
Performance Evaluation of an API Stock Exchange Web System on Cloud Docker Containers


Abstract
:1. Introduction
1.1. Motivation
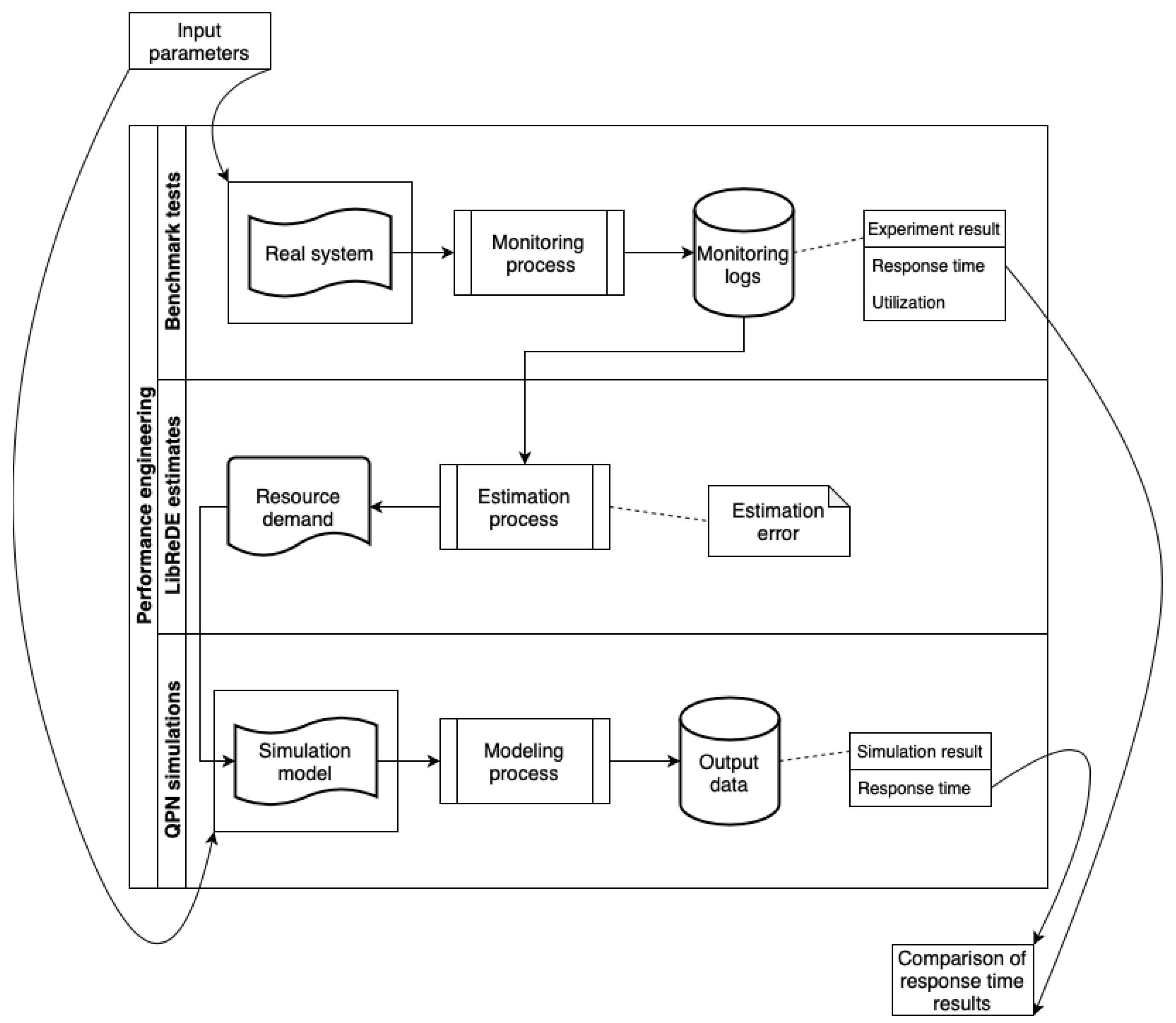
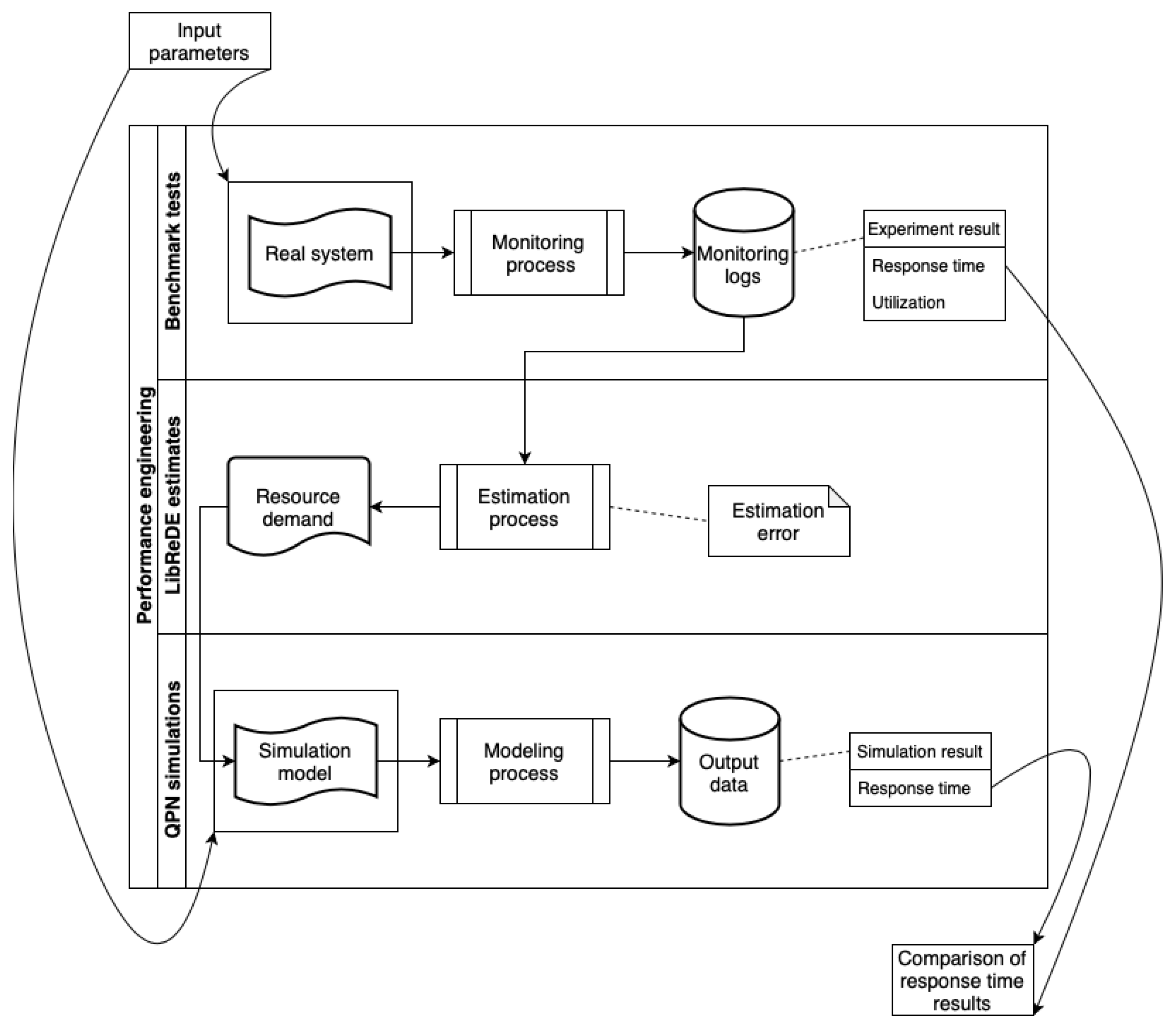
1.2. Performance Evaluation Process
1.3. Organization
2. Related Work
3. Container-Based Web System Architecture and Experiments
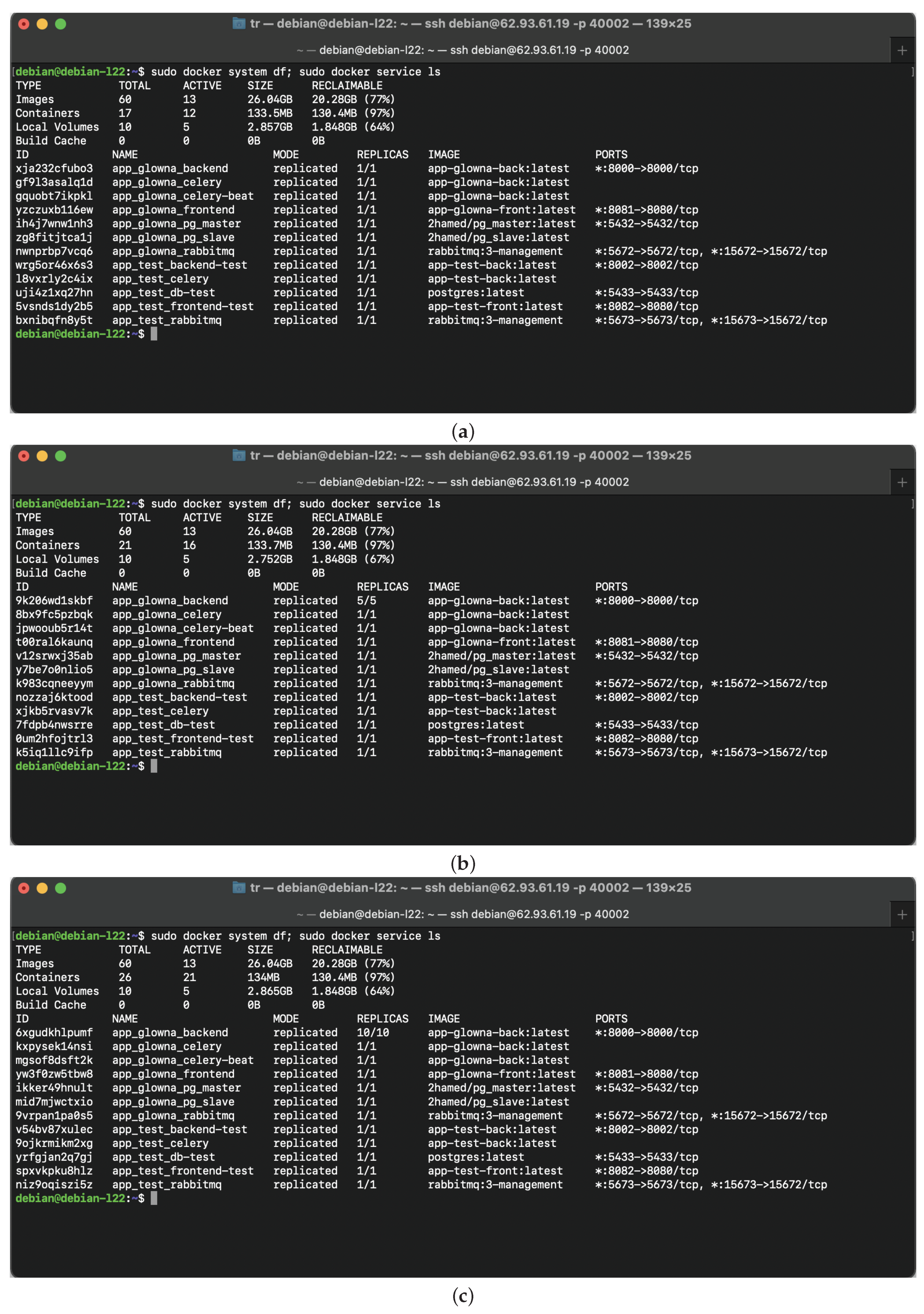
3.1. Container-Based Web System Architecture Approach
3.2. Hardware Elements
3.3. Software Elements
3.3.1. SEWS
- (1) User registration;
- (2) User login and (3) user logout;
- (4) Create a new purchase offer, (5) delete the purchase offer, (6) create a new sale offer, and (7) delete the sale offer;
- (8) Return the list of companies, (9) returns the list of all companies, (10) return details about the company;
- (11) Details of the current user, adding users, and editing the user;
- (12) Returns the current user’s wallet status;
- (13) Returns the list of resources owned by the user, (14) returns the list of active sell/buy offers for a given user, (15) returns the list of completed transactions for a given user, and(16) returns the list of all available actions;
- (17) Allows you to buy stocks at the current price and (18) allows you to sell stocks at the current price;
- (19) Returns the list of all buy and sell orders: active and closed and (20) returns a list of all buy and sell orders for a given action: active and closed.
3.3.2. SELG
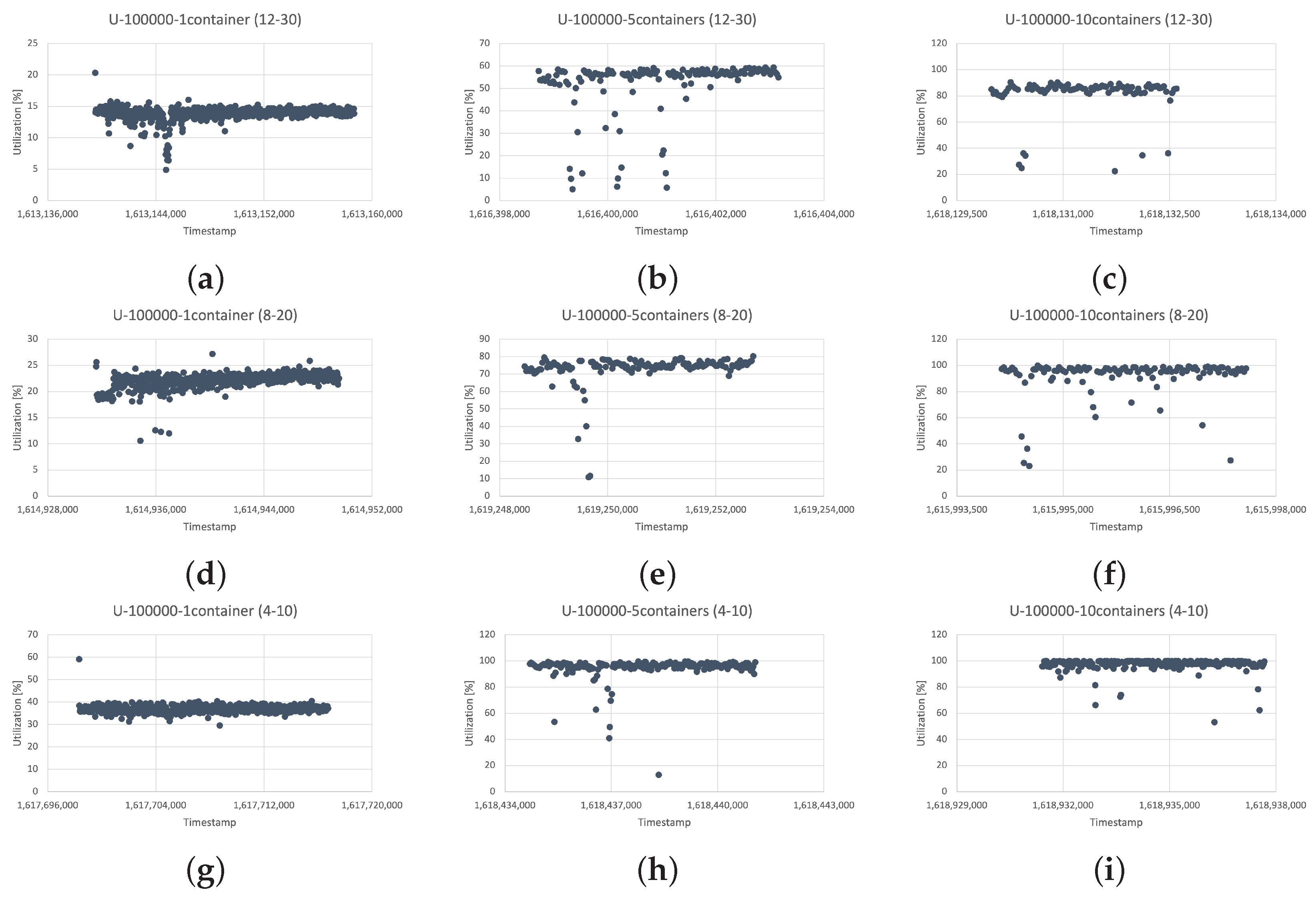
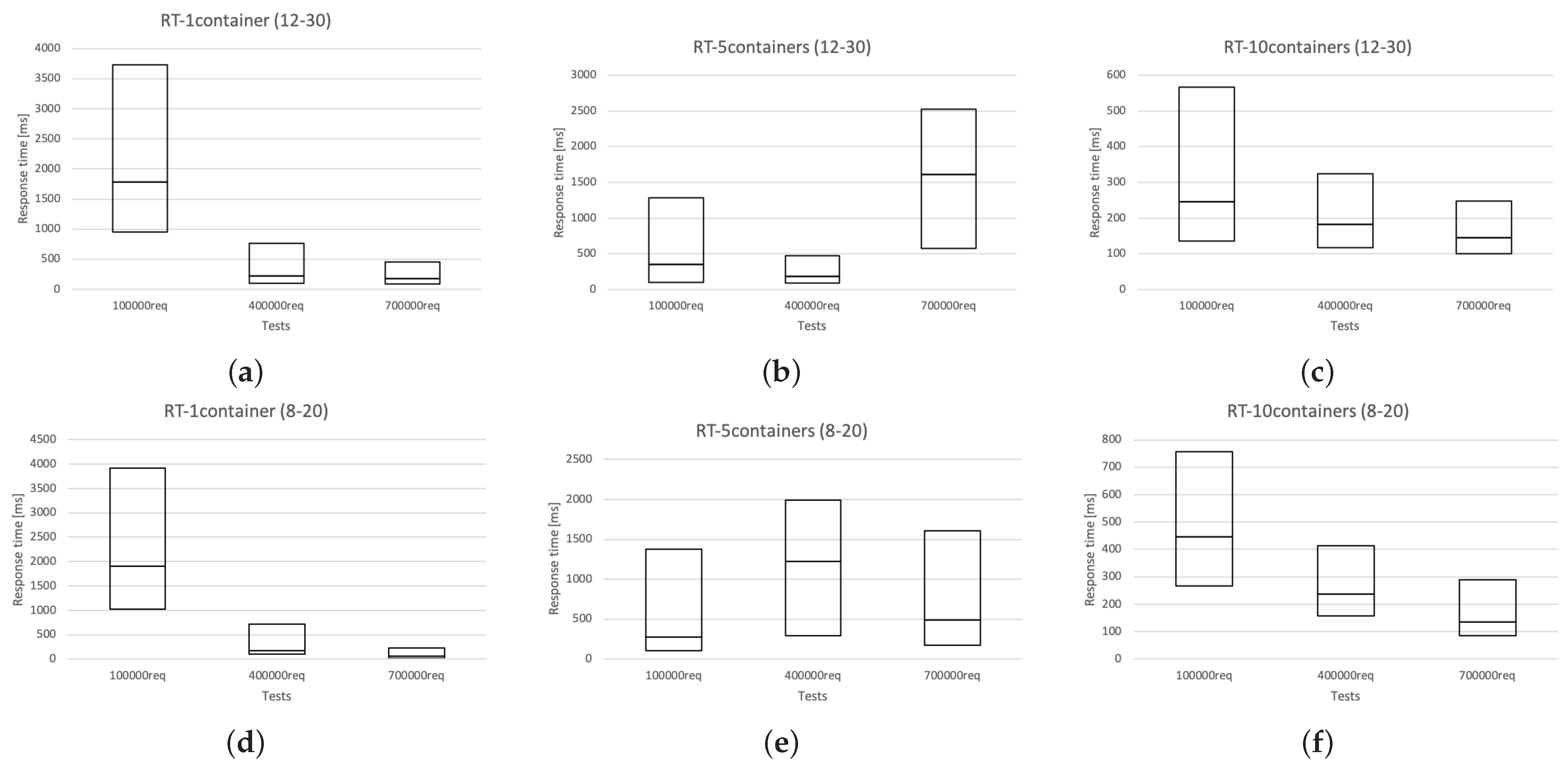
3.4. Benchmark Tests
- Each request is associated with a real client and represents their behaviour in the system.
- User sends the request to a specified endpoint of SEWS.
- User think time (Think time is defined as the time between the completion of one request and the start of the next request.) between two requests is drawn from an exponential distribution. It is possible to scale the workload by changing user think time [37].
- User behaviour is connected to the possible navigation paths within a scenario.
- User registration;
- Login;
- List of all available stock exchange,;
- User wallet status;
- Purchase of a single stock of the SEWS;
- List of resources owned by the user;
- Sale offers;
- List of the user’s current sale/purchase offers;
- List of completed user transactions.
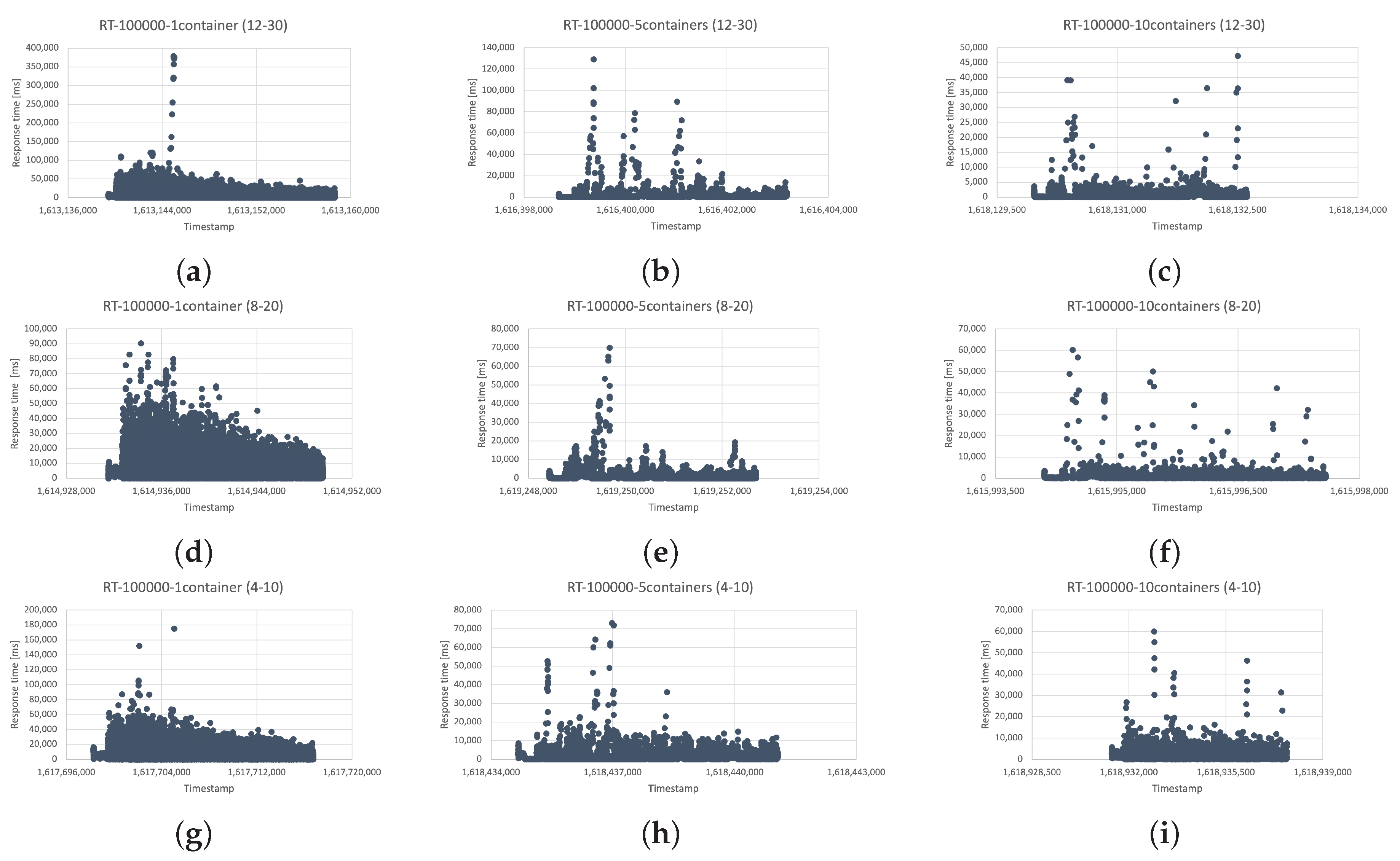
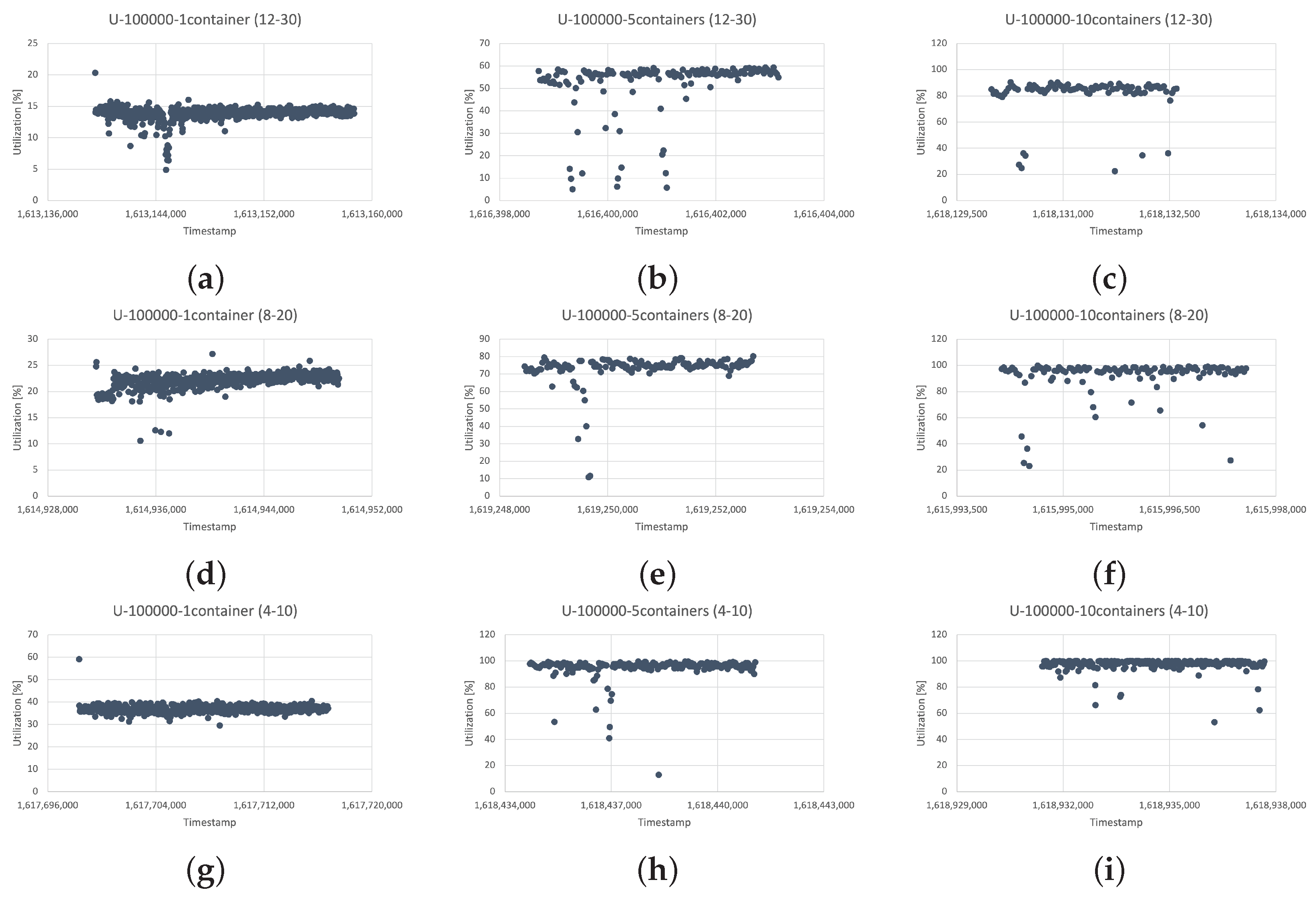
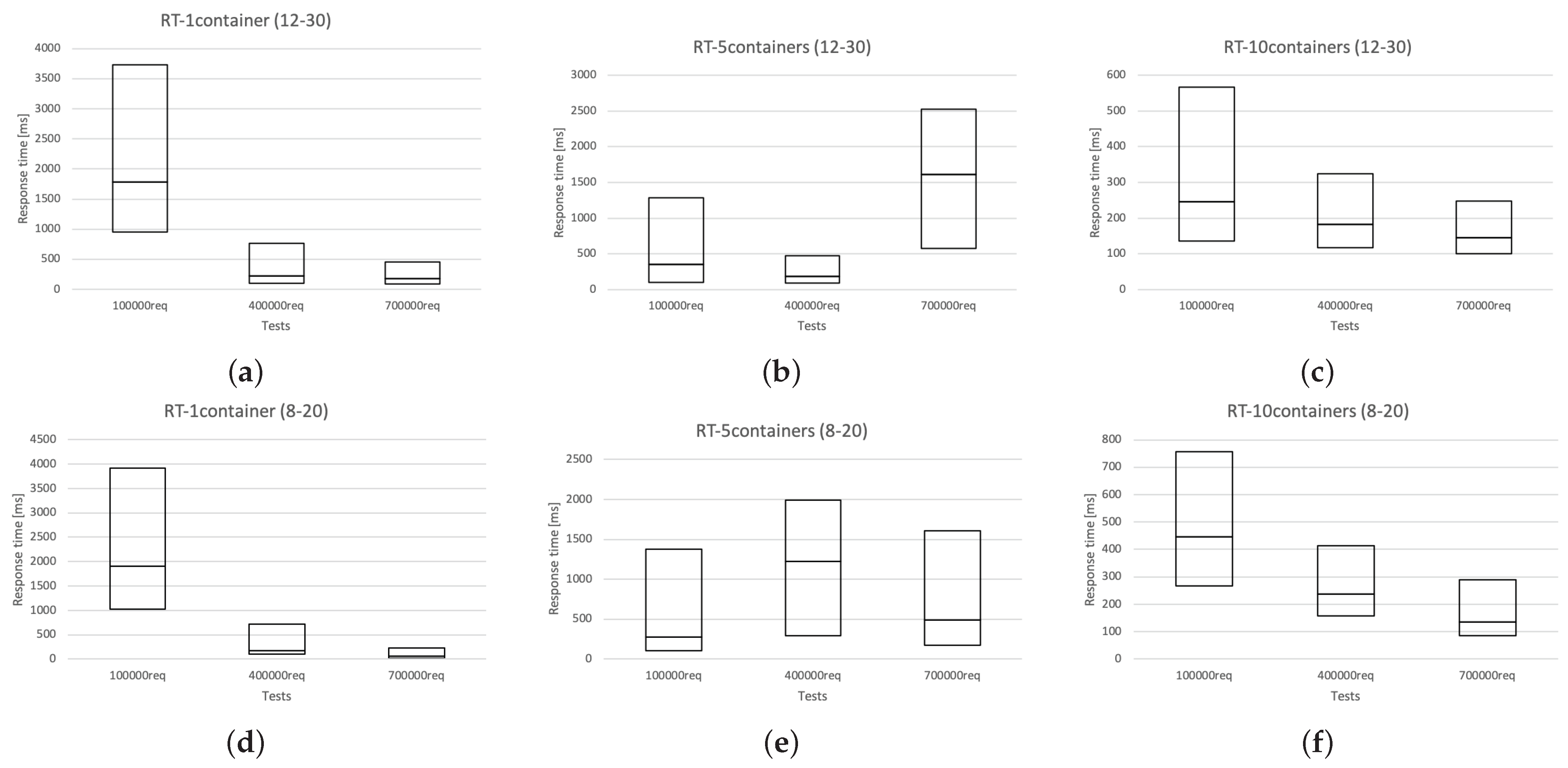
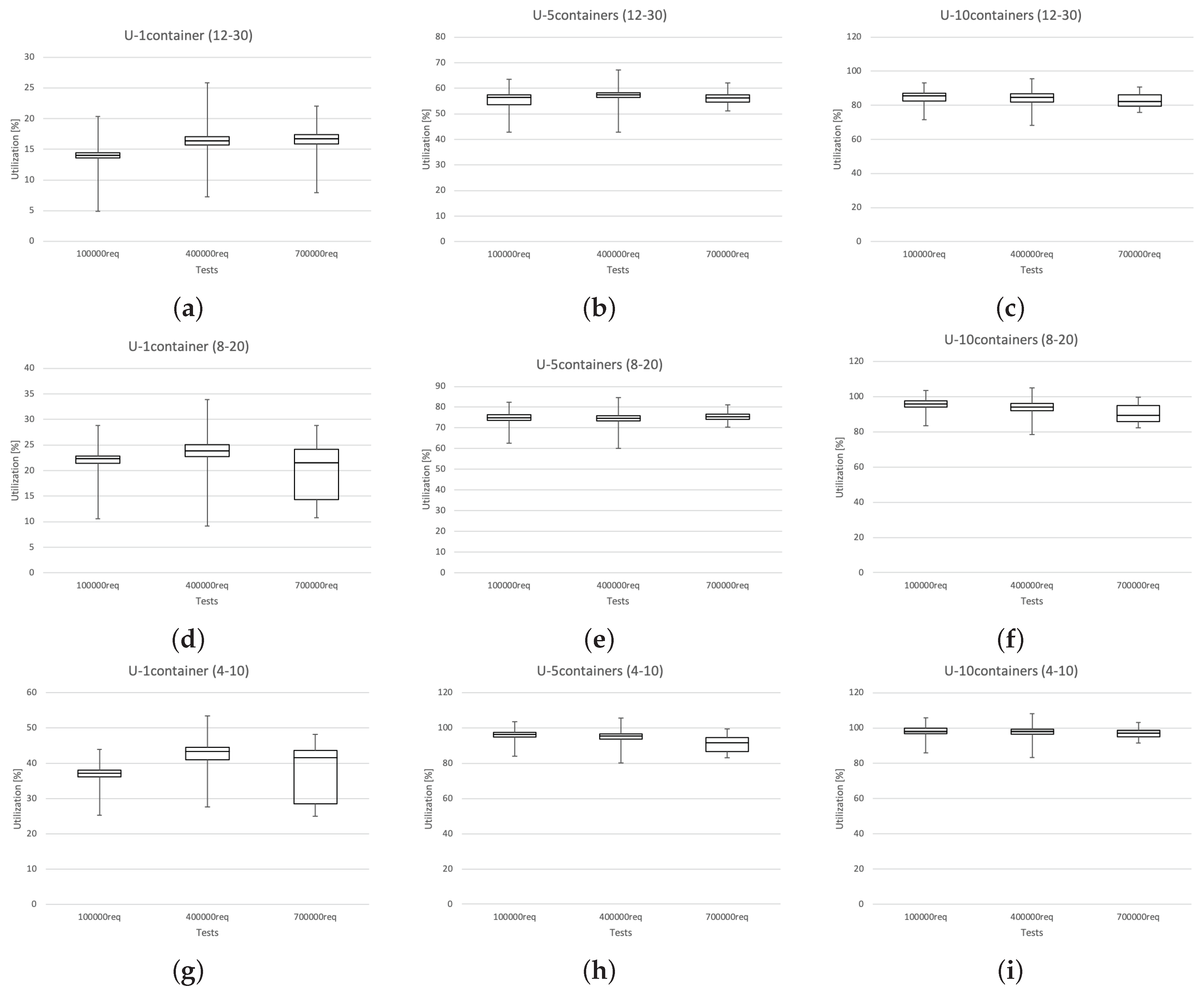
3.5. Experiment Results
4. Resource Demand Prediction
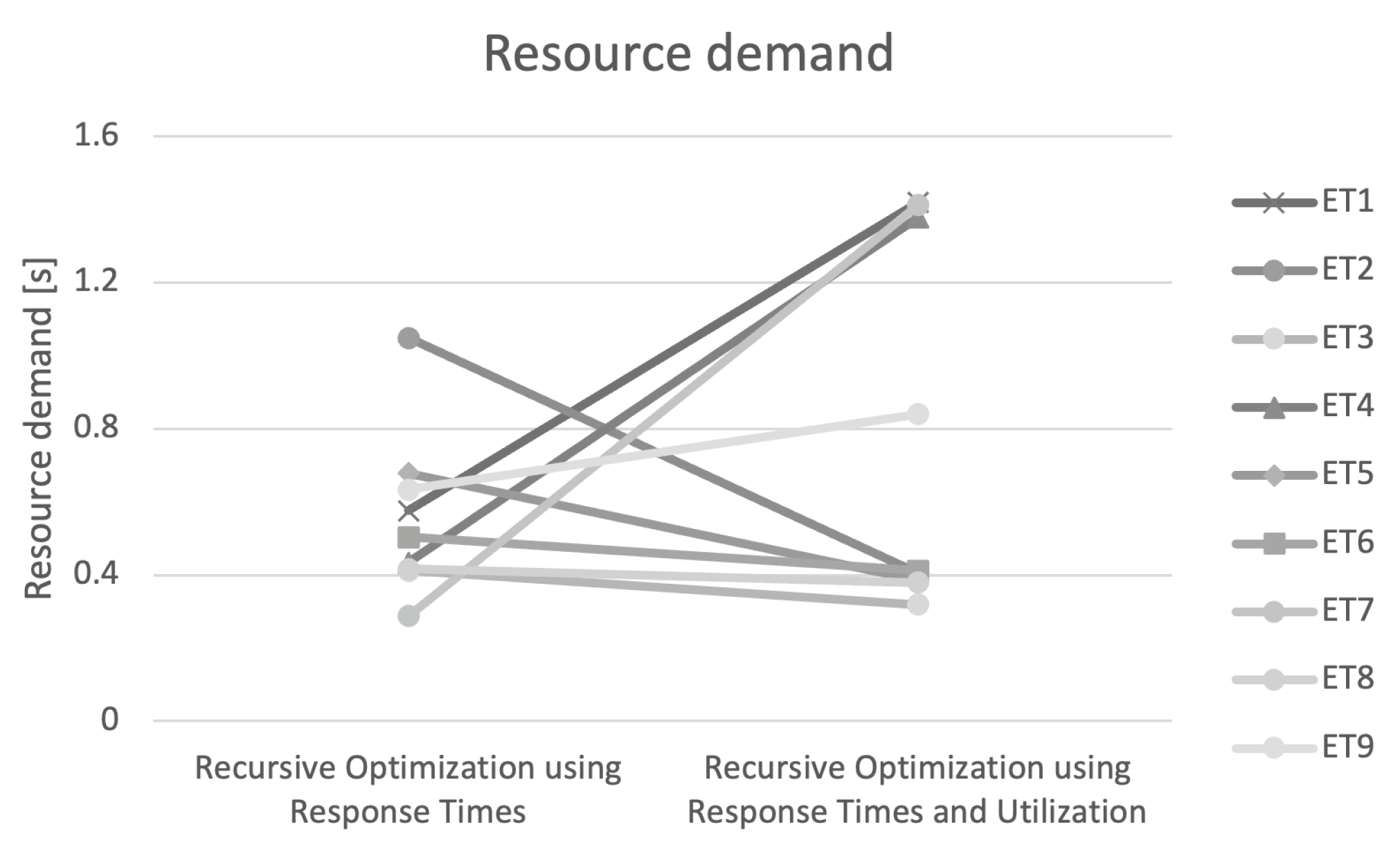
4.1. Estimation Parameters
4.2. Approaches to Resource Demand Prediction
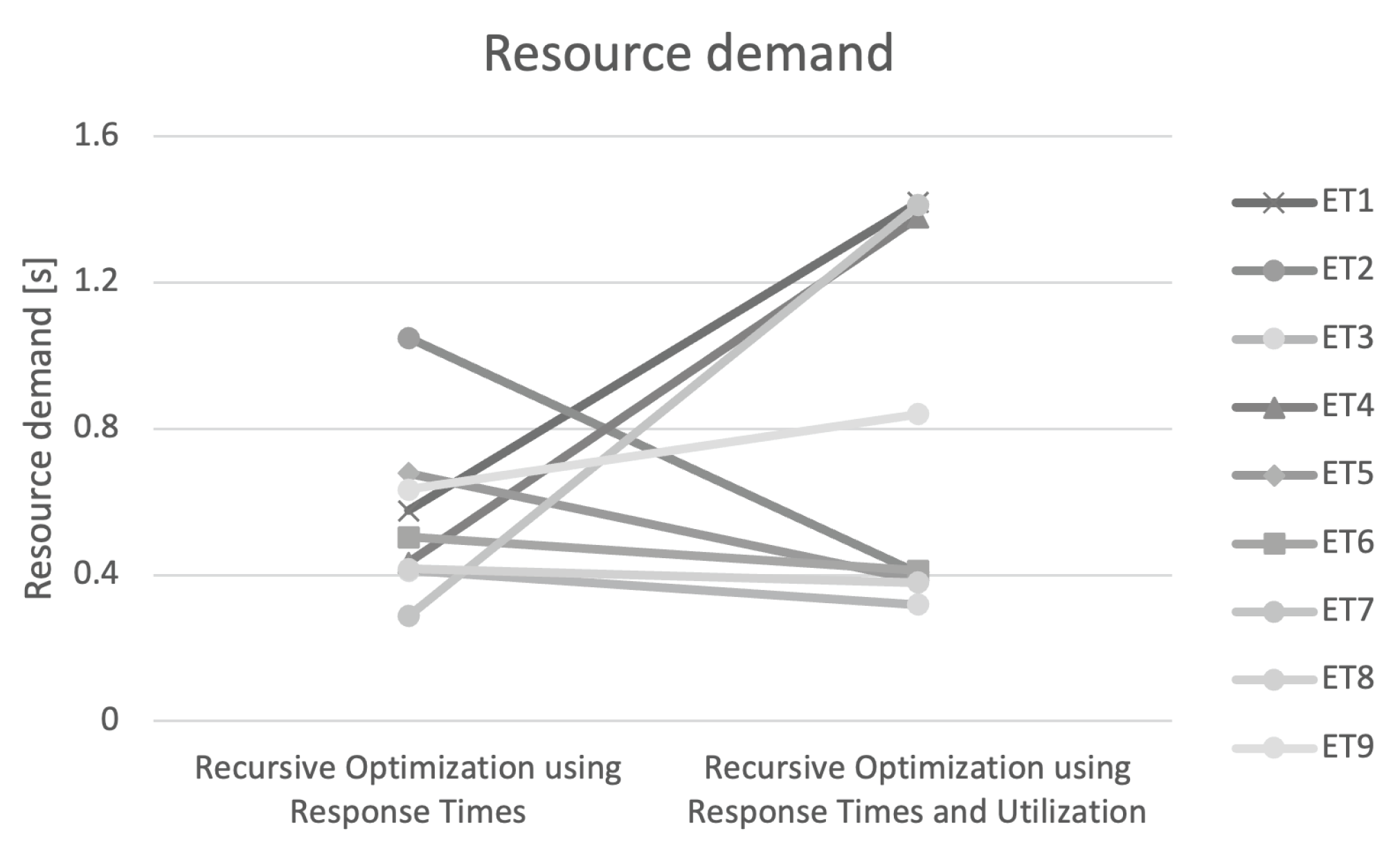
4.3. LibReDE Estimates
4.4. Results
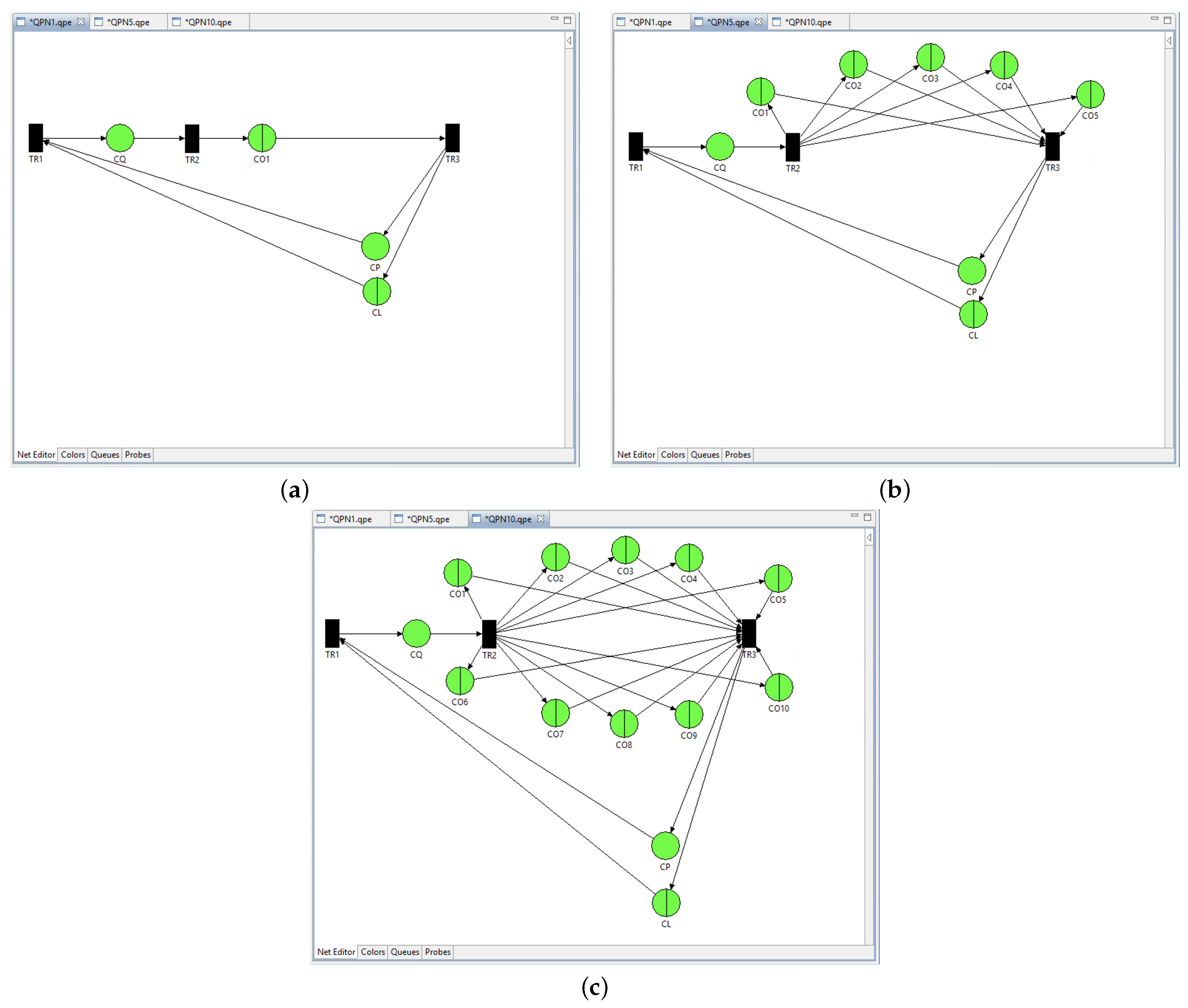
5. QPN Simulations
- Number of requests;
- Number of requests per second;
- Kind of resources;
- Request classes;
- Resource demands;
- Scenarios of requests with route probability.
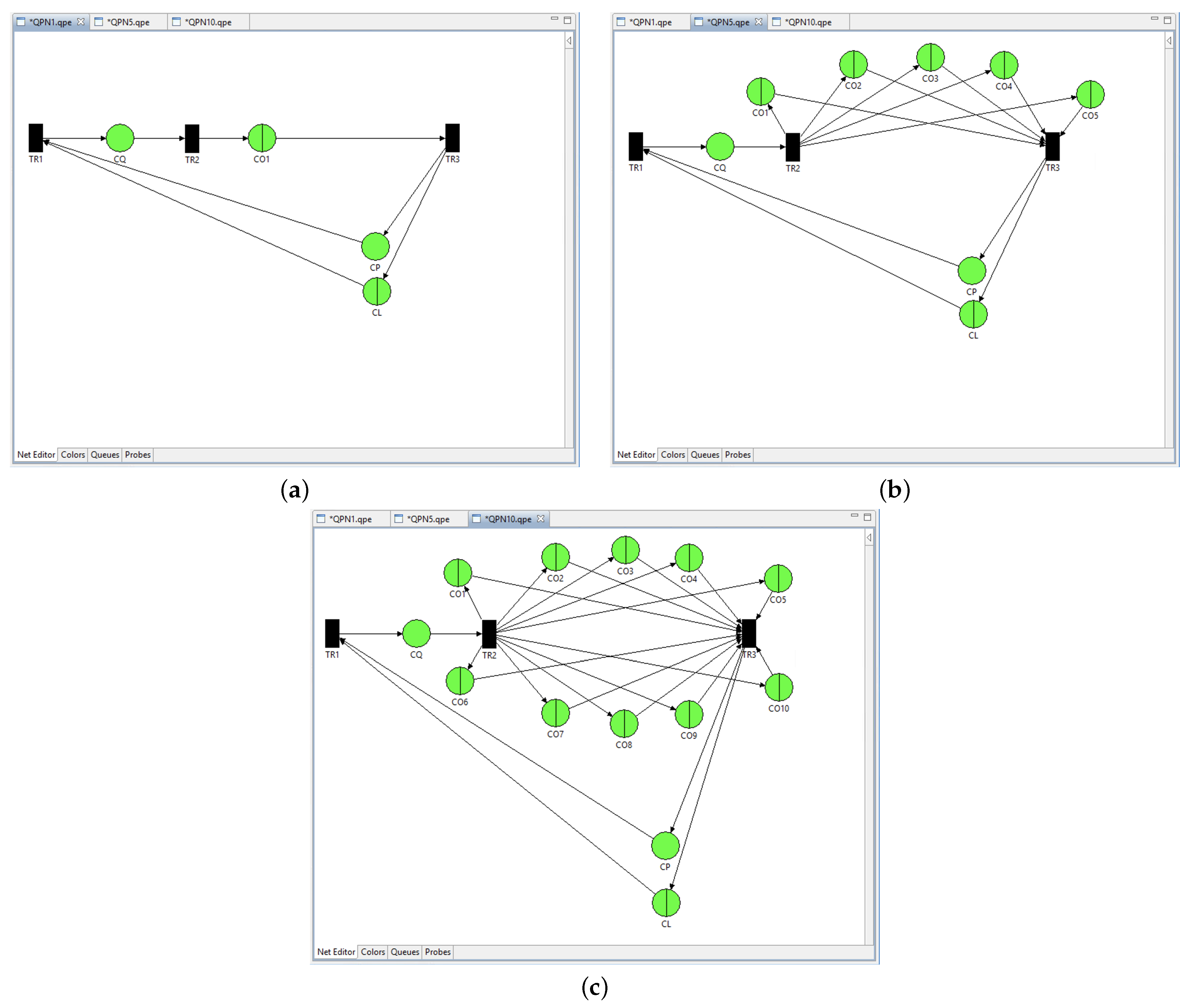
5.1. Queueing Petri Nets
Input Parameters
5.2. Results and Errors of Simulations
6. Conclusions
- Individual simulation approaches for different numbers of containers are required.
- The containerized platform causes additional delays.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rak, T. Formal Techniques for Simulations of Distributed Web System Models. In Cognitive Informatics and Soft Computing; Springer: Singapore, 2021; pp. 365–380. [Google Scholar] [CrossRef]
- Xia, B.; Li, T.; Zhou, Q.; Li, Q.; Zhang, H. An Effective Classification-Based Framework for Predicting Cloud Capacity Demand in Cloud Services. IEEE Trans. Serv. Comput. 2021, 14, 944–956. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, X.; Wang, L.; Han, Z. Prediction of Cloud Resources Demand Based on Hierarchical Pythagorean Fuzzy Deep Neural Network. IEEE Trans. Serv. Comput. 2021, 14, 1890–1901. [Google Scholar] [CrossRef]
- Rak, T.; Żyła, R. Using Data Mining Techniques for Detecting Dependencies in the Outcoming Data of a Web-Based System. Appl. Sci. 2022, 12, 6115. [Google Scholar] [CrossRef]
- Rak, T. Performance Modeling Using Queueing Petri Nets. In Computer Networks, Proceedings of the 24th International Conference on Computer Networks, Ladek Zdroj, Poland, 20–23 June 2017; Communications in Computer and Information Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Volume 718, pp. 321–335. [Google Scholar] [CrossRef]
- Cherbal, S. Load balancing mechanism using mobile agents. Informatica 2021, 45, 257–266. [Google Scholar] [CrossRef]
- Nguyen, V.Q.; Nguyen, V.H.; Nguyen, M.Q.; Huynh, Q.T.; Kim, K. Efficiently Estimating Joining Cost of Subqueries in Regular Path Queries. Electronics 2021, 10, 990. [Google Scholar] [CrossRef]
- Zatwarnicki, K.; Zatwarnicka, A. Two-Layer Cloud-Based Web System. In Information Systems Architecture and Technology: Proceedings of 39th International Conference on Information Systems Architecture and Technology, San Francisco, CA, USA, 13–16 December 2018; Borzemski, L., Światek, J., Wilimowska, Z., Eds.; Springer: Cham, Switzerland, 2019; pp. 125–134. [Google Scholar] [CrossRef]
- Pant, A. Design and Investigation of a Web Application Environment With Bounded Response Time. Int. J. Latest Trends Eng. Technol. 2019, 14, 31–33. [Google Scholar] [CrossRef]
- Eismann, S.; Grohmann, J.; Walter, J.; von Kistowski, J.; Kounev, S. Integrating Statistical Response Time Models in Architectural Performance Models. In Proceedings of the 2019 IEEE International Conference on Software Architecture, Hamburg, Germany, 25–26 March 2019; pp. 71–80. [Google Scholar] [CrossRef]
- Zhou, J.; Reniers, G. Modeling and analysis of vapour cloud explosions knock-on events by using a Petri-net approach. Saf. Sci. 2018, 108, 188–195. [Google Scholar] [CrossRef]
- Giebas, D.; Wojszczyk, R. Atomicity Violation in Multithreaded Applications and Its Detection in Static Code Analysis Process. Appl. Sci. 2020, 10, 8005. [Google Scholar] [CrossRef]
- Kounev, S.; Lange, K.D.; von Kistowski, J. Systems Benchmarking: For Scientists and Engineers; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Walid, B.; Kloul, L. Formal Models for Safety and Performance Analysis of a Data Center System. Reliab. Eng. Syst. Saf. 2019, 193, 106643. [Google Scholar] [CrossRef]
- Krajewska, A. Performance Modeling of Database Systems: A Survey. J. Telecommun. Inf. Technol. 2019, 8, 37–45. [Google Scholar] [CrossRef]
- Spinner, S.; Walter, J.; Kounev, S. A Reference Architecture for Online Performance Model Extraction in Virtualized Environments. In Proceedings of the Companion Publication for ACM/SPEC on International Conference on Performance Engineering, New York, NY, USA, 22–26 April 2016; pp. 57–62. [Google Scholar] [CrossRef]
- Doc, V.; Nguyen, T.B.; Huynh Quyet, T. Formal Transformation from UML Sequence Diagrams to Queueing Petri Nets. In Advancing Technology Industrialization Through Intelligent Software Methodologies, Tools and Techniques; IOS Press: Clifton, VA, USA, 2019; pp. 588–601. [Google Scholar] [CrossRef]
- Fiuk, M.; Czachórski, T. A Queueing Model and Performance Analysis of UPnP/HTTP Client Server Interactions in Networked Control Systems. In Computer Networks; Communications in Computer and Information Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 366–386. [Google Scholar] [CrossRef]
- Rzońca, D.; Rzasa, W.; Samolej, S. Consequences of the Form of Restrictions in Coloured Petri Net Models for Behaviour of Arrival Stream Generator Used in Performance Evaluation. In Computer Networks; Gaj, P., Sawicki, M., Suchacka, G., Kwiecień, A., Eds.; Springer: Cham, Switzerland, 2018; pp. 300–310. [Google Scholar] [CrossRef]
- Rak, T. Cluster-Based Web System Models for Different Classes of Clients in QPN. In Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 1039, pp. 347–365. [Google Scholar] [CrossRef]
- Szpyrka, M.; Brzychczy, E.; Napieraj, A.; Korski, J.; Nalepa, G.J. Conformance Checking of a Longwall Shearer Operation Based on Low-Level Events. Energies 2020, 13, 6630. [Google Scholar] [CrossRef]
- Requeno, J.; Merseguer, J.; Bernardi, S.; Perez-Palacin, D.; Giotis, G.; Papanikolaou, V. Quantitative Analysis of Apache Storm Applications: The NewsAsset Case Study. Inf. Syst. Front. 2019, 21, 67–85. [Google Scholar] [CrossRef]
- Borzemski, L.; Kedras, M. Measured vs Perceived Web Performance. Adv. Intell. Syst. Comput. 2020, 1050, 285–301. [Google Scholar] [CrossRef]
- Zatwarnicki, K. Providing Predictable Quality of Service in a Cloud-Based Web System. Appl. Sci. 2021, 11, 2896. [Google Scholar] [CrossRef]
- Kosińska, J.; Zieliński, K. Autonomic Management Framework for Cloud-Native Applications. J. Grid Comput. 2020, 18, 779–796. [Google Scholar] [CrossRef]
- Zatwarnicki, K.; Zatwarnicka, A. A Comparison of Request Distribution Strategies Used in One and Two Layer Architectures of Web Cloud Systems. In Computer Networs; Communications in Computer and Information Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 178–190. [Google Scholar] [CrossRef]
- Zatwarnicki, K.; Barton, S.; Mainka, D. Acquisition and Modeling of Website Parameters. In Advanced Information Networking and Applications, Proceedings of the 35th International Conference on Advanced Information Networking and Applications, Toronto, Canada, 12–15 May 2021; Lecture Notes in Networks and Systems; Barolli, L., Woungang, I., Enokido, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 227, pp. 594–605. [Google Scholar] [CrossRef]
- Herrnleben, S.; Grohmann, J.; Rygielski, P.; Lesch, V.; Krupitzer, C.; Kounev, S. A Simulation-Based Optimization Framework for Online Adaptation of Networks. In Simulation Tools and Techniques; Song, H., Jiang, D., Eds.; Springer: Cham, Switzerland, 2021; pp. 513–532. [Google Scholar] [CrossRef]
- Rak, T. Modeling Web Client and System Behavior. Information 2020, 11, 337. [Google Scholar] [CrossRef]
- Pawlik, R.; Werewka, J. Recreation of Containers for High Availability Architecture and Container-Based Applications. In Computer Networks, Proceedings of the 26th International Conference, CN 2019, Kamien Slaski, Poland, 25–27 June 2019; Volume 1039, pp. 287–298. [Google Scholar] [CrossRef]
- Urbańczyk, W.; Werewka, J. Contribution Title Enterprise Architecture Approach to Resilience of Government Data Centre Infrastructure. In Information Systems Architecture and Technology, Proceedings of the 39th International Conference on Information Systems Architecture and Technology, San Francisco, CA, USA, 13–16 December 2018; Borzemski, L., Światek, J., Wilimowska, Z., Eds.; Springer: Cham, Switzerland, 2019; pp. 135–145. [Google Scholar] [CrossRef]
- Suoniemi, S.; Meyer-Waarden, L.; Munzel, A.; Zablah, A.R.; Straub, D. Big data and firm performance: The roles of market-directed capabilities and business strategy. Inf. Manag. 2020, 57, 103365. [Google Scholar] [CrossRef]
- Burgin, M.; Eberbach, E.; Mikkilineni, R. Processing Information in the Clouds. Proceedings 2020, 47, 25. [Google Scholar] [CrossRef]
- Chen, X.; Guo, M.; Shangguan, W. Estimating the impact of cloud computing on firm performance: An empirical investigation of listed firms. Inf. Manag. 2022, 59, 103603. [Google Scholar] [CrossRef]
- Zhu, B.; Guo, D.; Ren, L. Consumer preference analysis based on text comments and ratings: A multi-attribute decision-making perspective. Inf. Manag. 2022, 59, 103626. [Google Scholar] [CrossRef]
- Neumann, A.; Laranjeiro, N.; Bernardino, J. An Analysis of Public REST Web Service APIs. IEEE Trans. Serv. Comput. 2021, 14, 957–970. [Google Scholar] [CrossRef]
- Zhang, X.L.; Demirkan, H. Between online and offline markets: A structural estimation of consumer demand. Inf. Manag. 2021, 58, 103467. [Google Scholar] [CrossRef]
- Suchacka, G.; Borzemski, L. Simulation-based performance study of e-commerce web server system-results for FIFO scheduling. Adv. Intell. Syst. Comput. 2013, 183, 249–259. [Google Scholar] [CrossRef]
- Menascé, D.; Dowdy, L.; Almeida, V.A.F. Performance by Design—Computer Capacity Planning by Example; Prentice Hall Professional: Old Bridge, NJ, USA, 2004. [Google Scholar]
- Menascé, D. Computing Missing Service Demand Parameters for Performance Models. In Proceedings of the International CMG Conference, Las Vegas, NV, USA, 7–12 December 2008; pp. 241–248. [Google Scholar]
- Liu, Z.; Wynter, L.; Xia, C.; Zhang, F. Parameter inference of queueing models for IT systems using end-to-end measurements. Perform. Eval. 2004, 63, 36–60. [Google Scholar] [CrossRef]
- Bause, F.; Buchholz, P.; Kemper, P. Hierarchically combined queueing Petri nets. In Proceedings of the International Conference on Analysis and Optimization of Systems Discrete Event Systems, Sophia-Antipolis, France, 15–17 June 1994; pp. 176–182. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Advantages | Disadvantages |
|---|---|---|
| [2] | Cloud infrastructure; online analysis | The time series segmentation strategy has limitations, especially concerning the selection of thresholds; One-class client |
| [3] | Cloud infrastructure; The proposed training method incorporates back propagation | Lack of performance analysis |
| [1] | Container-based infrastructure | Measured model parameters; one-class client |
| [10] | Cloud infrastructure | Measured model parameters; offline analysis |
| [28] | Parameter prediction; online analysis; | Native systems |
| [29] | Multi-class client | Native systems; measured model parameters |
| This approach | Container-based infrastructure; parameter prediction | One-class client; offline analysis |
| Parameter | |||
|---|---|---|---|
| Processors | 12 | ||
| RAM [GB] | 30 | ||
| Container structure | |||
| Test | |||
| 6.242 | 4.849 | 3.826 | |
| – [req/s] | |||
| 0.166 | 0.207 | 0.261 | |
| – [s] | |||
| Parameter | |||
|---|---|---|---|
| Processors | 8 | ||
| RAM [GB] | 20 | ||
| Container structure | |||
| Test | |||
| 66.732 | 5.009 | 2.975 | |
| – [req/s] | |||
| 0.55 | 0.200 | 0.337 | |
| – [s] | |||
| Parameter | |||
|---|---|---|---|
| Processors | 4 | ||
| RAM [GB] | 10 | ||
| Container structure | |||
| Test | |||
| 6.366 | 3.152 | 1.644 | |
| – [req/s] | |||
| 0.164 | 0.317 | 0.610 | |
| – [s] | |||
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
| −33.73121568 | 19.84842247 | 845.240542 | −95.91645773 | |
| −6487.021564 | 946.457702 | 42,268.09643 | 38.10226782 | |
| 0.379664096 | 0.370576906 | 357,284 224.4 | 0.388762798 | |
| −0.070396545 | −1.235334562 | 1 130.442687 | 0.113804428 | |
| 37 399.04116 | 120.538286 | 27 120.31354 | −459.1572704 | |
| 0.400369085 | 0.383722564 | 167 698.4815 | 0.409635151 | |
| 1.450755404 | 1.363932945 | 831.2420911 | 1.486306432 | |
| −3.776294824 | 98.19939577 | 42 774.64724 | −2.776643656 | |
| 30.65167827 | 4.205167963 | 99 186.91791 | 16.31688764 | |
| 5 | 6 | 7 | 8 | |
| 729.2034814 | 0.646818098 | −0.897905511 | 845.2399791 | |
| 33 164.44074 | 79.38060097 | 0.430180122 | 44 323.6072 | |
| 356 184 355.5 | 0.351120179 | 0.230979692 | 356 208 326.1 | |
| 1 124.470638 | 0.771952155 | 1.04651969 | 1,130.443295 | |
| 23 732.13498 | 3.154876279 | −322.1905826 | 27,191.73684 | |
| 143,759.0219 | 0.394169807 | 0.355737927 | 170 410.6652 | |
| 826.9900691 | 1.899608047 | 1.891813012 | 831.2422076 | |
| 35,480.82464 | 7.169014737 | 0.323881793 | 42 784.55392 | |
| 96,552.10109 | 0.669395411 | 1.977049405 | 99,190.83672 |
| [s] | [req/s] | |
|---|---|---|
| 0.997588333 | 1.002417497 | |
| 0.727264667 | 1.37501524 | |
| 0.3652765 | 2.737652162 | |
| 0.905941667 | 1.10382383 | |
| 0.532029333 | 1.879595611 | |
| 0.457546 | 2.185572598 | |
| 0.849838333 | 1.176694391 | |
| Parameter | |||
|---|---|---|---|
| Number of servers | 12 | ||
| QPNi model | 1 | 5 | 10 |
| SimulationTest | |||
| queueing place | 90 | ||
| – [req/s] | 6.242 | 4.849 | 3.826 |
| place | 90 | ||
| – [req/s] | 1.002 | 1.375 | 2.737 |
| Parameter | |||
|---|---|---|---|
| Number of servers | 12 | ||
| QPNi model | 1 | 5 | 10 |
| SimulationTest | |||
| queueing place | 90 | ||
| – [req/s] | 6.732 | 5.064 | 2.975 |
| place | 90 | ||
| – [req/s] | 1.103 | 1.879 | 2.185 |
| Parameter | |||
|---|---|---|---|
| Number of servers | 12 | ||
| QPNi model | 1 | 5 | 10 |
| SimulationTest | |||
| queueing place | 90 | ||
| – [req/s] | 6.366 | 3.152 | 1.644 |
| place | 90 | ||
| – [req/s] | 0.164 | 0.317 | 0.610 |
| Simulation [s] | 1.003483 | 1.222707 | 0.528284 |
| Measured [s] | 0.904 | 1.014 | 0.599 |
| Error [%] | −11.00475664 | −20.58254438 | 11.80567613 |
| Simulation [s] | 1.075831 | 0.832224 | 0.711255 |
| Measured [s] | 1.128 | 0.928 | 0.871 |
| Error [%] | 4.624911348 | 10.32068966 | 18.34041332 |
| Simulation [s] | 0.851 | 1.914936 | 2.031159 |
| Measured [s] | 0.804 | 1.455 | 0.846 |
| Error [%] | −5.845771144 | −31.61072165 | −140.0897163 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rak, T. Performance Evaluation of an API Stock Exchange Web System on Cloud Docker Containers. Appl. Sci. 2023, 13, 9896. https://doi.org/10.3390/app13179896
Rak T. Performance Evaluation of an API Stock Exchange Web System on Cloud Docker Containers. Applied Sciences. 2023; 13(17):9896. https://doi.org/10.3390/app13179896
Chicago/Turabian StyleRak, Tomasz. 2023. "Performance Evaluation of an API Stock Exchange Web System on Cloud Docker Containers" Applied Sciences 13, no. 17: 9896. https://doi.org/10.3390/app13179896
APA StyleRak, T. (2023). Performance Evaluation of an API Stock Exchange Web System on Cloud Docker Containers. Applied Sciences, 13(17), 9896. https://doi.org/10.3390/app13179896