Abstract
Traditional methods for 3D reconstruction of unmanned aerial vehicle (UAV) images often rely on classical multi-view 3D reconstruction techniques. This classical approach involves a sequential process encompassing feature extraction, matching, depth fusion, point cloud integration, and mesh creation. However, these steps, particularly those that feature extraction and matching, are intricate and time-consuming. Furthermore, as the number of steps increases, a corresponding amplification of cumulative error occurs, leading to its continual augmentation. Additionally, these methods typically utilize explicit representation, which can result in issues such as model discontinuity and missing data during the reconstruction process. To effectively address the challenges associated with heightened temporal expenditures, the absence of key elements, and the fragmented models inherent in three-dimensional reconstruction using Unmanned Aerial Vehicle (UAV) imagery, an alternative approach is introduced—the neural radiance field. This novel method leverages neural networks to intricately fit spatial information within the scene, thereby streamlining the reconstruction steps and rectifying model deficiencies. The neural radiance field method employs a fully connected neural network to meticulously model object surfaces and directly generate the 3D object model. This methodology simplifies the intricacies found in conventional 3D reconstruction processes. Implicitly encapsulating scene characteristics, the neural radiance field allows for iterative refinement of neural network parameters via the utilization of volume rendering techniques. Experimental results substantiate the efficacy of this approach, demonstrating its ability to complete scene reconstruction within a mere 5 min timeframe, thereby reducing reconstruction time by 90% while markedly enhancing reconstruction quality.
1. Introduction
The reconstruction of 3D geometry from multiple images has been a long-standing problem in the fields of oblique photogrammetry and computer vision [1]. In the era before the advent of deep learning, traditional methods for multi-view 3D reconstruction could be broadly categorized into two groups: point- and surface-based reconstruction [2,3,4] and volumetric reconstruction [5,6,7,8,9]. Point- and surface-based reconstruction methods extract and match image features across different views by exploiting the photometric consistency [10] between images to estimate the depth value of each pixel [11]. They then fuse the depth maps into a global dense point cloud [12]. To obtain the surface, an additional meshing step such as Poisson surface reconstruction [13] is applied. The quality of reconstruction heavily relies on the accuracy of correspondence matching. Difficulties in matching correspondences for objects without rich textures often result in severe artifacts and missing parts in the reconstructed output. Furthermore, these methods with complex pipelines may accumulate errors at each stage, often resulting in incomplete 3D models. This is especially true for non-Lambertian surfaces, as they cannot handle view-dependent colors. Alternatively, volumetric reconstruction methods overcome the challenge of explicit correspondence matching by estimating occupancy and color in a voxel grid from multi-view images [14]. They then evaluate the color consistency of each voxel. Voxel-based approaches are often limited to low resolution due to their high memory consumption [15].
In contrast, neural radiance fields [16] for 3D reconstruction do not suffer from discretization artifacts, as they represent surfaces based on the level set for a neural network with continuous outputs. By combining neural radiance fields with the classic 3D reconstruction method, it is possible to reconstruct the smooth surface of a 3D object from a 2D image, showcasing its effectiveness beyond the classical 3D reconstruction method. This novel approach opens up new possibilities for research and applications in the fields of oblique photogrammetry [17] and computer vision. Despite the significant potential demonstrated by deep learning-based methods in 3D reconstruction, limited research has been conducted on their application in UAV image reconstruction [18]. Hence, it is crucial to conduct further studies and explore the potential of employing these methods in this field.
However, the quality of classical multi-view 3D reconstruction heavily depends on the accuracy of feature matching. In regions with limited texture information, feature matching becomes challenging, leading to incomplete model generation. Moreover, this traditional approach involves complex procedures and is associated with significant time costs. In recent times, the field of multi-view 3D reconstruction has witnessed remarkable advancements due to the rapid development of deep learning methods. State-of-the-art results have been achieved by research projects such as Colmap [19] and MVSnet [20]. Nevertheless, even with these advanced methods, reconstructing scenes in areas with weak textures remains a persistent challenge, and the computational time required remains high. Although neural radiance fields, represented by models like Nerf [16], have shown promise in generating complete 3D scenes, their applicability is currently limited to smaller indoor objects and scenes. Further research is needed to extend their capabilities for more diverse and complex scenes.
To address challenges like model incompleteness, discontinuity, and high time costs in UAV oblique photogrammetry 3D reconstruction, we present a fast 3D reconstruction method for UAV oblique photogrammetry based on neural radiance fields. By integrating UAV oblique photogrammetry techniques with neural radiance fields, we have developed a method that generates continuous 3D surfaces. This approach significantly improves model completeness and continuity while avoiding the need for per-pixel depth estimation, leading to a reduction in computational time.
2. Methodology
Neural radiance fields represent a 3D scene as a function with a 5D vector as its input. This function can be modeled using a neural network, allowing any scene in space to be represented by learning the parameters of the neural network. This approach enables scene reconstruction.
Given a set of UAV images I = I1, …, In, the corresponding camera pose P = (R1|t1, …,Rn|tn), camera internal parameters K = k1, …, kn in the pixel plane, a and sampling point (u, v), a ray is generated from the camera optical center o-(u, v), a series of three-dimensional points x = (x, y, z) is sampled on the ray, and the direction vector of all points is d = (θ, φ).
In Figure 1a, a depiction of points sampled along the camera ray is presented. Each individual point is characterized by a five-dimensional vector. Progressing to Figure 1b, this five-dimensional vector is utilized as input within a neural network framework. The resultant outcomes encompass both RGB values and volume density, denoted as σ. Figure 1c elucidates the transformation of these derived values into images, employing the methodology of volume rendering [13]. Ultimately, as demonstrated in Figure 1d, the rendered image and the original image are juxtaposed to compute a loss value. Subsequently, this loss value serves to iteratively refine the neural network’s parameters.
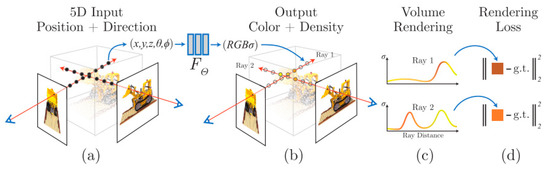
Figure 1.
An overview of neural radiance field scene reconstruction.
Since the neural network is a fully connected network (MLP), it faces limitations in simultaneously capturing both low-frequency and high-frequency information within the scene. The low-frequency information is converted into high-frequency information via Fourier transform [21] using position coding. The mapping function γ(p) is expressed as follows:
In Formula (1), p represents the vectors that need to be input into the neural network. Γ(·) is applied to each coordinate vector of x and each direction vector value of d. The hyperparameter L is determined using experimental analysis. The optimal value for the hyperparameter γ(x) is found to be 10 when γ(d) is set to 4, resulting in vectors of dimensions 60 and 24 for γ(x) and γ(d), respectively.
The following Figure 2 is the structure of the neural network:
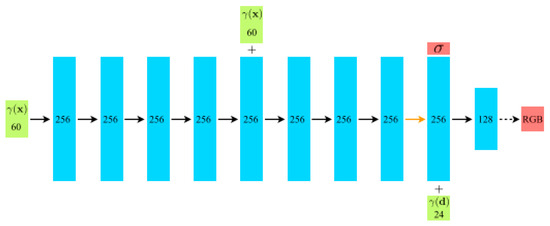
Figure 2.
Network structure diagram of neural radiance field in Figure 1.
In Figure 2, the process begins with the input location vector (γ(x)), which undergoes a sequence of transformations through 8 successive fully connected Rectified Linear Unit (ReLU) layers. Each of these layers comprises 256 channels, contributing to the extraction of complex spatial features. Subsequently, an extra layer serves a dual purpose: it produces the volume density parameter (σ), which is subjected to rectification via a ReLU activation to guarantee its non-negativity while concurrently generating a 256-dimensional feature vector. This feature vector is fused with the input viewing direction vector (γ(d)) and processed through an additional fully connected ReLU layer with 128 channels. This amalgamation enriches the model’s capacity to capture nuanced correlations between features and viewing angles. The ultimate step involves a sigmoid-activated layer that produces the emitted RGB radiance at position x, as observed from a ray directed along d.
The color value C = (r,g,b) and the volume density σ obtained from the neural network’s output are utilized in the process of volume rendering to derive the final pixel value. The loss between the volume rendering result and the original image is calculated and used as feedback to continuously optimize the reconstruction outcome.
The volume density, σx, is defined as the probability that a camera ray terminates at a microscopic particle located at position x. The color prediction value within a specified interval can be expressed as follows:
In Formula (3), the function T(t) denotes the accumulated transmittance along the ray from tn to t, i.e., the probability that the ray travels from tn to t without hitting any other particle. Since the integral equation presented earlier cannot be directly calculated numerically, Formulas (2) and (3) can be reformulated as Riemann integrals, expressed as follows:
The Riemann integral is a fundamental concept in mathematical analysis that approximates the area under a curve by dividing it into smaller intervals and summing their contributions. In Formula (4), δi = ti + 1 − ti is the distance between adjacent samples. In Formula (5), Ti represents the accumulated transmittance between point i and point j. This function for calculating (r) from the set of (ci, σi) values is trivially differentiable and reduces to traditional alpha compositing with alpha values αi = 1 − exp(−σiδi).
3. Experiments and Results
3.1. Data and Implementation Details
We perform data collection using the DJI Phantom 4 UAV. Figure 3 shows the UAV platform used in the experiments. The DJI UAV platform consists of two integral components: the aircraft itself and the integrated camera systems it carries. Detailed information is shown in Table 1.

Figure 3.
The system hardware of DJI Phantom 4.

Table 1.
Information on DJI Phantom 4 UAV.
For the acquisition of UAV imagery, we employ the publicly available dataset provided by Pix4Dmapper. Pix4Dmapper is one of the most widely used commercial software. Pix4Dmapper is a three-dimensional modeling software specifically designed for automated UAV aerial surveying. It combines the features of full automation, high-speed processing, and professional-grade precision, allowing effortless handling of UAV data and aerial imagery to achieve an automated three-dimensional modeling process.
The dataset is divided into three subsets, among which two are customized datasets. These datasets are highly representative and encompass scenes crucial for reconstruction in production operations, such as significant landmarks, large-scale apartment buildings, and small-scale villas. Table 2 is the details of the dataset.
Table 2.
Number of datasets and types of scenarios represented.
The acquired UAV imagery dataset is highly representative, encompassing scenes crucial for reconstruction in production operations, such as significant landmarks, large-scale apartment buildings, and small-scale villas. Figure 4 shows the types of scenarios.

Figure 4.
Real images captured by UAV.
We conducted experiments employing classical 3D reconstruction and neural radiance field methods, respectively. Classical 3D reconstruction methods generally use Colmap software. Colmap is a widely recognized and extensively employed software in the field of 3D reconstruction. Colmap serves as a comprehensive Structure from Motion (SFM) and Multiview Stereo (MVS) pipeline, adeptly catering to both graphical and command-line interfaces. Within its framework lies an extensive spectrum of functionalities meticulously tailored to facilitate the meticulous reconstruction of both meticulously curated and apparently disordered image assemblages. To enhance the utilization of the interactive interface, we utilized the Instant-ngp [22] software, which offers visual reconstruction results.
The input of the neural radiation field requires the pose parameters of the camera; however, the camera-captured images frequently lack these parameters. In this study, we employ the incremental SFM method to estimate the camera’s pose. The incremental pose estimation method exhibits robustness and can accurately estimate the camera’s pose across diverse environments.
We estimated the camera pose using Colmap software and conducted sparse reconstruction. Refer to Figure 5 for the visualization of the depicted camera pose and sparse reconstruction.
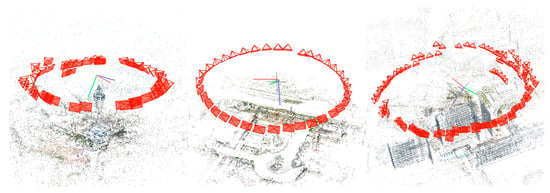
Figure 5.
Camera pose visualization.
The experiments in this study were conducted within a controlled environment using the Windows 10 operating system, an Intel i5-12400F central processing unit, an Rtx2060 graphics card, and 64 GB of memory.
3.2. Analysis and Comparison of Experimental Results
We compared the reconstruction results of the two methods from the following two aspects: (1) model reconstruction effect; (2) model reconstruction time.
3.2.1. Model Reconstruction Effect
Based on Figure 6, a meticulous visual scrutiny of the image reveals that the outcomes of the reconstruction process, as facilitated by the neural radiation field method, evince a heightened lucidity in encapsulating the architectural perimeters and vertices of the edifice. Nevertheless, a modicum of inconsequential noise subsists, which is conjecturally ascribable to the potential overexposure incurred during the image acquisition phase. In the case of Dataset 1, the resultant reconstructions stemming from the classical methodology lay bare noteworthy lacunae within the models, predominantly stemming from occlusions induced by the overhanging eaves of the structure. In stark contradistinction, the employment of the neural radiance field approach conspicuously obviates any semblance of such omissions. Dataset 2 exposes the proclivity of the conventionally adopted technique to yield a substantially uneven surface, thereby engendering a blurred demarcation of the building’s contours, particularly pronounced in regions like the spire, where conspicuous morphological distortions manifest. In contradistinction, the neural radiance field paradigm evinces a remarkable efficacy in effecting precise reconstruction of the architectural outlines, even when contending with delicate configurations such as lightning rods. A comprehensive analysis of Dataset 3 serves to underscore that the neural radiation field modality engenders superior architectural contours and a more seamlessly rendered surface reconstruction.

Figure 6.
Comparison of reconstruction results of different methods.
In Figure 7, based on detailed comparisons, it is clearly shown that our method produces reconstructed objects that are more complete with almost no missing parts. Additionally, the object outlines are sharper, and the surfaces are smoother. In comparison to our method, commonly used solutions like the open-source software Colmap and the commercial software Pix4dmapper result in reconstructed objects with rough surfaces and missing components.


Figure 7.
Comparison of details of reconstruction results by different methods.
3.2.2. Reconstruction Time
Time efficiency is a critical factor in UAV image reconstruction. In the conventional reconstruction process, dense reconstruction estimates the depth of each pixel, resulting in significant time consumption. In contrast, the neural radiance field method bypasses this step, significantly reducing the reconstruction time. Determining the completion of model training based on a specific time is infeasible for neural network training. The duration of scene reconstruction using the neural radiance field primarily depends on the speed of neural network training. Typically, a predefined number of iterations is employed to terminate the neural network training process. In this study, the reconstruction time is defined as the duration required for 60,000 iterations. Following experimental analysis, the training duration of the neural network is constrained to 30 min.
Table 3 clearly demonstrates that the neural radiance field method exhibits significantly lower time requirements compared to the classical method. With an increasing number of images, the time cost of both methods increases accordingly, albeit with a minimal increase observed in the neural radiance field method.
Table 3.
Reconstruction timetable.
3.2.3. PSNR
Peak Signal-to-Noise Ratio (PSNR) is a widely used metric to measure the quality of reconstructed images. PSNR measures the difference between the original image and the processed image by quantifying their Mean Squared Error (MSE). To compute PSNR in image processing, the original image is compared pixel by pixel with the processed image to calculate the MSE, which represents the average squared difference between corresponding pixels. The MSE is then compared to the maximum possible pixel value squared, and the result is converted to decibels (dB). The formula for PSNR is as follows:
In Formula (6), MAX represents the maximum possible pixel value in the image. For an 8-bit image, MAX would be 255. MSE is the Mean Squared Error between the original and processed images calculated as the average of the squared pixel differences. A higher PSNR value indicates a smaller distortion between the original and processed images, indicating better quality. Therefore, in image processing, a high PSNR value is often considered indicative of a better preservation of the original information and higher quality.
We computed the PSNR between our reconstruction results and the ground truth images, as shown in Table 3:
A PSNR value within the confines of 20 to 30 delineates a favorable echelon of reconstruction quality, thus signifying the efficacy of the restoration process. Our devised methodology engenders a robust and commendable performance envelope, substantiated by the comprehensive panorama of scene archetypes as tabulated in Table 4. The method’s conspicuous adaptability and augmented resilience vis à vis conventional paradigms serve to underscore its versatile utility, traversing a broad spectrum of reconstruction exigencies that span disparate contextual settings.
Table 4.
PSNR.
An inherent rationale behind the attenuated metrics recorded within Datasets 2 and 3 can be ascribed to the dominant luminosity characterizing the image acquisition phase. Our in-depth examination posits that the excessive luminance permeating the acquisition milieu could have fundamentally precipitated the observed outcomes. It is plausible that mitigating the deleterious influence arising from heightened luminous conditions during the data collection process holds significant potential in effecting a palpable enhancement in the caliber of the reconstruction outcomes.
4. Conclusions
In summary, our approach has demonstrated remarkable advancements in enhancing the efficiency of 3D reconstruction tasks using UAV imagery, surpassing the capabilities of conventional methods. Moreover, it has effectively minimized reconstruction time, resulting in a highly efficient workflow. The demonstrated robustness of our approach positions it as a reliable choice for expedited 3D reconstruction across diverse scenarios involving UAV imagery.
Highlighting our contributions, we have introduced a novel neural network architecture that specifically addresses the challenges of UAV-based 3D reconstruction. By leveraging this architecture, we have successfully achieved substantial improvements in both the reconstruction effect and processing speed. These contributions collectively contribute to the evolution of 3D reconstruction techniques in the context of UAV imagery.
The implications of our work are significant. The efficiency gains and accuracy improvements realized by our approach hold great promise for a wide range of applications. From urban planning to disaster assessment, our method’s capabilities open new avenues for leveraging UAV data in critical decision-making processes. The ability to rapidly generate detailed 3D models empowers professionals across various domains to make more informed choices. Moreover, our method boasts two key innovative features. Firstly, by seamlessly integrating a neural network into our framework, we demonstrate the immense potential of synergistic learning approaches in tackling intricate tasks like 3D reconstruction. Secondly, our dedicated efforts to minimize reconstruction time underscore our unwavering commitment to real-world usability and practicality. These groundbreaking advancements collectively enrich the realm of UAV-based 3D reconstruction and deep learning applications.
Looking ahead, our research trajectory is clear. We intend to refine our neural network structure by leveraging the latest advancements in deep learning architectures. Additionally, we will explore the integration of diverse neural networks, aiming to harness their complementary strengths for enhanced performance. Concurrently, we are dedicated to further optimizing reconstruction time using algorithmic enhancements and hardware acceleration. Expanding the scope of our work, we aspire to extend the application of deep learning-based techniques to encompass large-scale 3D reconstruction tasks spanning entire cities. This ambitious direction not only pushes the boundaries of technology but also holds immense potential for transforming urban planning, architecture, and infrastructure development. By producing comprehensive 3D models of urban environments, we hope to facilitate smarter city design, resource allocation, and sustainable development.
In conclusion, our research marks a significant step forward in the realm of UAV-based 3D reconstruction. The method’s efficiency gains, accuracy improvements, and innovative elements contribute to its relevance and applicability. As we move forward, our commitment to refining the method and expanding its scope promises to bring about transformative impacts in various domains.
Author Contributions
C.J. contributed to searching the literature, describing the model, analyzing the data and model performances, providing the figures and maps, and writing the manuscript. H.S. contributed to designing the research. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data presented in this research are available upon fair request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Galliani, S.; Lasinger, K.; Schindler, K. Gipuma: Massively parallel multi-view stereo reconstruction. In Publikationen der Deutschen Gesellschaft für Photogrammetrie, Fernerkundung und Geoinformation e. V; Geschäftsstelle der DGPF: Münster, Germany, 2016; Volume 25, p. 2. [Google Scholar]
- Agrawal, M.; Davis, L.S. A probabilistic framework for surface reconstruction from multiple images. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- De Bonet, J.S.; Viola, P. Poxels: Probabilistic voxelized volume reconstruction. In Proceedings of the International Conference on Computer Vision (ICCV), Corfu, Greece, 20–27 September 1999; Citeseer: Tokyo, Japan. [Google Scholar]
- Broadhurst, A.; Drummond, T.W.; Cipolla, R. A probabilistic framework for space carving. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Kutulakos, K.N.; Seitz, S.M. A theory of shape by space carving. Int. J. Comput. Vis. 2000, 38, 199–218. [Google Scholar] [CrossRef]
- Marr, D.; Poggio, T. Cooperative Computation of Stereo Disparity: A cooperative algorithm is derived for extracting disparity information from stereo image pairs. Science 1976, 194, 283–287. [Google Scholar] [CrossRef] [PubMed]
- Paschalidou, D.; Ulusoy, O.; Schmitt, C.; Van Gool, L.; Geiger, A. Raynet: Learning volumetric 3d reconstruction with ray potentials. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. 2009, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Merrell, P.; Akbarzadeh, A.; Wang, L.; Mordohai, P.; Frahm, J.; Yang, R.; Nistér, D.; Pollefeys, M. Real-time visibility-based fusion of depth maps. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A globally optimal algorithm for robust tv-l 1 range image integration. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. ACM Trans. Graph. (ToG) 2013, 32, 1–13. [Google Scholar] [CrossRef]
- Seitz, S.M.; Dyer, C.R. Photorealistic scene reconstruction by voxel coloring. Int. J. Comput. Vis. 1999, 35, 151–173. [Google Scholar] [CrossRef]
- Tulsiani, S.; Zhou, T.; Efros, A.A.; Malik, J. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, W.; Huang, W.; Yang, L. UAV-based oblique photogrammetry for outdoor data acquisition and offsite visual inspection of transmission line. Remote Sens. 2017, 9, 278. [Google Scholar] [CrossRef]
- Xu, Z.; Wu, L.; Shen, Y.; Li, F.; Wang, Q.; Wang, R. Tridimensional reconstruction applied to cultural heritage with the use of camera-equipped UAV and terrestrial laser scanner. Remote Sens. 2014, 6, 10413–10434. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tancik, M.; Srinivasan, P.; Mildenhall, B.; Fridovich-Keil, S.; Raghavan, N.; Singhal, U.; Ramamoorthi, R.; Barron, J.; Ng, R. Fourier features let networks learn high frequency functions in low dimensional domains. Adv. Neural Inf. Process. Syst. 2020, 33, 7537–7547. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. (ToG) 2022, 41, 1–15. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).