1. Introduction
With the rapid development of pretraining language models in natural language processing, using language models to finetune downstream tasks has become the primary method. However, there is a particular gap between language models and the training objectives of downstream tasks, which limits the ability of the language model to learn during the training phase, especially in small sample scenarios. To address this issue, Brown et al. [
1] proposed a prompt learning method, which has attracted widespread attention from researchers for its outstanding performance in small sample scenarios.
Earlier studies have demonstrated that cue messages can be constructed manually to stimulate the fact and common sense knowledge learned by pretrained language models during the pretraining stage [
2,
3]. For example, to search for the location of the 2008 Olympic Games, this paper can use “2008 Olympic Games Successfully Held in ___” as a prompt template. This paper fills in “2008” in the first underlined area and asks the language model to predict the words in the second underlined area. The prompt language used by Petroni et al. [
3] was manually created, while Jiang et al. [
2] used mining and reporting-based methods to construct a prompt set. However, the model is susceptible to different prompts [
4], and artificially constructing the best-performing prompt template is like looking for a needle in a haystack, which often requires many validation sets for experimentation [
5]. Because neural networks are inherently continuous, discrete cues may not be the best. For another example, to extract a person’s birth information, this paper can construct a hint of “he was born in ____”. This hint may be effective for men, but there are apparent syntax errors for women. This paper should now replace “he” with “she” in the hint. In response to the previous issue, the continuous prompt proposed by Li et al. [
6] and Zhong et al. [
7] is no longer constructed manually. Instead, it inputs virtual prompts automatically updated using model backpropagation. The advantage of doing so is that it can automatically search for the most suitable prompt for the current input through gradient descent while avoiding the syntax universality problem of manually constructing a prompt.
This paper proposes a hybrid prompt that introduces a discrete prompt in the continuous prompt by combining a discrete prompt [
8] with the continuous prompt. This paper used the cross-language pretraining model CINO (Chinese mINOrity PLM) [
9] as a classifier and trained discrete, continuous, and mixed prompts on a small sample cross-language text topic classification task [
10]. This paper compared the results and found that the mixed prompt was more stable and effective compared to the continuous prompt. To set the length of the virtual token in the continuous prompt and mixed prompt, this paper designed several groups of hyperparameters for experiments. The experimental results show that the length of the virtual token should not exceed the average length of sentences in the dataset. Finally, this paper utilized the vector similarity method to explore the true meaning represented by the virtual token, and the results showed that the language model knew more than we thought and could automatically generate an appropriate prompt based on input samples [
11].
This article proposes a hybrid prompt learning method that combines manually constructed discrete prompts with continuous prompts. It can compensate for the shortcomings of discrete and continuous prompts, and effectively provide richer language knowledge for the model. Secondly, the setting of virtual token hyperparameters in continuous and hybrid prompts was analyzed, and an appropriate range of length hyperparameters was obtained. At the same time, we apply cosine similarity analysis of the algorithms and discuss the actual meaning of a virtual token and its impact on the model.
The structure of this article is as follows: The introduction introduces the development of the prompt; the relevant work regarding our prompt is explained in
Section 2; in
Section 3, this paper reviews the theory and related structures of the prompt; in
Section 4, this paper discusses the theoretical performance of discrete, continuous, and mixed prompts, and analyzes their advantages and disadvantages; in
Section 5, this paper compares the performance differences between discrete, continuous, and mixed prompts for cross-language text topic classification scenarios, and analyzes and explores the length setting of the virtual token. Finally, this paper designs a method to explore the true meaning represented by a virtual token; in the concluding section, this paper summarizes the work and some research directions that can be further developed in the future.
2. Related Work
Few-shot sample research is a research method for text analysis and modelling with very limited data sets. In the field of natural language processing, large amounts of text data are usually required to train accurate models and algorithms, but in some application scenarios, it may be very difficult or impractical to obtain large amounts of text data. In such cases, researchers can use existing text datasets and try to analyze the text using small sample learning methods to achieve the most accurate results. In a small sample learning task, the model can improve its learning by using additional information or prior knowledge. This approach allows the model to make better use of the limited sample data to produce better results.
Prompt learning is an emerging technology in natural language processing that adopts a linguistic prompt-based approach to guide the model to generate text by providing natural language prompts, so as to achieve the tasks of text generation, text classification [
12,
13], question answering, and so on in small sample scenarios. Compared with traditional label-based and rule-based machine learning methods, cue learning can process text data more naturally and efficiently, and at the same time has good interpretability and scalability. The core idea of prompt learning is to use short natural language texts (prompts) to guide the output of the model. These hints can be a question, a topic, a keyword, etc., which are used to guide the model to generate relevant text.
Brown et al. [
1] proposed using prompt learning in GPT-3 to finetune language models, achieving excellent performance in small sample scenarios. Since then, prompt-based learning has received widespread attention. Language prompts have proved to be effective in downstream tasks leveraging pretrained language models [
14,
15,
16]. Schick and Schütze [
17,
18] proposed PET, which converts input text into closed-form representations to help language models understand given tasks and perform gradient-based finetuning. Tam et al. [
19] improved PET with more dense supervised objects when finetuning language models. Han et al. [
20] proposed PTR to solve multicategory relationship extraction tasks, using logical rules to construct multiple subprompts manually and then combine these subprompts into a complete task-specific prompt. However, these methods require manual template design and require a significant amount of manpower.
In order to avoid manual prompt design, some researchers use the method of automatic prompt search to construct prompt templates. Shin et al., proposed AUTOPROMPT, which uses a gradient search-based method to generate a set of templates and label words. Wang et al. [
21] proposed remodeling downstream tasks as textual tasks and then finetuning the model with small samples. Gao et al. [
4] proposed LM-BFF, which utilizes the T5 model to train on a training set and generate a series of templates. These methods mainly construct prompt templates in discrete space, which limits the ability of the language models. Therefore, some scholars have proposed searching in the continuous space of language models in order to construct templates that are more appropriate to the language model. Liu et al. [
5] proposed P-tuning, which uses LSTM to learn trainable continuous prompt cue embeddings and optimize them during training. Lester et al. [
22] proposed a mechanism for learning “soft cues” to freeze language models for the conditional performance of downstream tasks. However, these methods still require optimization of external parameters (such as LSTM in P-tuning) and are prone to complex label spaces. Zhang et al. [
23] significantly improved the learning ability of machine intelligence and practical adaptive applications. Small sample learning only requires access to a small number of annotated samples.
3. Methods
Our experiments aim to investigate the differences in the ability of discrete, continuous, and hybrid prompts to handle the same problem in the same scenario, and for this purpose, this paper unifies the models and datasets used during the experiments. The prompt designed in the thesis is a paragraph or sentence containing two empty spaces, for example, the following prompt on topic classification:
This paper puts the original input
into
and then calculates the probability distribution of the output of the language model (LM)
, which gives us
, the padding value at
Our optimization objective is, therefore:
where
denotes the vocabulary of the language model.
3.1. Discrete Prompt
A discrete prompt is composed by adding an artificially constructed prompt sentence before or after the original input sentence [
1,
24]. These options can be predefined or dynamically generated based on a specific question or task. The purpose of the discrete prompt is to guide the model in generating the answer by selecting from the given options or generating the appropriate result. Specifically, taking topic classification as an example, for a given sentence containing
sentences containing token
, the general discrete prompt representation is as follows:
where
, where there is at least one index
, such that
= [MASK] is used to predict the label. In this article, our artificially constructed discrete prompt is shown below:
Taking a sample in the dataset as an example, the input to the model is: “This is a [MASK] text. Liaoning Youth is a youth publication distributed in mainland China. Its predecessor was Life Knowledge Newspaper on 15 August 1949.” The output of the model at position [MASK] is
, and satisfies
. If the model fills the [MASK] position with “art”, the model predicts correctly. Otherwise, it predicts incorrectly. The network structure of the discrete prompt is shown in
Figure 1.
In summary, discrete prompting works by adding discrete options to the model input in order to guide the model to choose from the given options when generating an answer or result. This approach involves the construction of model inputs and the preparation and goal setting for model training. With proper design and training, discrete prompts can help models better understand task requirements and produce more accurate and consistent results.
3.2. Continuous Prompt
The continuous prompt is not fed into the model as a discrete token but as a continuous vector [
20,
22,
25,
26]. Rather than relying on predefined options or choices, a continuous prompt provides contextual information to guide the model in generating continuous results by providing continuous text. The model can generate an appropriate continuous output based on the input continuous text sequence to meet the requirements of a particular task. Specifically, for a given sentence containing m token
, the generic continuous type of prompt is represented as follows:
of which
,
denotes the vector obtained by feeding,
is the vector obtained by feeding the prompt encoder, and
denotes the vector obtained by feeding the token;
is the vector obtained by feeding the token into the embedded word, where there is at least one index
such that
, and at this point, the token is replaced by
, which is replaced by
.
Unlike a discrete prompt, a continuous prompt is initially provided with templates
that may not be in a natural language. In this article, the special token [PAD] is used to initialize each
. Thus, the continuous prompt constructed in this article is shown below:
Taking a sample in the dataset as an example, the input to the model is as follows:
“[PAD] [PAD] … [PAD] [MASK]. Liaoning Youth is a youth publication distributed in mainland China. Its predecessor was Life Knowledge Newspaper on 15 August 1949.”
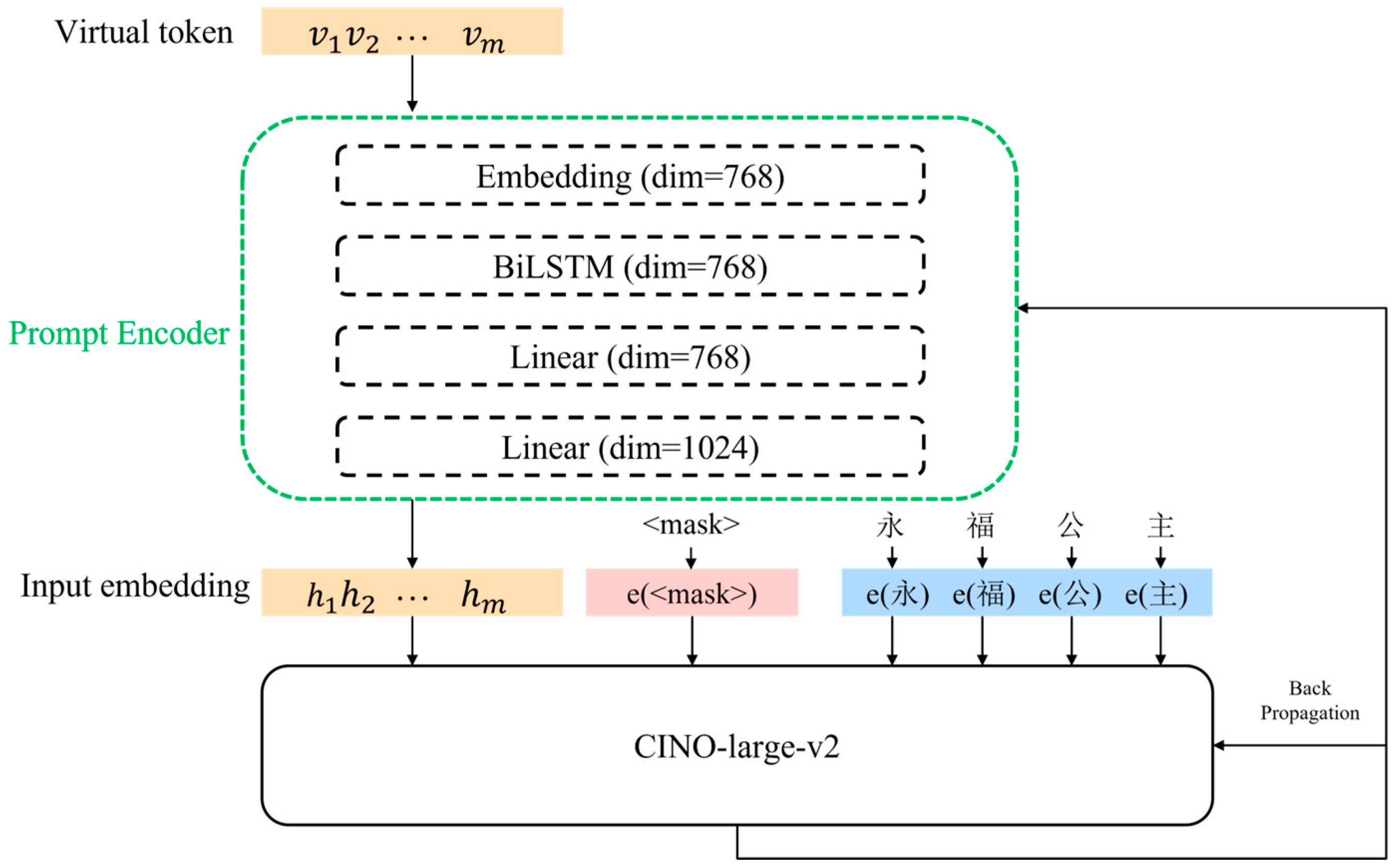
Since the set v of a token in a continuous prompt does not have an actual meaning but acts like a placeholder, this paper calls the prompt in the continuous prompt a virtual prompt or virtual token. The structure of the continuous prompt network constructed in this article is shown in
Figure 2.
In summary, the continuous prompt guides the model to produce a coherent output by taking a continuous sequence of text as the input. The input representation stage combines successive segments of text into one long input sequence. The generation process uses an autoregressive approach where the model progressively generates the next word or phrase to build a coherent output sequence. This approach allows the model to understand contextual information and generate contextually appropriate results.
3.3. Hybrid Prompt
A hybrid prompt is a combination of discrete prompts and continuous prompts, in which there are both artificially constructed prompts and virtual prompts. The purpose of the hybrid prompt is to combine multiple sources of information to generate richer and more diverse results. Specifically, for a given sentence containing
sentence with a token
, the generic hybrid prompt is represented as follows:
of which
, the
denotes the vector obtained by feeding the token,
is the vector obtained by feeding the token into the prompt encoder, and
denotes the vector obtained by feeding the token;
is the vector obtained by feeding the token into the word embedding. There is at least one index
and
such that
that
is an artificially constructed cue, and at this point, it is replaced by
, which replaces
, and
replaces
.
To ensure consistency in our experiments, this paper treats the virtual token in the hybrid prompt the same as the continuous prompt, both using
for initialization. The hybrid prompt constructed in this article is shown below:
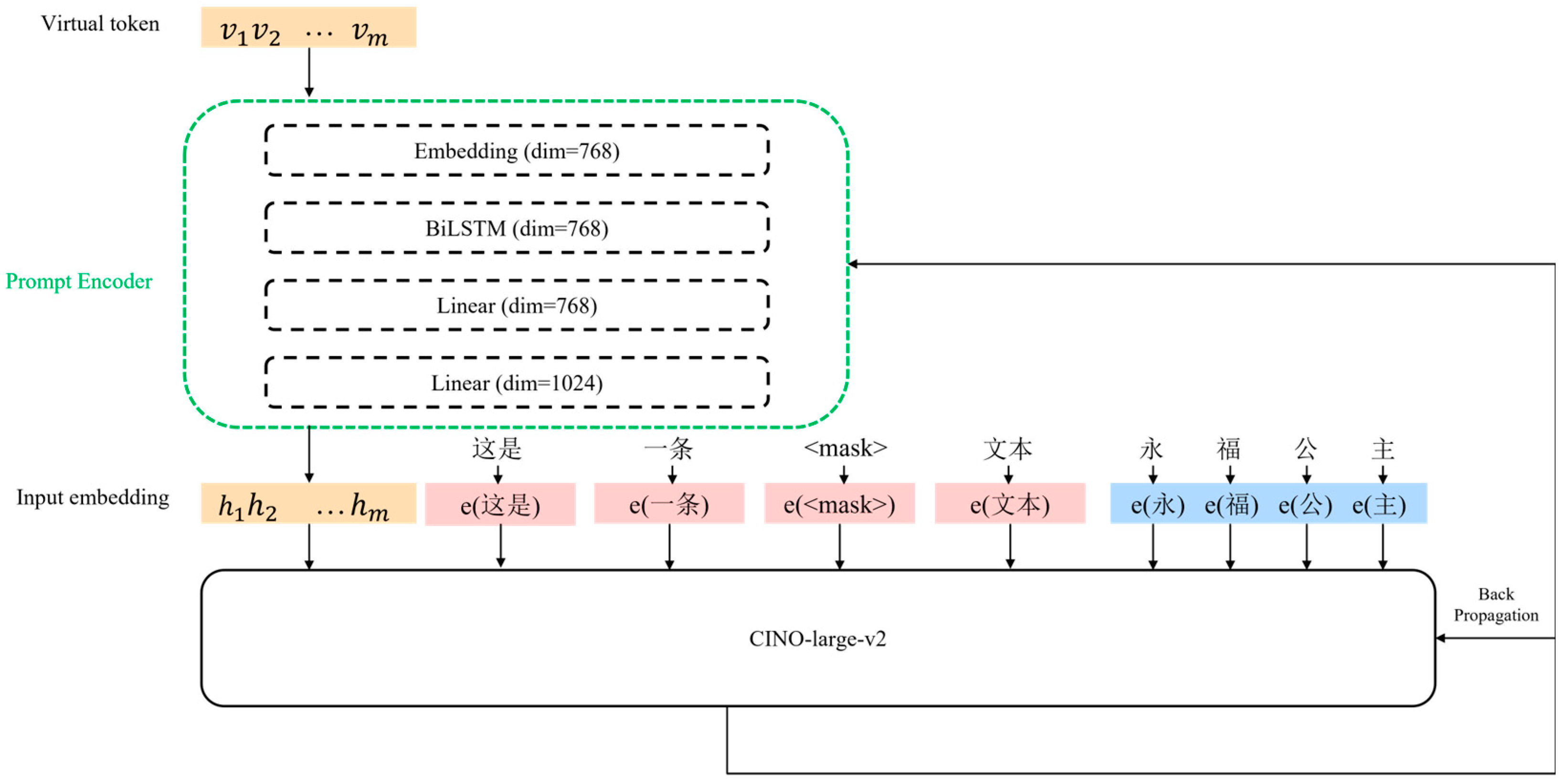
Taking a sample in the dataset as an example, the input to the model is as follows:
“
Liaoning Youth is a youth publication distributed in mainland China. Its predecessor was Life Knowledge Newspaper on 15 August 1949.” The structure of the hybrid prompt network constructed in this article is shown in
Figure 3.
In summary, hybrid prompts are used to guide the model in generating an output using several different types of prompts. This includes the selection of prompts, the combination of prompts, and the generation process. The purpose of a hybrid prompt is to combine multiple sources of information to produce richer and more varied generated results. By introducing multiple prompts into the model, richer guidance and constraints can be provided to enable the model to generate more creative and diverse outputs.
4. Theoretical Analysis
Before the experiment, this paper first compares the advantages and disadvantages of finetuning and prompts in theory, followed by a theoretical analysis of discrete prompt, continuous prompt, and hybrid prompt architectures.
Taking text topic classification as an example, in the standard finetuning process, researchers typically add a fully connected linear layer to transform dimensions as a classifier after the model. Compared to the original pretrained model, the new layer introduces additional parameters, which increases time and space consumption during training. For example, a binary classification model based on RoBERTa-large [
27] introduces at least 2048 additional parameters, and the model requires a large amount of annotated data for training to learn about downstream tasks. However, if there are only 100 training samples in a small sample scenario, finetuning becomes very difficult, which causes overfitting. Unlike finetuning, the prompt method directly converts downstream tasks into masked language modeling tasks with limited output space [
28]. It only finetunes the pretrained model parameters without introducing new parameters, narrowing the gap between the pretrained and downstream tasks. Therefore, the prompt method is more effective in small sample scenarios than in finetuning.
For a discrete prompt, given a pretrained model , a discrete sequence of input tokens is used by the pretrained model of the word-embedding layer mapped as an embedding vector {}. The role of the prompt is to map the input , the tag and itself into a template T. For example, if we want to predict the capital of a country, we can construct the prompt: “The capital of the UK is [MASK]”, where the UK is the input and [MASK] is the location of the label output.
The construction method of the discrete prompt mentioned above is straightforward, but in practical use, it faces a discreteness challenge. During the gradient descent process, the word embedding e only changes in a small range for the dense vector generated by any discrete input [
29]. In other words, the optimizer is prone to falling into local minima. In order to avoid such discreteness issues, continuous prompts have emerged. The structure of a continuous prompt is shown in
Figure 2. Specifically, it includes an embedding layer for encoding virtual tokens into vectors. Liu et al. [
30] believed that the suggested embedding vectors should be interdependent rather than independent so that structures such as LSTM [
31] or TextCNN [
32] can be used to embed virtual tokens for correlation and finally a two-layer neural network connected using a ReLU activation function. If the virtual input token is
, we can obtain its vector representation using the following equation
(
https://huggingface.co/hfl/cino-large-v2/ (accessed on 15 March 2023)):
Continuous prompts solve the instability of discrete prompts and avoid the problem of manual construction of hints, but they still have some shortcomings. For example, it is not clear what the virtual token really represents, so there is a real possibility that the virtual token will not work. To address this situation, this paper proposes a hybrid prompt that introduces a discrete prompt within a continuous prompt.
The original intention of the hybrid prompt’s design is to avoid a situation where virtual tokens do not work. At this point, we can consider the dense vectors generated by virtual tokens as meaningless noise, and the discrete prompts in the hybrid prompt truly serve as reminders. The prompt method essentially provides prior knowledge for the model in addition to input [
30], but model training ultimately relies on the information contained in the original sentence. If the length of the prompt exceeds a certain threshold, it will, to some extent, mask the original information, thereby having a negative impact on the model’s training. Therefore, one of the purposes of our experiment is to identify this threshold, i.e., to analyze the impact of virtual token length on prompt performance.
5. Experiment
There are three issues that need to be addressed in this article: firstly, the performance differences between discrete, continuous, and mixed prompts and finetuning are compared; secondly, for continuous and mixed prompts, the impact of the length of the virtual token on the performance is analyzed, and an appropriate hyperparameter range of length is obtained; finally, this paper explores the meaning represented by the virtual token.
The experimental task in this article is a few-shot cross-linguistic textual topic with ten classifications with the true label set of:
The dataset this paper used was the Wikipedia corpus of minority languages and its classification system tag Wiki-Chinese-Minority (WCM), with a training set of 100 sentences, a validation set of 100 sentences, and a test set of 385 sentences. The detailed data distribution is shown in
Table 1.
We chose the pretrained language model CINO-large-v2 as the classifier and conducted experiments on four cases: discrete, continuous, mixed prompt, and finetune. Learning rate = 1 × 10−5, batch size = 32, epoch = 50, and other parameters are the same as the original model. Three different experiments were conducted on three random seeds for each case, and the results were taken as the average F1 value of the three random seeds on the test set.
5.1. Discrete Prompt
The discrete prompt set up for the experiments in this article is shown below:
, the output of the position, is one of the true label sets
.
Figure 4 shows the F1 values on the validation set at the end of each epoch for 50 epochs trained using the discrete prompt. The middle dash is the average of the three random seeds, and the shading is the maximum and minimum values of the effect of different random seeds running out of the same epoch, respectively. The performance of the discrete prompt on the test set is shown in
Table 2.
5.2. Continuous Prompt
The experiments in this article were designed with a continuous type of prompt:
Among them,
is a virtual token; the setting of its length hyperparameter is the focus of this experiment; we designed the length of the virtual token as
p = 6, 10, 50, 68, 100, 200, 201, 202, respectively (68 is the average length of the corpus of this experimental dataset). For each hyperparameter
, we used three different random seeds for each experiment, and the F1 values of the validation set are shown in
Figure 5 and
Figure 6.
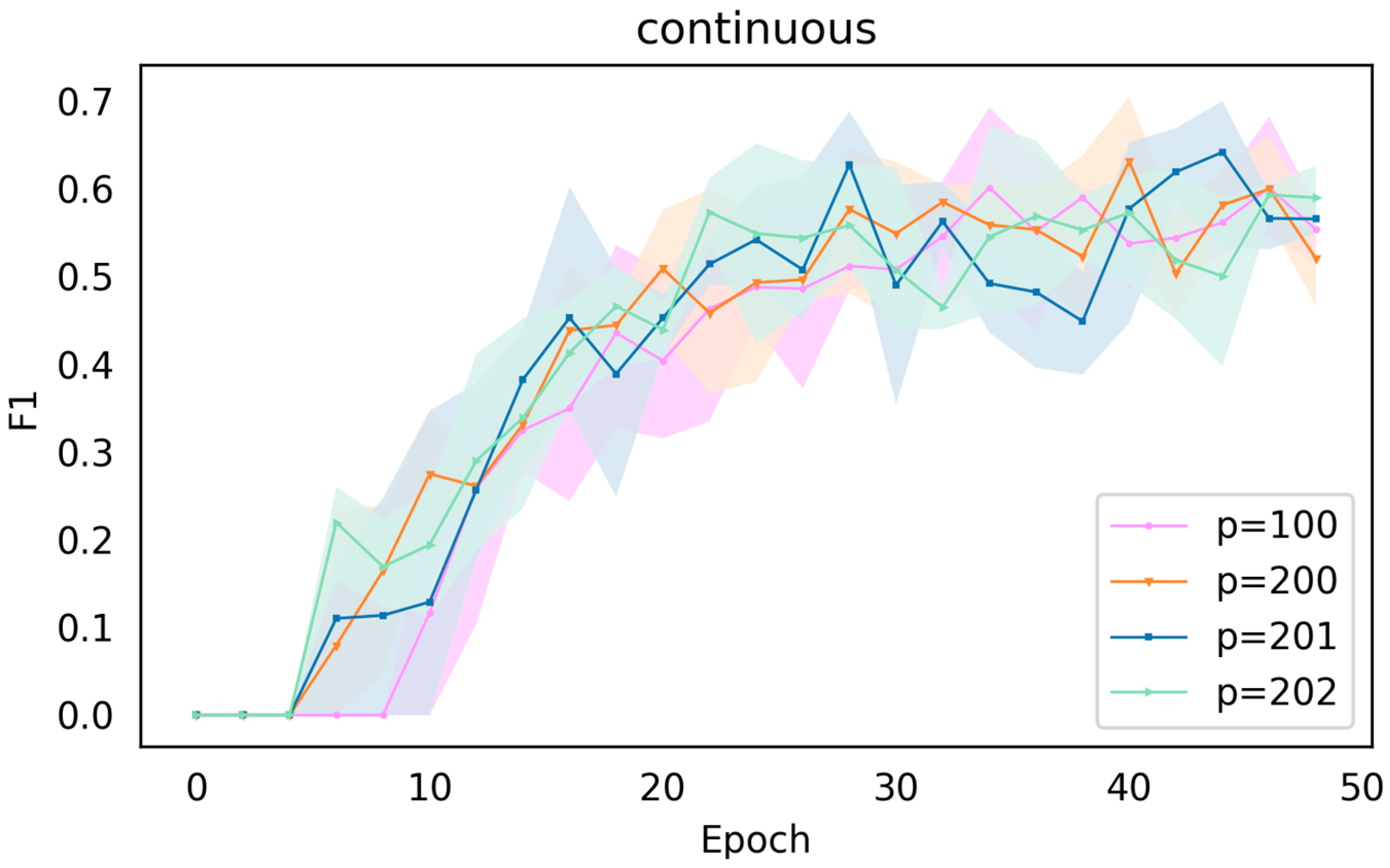
In
Figure 5, i.e., the comparison for
= 6, 10, 50, 68, it is clear that there is a more significant drop in the effect when the length of the virtual token reaches the average length of the dataset
= 68, whereas the effects for
= 6, 10, 50 are closer without much difference.
Comparing
Figure 5 and
Figure 6, it can be found that when the length
of the virtual token is greater than the average length 68 of the dataset, the overall process oscillates heavily and presents a hard-to-converge state, and this hard-to-converge state is especially obvious when comparing with
Figure 5.
The effect of the continuous prompt on the test set is shown in
Table 3. From
Table 3, when the length of the virtual token is 6, the continuous prompt has the best effect. When the length
= 68, the F1 values are all above 70, but when
> 68, the effect decreases significantly. From this, it can be found that the virtual token length of a continuous prompt has a certain relationship with the average sentence length of the dataset, and there is a threshold. When the virtual token length is greater than this threshold, the final effect of the model decreases.
5.3. Hybrid Prompt
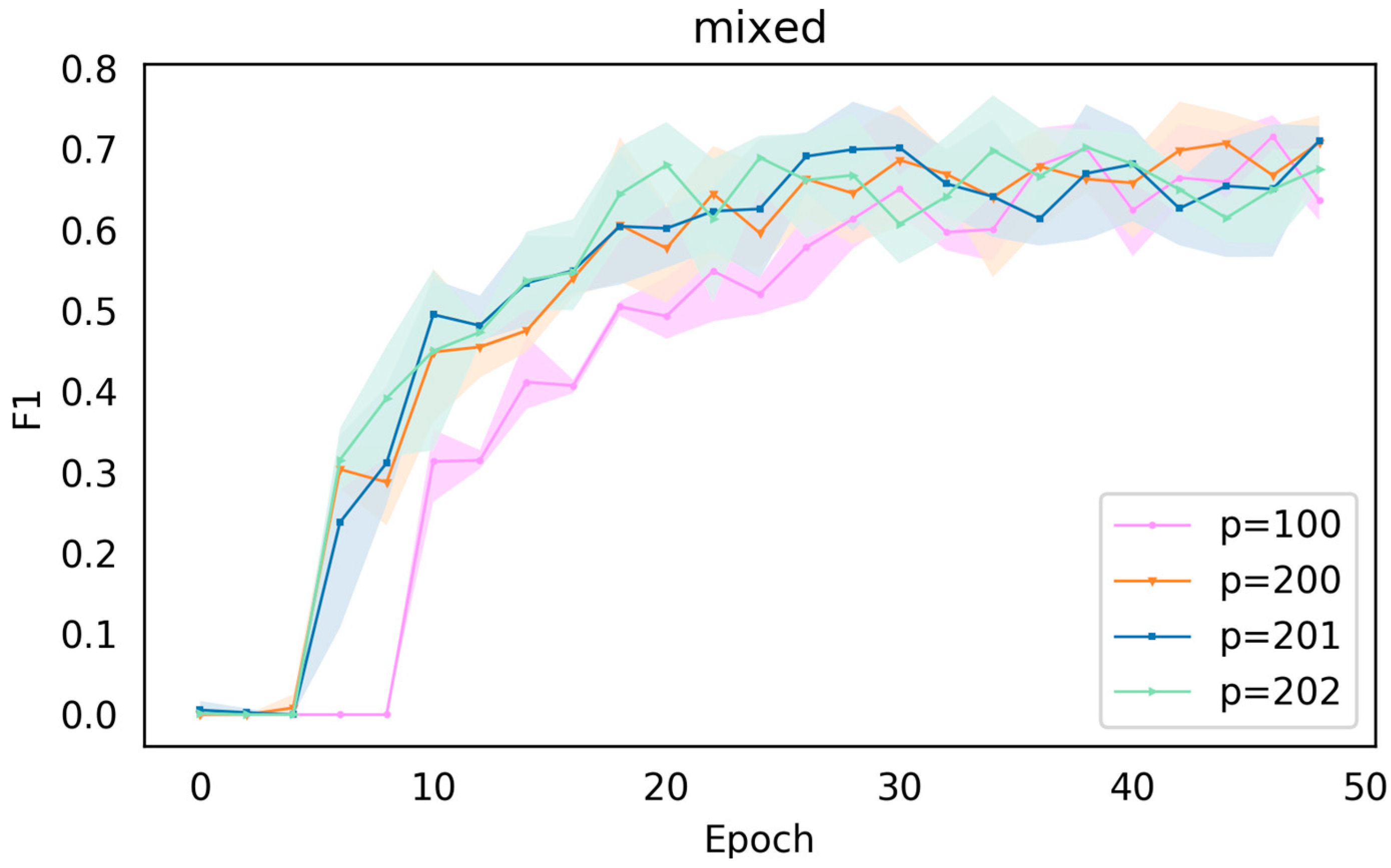
The experimental design of the hybrid prompt in this article is as shown below:
For the hybrid prompt, the research focus is also on the length
of the virtual token, which is similar to the continuous prompt. We also set eight hyperparameters,
= 6, 10, 50, 68, 100, 200, 201, and 202. The F1 value’s influence on the verification set is shown in
Figure 7 and
Figure 8.
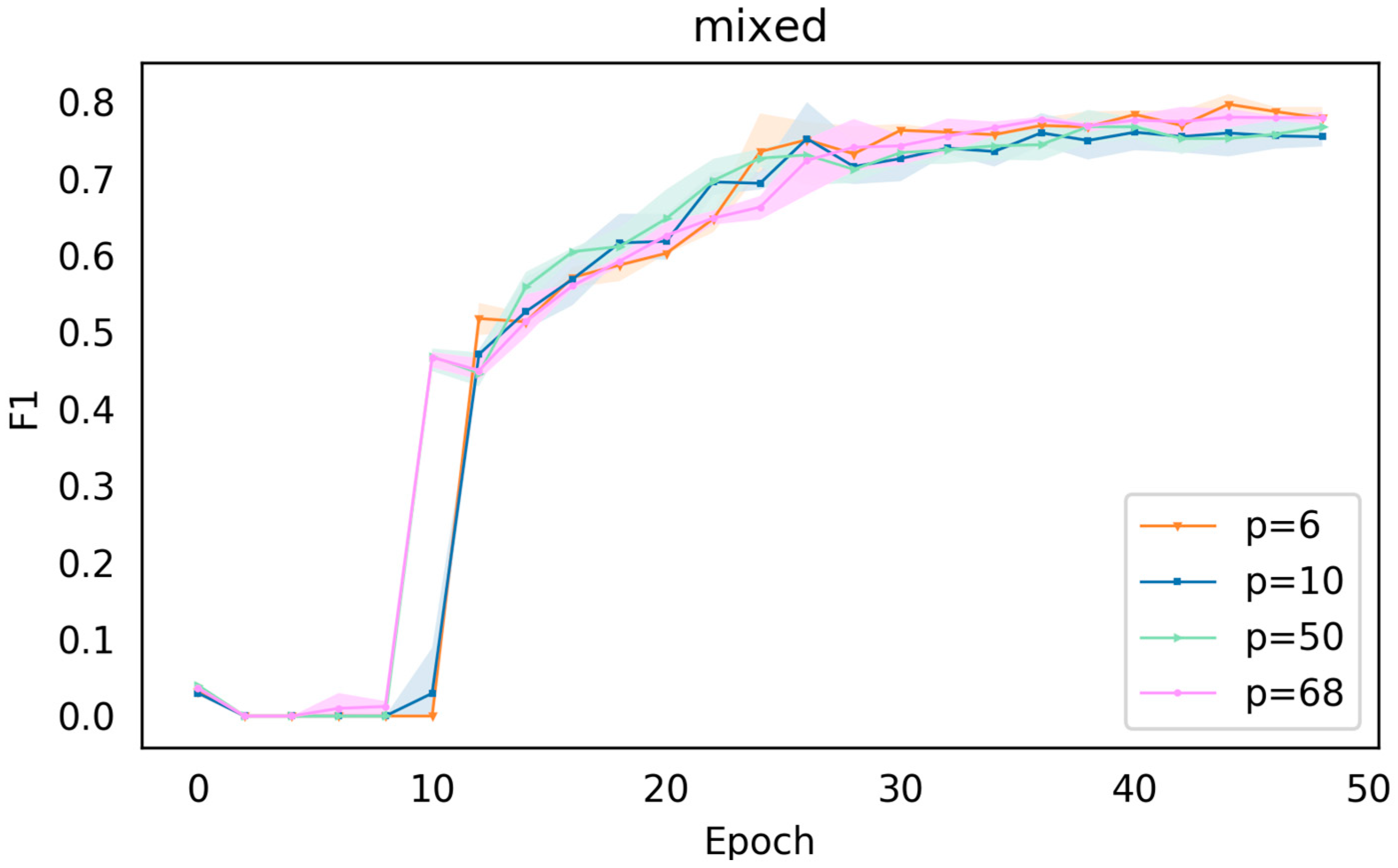
As can be seen from
Figure 7, the effect of
= 6 is slightly better among these four parameters. It is worth noting that, again, for
= 6, 10, 50, 68, the overall curve for the hybrid prompt is more compact than the continuous one, suggesting that the discrete cues in the hybrid play a role in helping the model train.
Comparing
Figure 7 and
Figure 8, we can see that when the length
of the virtual token is greater than the average length 68 of the dataset, the overall process is also oscillates heavily, showing a state of hard convergence.
The effect of the hybrid prompt on the test set is shown in
Table 4. As can be seen from
Table 4, the hybrid prompt works best when the length of the virtual token is 50. Unlike the continuous prompt, the performance of the model does not show significant degradation even when the length of the virtual token is greater than 68. We believe that this may be due to the role played by the discrete prompt, and when comparing
Table 3 and
Table 4, it is clear that the overall effect of the hybrid prompt is better than that of the continuous prompt, suggesting that introducing an artificially constructed discrete prompt into the continuous prompt helps the model learn more.
5.4. Finetuning
To ensure consistency, the pretrained model used in finetuning is the same as the above prompt.
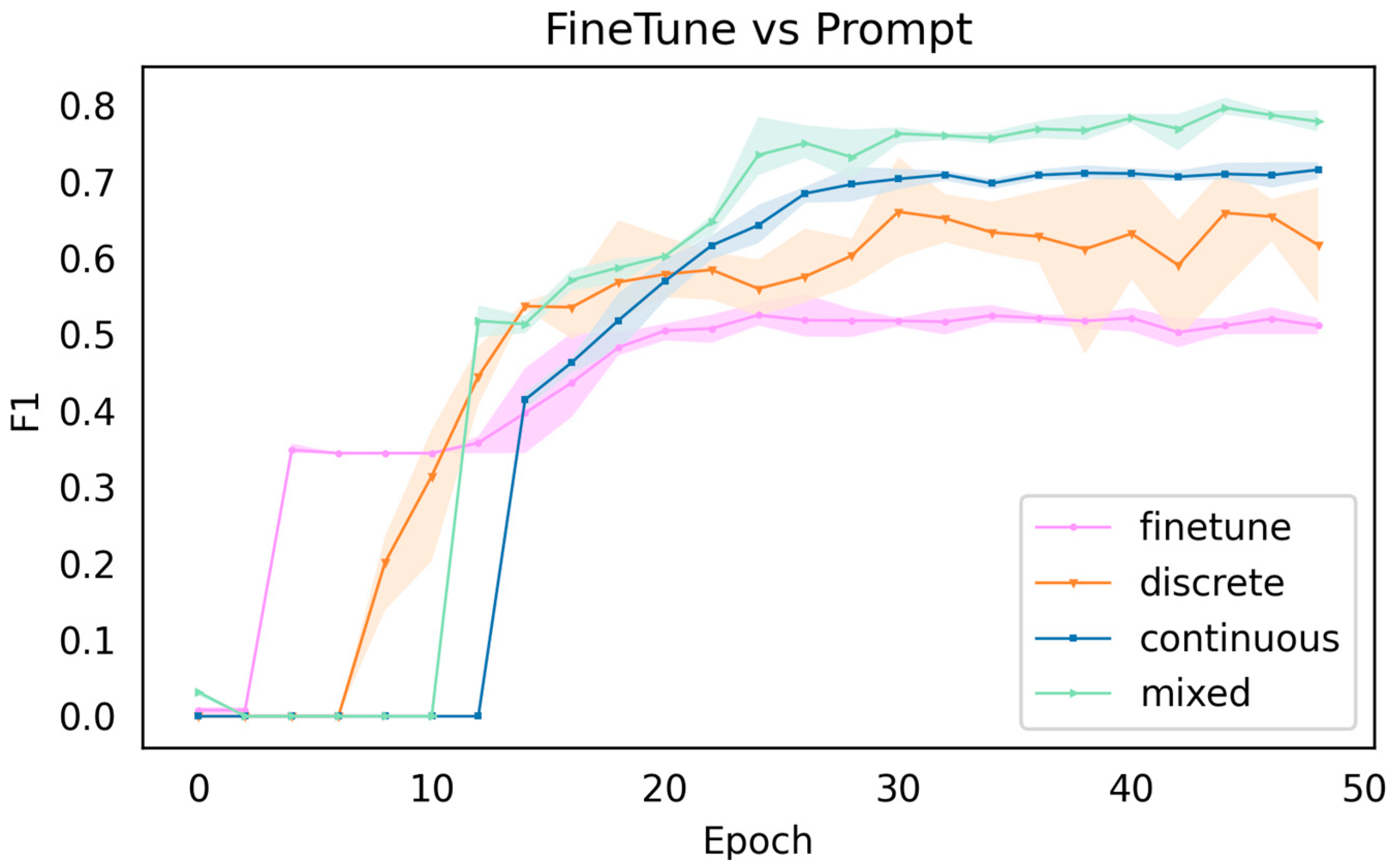
Figure 9 shows the results of finetuning compared to the discrete prompt, continuous prompt, and hybrid prompt on the validation set, where the dummy token lengths for both the continuous and hybrid prompt are 6.
Overall, the results using the prompt method are better than in finetuning, but one thing to note about the results presented in
Figure 9 is that the discrete prompt is very unstable, and at some stages, the results are inferior to finetuning. In the context of the mixed type, the best results are obtained, and the discrete type is slightly better than the continuous type. This paper analyzes two possible reasons for the performance of the continuous and discrete prompts: firstly, the continuous prompt can dynamically generate hints compared to the discrete prompt, but it also introduces more training parameters, which may have an impact on the results; secondly, the discrete prompt is inherently unstable, as it is artificially constructed. The second reason is the instability of the discrete prompt, as the artificially constructed prompt is highly subjective, and the model is very sensitive to changes in discrete inputs, which may have a significant impact on the results simply by adding or subtracting a word/ character. We designed two sets of comparative experiments with a discrete prompt based on the original experiments, and the form of the discrete prompt is shown in
Table 5.
Discrete-deletion and Discrete-add are constructed by removing and adding words or phrases to the original discrete prompt, respectively. The performance of these discrete prompts on the test set is shown in
Table 6. As can be seen from
Table 6, there can be a maximum difference of 2.266% in the effect of a discrete prompt for just one character/word, which shows the instability of the discrete prompts.
5.5. What the Virtual Token Represents
As shown in
Figure 2 and
Figure 3, the vector generated after the virtual token has been passed through the prompt encoder is treated as a word embedding and fed into the model together with the original input word embedding. Let the word embedding matrix be
and the vector
is the virtual token;
is the vector generated by the prompt encoder. This paper compares the vectors
, respectively, with the word embedding
in the vector
. Calculate the similarity if it satisfies:
Then, the words corresponding to the virtual token are considered to be , where “cos”() denotes the calculation of the similarity of the two vectors.
Using the above method, some of the results for the continuous prompt and the mixed prompt are shown in
Table 7.
The dataset used in this paper is a Chinese-Western cross-lingual dataset, but
Table 7 shows that the hints automatically constructed using the virtual token are not limited to Chinese and Uyghur, and it is difficult to take this situation into account by constructing discrete hints artificially, so the virtual token can only learn and select suitable hints by itself. For example, the word “bicarbonate” corresponds to a sample of the “science” category in the dataset (
Table 8).
5.6. Discussion
Through the comparative experiment of finetuning, discrete prompt, and continuous prompt, the performance of each method was analyzed in detail. At the same time, we propose a hybrid prompt learning method, which combines the artificial discrete prompt with the continuous prompt, effectively providing richer and more accurate language prompt information to the model and compensating for the instability of the discrete prompt and the shortcomings of the continuous virtual prompt. The experimental results show that the hybrid prompt can better combine the advantages of both. A series of experiments were carried out to investigate the effect of the virtual token’s length on the performance of the model. The experimental results show that the virtual token’s length has an important impact on the performance of the model. If the virtual token’s length is too long, non-task-specific vocabulary is introduced, which reduces the performance of the model. Finally, we used the cosine similarity calculation method to find the word with the highest similarity in the word embedding to analyze the meaning of the virtual token in the continuous and hybrid prompts. We found that if the length of the virtual token is too long, there are non-task-specific language words in it, which is a kind of noise for the model. Therefore, in practical applications, the appropriate length of the virtual token should be carefully chosen to improve the performance of the model.
6. Conclusions
The aim of this paper was to explore the performance difference between multiple prompts, the length setting problem of virtual tokens, and the real meaning represented by virtual tokens. Based on a cross-lingual text topic classification scenario, we constructed discrete, continuous, and hybrid prompts, and trained the dataset with these three prompts to investigate the effect of different prompts on classification performance under the cross-lingual low-sample topic. Among them, the hybrid prompt was found to be the most effective due to the human-constructed and self-learning prompts, encouraging the model to learn more semantic knowledge from a small number of training samples. Secondly, to address the issue of setting the length of the virtual token, we set eight sets of different length hyperparameters with the average sentence length of the dataset being 68 as the cutoff value, and the experimental results show that the virtual token that exceeded the average length of the corpus in the training set reduced the performance of the model. Finally, in order to understand the real meaning represented by the virtual tokens, we used the cosine similarity-based vector matching method to find the vectors in the word embeddings that are most similar to the vectors of each virtual token, and thus obtained the real tokens represented by each virtual token. The results show that the cues automatically learned by the virtual tokens have some correlation with the input text.
In the future, this research will provide new ideas and solutions for various tasks of natural language processing, such as relationship extraction, entity recognition, text classification and generation. In future work, we plan to incorporate the conclusions of this article into the sentence similarity task [
33] to further improve its performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}