
Deep-Learning Multiscale Digital Holographic Intensity and Phase Reconstruction

Abstract
:1. Introduction
2. Principles and Methods
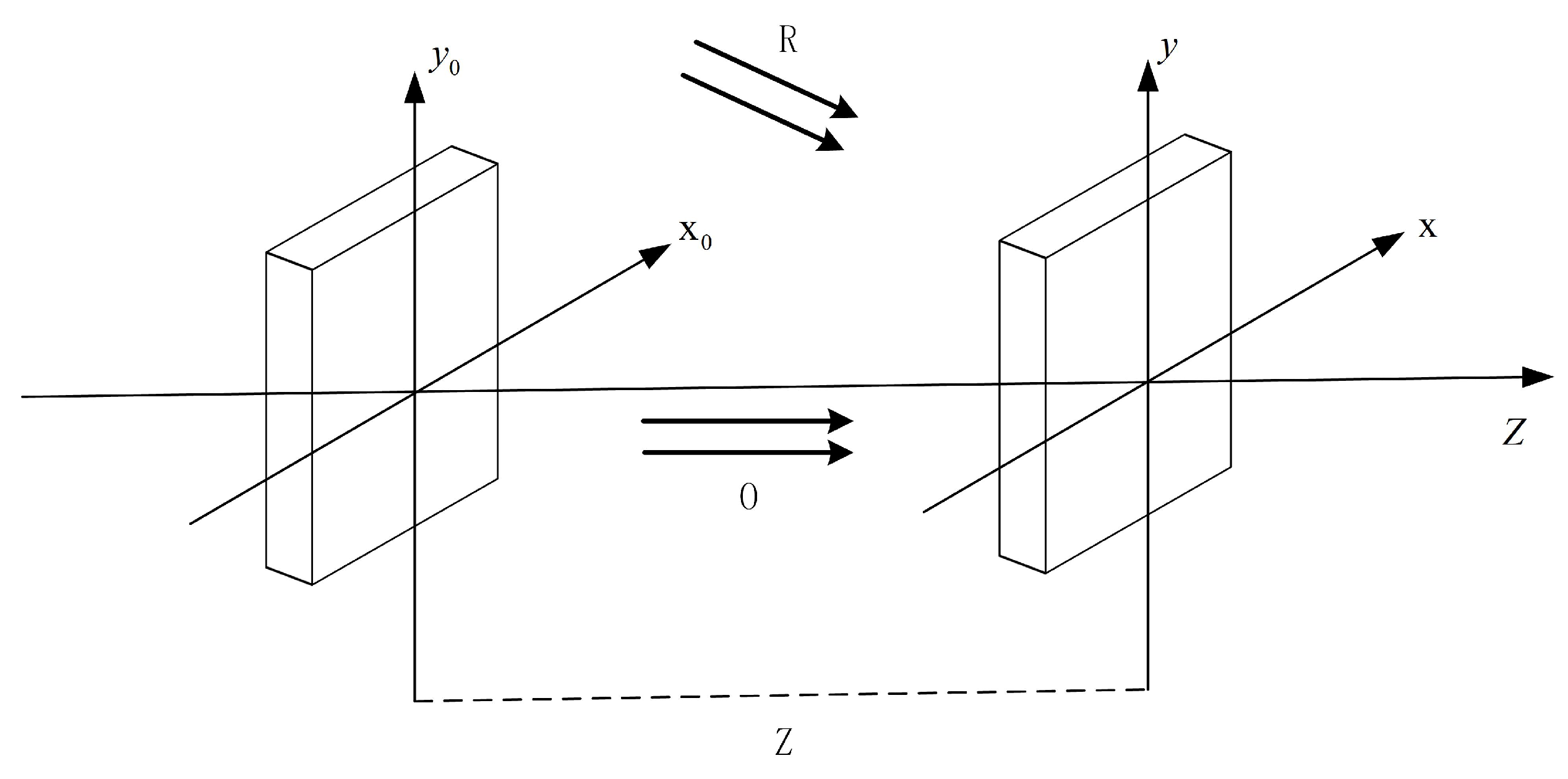
2.1. Principles of Digital Holography
2.2. Principles of Deep-Learning Reconstruction
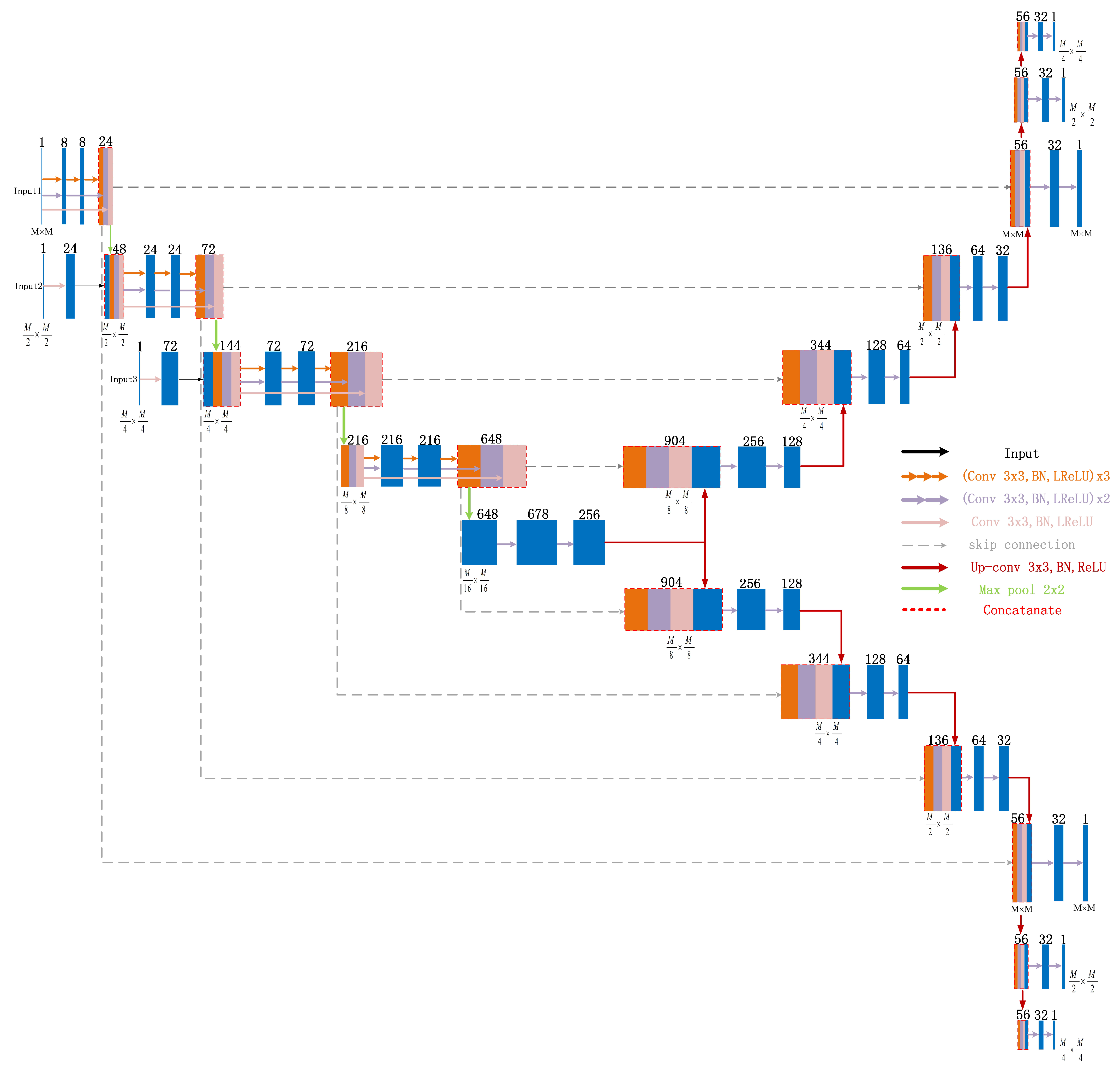
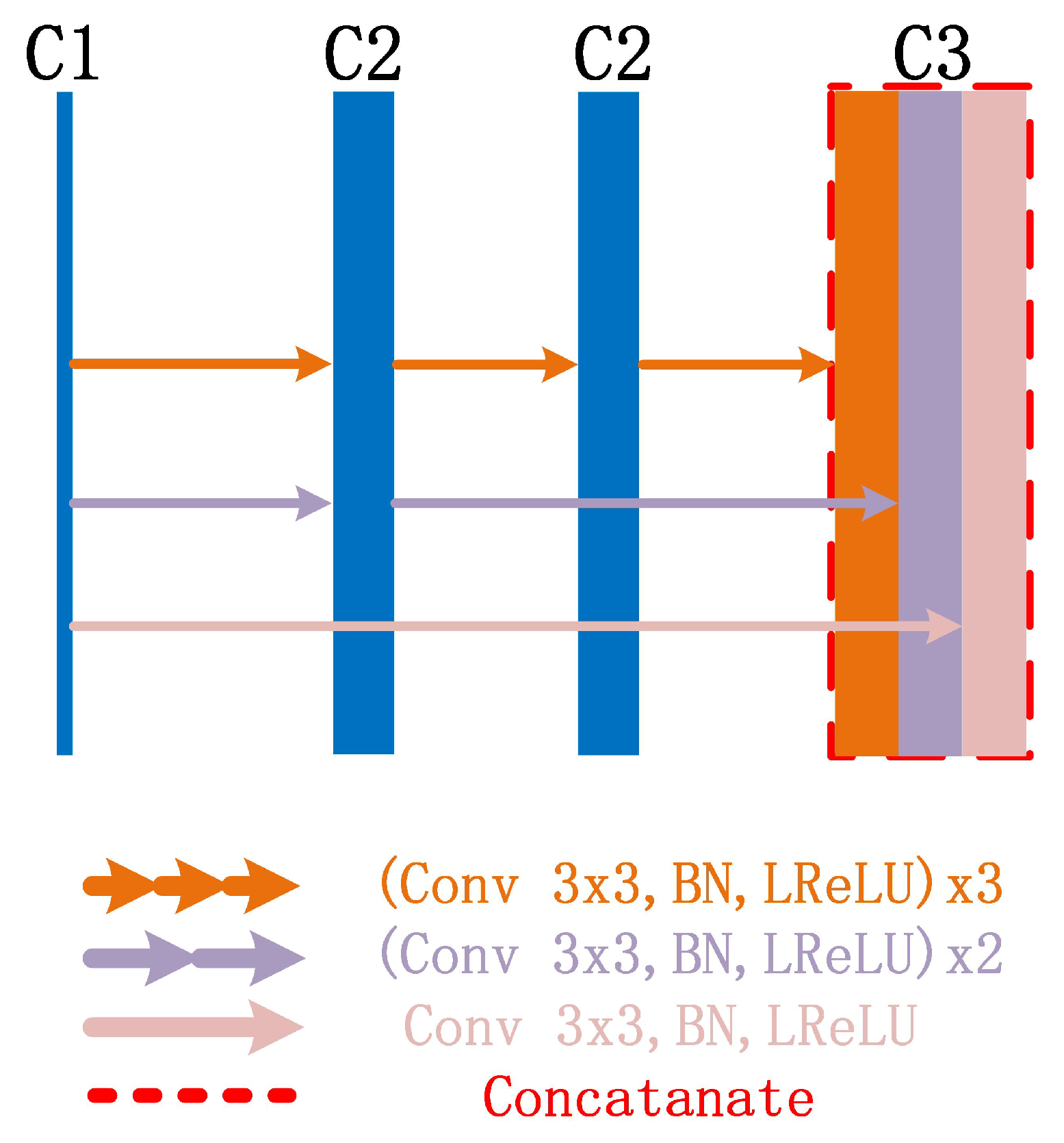
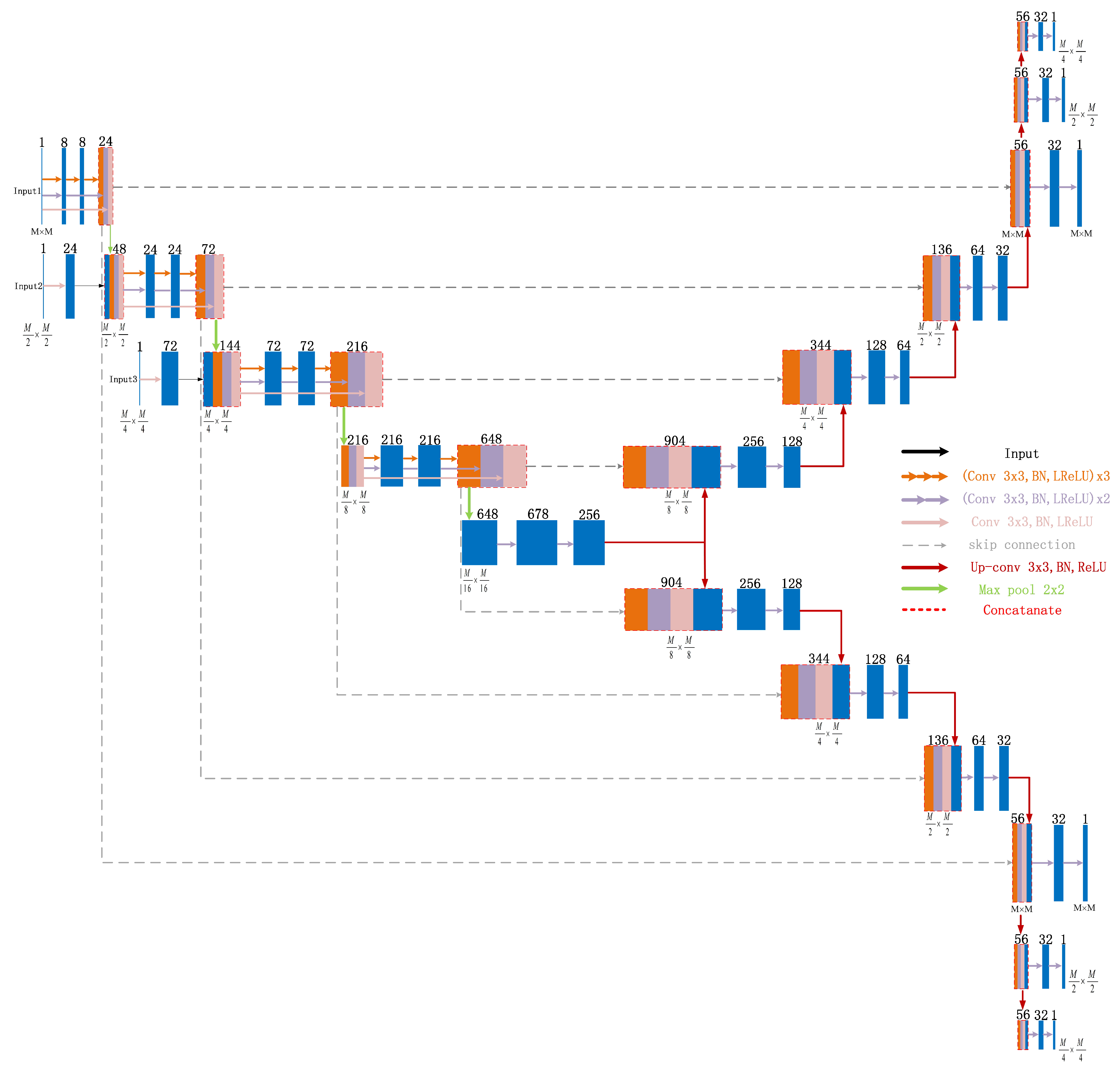
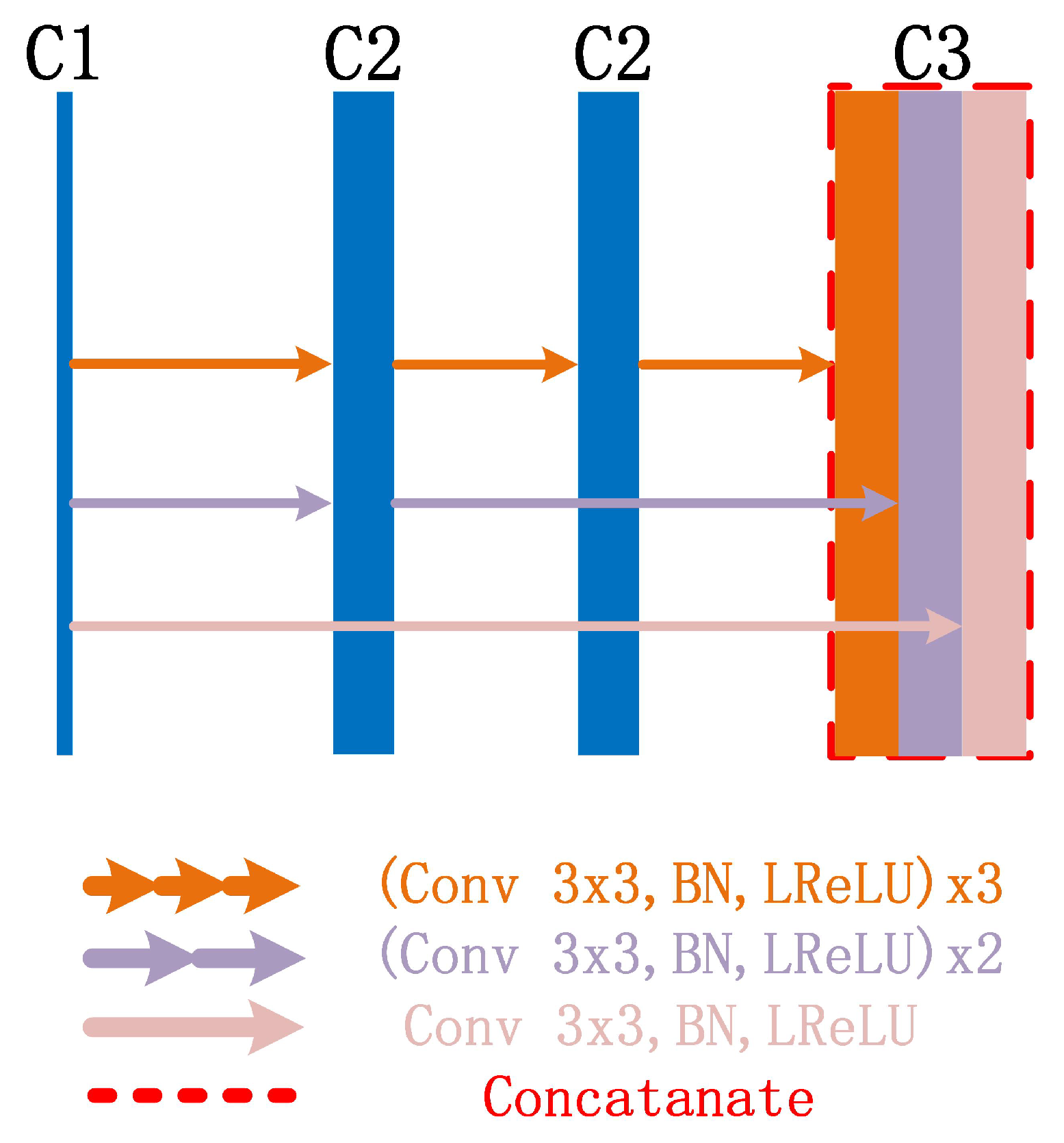
2.3. Mimo-Net Network Structure
3. Experiment and Result Analysis
3.1. Experiment Setup and Dataset Generation
3.2. Evaluation Index
3.3. Experimental Results and Analysis
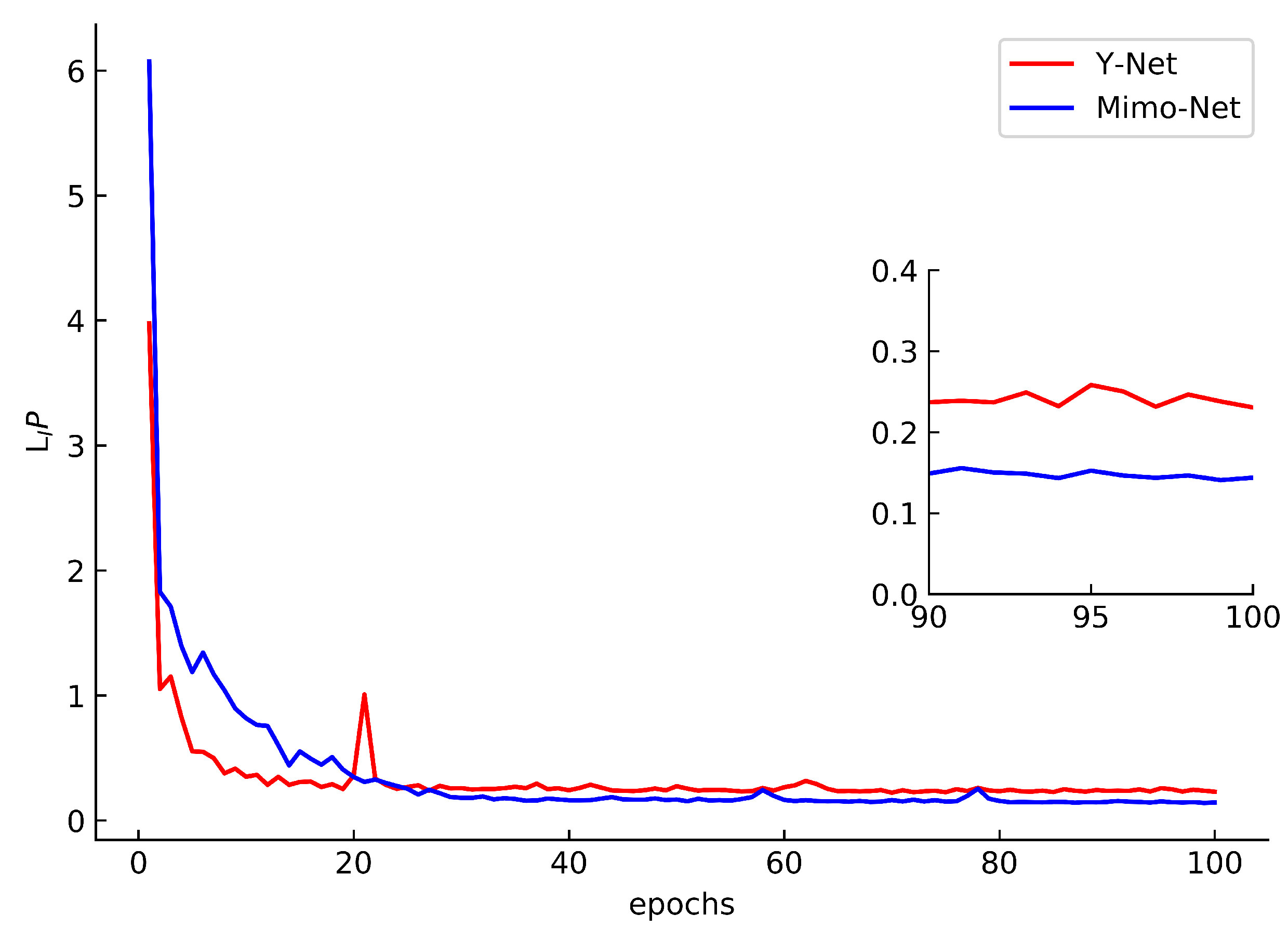
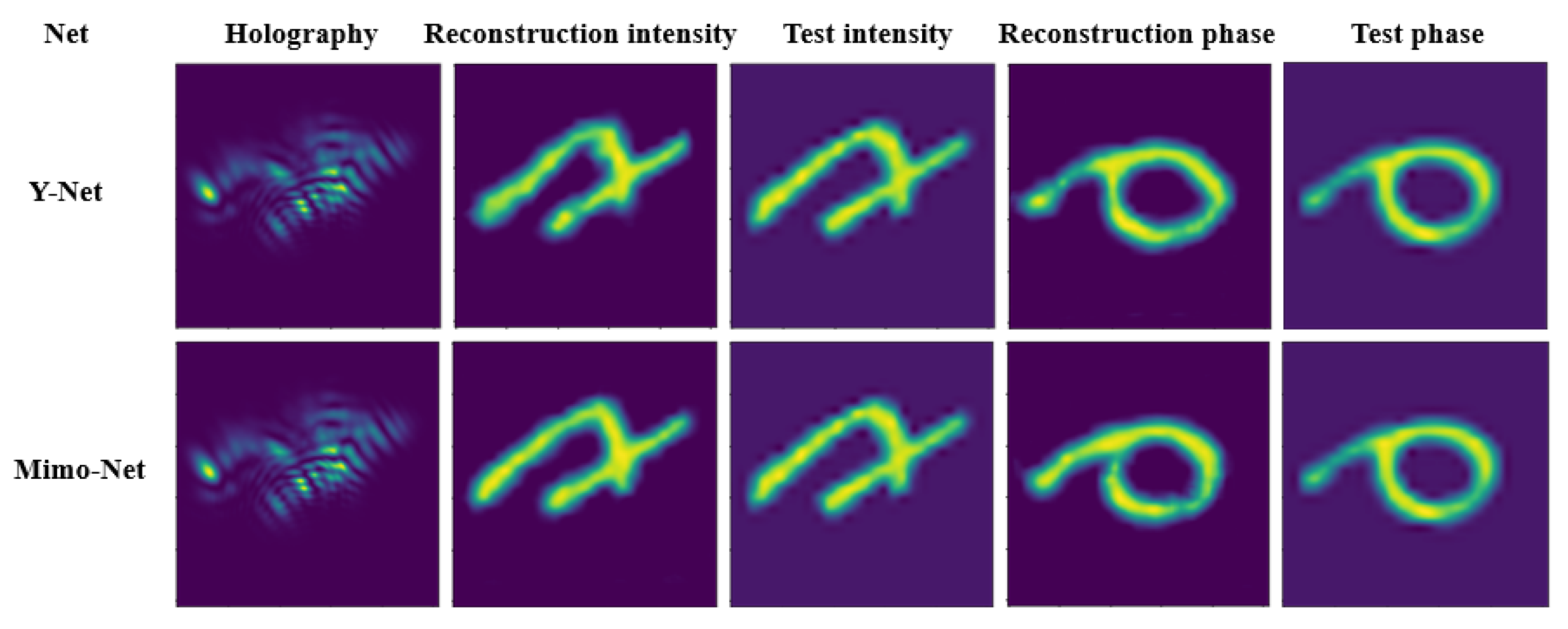
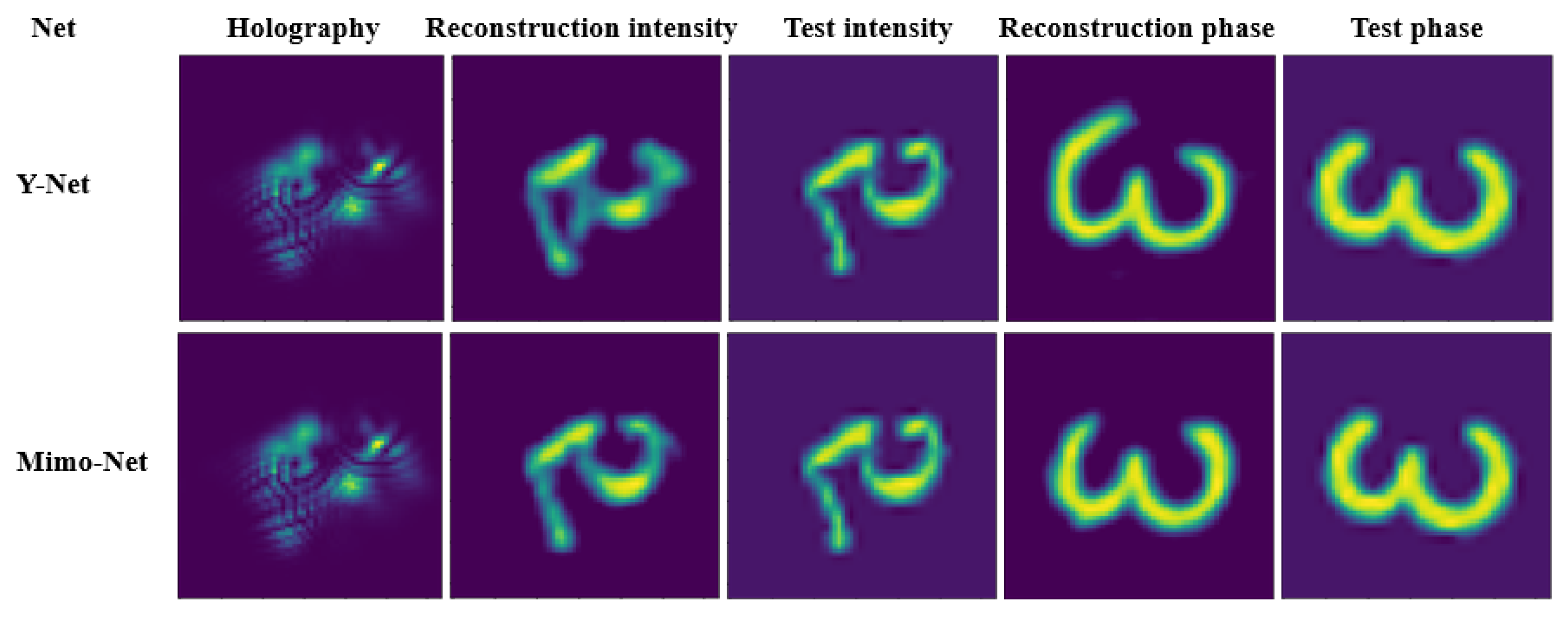
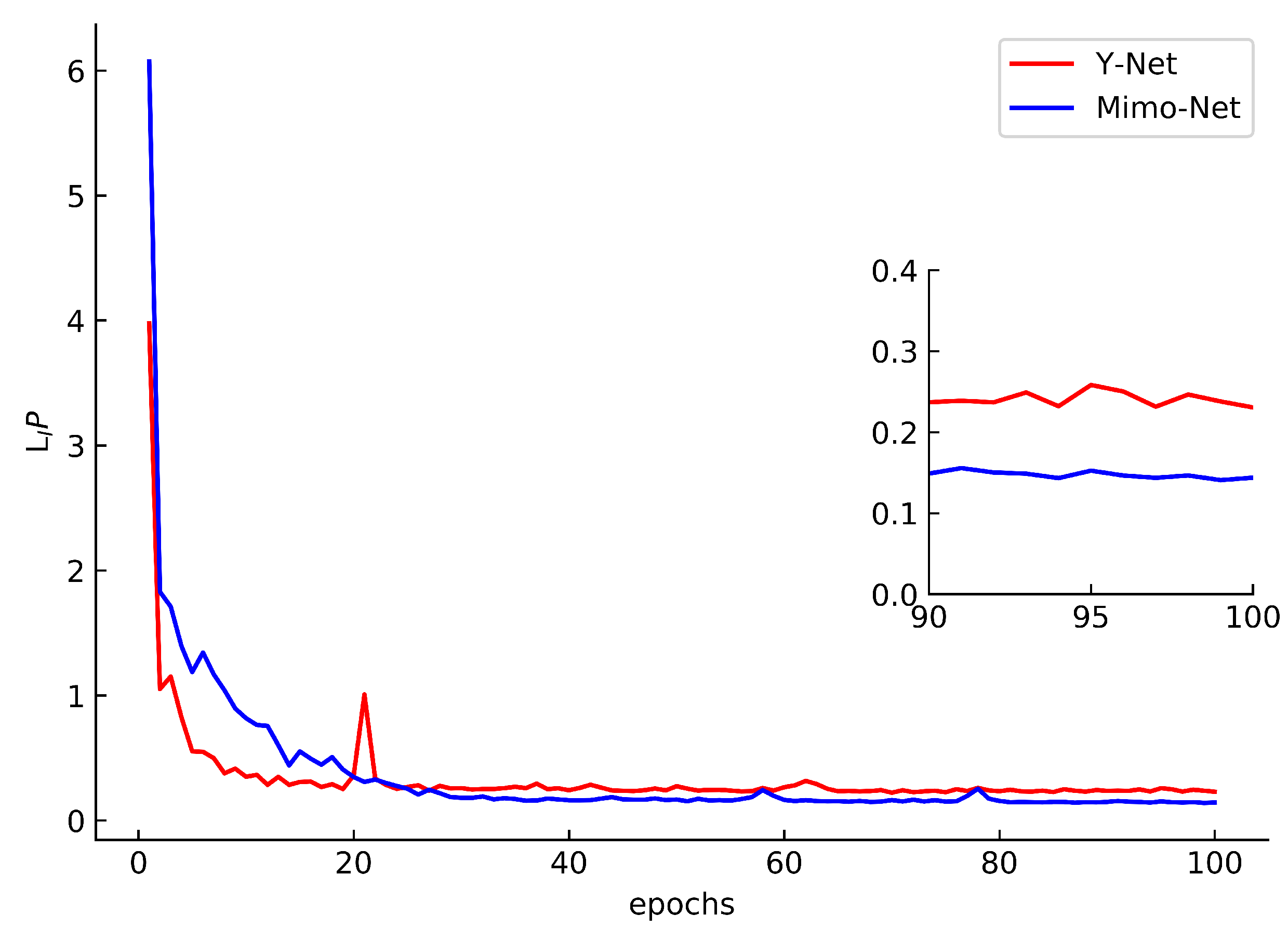
3.3.1. Comparison of Mimo-Net and Y-Net Training Results
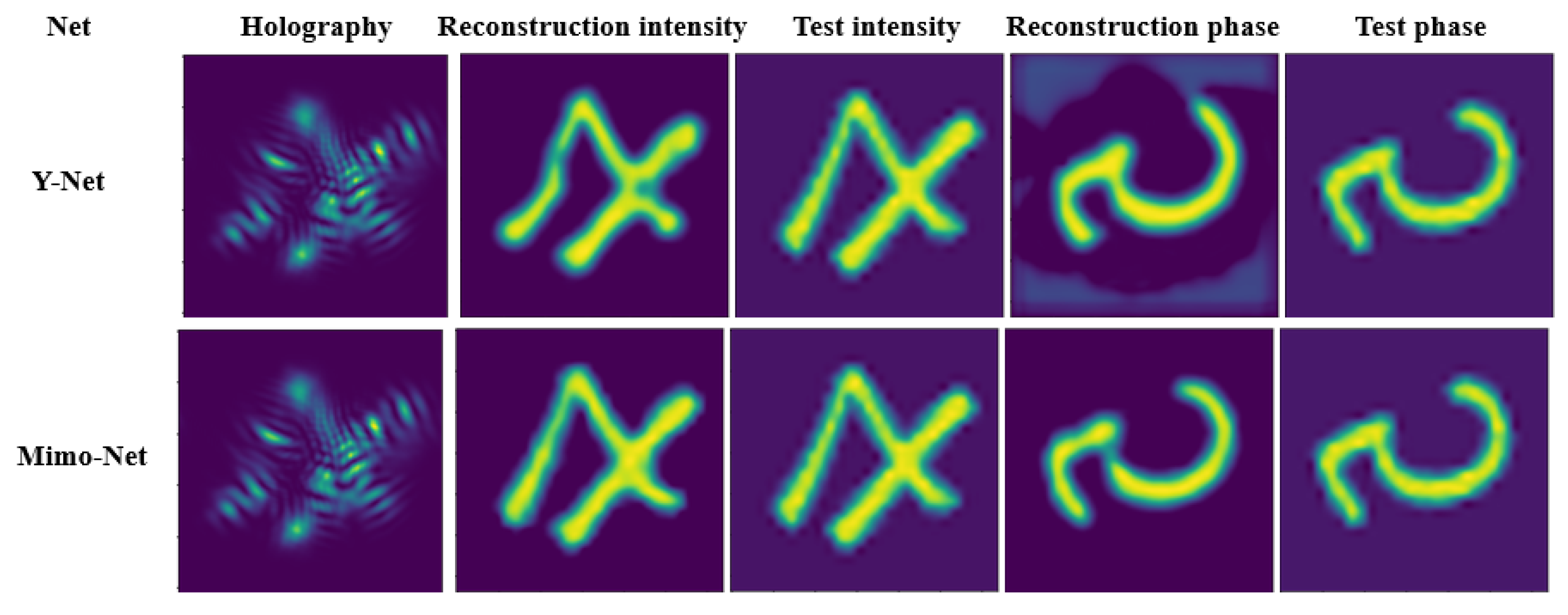
3.3.2. Comparison of Mimo-Net and Y-Net at 256 × 256 Scale
3.3.3. Comparison of Mimo-Net and Y-Net at 128 × 128 Scale
3.3.4. Comparison of Mimo-Net and Y-Net at 64 × 64 Scale
4. Summary and Analysis
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sheridan, J.T.; Kostuk, R.K.; Gil, A.F.; Wang, Y.; Lu, W.; Zhong, H.; Tomita, Y.; Neipp, C.; Francés, J.; Gallego, S.; et al. Roadmap on holography. J. Opt. 2020, 22, 123002. [Google Scholar] [CrossRef]
- Chernykh, A.V.; Ezerskii, A.S.; Georgieva, A.O.; Petrov, N.V. Study on object wavefront sensing in parallel phase-shifting camera with geometric phase lens. In Proceedings of the SPIE, San Diego, CA, USA, 1–5 August 2021; Volume 11898, p. 118980X. [Google Scholar]
- Kim, M.K. Principles and techniques of digital holographic microscopy. SPIE Rev. 2010, 1, 018005. [Google Scholar] [CrossRef]
- Rabosh, E.V.; Balbekin, N.S.; Timoshenkova, A.M.; Shlykova, T.V.; Petrov, N.V. Analog-to-digital conversion of information archived in display holograms: II. photogrammetric digitization. JOSA A 2023, 40, B57–B64. [Google Scholar] [CrossRef]
- Marquet, P.; Rappaz, B.; Magistretti, P.J.; Cuche, E.; Emery, Y.; Colomb, T.; Depeursinge, C. Digital holographic microscopy: A noninvasive contrast imaging technique allowing quantitative visualization of living cells with subwavelength axial accuracy. Opt. Lett. 2005, 30, 468–470. [Google Scholar] [CrossRef]
- Stepanishen, P.R.; Benjamin, K.C. Forward and backward projection of acoustic fields using FFT methods. J. Acoust. Soc. Am. 1982, 71, 803–812. [Google Scholar] [CrossRef]
- Dyomin, V.; Davydova, A.; Kirillov, N.; Polovtsev, I. Features of the Application of Coherent Noise Suppression Methods in the Digital Holography of Particles. Appl. Sci. 2023, 13, 8685. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Zhu, L.; Fang, C.; Yu, T.; Zhu, D.; Fei, P. Deep-learning super-resolution light-sheet add-on microscopy (Deep-SLAM) for easy isotropic volumetric imaging of large biological specimens. Biomed. Opt. Express 2020, 11, 7273–7285. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Huang, Y.; Lu, Z.; Shao, Z.; Ran, M.; Zhou, J.; Fang, L.; Zhang, Y. Simultaneous denoising and super-resolution of optical coherence tomography images based on generative adversarial network. Opt. Express 2019, 27, 12289–12307. [Google Scholar] [CrossRef] [PubMed]
- Svistunov, A.S.; Rymov, D.A.; Starikov, R.S.; Cheremkhin, P.A. HoloForkNet: Digital Hologram Reconstruction via Multibranch Neural Network. Appl. Sci. 2023, 13, 6125. [Google Scholar] [CrossRef]
- Zhang, G.; Guan, T.; Shen, Z.; Wang, X.; Hu, T.; Wang, D.; He, Y.; Xie, N. Fast phase retrieval in off-axis digital holographic microscopy through deep learning. Opt. Express 2018, 26, 19388–19405. [Google Scholar] [CrossRef]
- Ren, Z.; Xu, Z.; Lam, E.Y. End-to-end deep learning framework for digital holographic reconstruction. Adv. Photonics 2019, 1, 016004. [Google Scholar] [CrossRef]
- Xiao, W.; Wang, Q.; Pan, F.; Cao, R.; Wu, X.; Sun, L. Adaptive frequency filtering based on convolutional neural networks in off-axis digital holographic microscopy. Biomed. Opt. Express 2019, 10, 1613–1626. [Google Scholar] [CrossRef]
- Barbastathis, G.; Ozcan, A.; Situ, G. On the use of deep learning for computational imaging. Optica 2019, 6, 921–943. [Google Scholar] [CrossRef]
- Sinha, A.; Lee, J.; Li, S.; Barbastathis, G. Lensless computational imaging through deep learning. Optica 2017, 4, 1117–1125. [Google Scholar] [CrossRef]
- Rivenson, Y.; Zhang, Y.; Günaydın, H.; Teng, D.; Ozcan, A. Phase recovery and holographic image reconstruction using deep learning in neural networks. Light. Sci. Appl. 2018, 7, 17141. [Google Scholar] [CrossRef]
- Wang, H.; Lyu, M.; Situ, G. eHoloNet: A learning-based end-to-end approach for in-line digital holographic reconstruction. Opt. Express 2018, 26, 22603–22614. [Google Scholar] [CrossRef]
- Wang, K.; Dou, J.; Kemao, Q.; Di, J.; Zhao, J. Y-Net: A one-to-two deep learning framework for digital holographic reconstruction. Opt. Lett. 2019, 44, 4765–4768. [Google Scholar] [CrossRef]
- Picart, P.; Li, J.C. Digital Holography; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Benton, S.A.; Bove, V.M., Jr. Holographic Imaging; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Schnars, U.; Jüptner, W. Direct recording of holograms by a CCD target and numerical reconstruction. Appl. Opt. 1994, 33, 179–181. [Google Scholar] [CrossRef]
- Kreis, T.M.; Adams, M.; Jüptner, W.P. Methods of digital holography: A comparison. In Proceedings of the Optical Inspection and Micromeasurements II, SPIE, Munich, Germany, 16–19 June 1997; Volume 3098, pp. 224–233. [Google Scholar]
- Grilli, S.; Ferraro, P.; De Nicola, S.; Finizio, A.; Pierattini, G.; Meucci, R. Whole optical wavefields reconstruction by digital holography. Opt. Express 2001, 9, 294–302. [Google Scholar] [CrossRef] [PubMed]
- Georgieva, A.; Ezerskii, A.; Chernykh, A.; Petrov, N. Numerical displacement of target wavefront formation plane with DMD-based modulation and geometric phase holographic registration system. Atmos. Ocean. Opt. 2022, 35, 258–265. [Google Scholar] [CrossRef]
- Zeng, T.; Zhu, Y.; Lam, E.Y. Deep learning for digital holography: A review. Opt. Express 2021, 29, 40572–40593. [Google Scholar] [CrossRef] [PubMed]
- Rivenson, Y.; Wu, Y.; Ozcan, A. Deep learning in holography and coherent imaging. Light. Sci. Appl. 2019, 8, 85. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Kim, Y.; Moon, I. Automated phase unwrapping in digital holography with deep learning. Biomed. Opt. Express 2021, 12, 7064–7081. [Google Scholar] [CrossRef]
- Vithin, A.V.S.; Vishnoi, A.; Gannavarpu, R. Phase derivative estimation in digital holographic interferometry using a deep learning approach. Appl. Opt. 2022, 61, 3061–3069. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hara, K.; Saito, D.; Shouno, H. Analysis of function of rectified linear unit used in deep learning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Wang, L.; Li, Y.; Wang, S. DeepDeblur: Fast one-step blurry face images restoration. arXiv 2017, arXiv:1711.09515. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Morgan, H.; Druckmüller, M. Multi-scale Gaussian normalization for solar image processing. Sol. Phys. 2014, 289, 2945–2955. [Google Scholar] [CrossRef]
- Chen, C.; Lee, B.; Li, N.N.; Chae, M.; Wang, D.; Wang, Q.H.; Lee, B. Multi-depth hologram generation using stochastic gradient descent algorithm with complex loss function. Opt. Express 2021, 29, 15089–15103. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Configuration | Parameter |
|---|---|
| CPU | i5 9400F |
| RAM | 32G |
| GPU | RTX3060 |
| GPU Memory | 12G |
| Framework | TensorFlow2.0 |
| Net | Scales | Times/s | Total Times/s |
|---|---|---|---|
| 256 × 256 | 1687 | ||
| Y-Net | 128 × 128 | 582 | 2713 |
| 64 × 64 | 444 | ||
| Mimo-Net | 256 × 256, 128 × 128, 64 × 64 | 1008 | 1008 |
| Parameter | Intensity of Y-Net | Intensity of Mimo-Net | Phase of Y-Net | Phase of Mimo-Net |
|---|---|---|---|---|
| PSNR/dB | 31.5431 | 33.9632 | 31.0891 | 31.3922 |
| SSIM | 0.9251 | 0.9463 | 0.9208 | 0.9252 |
| Parameter | Intensity of Y-Net | Intensity of Mimo-Net | Phase of Y-Net | Phase of Mimo-Net |
|---|---|---|---|---|
| PSNR/dB | 29.7061 | 32.4975 | 31.3524 | 31.5966 |
| SSIM | 0.9499 | 0.9676 | 0.9239 | 0.9403 |
| Parameter | Intensity of Y-Net | Intensity of Mimo-Net | Phase of Y-Net | Phase of Mimo-Net |
|---|---|---|---|---|
| PSNR/dB | 29.5614 | 31.9453 | 28.4567 | 29.5390 |
| SSIM | 0.8794 | 0.9249 | 0.8943 | 0.9320 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Li, Z.; Zhou, Y.; Zhang, Y.; Jia, J.; Wang, Y. Deep-Learning Multiscale Digital Holographic Intensity and Phase Reconstruction. Appl. Sci. 2023, 13, 9806. https://doi.org/10.3390/app13179806
Chen B, Li Z, Zhou Y, Zhang Y, Jia J, Wang Y. Deep-Learning Multiscale Digital Holographic Intensity and Phase Reconstruction. Applied Sciences. 2023; 13(17):9806. https://doi.org/10.3390/app13179806
Chicago/Turabian StyleChen, Bo, Zhaoyi Li, Yilin Zhou, Yirui Zhang, Jingjing Jia, and Ying Wang. 2023. "Deep-Learning Multiscale Digital Holographic Intensity and Phase Reconstruction" Applied Sciences 13, no. 17: 9806. https://doi.org/10.3390/app13179806
APA StyleChen, B., Li, Z., Zhou, Y., Zhang, Y., Jia, J., & Wang, Y. (2023). Deep-Learning Multiscale Digital Holographic Intensity and Phase Reconstruction. Applied Sciences, 13(17), 9806. https://doi.org/10.3390/app13179806