 13(19):10637. https://doi.org/10.3390/app131910637
Chicago/Turabian StyleValdebenito Maturana, Claudio Navar, Ana Lucila Sandoval Orozco, and Luis Javier García Villalba. 2023. "Exploration of Metrics and Datasets to Assess the Fidelity of Images Generated by Generative Adversarial Networks" Applied Sciences 13, no. 19: 10637. https://doi.org/10.3390/app131910637
APA StyleValdebenito Maturana, C. N., Sandoval Orozco, A. L., & García Villalba, L. J. (2023). Exploration of Metrics and Datasets to Assess the Fidelity of Images Generated by Generative Adversarial Networks. Applied Sciences, 13(19), 10637. https://doi.org/10.3390/app131910637