
Fall Detection Approaches for Monitoring Elderly HealthCare Using Kinect Technology: A Survey

 ,
,  ,
,  ,
, 
Abstract
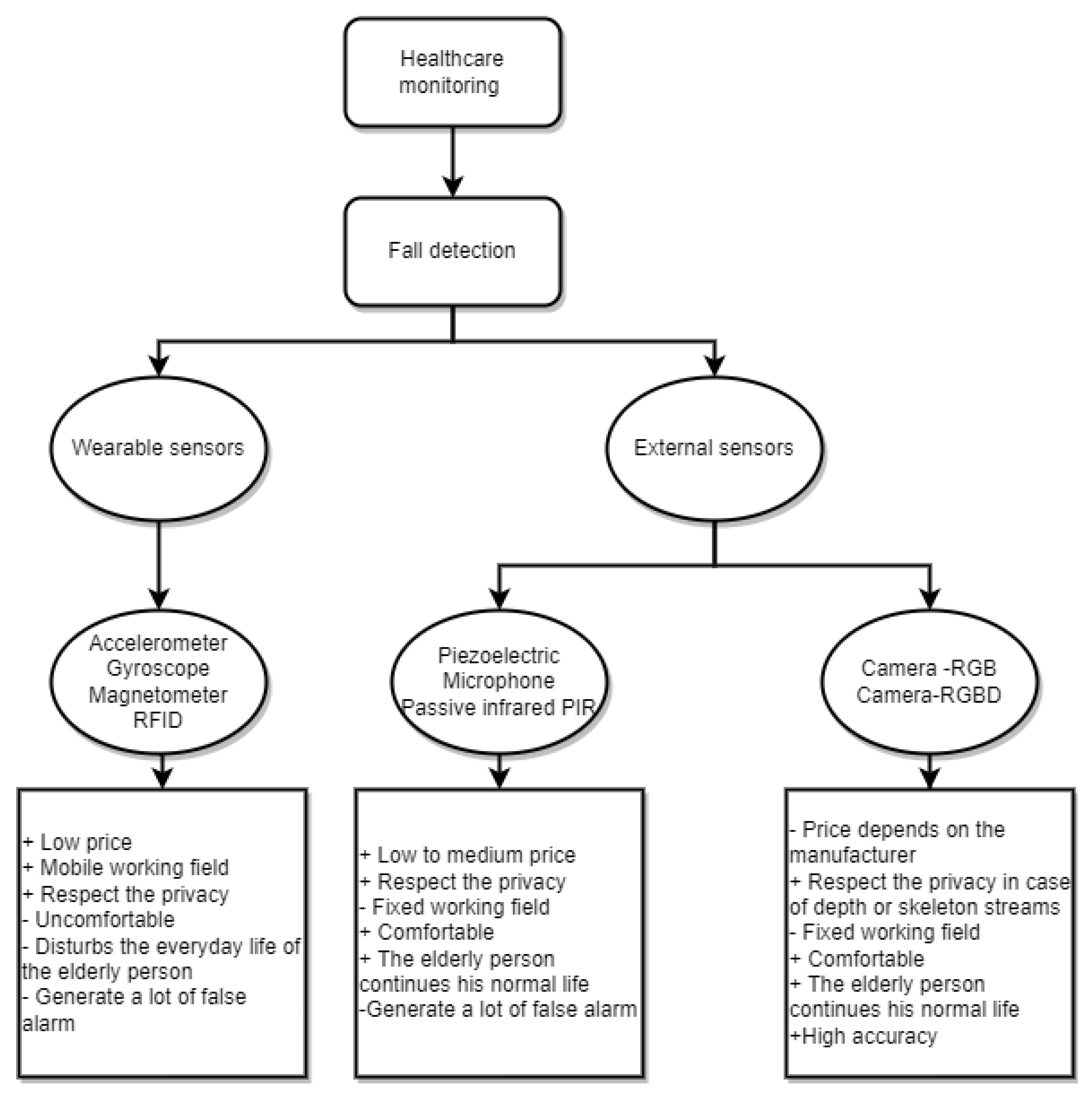
:1. Introduction
- The technical advantages of Kinect for the multi-sensor type include depth, RGB, infrared, and voice, producing a precise system for detecting falls.
- Kinect’s Time Of Flight (TOF) principle makes it insensitive to lighting issues that reduce system reliability [24].
- Kinext generates 3D data with a single camera, whereas a stereoscopic system is needed to attain the same objective in the RGB domain.
- The acceptable price of Kinect compared to other motion-tracking cameras encourages researchers to invest in the field of computer vision for health applications.
- Kinect fully respects the privacy of the person, and provides skeleton and depth data independently of RGB data.
- The release of the new Kinect Azure motivated us to write a survey on the different fall detection approaches that use Kinect V1 or V2.
2. Related Work
- This article serves as a valuable reference for the development of elderly fall detection applications. We have compiled a comprehensive overview of both older and recent articles spanning from 2011 to 2022. Additionally, we provide in-depth insights into the various components of fall detection approaches, including data acquisition, preprocessing, feature extraction, actuation algorithms, and alert systems. Furthermore, we offer an extensive examination of performance metrics and highlight all publicly available Kinect-based datasets, making this resource indispensable for researchers and practitioners in the field.
- We cover Kinect applications in a critical area of our society, namely, healthcare fall detection.
- We do not focus on commercial fall detection products.
- We present guidelines for further research.
3. The Microsoft Kinect
3.1. Success of Kinect Technology
3.2. Technical Characteristics
3.3. Kinect Software Tools
4. Kinect-Based Fall Detection Approaches
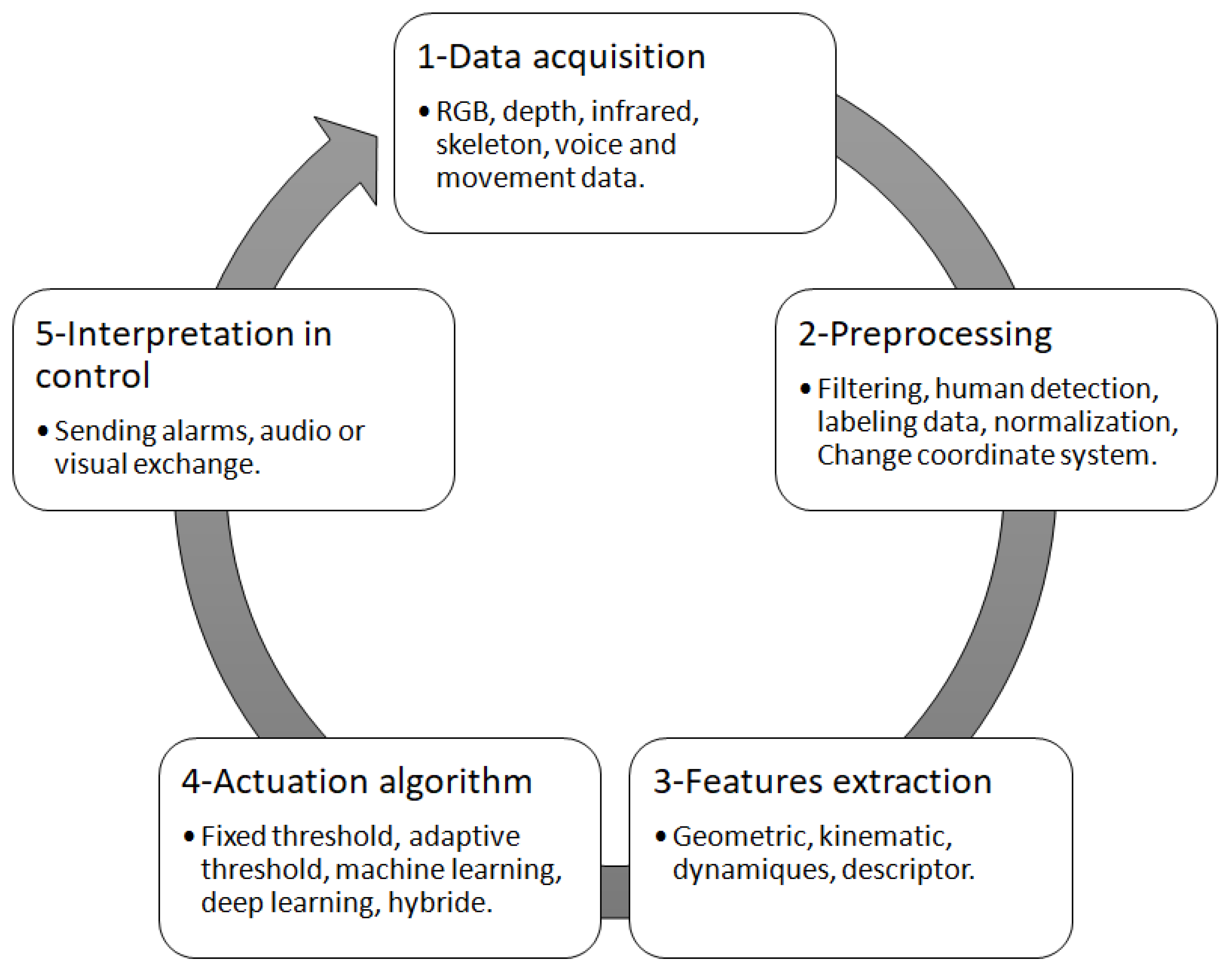
4.1. Data Acquisition
4.2. Preprocessing
4.3. Feature Extraction
4.4. Actuation Algorithm
4.5. Interpretation in Control

| Paper | Data | Preprocessing | Features | Algorithm | Threshold Values | Performance |
|---|---|---|---|---|---|---|
| [89] | - Skeletal | - Apply the average filter of 4 previous samples | (1) Location of the center of mass with respect to the support polygon (2) Height of center of mass (3) Dispersion of joint heights (4) change of dispersion of joint heights | - SVM | - | - Acc 98.5% |
| [90] | - Skeletal | - | (1) Standard deviation of the head joint y-axis trajectory | - KNN | - | - Acc 95% |
| [88] | - RGB | - Segment the foreground using the adaptive background mixture model - Extract the key frame | (1) Optical flow vectors (2) Orientation of the elliptical pattern | - SVM with linear Kernel | - | - Acc 97.14% - Pr 93.75% - Se 100% - Sp 95% |
| [66] | - RGB | - Extract the human shape - Create the groups of pictures (GOP) - Select Keyframes from GOP | (1) Motion qunatification from the optical flow | - Fixed thresholding | (1) >0.95 (1) ≤ 0.05 | - Se 99% - Sp 98.57% - Pr 98.57% - Acc 99% |
| [65] | - Depth - 3-axis acceleration | - Compute the threshould value from the training data - Extract the depth difference map each 15 frames - Generate the depth difference gradiant along the 4 perpendiculare directions | (1) Sum vector magnitude (2) Number of entropy of depth difference (3) Gradient map | - Fixed thresholding - Sparse representation | - | - Mean Acc 97.86% - Mean Pr 95.05% - Mean Se 100% - Mean Sp 96.37% |
| [99] | - Depth - 3-axis acceleration | - | (1) Acceleration along x, y and z (2) Magnitude of the acceleration vector (3) Differentiel of acceleration along x, y and z (4) Height, width, and depth of the user (5) Area (6) ratio of height to width (7) ratio of height to depth (8) differential of the height, width and depth | - Random forest | - | - Acc 90% |
| [75] | - Depth | - Noise reduction | (1) HOG features | - SVM with linear kernel | - | - Acc 98.1% - Se 97.6% - Sp 100% |
| [43] | - Skeletal | - Skeleton normalization | (1) Common 12 features from NCA (2) Original distances from Kinect (3) Normalized distance from Kinect (4) Velocities and distance from Kinect | - C4.5 - RF - ANN - SVM - NCA | - | - Mean Acc 99.03% |
| [55] | - Skeletal | - | (1) y-coorinate (2) And angle of the upper body (head, neck, shoulder right, shoulder left and spine shoulder) | - Fixed thresholding | (2) 30° | - Se 70% - Sp 75% |
| [76] | - Skeletal | - Manual labeling of dataset - Outlier skeleton filter using one-class SVM | (1) EDM of 17 normalized joints by the height of the monitored human (2) Interframe speed | - SVM with Gaussian RBF kernel + CUSUM | - | - Acc 91.7% |
| [103] | - Depth | - Forground segmentation - Labeling RLC and object labeling - Thining Zhang Suen’s rapid thining method Searching | (1) 2D skeleton information of calculated joints (Head, ShoulderLeft, ElbowLef, HandLeft, ShoulderRight, ElbowRight, and HandRight) | - DNN MyNet1D-D | - | - Acc 99.2% - Pr 99.1% - Recall rate 98.9% |
| [59] | - Depth | - Get the 3D point cloud images - Generate the 3D human point cloud - Foreground map by segmentation - Estimate the height of the human point cloud | (1) Speed, and height of the user’s point cloud (2) Inactivity time | - Fixed thresholding | (2) 10 s | - Acc 99% |
| [105] | - Skeletal | - Calibration - Coordinate transformation from 2D data to 3D - Normalization with the Euclidean norm | (1) 3D position of the 20 joints | - BPNN | - | - Acc 98.5% |
| [104] | - Skeletal | - | (1) Body centroid height * (2) Left hip angle (3) Right hip angle (4) Left knee angle (5) Right knee angle (6) Left feet height * (7) Right feet height * | - ResNet modified | - | - Acc 98.51% - Pr 99.02% - Recall 98.06% - F1 score 98.54% |
| [44] | - Depth | - Resized the depth input frames to 224 × 224 × 3 - Normalize the depth values - Apply a color map to produce a RGB frames | (1) Visual features using ResNet | - LSTM | - | - Acc 98% - Pr 97% - Se 100% - Sp 97% |
| [100] | - Depth | - Extract the 3D human upper body and the head through random forest classifier - Mean-shift clustering | (1) Human head height * (2) Upper body center * (3) Inactivity (4) Human-bed position | - LMNN | (2) 0.3 m (3) >3 s | - Acc 92.3% - Error 7.7% - Pr 97.8% - Se 86.6% - Sp 98.1% |
| [91] | - Skeletal | - FFT image encryption | (1) Height and width of the circumscrid rectangle of the skeleton image | - K-means | - | - |
| [63] | - Depth | - Median filter - Background elimination - Morphological operations - Speed constraint | (1) Inclinaison angle (2) Aspct ratio of the bounding rectangle (3) Average distance of ellipse’s center * | - Fixed thresholding - SVM | - | - Mean Se 98.52% - Mean Sp 97.35% |
| [84] | - Skeletal | - Min-max normalization - Euclidean distance - K-mean clustering to detect the limits of the transistion phase | (1) Duration of the transition phase (2) Average distance of torso joint poisition during the transition phase (3) Derived ratio of the average distance over transition phase half time | - MLP - SVM with RBF kernel | - | - Mean Acc 99.5% - Mean Pr 99.71% - Mean recall 99.95% |
| [86] | - Depth | - Background elimination - Denoising - Remove the discontinuities in the silhouette through median filter and a closing operator - Compute the 3D coordinates of the silhouette’s center | (1) More than 30 kinematic features related to the position, velocity and acceleration of the monitored person (2) Mel-cepstrum related features | - SVM - ANN - NBC | - | - Mean Se 96.25% 98.85%. |
| [69] | - Depth | - Filtration - Background substraction - Binarization - Connected component analysis | (1) Height of the region of interest | - Adaptive thresholding | - (Traget’s height) /3 | - Mean Acc 86.65% - Mean Pr 100% - Mean Recall 65.5% |
| [74] | - Depth | - Background substraction | (1) Distance of person’s central point from sensor * (2) Recovery time (3) Wind time (4) Sit time (5) Shift time | - Fixed and Adaptive Thresholding | (1) KinectHeight- 0.6 m (2) 2 s (3) 3 s (4) 3 s (5) 1 s | - Mean Acc 95.9% |
| [106] | - Skeletal | - Determine the state of equilibrium by estimating the support of base and line of gravity - Compute the dynamic position of COM of 5 kinematic chains (trunk, left arm, right arm, left leg and right leg) | (1) Accelerated velocity of COM of 5 body segments (2) 3D skeleton data | - LSTM | - | - Acc 97.41% |
| [64] | - Skeletal - 3-axs acceleration | - Median filter | (1) Signal magnitude area (2) Signal magnitude vector (3) Tilt angle between y axis and vertical direction (4) Head speed along z axis and x-y combined axis | - Fixed thresholding - SVM with RBF | - | - Acc 100% |
| [71] | - Depth | - Estimate floor plane - Generate skeletal data - Identification of fall factors (step summetry, trunk sway and arm spread) | (1) Velocity and height * of subject | - Adaptive thresholding | - | - Acc 88.57% - Pr 80.56% - Se 96.67% - Sp 82.5% |
| [78] | - Depth | - Foreground segmentation - Filtering/erosion/hole filling/ blob analysis - Random decision features to recognize the posture(stantind, sitting, lying) | (1) Change in lying posture confidence levels | - SVM | - | - Acc 96% - Pr 91% - Se 100% - Sp 93% |
| [70] | - Skeletal | - Generate the collection of Skeleton stream using the 20 joints - Build the adaptive directional bounding box to rotate virtually the camera view in ordre to the fall be in front view | (1) Aspect ratio of DHW(DW to DH) (2) Aspect ratio of center of gravity (COG) (3) Aspect ratio of diagonal line (DGNL) (4) Aspect ratio of bonding box -Height (BB-Height) | - Adaptive thresholding | (1) 1.38–3.20 (2) 0.27 (3) 0.85 (4) 0.81 | - Acc 98.15% - Se 97.75% - Sp 98.25% |
| [53] | - Depth | - GMM background substraction method - Apply morphological operation erosion and dilatation - Approximate head to ellipse - Particle filter - Cross product of 3 points to estimate the floor plane detection | (1) Head distance * (2) Covariance of the center of mass movement | - Fixed thresholding | - | - Mean Acc 85.97% - Mean Se 81.46% - Mean Sp 87.35% |
| [62] | - Depth | - Get the 3D position of hip center and shoulder center joints - Forme the torso line using the shoulder center and hip center joints - Use the hip center joint and a point on the y-axis to draw the gravity vector - Considered the hip center joint like as the person’s centroid - When the Kinect can not estimate the ground parameter they detecded the foot joint - Start the human torso motion model processing when the torso angle exceed 13° | (1) Max changing rate of the angle torso which formed between the torso line vector and the gravity vector (2) Max changing rate of the centroid height * (3) Tracking time | - Fixed thresholding | (1) 12°/100 ms (2) 1.21 m/s (3) 1300 ms | - Acc 97.5% - TPR 98% - TNR 97% |
| [80] | - Depth | - Person detected segmentation - Extract the data of all the detected joints | (1) Height and velocity change of the person (2) Position of the subject during and after a mouvement | - SVM | - | - Average Ac 97.39% - Sp 96.61% - Se 100% |
| [83] | - Depth | - Transforme the coordinate system from camera coordinate to the global coordinate - Foreground detection Gaussian distributed backgound; - Background susbtraction method | (1) COG (2) Vertical velocity of the COG (3) Ratio of the height and width of the bounding box (4) Ratio of floor pixels (of the detected foreground) (5) Amount of floor pixels (6) Angle of the main axes | - MLP - RBF; - SVM - DNN | - | - Acc ratio 98.15% - k 0.96 |
| [87] | - Depth | - Create a new coordinate system centered at the hip center - Calculate the 3D skeletal data regarding to the new coordinate system - Build the three anatomical planes centered at the hip center - Calculate the displacement vectors and the signed distances for the skeletl joints - Estimate the pose profile using some relational geometric characteristics | (1) Histogramme based representation of the motion-pose geometric descriptor | - SVM with a RBF kernel | - | - Mean Acc 78.77% |
| [72] | - Skeletal | - Change axis in coordinates system - Apply a sliding windows of 2 s | (1) Head velocity (2) Horizontal velocity of hip center joint (center of gravity) (3) Vertical velocity of hip center joint | - Adaptive thresholding | (1) 0.6 *((rac2 * person’s height)/2) (2) 0.55 *(person’s height/4) (3) 0.7 * (person’s height/4) | - F1 measure 94.4% |
| [67] | - Depth | - Background substraction - Noise filter - Calculate Depth histrogram of the body detected | (1) Depth range difference (2) Depth mean difference (3) Inactivity | - Adaptive thresholding | (3) 2 s | - Acc 97.2% - Error rate 2.8% - Se 94% - Sp 100% |
| [54] | - Depth | - Median filter - Canny filter - Calculate bthe the tangent vector angle of the outline binary image | (1) Percentage of tangent vector angle divided into 15° groups | - Fixed thresholding | (1) 40% | - Acc 97.1% - Error rate 2.9% - Se 94.9% - Sp 100% |
| [42] | - Depth | - Image normalization - Image polar coordinates - FFT transform | (1) Wavelet moment | - Minimum distance - SVM with linear kernel | - | - Mean Acc 91% |
| [96] | - Depth - 3-axis acceleration | - Person extraction if sum vector of acceleration >3 g using differencing technique or region growing - Floor plane extraction - Upload parameters’s floor plane through RANdom Sample Consensus - Transformation data to 3D point cloud | (1) Height to width ratio of the person’s bounding box in the maps of depth (2) Ratio of height of the person’s bounding box to the real height of person (3) Height of person’s centroid to the ground (4) Largest standard derivation from the centroid for the abscissa and the application (5) Ratio of the number of points in the cuboid to the number of points in the surrounding cuboid measured from 40 cm height (6) Sum vector of acceleration and 2 dynamic features | - Fuzzy logic | - | - Acc 97.14% - Pr 93.75% - Se 100% - Sp 95% |
| [93] | - Depth | - Human body segmentation using static background substraction - Noise removel by morphological operations - Silhouette extraction using edge detection - Generate the coodbook by K-medoids clustering | (1) Silhouette orientation volume | - BoW-Naïve bayes | - | - Mean Acc 93.84% |
| [60] | - Depth | - Person detection by background substraction - Noise filtering using erosion and dialatation operations - Model the head by an ellipse - Track the head by Praticle Filter | (1) Ratio of y-coordinate of the head’s center to the person’s height (2) Covariance of fall’s duraction and velocity of center of mass | - Fixed thresholding | - | - Acc 92.98% - Se 90.76% - Sp 93.52% |
| [48] | - Depth | - Median filter - Background substraction - Otsu algorithm - V-disparity - least squares - Convert coordinates to the world coodinate system | (1) Distance * of the approximated ellipse (2) Orientation * of the approximated ellipse | - Fixed thresholding | (1) 0.5 m (2) 45° | - |
| [81] | - Skeletal | - Devided the behvior sequences to 3 types actual fall, non-fall and ADL - Use the y-coodinates of head-left shoulder, right shoulder and torso joints | (1) 5 Body shapes and behior sequences | - SVM | - | - Mean Acc 95.89% |
| [85] | - Depth | - Human body extraction from the background using the adaptive mixture of gaussian method - Extraction of human silhouette using Canny edge detector - Generate the codebook | (1) CSS features | - Fisher vector - SVM with RBF | - | - Mean Acc 93.8% |
| [61] | - Skeletal - 3-axis acceleration | - Linearzied the samples of accelerometrs by linear regression algorithm - Sychronie one acceleration sample to one skeletal frame based on timestampes - Modeling the floor plane | (1) Varation of the y-spine base joint (2) Height of the spine base joint * (3) Acceleration magnitude (4) Angle formed between the g vector and x axis | - Fixed thresholding | (1) 0.5 m (2) 0.2 m (3) 3 g (4) 90° for 0.5 s | - Mean Se 79.3% - Mean Sp 99% |
| [98] | - Depth | - Filtering Dilation hole filling erosion and erosion - 3-D foreground segmentation - Median/average filters - Vertical state characterisation - On ground event segmentation | (1) Minimum vertical velocity (2) Maximum vertical acceleration (3) Mean of smoothed signal of the vertical state time series (4) Occlusion adjusted change in pixels (5) Minimum frame-to-frame vertical velocity | - Decision tree | - | - |
| [52] | - Depth | - Background substraction - Smooth velocity Kalman Filer - Estimated threshould random search | (1) Velocity of the height of the user bounding box (2) Velocity of the width-depth of the user bounding box (3) Inactivity | - Fixed thresholding | (1) 1.18 m/s (2) 1.2 m/s (3) 2 s | - Se 100% |
| [73] | - Skeletal - Audio | - | (1) Positions * of some joints (head, shouldercenter, hipcenter, ankleright, ankleleft) | - Fixed and adaptive thresholding | 0.3 m or 0.7 * target’s height | - Mean Acc 81.25% |
| [58] | - Depth | - Foreground segmentation - Floor uniformization - Substitues the null pixels - Edge detection using sobel filter - Generate the super-pixel frame 40 × 40 - Split the object in the depth scene - Idententification of the human subjects through (head-ground/head- shoulder distance gap and the appropriate head dimension) | (1) height * of the person’s central point | - Fixed thresholding | (1) 0.4 m | - |
| [82] | - Skeletal | - Compute gound plane using V-disparity the Hough transform or the SDK Kinect - Convert the 3D joint coordinate into the coordinate of the plane ground | (1) Distance * and velocity * of 5 modes composed from 8 joints (headshoulder center, spine, hip center, shoulder right, shoulder left, hip right, and hip left) (2) Angle composed between the normal of the floor plane and the line joint the head with specific joints | - SVM | - | - FN 0 (mode(2)) - FP 3.3% (mode(2)) |
| [47] | - Depth | - Kalman filter - Create the 3D human bouding Box | (1) Speed of height (2) Speed of width-depth (3) speed of y-coordinate of the top left vertex, of the user bounding box | - Fixed thresholding | (1) 1.1 m/s (2) 1.4–1.7 m/s (3) 0.5 m/s | - Reliability 97.3% - Efficiency 80% |
| [92] | - Depth | - Foreground segmentation GMM - Countour detection canny edge detector - Use K-means to generate the codebook | (1) CSS features of the extracted human silhouette | - BoW-VPSO-ELM | - | - Mean Ac 92.02% - Mean Se 95.54% - Mean Sp 84.56% |
| [102] | - Depth | - Background extraction using the running average method - Denoising through erode and dilate filtres - Estimate the real word coordinate and composate the Kinect tilt angle - Detect the pixel belonging to the same object in scene using the component labelling method - Calculate the person’s center of mass | (1) Vertical position of the center of mass (2) Vertical speed and the standard derivation of all the person’s points | - Hidden Markov Model | - | - Mean Se 86.25% - Mean Sp 97.88% |
| [77] | - Skeletal | - Rigid transformation from camera coordinates to world coordinates | (1) Average Height of the shoulders (2) Vertical speed of the upper body (3) Body orientation(shoulders, torso, and hips) (4) Temporal gradient of body orientation (5) Distance between COM and COS | - Linear SVM | - | - Se 89.1% - False alarm rate 4.5% |
| [57] | - Skeletal | - Adding postural recongnition algorithm to separate the false positive and the true positive | (1) Position (2) Velocity(vertical, horizontal) of user’s hip center reprsented the center of mass | - Fixed thresholding | (2) 1.9 m/s | - Se 100% - Sp 90% |
| [56] | - Skeletal | - Calculate the floor plane equation based on the angle of the Kinect in case of difficulty having the equation given by the SDK | (1) Position * (2) Average velocity of 20 joints | - Fixed thresholding | (2) −1 m/s | - |
| [51] | - Depth | - V-disparity - Last squares algorithm - Eliminating tracking error - Calculate the mean position of the Knee | (1) Major axi’s orientation formed by the (head, shoulderCenter, spine, hip, and knee) joints in 2D and 3D (2) Height * of the spine * in 2D and 3D | - Fixed thresholding | (1) Parallel to the floor plane | - Mean Acc 87.7% - Mean Pr 92.5% - Mean recall 85% - Mean true negative rate 91.3% - Mean F-score 88.15% |
| [49] | - Depth | - Background substraction - Head detection the head model algorithm - Recongnize people HOG features modified-SVM | (1) Vertical speed (2) Distance * of the head and the body center | - Fixed thresholding | (1) 2 m/s, and 1 m/s (2) 0.5 m | - Acc 98.4% - Se 96.7% - Sp 100% |
| [97] | - Skeletal | - Removed th depth value unrealistic to room’s size or the direct neighbourhood pixel - Manuel segmentation to identify the regions in the reference image - Apply some rules to distinct person for objects in the scene | (1) Prson’s height and width (2) Ratio of corcumference to area (3) Orientattion of patches (4) Change of salopes of object’s longer axis (5) COG | - Decision tree | - | - Se 93% |
| [94] | - Depth | - Median filter - Interpolation - Decimation - Synchronization | (1) Acceleration (2) Angular velocity (3) Difference between the person’s center of gravity and the height at wich the Kinect is located | - Fuzzy logic | - | - Se 100% |
| [95] | - Depth | - Forground extraction - Median filter - Interpolation - Decimation - Synchronization | (1) acceleration (2) Angular velocity (3) Difference between the person’s center of gravity and the height at wich the Kinect is located | - Fuzzy logic | - | - Se 100% - Sp 96.4% |
| [50] | - Depth | - Median filter - Segmentation Mean shift/connected components | (1) Difference between the person’s center of gravity and the height at wich the Kinect is located | - Fixed thresholding | - | - |
| [79] | - Depth - RGB | - Generate the three dimensional motion history Images | - 7 hu-moments for each dimension of MHI | - SVM | - | - Acc 97% - Error rate 0.03% |
| [68] | - Skeletal | - | (1) Distance * (2) Vertical velocity * of the (hipcenter, head, and neck)joints | - Adaptive thresholding | - 1.5 * (distance head to neck) | - |
| [101] | - Depth | - Preson detection using background treshoulding susbtraction - Coordinate transformation from image to 3D world coordinate system - Estimate the floor level by using 2,5-th percentile of heights in image - Average the top 5% values in the y-coordinate to compute the head position to the floor | (1) Time span of fall (2) Total head height change throughout fall (3) Maximum head speed (4) Head’s height * (5) Pourcentage of frames where the head’s height is small | - Bayesian framework | - | - Pr 92% |
| [46] | - Depth | - V-disparity - Hough transform - Least squares - Background substraction - Morphological filtering | (1) Human centroid height * (2) body velocity | - Fixed thresholding | (1) 0.358 m (2) 0.63 m/s | - Success rate 98.7% |
5. The Performance Measurement Terms
6. Kinect Datasets for Fall Detection
7. Discussion
8. Conclusions
- Open and Balanced Datasets: Researchers should strive to make their datasets publicly accessible, encompassing diverse fall scenarios and daily activities performed by various volunteers. Ensuring dataset balance is crucial for robust model training.
- Multi-Sensor Integration: Combining Kinect sensor technology with other sensor types can mitigate constraints limiting system performance, such as occlusion, data scarcity, and spatial limitations in monitoring areas.
- Leveraging 3D Biomechanical Data: Focusing on utilizing skeletal data can more effectively characterize the biomechanics of the human body, while 3D data are better suited for precise motion analysis as compared to 2D data.
- Real-World Data Validation: Evaluating methods using real data acquired from retirement homes or government organizations while respecting the privacy of elderly individuals and avoiding commercial objectives is essential for real-world validation and practical applicability.
- Real-Time Performance Evaluation: Evaluating approaches in real-time scenarios should be prioritized in order to enhance their generality and suitability for practical deployment.
- Incorporating Social and Ethical Aspects: The significance of the alarm unit within each model and the importance of elderly individuals’ social lives must be acknowledged during fall detection application development.
- Dynamic Thresholds: Direct algorithm development toward adaptive thresholding is needed in order to infuse dynamism into the system, thereby improving its responsiveness to varying conditions. These techniques is more relevant than techniques based on fixed thresholds.
- Deep Learning Advancements: Embracing the application of deep learning algorithms, which have demonstrated remarkable results with minimal errors in the healthcare domain, can further enhance the reliability of fall detection systems, and issues with a lack of samples can be solved through the use of deep generative models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. WHO|Facts about Ageing; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- He, W.; Goodkind, D.; Kowal, P.; West, L.A.; Ferri, G.; Fitzsimmons, J.D.; Humes, K. An Aging World: 2015; United States Census Bureau: Suitland, MD, USA, 2016.
- Carone, G.; Costello, D. Can Europe afford to grow old. Financ. Dev. 2006, 43, 28–31. [Google Scholar]
- Ortman, J.M.; Velkoff, V.A.; Hogan, H. An Aging Nation: The Older Population in the United States; United States Census Bureau; Economics and Statistics Administration: Washington, DC, USA, 2014.
- Leung, K.M.; Chung, P.K.; Chan, A.W.; Ransdell, L.; Siu, P.M.F.; Sun, P.; Yang, J.; Chen, T.C. Promoting healthy ageing through light volleyball intervention in Hong Kong: Study protocol for a randomised controlled trial. BMC Sport. Sci. Med. Rehabil. 2020, 12, 6. [Google Scholar] [CrossRef] [PubMed]
- Berg, R.L.; Cassells, J.S. Falls in older persons: Risk factors and prevention. In The Second Fifty Years: Promoting Health and Preventing Disability; National Academies Press (US): Washington, DC, USA, 1992. [Google Scholar]
- World Health Organization (Ed.) WHO Global Report on Falls Prevention in Older Age; World Health Organization: Geneva, Switzerland, 2008. [Google Scholar]
- Heinrich, S.; Rapp, K.; Rissmann, U.; Becker, C.; König, H.H. Cost of falls in old age: A systematic review. Osteoporos. Int. 2010, 21, 891–902. [Google Scholar] [CrossRef] [PubMed]
- Turner, S.; Kisser, R.; Rogmans, W. Falls among older adults in the EU-28: Key facts from the available statistics. EuroSafe, Amsterdam; The European Public Health Association: Brussels, Belgium, 2015. [Google Scholar]
- Important Facts about Falls | Home and Recreational Safety | CDC Injury Center; CDC Injury Center: Atlanta, GA, USA, 2019.
- Bourke, A.; O’brien, J.; Lyons, G. Evaluation of a threshold-based tri-axial accelerometer fall detection algorithm. Gait Posture 2007, 26, 194–199. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Stankovic, J.A.; Hanson, M.A.; Barth, A.T.; Lach, J.; Zhou, G. Accurate, Fast Fall Detection Using Gyroscopes and Accelerometer-Derived Posture Information. In Proceedings of the BSN, Berkeley, CA, USA, 3–5 June 2009; Volume 9, pp. 138–143. [Google Scholar]
- Hwang, S.; Ryu, M.; Yang, Y.; Lee, N. Fall detection with three-axis accelerometer and magnetometer in a smartphone. In Proceedings of the International Conference on Computer Science and Technology, Jeju, Republic of Korea, 22–25 November 2012; pp. 25–27. [Google Scholar]
- Chen, Y.C.; Lin, Y.W. Indoor RFID gait monitoring system for fall detection. In Proceedings of the 2010 2nd International Symposium on Awaregs o Computing, Tainan, Taiwan, 1–4 November 2010; pp. 207–212. [Google Scholar]
- Alwan, M.; Rajendran, P.J.; Kell, S.; Mack, D.; Dalal, S.; Wolfe, M.; Felder, R. A smart and passive floor-vibration based fall detector for elderly. In Proceedings of the Information and Communication Technologies, Damascus, Syria, 24–28 April 2006; Volume 1, pp. 1003–1007. [Google Scholar]
- Li, Y.; Ho, K.; Popescu, M. A microphone array system for automatic fall detection. IEEE Trans. Biomed. Eng. 2012, 59, 1291–1301. [Google Scholar] [PubMed]
- Popescu, M.; Hotrabhavananda, B.; Moore, M.; Skubic, M. VAMPIR-an automatic fall detection system using a vertical PIR sensor array. In Proceedings of the 2012 6th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth) and Workshops, San Diego, CA, USA, 21–24 May 2012; pp. 163–166. [Google Scholar]
- Miaou, S.G.; Sung, P.H.; Huang, C.Y. A customized human fall detection system using omni-camera images and personal information. In Proceedings of the 1st Transdisciplinary Conference on Distributed Diagnosis and Home Healthcare, Arlington, VA, USA, 2–4 April 2006; pp. 39–42. [Google Scholar]
- Cucchiara, R.; Prati, A.; Vezzani, R. A multi-camera vision system for fall detection and alarm generation. Expert Syst. 2007, 24, 334–345. [Google Scholar] [CrossRef]
- Wang, Z.; Ramamoorthy, V.; Gal, U.; Guez, A. Possible life saver: A review on human fall detection technology. Robotics 2020, 9, 55. [Google Scholar] [CrossRef]
- Mohamed, O.; Choi, H.J.; Iraqi, Y. Fall detection systems for elderly care: A survey. In Proceedings of the 2014 6th International Conference on New Technologies, Mobility and Security (NTMS), Dubai, United Arab Emirates, 12 May 2014; pp. 1–4. [Google Scholar]
- Kandroudi, M.; Bratitsis, T. Exploring the educational perspectives of XBOX kinect based video games. Proc. ECGBL 2012, 2012, 219–227. [Google Scholar]
- Saenz-de Urturi, Z.; Garcia-Zapirain Soto, B. Kinect-based virtual game for the elderly that detects incorrect body postures in real time. Sensors 2016, 16, 704. [Google Scholar] [CrossRef]
- Gallo, L.; Placitelli, A.P.; Ciampi, M. Controller-free exploration of medical image data: Experiencing the Kinect. In Proceedings of the 2011 24th international symposium on computer-based medical systems (CBMS), Bristol, UK, 27–30 June 2011; pp. 1–6. [Google Scholar]
- Zhu, L.; Zhou, P.; Pan, A.; Guo, J.; Sun, W.; Wang, L.; Chen, X.; Liu, Z. A survey of fall detection algorithm for elderly health monitoring. In Proceedings of the 2015 IEEE Fifth International Conference on Big Data and Cloud Computing, Dalian, China, 26–28 August 2015; pp. 270–274. [Google Scholar]
- Khosrow-Pour, D.B.A. Encyclopedia of Information Science and Technology, 3rd ed.; IGI Global: Hershey, PA, USA, 2015. [Google Scholar] [CrossRef]
- Zhang, Z.; Conly, C.; Athitsos, V. A survey on vision-based fall detection. In Proceedings of the 8th ACM International Conference on Pervasive Technologies Related to Assistive, Corfu, Greece, 1–3 July 2015; p. 46. [Google Scholar]
- Bet, P.; Castro, P.C.; Ponti, M.A. Fall detection and fall risk assessment in older person using wearable sensors: A systematic review. Int. J. Med. Inform. 2019, 130, 103946. [Google Scholar] [CrossRef]
- Kinect Introduced at E3. 2010. Available online: https://blogs.microsoft.com/blog/2010/06/14/kinect-introduced-at-e3/ (accessed on 10 September 2023).
- Suma, E.A.; Krum, D.M.; Lange, B.; Koenig, S.; Rizzo, A.; Bolas, M. Adapting user interfaces for gestural interaction with the flexible action and articulated skeleton toolkit. Comput. Graph. 2013, 37, 193–201. [Google Scholar] [CrossRef]
- Microsoft at MWC Barcelona: Introducing Microsoft HoloLens 2; Microsoft: Redmond, WA, USA, 2019.
- Technical Documentation, API, and Code Examples|Microsoft Docs; Microsoft: Redmond, WA, USA, 2020.
- Webb, J.; Ashley, J. Beginning Kinect Programming with the Microsoft Kinect SDK; Apress: New York, NY, USA, 2012. [Google Scholar]
- Ouvré, T.; Santin, F. Kinect: Intégrez le Capteur de Microsoft dans vos Applications Windows; Epsilon, Editions ENI: Saint-Herblain, France, 2015. [Google Scholar]
- Rahman, M. Beginning Microsoft Kinect for Windows SDK 2.0: Motion and Depth Sensing for Natural User Interfaces; Apress: New York, NY, USA, 2017. [Google Scholar]
- Cruz, L.; Lucio, D.; Velho, L. Kinect and rgbd images: Challenges and applications. In Proceedings of the 2012 25th SIBGRAPI Conference on Graphics, Patterns and Images Tutorials, Ouro Preto, Brazil, 22–25 August 2012; pp. 36–49. [Google Scholar]
- Cai, Z.; Han, J.; Liu, L.; Shao, L. RGB-D datasets using microsoft kinect or similar sensors: A survey. Multimed. Tools Appl. 2017, 76, 4313–4355. [Google Scholar] [CrossRef]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar]
- Lan, Y.; Li, J.; Ju, Z. Data fusion-based real-time hand gesture recognition with Kinect V2. In Proceedings of the 2016 9th International Conference on Human System Interactions (HSI), Portsmouth, 6–8 July 2016; pp. 307–310. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Jarraya, S.K. Computer Vision-Based Fall Detection Methods Using the Kinect Camera: A Survey. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 2018, 10, 73–92. [Google Scholar] [CrossRef]
- Ding, Y.; Li, H.; Li, C.; Xu, K.; Guo, P. Fall detection based on depth images via wavelet moment. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–5. [Google Scholar]
- Alzahrani, M.S.; Jarraya, S.K.; Ben-Abdallah, H.; Ali, M.S. Comprehensive evaluation of skeleton features-based fall detection from Microsoft Kinect v2. Signal Image Video Process. 2019, 13, 1431–1439. [Google Scholar] [CrossRef]
- Abobakr, A.; Hossny, M.; Abdelkader, H.; Nahavandi, S. Rgb-d fall detection via deep residual convolutional lstm networks. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 10–13 December 2018; pp. 1–7. [Google Scholar]
- Lockhart, T.E.; Smith, J.L.; Woldstad, J.C. Effects of aging on the biomechanics of slips and falls. Hum. Factors 2005, 47, 708–729. [Google Scholar] [CrossRef] [PubMed]
- Rougier, C.; Auvinet, E.; Rousseau, J.; Mignotte, M.; Meunier, J. Fall detection from depth map video sequences. In Proceedings of the International conference on smart homes and health telematics, Montreal, QC, Canada, 20–22 June 2011; pp. 121–128. [Google Scholar]
- Bevilacqua, V.; Nuzzolese, N.; Barone, D.; Pantaleo, M.; Suma, M.; D’Ambruoso, D.; Volpe, A.; Loconsole, C.; Stroppa, F. Fall detection in indoor environment with kinect sensor. In Proceedings of the 2014 IEEE International Symposium on Innovations in Intelligent Systems and Applications (INISTA) Proceedings, Alberobello, Italy, 23–25 June 2014; pp. 319–324. [Google Scholar]
- Yang, L.; Ren, Y.; Zhang, W. 3D depth image analysis for indoor fall detection of elderly people. Digit. Commun. Netw. 2016, 2, 24–34. [Google Scholar] [CrossRef]
- Nghiem, A.T.; Auvinet, E.; Meunier, J. Head detection using kinect camera and its application to fall detection. In Proceedings of the 2012 11th international conference on information science, signal processing and their applications (ISSPA), Montreal, QC, Canada, 2–5 July 2012; pp. 164–169. [Google Scholar]
- Kepski, M.; Kwolek, B. Human fall detection by mean shift combined with depth connected components. In Proceedings of the International Conference on Computer Vision and Graphics, Warsaw, Poland, 24–26 September 2012; pp. 457–464. [Google Scholar]
- Planinc, R.; Kampel, M. Introducing the use of depth data for fall detection. Pers. Ubiquitous Comput. 2013, 17, 1063–1072. [Google Scholar] [CrossRef]
- Mastorakis, G.; Makris, D. Fall detection system using Kinect’s infrared sensor. J. Real-Time Image Process. 2014, 9, 635–646. [Google Scholar] [CrossRef]
- Merrouche, F.; Baha, N. Fall detection using head tracking and centroid movement based on a depth camera. In Proceedings of the International Conference on Computing for Engineering and Sciences, Istanbul Turkey, 22–24 July 2017; pp. 29–34. [Google Scholar]
- Kong, X.; Meng, L.; Tomiyama, H. Fall detection for elderly persons using a depth camera. In Proceedings of the 2017 International Conference on Advanced Mechatronic Systems (ICAMechS), Xiamen, China, 6–9 December 2017; pp. 269–273. [Google Scholar]
- Fayad, M.; Mostefaoui, A.; Chouali, S.; Benbernou, S. Fall Detection Application for the Elderly in the Family Heroes System. In Proceedings of the 17th ACM International Symposium on Mobility Management and Wireless Access, Miami Beach, FL, USA, 25–29 November 2019; pp. 17–23. [Google Scholar]
- Kawatsu, C.; Li, J.; Chung, C.J. Development of a fall detection system with Microsoft Kinect. In Robot Intelligence Technology and Applications 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 623–630. [Google Scholar]
- Lee, C.K.; Lee, V.Y. Fall detection system based on kinect sensor using novel detection and posture recognition algorithm. In Proceedings of the International Conference on Smart Homes and Health Telematics, Singapore, 18–21 June 2013; pp. 238–244. [Google Scholar]
- Gasparrini, S.; Cippitelli, E.; Spinsante, S.; Gambi, E. A depth-based fall detection system using a Kinect® sensor. Sensors 2014, 14, 2756–2775. [Google Scholar] [CrossRef]
- Peng, Y.; Peng, J.; Li, J.; Yan, P.; Hu, B. Design and development of the fall detection system based on point cloud. Procedia Comput. Sci. 2019, 147, 271–275. [Google Scholar] [CrossRef]
- Merrouche, F.; Baha, N. Depth camera based fall detection using human shape and movement. In Proceedings of the 2016 IEEE International Conference on Signal and Image Processing (ICSIP), Beijing, China, 13–15 August 2016; pp. 586–590. [Google Scholar]
- Gasparrini, S.; Cippitelli, E.; Gambi, E.; Spinsante, S.; Wåhslén, J.; Orhan, I.; Lindh, T. Proposal and experimental evaluation of fall detection solution based on wearable and depth data fusion. In Proceedings of the International Conference on ICT Innovations, Lugano, Switzerland, 3–6 February 2015; pp. 99–108. [Google Scholar]
- Yao, L.; Min, W.; Lu, K. A new approach to fall detection based on the human torso motion model. Appl. Sci. 2017, 7, 993. [Google Scholar] [CrossRef]
- Panahi, L.; Ghods, V. Human fall detection using machine vision techniques on RGB—D images. Biomed. Signal Process. Control 2018, 44, 146–153. [Google Scholar] [CrossRef]
- Li, X.; Nie, L.; Xu, H.; Wang, X. Collaborative fall detection using smart phone and Kinect. Mob. Netw. Appl. 2018, 23, 775–788. [Google Scholar] [CrossRef]
- Jansi, R.; Amutha, R. Detection of fall for the elderly in an indoor environment using a tri-axial accelerometer and Kinect depth data. Multidimens. Syst. Signal Process. 2020, 31, 1207–1225. [Google Scholar] [CrossRef]
- Sowmyayani, S.; Murugan, V.; Kavitha, J. Fall detection in elderly care system based on group of pictures. Vietnam. J. Comput. Sci. 2021, 8, 199–214. [Google Scholar] [CrossRef]
- Sun, C.C.; Sheu, M.H.; Syu, Y.C. A new fall detection algorithm based on depth information using RGB-D camera. In Proceedings of the 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Xiamen, China, 6–9 November 2017; pp. 413–416. [Google Scholar]
- Bian, Z.P.; Chau, L.P.; Magnenat-Thalmann, N. A depth video approach for fall detection based on human joints height and falling velocity. In Proceedings of the International Conference on Computer Animation and Social Agents, Singapore, 9–11 May 2012. [Google Scholar]
- Sase, P.S.; Bhandari, S.H. Human fall detection using depth videos. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 546–549. [Google Scholar]
- Yajai, A.; Rasmequan, S. Adaptive directional bounding box from RGB-D information for improving fall detection. J. Vis. Commun. Image Represent. 2017, 49, 257–273. [Google Scholar] [CrossRef]
- Nizam, Y.; Mohd, M.N.H.; Jamil, M. Development of a user-adaptable human fall detection based on fall risk levels using depth sensor. Sensors 2018, 18, 2260. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Z.; Wei, Z.; Wang, S. An automatic human fall detection approach using RGBD cameras. In Proceedings of the 2016 5th International Conference on Computer Science and Network Technology (ICCSNT), Changchun, China, 10–11 December 2016; pp. 781–784. [Google Scholar]
- Mundher, Z.A.; Zhong, J. A real-time fall detection system in elderly care using mobile robot and kinect sensor. Int. J. Mater. Mech. Manuf. 2014, 2, 133–138. [Google Scholar] [CrossRef]
- Spinsante, S.; Fagiani, M.; Severini, M.; Squartini, S.; Ellmenreich, F.; Martelli, G. Depth-based fall detection: Outcomes from a real life pilot. In Proceedings of the Italian Forum of Ambient Assisted Living, Catania, Italy, 21–23 February 2018; pp. 287–299. [Google Scholar]
- Kong, X.; Meng, Z.; Nojiri, N.; Iwahori, Y.; Meng, L.; Tomiyama, H. A hog-svm based fall detection iot system for elderly persons using deep sensor. Procedia Comput. Sci. 2019, 147, 276–282. [Google Scholar] [CrossRef]
- Seredin, O.; Kopylov, A.; Huang, S.C.; Rodionov, D. A Skeleton Features-Based Fall Detection Using Microsoft Kinect V2 with One Class-Classifier Outlier Removal. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W12, 189–195. [Google Scholar] [CrossRef]
- Davari, A.; Aydin, T.; Erdem, T. Automatic fall detection for elderly by using features extracted from skeletal data. In Proceedings of the 2013 International Conference on Electronics, Computer and Computation (ICECCO), Ankara, Turkey, 7–9 November 2013; pp. 127–130. [Google Scholar]
- Abobakr, A.; Hossny, M.; Nahavandi, S. A skeleton-free fall detection system from depth images using random decision forest. IEEE Syst. J. 2017, 12, 2994–3005. [Google Scholar] [CrossRef]
- Dubey, R.; Ni, B.; Moulin, P. A depth camera based fall recognition system for the elderly. In Proceedings of the International Conference Image Analysis and Recognition, Aveiro, Portugal, 25–27 June 2012; pp. 106–113. [Google Scholar]
- Mohd, M.N.H.; Nizam, Y.; Suhaila, S.; Jamil, M.M.A. An optimized low computational algorithm for human fall detection from depth images based on Support Vector Machine classification. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 407–412. [Google Scholar]
- Yoon, H.J.; Ra, H.K.; Park, T.; Chung, S.; Son, S.H. FADES: Behavioral detection of falls using body shapes from 3D joint data. J. Ambient. Intell. Smart Environ. 2015, 7, 861–877. [Google Scholar] [CrossRef]
- Le, T.L.; Morel, J. An analysis on human fall detection using skeleton from Microsoft Kinect. In Proceedings of the 2014 IEEE Fifth International Conference on Communications and Electronics (ICCE), Danang, Vietnam, 30 July–1 August 2014; pp. 484–489. [Google Scholar]
- Su, M.C.; Liao, J.W.; Wang, P.C.; Wang, C.H. A smart ward with a fall detection system. In Proceedings of the 2017 IEEE International Conference on Environment and Electrical Engineering and 2017 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Milan, Italy, 6–9 June 2017; pp. 1–4. [Google Scholar]
- Patsadu, O.; Watanapa, B.; Dajpratham, P.; Nukoolkit, C. Fall motion detection with fall severity level estimation by mining kinect 3D data stream. Int. Arab J. Inf. Technol. 2018, 15, 378–388. [Google Scholar]
- Aslan, M.; Sengur, A.; Xiao, Y.; Wang, H.; Ince, M.C.; Ma, X. Shape feature encoding via fisher vector for efficient fall detection in depth-videos. Appl. Soft Comput. 2015, 37, 1023–1028. [Google Scholar] [CrossRef]
- Mazurek, P.; Wagner, J.; Morawski, R.Z. Use of kinematic and mel-cepstrum-related features for fall detection based on data from infrared depth sensors. Biomed. Signal Process. Control 2018, 40, 102–110. [Google Scholar] [CrossRef]
- Alazrai, R.; Momani, M.; Daoud, M.I. Fall detection for elderly from partially observed depth-map video sequences based on view-invariant human activity representation. Appl. Sci. 2017, 7, 316. [Google Scholar] [CrossRef]
- Jeffin Gracewell, J.; Pavalarajan, S. Fall detection based on posture classification for smart home environment. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 3581–3588. [Google Scholar] [CrossRef]
- Maldonado-Mendez, C.; Hernandez-Mendez, S.; Torres-Muñoz, D.; Hernandez-Mejia, C. Fall detection using features extracted from skeletal joints and SVM: Preliminary results. Multimed. Tools Appl. 2022, 81, 27657–27681. [Google Scholar] [CrossRef]
- Mansoor, M.; Amin, R.; Mustafa, Z.; Sengan, S.; Aldabbas, H.; Alharbi, M.T. A machine learning approach for non-invasive fall detection using Kinect. Multimed. Tools Appl. 2022, 81, 15491–15519. [Google Scholar] [CrossRef]
- Kong, X.; Meng, Z.; Meng, L.; Tomiyama, H. A privacy protected fall detection iot system for elderly persons using depth camera. In Proceedings of the 2018 International Conference on Advanced Mechatronic Systems (ICAMechS), Zhengzhou, China, 25 October 2018; pp. 31–35. [Google Scholar]
- Ma, X.; Wang, H.; Xue, B.; Zhou, M.; Ji, B.; Li, Y. Depth-based human fall detection via shape features and improved extreme learning machine. IEEE J. Biomed. Health Inform. 2014, 18, 1915–1922. [Google Scholar] [CrossRef] [PubMed]
- Akagündüz, E.; Aslan, M.; Şengür, A.; Wang, H.; İnce, M.C. Silhouette orientation volumes for efficient fall detection in depth videos. IEEE J. Biomed. Health Inform. 2016, 21, 756–763. [Google Scholar] [CrossRef] [PubMed]
- Kepski, M.; Kwolek, B.; Austvoll, I. Fuzzy inference-based reliable fall detection using kinect and accelerometer. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 29 April–3 May 2012; pp. 266–273. [Google Scholar]
- Kepski, M.; Kwolek, B. Fall detection on embedded platform using kinect and wireless accelerometer. In Proceedings of the International Conference on Computers for Handicapped Persons, Linz, Austria, 11–13 July 2012; pp. 407–414. [Google Scholar]
- Kwolek, B.; Kepski, M. Fuzzy inference-based fall detection using kinect and body-worn accelerometer. Appl. Soft Comput. 2016, 40, 305–318. [Google Scholar] [CrossRef]
- Marzahl, C.; Penndorf, P.; Bruder, I.; Staemmler, M. Unobtrusive fall detection using 3D images of a gaming console: Concept and first results. In Ambient Assisted Living; Springer: Berlin/Heidelberg, Germany, 2012; pp. 135–146. [Google Scholar]
- Stone, E.E.; Skubic, M. Fall detection in homes of older adults using the Microsoft Kinect. IEEE J. Biomed. Health Inform. 2014, 19, 290–301. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.; Yun, G.; Park, S.K.; Kim, D.H. Fall detection for the elderly based on 3-axis accelerometer and depth sensor fusion with random forest classifier. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 4611–4614. [Google Scholar]
- Zhao, F.; Cao, Z.; Xiao, Y.; Mao, J.; Yuan, J. Real-time detection of fall from bed using a single depth camera. IEEE Trans. Autom. Sci. Eng. 2018, 16, 1018–1032. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, W.; Metsis, V.; Athitsos, V. A viewpoint-independent statistical method for fall detection. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 3626–3630. [Google Scholar]
- Dubois, A.; Charpillet, F. Human activities recognition with RGB-Depth camera using HMM. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 4666–4669. [Google Scholar]
- Tsai, T.H.; Hsu, C.W. Implementation of Fall Detection System Based on 3D Skeleton for Deep Learning Technique. IEEE Access 2019, 7, 153049–153059. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, S.; Wang, Z.; Rao, Y. ReFall: Real-Time Fall Detection of Continuous Depth Maps with RFD-Net. In Proceedings of the Chinese Conference on Image and Graphics Technologies, Beijing, China, 23–25 August 2019; pp. 659–673. [Google Scholar]
- Xu, Y.; Chen, J.; Yang, Q.; Guo, Q. Human Posture Recognition and fall detection Using Kinect V2 Camera. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8488–8493. [Google Scholar]
- Xu, T.; Zhou, Y. Elders’ fall detection based on biomechanical features using depth camera. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 1840005. [Google Scholar] [CrossRef]
- Reece, A.C.; Simpson, J.M. Preparing older people to cope after a fall. Physiotherapy 1996, 82, 227–235. [Google Scholar] [CrossRef]
- Fleming, J.; Brayne, C. Inability to get up after falling, subsequent time on floor, and summoning help: Prospective cohort study in people over 90. BMJ 2008, 337, a2227. [Google Scholar] [CrossRef]
- Cummings, S.R.; Kelsey, J.L.; Nevitt, M.C.; O’DOWD, K.J. Epidemiology of osteoporosis and osteoporotic fractures. Epidemiol. Rev. 1985, 7, 178–208. [Google Scholar] [CrossRef]
- Pannurat, N.; Thiemjarus, S.; Nantajeewarawat, E. Automatic fall monitoring: A review. Sensors 2014, 14, 12900–12936. [Google Scholar] [CrossRef]
- Vlaeyen, E.; Deschodt, M.; Debard, G.; Dejaeger, E.; Boonen, S.; Goedemé, T.; Vanrumste, B.; Milisen, K. Fall incidents unraveled: A series of 26 video-based real-life fall events in three frail older persons. BMC Geriatr. 2013, 13, 103. [Google Scholar] [CrossRef] [PubMed]
- Charlton, K.; Murray, C.M.; Kumar, S. Perspectives of older people about contingency planning for falls in the community: A qualitative meta-synthesis. PLoS ONE 2017, 12, e0177510. [Google Scholar] [CrossRef] [PubMed]
- Provost, F.; Kohavi, R. Glossary of terms. J. Mach. Learn. 1998, 30, 271–274. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Proceedings of the Australasian joint conference on artificial intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]
- Liu, Y.; Wang, N.; Lv, C.; Cui, J. Human body fall detection based on the Kinect sensor. In Proceedings of the 2015 8th International Congress on Image and Signal Processing (CISP), Shenyang, China, 14–16 October 2015; pp. 367–371. [Google Scholar]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Medica Biochem. Medica 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Xu, T.; Zhou, Y.; Zhu, J. New advances and challenges of fall detection systems: A survey. Appl. Sci. 2018, 8, 418. [Google Scholar] [CrossRef]
- Zhang, Z.; Conly, C.; Athitsos, V. Evaluating depth-based computer vision methods for fall detection under occlusions. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 8–10 December 2014; pp. 196–207. [Google Scholar]
- Kwolek, B.; Kepski, M. Human fall detection on embedded platform using depth maps and wireless accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
{kind=link}
{kind=link}
{kind=link}
| Features | Kinect V1 | Kinect V2 | Azure Kinect |
|---|---|---|---|
| Sensors | RGB 3D Depth 4-mic progressif linear array Accelerometer 3 axis | RGB 3D Depth 4-mic progressif linear array Accelerometer 3 axis | RGB 3D Depth 7-mic circular array Accelerometer 3 axis Gyroscope 3 axis |
| Color stream | 640 × 480 @30 fps | 1920 × 1080 @30 fps 1920 × 1080 @15 fps | 3840 × 2160 @30 fps |
| Depth stream | 320 × 240 @30 fps | 512 × 424 @30 fps | 640 × 576 @30 fps 512 × 512 @30 fps 1024 × 1024 @15 fps |
| Operating range | 0.8∼4.5 m | 0.5∼4.5 m | 0.5∼3.86 m |
| View angles (H × V) | 57° × 43° | 70° × 60° | 75° × 65° |
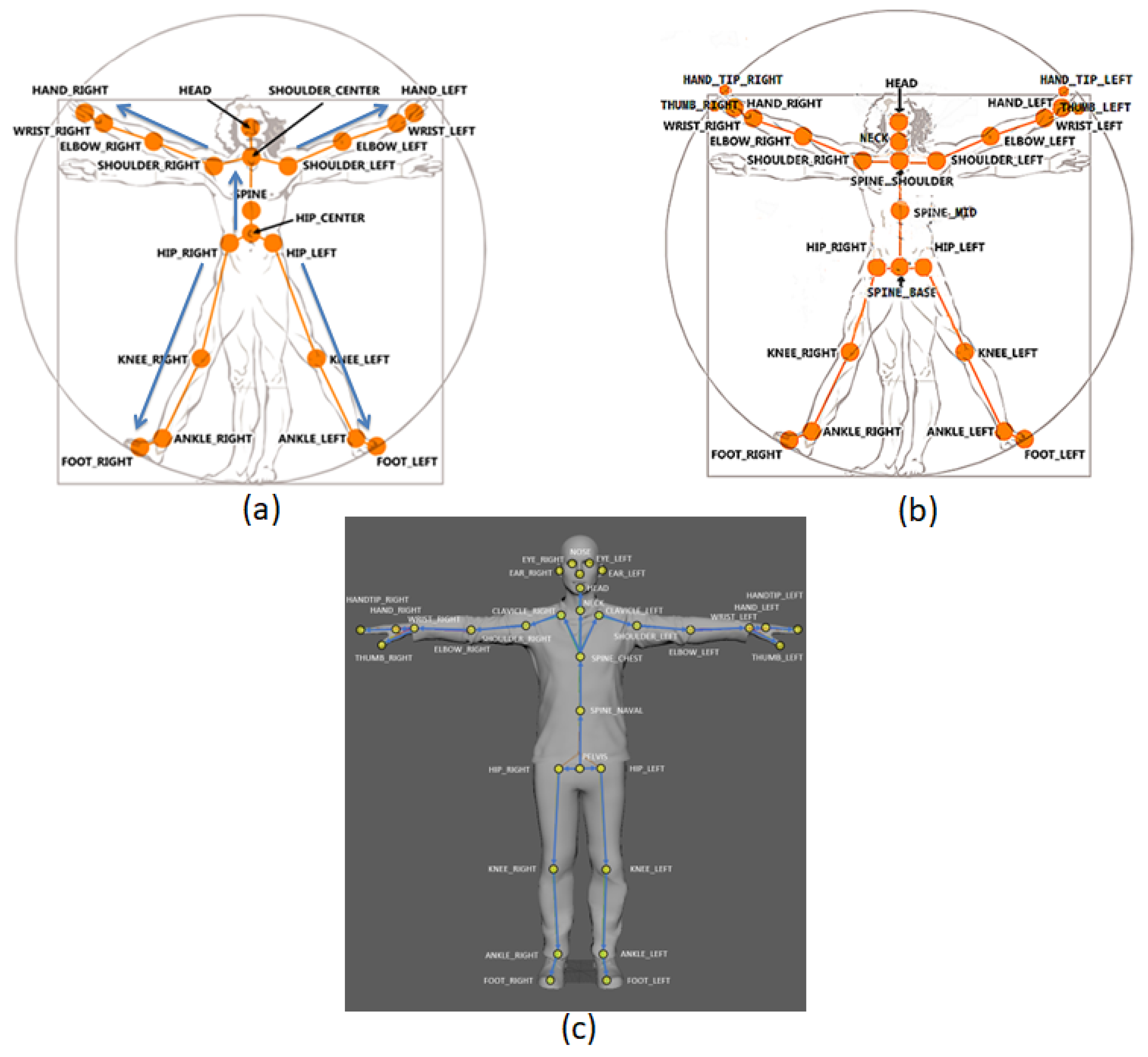
| Joints per person | 20 | 25 | 31 |
| Depth method | Structured light | TOF | TOF |
| Tilt motor | Motorized (up down 27°) | Manual | Manual |
| Hardware Requirements | Dual-core 2.66 GHz 2 GB RAM | Dual-core 3.1 GHz DX11 graphics processor 4 GB RAM | Dual-core 2.4 GHz HD620 graphics processor 4 GB RAM |
| Supported OS | Win 7, Win 8 Win embedded standard 7 | Win 8 Win embedded 8 | Win 10 Ubuntu 18.04 |
| Connectivity | USB 2.0 | USB 3.0 | USB 3.0 |
| Kinect V1 | Kinect V2 | Azure Kinect | |
|---|---|---|---|
| Number of body tracked simultaneously | 2 | 6 | N/A a |
| Number of joint per person | 20 | 25 | 32 |
| Enumerates of Joints in SDK | 0-Hip_Center 1-Spine 2-Shoulder_Center 3-Head 4-Shoulder_Left 5-Elbow_Left 6-Wrist_Left 7-Hand_Left 8-Shoulder_Right 9-Elbow_Right 10-Wrist_Right 11-Hand_Right 12-Hip_Left 13-Knee_Left 14-Ankle_Left 15-Foot_Left 16-Hip_Right 17-Knee_Right 18-Ankle_Right 19-Foot_Right | 0-Spine_Base 1-Spine_Mid 2-Neck 3-Head 4-Shoulder_Left 5-Elbow_Left 6-Wrist_Left 7-Hand_Left 8-Shoulder_Right 9-Elbow_Right 10-Wrist_Right 11-Hand_Right 12-Hip_Left 13-Knee_Left 14-Ankle_Left 15-Foot_Left 16-Hip_Right 17-Knee_Right 18-Ankle_Right 19-Foot_Right 20-Spine_Shoulder 21-HandTip_Left 22-Thumb_Left 23-HandTip_Right 24-Thumb_Right | 0-Pelvis 1-Spine_Naval 2-Spine_Chest 3-Neck 4-Clavicle_Left 5-Shoulder_Left 6-Elbow_Left 7-Wrist_Left 8-Hand_Left 9-Handtip_Left 10-Thumb_Left 11-Clavicle_Right 12-Shoulder_right 13-Elbow_Right 14-Wrist_Right 15-Hand_Right 16-Handtip_Right 17-Thumb_Right 18-Hip_Left 19-Knee_Left 20-Ankle_Left 21-Foot_Left 22-Hip_Right 23-Knee_Right 24-Ankle_Right 25-Foot_Right 26-Head 27-Nose 28-Eye_Left 29-Ear_Left 30-Eye_Right 31-Ear_Right |
| Development language | C++, C#, VB | C++, C#, VB | C, C++ |
| Real Situation | |||
|---|---|---|---|
| Fall | No-Fall/ADLs | ||
| predicted situation | Fall | TP | FP |
| No-fall/ADLs | FN | TN | |
| Dataset | Year | Devices | Data | Size | Contens |
|---|---|---|---|---|---|
| ZZ-VA | 2012 | 2 Kinect V1 | Depth | 12 sequences performed by 6 subjects | Depth frames Number of start and end frame for fall |
| EDF | 2014 | 2 Kinect V1 | Depth | 110 actions performed by 5 subjects | Depth frame Number of start and end frame for fall The parameters of floor plane estimation |
| OCCU | 2014 | 2 Kinect V1 | Depth | 140 actions performed by 5 subjects | Depth frame Number of start and end frame for fall The parameters of floor plane estimation |
| SDUFall | 2014 | Kinect V1 | Depth | 1800 video clips performed by 10 young and woman subjects | Depth video in 320 × 240 @30 fps |
| URFD | 2014 | 2 Kinect V1 PS-Move x-IMU | Depth RGB Acceleration | 70 video sequences performed by 5 subjects | Acceleration value along x, y and z axis. Signal magnitude vector of acceleration. Ratio of the person’s bounding box height to width. Ratio of Major to minor axis of the segmented person. Standard derivation of pixels from the centroid for the X axis and Z axis. Ratio of the bounding box occupancy. Ratio of human heigh in current frame to the physical human height while standing. Actual height of the person. Distance from the person’s centroid to the ground. Ratio of the number of point clouds attached to the cuboid of 40 cm height to the cuboid of person’s height. |
| TSTv1 | 2014 | Kinect V1 | Depth | 20 tests performed by 4 volunters aged between 26–27 and measuring 1.62 to 1.78 m | Depth frames in 320 × 240 pixels |
| TSTv2 | 2015 | Kinect V2 2 IMU shimmer | Depth Skeletal Acceleration | 264 sequences performed by 11 young actors from 22 to 39 years with different height 1.62–1.97 m | Depth frames Acceleration streams Skeleton joints in depth and skeleton space Timestamps |
| IRMTv1 | 2018 | 2 Kinect V1 | Depth | 160 sequences performed by 2 males in their mid-twenties | Depth value of the points in imaged scene (background and frame) |
| Dataset | Types of Events | Available from (*) |
|---|---|---|
| ZZ-VA | Real falls Picking up object from the ground Tying shoelaces Sitting-Lying on the floor Lying down-Jumping on the bed Opening-Closing a drawer at ground level | http://vlm1.uta.edu/~zhangzhong/fall_detection/ |
| EDF | Falls Picking up object from the ground Sitting on the ground Lying down on the ground | https://sites.google.com/site/occlusiondataset/ |
| OCCU | Totally occuled falls un-occluded picking up something from the ground un-occluded sitting on the ground un-occluded tying shoelaces Lying down on the ground(end frame is totally occluded) | https://sites.google.com/site/occlusiondataset/ |
| SDUFall | Falling down Bending Squatting Sitting Lying Walking | https://sites.google.com/view/haibowang/home |
| URFD | Falls from standing Falls from sitting on the chair Walking Sitting down Lying on the floor Lying on bed/sofa Bending to take or putt an object from the floor Ting laces Crouching down | http://fenix.univ.rzeszow.pl/~mkepski/ds/uf.html |
| TSTv1 | FallsTwo or more people waling | https://ieee-dataport.org/documents/tst-fall-detection-dataset-v1 https://www.tlc.dii.univpm.it/research/processing-of-rgbd-signals-for-the-analysis-of-activity-daily-life/Kinect-based-dataset-for-motion-analysis |
| TSTv2 | Fall forward and ends up lyojng Fall backward and ends up lying/sitting Fall lateral and ends up lying Sitting on a chair Walking and Picking an object from the floor Walking back and forth Lying down on the floor | https://ieee-dataport.org/documents/tst-fall-detection-dataset-v2 https://www.tlc.dii.univpm.it/research/processing-of-rgbd-signals-for-the-analysis-of-activity-daily-life/Kinect-based-dataset-for-motion-analysis |
| IRMTv1 | Fall forward when (trying-always) to sit on a chair with and without rotation Fall lateral when(trying-always) to sit on a chair without rotation Fall forward-backward when trying to sit on the floor with and without rotation Fall forward-backward from standing with and without rotation Fall lateral without rotation Fall forward when walking wwith and without rotation Fall dorward against the wall without rotation Fall lateral from (trying-always) lying on a bed without rotation Sitting down on a chair + slowlySitting down on the floor + slowly Rising from a sitting position on a chair-the floor Rising from a lying position on the floor-a bed Rising from one’s knees-crouching position Lying down on a bed-on the floor Kneeling-Crouching down on the floor Standing still Bending to pick up an object from the floor Stretching Shiflting from one foot to the other Resting against the wall Stumbling while walking with recovery | http://home.elka.pw.edu.pl/~pmazurek/ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fayad, M.; Hachani, M.-Y.; Ghoumid, K.; Mostefaoui, A.; Chouali, S.; Picaud, F.; Herlem, G.; Lajoie, I.; Yahiaoui, R. Fall Detection Approaches for Monitoring Elderly HealthCare Using Kinect Technology: A Survey. Appl. Sci. 2023, 13, 10352. https://doi.org/10.3390/app131810352
Fayad M, Hachani M-Y, Ghoumid K, Mostefaoui A, Chouali S, Picaud F, Herlem G, Lajoie I, Yahiaoui R. Fall Detection Approaches for Monitoring Elderly HealthCare Using Kinect Technology: A Survey. Applied Sciences. 2023; 13(18):10352. https://doi.org/10.3390/app131810352
Chicago/Turabian StyleFayad, Moustafa, Mohamed-Yacine Hachani, Kamal Ghoumid, Ahmed Mostefaoui, Samir Chouali, Fabien Picaud, Guillaume Herlem, Isabelle Lajoie, and Réda Yahiaoui. 2023. "Fall Detection Approaches for Monitoring Elderly HealthCare Using Kinect Technology: A Survey" Applied Sciences 13, no. 18: 10352. https://doi.org/10.3390/app131810352
APA StyleFayad, M., Hachani, M.-Y., Ghoumid, K., Mostefaoui, A., Chouali, S., Picaud, F., Herlem, G., Lajoie, I., & Yahiaoui, R. (2023). Fall Detection Approaches for Monitoring Elderly HealthCare Using Kinect Technology: A Survey. Applied Sciences, 13(18), 10352. https://doi.org/10.3390/app131810352