1. Introduction
Cultural heritage (CH) is a subfield of digital humanities that encompasses a wide range of different aspects related to the study and preservation of previously conducted human activities and various societal attributes from previous generations. Of course, these aspects have traditionally included tangible elements (both movable or immovable), such as artwork, legacy artefacts, monuments, museums, groups of buildings, or archaeological sites, with a broad range of values from a symbolic, historic, and artistic points of view, that is, a long-established interpretation of heritage usually having significant scientific interest (ethnological, anthropological, architectural…) and a close relationship to social traits, beliefs, and behaviors. But, additionally, a more recent approach to CH is paying a growing attention to intangible features of this inherited patrimony that have been presented in a variety of forms throughout their long history of civilization [
1,
2], extending the mentioned ones with music, values, traditions, oral history, religious ceremonies, storytelling, or even the more mundane aspects of human life, such as cuisine or clothing, reflecting a shift from a conservation-oriented viewpoint to a value-oriented one.
This systemic perspective that nowadays rules the study of CH depicts both tangible and intangible worthy-of-preservation components as inextricably bound [
3], a multidimensional and transversal cross-disciplinary expression of the pillars that explain both the external attributes and the idiosyncrasy of current societies. Together, they conform a shared bound between individuals and communities, between our present and our past, a complex framework that sustains and shapes our thinking and identity as members of a homogeneous local neighborhood or a universal nation. That is, CH is usually a key element in the identity formation of citizens [
4].
Another peculiarity of the modern interpretation of CH lies in its live characterization, a changing definition under permanent construction that constantly evolves according to the society values, almost ever expanding in recent times. In any case, whether these CH manifestations are places, objects, traditions, or daily life reflections, there is intensified interdisciplinary research activity that pursues both understanding and preserving such symbols of our ancestors’ way of life, safeguarding such inheritance for future generations regardless where they live. As a result, it has become critical to ensure that, in addition to the heritage originals, the digital material of this heritage is preserved, accessible, and comprehensible over time.
Technological advancements and the CH domain have always had a very contentious relationship, which incorporates the application of information and communication technologies (ICT) in CH, which can certainly become a burden and challenge during users’ cultural experiences [
5,
6]. The strategic integration of CH and ICTs is not a new concept; for many years, the technology and tourism industries and cultural heritage organizations have collaborated closely to adapt to these developments [
4,
7,
8]. CH institutions can use digital and communication platforms to improve their collection management and offer visitors an exciting experience that extends beyond their physical boundaries [
9,
10]. Currently, we have more opportunities than ever to allow people to participate in CH activities and become content producers, with many exciting engagement opportunities in digital heritage communities thanks to advanced technologies, applications, and services that can potentially bridge the existing gap between citizens and culture [
11,
12,
13].
Galleries, libraries, archives, and museums (GLAMs) are among the many organizations that have developed major efforts in the processes of digital transformation in recent years, but it is uncommon that they have the resources to properly characterize their digital collection assets, which results in metadata that are typically restricted by the vocabulary, taxonomies, and perspective managed by the specific institution [
14]. The limited annotations and the semantic gap that exists between experts and the public will have a negative impact on the CH institution, affecting its visibility and long-term relevance as well as providing a poor user experience on their platforms [
15]. The European Union, the American Library Association, and UNESCO [
16] have been urged to take advantage of such advances in ICT and launch digitalization projects along with digital collections in order to encourage people to actively engage with CH content [
17,
18]. However, their major shortcoming is a lack of well-defined and rich annotations for most of the large number of items they comprehend. This type of issue has a significant impact on the accessibility and discoverability of available digital content and limits the usability of these resources in new and interesting ways, hence limiting the user experience.
Metadata quality improvement and enhancement are crucial factors in the CH domain, where the inventory of items that must be described or transcribed is generally too large to be addressed through normal procedures due to the significant time, effort, and resources required [
19]. Since it is quite rare for GLAMs and other CH organizations to have the capacity to adequately identify, describe, or enhance digital collection items, they have turned to investigate the potential of crowdsourcing, as the digitization of their artworks is critical for their appropriate promotion on the Internet [
20,
21]. All around the globe, exploring the potential of crowdsourcing in the CH domain is a growing trend, with CH institutions starting to share metadata descriptions that need to be enhanced, corrected, or annotated, and soliciting public assistance to help improve them [
22,
23]. More and more, these organizations encourage people to enrich artworks and cultural assets contributing their knowledge and expertise to help improve their descriptions [
24], providing annotations voluntarily to complete existing characterizations of paintings, statues, buildings, or even the more intangible aspects of heritage mentioned above, just from pictures or available descriptions of the items from the organization collections or archives [
25].
Of course, this approach falls squarely into the open debate in the literature about the advantages and disadvantages of collaborative efforts of interested users (social tags) compared to taxonomies developed by field experts (controlled vocabularies). Even though a large number of research works have been published in recent years [
26,
27,
28,
29], it is possible to identify complementary strengths in each technique, and there are no conclusive conclusions about the superiority of a particular approach, the most adequate option being largely dependent on the application scenery, the available resources, and the evaluation criteria. In any case, the research presented in this paper is not affected by this open debate. We are not faced with the dilemma between social tags and controlled vocabularies when implementing a given system. This work is focused on scenery where human resources are certainly scarce, and it is aimed at developing technological tools to improve the effectiveness of the open collaborative effort approaches.
While crowdsourcing systems face the challenge of reaching and utilizing an adequate number of available individuals, it is ultimately up to individual persons to discover assets that best match their interests or preferences, even though there is no monetary compensation for participation (the final result should be sufficiently rewarding for these kinds of volunteers). Research about motivating contributors across different types of crowdsourcing systems emphasizes the importance of intrinsic motivation, which occurs when contributors choose tasks that are inherently interesting or enjoyable rather than only extrinsic factors, such as payment [
30,
31,
32]. This is to mean that the preference of people for concrete tasks is not solely determined by rewarding incentives set by the task requester. Instead, they rely heavily on the relationship of the characteristics of the task to the personal interests of the contributor. Therefore, CH crowdsourcing projects should pay more attention to targeting those people who might be especially interested in some types of assets, and they should be more concerned with engaging enthusiasts who can provide their contributions through the use of modern technologies. However, the main issue with most crowdsourcing initiatives is that items on CH platforms are assigned and displayed to all users at random without any distinctions or specific personalization, which frequently implies assigning users to annotation tasks that are far from their preferences and with their subsequent lack of interest.
In this sense, the primary goal of the research presented in this paper is to assist interested contributors to find the best matching assets of CH platforms to annotate based on their personal interests as well as to help CH institutions make efficient use of the crowd to achieve higher quality annotations. The objective is to define and implement analysis strategies to identify such appealing assets for every contributor, discharging them from the arduous task of browsing the whole catalogue of the platform searching for the items most appropriate according to their knowhow or preferences. The premise of this research is that this quick access to the most motivating elements to contribute will improve the engagement of the crowd and the quality and amount of their contributions. To implement the results of this research line, an image annotation recommendation system for platform users has been developed, which was built leveraging technologies based on the semantic web, ontologies, word embeddings, and machine learning. In this context, we developed a model that classifies images on crowdsourcing CH platforms based on user features and recommends images to the user for annotation.
As it is usually difficult to build accurate user profiles in these kinds of systems used sporadically, the approach of the work is to leverage the unstructured data stored in the social network of the contributors (with their agreement). These data, together with the textual data describing the CH platform assets, will be extended with tools and techniques of the Semantic Web field (using linked open data ontologies to discover more relevant features in them) and later processed with machine learning techniques and algorithms to achieve a structured representation and identify the most appropriate assets for each contributor. Obtaining structured data from the preceding methods was required to contribute to the development and evaluation of a classifier-based recommendation system that assists users in finding images that match their preferences and/or interests according to the features obtained or inferred for both of them. As described later, the system was tested and evaluated using three cutting-edge classifiers, including random forest, neural networks, and support vector machines. The restriction to image annotations is purely an implementation simplification to easily reach an appealing user interface to optimize user motivation. As the core of the algorithms are based in text descriptions accompanying the images (later semantically extended), simple descriptive characterizations of the CH items could also be offered to users.
The rest of this paper is organized as follows. In
Section 2, we present the related work regarding CH crowdsourcing initiatives.
Section 3 details the materials and methods we exploit in the developed crowdsourcing recommendation system. Next,
Section 4 delves into the components of the recommendation model as well as the processes involved. Experimental results for the classification methods and a discussion are represented in
Section 5. Finally, in
Section 6, we provide a conclusion along with plans for further research work.
2. Related Work
There are plenty of works in the literature describing the overwhelming use of technology in heritage study and preservation in any aspect the reader can imagine [
33,
34], and these technical advances have incorporated in more recent times a growing number of ICT technologies [
35,
36,
37,
38], including the ones used in this work, that is, system recommenders [
39] making extensive use of semantic approaches (LOD) [
40,
41] and machine learning [
42,
43]. However, much less effort has been dedicated to crowdsourcing initiatives in the field of CH [
44,
45].
When developing crowdsourcing initiatives in the field of cultural heritage, it is not only important to fully understand the feasible contribution of humans in computation tasks but also the conveniences and disadvantages of software and tools adopted for the facilitation of this process and, increasingly importantly, the motivation of each specific individual. In 2005, The
Steve Museum project was one of the first projects launched to explore the crowdsourcing concept and encourage the public to contribute tags to some UK and US museum collections [
46]. Tagging has been shown to provide a quite different vocabulary compared to museum official descriptions, with 86% of tags submitted not found in the museum documentation [
47]. This was a proof-of-concept project with limited user functions and no support for linking to semantic vocabularies. However, in 2008 the Australian Newspapers Digitization Program can be considered the earliest large-scale initiative developed in this field to date, a project requiring the general public to review and correct a rather poor optical character recognition (OCR) text of millions of articles extracted from their database of historical newspapers. During the life of this successful project, more than 166 million text lines from newspaper articles were reviewed, corrected, or enhanced by volunteers working for the project [
48]. In 2009, the
Waisda? video labeling game was also released as a popular platform that used gaming to annotate television heritage [
49], awarding points to players when their tags match some other one that their adversaries had already submitted within a certain time frame.
Waisda? gameplay put a focus on responsiveness and accuracy, implicitly assuming that tags are genuine if there is widespread agreement among players; but still, the community itself acts as the filter, with no technological or interaction support to correct or improve the information quality. Furthermore, the European Union recently launched the
CrowdHeritage platform, an online crowdsourcing platform for enriching the metadata of digitized cultural heritage material available on the
Europeana portal [
50]. The website of this project allows users to leave comments on selected cultural archives or authenticate existing ones in the same basic way that people browse all existing catalogues with no customization provided. In 2014, some Swiss Heritage institutions were deeply studied in a complete survey to examine to what extent crowdsourcing and open data practices were present in their initiatives and routines [
51], concluding that crowdsourcing and open data policies had been considered by very few institutions. However, there were some indications that several institutions might use these innovations in the near future, as the majority of the surveyed institutions deemed them important, considering that their opportunities overcome the identified risks.
Regarding the Egyptian heritage, which is the testing scenery of this research, no documented crowdsourcing initiative was found in the literature. However, some Egyptian community-based initiatives have emerged with the goal of raising awareness about the ongoing loss of heritage, addressing acts of heritage damage, and seeking community support. The proliferation of social media facilitates information distribution among initiatives that are typically focused on a single topic by sharing images and links to articles to highlight changes that have a negative impact on significant buildings.
According to the literature, many CH institutions started to explore the potential of involving public users in the description, classification, and transcription of their metadata in order to build and enrich their digital cultural heritage [
44]. Furthermore, a number of projects have demonstrated that crowdsourcing can create meaningful experiences through their collections while also encouraging creativity and engagement on their CH platforms [
52]. Also, they must be aware motivating factors, such as user participation, are critical to guarantee the success of these initiatives. Regrettably, all of them usually provide the same set of items for all users to annotate or enhance, disregarding any personal preferences. Thus, in our opinion, it is necessary to improve the assignment of activities or tasks taking into account users’ interests and preferences instead of resorting to random approaches. This can be accomplished by utilizing web technologies that help in the identification of interesting data for each user according to the context if possible.
4. Crowdsourcing Recommendation System
In this section, we describe how the system was developed to recommend images for annotations to users on CH crowdsourcing platforms. The users in the system represent the crowd, and the cultural platform is the CH organization that requests the image annotation task. As discussed previously, users on CH platforms volunteer their efforts and time to assist cultural organizations in the activities required; thus, CH platforms should make the user experience more appealing and intrinsically rewarding to avoid users leaving or becoming bored with participation.
In fact, current CH platforms display all available collections for users in a similar manner, allowing them to select which images to annotate and provide descriptions for. With the vast number of images available on the platform, requiring the user to scroll and browse through them all to find interesting tasks to participate in may be very time-consuming and can lead to a negative user experience on such platforms, making users lose interest quite frequently. In other words, depending on the user’s preferences, the probability of a match can be quite low and unsatisfactory, and we cannot rely on a simple browsing process to reduce the likelihood of user abandonment.
Our recommendation system is intended to help users by suggesting images from the crowdsourcing platform that could be appealing to them for annotation rather than wasting their time browsing and looking for revealing choices for them, thereby improving their experience on such platforms and encouraging their engagement. The system is built around several classification technologies that support users in deciding which images to annotate because they are supposed to be related to their interests and/or preferences. The system development entails the following steps, which will be discussed in detail in the following subsections:
Preparing datasets for system users as well as images available for annotation on the platform.
Retrieving extended structured data from the information extracted from various sources to be able to create user and image profiles.
Discovering semantic similarities between users and image data to guide the classification model used in the recommendation process.
Representing user and image features as well as training and testing them across different classification models to make recommendations.
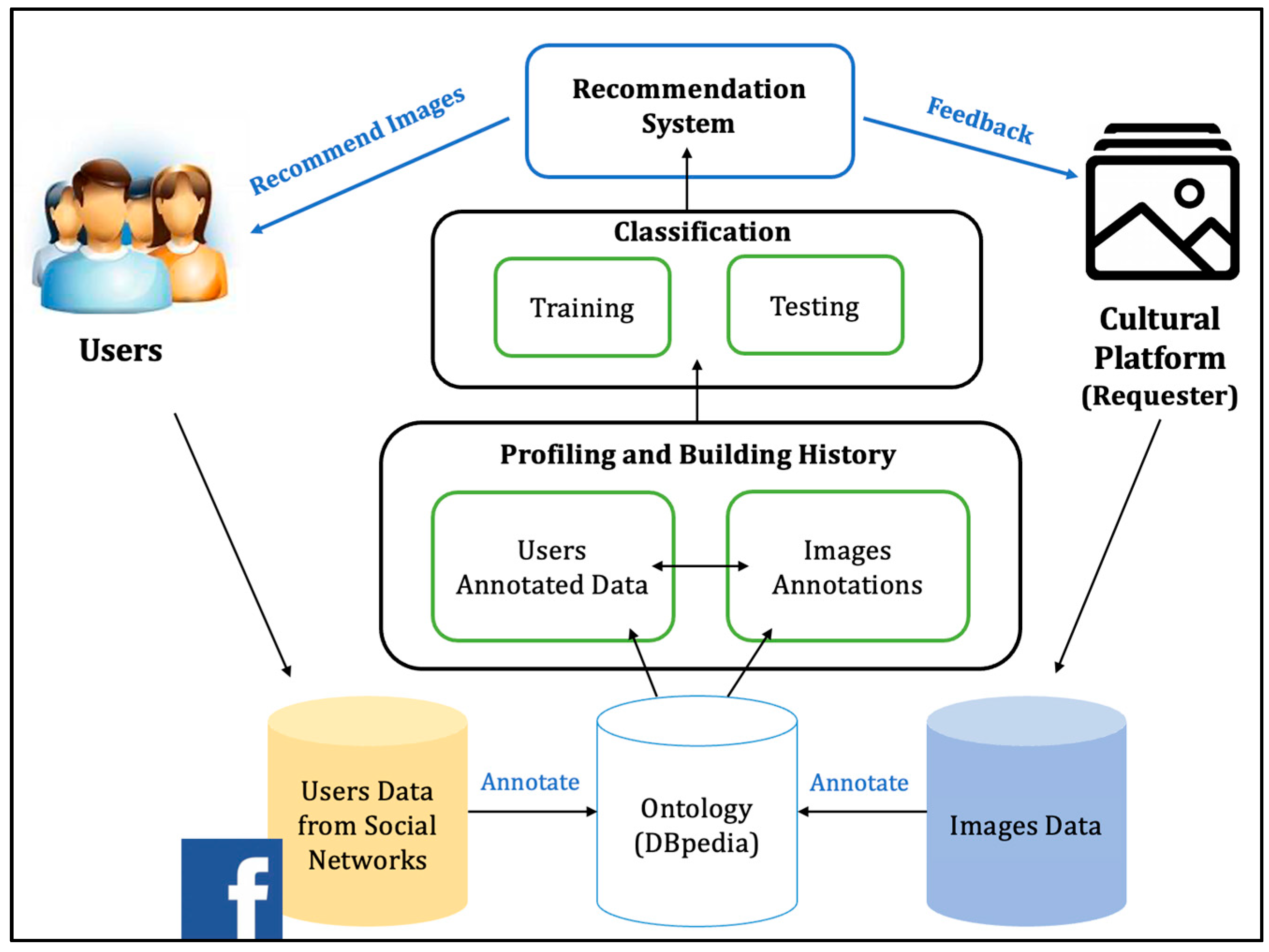
The overall system model is depicted in
Figure 1, showing the processes and system users with the necessary interactions. In terms of crowdsourcing technologies, the users of the annotation platform represent the crowd, while the role of the requestor organization is played by the cultural institution that wants to enhance their assets’ descriptions.
The automatic recommendation system we have developed, aimed to suggest to users the images from the crowdsourcing platform most appropriate for them to annotate, uses several classification models to help users in making their decisions about what to annotate, and such a procedure is logically fed by several data sources containing a large amount of relevant information we have gathered to build and test the resulting framework. Finally, in the middle of these components, we can find the necessary algorithms and procedures to digitize and vectorize annotations about images and users to obtain the data format used by machine learning tools. In the following sections, all of this framework is detailed and described.
4.1. Data Collection for Users and Images
Our discussion will start by describing the gathering of the data we need to develop the system, mainly two datasets representing the actors of the recommendation task. The first dataset is composed of the user data, that is, the crowd on the crowdsourcing platform, while the second one will contain the image data and their descriptions that the CH institution needs to be enhanced.
4.1.1. Users Data
Every day, users contribute abundant information about their opinions, preferences, or interests in their social networks, where this information can be formulated in a useful way. To build a user’s profile in our work, information was extracted from various pages on the Facebook application, currently the largest personal social network on the Internet. First, information about users was extracted from a Facebook social public page called
Nomads (
https://www.facebook.com/groups/nomadsexplore (accessed on 25 July 2023)). This page is very popular among all Egyptian travelers to share their travel experiences, communicate details about the visited places, and offer recommendations, tips, etc. Thus, a large number of posts were collected and structured for each user to create their profiles based on their published experiences, descriptions, reviews, etc.
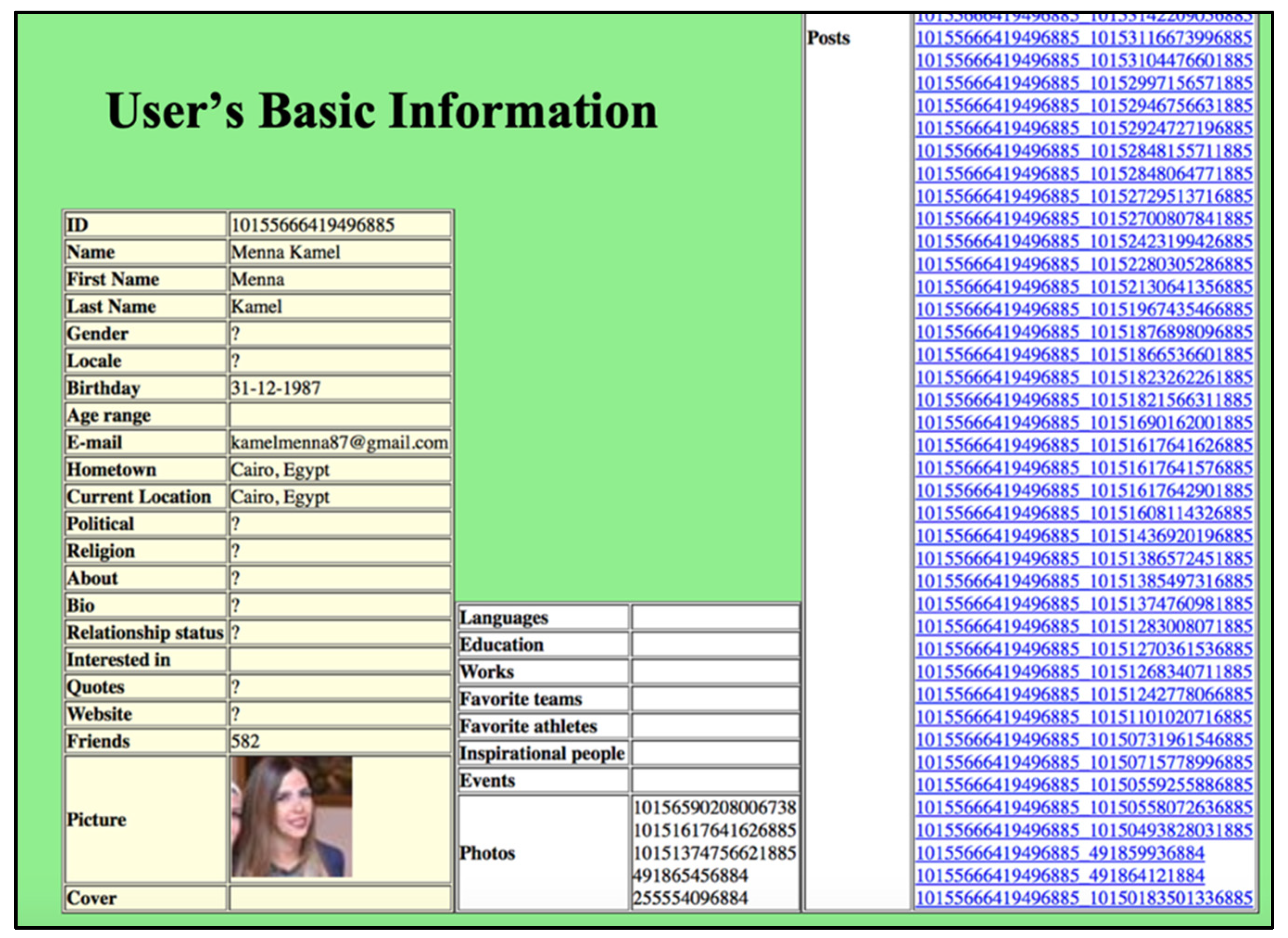
Then, for those users, data were extracted with permission from their profiles, including basic open user data, the contents on the user’s wall (publications and comments), the groups they are engaged in, and the pages they like, in order to extend and enrich the user profiles. An example of the data extracted from a user’s Facebook profile is shown in
Figure 2.
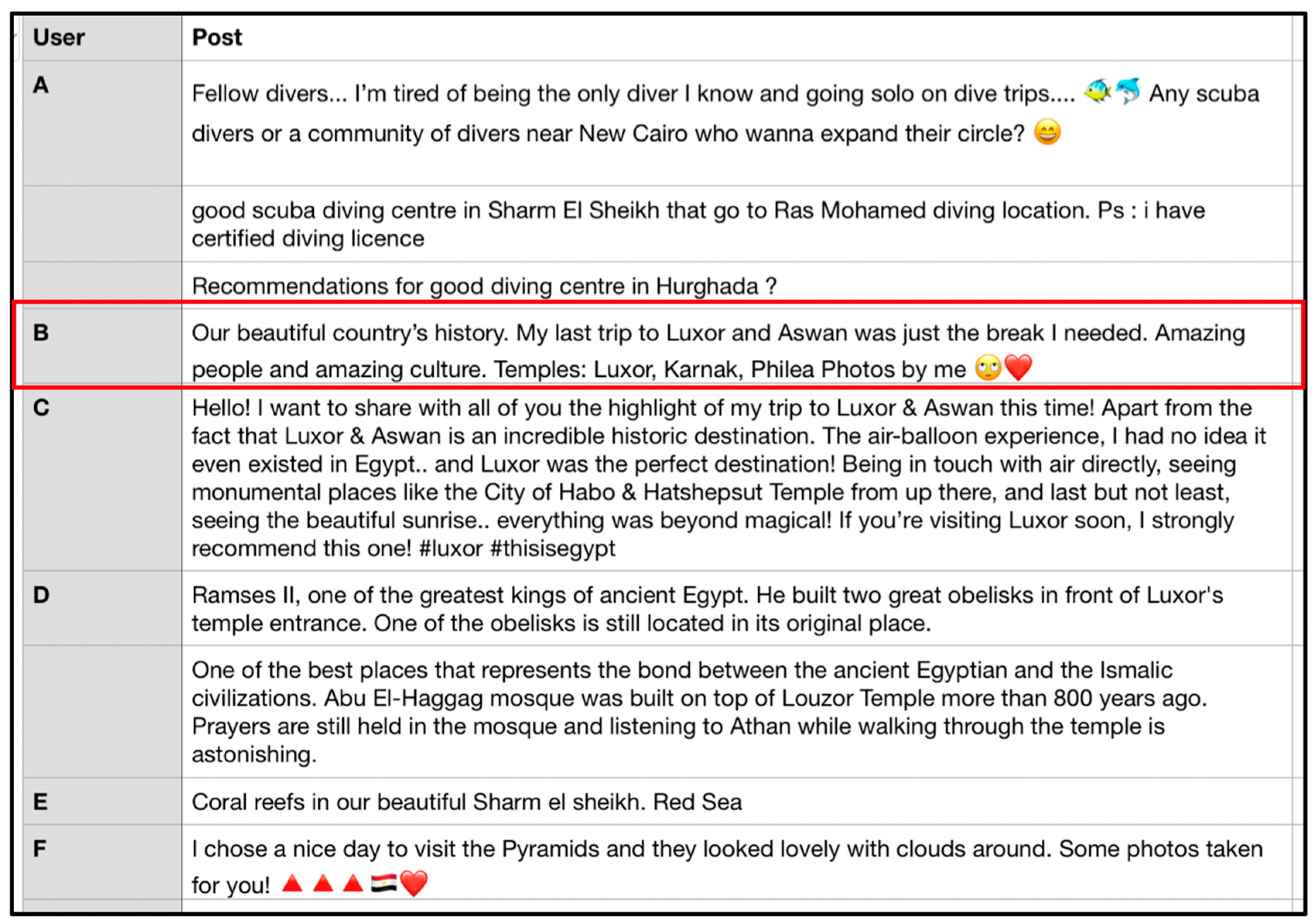
As a result, we have a lot of text relating to the user and most likely indicating their interests and preferences. In
Figure 3, a sample of such user data can be observed that has been extracted from the user’s public Facebook page. For instance, the highlighted line from the user ‘B’ shows his/her post about a Luxor and Aswan trip experience and the temples visited. As Luxor and Aswan are very well-known examples of Upper Egyptian cities with well-preserved temples over 4000 years old, the interest of the user in annotating images related to these Egyptian CH places and historical monuments can be derived.
It is interesting to note that the Facebook Nomads page only allows users to publish their post in English (even though most of its visitors are Egyptians), so this is the language which our system has been designed for to be able to work with the most extended art collections and users (annotators) in the world. In the likely case any post contains some Arabic text, this was filtered in the data preprocessing, as well as some non-text symbols, such as numbers or emojis. Last, if some user posts pictures with description, they become ignored as well as they are not useful for our processing.
4.1.2. Image Data
Regarding the visual-related digital data usually stored in CH platforms, they typically include pictures and videos about the assets of the cultural sites, such as monuments, buildings, paintings, sculptures, historic artifacts, drawings inside ancient documents, etc. These data items are usually provided by the owner of their rights, the CH institution ruling the crowdsourcing platform. For the processing described in this research, image data along with their associated comments were extracted from a set of sources corresponding to different Internet pages devoted to ancient Egyptian cultural heritage, which comprise a large number of free pictures about artistic assets (e.g., FreeImages (
https://www.freeimages.com/search/ancient-egypt (accessed on 25 July 2023)), Pixabay (
https://pixabay.com/images/search/egypt (accessed on 25 July 2023)), Pinterest (
https://www.pinterest.es/pin/451626668875796316/ (accessed on 25 July 2023)), Megapixl (
https://www.megapixl.com/search?author=&keyword=ancient+egypt (accessed on 25 July 2023)), Pexels (
https://www.pexels.com/search/egypt/), Depositphotos (
https://sp.depositphotos.com/stock-photos/ancient-egypt.html?filter=all (accessed on 25 July 2023)), or Dreamstime (
https://www.dreamstime.com/free-photos-images/ancient-egypt.html (accessed on 25 July 2023)), just to name a few). To feed our recommendation system, we randomly scraped a testing sample of around 6000 culture-related Egypt-annotated images from some of these pages. We were mainly interested in extracting only annotated images and collecting their text descriptions to be able to use them as input for our classification models.
Figure 4 shows a typical example of the kind of artistic image extracted from these places, along with the descriptions provided for each. The set of pictures extracted and their associated descriptions were collected and stored offline for later construction of the image dataset that we used in the processing we describe in the following sections.
4.2. Data Annotation and Extension
Since the extracted text data for users and images contain unstructured information, those texts are processed to identify representative keywords inside, which are then extended and used to represent the user and image features in the system. To accomplish this, the text is first annotated by building automatic queries to the DBpedia Spotlight (DB-SL) tool, which identifies DBpedia-named entities in the input text data, thus connecting the unstructured information fragments to the linked data cloud through the DBpedia framework. The DBpedia initiative is built around a very flexible, rich, and easy-to-use framework to collect different kinds of structured information published in Wikipedia, storing them in a hierarchical database according to a well-known data ontology, linking the information to various additional datasets on the Web, and finally allowing you to request complex queries against such data repository to enhance your original information. In any case, it is worth mentioning that this automatic identification of entities named in a given text is not an error-free process. As there is usually some ambiguity, different alternatives can exist for a given surface form, and the tool does not always make the right decision. In order to detect these errors, we carry out consistency checks over the results, trying to detect entities with property values excessively unrelated (sharing few of them) to the rest of the detected entities and searching among the alternatives for those ones more likely to fit in the set.
In our work, we examined the rdf:type property in the DBpedia ontology (dbo) domain, as the generality of these classes is useful for allowing the identification of the most relevant entities within the provided text. The specific goal of utilizing the DBpedia classes is to be able to enhance the annotations of users and images that feed the classification process, discovering related concepts between both datasets. In other words, identifying similar concepts to bridge the gap between the original annotations about images and users’ profiles. That is, identifying the hierarchy of classes associated with the annotations of users and images will permit us to discover hidden relationships between different terminologies and similarities that may lead to related common concepts in the ontology, paving the way to suggest for annotation the instances of such associated categories. That is, if the user-extended information indicates an interest in some group of classes, it is reasonable to think that the instances classified in such categories could be appealing to him/her for image annotation. This task is performed through a process that extends the data of both users and images querying the DB-SL to identify the classes related to the original information, inspecting common features, and later feeding the extended similar concepts to the classifiers. For all extracted images and user data, all annotations and extractions were carried out using automatic SPARQL queries to the DBpedia and DB-SL.
For instance, consider a typical image annotated with the description “Felucca sailboats cruising on the river—Upper Egypt”, and suppose we have gathered a user post containing the text “Luxor and Aswan Nile Cruise trip”. The JSON response of the DB-SL API returns resources and classes with some overlapping data for both image and user text (such as the “Cruise_ship” resource and the “PopulatedPlace, Place, & Location” classes), in addition to a newly discovered class “River” that is additionally retrieved from the user post and which had been already annotated as an important keyword from the text describing the image. In summary, using DBpedia ontology classes to extend the categories related to the original annotations may be very helpful to discover new similar categories between users and images, categories that may not be explicitly mentioned in the texts.
4.3. History of User’s Previous Image Annotations
One of the elements required by our recommendation model to train the classifiers to make predictions is the history of image annotations performed in the past by the users of the CH platform. The most historical data available, and the most reliable, will be the recommendations provided by the classifiers. In real scenarios, where the recommendation system is developed and controlled by the requestor organization, these data will be available for all the users of the platform. However, the existing CH platforms do not provide access to external agents to the information stating which images have previously been annotated by the system users. Consequently, we resorted to designing and creating our own synthetic data [
67,
68] to represent the users’ previously performed annotations on some sets of the available images.
A new semantic mechanism was devised to create a synthetic set of historical annotations corresponding to each user, identifying semantic matchings between images and users. In other words, we proceed to match users’ characteristic information with the images’ descriptive data having a very related meaning and establishing higher matches, such as the annotations performed by the user in the past. Otherwise, in case of a very low value for the resulting matching, it will be recorded in the user’s history as a rejected item.
The devised method for assessing matchings makes heavy use of the word embeddings technique, employing neural networks to learn real-valued numerical vector representations for words after a training phase using a large corpus of text. To accomplish this, we resort to Word2Vec to explore relationships between user-annotated text and annotated descriptions of images in order to compute the probability that those user texts are similar to the descriptions of the images. Both users’ annotations and the images’ descriptive data are represented as large vectors of scalars generated using the Word2Vec model, so data with similar meaning will have similar vector representation. In our work, we used the specific Word2Vec model that is trained on the Google News corpus (about 100 billion words), which contains 3 million different words and phrases and was fit using 300-dimensional word vectors. To access and manipulate the word embeddings, we used the Gensim library of the open-source Python programming language, which provides all the features needed for the Word2Vec implementation.
Once we have the embeddings collecting the meanings of the annotations, we proceed to estimate the similarities by measuring the distance between image words and the user words by using the Word Mover’s Distance (WMD) function [
69]. This function measures how dissimilar two documents are as the shortest distance that the embeddings of the words of one document (the users’ terms) must move to reach the other document embeddings (the images’ terms). In other words, we estimate the distance between a given user and a specific image by computing the WMD between the user description embeddings and image description embeddings. This is repeated for each user and for all available images, yielding a matrix of distances for each user to all the images of the dataset.
After computing all the crossed distances between users and images, the lowest distance/s are taken as the representative sets of history matchings between users and images, as the generated embeddings are the most similar regarding Word2Vec meanings. In that case, the
Status field is set to ‘1’ (see
Figure 5) denoting the fact that the user accepted the image for annotation; otherwise, in the case of the biggest distances calculated, a ‘0’ is added, indicating the most likely probability is that the user had rejected this image for annotation. These sets of records are stored as the history of previously completed image annotations to be used when training classifiers.
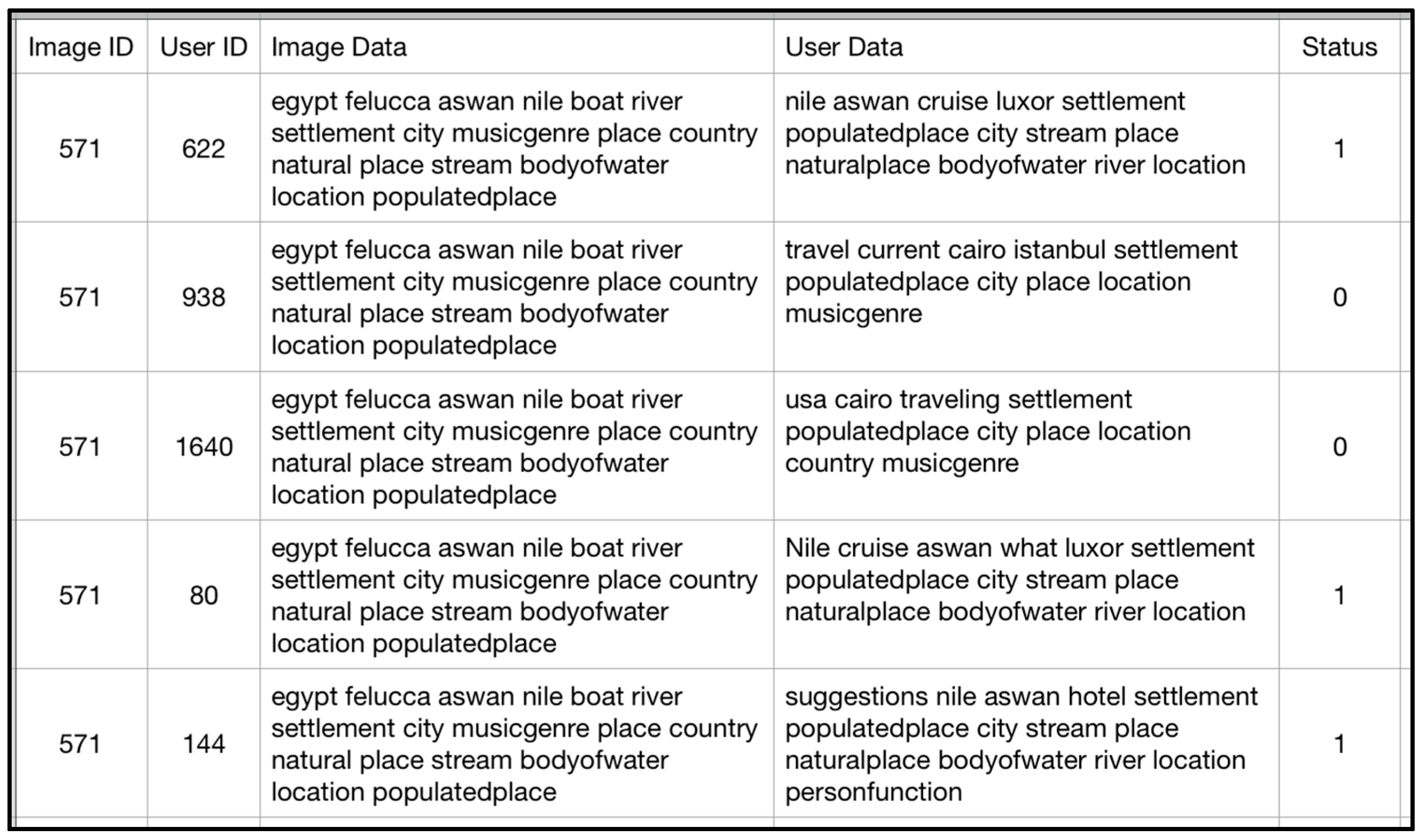
Figure 5 illustrates the resulting dataset with a sample of accepted/rejected images after semantically matching their descriptions. The stored fields (
image id,
user id,
image data,
user data) containing identifications and the annotated data are associated with a
Status denoting whether the annotation was accepted or rejected (1/0). Here, the image with id 571 is matched with status ‘1’ for three users with meaning features close to the image, while ‘0’ was appended to the status of the other users.
4.4. Feature Representation and Classification
In this section, we focus on details of the data modeling for both users and images, with the goal of representing each as a collection of features that characterize them, and with the final goal of transforming text data into numerical features that can be processed with machine learning (ML) techniques as classifiers. In this feature extraction process, uncorrelated or superfluous features will be removed to simplify the job and avoid noise. The BoW and TF-IDF methods were tested to represent the data, and the BoW technique was sufficient in our work as the TF-IDF did not produce better results. This way, the BoW technique was used to pass from text descriptions to numeric vectors for both users and images, denoting with 1’s and 0’s the presence or absence of the extracted features in the frequency vector. Previous to any ML process, including classification, some preprocessing to remove meaningless symbols and some normalization of data to set a common scale for input values are usually necessary, so similar ranges are used for similar features to avoid making some features dominate over the others and to resemble standard normally distributed data in some way to allow the classification model to converge faster.
In order to compare different techniques to build the recommendation system, three different well-known classification methods were used: random forests (RFs), support vector machines (SVMs), and neural networks (NNs). Some implementation and testing details for each one are included in
Section 5, where the input data for all of them are the numerical vectors describing users, images, and the set of historically completed tasks, annotated, or rejected.
According to our previous definitions about accepted or rejected tasks, the Status value for each user across all images is used as a classification label, dividing the input records randomly into training and testing sets as usual to feed the classification process. For the training phase, historic records of accepted/rejected tasks according to the user and image features are fed to the classifier. In the testing phase, the trained model is used to predict some randomly selected images across the user’s features to see if the prediction is correct or not, or, in other words, whether the user has taken the same decision as the classifier prediction, being this a binary value for acceptance (classifier output is ‘1’) or rejection (classifier output is ‘0’).
5. Experimental Results and Discussion
Our implementation of the system described in the previous section was built using Python as a programming language, making extensive use of the Scikit-learn open-source library [
70] to implement the classification techniques involved in our comparative experiments. The system addresses Egyptian CH, and, in order to verify the validity of the developed model, we crawled 6000 images and approximately 3100 user data elements. The experimental testing was carried out by comparing the performance of the three different classifiers (RF, SVM, and NN) on the same training and testing sets making use of random subsampling (that is, splitting randomly the dataset into two disjoint sets to use each in the training and testing phases). A large number of different tests were carried out to study the accuracy of the classifiers depending on the size of the training sets. For all of the abovementioned classifiers, the dataset used contained 125,216 samples of the users’ history, each of 500-vector size, with splits of 60% for training and 40% for testing, 70–30%, and 80–20%. To analyze results, classification accuracy, average precision, and F-score were used as evaluation indices (computing three different averaging “binary, micro, and macro” [
71]). In all cases, the results were averaged by repeating each measure across 10 trials for each split size of the train/test sets. In the next sections, we present the results achieved by each classifier.
5.1. Random Forest Classifier
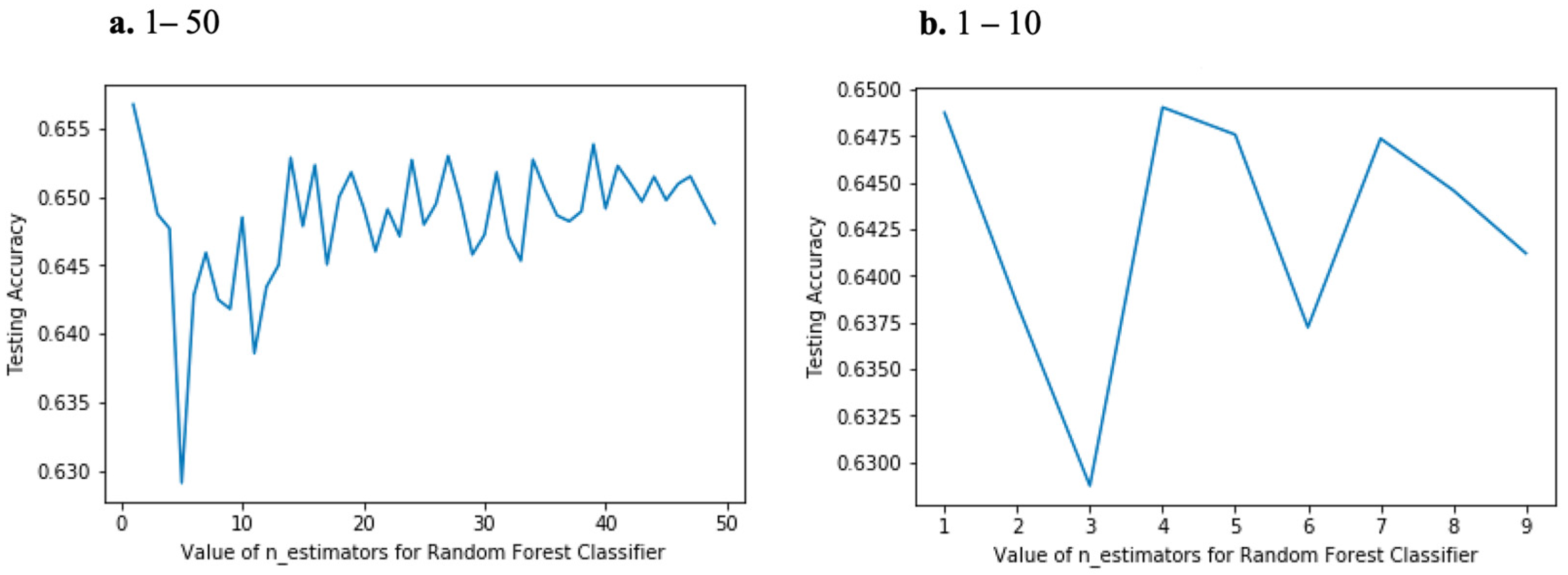
In the random forest model, the main parameter influencing the performance of the resulting tool is the number of estimators, which in this model is the number of decision trees created by the classifier to fit the provided training set. Instead of selecting a random number for this task, we proceeded to compute and draw the accuracy of the system for a number of estimators. Subsequently, we studied the classifier performance for this curve and selected the number of estimators corresponding to the best performance for the tests. The result of the process is depicted in
Figure 6.
In part ‘a’, results from with 1 to 50 estimators are shown, which allows us to evaluate performance at large scale, every 10 estimators. The resulting accuracy curve fluctuates (
Figure 6a), not improving as the number of estimators increases. Taking a closer look at the low number of estimators (from 1 to 10 as shown in
Figure 6b), it was confirmed that a low number of estimators can achieve the highest accuracy. Considering these curves, four estimators were selected to be used in the comparative tests.
For these four estimators, the results achieved by the random forest classifier are shown in
Table 2. Studying the three different splits for training–testing sets, it was discovered that all of them achieved almost the same accuracy, with 66.5% being the best accuracy value for the 70–30 division. From the analysis of the computed average precision, it can be said that this is a fairly balanced classifier model, as correct predictions are provided for approximately 60% of the positive examples.
5.2. Neural Network Classifier
In the case of an NN classifier, the number of hidden layers is also a relevant factor that decisively conditions the final model and its results. In this work, the model of the NN classifier has been created with only one hidden layer because of two reasons: first, it is the most frequent value in the literature for binary classifiers in terms of time complexity [
72,
73,
74], and second, because the size and complexity of the dataset were small enough to overcome any overfitting problem with only one hidden layer. Following the same strategy we adopted in the case of the RF classifier, a curve was plotted to compare the accuracy depending on the number of neurons used in the hidden layer to be able to select the number of neurons to obtain the best results with our dataset. A significant number of tests were carried out using the MLP classifier on an underlying neural network, which is based on optimizing the log-loss function using the stochastic gradient descend (SGD) algorithm. Regarding the activation functions of the hidden layer, the following four were tested: the
logistic sigmoid function, the
identity (or linear) function, the
rectified linear unit (relu) function, and the
hyperbolic tan (
tanh) function. In addition, two solvers were used in order to optimize the weights of the NN:
adam, which is an SGD optimizer, and
lbfgs, which is significantly popular for parameter estimation when trying to minimize the activation function [
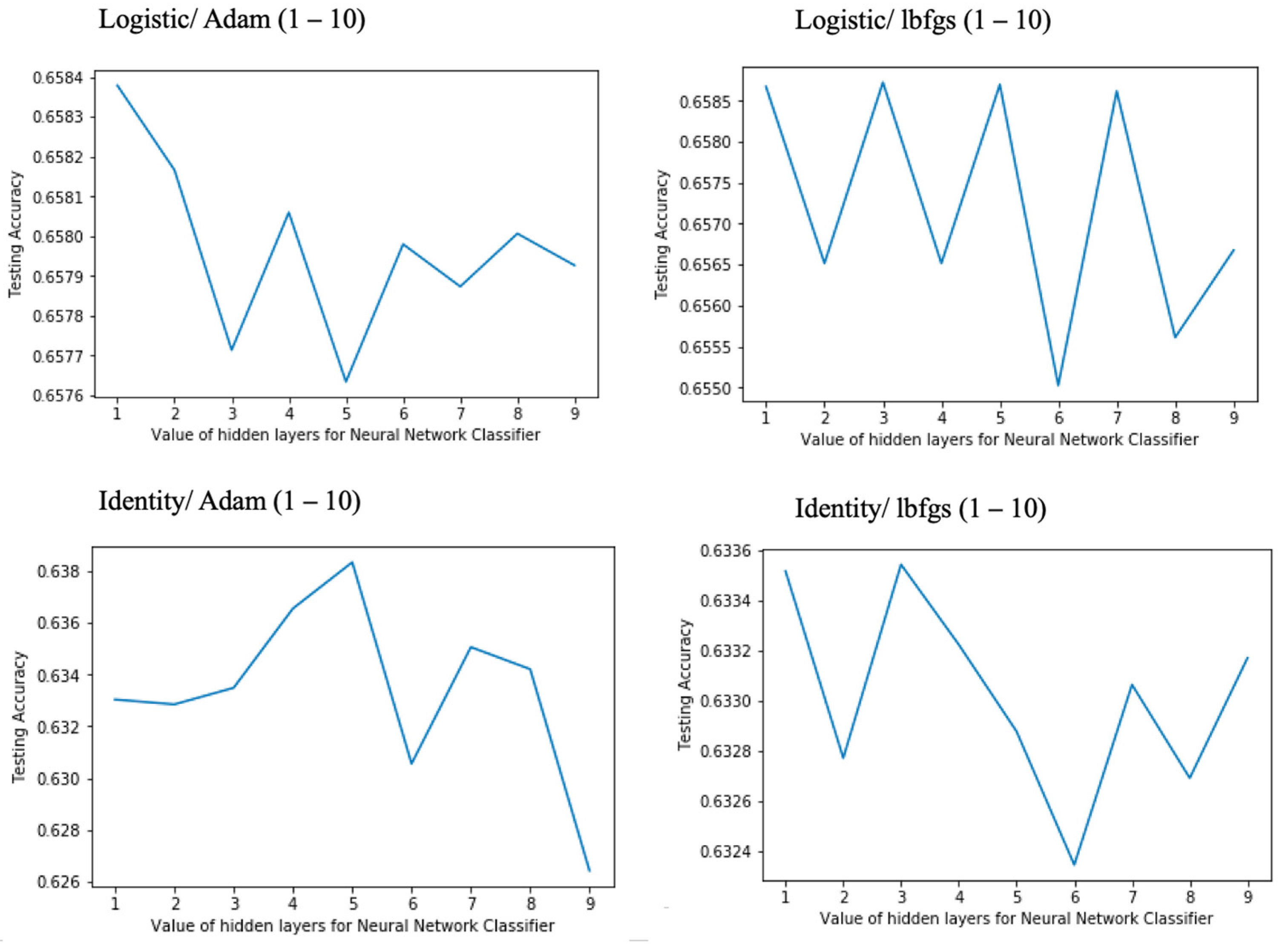
75]. This way, the accuracy of different combinations of solvers and activation functions were plotted for several selections of the number of neurons for the NN hidden layer, as shown in
Figure 7 and
Figure 8, where all the tests were performed with the training–testing distribution corresponding to the 70–30 split. Firstly, in
Figure 7 the
logistic and
identity activation functions’ curves are depicted.
As it can be seen in the plot of the
logistic function with the
adam solver, the accuracy decreases as the number of neurons increases, so a hidden layer with only one neuron was selected for the NN classifier with this configuration. When changing to the
lbfgs solver, the curve of testing accuracy fluctuates and decreases after eight neurons, so five neurons were considered as the selected value. Next, repeating the same process for the
identity activation function, we concluded that five neurons were an optimal value for the
adam solver, while the best accuracy was achieved for three neurons in the case of the
lbfgs solver. Second, a similar analysis is carried out for the results of the
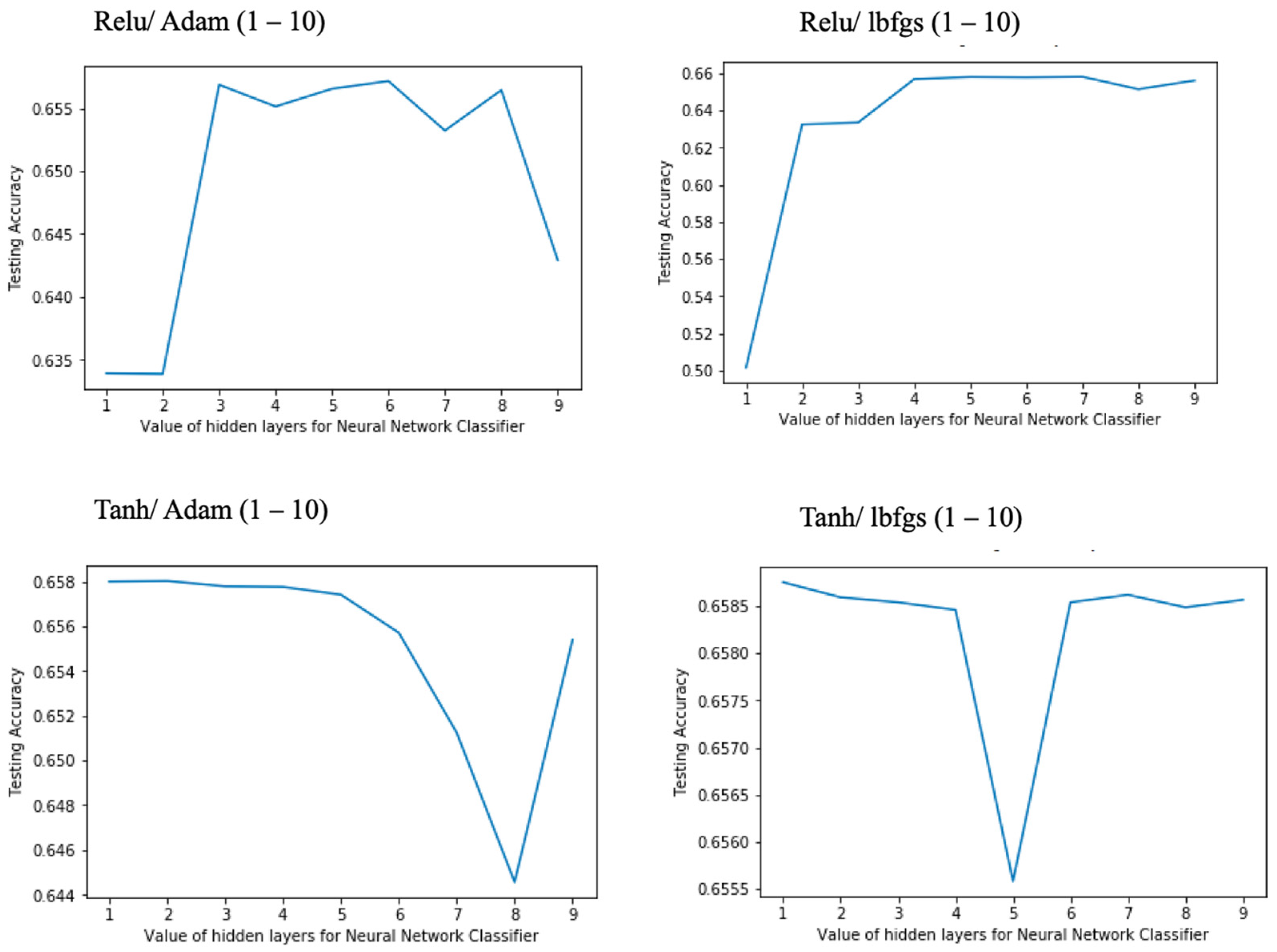
relu and
tanh activation functions, and the corresponding plots are presented in
Figure 8.
The relu function with the adam solver plot shows that starting with three neurons, the accuracy increases, but there was no further improvement with increasing the number of neurons, so three neurons were used in the hidden layer for training the NN. Regarding the lbfgs solver used with the relu function, the curve shows a rise starting at two neurons, with a peak at four neurons, and no further improvement in testing accuracy is observed if the number of neurons is increased above four, so four neurons were selected as the value for this configuration. The tanh function with adam solver curve started at the peak at two neurons and then began to decline. In addition, with the lbfgs solver, two neurons were also sufficient for training the NN.
Once selected as the best configuration for each combination of activation functions and solvers, we present in
Table 3 the results obtained after testing each scenario with the different splits of the training/testing dataset.
The best classification accuracy was achieved by the majority of the configurations for the 80–20 split, and this peak value was slightly above 68%. Regarding the comparison between adam and lbfgs solver’s performance for each activation function, it can be concluded that both solvers produce almost indistinguishable results, with no appreciable difference among the different activation functions when analyzed on this dataset.
In the case of the identity activation function, we obtained the poorest results with the used dataset, observing the accuracy ranging from 63% for the 60–40 and 70–30 splits to 66% for the 80–20 one. On the other side, even though not significantly higher, the logistic, relu, and tanh functions all provided similar results, with an average accuracy of around 68% for the 80–20 split and descending to 66% for the 70–30 and 60–40 partitions, all of them for the adam solver. Using the lbfgs solver, almost the same results were obtained, which permits us to conclude that the lbfgs solver converges faster and performs better than the adam on this dataset.
Regarding the lower results for the linear activation function, it is necessary to say that the identity function does not help the model to establish strong mappings between the network’s inputs and outputs, so the lower performance accuracy is observed when compared to the non-linear models. Comparing the result of the latter ones, we observe a very small difference in the performance accuracy of the NN non-linear activation functions; i.e., they are nearly identical, mostly considering that slight variations inevitably occur because of the different random sampling for the successive 10 averaged trials. As a final comment, note that the prediction model seems to be well-balanced, with an average precision of around 0.6 for all the experiments performed.
5.3. Support Vector Machine Classifier
In the case of the SVM classifier, it is necessary to select a kernel function to train and test the model. In this work, we have used four different kernel functions to make comparisons, i.e.,
linear,
sigmoid,
rbf, and
polynomial [
76], providing the results presented in
Table 4.
There, we can observe that both the rbf and linear kernel functions achieve similar performance, with the best classification accuracy of around 67% for the 80–20 split in the training and testing sets. Next, using the polynomial function for the kernel, we obtain an accuracy of 64%, and, finally, the sigmoid kernel function provides a 56.4%. In the case of the 70–30 split, the rbf function leads to an accuracy of 65.7%, while the linear, polynomial, and sigmoid achieve accuracies of 65.4%, 62.3%, and 56%, respectively. Finally, the split consisting of 60–40 partitions takes us to a similar performance of accuracy for both rbf and linear kernel functions (65.5% and 65.3%, respectively), followed by the polynomial function with an accuracy of 62.2%, and last, the sigmoid kernel with 55.8% accuracy. As in the case of the NN classifier, the average precision obtained shows that the prediction models are pretty well balanced.
5.4. Results Discussion
The analysis of findings from the extracted sample data for users and images confirms that personalized annotation recommendations on CH platforms can improve the user’s experience and efforts for finding images that matched their preferences, rather than a browsing process searching for appealing images, which could be completely unsatisfactory. In general, the three classifiers (random forest, neural networks, and support vector machines) perform with comparable accuracy in the classification task, with a result rounding to 60% of average precision, revealing a fairly balanced classification model. In view of our results, classifying images among users resulted in relatively high average accuracy rates, with the NN classifier achieving the best accuracy of 68.2% and the RF achieving the lowest accuracy of 66.4%. In our opinion, incorrectly predicted images are highly influenced by the nature and availability of the dataset, particularly the history of previous annotations performed by the system users, which affects the training of the classifier prediction model. However, the word embedding method alleviates this obvious limitation and aids in the conducting of experiments and testing.
Generally, for classification models, the tuning of parameters such as the number of estimators in an RF classifier and the number of hidden layer nodes in a NN classifier has a significant impact on the classification accuracy. Furthermore, after extensive testing, we conclude that, although choosing an activation function and solvers for a neural network is important, other factors, such as the learning parameters and the number of hidden layer nodes, are more crucial for effective network training as the accuracy results show only minor differences when training with different activation functions. On the other hand, the selection of the activation function in SVM had an obvious effect on the training process and, as a result, the classification accuracy with an average of 10% difference in accuracy was recorded. To be more specific, the linear kernel in the SVM was sufficient to train the features and find a clear separable hyperplane for this dataset, whereas non-linear kernels (rbf, polynomial, sigmoid) required longer training times to converge despite some having similar accuracy rates. According to the results obtained, the rbf kernel performs similar to the linear kernel, making it the second choice recommended when the problem is non-linearly separable. Furthermore, although the sigmoid function was quite prominent for the SVM due to its origin from NN, it produces lower classification accuracy when used with the SVM than when used to train the data for the NN classifier on this dataset.
6. Conclusions and Future Work
In the last decades, CH institutions have made a significant effort to introduce crowdsourcing technologies to increase the value of their online collections, encouraging the crowd to enhance the CH digital assets with their knowledge and experience. However, more research is necessary to address issues affecting the accessibility of users in CH environments. In this paper, we have presented a research work intended to build a recommendation system for the CH scenery, assisting users in finding the best artistic images for annotating based on a personalization approach, that is, considering their interests, preferences, and personal history to identify a collection of the most appropriate CH assets to them. The developed approach involves intelligent end-to-end processing of both images and user descriptions, starting with data gathering from different sources to test the system outside of a specific CH platform, mainly Facebook resources and Internet-free repositories of annotated images. Furthermore, the work revealed how semantic matchings using embeddings can compensate for the lack of data for testing the system. Moreover, the DBpedia SpotLight tool was used to annotate the unstructured data, and DBpedia SPARQL endpoints were exploited to extend it with related DBpedia classes in order to find more relevant matches between users and images data. At the final stage, several well-known machine learning classification methods were used to identify the relevant assets to recommend (random forests, support vector machines, and neural networks). The data analysis derived from the experimental results indicates that the combination of semantic technologies and machine learning tools, like classification techniques, is a promising way to build recommendation systems that help to incorporate crowdsourcing approaches in the enhancement of CH asset annotations. The automatic recommendation of the most appropriate images for each user, matching their interests, expertise, and preferences, seems undoubtedly a more promising approach to engage them in the crowdsourcing task, rather than a sometimes laborious and fruitless search through the vast collections of CH institutions.
Our work revolves around existing well-known methods and tools, but we were able to apply them in different ways other than those traditionally used in the literature. On one hand, our results show that using word embedding techniques to enhance processes of semantic matching is an approach that deserves attention when creating synthetic data in scenarios with scarce datasets. Additionally, the work emphasized the benefits of utilizing the vast information of social media that users contribute, as well as their engagements on various pages and groups, to create profiles and users’ datasets. Furthermore, the research shows the benefits of using the huge amount of structured information contained in the DBpedia ontology to identify features related to the original data for both assets and users, that is, to discover hidden links between them that can be used to enhance the matching process from a semantic point of view, resulting in better classification results.
Finally, while crowdsourcing for cultural heritage preservation is a growing demand that has been addressed by large cultural organizations, there is a growing need to explore new technologies and develop such customized recommendation systems in order to capitalize on the best opportunity to achieve better quality from user participation and as well provide users with satisfactory experiences.
As future evolutions of the presented research, we can identify several lines focused on different aspects of the developed system, ranging from using other intelligent technologies to build the task recommendation algorithm to exploring different target scenarios to apply a similar crowdsourcing approach. Our immediate objective is to test the developed crowdsourcing application on a real Egyptian CH institution platform to demonstrate the benefits of the personalized annotation recommendation in crowdsourcing approaches to help in the preservation and enhancement of digital culture as well as to confirm its performance when used with users really interested in participating. Also, it would be very interesting to explore other structures of the DBpedia ontology as well as to incorporate more specialized domain ontologies in the process of enrichment of the original data with additional semantics in order to improve their description and matching capabilities. Finally, as crowdsourcing involves a large number of contributions from unknown and unreliable participants, exploring technologies to detect incorrect annotations would be an interesting research line to explore. In this regard, considering that the same assets will be annotated by a number of different contributors, we think that the advanced classification capabilities of the new deep learning approaches based on transformers are a promising approach to detect outlier annotations, that is, contributions that are not in line with the annotations of the rest of the participants in the crowdsourcing task.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}