
X-ray Diffraction Data Analysis by Machine Learning Methods—A Review



Abstract
:1. Introduction
1.1. Overview of X-ray Diffraction (XRD) Technique
- n is the order of the diffraction peak (usually 1 for primary peaks);
- λ is the wavelength of the incident X-rays;
- d is the lattice spacing of the crystal planes;
- θ is the angle between the incident X-rays and the crystal plane.
1.2. Applications of XRD Data Analysis
1.3. Motivation for Machine Learning in XRD Data Analysis
- Handling big data: The development of synchrotrons has enabled the fast acquisition of XRD patterns, which results in a significant increase in the amount of data collected during experiments. The fine-tuning of beam-time experiments depends on the analysis of patterns, and, thus, an automatic processing flow would be required to further increase its autonomy. In this regard, machine learning routines using clustering represent a potential solution to the challenges faced by the scientific community [70];
- Automated phase identification: In traditional XRD data analysis, the manual identification of phases in complex samples can be time consuming and error prone, especially when dealing with overlapping peaks or noisy data recorded in cases in which short measurement times are a must. ML algorithms can accurately identify and quantify phases and even predict material features from XRD patterns. Moreover, the successful implementation of the algorithms would save time while also benefitting XRD users who are not experts [71,72,73];
- Quantitative phase analysis (QPA): Several traditional methods with different complexity and sample preparation requirements are available for the evaluation of phase fractions, including the reference intensity ratio (RIR) method, which requires the introduction of an internal standard calibration [74]; the whole pattern fitting procedure [51,52,53,54]; or Rietveld refinement [54]. Each of the traditional methods is time consuming and requires trained personnel to deliver accurate results. ML algorithms, such as regression models and support vector machines, can efficiently estimate phase proportions based on trained patterns, greatly improving the accuracy and speed of QPA [75,76].
- The bibliographic source must refer to the use of machine learning methods for the analysis of XRD patterns;
- The bibliographic source must be written in English;
- The bibliographic source represents a peer-reviewed article, conference proceeding, or an edited book.
2. Challenges in Traditional XRD Data Analysis
2.1. Data Preprocessing and Reduction
2.2. Phase Identification and Crystallographic Analysis
2.3. Quantitative Phase Analysis
2.4. Microstructural Characterization
3. Introduction to Machine Learning
- SVMs, which are very suitable for binary classification and linearly separable data, work by transforming (mapping) the input data to a high-dimensional feature space such that different categories become linearly separable [86];
- Decision trees work (as their name implies) by inferring simple if–then–else decision rules from the data features and can be visualized as a piecewise constant approximation of the data [86];
- Random forests (RFs) are ensemble methods that make predictions by aggregating the output of multiple decision trees. Randomness is built into the algorithm to decrease the variance in the predictions of the generated forest. RFs are robust in overfitting and useful for both regression and classification applications. A different ensemble method, called “extremely randomized trees” may be employed to increase the prediction power by reducing the variance [86];
- Nearest neighbor methods predict labels from a predefined number of training samples that are closest to the given input point; in KNNs, this number is a user-defined constant [86];
- Naïve Bayes methods are an application of Bayes’ theorem under the “naïve” assumption that input features are independent from each other [86]. For example, this assumption would be violated when using length, width, and area as input features in the same data analysis workflow;
- Neural networks can identify and encode nonlinear relationships in high-dimensional data; sometimes NNs used in machine learning are referred to as ANNs, where the letter A stands for “artificial”. NNs are composed of layers of “neurons” that mimic their biological counterparts: they have multiple input streams (which work like dendrites) and a single output activation signal (similar in function to an axon). Each layer of neurons has adjustable parameters that are used to compute the output signal. Based on the connectivity between layers, NNs can be categorized as dense (whereby each neuron in a layer is connected to every neuron in the previous layer) or sparse. The term multilayer perceptron (MLP) is sometimes used to refer to modern ANNs; MLPs consist of (at least three) dense layers: input, output, and at least one hidden (other) layer [86].
- The K-means method is used for partitioning the data into a predetermined number of K disjoint clusters, which are chosen with the aim to evenly distribute the variance between different clusters [86];
- Gaussian mixture models are probabilistic in nature and try to represent the input data as a mixture of a finite number of Gaussian distributions with unknown parameters to be learned during training [86];
- Hierarchical clustering works by successively merging or splitting clusters to create a tree-like (nested) representation of the data. In agglomerative clustering, a hierarchy is built using a bottom-up approach (each observation starts as a single-item cluster, and clusters are successively merged until a single, all-encompassing cluster is formed) [86];
- Autoencoders use ANNs to learn an encoder–decoder pair that can efficiently represent unlabeled data: the encoder compresses the input data, while the decoder reconstructs an output from the compressed version of the input. Autoencoders are suitable for unsupervised feature learning and data compression [86].
- CNNs, belonging to the artificial neural network group, are commonly used in image data analysis. Their name stems from the mathematical operation convolution, which is used in at least one of the neuron layers, instead of the simpler matrix multiplication used by regular ANNs [86];
- The architecture of RNNs makes them suitable for identifying patterns in sequences of data and are used for applications such as speech and natural language processing. In contrast to regular ANNs, in which calculations are performed layer-by-layer from input to output, in recursive NNs information can also flow backward, allowing the output from some nodes to affect their inputs in the future (in subsequent evaluations of the neural network), thus introducing an internal state useful for inferring meaning in text processing based on words previously read by the algorithm [86,89];
- Long short-term memory (LSTM) units were introduced within the RNN framework to enable RNNs to learn over thousands of steps, which would have not been possible otherwise because of the problem of vanishing or exploding gradients (that accumulate and compound over multiple iterations of the NN) [86,89].
4. Applications of Machine Learning in XRD Data Analysis
4.1. Pattern Matching and Classification Algorithms
4.2. Quantitative Phase Analysis
4.3. Lattice Analysis
4.4. Defects and Substituent Concentration Detection
4.5. Microstructural Characterization
4.6. Challenges and Limitations of Machine Learning
5. Conclusions and Future Development
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Raj, C.; Agarwal, A.; Bharathy, G.; Narayan, B.; Prasad, M. Cyberbullying Detection: Hybrid Models Based on Machine Learning and Natural Language Processing Techniques. Electronics 2021, 10, 2810. [Google Scholar] [CrossRef]
- Olthof, A.W.; Shouche, P.; Fennema, E.M.; IJpma, F.F.A.; Koolstra, R.H.C.; Stirler, V.M.A.; van Ooijen, P.M.A.; Cornelissen, L.J. Machine Learning Based Natural Language Processing of Radiology Reports in Orthopaedic Trauma. Comput. Methods Programs Biomed. 2021, 208, 106304. [Google Scholar] [CrossRef] [PubMed]
- Bashir, M.F.; Arshad, H.; Javed, A.R.; Kryvinska, N.; Band, S.S. Subjective Answers Evaluation Using Machine Learning and Natural Language Processing. IEEE Access 2021, 9, 158972–158983. [Google Scholar] [CrossRef]
- Mollaei, N.; Cepeda, C.; Rodrigues, J.; Gamboa, H. Biomedical Text Mining: Applicability of Machine Learning-Based Natural Language Processing in Medical Database. In Proceedings of the 15th International Joint Conference on Biomedical Engineering Systems and Technologies—Volume 4: BIOSTEC, Online, 9–11 February 2022; pp. 159–166. [Google Scholar] [CrossRef]
- Houssein, E.H.; Mohamed, R.E.; Ali, A.A. Machine Learning Techniques for Biomedical Natural Language Processing: A Comprehensive Review. IEEE Access 2021, 9, 140628–140653. [Google Scholar] [CrossRef]
- Zhang, Z.H. Image Recognition Methods Based on Deep Learning. In 3D Imaging—Multidimensional Signal Processing and Deep Learning, Volume 1; Smart Innovation, Systems and Technologies Series; Springer: Singapore, 2022; Volume 297, pp. 23–34. [Google Scholar]
- Wang, Y.S.; Hu, X. Machine Learning-Based Image Recognition for Rural Architectural Planning and Design. Neural Comput. Appl. 2022, 1–10. [Google Scholar] [CrossRef]
- Jabnouni, H.; Arfaoui, I.; Cherni, M.A.; Bouchouicha, M.; Sayadi, M. Machine Learning Based Classification for Fire and Smoke Images Recognition. In Proceedings of the 2022 8th International Conference on Control, Decision and Information Technologies (CODIT’22), Istanbul, Turkey, 17–20 May 2022; pp. 425–430. [Google Scholar] [CrossRef]
- Shah, S.S.H.; Ahmad, A.; Jamil, N.; Khan, A.U.R. Memory Forensics-Based Malware Detection Using Computer Vision and Machine Learning. Electronics 2022, 11, 2579. [Google Scholar] [CrossRef]
- Medeiros, E.C.; Almeida, L.M.; Teixeira, J.G.D. Computer Vision and Machine Learning for Tuna and Salmon Meat Classification. Informatics 2021, 8, 70. [Google Scholar] [CrossRef]
- Yin, H.; Yi, W.L.; Hu, D.M. Computer Vision and Machine Learning Applied in the Mushroom Industry: A Critical Review. Comput. Electron. Agric. 2022, 198, 107015. [Google Scholar] [CrossRef]
- Shah, N.; Bhagat, N.; Shah, M. Crime Forecasting: A Machine Learning and Computer Vision Approach to Crime Prediction and Prevention. Vis. Comput. Ind. Biomed. Art 2021, 4, 9. [Google Scholar] [CrossRef]
- Mahadevkar, S.V.; Khemani, B.; Patil, S.; Kotecha, K.; Vora, D.R.; Abraham, A.; Gabralla, L.A. A Review on Machine Learning Styles in Computer Vision-Techniques and Future Directions. IEEE Access 2022, 10, 107293–107329. [Google Scholar] [CrossRef]
- Khan, A.A.; Laghari, A.A.; Awan, S.A. Machine Learning in Computer Vision: A Review. EAI Endorsed Trans. Scalable Inf. Syst. 2021, 8, e4. [Google Scholar] [CrossRef]
- Mun, C.H.; Rezvani, S.; Lee, J.; Park, S.S.; Park, H.W.; Lee, J. Indirect Measurement of Cutting Forces during Robotic Milling Using Multiple Sensors and a Machine Learning-Based System Identifier. J. Manuf. Processes 2023, 85, 963–976. [Google Scholar] [CrossRef]
- Kim, N.; Barde, S.; Bae, K.; Shin, H. Learning Per-Machine Linear Dispatching Rule for Heterogeneous Multi-Machines Control. Int. J. Prod. Res. 2023, 61, 162–182. [Google Scholar] [CrossRef]
- Piat, J.R.; Dafflon, B.; Bentaha, M.L.; Gerphagnon, Y.; Moalla, N. A Framework to Optimize Laser Welding Process by Machine Learning in a SME Environment. In Product Lifecycle Management. PLM in Transition Times: The Place of Humans and Transformative Technologies, PLM 2022; Springer: Cham, Switzerland, 2023; Volume 667, pp. 431–439. [Google Scholar]
- Carpanzano, E.; Knuttel, D. Advances in Artificial Intelligence Methods Applications in Industrial Control Systems: Towards Cognitive Self-Optimizing Manufacturing Systems. Appl. Sci. 2022, 12, 10962. [Google Scholar] [CrossRef]
- Hashemnia, N.; Fan, Y.Y.; Rocha, N. Using Machine Learning to Predict and Avoid Malfunctions: A Revolutionary Concept for Condition-Based Asset Performance Management (APM). In Proceedings of the 2021 IEEE PES Innovative Smart Grid Technologies—ASIA (ISGT ASIA), Brisbane, Australia, 5–8 December 2021. [Google Scholar]
- Xu, D.; Chen, L.Q.; Yu, C.; Zhang, S.; Zhao, X.; Lai, X. Failure Analysis and Control of Natural Gas Pipelines under Excavation Impact Based on Machine Learning Scheme. Int. J. Press. Vessels Pip. 2023, 201, 104870. [Google Scholar] [CrossRef]
- Shcherbatov, I.; Lisin, E.; Rogalev, A.; Tsurikov, G.; Dvorak, M.; Strielkowski, W. Power Equipment Defects Prediction Based on the Joint Solution of Classification and Regression Problems Using Machine Learning Methods. Electronics 2021, 10, 3145. [Google Scholar] [CrossRef]
- Nuhu, A.A.; Zeeshan, Q.; Safaei, B.; Shahzad, M.A. Machine Learning-Based Techniques for Fault Diagnosis in the Semiconductor Manufacturing Process: A Comparative Study. J. Supercomput. 2023, 79, 2031–2081. [Google Scholar] [CrossRef]
- Ko, H.; Lu, Y.; Yang, Z.; Ndiaye, N.Y.; Witherell, P. A Framework Driven by Physics-Guided Machine Learning for Process-Structure-Property Causal Analytics in Additive Manufacturing. J. Manuf. Syst. 2023, 67, 213–228. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D. Machine Learning and Data Mining in Manufacturing. Expert Syst. Appl. 2021, 166. [Google Scholar] [CrossRef]
- Acosta, S.M.; Oliveira, R.M.A.; Sant’Anna, A.M.O. Machine Learning Algorithms Applied to Intelligent Tyre Manufacturing. Int. J. Comput. Integr. Manuf. 2023, 1–11. [Google Scholar] [CrossRef]
- Gao, C.C.; Min, X.; Fang, M.H.; Tao, T.Y.; Zheng, X.H.; Liu, Y.G.; Wu, X.W.; Huang, Z.H. Innovative Materials Science via Machine Learning. Adv. Funct. Mater. 2022, 32, 2108044. [Google Scholar] [CrossRef]
- Peterson, G.G.C.; Brgoch, J. Materials Discovery through Machine Learning Formation Energy. J. Phys.-Energy 2021, 3, 022002. [Google Scholar] [CrossRef]
- Fuhr, A.S.; Sumpter, B.G. Deep Generative Models for Materials Discovery and Machine Learning-Accelerated Innovation. Front. Mater. 2022, 9, 865270. [Google Scholar] [CrossRef]
- Fang, J.H.; Xie, M.; He, X.Q.; Zhang, J.M.; Hu, J.Q.; Chen, Y.T.; Yang, Y.C.; Jin, Q.L. Machine Learning Accelerates the Materials Discovery. Mater Today Commun. 2022, 33, 104900. [Google Scholar] [CrossRef]
- Juan, Y.F.; Dai, Y.B.; Yang, Y.; Zhang, J. Accelerating Materials Discovery Using Machine Learning. J. Mater. Sci. Technol. 2021, 79, 178–190. [Google Scholar] [CrossRef]
- Hou, H.B.; Wang, J.F.; Ye, L.; Zhu, S.J.; Wang, L.G.; Guan, S.K. Prediction of Mechanical Properties of Biomedical Magnesium Alloys Based on Ensemble Machine Learning. Mater. Lett. 2023, 348, 134605. [Google Scholar] [CrossRef]
- Magar, R.; Farimani, A.B. Learning from Mistakes: Sampling Strategies to Efficiently Train Machine Learning Models for Material Property Prediction. Comput. Mater. Sci. 2023, 224, 112167. [Google Scholar] [CrossRef]
- Rong, C.; Zhou, L.; Zhang, B.W.; Xuan, F.Z. Machine Learning for Mechanics Prediction of 2D MXene-Based Aerogels. Compos. Commun. 2023, 38, 101474. [Google Scholar] [CrossRef]
- Chan, C.H.; Sun, M.Z.; Huang, B.L. Application of Machine Learning for Advanced Material Prediction and Design. EcoMat 2022, 4, e12194. [Google Scholar] [CrossRef]
- Sendek, A.D.; Ransom, B.; Cubuk, E.D.; Pellouchoud, L.A.; Nanda, J.; Reed, E.J. Machine Learning Modeling for Accelerated Battery Materials Design in the Small Data Regime. Adv. Energy Mater. 2022, 12, 2200553. [Google Scholar] [CrossRef]
- Pei, Z.R.; Rozman, K.A.; Dogan, O.N.; Wen, Y.H.; Gao, N.; Holm, E.A.; Hawk, J.A.; Alman, D.E.; Gao, M.C. Machine-Learning Microstructure for Inverse Material Design. Adv. Sci. 2021, 8, 2101207. [Google Scholar] [CrossRef] [PubMed]
- He, J.J.; Li, J.J.; Liu, C.B.; Wang, C.X.; Zhang, Y.; Wen, C.; Xue, D.Z.; Cao, J.L.; Su, Y.J.; Qiao, L.J.; et al. Machine Learning Identified Materials Descriptors for Ferroelectricity. Acta Mater. 2021, 209, 116815. [Google Scholar] [CrossRef]
- McSweeney, D.M.; McSweeney, S.M.; Liu, Q. A Self-Supervised Workflow for Particle Picking in Cryo-EM. IUCrJ 2020, 7, 719–727. [Google Scholar] [CrossRef]
- Ramakrishnan, R.; Dral, P.O.; Rupp, M.; Von Lilienfeld, O.A. Quantum Chemistry Structures and Properties of 134 Kilo Molecules. Sci. Data 2014, 1, 140022. [Google Scholar] [CrossRef] [PubMed]
- Xie, T.; Grossman, J.C. Crystal Graph Convolutional Neural Networks for an Accurate and Interpretable Prediction of Material Properties. Phys. Rev. Lett. 2018, 120, 145301. [Google Scholar] [CrossRef] [PubMed]
- Luo, R.; Popp, J.; Bocklitz, T. Deep Learning for Raman Spectroscopy: A Review. Analytica 2022, 3, 287–301. [Google Scholar] [CrossRef]
- Gadre, C.A.; Yan, X.; Song, Q.; Li, J.; Gu, L.; Huyan, H.; Aoki, T.; Lee, S.W.; Chen, G.; Wu, R.; et al. Nanoscale Imaging of Phonon Dynamics by Electron Microscopy. Nature 2022, 606, 292–297. [Google Scholar] [CrossRef]
- Friedrich, W.; Knipping, P.; Laue, M. Interferenzerscheinungen Bei Röntgenstrahlen. Ann. Phys. 1913, 346, 971–988. [Google Scholar] [CrossRef]
- Authier, A. Early Days of X-ray Crystallography; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Singh, A.K. Advanced X-ray Techniques in Research and Industry; IOS Press: Amsterdam, The Netherlands, 2005; ISBN 1586035371. [Google Scholar]
- Bragg, W.L.; Thomson, J.J. The Diffraction of Short Electromagnetic Waves by a Crystal. Proc. Camb. Philos. Soc. Math. Phys. Sci. 1914, 17, 43–57. [Google Scholar]
- Withers, P.J. Synchrotron X-ray Diffraction. In Practical Residual Stress Measurement Methods; Wiley: Hoboken, NJ, USA, 2013; pp. 163–194. ISBN 9781118402832. [Google Scholar]
- Li, Y.; Beck, R.; Huang, T.; Choi, M.C.; Divinagracia, M. Scatterless Hybrid Metal-Single-Crystal Slit for Small-Angle X-ray Scattering and High-Resolution X-ray Diffraction. J. Appl. Crystallogr. 2008, 41, 1134–1139. [Google Scholar] [CrossRef]
- Wohlschlögel, M.; Schülli, T.U.; Lantz, B.; Welzel, U. Application of a Single-Reflection Collimating Multilayer Optic for X-ray Diffraction Experiments Employing Parallel-Beam Geometry. J. Appl. Crystallogr. 2008, 41, 124–133. [Google Scholar] [CrossRef]
- Saha, G.B. Scintillation and Semiconductor Detectors. In Physics and Radiobiology of Nuclear Medicine; Saha, G.B., Ed.; Springer: New York, NY, USA, 2006; pp. 81–107. ISBN 978-0-387-36281-6. [Google Scholar]
- Maniammal, K.; Madhu, G.; Biju, V. X-Ray Diffraction Line Profile Analysis of Nanostructured Nickel Oxide: Shape Factor and Convolution of Crystallite Size and Microstrain Contributions. Phys. E Low Dimens. Syst. Nanostruct. 2017, 85, 214–222. [Google Scholar] [CrossRef]
- Uvarov, V.; Popov, I. Metrological Characterization of X-Ray Diffraction Methods for Determination of Crystallite Size in Nano-Scale Materials. Mater. Charact. 2007, 58, 883–891. [Google Scholar] [CrossRef]
- Epp, J. 4—X-Ray Diffraction (XRD) Techniques for Materials Characterization. In Materials Characterization Using Nondestructive Evaluation (NDE) Methods; Hübschen, G., Altpeter, I., Tschuncky, R., Herrmann, H.-G., Eds.; Woodhead Publishing: Sawston, UK, 2016; pp. 81–124. ISBN 978-0-08-100040-3. [Google Scholar]
- Chipera, S.J.; Bish, D.L. Fitting Full X-ray Diffraction Patterns for Quantitative Analysis: A Method for Readily Quantifying Crystalline and Disordered Phases. Adv. Mater. Phys. Chem. 2013, 3, 47–53. [Google Scholar] [CrossRef]
- Sitepu, H.; O’Connor, B.H.; Li, D. Comparative Evaluation of the March and Generalized Spherical Harmonic Preferred Orientation Models Using X-ray Diffraction Data for Molybdite and Calcite Powders. J. Appl. Crystallogr. 2005, 38, 158–167. [Google Scholar] [CrossRef]
- Jenkins, R.; Snyder, R.L. Introduction to X-ray Powder Diffractometry; Wiley: New York, NY, USA, 1996; Volume 138. [Google Scholar]
- Reventos, M.M.; Descarrega, J.M.A. Mineralogy and Geology: The Role of Crystallography since the Discovery of X-ray Diffraction in 1912. Mineralogía y Geología: El papel de la Cristalografía desde el descubrimiento de la difracción de Rayos X en 1912. Rev. Soc. Geol. España 2012, 25, 133–143. [Google Scholar]
- Okoro, C.; Levine, L.E.; Xu, R.; Hummler, K.; Obeng, Y.S. Nondestructive Measurement of the Residual Stresses in Copper Through-Silicon Vias Using Synchrotron-Based Microbeam X-Ray Diffraction. IEEE Trans. Electron. Devices 2014, 61, 2473–2479. [Google Scholar] [CrossRef]
- Bunaciu, A.A.; Udriştioiu, E.G.; Aboul-Enein, H.Y. X-ray Diffraction: Instrumentation and Applications. Crit. Rev. Anal. Chem. 2015, 45, 289–299. [Google Scholar] [CrossRef]
- Kotrly, M. Application of X-ray Diffraction in Forensic Science. Z. Kristallogr. Suppl. 2006, 23, 35–40. [Google Scholar] [CrossRef]
- Warren, B.E.; Biscob, J. Fourier Analysis of X-ray Patterns of Soda-Silica Glass. J. Am. Ceram. Soc. 1938, 21, 259–265. [Google Scholar] [CrossRef]
- Misture, S.T. X-ray Powder Diffraction. In Encyclopedia of Materials: Technical Ceramics and Glasses; Pomeroy, M., Ed.; Elsevier: Oxford, UK, 2021; pp. 549–559. ISBN 978-0-12-822233-1. [Google Scholar]
- Zok, F.W. Integrating Lattice Materials Science into the Traditional Processing–Structure–Properties Paradigm. MRS Commun. 2019, 9, 1284–1291. [Google Scholar] [CrossRef]
- Scarlett, N.V.Y.; Madsen, I.C.; Manias, C.; Retallack, D. On-Line X-ray Diffraction for Quantitative Phase Analysis: Application in the Portland Cement Industry. Powder Diffr. 2001, 16, 71–80. [Google Scholar] [CrossRef]
- Conconi, M.S.; Gauna, M.R.; Serra, M.F.; Suarez, G.; Aglietti, E.F.; Rendtorff, N.M.; Gonnet, M.B.; Aires, B.; Aires, B. Quantitative Firing Transformatons of Triaxial Ceramic by X-Ray Diffraction Methods. Ceramica 2014, 60, 524–531. [Google Scholar] [CrossRef]
- Cheary, R.W.; Ma-Sorrell, Y. Quantitative Phase Analysis by X-ray Diffraction of Martensite and Austenite in Strongly Oriented Orthodontic Stainless Steel Wires. J. Mater. Sci. 2000, 35, 1105–1113. [Google Scholar] [CrossRef]
- Wilkinson, A.P.; Speck, J.S.; Cheetham, A.K.; Natarajan, S.; Thomas, J.M. In Situ X-ray Diffraction Study of Crystallization Kinetics in PbZr1-XTixO3, (PZT, x = 0.0, 0.55, 1.0). Chem. Mater. 1994, 6, 750–754. [Google Scholar] [CrossRef]
- Purushottam raj purohit, R.R.P.; Arya, A.; Bojjawar, G.; Pelerin, M.; Van Petegem, S.; Proudhon, H.; Mukherjee, S.; Gerard, C.; Signor, L.; Mocuta, C.; et al. Revealing the Role of Microstructure Architecture on Strength and Ductility of Ni Microwires by In-Situ Synchrotron X-ray Diffraction. Sci. Rep. 2019, 9, 79. [Google Scholar] [CrossRef]
- Prasetya, A.D.; Rifai, M.; Mujamilah; Miyamoto, H. X-ray Diffraction (XRD) Profile Analysis of Pure ECAP-Annealing Nickel Samples. J. Phys. Conf. Ser. 2020, 1436, 012113. [Google Scholar] [CrossRef]
- Wang, C.; Steiner, U.; Sepe, A. Synchrotron Big Data Science. Small 2018, 14, 1802291. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, Y. Automated Data Analysis for Powder X-ray Diffraction Using Machine Learning. Synchrotron. Radiat. News 2022, 35, 9–15. [Google Scholar] [CrossRef]
- Laalam, A.; Boualam, A.; Ouadi, H.; Djezzar, S.; Tomomewo, O.; Mellal, I.; Bakelli, O.; Merzoug, A.; Chemmakh, A.; Latreche, A.; et al. Application of Machine Learning for Mineralogy Prediction from Well Logs in the Bakken Petroleum System. In Proceedings of the SPE Annual Technical Conference and Exhibition, Houston, TX, USA, 3–5 October 2022; p. D012S063R002. [Google Scholar] [CrossRef]
- Zhao, B.; Greenberg, J.A.; Wolter, S. Application of Machine Learning to X-ray Diffraction-Based Classification. In Anomaly Detection and Imaging with X-Rays (ADIX) III; SPIE: Bellingham, WA, USA, 2018; p. 1063205. [Google Scholar] [CrossRef]
- Hillier, S. Accurate Quantitative Analysis of Clay and Other Minerals in Sandstones by XRD: Comparison of a Rietveld and a Reference Intensity Ratio (RIR) Method and the Importance of Sample Preparation. Clay Miner. 2000, 35, 291–302. [Google Scholar] [CrossRef]
- Lee, D.; Lee, H.; Jun, C.-H.; Chang, C.H. A Variable Selection Procedure for X-Ray Diffraction Phase Analysis. Appl. Spectrosc. 2007, 61, 1398–1403. [Google Scholar] [CrossRef] [PubMed]
- Greasley, J.; Hosein, P. Exploring Supervised Machine Learning for Multi-Phase Identification and Quantification from Powder X-ray Diffraction Spectra. J. Mater. Sci. 2023, 58, 5334–5348. [Google Scholar] [CrossRef]
- Visser, J.W.; Sonneveld, E.J. Automatic Collection of Powder Data from Photographs. J. Appl. Crystallogr. 1975, 8, 1–7. [Google Scholar]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Hanawalt, J.D. Phase Identification by X-ray Powder Diffraction Evaluation of Various Techniques. Adv. X-ray Anal. 1976, 20, 63–73. [Google Scholar] [CrossRef]
- Scherrer, P. Estimation of the Size and Internal Structure of Colloidal Particles by Means of Röntgen. Nachr. Ges. Wiss. Göttingen 1918, 2, 96–100. [Google Scholar]
- Williamson, G.K.; Hall, W.H. X-Ray Line Broadening from Filed Aluminium and Wolfram. Acta Metall. 1953, 1, 22–31. [Google Scholar] [CrossRef]
- Bourniquel, B.; Sprauel, J.M.; Feron, J.; Lebrun, J.L. Warren-Averbach Analysis of X-Ray Line Profile (Even Truncated) Assuming a Voigt-like Profile. In International Conference on Residual Stresses: ICRS2; Beck, G., Denis, S., Simon, A., Eds.; Springer: Dordrecht, The Netherlands, 1989; pp. 184–189. ISBN 978-94-009-1143-7. [Google Scholar]
- Dollase, W.A. Correction of Intensities of Preferred Orientation in Powder Diffractometry: Application of the March Model. J. Appl. Crystallogr. 1986, 19, 267–272. [Google Scholar] [CrossRef]
- Alzubi, J.; Nayyar, A.; Kumar, A. Machine Learning from Theory to Algorithms: An Overview. J. Phys. Conf. Ser. 2018, 1142, 012012. [Google Scholar] [CrossRef]
- Pane, S.A.; Sihombing, F.M.H. Classification of Rock Mineral in Field X Based on Spectral Data (SWIR & TIR) Using Supervised Machine Learning Methods. IOP Conf. Ser. Earth Environ. Sci. 2021, 830, 012042. [Google Scholar] [CrossRef]
- Colliot, O. (Ed.) Machine Learning for Brain Disorders; Neuromethods; Springer: New York, NY, USA, 2023; Volume 197, ISBN 978-1-0716-3194-2. [Google Scholar]
- Ige, A.O.; Mohd Noor, M.H. A Survey on Unsupervised Learning for Wearable Sensor-Based Activity Recognition. Appl. Soft Comput. 2022, 127, 109363. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019; ISBN 9781492032649. [Google Scholar]
- Schmidt, R.M. Recurrent Neural Networks (RNNs): A Gentle Introduction and Overview. arXiv 2019. [Google Scholar] [CrossRef]
- Oh, S.; Ashiquzzaman, A.; Lee, D.; Kim, Y.; Kim, J. Study on Human Activity Recognition Using Semi-Supervised Active Transfer Learning. Sensors 2021, 21, 2760. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Guan, Z.; Yao, S.; Qin, H.; Nguyen, M.H.; Yager, K.; Yu, D. Deep Learning for Analysing Synchrotron Data Streams. In Proceedings of the 2016 New York Scientific Data Summit (NYSDS), New York, NY, USA, 14–17 August 2016. [Google Scholar] [CrossRef]
- Czyzewski, A.; Krawiec, F.; Brzezinski, D.; Porebski, P.J.; Minor, W. Detecting Anomalies in X-Ray Diffraction Images Using Convolutional Neural Networks. Expert Syst. Appl. 2021, 174, 114740. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, A.; Sharma, R. See Deeper: Identifying Crystal Structure from X-Ray Diffraction Patterns. In Proceedings of the 2020 International Conference on Cyberworlds (CW), Caen, France, 29 September–1 October 2020; pp. 49–54. [Google Scholar] [CrossRef]
- Chakraborty, A.; Sharma, R. A Deep Crystal Structure Identification System for X-Ray Diffraction Patterns. Vis. Comput. 2022, 38, 1275–1282. [Google Scholar] [CrossRef]
- Massuyeau, F.; Broux, T.; Coulet, F.; Demessence, A.; Mesbah, A.; Gautier, R. Perovskite or Not Perovskite? A Deep-Learning Approach to Automatically Identify New Hybrid Perovskites from X-ray Diffraction Patterns. Adv. Mater. 2022, 34, 2203879. [Google Scholar] [CrossRef]
- Ishitsuka, K.; Ojima, H.; Mogi, T.; Kajiwara, T.; Sugimoto, T.; Asanuma, H. Characterization of Hydrothermal Alteration along Geothermal Wells Using Unsupervised Machine-Learning Analysis of X-ray Powder Diffraction Data. Earth Sci. Inform. 2022, 15, 73–87. [Google Scholar] [CrossRef]
- Yuan, S.; Wolter, S.D.; Greenberg, J.A. Classification-Free Threat Detection Based on Material-Science-Informed Clustering. In Anomaly Detection and Imaging with X-rays (ADIX) II; SPIE: Bellingham, WA, USA, 2017; Volume 10187, p. 101870K. [Google Scholar] [CrossRef]
- Lee, J.W.; Park, W.B.; Kim, M.; Pal Singh, S.; Pyo, M.; Sohn, K.S. A Data-Driven XRD Analysis Protocol for Phase Identification and Phase-Fraction Prediction of Multiphase Inorganic Compounds. Inorg. Chem. Front. 2021, 8, 2492–2504. [Google Scholar] [CrossRef]
- Park, S.Y.; Son, B.K.; Choi, J.; Jin, H.; Lee, K. Application of Machine Learning to Quantification of Mineral Composition on Gas Hydrate-Bearing Sediments, Ulleung Basin, Korea. J. Pet. Sci. Eng. 2022, 209, 109840. [Google Scholar] [CrossRef]
- Pasha, M.F.; Rahmat, R.F.; Budiarto, R.; Syukur, M. A Distributed Autonomous Neuro-Gen Learning Engine and Its Application to the Lattice Analysis of Cubic Structure Identification Problem. Int. J. Innov. Comput. Inf. Control 2010, 6, 1005–1022. [Google Scholar]
- Vecsei, P.M.; Choo, K.; Chang, J.; Neupert, T. Neural Network Based Classification of Crystal Symmetries from X-Ray Diffraction Patterns. Phys. Rev. B 2019, 99, 245120. [Google Scholar] [CrossRef]
- Suzuki, Y.; Hino, H.; Hawai, T.; Saito, K.; Kotsugi, M.; Ono, K. Symmetry Prediction and Knowledge Discovery from X-Ray Diffraction Patterns Using an Interpretable Machine Learning Approach. Sci. Rep. 2020, 10, 21790. [Google Scholar] [CrossRef] [PubMed]
- Oviedo, F.; Ren, Z.; Sun, S.; Settens, C.; Liu, Z.; Hartono, N.T.P.; Ramasamy, S.; DeCost, B.L.; Tian, S.I.P.; Romano, G.; et al. Fast and Interpretable Classification of Small X-Ray Diffraction Datasets Using Data Augmentation and Deep Neural Networks. NPJ Comput. Mater. 2019, 5, 60. [Google Scholar] [CrossRef]
- Venderley, J.; Mallayya, K.; Matty, M.; Krogstad, M.; Ruff, J.; Pleiss, G.; Kishore, V.; Mandrus, D.; Phelan, D.; Poudel, L.; et al. Harnessing Interpretable and Unsupervised Machine Learning to Address Big Data from Modern X-Ray Diffraction. Proc. Natl. Acad. Sci. USA 2022, 119, e2109665119. [Google Scholar] [CrossRef]
- Samarakoon, A.M.; Alan Tennant, D. Machine Learning for Magnetic Phase Diagrams and Inverse Scattering Problems. J. Phys. Condens. Matter 2022, 34, 044002. [Google Scholar] [CrossRef]
- Kautzsch, L.; Ortiz, B.R.; Mallayya, K.; Plumb, J.; Pokharel, G.; Ruff, J.P.C.; Islam, Z.; Kim, E.A.; Seshadri, R.; Wilson, S.D. Structural Evolution of the Kagome Superconductors A V3Sb5 (A = K, Rb, and Cs) through Charge Density Wave Order. Phys. Rev. Mater. 2023, 7, 024806. [Google Scholar] [CrossRef]
- Song, Y.; Tamura, N.; Zhang, C.; Karami, M.; Chen, X. Data-Driven Approach for Synchrotron X-Ray Laue Microdiffraction Scan Analysis. Acta Crystallogr. A Found. Adv. 2019, 75, 876–888. [Google Scholar] [CrossRef]
- Al Hasan, N.M.; Hou, H.; Gao, T.; Counsell, J.; Sarker, S.; Thienhaus, S.; Walton, E.; Decker, P.; Mehta, A.; Ludwig, A.; et al. Combinatorial Exploration and Mapping of Phase Transformation in a Ni-Ti-Co Thin Film Library. ACS Comb. Sci. 2020, 22, 641–648. [Google Scholar] [CrossRef]
- Narayanachari, K.V.L.V.; Bruce Buchholz, D.; Goldfine, E.A.; Wenderott, J.K.; Haile, S.M.; Bedzyk, M.J. Combinatorial Approach for Single-Crystalline Taon Growth: Epitaxial β-Taon (100)/α-Al2O3 (012). ACS Appl. Electron. Mater. 2020, 2, 3571–3576. [Google Scholar] [CrossRef]
- Utimula, K.; Hunkao, R.; Yano, M.; Kimoto, H.; Hongo, K.; Kawaguchi, S.; Suwanna, S.; Maezono, R. Machine-Learning Clustering Technique Applied to Powder X-Ray Diffraction Patterns to Distinguish Compositions of ThMn12-Type Alloys. Adv. Theory Simul. 2020, 3, 2000039. [Google Scholar] [CrossRef]
- Utimula, K.; Yano, M.; Kimoto, H.; Hongo, K.; Nakano, K.; Maezono, R. Feature Space of XRD Patterns Constructed by an Autoencoder. Adv. Theory Simul. 2023, 6, 2200613. [Google Scholar] [CrossRef]
- Boulle, A.; Debelle, A. Convolutional Neural Network Analysis of X-Ray Diffraction Data: Strain Profile Retrieval in Ion Beam Modified Materials. Mach. Learn. Sci. Technol. 2023, 4, 015002. [Google Scholar] [CrossRef]
- Mitsui, S.; Sasaki, T.; Shinya, M.; Arai, Y.; Nishimura, R. Anomaly Detection in Rails Using Dimensionality Reduction. ISIJ Int. 2023, 63, 170–178. [Google Scholar] [CrossRef]
- Wu, L.; Yoo, S.; Suzana, A.F.; Assefa, T.A.; Diao, J.; Harder, R.J.; Cha, W.; Robinson, I.K. Three-Dimensional Coherent X-Ray Diffraction Imaging via Deep Convolutional Neural Networks. NPJ Comput. Mater. 2021, 7, 175. [Google Scholar] [CrossRef]
- Chang, M.-C.; Tung, C.-H.; Chang, S.-Y.; Carrillo, J.M.; Wang, Y.; Sumpter, B.G.; Huang, G.-R.; Do, C.; Chen, W.-R. A Machine Learning Inversion Scheme for Determining Interaction from Scattering. Commun. Phys. 2022, 5, 46. [Google Scholar] [CrossRef]
- Kløve, M.; Sommer, S.; Iversen, B.B.; Hammer, B.; Dononelli, W. A Machine-Learning-Based Approach for Solving Atomic Structures of Nanomaterials Combining Pair Distribution Functions with Density Functional Theory. Adv. Mater. 2023, 35, 2208220. [Google Scholar] [CrossRef]
- Lee, B.D.; Lee, J.-W.; Park, W.B.; Park, J.; Cho, M.-Y.; Pal Singh, S.; Pyo, M.; Sohn, K.-S. Powder X-Ray Diffraction Pattern Is All You Need for Machine-Learning-Based Symmetry Identification and Property Prediction. Adv. Intell. Syst. 2022, 4, 2200042. [Google Scholar] [CrossRef]
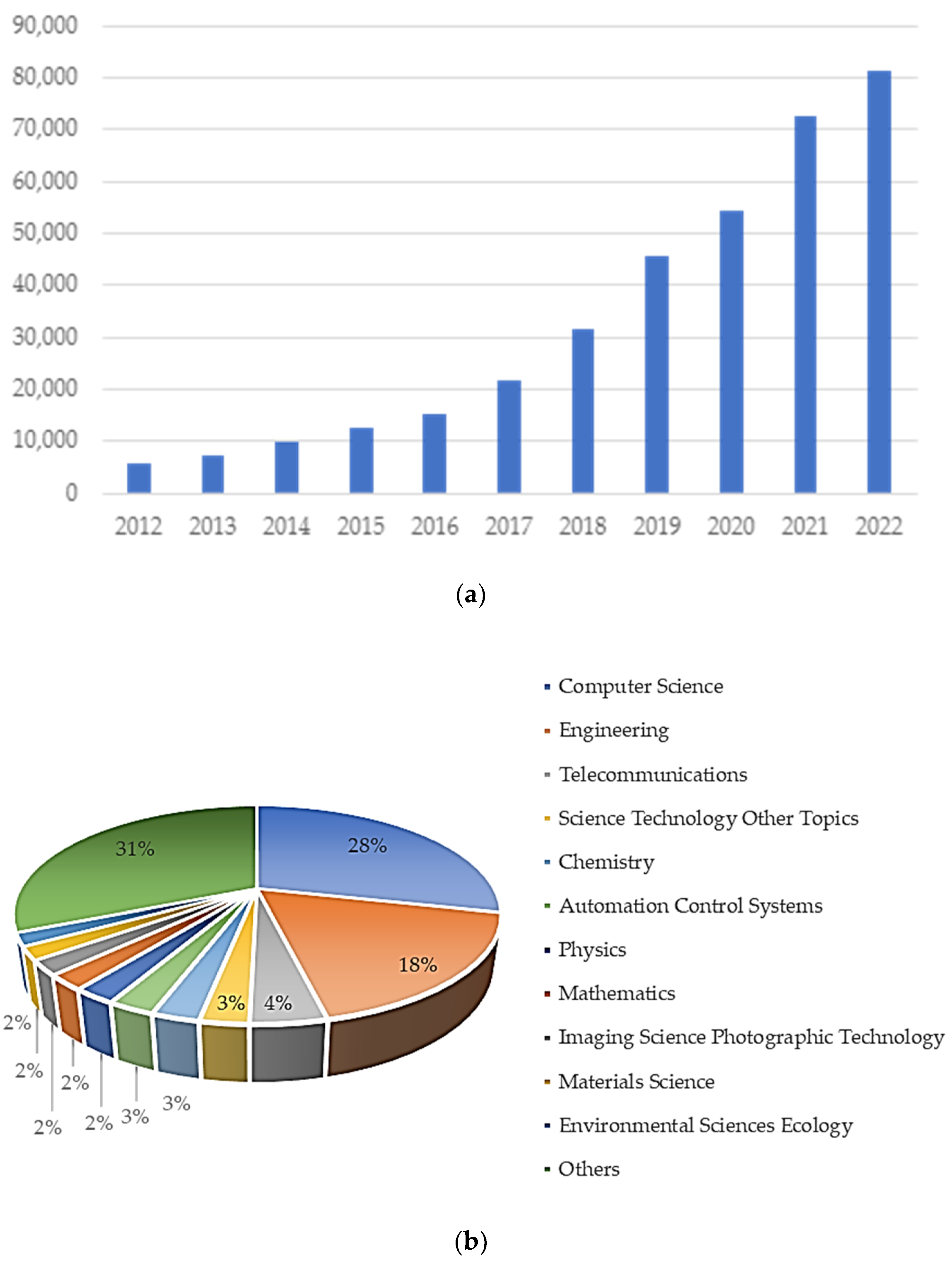


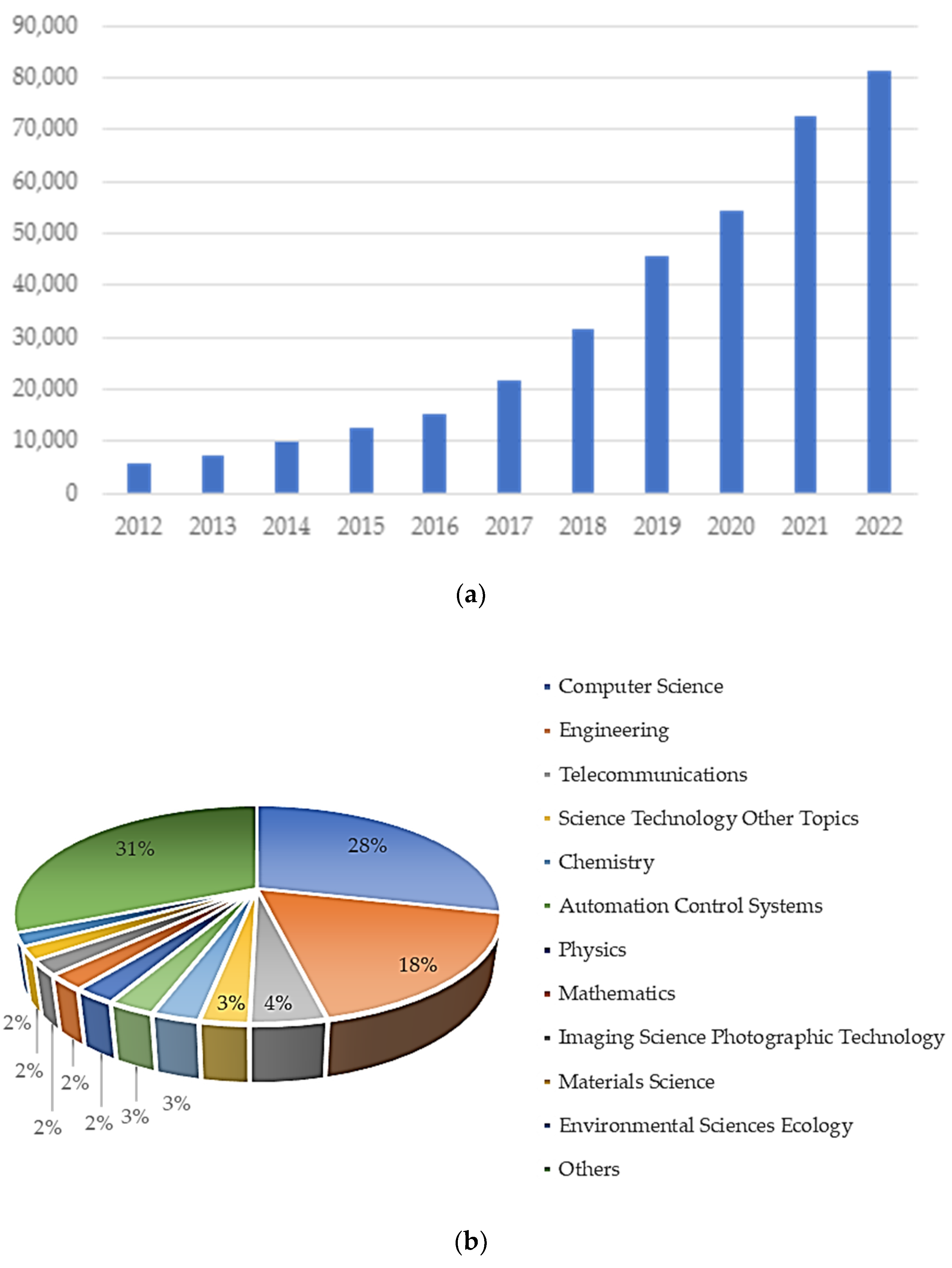{kind=link}
{kind=link}
| Group Number | Group Attributes | Labels |
|---|---|---|
| G1 | Experiments | GIWAXS, GISAXS, TSAXS, TWAXS, GTSAXS, Theta sweep, and phi sweep. |
| G2 | Instrumentation | Beam off image, photonics CCD, MarCCD, Linear beamstop, saturation, asymmetric (left/right), and circular beamstop. |
| G3 | Imaging | Specular rod, weak scattering, 2D detector obstruction, strong scattering, saturation artifacts, misaligned, beam streaking, blocked, bad beam shape, direct, object obstruction, empty cell, parasitic slit scattering, and point detector obstruction. |
| G4 | Scattering Features | Horizon, peaks: isolated, ring: oriented z, halo: isotropic, ring: isotropic, ring: textured, higher orders: 2 to 3, ring: oriented xy, vertical streaks, peaks: many/field, diffuse high-q: isotropic, higher orders: 4 to 6, higher orders: 7 to 10, Bragg rods, ring: anisotropic, peaks: along ring, diffuse low-q: isotropic, Yoneda, halo: oriented z, high background, ring: spotted, peak: line Z, peaks: line xy, diffuse low-q: anisotropic, many rings, diffuse low-q: oriented z, diffuse low-q: oriented xy, diffuse specular rod, smeared horizon, symmetry ring: 4-fold, higher orders: 10 to 20, ring doubling, halo: anisotropic, specular rod peaks, ring: oriented other, peaks: line, diffuse high-q: oriented z, peak doubling, halo: oriented xy, diffuse high-q: oriented xy, peaks: line other, waveguide streaks, higher orders: 20 or more, substrate streaks/Kikuchi, diffuse low-q: oriented other, halo: spotted, diffuse low-q: spotted, and diffuse high-q: spotted. |
| G5 | Samples | Thin film, ordered, single crystal, grating, amorphous, composite, nanoporous, powder, and polycrystalline. |
| G6 | Materials | Polymer, block–copolymer, and superlattice. |
| G7 | Specific Substances | P3HT, SiO2, PCBM, rubrene, PS-PMMA, silicon, MWCNT, PDMS, AgBH, and LaB6. |
| Class | Classifier | ||||||
|---|---|---|---|---|---|---|---|
| SVM | NB | KNN | RF | CNN: Cartesian | CNN: Polar-Min | CNN: Polar-Max | |
| Artifact | 0.85 | 0.78 | 0.87 | 0.91 | 0.94 | 0.93 | 0.92 |
| Background Ring | 0.72 | 0.61 | 0.72 | 0.86 | 0.92 | 0.91 | 0.90 |
| Diffuse Scattering | 0.93 | 0.45 | 0.93 | 0.93 | 0.96 | 0.95 | 0.97 |
| Ice Ring | 0.14 | 0.80 | 0.93 | 0.95 | 0.99 | 0.99 | 0.98 |
| Loop Scattering | 0.70 | 0.62 | 0.71 | 0.83 | 0.94 | 0.95 | 0.96 |
| Nonuniform Detector Response | 0.45 | 0.68 | 0.75 | 0.81 | 0.87 | 0.89 | 0.89 |
| Strong Background | 0.90 | 0.87 | 0.89 | 0.93 | 0.94 | 0.91 | 0.93 |
| Mineral Group | Mineral |
|---|---|
| Clay Minerals | Smectite, chlorite, sericite, and kaolinite |
| Zeolite Minerals | Laumontite and wairakite |
| Silica Minerals | Tridymite and cristobalite |
| Silicate Minerals | Clinopyroxene, epidote, prehnite, antrophyllite, and biotite, cordierite, and talc |
| Oxide Minerals | Magnetite, ilmenite, hematite, anatase, and rutile |
| Sulfide Minerals | Marcasite |
| Sulfate Minerals | Anhydrite and alunite |
| Carbonate Minerals | Calcite |
| Dataset | CNN | KNN | RF | SVM | |
| Synthetic dataset | D1-trained | 94.36% | 12.15% | 56.82% | 33.60% |
| D2-trained | 96.47% | 13.08% | 63.62% | 42.74% | |
| Real-world dataset | D1-trained | 88.88% | 24.44% | 17.78% | 13.33% |
| D2-trained | 91.11% | 22.22% | 15.56% | 13.33% |
| Dataset | ANN | KNN | RF | SVM | |
|---|---|---|---|---|---|
| Synthetic dataset | MSE | 0.004612 | 0.002507 | 0.003987 | 0.001809 |
| R2 | 0.923253 | 0.956168 | 0.930789 | 0.968471 | |
| Real-world dataset | MSE | 0.008260 | 0.008035 | 0.006453 | 0.002423 |
| R2 | 0.821816 | 0.860250 | 0.894196 | 0.958704 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Surdu, V.-A.; Győrgy, R. X-ray Diffraction Data Analysis by Machine Learning Methods—A Review. Appl. Sci. 2023, 13, 9992. https://doi.org/10.3390/app13179992
Surdu V-A, Győrgy R. X-ray Diffraction Data Analysis by Machine Learning Methods—A Review. Applied Sciences. 2023; 13(17):9992. https://doi.org/10.3390/app13179992
Chicago/Turabian StyleSurdu, Vasile-Adrian, and Romuald Győrgy. 2023. "X-ray Diffraction Data Analysis by Machine Learning Methods—A Review" Applied Sciences 13, no. 17: 9992. https://doi.org/10.3390/app13179992
APA StyleSurdu, V.-A., & Győrgy, R. (2023). X-ray Diffraction Data Analysis by Machine Learning Methods—A Review. Applied Sciences, 13(17), 9992. https://doi.org/10.3390/app13179992