

Arabic Text Clustering Using Self-Organizing Maps and Grey Wolf Optimization


Abstract
1. Introduction
- A novel Arabic text clustering approach that is based on Self-Organizing Maps (SOM) and Grey Wolf Optimization (GWO).
- An extensive overview of the research that is related to our approach.
- An evaluation of our proposed approach that demonstrates its effectiveness and efficiency in comparison with other clustering techniques.
- A publicly available implementation of our proposed approach.
2. Related Work
2.1. Arabic Text Clustering
2.2. Self-Organizing Maps
2.3. Grey Wolf Optimization Algorithm
3. Background
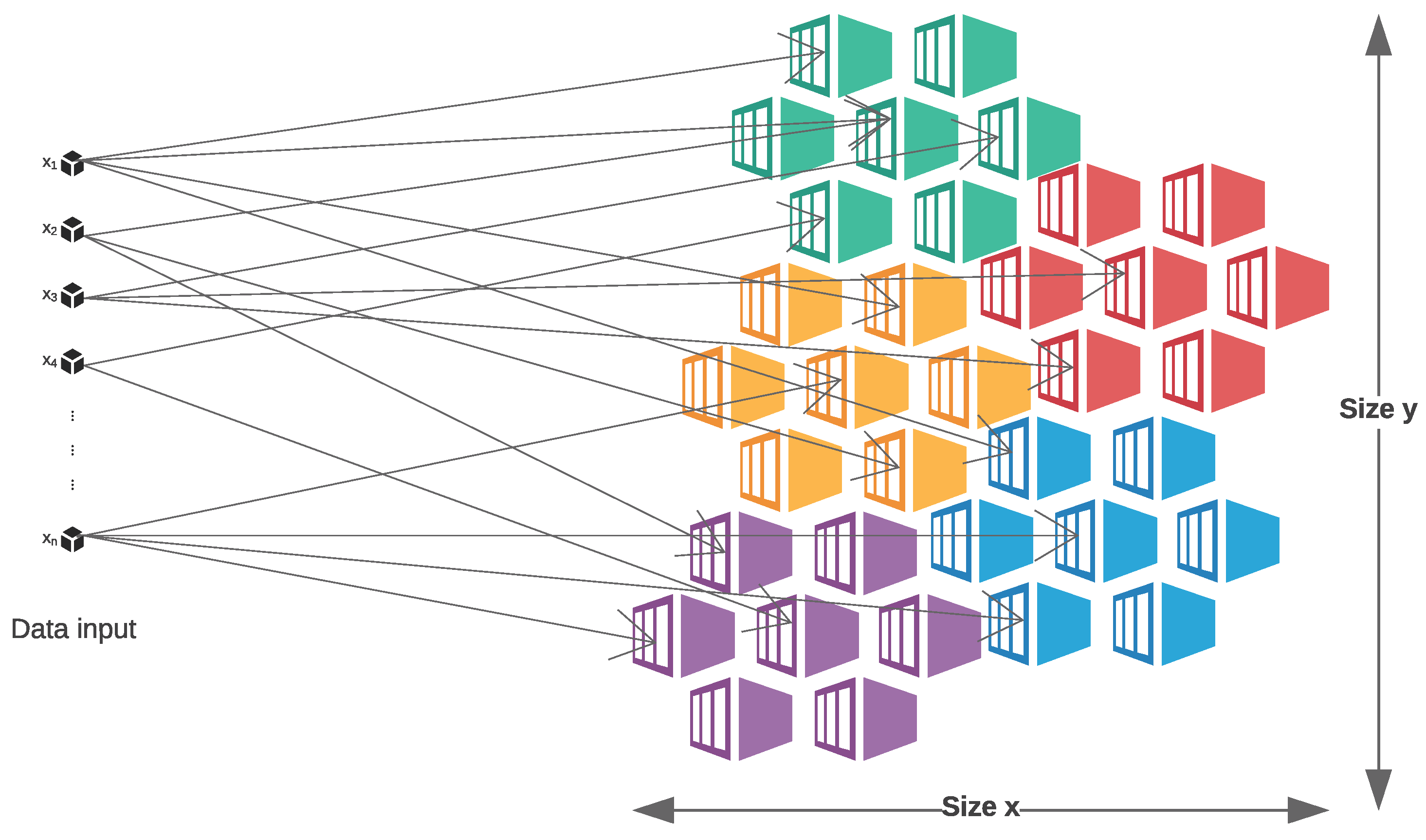
3.1. Self-Organizing Maps
- : the weights.
- t: the current iteration.
- : the learning rate.
- : the neighborhood function.
- : the input
- BMU: The Best Matching Unit reflecting the closest weight for the input instance.
3.2. Grey Wolf Optimization Algorithm
- Initialization: Initialize a population of wolves representing potential solutions to the optimization problem. The number of wolves and their positions are generated randomly.
- Fitness evaluation: Evaluate the fitness of each wolf in the population by applying the fitness function of the optimization problem.
- Alpha, beta, delta, and omega determination: Identify the alpha, beta, and delta wolves based on the population fitness values.
- Update positions of the wolves: The beta and delta wolves adjust their positions based on their current position and the position of the alpha wolf, while the omega wolves explore new positions by more random movement in the solution space.
- Repeat the second step: Evaluate the fitness of the population again after the position updates and determine the new alpha, beta, delta, and omega wolves based on their new fitness values.
- Termination criteria: Check if the termination criteria are met. The termination criteria might include a maximum number of iterations or a fit-enough solution is obtained.
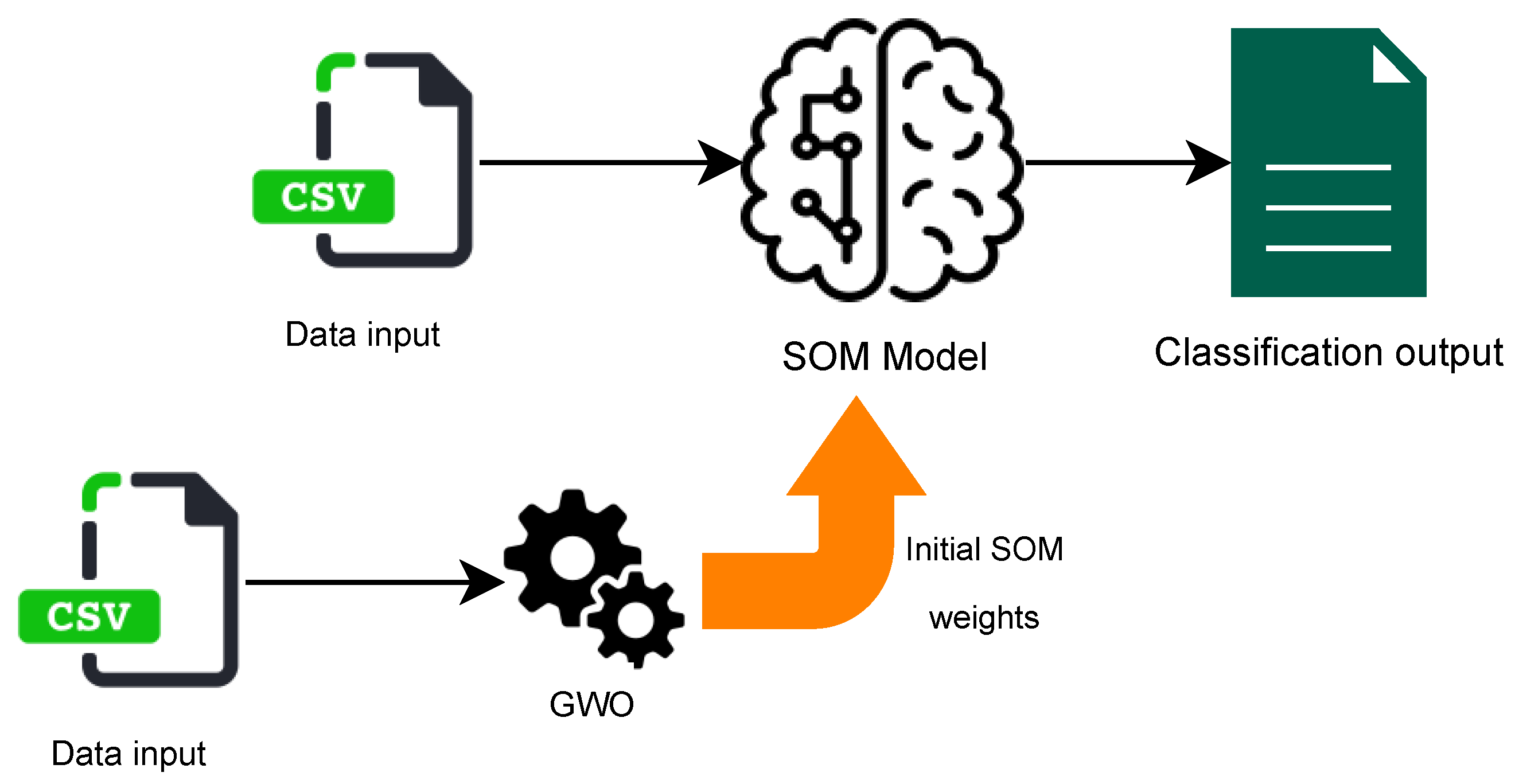
4. Proposed Approach
4.1. Phase1: Grey Wolf Optimization Algorithm
- Fitness function.
- Dimension.
- Lower bound.
- Upper bound.
- Dataset.
- Number of search agents.
4.2. Phase2: Self-Organizing Maps Optimization
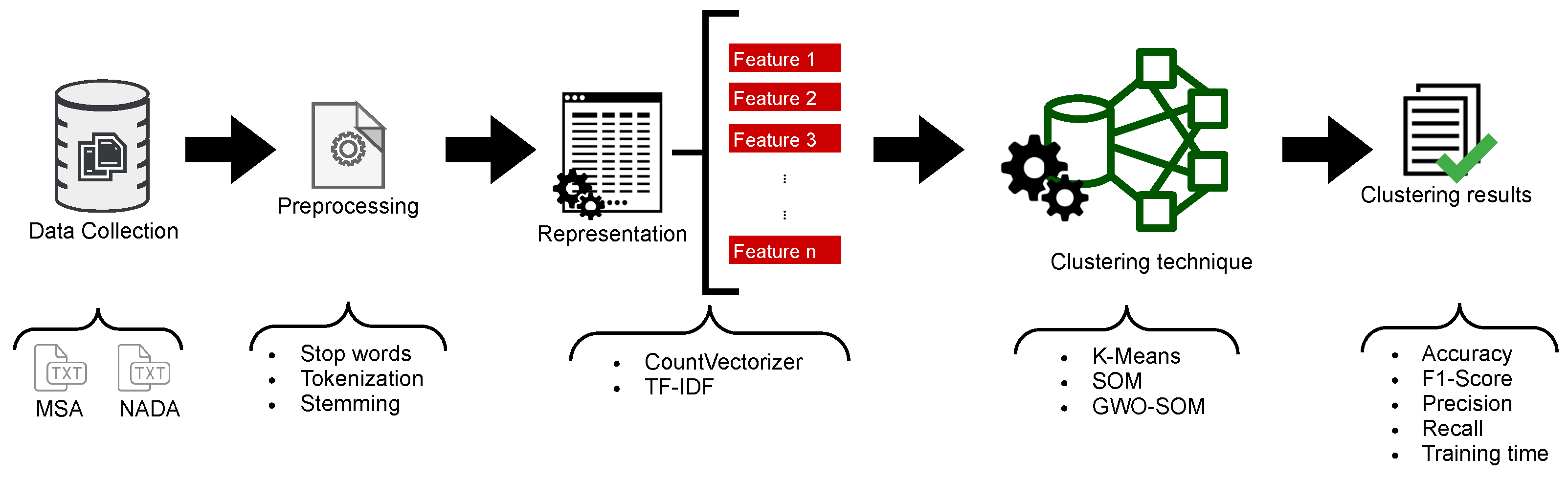
5. Experimental Evaluation
- RQ1: What is the effectiveness of GWO-optimized SOM in clustering Arabic text compared to other models?
- RQ2: How efficient are GWO-optimized SOM in clustering Arabic text compared to other models?
- RQ3: What is the impact of data representation techniques on the effectiveness and efficiency of clustering Arabic text?
5.1. Data Collection
5.2. Data Preprocessing
- Text tokenization.
- Text stemming and morphological analysis.
5.2.1. Text Tokenization
5.2.2. Stemming and Morphological Analysis
- Remove the diacritics from the Arabic word.
- Remove the prefixes from the Arabic word.
- Remove the suffixes from the Arabic word.
- Remove the connective letters from the Arabic word.
- Normalize the initial Hamza to bare Alif.
5.3. Data Representation
5.3.1. CV
5.3.2. TF-IDF Vectorizer
5.4. Clustering Techniques
- The K-Means clustering technique.
- The Self-Organizing Maps clustering technique.
- The Grey Wolf-Optimized Self-Organizing Maps clustering technique (our proposed model).
5.4.1. K-Means Clustering Technique
5.4.2. Self-Organizing Maps Clustering Technique
- : the x dimension of the map.
- : the y dimension of the map.
- D: the number of features in the dataset.
- : the sigma value representing the radius of the different neighbors in the SOM representing the different categories.
- : the learning rate value.
- t: the number of iterations (epochs).
5.4.3. Grey Wolf-Optimized Self-Organizing Maps Clustering Technique
- Divide the dataset into three portions: 60% for training, 20% for validation, and 20% for testing.
- Set the parameters of the GWO as follows:
- Fitness function: We used the QE function provided by the MiniSom python library as a fitness function for the Grey Wolf Optimization algorithm.
- Dimension: We set the dimension to be the product of the total number of corpus features by the selected SOM dimensions, and .
- The number of search agents: For the purpose of this paper, we chose the number of search agents to be five. Note that the initial experiments with different numbers of search agents were performed and the difference between their results was negligible.
- Initiate the positions of the most powerful wolves, alpha, beta, and delta. The initial positions are set as a matrix of 0 s.
- Initiate random values for the search agents with the same GWO dimension.
- Calculate the fitness value using the QE, on the validation data portion, provided by the MiniSom Python library.
- With every fitness calculation, the result is compared against the alpha, beta, and delta wolves. Accordingly, if the new fitness is less than the values of these wolves, update the wolves’ values with the new fitness.
- When a stopping criterion is met, whether completing the maximum number of iterations or having no improvement in fitness for five consecutive iterations, the GWO function terminates by passing the value of the fitness into the MiniSom to train the model.
- Test the model using the testing data portion and report the results as shown in Table 4.
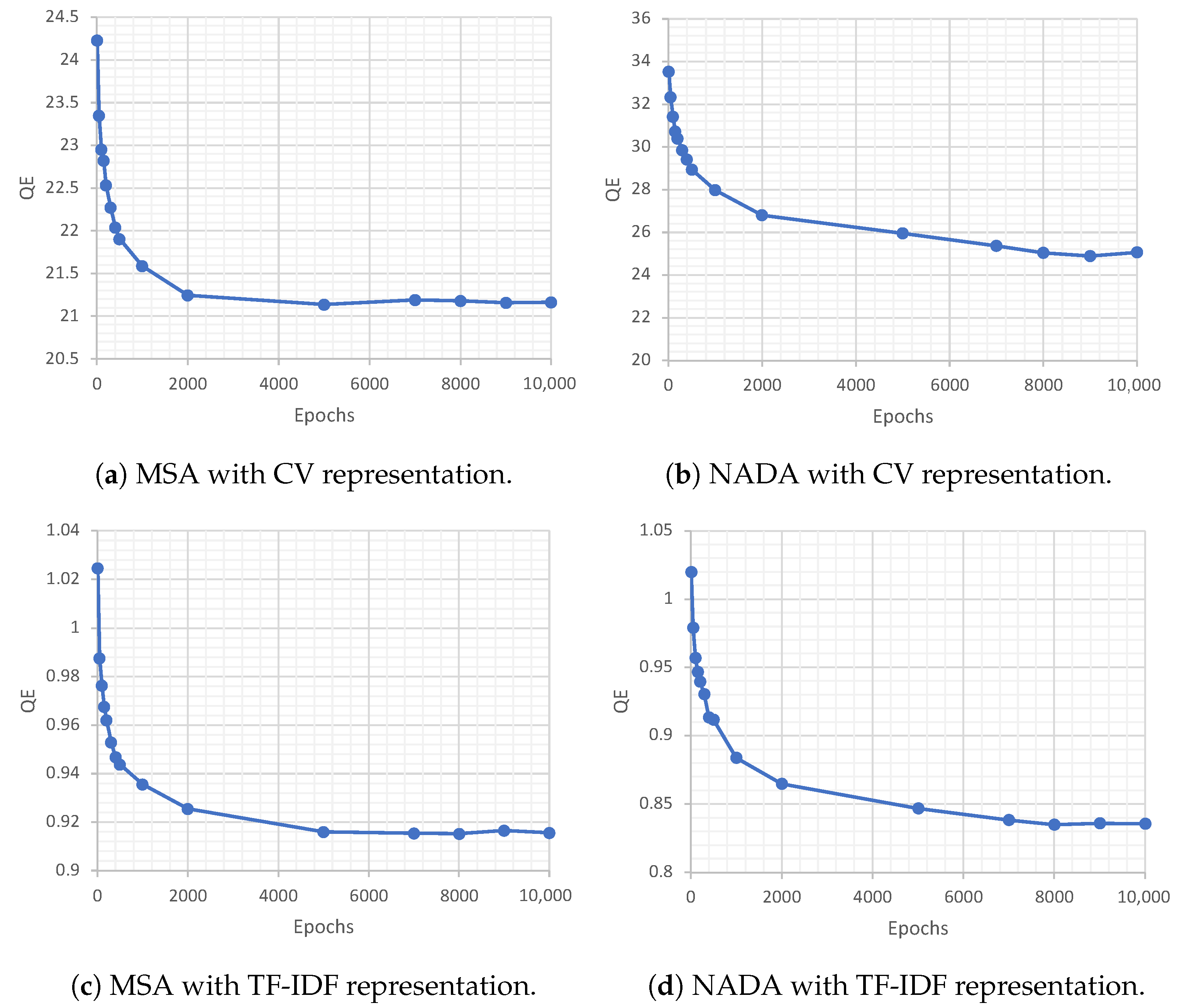
5.5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Farghaly, A.; Shaalan, K. Arabic natural language processing: Challenges and solutions. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2009, 8, 14. [Google Scholar] [CrossRef]
- Jindal, V. A Personalized Markov Clustering and Deep Learning Approach for Arabic Text Categorization. In Proceedings of the ACL 2016 Student Research Workshop, Berlin, Germany, 7–12 August 2016; pp. 145–151. [Google Scholar]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar]
- Wenchao, L.; Yong, Z.; Shixiong, X. A novel clustering algorithm based on hierarchical and K-means clustering. In Proceedings of the Control Conference, Zhangjiajie, China, 26–31 July 2007; pp. 605–609. [Google Scholar]
- Alotaibi, S.; Anderson, C. Word Clustering as a Feature for Arabic Sentiment Classification. IJ Educ. Manag. Eng. 2017, 1, 1–13. [Google Scholar] [CrossRef][Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Kriesel, D. A Brief Introduction on Neural Networks. 2007. Available online: https://www.dkriesel.com/en/science/neural_networks (accessed on 26 July 2023).
- Mahdavi, M.; Abolhassani, H. Harmony K-means algorithm for document clustering. Data Min. Knowl. Discov. 2009, 18, 370–391. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA’07, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Sahmoudi, I.; Lachkar, A. Towards a linguistic patterns for arabic keyphrases extraction. In Proceedings of the Information Technology for Organizations Development (IT4OD), Fez, Morocco, 30 March–1 April 2016; pp. 1–6. [Google Scholar]
- Al-Anzi, F.S.; AbuZeina, D. Big data categorization for arabic text using latent semantic indexing and clustering. In Proceedings of the International Conference on Engineering Technologies and Big Data Analytics (ETBDA 2016), Bangkok, Thailand, 21–22 January 2016; pp. 1–4. [Google Scholar]
- Pujari, P.S.; Waghmare, A. A Review of Merging based on Suffix Tree Clustering. In Proceedings of the National Conference on Advances in Computing, Roorkee, India, 13–15 February 2020. [Google Scholar]
- Cottrell, M.; Olteanu, M.; Rossi, F.; Villa-Vialaneix, N. Self-organizing maps, theory and applications. Rev. Investig. Oper. 2018, 39, 1–22. [Google Scholar]
- Yoshioka, K.; Dozono, H. The classification of the documents based on Word2Vec and 2-layer self organizing maps. Int. J. Mach. Learn. Comput. 2018, 8, 252–255. [Google Scholar] [CrossRef]
- Yang, H.C.; Lee, C.H.; Wu, C.Y. Sentiment discovery of social messages using self-organizing maps. Cogn. Comput. 2018, 10, 1152–1166. [Google Scholar] [CrossRef]
- Gunawan, D.; Amalia, A.; Charisma, I. Clustering articles in bahasa indonesia using self-organizing map. In Proceedings of the 2017 International Conference on Electrical Engineering and Informatics (ICELTICs), Banda Aceh, Indonesia, 18–20 October 2017; pp. 239–244. [Google Scholar]
- Liu, Y.C.; Liu, M.; Wang, X.L. Application of Self-Organizing Maps in Text Clustering: A Review; IntechOpen: London, UK, 2012; Volume 10. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Alhawarat, M.; Hegazi, M. Revisiting K-Means and Topic Modeling, a Comparison Study to Cluster Arabic Documents. IEEE Access 2018, 6, 42740–42749. [Google Scholar] [CrossRef]
- Abuaiadh, D. Dataset for Arabic Document Classification. 2014. Available online: http://diab.edublogs.org/dataset-for-arabic-document-classification (accessed on 26 July 2023).
- Al-Azzawy, D.S.; Al-Rufaye, F.M.L. Arabic words clustering by using K-means algorithm. In Proceedings of the New Trends in Information & Communications Technology Applications (NTICT), Baghdad, Iraq, 7–9 March 2017; pp. 263–267. [Google Scholar]
- Mahmood, S.; Al-Rufaye, F.M.L. Arabic text mining based on clustering and coreference resolution. In Proceedings of the Current Research in Computer Science and Information Technology (ICCIT), Sulaymaniyah, Iraq, 26–27 April 2017; pp. 140–144. [Google Scholar]
- Al-Rubaiee, H.; Alomar, K. Clustering Students’ Arabic Tweets using Different Schemes. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 276–280. [Google Scholar] [CrossRef]
- Bsoul, Q.; Atwan, J.; Salam, R.A.; Jawarneh, M. Arabic Text Clustering Methods and Suggested Solutions for Theme-Based Quran Clustering: Analysis of Literature. J. Inf. Sci. Theory Pract. (JISTaP) 2021, 9, 15–34. [Google Scholar]
- Abuaiadah, D.; Rajendran, D.; Jarrar, M. Clustering Arabic tweets for sentiment analysis. In Proceedings of the Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 449–456. [Google Scholar]
- Daoud, A.S.; Sallam, A.; Wheed, M.E. Improving Arabic document clustering using K-means algorithm and Particle Swarm Optimization. In Proceedings of the Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 879–885. [Google Scholar]
- Saad, M.K.; Ashour, W.M. OSAC: Open source arabic corpora. In Proceedings of the 6th International Conference on Electrical and Computer Systems (EECS’10), Lefke, North Cyprus, 25–26 November 2010; Volume 10. [Google Scholar]
- Newspaper, E.S. Electronic Sabq Newspaper. 2020. Available online: https://sabq.org/ (accessed on 26 July 2023).
- Souq Online Shopping. 2022. Available online: https://saudi.souq.com/sa-en/ (accessed on 26 July 2023).
- Al-Subaihin, A.A.; Al-Khalifa, H.S.; Al-Salman, A.S. A proposed sentiment analysis tool for modern arabic using human-based computing. In Proceedings of the 13th International Conference on Information Integration and Web-Based Applications and Services, Ho Chi Minh City, Vietnam, 5–7 December 2011; pp. 543–546. [Google Scholar]
- Farra, N.; Challita, E.; Assi, R.A.; Hajj, H. Sentence-level and document-level sentiment mining for arabic texts. In Proceedings of the Data Mining Workshops (ICDMW), Ho Chi Minh City, Vietnam, 5–7 December 2010; pp. 1114–1119. [Google Scholar]
- Al-Harbi, S.; Almuhareb, A.; Al-Thubaity, A.; Khorsheed, M.; Al-Rajeh, A. Automatic Arabic text classification. In Proceedings of the 9th International Conference on the Statistical Analysis of Textual Data, Lyon, France, 12–14 March 2008. [Google Scholar]
- Alanba News. 2022. Available online: https://www.alanba.com.kw (accessed on 26 July 2023).
- Alazzam, H.; AbuAlghanam, O.; Alsmady, A.; Alhenawi, E. Arabic Documents Clustering using Bond Energy Algorithm and Genetic Algorithm. In Proceedings of the 2022 13th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 21–23 June 2022; pp. 4–8. [Google Scholar] [CrossRef]
- Zeng, J.; Yin, Y.; Jiang, Y.; Wu, S.; Cao, Y. Contrastive Learning with Prompt-derived Virtual Semantic Prototypes for Unsupervised Sentence Embedding. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 7042–7053. [Google Scholar] [CrossRef]
- Kohonen, T. The’neural’phonetic typewriter. Computer 1988, 21, 11–22. [Google Scholar] [CrossRef]
- Grajciarova, L.; Mares, J.; Dvorak, P.; Prochazka, A. Biomedical image analysis using self-organizing maps. In Proceedings of the Annual Conference of Technical Computing, Prague, Czech Republic, 1 January 2012. [Google Scholar]
- Miljković, D. Brief review of self-organizing maps. In Proceedings of the MIPRO 2017, Opatija, Croatia, 22–26 May 2017. [Google Scholar]
- He, Z.; Chen, J.; Gao, M. Feature time series clustering for lithium battery based on SOM neural network. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 358–363. [Google Scholar]
- Bara, M.W.; Ahmad, N.B.; Modu, M.M.; Ali, H.A. Self-organizing map clustering method for the analysis of e-learning activities. In Proceedings of the Majan International Conference (MIC), Muscat, Oman, 19–20 March 2018; pp. 1–5. [Google Scholar]
- Simon, N.T.; Elias, S. Detection of fake followers using feature ratio in self-organizing maps. In Proceedings of the 2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computed, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), San Francisco, CA, USA, 4–8 August 2017; pp. 1–5. [Google Scholar]
- Mei, P.A.; de Carvalho Carneiro, C.; Kuroda, M.C.; Fraser, S.J.; Min, L.L.; Reis, F. Self-organizing maps as a tool for segmentation of Magnetic Resonance Imaging (MRI) of relapsing-remitting multiple sclerosis. In Proceedings of the Self-Organizing Maps and Learning Vector Quantization, Clustering and Data Visualization (WSOM), Nancy, France, 28–30 June 2017; pp. 1–7. [Google Scholar]
- Sarmiento, J.A.R.; Lao, A.; Solano, G.A. Pathway-based human disease clustering tool using self-organizing maps. In Proceedings of the Information, Intelligence, Systems & Applications (IISA), Larnaca, Cyprus, 27–30 August 2017; pp. 1–6. [Google Scholar]
- Guo, L.; Xie, Q.; Huang, X.; Chen, T. Time difference of arrival passive location algorithm based on grey wolf optimization. In Proceedings of the Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 877–881. [Google Scholar]
- Mostafa, E.; Abdel-Nasser, M.; Mahmoud, K. Application of mutation operators to grey wolf optimizer for solving emission-economic dispatch problem. In Proceedings of the Innovative Trends in Computer Engineering (ITCE), Aswan, Egypt, 19–21 February 2018; pp. 278–282. [Google Scholar]
- Xiao, J.; Zou, G.; Xie, J.; Qiao, L.; Huang, B. Identification of Shaft Orbit Based on the Grey Wolf Optimizer and Extreme Learning Machine. In Proceedings of the 2018 2nd IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 25–27 May 2018; pp. 1147–1150. [Google Scholar]
- Sankaranarayanan, S.; Swaminathan, G.; Sivakumaran, N.; Radhakrishnan, T. A novel hybridized grey wolf optimzation for a cost optimal design of water distribution network. In Proceedings of the Computing Conference, London, UK, 18–20 July 2017; pp. 961–970. [Google Scholar]
- Majeed, M.A.M.; Rao, P.S. Optimization of CMOS Analog Circuits Using Grey Wolf Optimization Algorithm. In Proceedings of the 2017 14th IEEE India Council International Conference (INDICON), Roorkee, India, 15–17 December 2017. [Google Scholar] [CrossRef]
- Mjahed, S.; Bouzaachane, K.; Taher Azar, A.; El Hadaj, S.; Raghay, S. Hybridization of fuzzy and hard semi-supervised clustering algorithms tuned with ant lion optimizer applied to Higgs boson search. Comput. Model. Eng. Sci. 2020, 125, 459–494. [Google Scholar]
- Khan, A.R.; Khan, S.; Harouni, M.; Abbasi, R.; Iqbal, S.; Mehmood, Z. Brain tumor segmentation using K-means clustering and deep learning with synthetic data augmentation for classification. Microsc. Res. Tech. 2021, 84, 1389–1399. [Google Scholar] [CrossRef] [PubMed]
- Khan, Z.; Koubaa, A.; Fang, S.; Lee, M.Y.; Muhammad, K. A Connectivity-Based Clustering Scheme for Intelligent Vehicles. Appl. Sci. 2021, 11, 2413. [Google Scholar] [CrossRef]
- Shah, Y.A.; Aadil, F.; Khalil, A.; Assam, M.; Abunadi, I.; Alluhaidan, A.S.; Al-Wesabi, F.N. An Evolutionary Algorithm-Based Vehicular Clustering Technique for VANETs. IEEE Access 2022, 10, 14368–14385. [Google Scholar] [CrossRef]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, UK, 1995. [Google Scholar]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Vettigli, G. MiniSom: Minimalistic and Numpy Based Implementation of the Self Organizing Maps. 2018. Available online: https://github.com/JustGlowing/minisom/ (accessed on 26 July 2023).
- GitHub—An Implementation of an Optimized Arabic Text Clustering Technique. Available online: https://github.com/majeedalameer/ArabicTextClustering (accessed on 26 July 2023).
- Alalyani, N.; Marie-Sainte, S.L. NADA: New Arabic Dataset for Text Classification. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 206–212. [Google Scholar] [CrossRef]
- Abuaiadah, D.; El Sana, J.; Abusalah, W. On the impact of dataset characteristics on arabic document classification. Int. J. Comput. Appl. 2014, 101, 31–38. [Google Scholar] [CrossRef]
- Attia, M.A. Arabic tokenization system. In Proceedings of the 2007 Workshop on Computational Approaches to Semitic Languages: Common Issues and Resources, Prague, Czech Republic, 28 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 65–72. [Google Scholar]
- Zerrouki, T. PyArabic, An Arabic language library for Python. 2010. Available online: https://pypi.python.org/pypi/pyarabic (accessed on 26 July 2023).
- Syarief, M.G.; Kurahman, O.T.; Huda, A.F.; Darmalaksana, W. Improving Arabic Stemmer: ISRI Stemmer. In Proceedings of the 2019 IEEE 5th International Conference on Wireless and Telematics (ICWT), Yogyakarta, Indonesia, 25–26 July 2019; pp. 1–4. [Google Scholar]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, UK, 1999. [Google Scholar]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Model | Dataset | Purity | F1-Score | Precision | Recall | Accuracy |
|---|---|---|---|---|---|---|---|
| [19] | K-Means | MSA | 93.3% | 87.32% | 87.13% | 87.52% | - |
| [21] | K-Means | Own corpus | - | 93% | 98% | 88% | |
| [26] | K-Means + (PSO) | BBC, CNN, OSAC | 50% | 47% | 33% | - | - |
| [5] | Brown clustering algorithm | Own corpus | 85% | - | - | - | - |
| [25] | K-Means | Arabic tweets | 76.4% | - | - | - | - |
| [23] | TF-IDF + BTO | Arabic tweets | - | - | - | - | - |
| [22] | K-Medious | Own corpus | - | 67% | 60% | 78% | - |
| [2] | Markov + Fuzzy-C-Means + DBN | Own corpus | - | 91.02% | 91.02% | 90.9% | - |
| [10] | Suffix Tree | Own corpus | - | 81.11% | 80.3% | 83.75% | - |
| [11] | SOM | Own corpus | - | - | - | - | 93.4% |
| Category | Number of Text Files |
|---|---|
| Technology | 300 |
| Religion | 300 |
| Politics | 300 |
| Law | 300 |
| Sports | 300 |
| Art | 300 |
| Literature | 300 |
| Economy | 300 |
| Health | 300 |
| Total | 2700 |
| Category | Number of Text Files |
|---|---|
| Arabic Literature | 400 |
| Economical Social Sciences | 1307 |
| Political Social Sciences | 400 |
| Law | 1644 |
| Sports | 1416 |
| Art | 400 |
| Islamic Religion | 515 |
| Computer Science | 400 |
| Health | 428 |
| Astronomy | 400 |
| Total | 7310 |
| Dataset | Representation | Clustering Technique | F1-Score | Precision | Recall | Accuracy | Time in Minutes |
|---|---|---|---|---|---|---|---|
| MSA | CV | K-Means | 73.00% | 75.00% | 89.60% | 73.00% | - |
| TF-IDF | K-Means | 90.80% | 89.80% | 94.20% | 93.80% | - | |
| K-Means in [19] | 87.32% | 87.13% | 87.52% | - | - | ||
| CV | SOM | 86.59% | 87.06% | 86.66% | 86.70% | 07:18 | |
| TF-IDF | SOM | 93.37% | 93.54% | 93.33% | 93.30% | 06:27 | |
| CV | SOM + GWO | 98.14% | 98.21% | 98.14% | 98.00% | 07:00 | |
| TF-IDF | SOM + GWO | 98.33% | 98.36% | 98.33% | 98.30% | 04:48 | |
| NADA | CV | K-Means | 44.30% | 34.30% | 31.90% | 44.30% | - |
| TF-IDF | K-Means | 57.70% | 60.20% | 71.60% | 57.70% | - | |
| CV | SOM | 91.84% | 92.01% | 91.79% | 91.80% | 54:27 | |
| TF-IDF | SOM | 93.33% | 93.47% | 93.29% | 93.30% | 18:22 | |
| CV | SOM + GWO | 98.70% | 98.77% | 98.70% | 98.70% | 18:10 | |
| TF-IDF | SOM + GWO | 98.44% | 98.53% | 98.42% | 98.40% | 16:00 |
| Dataset | Representation | Weights Initialization (GWO Optimization) | Training | Total Time |
|---|---|---|---|---|
| MSA | CV | 02:23 | 04:37 | 07:00 |
| TF-IDF | 01:38 | 03:10 | 04:48 | |
| NADA | CV | 05:00 | 13:00 | 18:00 |
| TF-IDF | 04:53 | 12:08 | 17:01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larabi-Marie-Sainte, S.; Bin Alamir, M.; Alameer, A. Arabic Text Clustering Using Self-Organizing Maps and Grey Wolf Optimization. Appl. Sci. 2023, 13, 10168. https://doi.org/10.3390/app131810168
Larabi-Marie-Sainte S, Bin Alamir M, Alameer A. Arabic Text Clustering Using Self-Organizing Maps and Grey Wolf Optimization. Applied Sciences. 2023; 13(18):10168. https://doi.org/10.3390/app131810168
Chicago/Turabian StyleLarabi-Marie-Sainte, Souad, Mashael Bin Alamir, and Abdulmajeed Alameer. 2023. "Arabic Text Clustering Using Self-Organizing Maps and Grey Wolf Optimization" Applied Sciences 13, no. 18: 10168. https://doi.org/10.3390/app131810168
APA StyleLarabi-Marie-Sainte, S., Bin Alamir, M., & Alameer, A. (2023). Arabic Text Clustering Using Self-Organizing Maps and Grey Wolf Optimization. Applied Sciences, 13(18), 10168. https://doi.org/10.3390/app131810168