1. Introduction
With the advent of new technologies such as cloud storage, scientific computing, medical imaging, and social networking, the creation of digital content is exploding, driving the need for cost-effective, high-capacity storage in the modern data center [
1,
2,
3]. Conventional Magnetic Recording (CMR) disks, known for their affordability and reliability, have been fundamental in constructing modern storage systems. However, their potential to achieve higher areal density gains through reducing bit size has seemingly reached its limits due to the superparamagnetic effect (SPE) [
4]. In response to this challenge, various magnetic recording technologies that utilize energy-assisted and optimized track layouts have been proposed to overcome the existing dilemma [
5,
6,
7,
8].
Among these candidates, Shingled Magnetic Recording (SMR) and Interlaced Magnetic Recording (IMR) technologies are considered to be cost-effective and have therefore gained widespread attention in recent years [
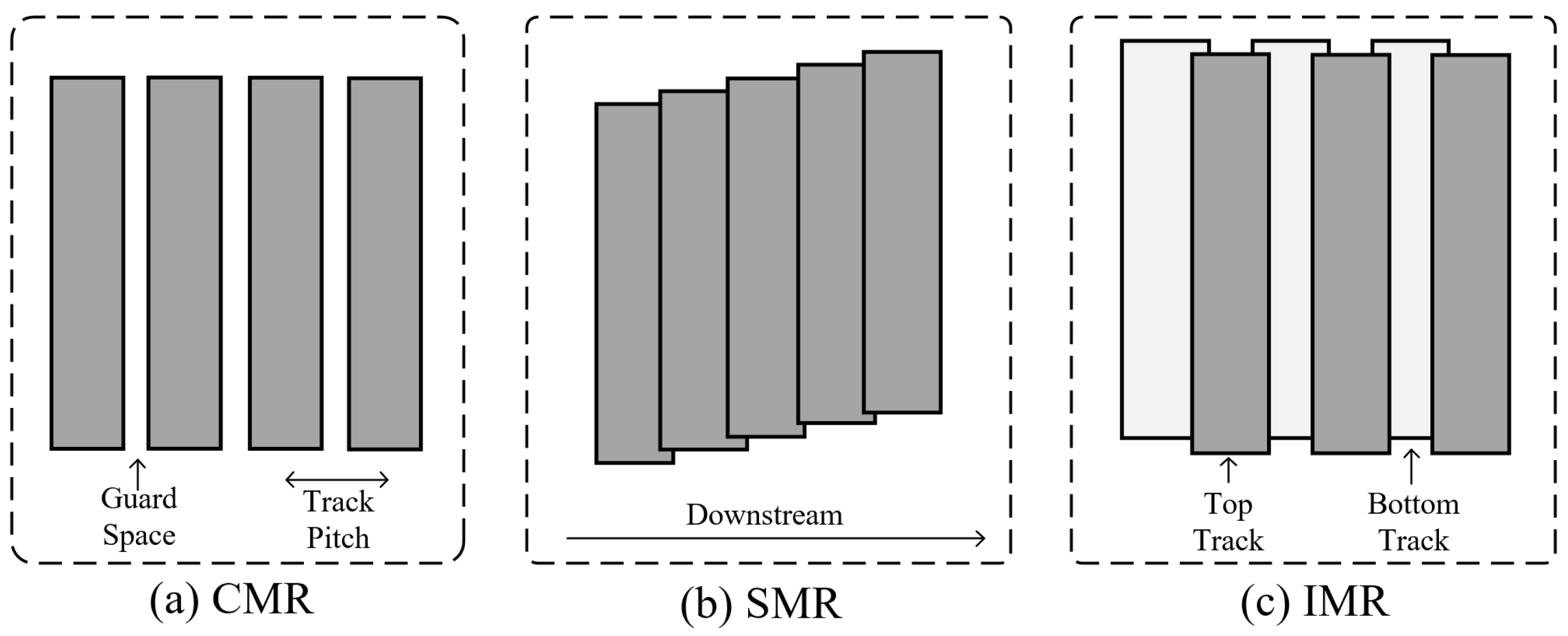
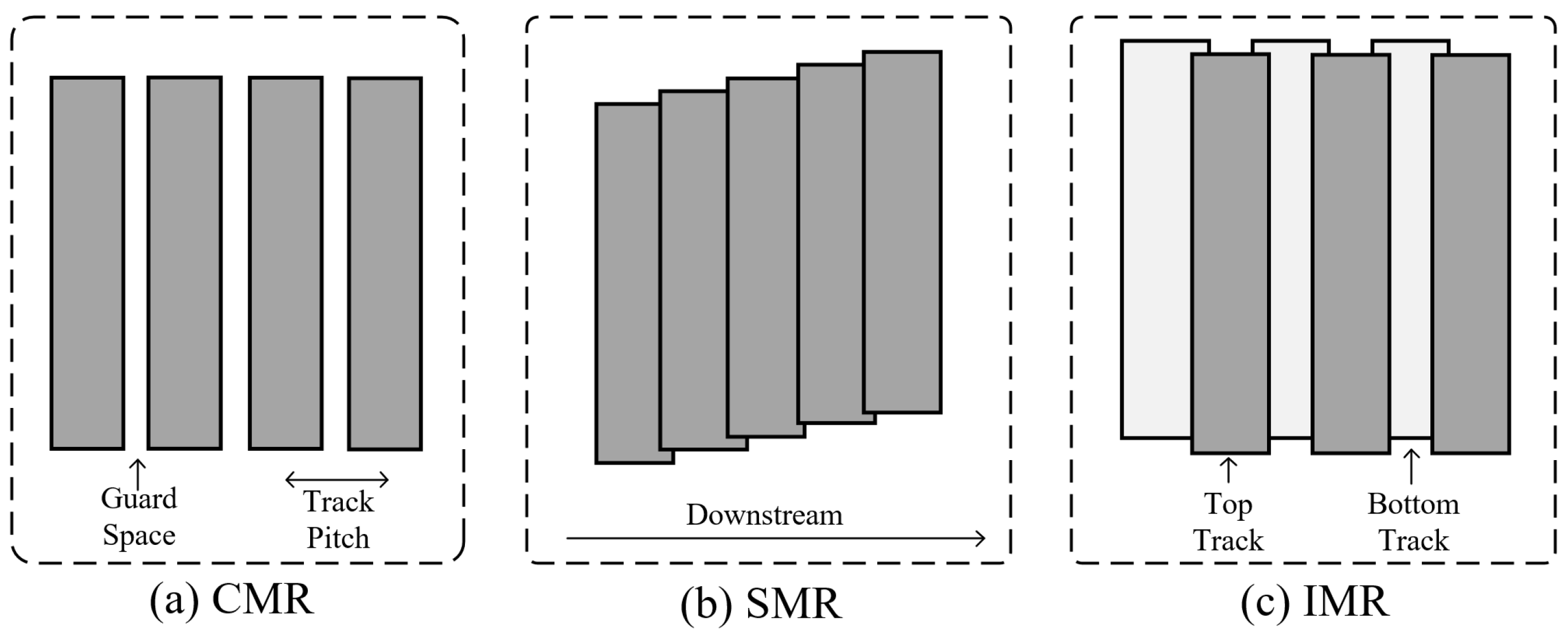
9]. CMR disk (
Figure 1a) tracks are separated by guard spaces, allowing random writes without affecting adjacent tracks. In contrast, the SMR disk (
Figure 1b) reduces track pitch by enlarging the write heads and subtly overlapping the tracks like shingles to achieve higher areal densities. However, this gain in capacity comes at the cost of introducing a significant amount of extra I/Os, as random writes to any track require time-consuming cascading track rewrites to maintain the integrity of adjacent valid data. Another promising successor to CMR, IMR, uses both heat-assist technology and an interlaced track layout to achieve capacity gains [
8]. As shown in
Figure 1c, an IMR disk conceptually divides tracks into the top and bottom tracks. Each narrower top track (smaller track pitch) is interleaved with two wider bottom tracks (higher line density). Writing to the bottom track requires stronger laser power than the top track, which introduces write interference that corrupts valid data in the top track. Consequently, writing to the bottom track requires rewriting two adjacent top tracks, a process known as read–modify–write (RMW). Although the write penalties of IMR are obviously lower than those of SMR, frequent RMWs degrade disk performance as space utilization (allocated track ratio) increases, limiting their use at scale [
10,
11].
To date, there have been several efforts from academia and industry to reduce the frequency of track rewrites. These efforts mainly focus on optimizing data placement and data shuffling techniques. Data placement policies that take into account the write interference effect, statically or dynamically allocate tracks for incoming data to minimize unnecessary rewrite overhead. For example, a typical three-phase write management method [
12,
13] places incoming new data evenly across free tracks based on space utilization to delay the onset of RMW as much as possible. On this basis, Wu et al. [
14] proposed a zigzag track allocation policy to improve the spatial locality of logical data blocks, resulting in reduced seek time. Compared with the static data placement policy, the dynamic data placement policy further reduces the track rewrite frequency by considering the track hotness. For example, during the top track allocation phase, MAGIC [
10] attempts to place data on the free top track adjacent to the cold (infrequently updated) bottom track and redirects write interference data (if there is valid data on the top tracks adjacent to the bottom tracks, writing to these bottom tracks will cause write interference. Therefore, the term “write interference data” is used to describe data written to the bottom tracks that cause such interference) to a persistent buffer inside the disk, effectively reducing the introduction of track rewrite overhead. In practice, the top track can be written freely without introducing rewrite overhead. To take advantage of this property, data shuffling policies periodically or actively swap hot (frequently updated) data from the bottom track with cold data from the top track, at either track-level or block-level granularity. For example, Hajkazemi et al. [
15] proposed three track-level data shuffling policies that minimize rewrite overhead by periodically moving bottom hot tracks to a persistent buffer or top tracks. Similarly, MOM [
11] reduces extra I/Os by actively moving data to be rewritten to the free top track instead of backing up and restoring the data. Recently, Wu et al. [
16] introduced two block-level data shuffling policies to improve the efficiency of data migration. The block-level data shuffling policy more accurately identifies hot data blocks, thereby improving the efficiency of each swap. In fact, data placement and data shuffling reduce the frequency of track rewrites from different perspectives; it is practical to use them together to achieve greater performance gains [
10,
14,
16]. Nevertheless, existing research lacks a comprehensive solution for efficiently combining data placement and data shuffling. In particular, there is a non-negligible performance gap between IMR disks and CMR disks under high space utilization, which greatly affects the practical use of IMR disks.
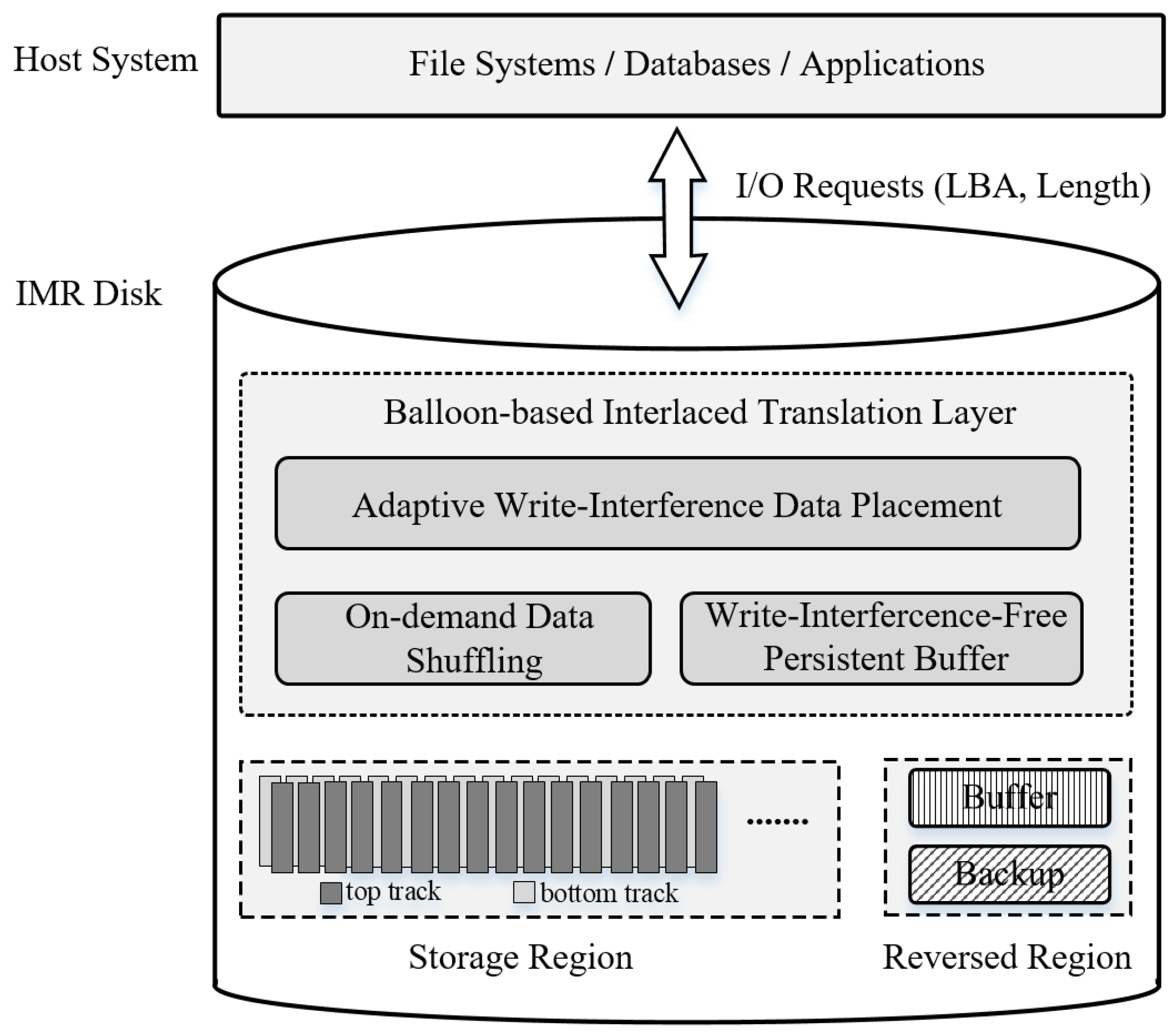
To mitigate the performance degradation caused by track rewrites, this paper presents an elastic data management strategy called Balloon, which is a device-level solution similar to the flash translation layer and the shingled translation layer. The principle behind this strategy is to proactively allocate incoming write interference data to the free top track. This not only eliminates the rewrite overhead of direct read–modify–write (RMW) operations but also enables low-cost data shuffling using the buffered data in the top track at no additional cost. As a result, the strategy uses on-demand data shuffling to relocate hot and cold data to specific regions, minimizing the frequency of track rewrites and the impact of data migration on user requests. The contributions of this research can be summarized as follows:
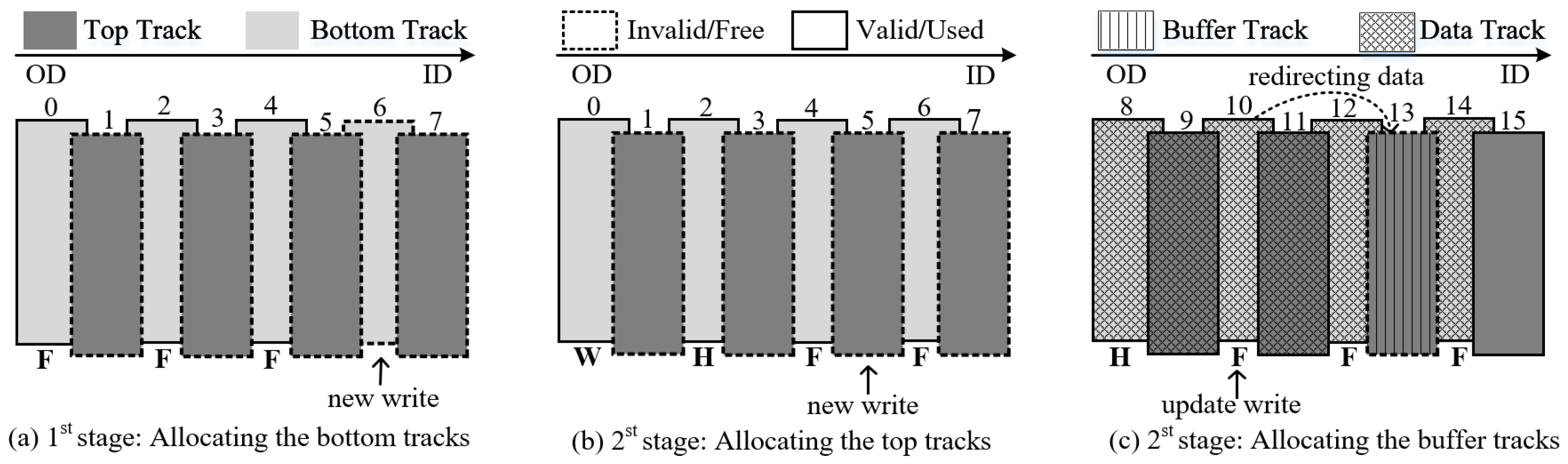
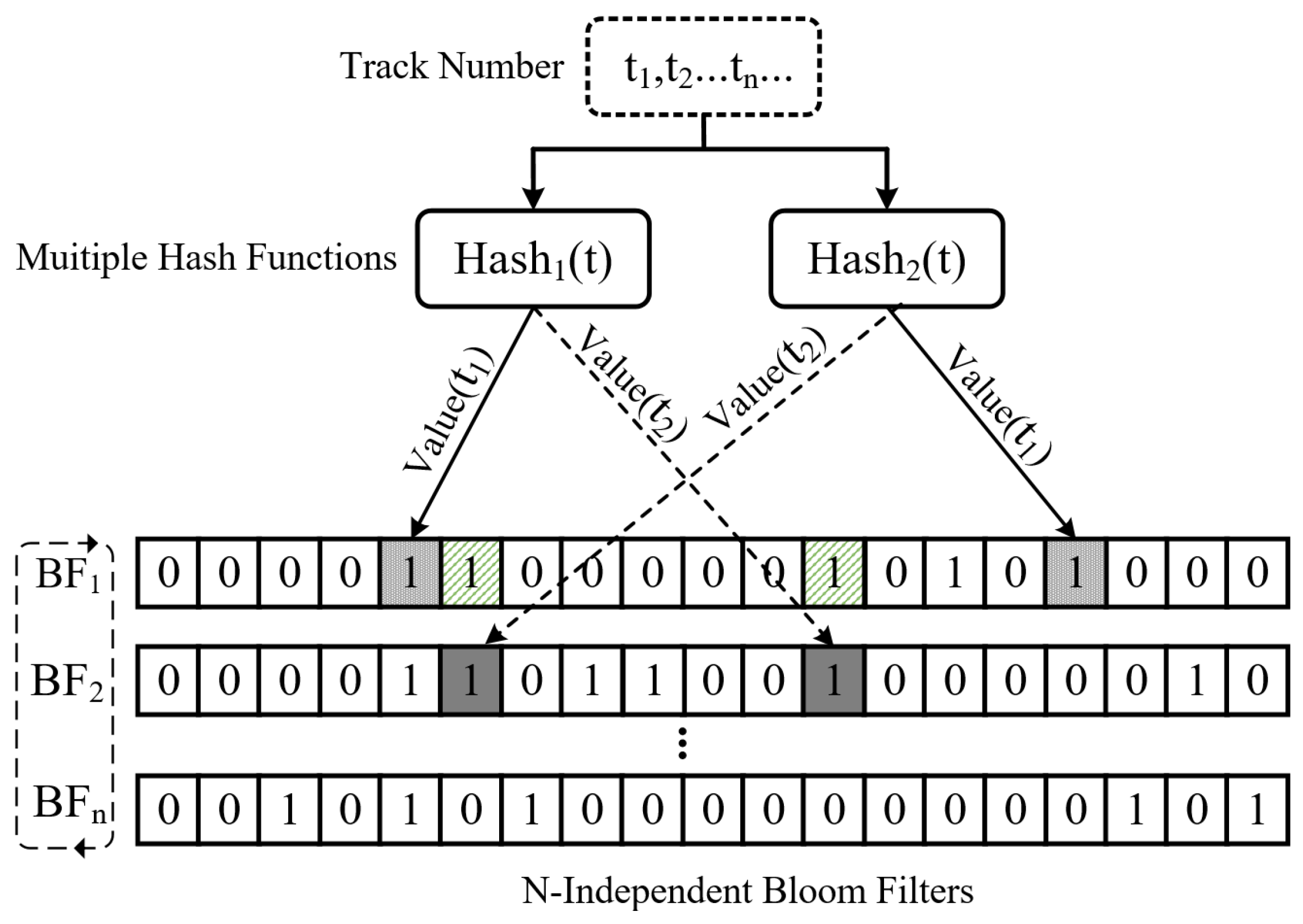
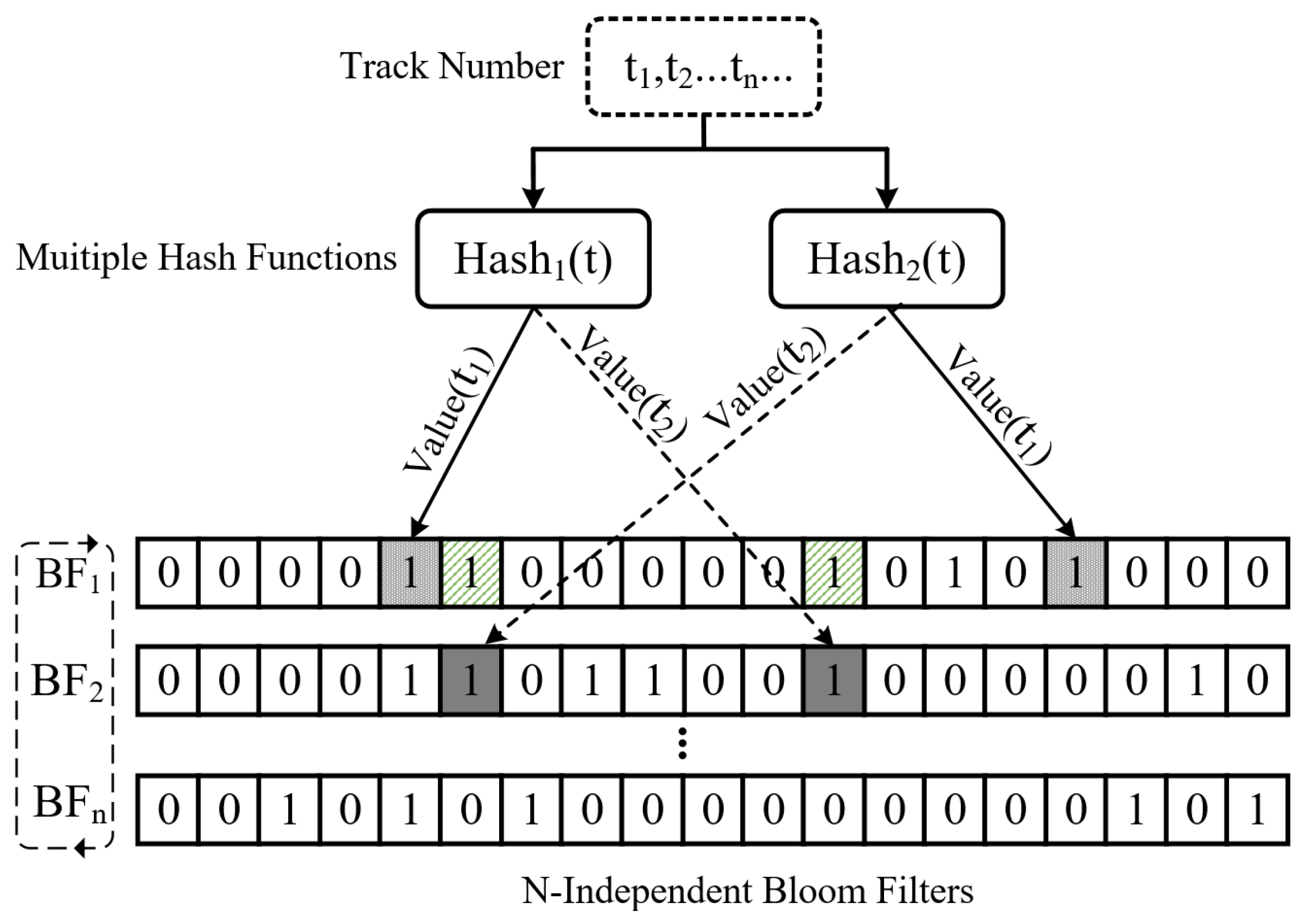
An adaptive write interference data placement policy is proposed that reduces unnecessary rewrite overhead by judiciously placing data in tracks with low rewrite probability and opportunistically using the free top track to buffer write interference data. Meanwhile, a lightweight Bloom-filter-based hotness scoring mechanism for tracks is established to better balance the accuracy and memory overhead of track-level hotness identification.
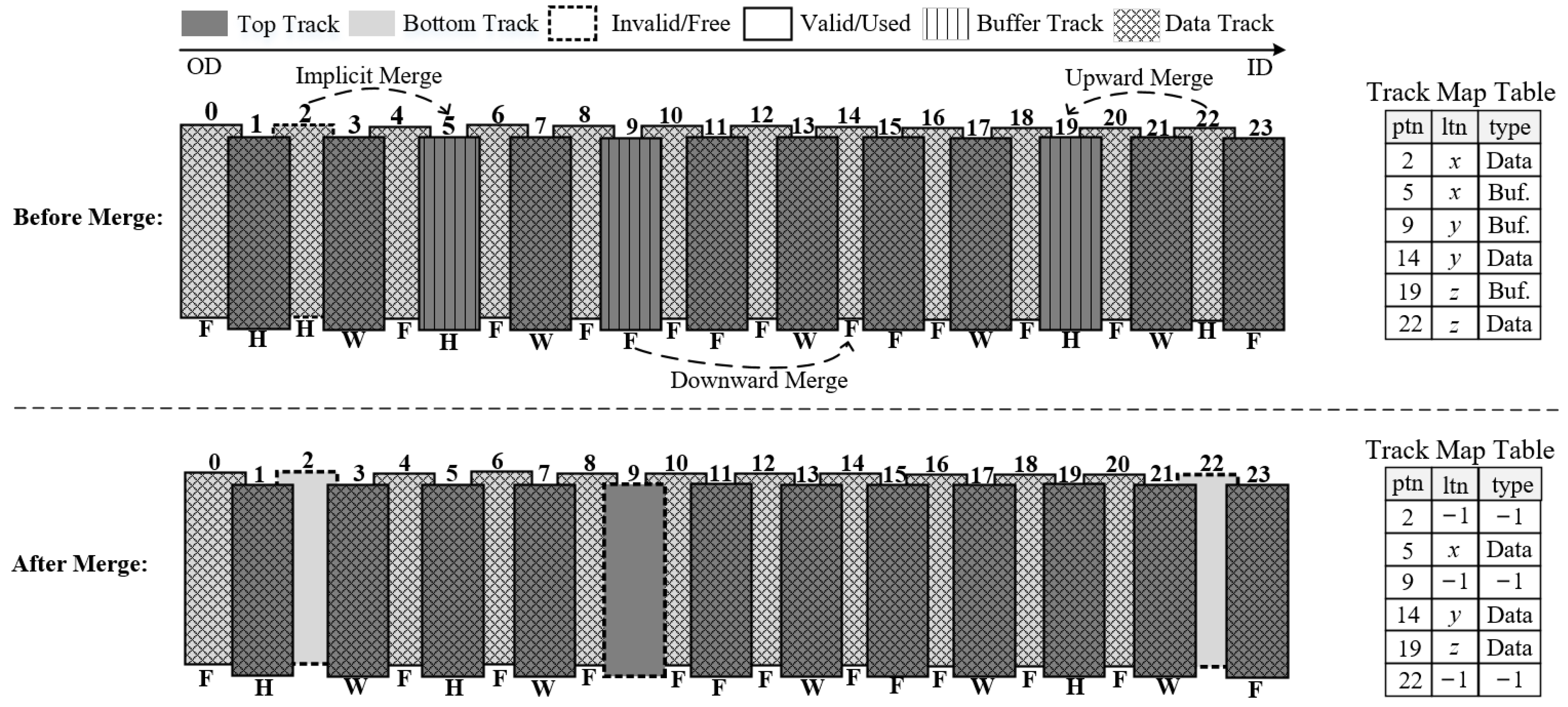
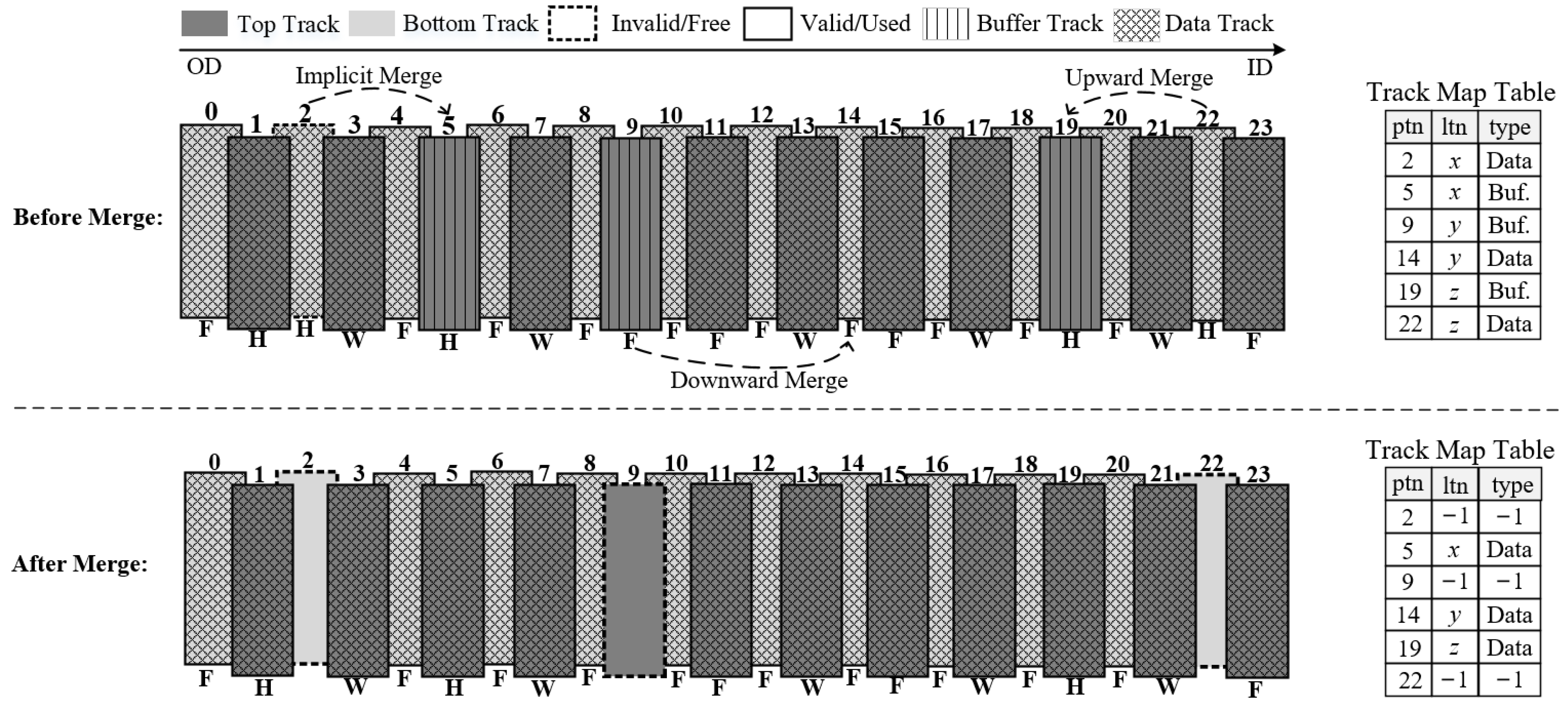
An on-demand data shuffling policy is introduced to further improve data placement efficiency. During data shuffling, hot tracks with low update block coverage are relocated to reserved regions of the disk to minimize the frequency of track rewrites, while tracks with high update block coverage are placed in the top region promptly to reduce seek time for subsequent update requests.
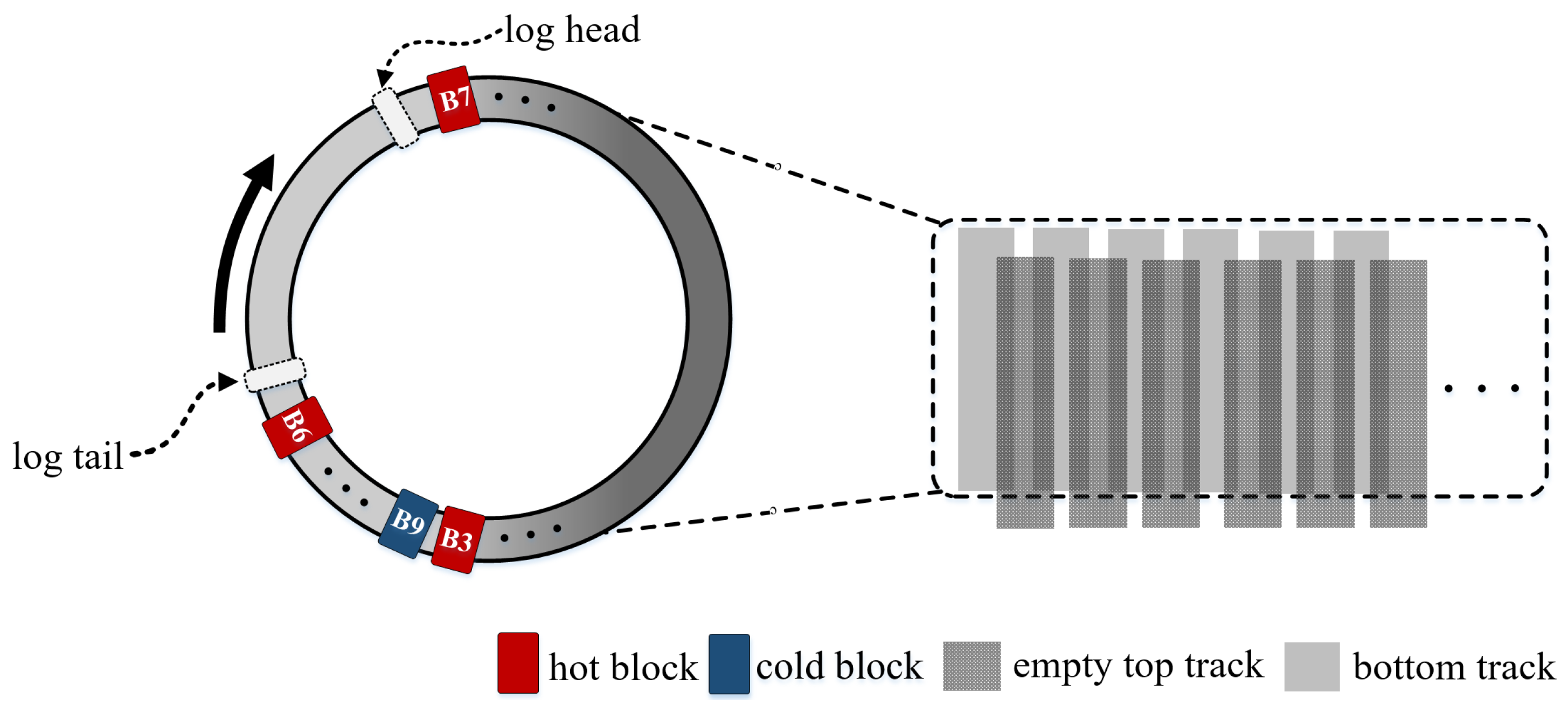
To boost the collaborative efficiency of data placement and data shuffling, a write-interference-free persistent buffer is introduced. The persistent buffer dynamically adjusts admission constraints based on space utilization, thereby reducing the cleanup frequency. Moreover, it selectively evicts data blocks to minimize the frequency of track rewrites.
The results of our evaluation show that the proposed strategy improves IMR write performance by up to 68.7% and 78.8% on average at medium and high space utilization, respectively, compared with state-of-the-art studies.
The rest of this paper is organized as follows.
Section 2 describes the background and related work. The motivation is then presented in
Section 3. Details of the Balloon design and implementation instructions are given in
Section 4. Evaluation results and analysis are given in
Section 5. Finally,
Section 6 summarizes the study.
3. Motivation
Compared with existing studies, our focus is on enhancing the write performance of IMR disks with high space utilization. To achieve this goal, the proposed strategy utilizes disk resources as much as possible to reduce the frequency of track rewrites and improve the efficiency of the cooperation between data placement and data shuffling.
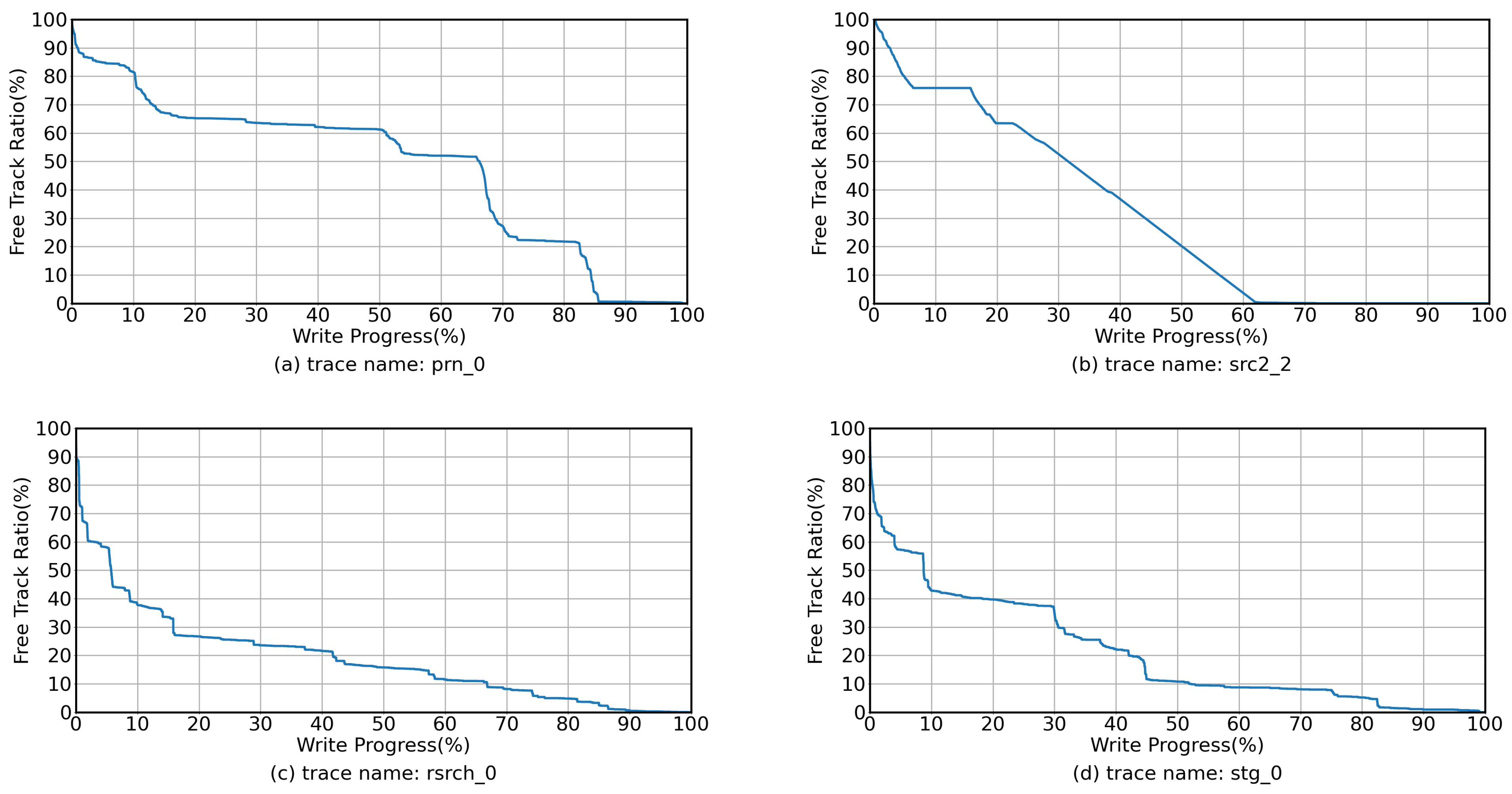
In real-world workloads, new write requests and update write requests alternate on disk, meaning that free tracks are not immediately exhausted. To better illustrate this phenomenon, we analyzed the block-level traces obtained from Microsoft Research (MSR) Cambridge [
17,
18] and selected four traces, namely prn_0, src2_2, rsrch_0, and stg_0. These traces are write-intensive workloads, with the key difference being that the first two are dominated by spatial locality, while the latter two are dominated by temporal locality. In addition, since all existing IMR studies use a track-level data placement method (each logical track is mapped to a unique physical track, and incoming data are placed at the appropriate location on the physical track according to its offset within the logical track), we used the typical three-phase write management method as the baseline policy for data placement. Detailed information about the workload and experimental platform characterization can be found in
Section 5.1. As shown in
Figure 3, the temporal-locality-dominated workloads, rsrch_0 and stg_0, trigger top-track allocation when write progress reaches 6% and 9%, respectively. In contrast, the spatial-locality-dominated workloads prn_0 and src2_2 have slower track consumption rates, with top track allocation triggered only when write progress is 66% and 32%, respectively. Although rsrch_0 and stg_0 initiate top-track allocation early in the workload, the rate of free track allocation gradually slows as write progress increases. In summary, regardless of the rate of free track consumption at each stage of the workload, there are always free tracks available on the disk until the write progress reaches 100%.
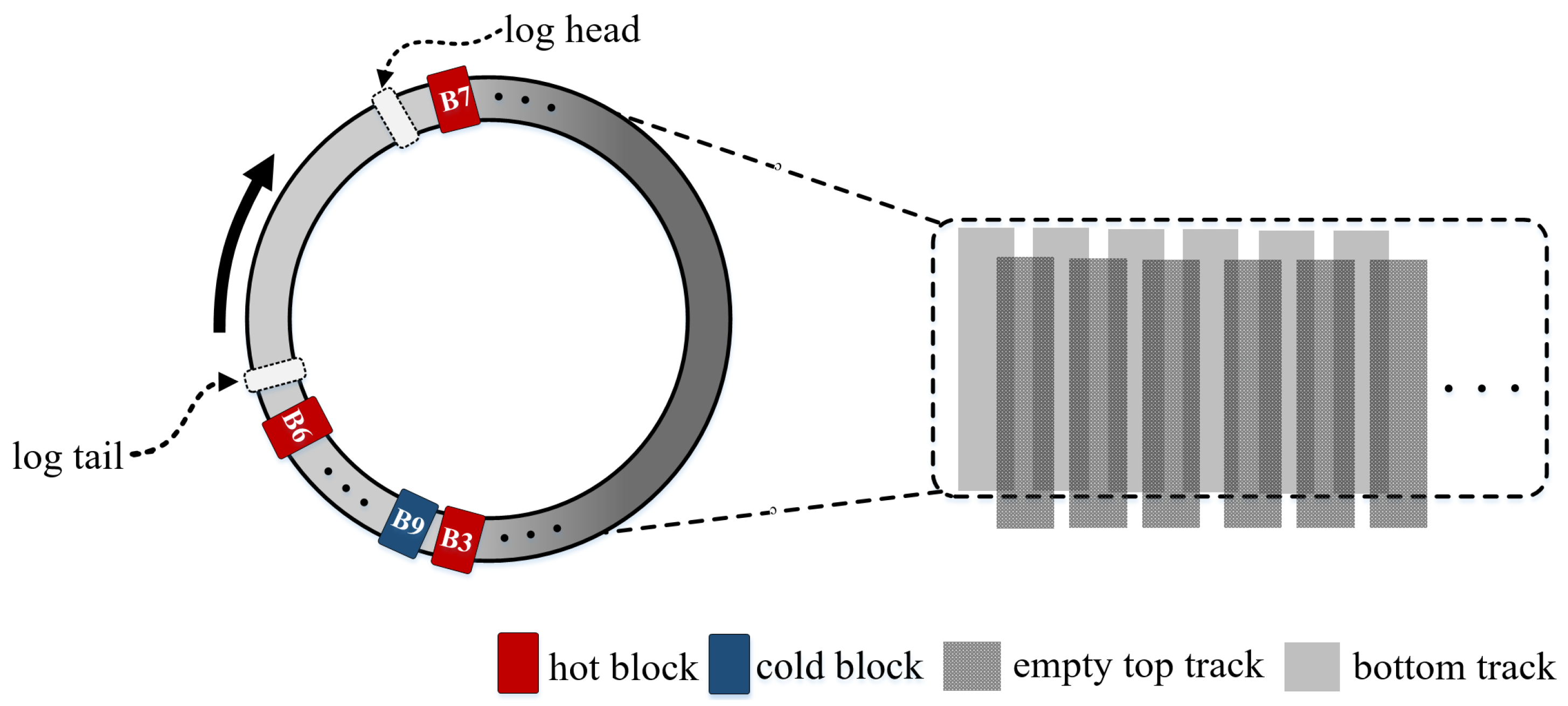
Inspired by the above observation, if free top tracks can be used to accommodate write interference data, then track rewrites can be efficiently suppressed. Therefore, the key to reducing rewrite overhead is to find a rational approach to using the free top track as a buffer track. However, this is not an easy task, and the challenge lies in the following aspects: (1) how to select the right candidate to act as a buffer track without accelerating the consumption of free tracks; (2) how to use buffer tracks to facilitate low-cost data shuffling; and (3) how to handle track rewrites when there are no reclaimable top tracks to act as buffer tracks.
5. Performance Evaluation
5.1. Evaluation Setup
In this section, the effectiveness of the proposed Balloon translation layer is evaluated and the related evaluation results are reported. Since IMR is a very new technology, there are no IMR disks in the market yet. Therefore, we simulate the characteristics of an IMR disk based on a real CMR disk (model ST500DM002 [
23]). The track size of the simulated IMR disk is set to 2 MB, which is set concerning recent studies [
10,
11,
15,
24]. The prototype system of the proposed strategy provides a block interface for the upper layer to replay I/O requests from block-level trace files. Specifically, all I/O requests are submitted to the simulated device through read and write functions provided by the open-source library libaio [
25]. To improve the accuracy of the evaluation, all replayed read and write requests are direct I/O, bypassing the kernel buffer, and the on-disk cache is disabled. In addition, the capacity of the IMR disks was not set to a fixed value but determined by the unique track count written in the currently replayed trace to evaluate the performance of Balloon and competitors under different space utilization. All evaluations are performed on an AMD workstation with EPYC 7302 CPU 3.0 GHz and 128 GB RAM. The operating system is Ubuntu 20.04.1 based on the Linux 5.15.0 kernel.
Our goal is to narrow the performance gap between IMR disks and CMR disks to make them suitable for traditional server application scenarios. To achieve this, we selected a set of write-intensive tracks from the MSR collection [
17,
18], since read-intensive workloads may not result in track rewrites. The write requests in the selected trace exhibit various characteristics, including temporal and spatial locality, as well as random and sequential nature.
Table 1 provides details about these characteristics. Throughout this study, our focus has been on evaluating the performance of the proposed strategy under high space utilization. Therefore, the number of available tracks is dynamically adjusted based on the footprint (total number of unique tracks written) of the selected trace. For example, at 100% space utilization, the total number of available tracks is equal to the total number of unique tracks written in the selected trace. Similarly, at 50% space utilization, the total number of available tracks is twice the number of unique tracks written.
In addition to the CMR disks used as a baseline, state-of-the-art ITL designs are carefully selected as Balloon competitors. These competitors include three-phase write management (Seagate) [
12,
13], selective track caching (STC) [
15], dynamic track mapping (DTM) [
15], MOM [
11], and MAGIC [
10], and their fundamentals are described in the related work in
Section 2. We also included a variant of Balloon in the evaluation, called Balloon-MS, which disables the WIF-PB and allows only merge and swap operations. This variant helps us observe the extent of performance improvement on IMR disks with limited disk resources. To ensure a fair evaluation, the parameters of all competitors are strictly set according to the source paper. Specifically, the update frequency of the selective track caching and dynamic track mapping policies is set to 20 K, with the persistent buffer size of the former set to 1% of the disk capacity (see the settings of the latest SMR disks), similar to the settings of the Balloon and MAGIC, while the latter has a hot/cold threshold of 50 and includes 256 pseudotracks per zone. For MAGIC, we use the default region size of 64 MB as suggested in the original paper. In Balloon, referencing studies [
19,
20], the TMBF is configured with N = 8 and
p = 2048, and the oldest BF is reset every 256 update requests for different tracks to decay the records in the TMBF. All these settings ensure a fair and comprehensive comparison between the ITL designs.
5.2. I/O Performance Evaluation
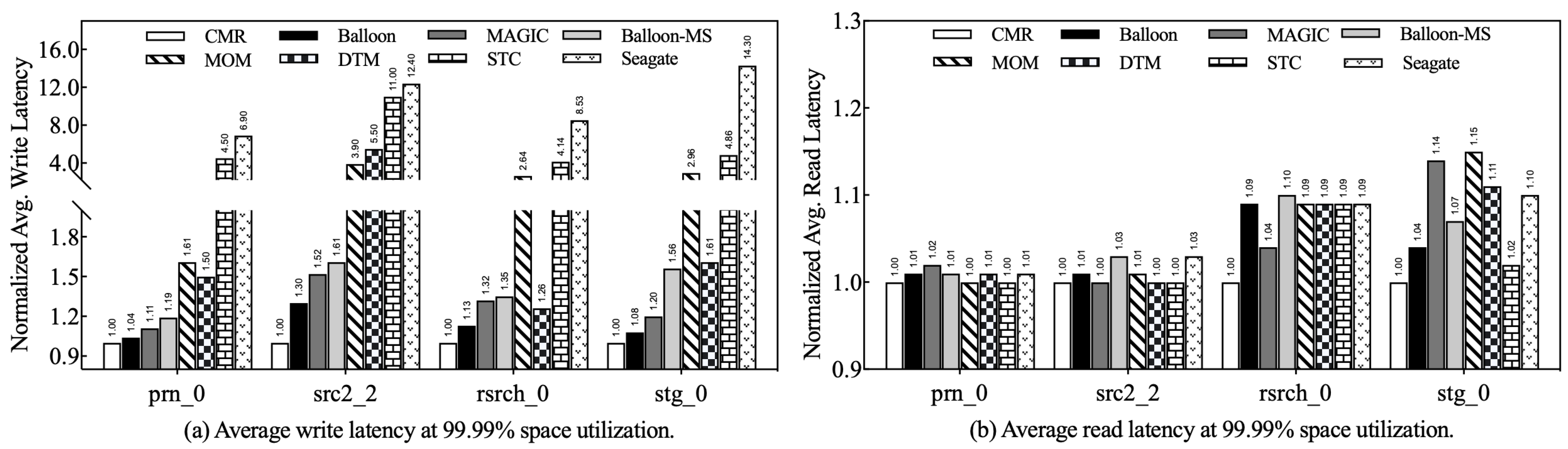
In general, the write performance of IMR disks exhibits fluctuations as the space utilization increases due to the increasing number of tracks triggering RMW operations. To evaluate the effectiveness of the proposed Balloon strategy, we evaluate the performance of IMR disks at 80% and 99.99% utilization (considered as medium and high utilization, respectively). These scenarios help us understand how the strategy performs at write-intensive workloads. In our evaluation, we analyze in detail the improvements in write and read performance achieved by the proposed strategy. While the average I/O latency of a workload provides insight into the overall performance of the disk, it may not fully capture the true read/write performance. Therefore, we focus on understanding how Balloon improves the read and write performance of IMR disks.
5.2.1. Write Performance
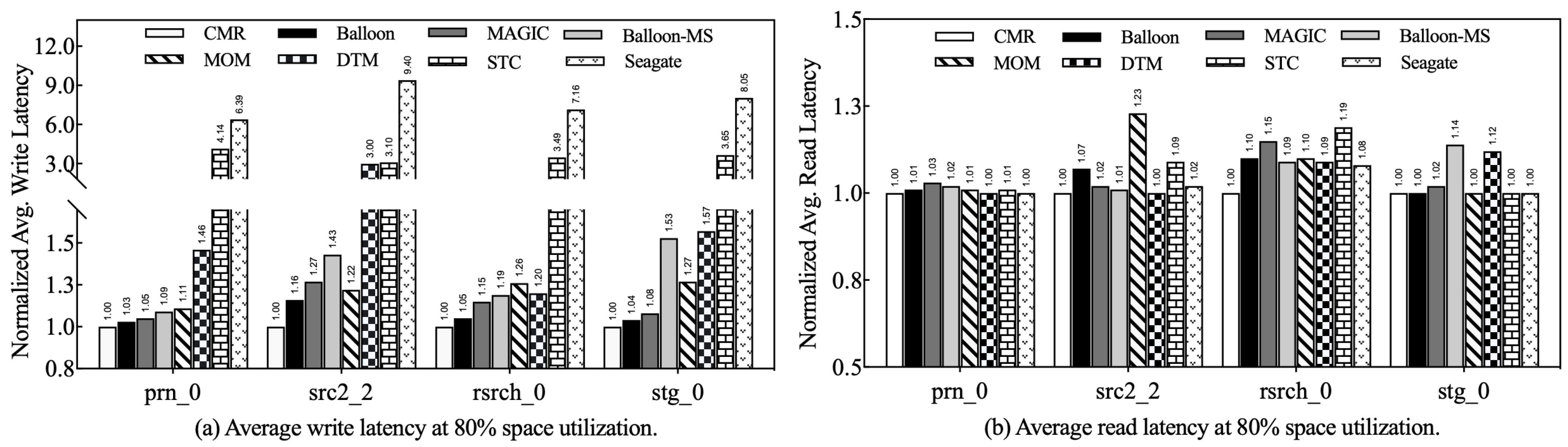
Figure 9a shows the comprehensive write performance comparison between Balloon and its competitors at medium utilization. Notably, the write performance of Balloon-based IMR disks is consistently the closest to that of CMR disks across different workloads. The similarity in performance between Balloon and MAGIC can be attributed to two factors: First, during the top allocation phase, Balloon and MAGIC dynamically select free top tracks based on the hotness of the bottom tracks. When disk utilization is at a medium level, a number of free tracks are available, making it easy to place data on tracks with low rewrite probability. Second, both strategies utilize the persistent buffer to manage write interference data. At medium utilization, the persistent buffer experiences fewer writes, which reduces the impact of cleanup activities on write performance. Despite these similarities, Balloon still outperforms MAGIC with an average write performance improvement of 5.74%. As shown in
Figure 10a, at high utilization rates, Balloon achieves a significant improvement in IMR disk write latency over its competitors, ranging from 6.3% to 92.4%. Of particular note is the 11.3% average improvement in write performance over MAGIC. The effectiveness of Balloon in improving write performance is attributed to its skillful use of the free top track as buffer tracks and its resilient persistent buffer admission and eviction constraints. In addition, Balloon’s lightweight track hotness scoring mechanism periodically discards historical data to adapt to current workload access patterns. The above measures significantly reduce the frequency of track rewrites and the impact of buffer cleanup on write performance.
In addition, we also focused on the performance gap between Balloon-MS and other competitors without a persistent buffer. As shown in
Figure 9a, Balloon-MS outperforms its competitors under both prn_0 and rsrch_0, achieving an average write performance improvement of 45.9% and 38.9%, respectively, while its write latency is higher than MOM under src2_2 and stg_0. This result is due to the fact that Balloon-MS makes full use of the available tracks to act as buffer tracks, and reclaiming buffer tracks introduces some overhead. At high utilization rates, as shown in
Figure 10a, Balloon-MS consistently outperforms MOM. It is noteworthy that both MOM and Balloon-MS resume RMW operations when the disk reaches full capacity, because there are no free tracks available to store the migrated data or act as buffer tracks. However, unlike MOM, which simply moves interfered data to other top tracks to minimize data rewrites, Balloon-MS proactively uses buffer tracks to migrate hot data to the top tracks, effectively reducing the frequency of track rewrites. This key advantage is responsible for the superior write performance of Balloon-MS over MOM in various high-load scenarios.
5.2.2. Read Performance
Figure 9b and
Figure 10b illustrate the differences in read performance between the evaluated strategies at medium and high utilization. Notably, the read latency is close for all strategies regardless of the utilization level. For DTM, STC, and Seagate, which use a one-to-one track mapping mechanism, the logical data block is concentrated on a specific physical track. As a result, their differences in read performance are caused by their respective data placement or data shuffling behaviors.
Distinctly from the aforementioned competitors, MAGIC and Balloon employ approaches that redirect write interference data to the persistent buffer or buffer track to avoid track rewrites. While this approach may intuitively result in slightly lower read performance compared with other competitors, as the block-level persistent buffer may split some read requests into multiple subrequests, the actual impact is mitigated by the specific design of MAGIC and Balloon. MAGIC uses the region mechanism to preserve logical data block sequentiality whenever possible, sacrificing spatial locality only at high utilization rates to reduce track rewrite overhead. Similarly, Balloon uses strict data placement constraints to improve the spatial locality of the logical data blocks. For example, write interference data, other than data tracks, can only be placed on one of the buffer tracks or the WIF-PB to prevent scattering of adjacent logical data blocks. These constraints effectively reduce the seek overhead of read requests and prevent significant read performance degradation.
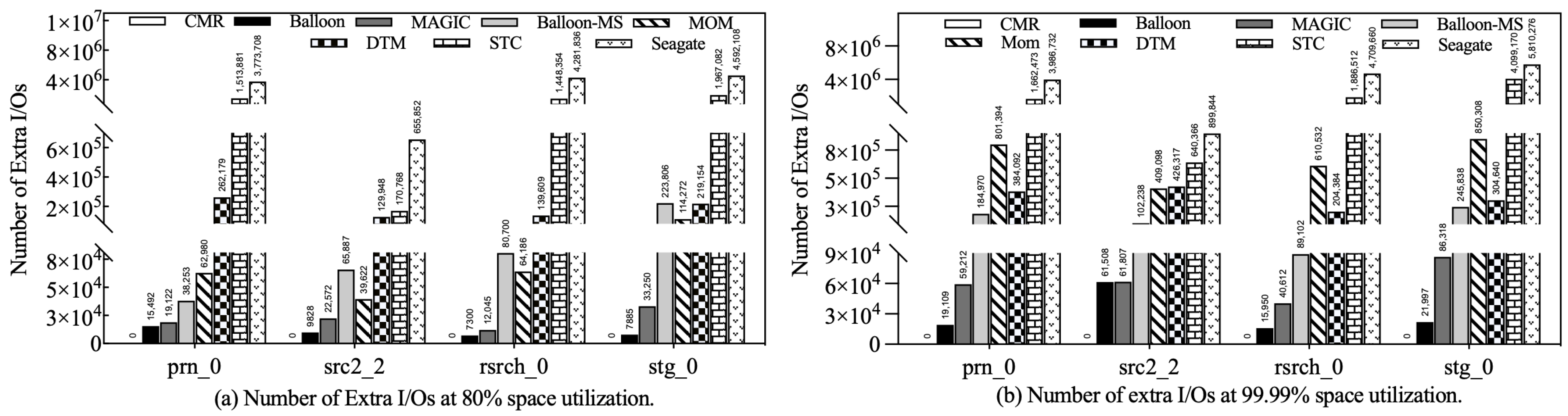
5.3. Number of Extra I/Os
Extra I/O refers to track-level I/O caused by RMW operations or data shuffling apart from the user request. Therefore, the number of extra I/Os is a critical factor affecting write performance.
Figure 11a,b shows the number of extra I/Os introduced by each strategy at medium and high utilization, respectively.
Seagate generates the highest number of extra I/Os in all scenarios because it only places incoming data on allocated tracks without using data shuffling. Conversely, other strategies significantly reduce the number of extra I/Os by periodically moving hot data to free-write regions, demonstrating the effectiveness of data shuffling. STC partially reduces track rewrites by placing hot tracks in the persistent buffer. However, the track-level data organization approach does not fully utilize the limited capacity of the persistent buffer, resulting in limited gains from data shuffling. On the other hand, DTM allows arbitrary hot and cold tracks to be swapped within zones and moved more bottom tracks to free-write regions, resulting in significantly fewer extra I/Os than STC. MOM uses hotness-aware data movement and performs well at moderate utilization. However, at high utilization, its extra I/Os increases dramatically because its data shuffling is limited to the top region, leaving hot data in the bottom track unmoved to the top region. Once the free tracks are exhausted, the expensive RMW operation is reactivated, resulting in a significant amount of extra I/O. Both Balloon-MS and MOM opportunistically use free top tracks to reduce track rewrite overhead. However, Balloon-MS goes a step further with its track merge/swap operation, which enables cost-free data shuffling using buffer tracks, effectively suppressing the introduction of extra I/O. Equipped with a block-level persistent buffer, MAGIC introduces significantly fewer extra I/Os than any other strategy except Balloon. In particular, Balloon has the lowest number of extra I/Os in all scenarios, which contributes significantly to its remarkable improvement in write performance.
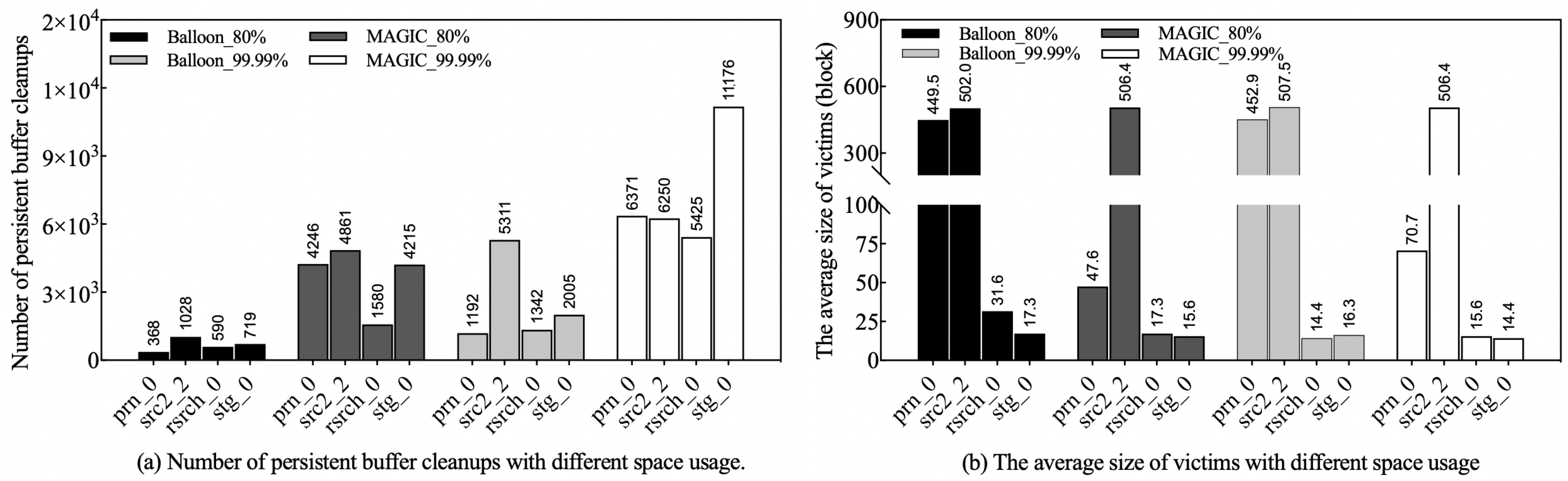
5.4. Persistent Buffer Cleanup Efficiency
Of all the strategies evaluated, Balloon and MAGIC stand out by introducing a persistent buffer to reduce the frequency of track rewrites. However, frequent cleanups degrade disk performance [
21,
22]. To further investigate the factors contributing to the performance gap between Balloon and MAGIC, this section focuses on evaluating the cleanup efficiency of their persistent buffers under varying space utilization and workloads. Therefore, the number of cleanups and the average size of the victims are used as performance metrics, which are commonly used in similar studies [
26,
27,
28,
29].
Figure 12a shows the buffer cleanup frequency of Balloon and MAGIC at different utilization and workloads. We can observe that both have lower cleanup frequencies at medium utilization than at high utilization. In particular, the cleanup frequency of Balloon is significantly lower than that of MAGIC in all scenarios. The reason for this is that Balloon allows only eligible data to enter the WIF-PB and swaps some buffer tracks from the top region directly to the bottom track, effectively increasing the efficiency of persistent buffer usage. In contrast, MAGIC indiscriminately directs write interference data to the persistent buffer, which results in frequent cleanups. Furthermore, Balloon takes proactive measures to retain hot data in the victims, preventing them from frequently moving in and out of the persistent buffer. This approach also contributes to a reduction in cleanup frequency. As another metric of cleanup efficiency, the average size of victims reflects the number of buffer blocks evicted per cleanup. The average size of the victims has a double meaning for evaluating the efficiency of each cleanup: first, the size of the victims somehow reflects the maximum spatial gain of the current cleanup operation; second, the size of the victims can reflect the effectiveness of Balloon in improving the spatial locality of the data. In general, the size of the victim is affected by a number of factors, including workload characteristics, hot data identification mechanisms, and data management policies.
Figure 12b shows the average size of victims evicted by Balloon and MAGIC for different utilization and workloads. Intuitively, the victim size of Balloon may not be as large as that of MAGIC, because it only redirects eligible data blocks to the persistent buffer. However, in most scenarios, the victim size of the Balloon is higher or close to that of MAGIC. Upon careful analysis, we find that most victims of the Balloon migrate from buffer tracks and tend to accumulate a significant number of data blocks before being swapped to the persistent buffer, potentially increasing the size of the victim. In a few cases, Balloon’s victims are smaller than MAGIC’s. The reason for the above result is that Balloon actively filters hot data from its victims, resulting in a reduction in victim size. In fact, Balloon reduces the cleaning frequency at the cost of reducing the size of the victims, which improves the efficiency of buffer cleaning in the long run. Therefore, the size of the victim is not a determining factor in the efficiency of the cleanup.
6. Conclusions
As an emerging magnetic recording technology, IMR can provide higher storage densities and much lower write penalties than SMR. However, with increasing space utilization, RMW operations are frequently triggered, which severely degrades disk performance. In this paper, we investigate how to improve the efficiency of the cooperative work between data placement and data shuffling to mitigate the performance jitter caused by track rewrites. To this end, an elastic data management strategy, the Balloon Transformation Layer, is proposed as a driver-level solution. Specifically, an adaptive write interference data placement policy is proposed to improve data placement efficiency by intelligently placing data in a track with low rewrite probability. Meanwhile, an on-demand data shuffling policy is designed. This policy can not only utilize the buffer tracks in the top region to perform low-cost data migration but also actively place the tracks with high update block coverage in the top region to reduce the write request seek latency. In addition, a write-interference-free persistent buffer is introduced that further reduces track rewrite frequency by elastically adjusting the persistent buffer admission constraint and selectively evicting data blocks. Evaluation results show that Balloon significantly reduces extra I/Os at medium and high space utilization compared with state-of-the-art studies, resulting in an average write performance improvement of up to 68.7% and 78.8%, respectively.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}