
Automatic Detection of Inconsistencies and Hierarchical Topic Classification for Open-Domain Chatbots

 , , , and
, , , and
Abstract
1. Introduction
2. Related Work
3. Architecture
3.1. Zero-Shot Topic Classification
3.2. Detection of Response Inconsistencies
4. Data Annotations
4.1. Zero-Shot Topic Classification
4.2. Detection of Response Inconsistencies
5. Results
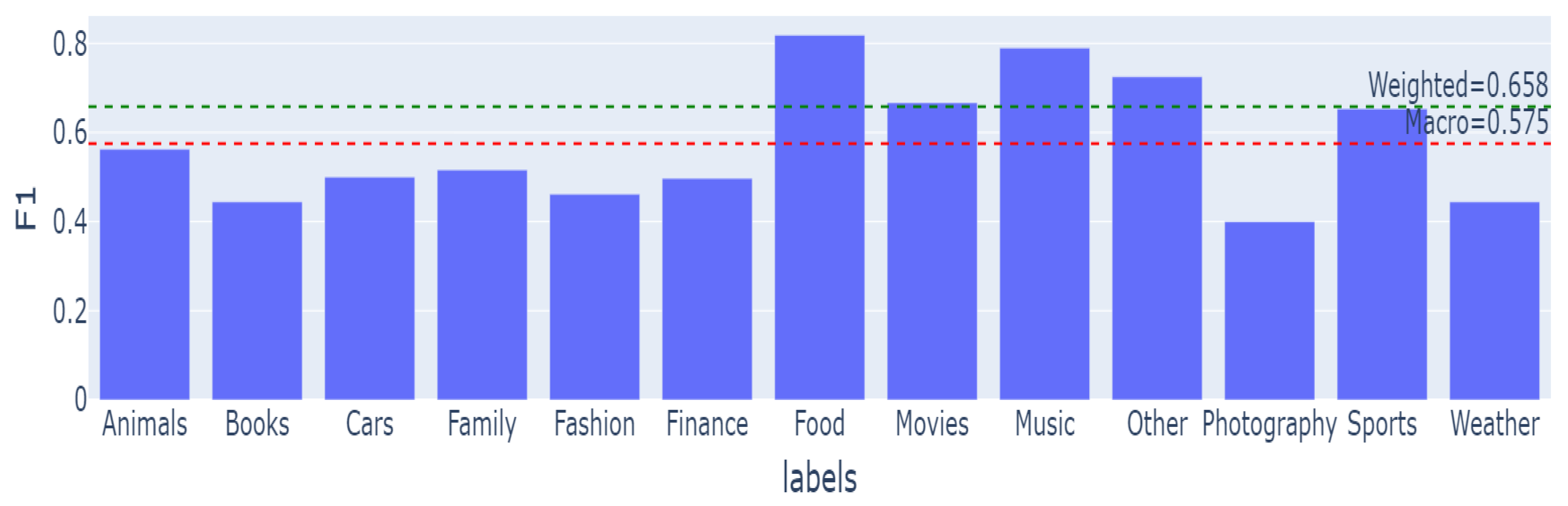
5.1. Zero-Shot Topic Classification
5.1.1. Original Results on DailyDialog—Topic Level
5.1.2. New Results on SGC5—Topic and Subtopic Level
- 2: BART topic is correct.
- 1: CoBot topic is correct.
- 0: Both BART and CoBot topics are correct.
- −1: Neither the BART nor the CoBot topics are correct.
- 1: The BART subtopic is correct.
- 0: The BART subtopic is not correct.
5.1.3. New Results on DailyDialog—Topic and Subtopic Level
5.2. Detection of Response Inconsistencies
5.3. Latency
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Superhero Topic Questions | GPT-4 Model Responses |
|---|---|
| Original: Who is your favorite superhero? | My favorite superhero is definitely Spider-Man because of his relatable struggles and character development through the years. |
| Paraphrase: Which superhero do you hold as your favorite? | I really enjoy Spider-Man because of his relatable struggles and witty humor, plus the iconic red and blue costume. |
| Paraphrase: What superhero character do you admire the most? | I personally admire Spider-Man the most because of his relatability and sense of responsibility towards his community. |
| Paraphrase: Who is the superhero you resonate with the most? | I really resonate with Spider-Man because he’s relatable, deals with everyday struggles, and always tries to do what’s right. |
| Paraphrase: What is your preferred superhero of all time? | My all-time favorite superhero is Spider-Man because of his relatability and the way he balances his personal life with heroism. |
| Paraphrase: Which fictional hero holds a special place in your heart? | Harry Potter has a special place in my heart because of his bravery, growth, and the magical world he introduced me to. |
| Paraphrase: Who is the superhero that you find most inspiring? | My all-time favorite superhero is Spider-Man because he teaches us the importance of responsibility and resilience in tough situations. |
| Paraphrase: What superhero character do you consider your favorite? | I absolutely love Spider-Man because of his relatability, witty humor, and the way he deals with everyday challenges. |
| Average Annotation: 2.0 | Average Prediction: 3.0 |
| Vacation Topic Questions | GPT-4 Model Responses |
|---|---|
| Original: What is your dream vacation destination? | My dream vacation destination would be exploring the beautiful landscapes of New Zealand and experiencing its rich culture. |
| Paraphrase: Where is your ultimate dream vacation spot? | My ultimate dream vacation spot would be Bora Bora, relaxing on a beautiful overwater bungalow and enjoying the crystal-clear water. |
| Paraphrase: What destination do you fantasize about for a perfect vacation? | I dream about relaxing on a beautiful tropical beach like Bali or Maldives, with warm turquoise water and palm trees. |
| Paraphrase: Which place would be your dream getaway location? | My dream getaway location would be the Amalfi Coast in Italy, with its beautiful scenery, charming towns, and delicious cuisine. |
| Paraphrase: If you could choose any place for a dream vacation, where would it be? | I’d absolutely love to visit New Zealand for a dream vacation, immersing myself in its breathtaking landscapes and rich culture. |
| Paraphrase: What is the vacation destination you yearn to visit the most? | I’ve always dreamed of visiting the Maldives, spending my days relaxing on the sandy beaches and swimming in crystal-clear waters. |
| Paraphrase: Where would you love to go on your dream vacation? | I would love to go to Bora Bora for my dream vacation, staying in an overwater bungalow and enjoying the beautiful beaches! |
| Paraphrase: Which location tops your list for an ideal vacation spot? | I absolutely love the idea of vacationing in Santorini, Greece, with its beautiful beaches, stunning sunsets, and unique architecture. |
| Average Annotation: 5.0 | Average Prediction: 4.0 |
| Unwind Topic Questions | GPT-4 Model Responses |
|---|---|
| Original: How do you like to unwind after a long day? | I love to relax with a good book, watch my favorite shows on Netflix, or enjoy a soothing cup of tea. |
| Paraphrase: What is your preferred method of relaxation after a tiring day? | I really enjoy winding down with a good book, cozying up on the couch, and sipping on some calming chamomile tea. |
| Paraphrase: How do you like to de-stress and unwind following a long day? | I love curling up with a good book, watching a movie, or taking a bubble bath to de-stress after a long day. |
| Paraphrase: What activities do you find most rejuvenating after a busy day? | After a busy day, I find relaxing with a good book, watching a movie, or going for a walk outside to be most rejuvenating. |
| Paraphrase: How do you prefer to unwind and recharge after a hectic day? | I love curling up with a good book, taking a warm bath, or watching my favorite TV show to relax after a long day! |
| Paraphrase: What is your go-to way of unwinding after a long and exhausting day? | I love taking a warm bath, listening to soothing music, and practicing mindfulness meditation to unwind after a tough day. |
| Paraphrase: What helps you relax and find peace of mind after a demanding day? | I love taking a warm bath, listening to soothing music, and practicing mindfulness meditation to unwind after a tough day. |
| Paraphrase: How do you like to wind down and find tranquility at the end of a long day? | I like to relax by reading a good book, listening to soothing music, or taking a warm bath to find tranquility. |
| Average Annotation: 5.0 | Average Prediction: 4.0 |
References
- Shuster, K.; Xu, J.; Komeili, M.; Ju, D.; Smith, E.M.; Roller, S.; Ung, M.; Chen, M.; Arora, K.; Lane, J.; et al. BlenderBot 3: A deployed conversational agent that continually learns to responsibly engage. arXiv 2022, arXiv:cs.CL/2208.03188. [Google Scholar]
- Thoppilan, R.; Freitas, D.D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. LaMDA: Language Models for Dialog Applications. arXiv 2022, arXiv:cs.CL/2201.08239. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:cs.CL/2303.08774. [Google Scholar]
- Rodríguez-Cantelar, M.; de la Cal, D.; Estecha, M.; Gutiérrez, A.G.; Martín, D.; Milara, N.R.N.; Jiménez, R.M.; D’Haro, L.F. Genuine2: An Open Domain Chatbot Based on Generative Models. In Alexa Prize SocialBot Grand Challenge 4 Proceedings; 2021; Available online: https://www.amazon.science/alexa-prize/proceedings/genuine2-an-open-domain-chatbot-based-on-generative-models (accessed on 14 July 2023).
- Hakkani-Tür, D. Alexa Prize Socialbot Grand Challenge Year IV. In Alexa Prize SocialBot Grand Challenge 4 Proceedings; 2021; Available online: https://www.amazon.science/alexa-prize/proceedings/alexa-prize-socialbot-grand-challenge-year-iv (accessed on 14 July 2023).
- Hu, S.; Liu, Y.; Gottardi, A.; Hedayatnia, B.; Khatri, A.; Chadha, A.; Chen, Q.; Rajan, P.; Binici, A.; Somani, V.; et al. Further advances in Open Domain Dialog Systems in the Fourth Alexa Prize SocialBot Grand Challenge. In Alexa Prize SocialBot Grand Challenge 4 Proceedings; 2021; Available online: https://www.amazon.science/publications/further-advances-in-open-domain-dialog-systems-in-the-fourth-alexa-prize-socialbot-grand-challenge (accessed on 14 July 2023).
- Fan, A.; Lewis, M.; Dauphin, Y. Hierarchical Neural Story Generation. arXiv 2018, arXiv:cs.CL/1805.04833. [Google Scholar]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. arXiv 2020, arXiv:cs.CL/1904.09751. [Google Scholar]
- Maynez, J.; Narayan, S.; Bohnet, B.; McDonald, R. On Faithfulness and Factuality in Abstractive Summarization. arXiv 2020, arXiv:cs.CL/2005.00661. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–Based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2021, 54, 3. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? In Proceedings of the Chinese Computational Linguistics; Sun, M., Huang, X., Ji, H., Liu, Z., Liu, Y., Eds.; Springer International Publishing: Cham, Swizerland, 2019; pp. 194–206. [Google Scholar]
- Guo, Z.; Zhu, L.; Han, L. Research on Short Text Classification Based on RoBERTa-TextRCNN. In Proceedings of the 2021 International Conference on Computer Information Science and Artificial Intelligence (CISAI), Kunming, China, 17–19 September 2021; pp. 845–849. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Vancouver, BC, Canada, 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference. arXiv 2021, arXiv:cs.CL/2001.07676. [Google Scholar]
- Pourpanah, F.; Abdar, M.; Luo, Y.; Zhou, X.; Wang, R.; Lim, C.P.; Wang, X.Z.; Wu, Q.M.J. A Review of Generalized Zero-Shot Learning Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4051–4070. [Google Scholar] [CrossRef]
- Tavares, D. Zero-Shot Generalization of Multimodal Dialogue Agents. In Proceedings of the 30th ACM International Conference on Multimedia; Association for Computing Machinery, MM’22, New York, NY, USA, 10–14 October 2022; pp. 6935–6939. [Google Scholar] [CrossRef]
- Krügel, S.; Ostermaier, A.; Uhl, M. ChatGPT’s inconsistent moral advice influences users’ judgment. Sci. Rep. 2023, 13, 4569. [Google Scholar] [CrossRef]
- Alkaissi, H.; McFarlane, S.I. Artificial hallucinations in ChatGPT: Implications in scientific writing. Cureus 2023, 15, e35179. [Google Scholar] [CrossRef]
- Dziri, N.; Milton, S.; Yu, M.; Zaiane, O.; Reddy, S. On the Origin of Hallucinations in Conversational Models: Is it the Datasets or the Models? arXiv 2022, arXiv:cs.CL/2204.07931. [Google Scholar]
- Mehri, S.; Choi, J.; D’Haro, L.F.; Deriu, J.; Eskenazi, M.; Gasic, M.; Georgila, K.; Hakkani-Tur, D.; Li, Z.; Rieser, V.; et al. Report from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges. arXiv 2022, arXiv:cs.CL/2203.10012. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Liu, C.W.; Lowe, R.; Serban, I.; Noseworthy, M.; Charlin, L.; Pineau, J. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 2122–2132. [Google Scholar] [CrossRef]
- Lowe, R.; Noseworthy, M.; Serban, I.V.; Angelard-Gontier, N.; Bengio, Y.; Pineau, J. Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1116–1126. [Google Scholar] [CrossRef]
- Tao, C.; Mou, L.; Zhao, D.; Yan, R. RUBER: An Unsupervised Method for Automatic Evaluation of Open-Domain Dialog Systems. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Ghazarian, S.; Wei, J.; Galstyan, A.; Peng, N. Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings. In Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 82–89. [Google Scholar] [CrossRef]
- Huang, L.; Ye, Z.; Qin, J.; Lin, L.; Liang, X. GRADE: Automatic Graph-Enhanced Coherence Metric for Evaluating Open-Domain Dialogue Systems. arXiv 2020, arXiv:cs.CL/2010.03994. [Google Scholar]
- Dziri, N.; Kamalloo, E.; Mathewson, K.W.; Zaiane, O. Evaluating Coherence in Dialogue Systems using Entailment. arXiv 2020, arXiv:cs.CL/1904.03371. [Google Scholar]
- Sun, W.; Shi, Z.; Gao, S.; Ren, P.; de Rijke, M.; Ren, Z. Contrastive Learning Reduces Hallucination in Conversations. Proc. AAAI Conf. Artif. Intell. 2023, 37, 13618–13626. [Google Scholar] [CrossRef]
- Prats, J.M.; Estecha-Garitagoitia, M.; Rodríguez-Cantelar, M.; D’Haro, L.F. Automatic Detection of Inconsistencies in Open-Domain Chatbots. In Proceedings of the Proceeding IberSPEECH 2022, Incheon, Republic of Korea, 18–22 September 2022; pp. 116–120. [Google Scholar] [CrossRef]
- Yin, W.; Hay, J.; Roth, D. Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 3914–3923. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:cs.CL/2203.05794. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. arXiv 2019, arXiv:cs.CL/1908.10084. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:stat.ML/1802.03426. [Google Scholar]
- Campello, R.J.; Moulavi, D.; Zimek, A.; Sander, J. Hierarchical density estimates for data clustering, visualization, and outlier detection. ACM Trans. Knowl. Discov. Data (TKDD) 2015, 10, 1–51. [Google Scholar] [CrossRef]
- Wolf, T.; Sanh, V.; Chaumond, J.; Delangue, C. TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents. arXiv 2019, arXiv:cs.CL/1901.08149. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Guided Open Vocabulary Image Captioning with Constrained Beam Search. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 936–945. [Google Scholar] [CrossRef]
- Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; Niu, S. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; pp. 986–995. [Google Scholar]
- Khatri, C.; Hedayatnia, B.; Venkatesh, A.; Nunn, J.; Pan, Y.; Liu, Q.; Song, H.; Gottardi, A.; Kwatra, S.; Pancholi, S.; et al. Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize. arXiv 2018, arXiv:cs.CL/1812.10757. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-Enhanced Bert with Disentangled Attention. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:cs.CL/1910.13461. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2020, arXiv:cs.CL/1910.01108. [Google Scholar]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation. arXiv 2020, arXiv:cs.CL/1911.00536. [Google Scholar]
- Roller, S.; Dinan, E.; Goyal, N.; Ju, D.; Williamson, M.; Liu, Y.; Xu, J.; Ott, M.; Shuster, K.; Smith, E.M.; et al. Recipes for Building an Open-Domain Chatbot. arXiv 2020, arXiv:cs.CL/2004.13637. [Google Scholar]
- Xu, J.; Szlam, A.; Weston, J. Beyond Goldfish Memory: Long-Term Open-Domain Conversation. arXiv 2021, arXiv:cs.CL/2107.07567. [Google Scholar]
- Komeili, M.; Shuster, K.; Weston, J. Internet-Augmented Dialogue Generation. arXiv 2021, arXiv:cs.AI/2107.07566. [Google Scholar]
- Shuster, K.; Komeili, M.; Adolphs, L.; Roller, S.; Szlam, A.; Weston, J. Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion. arXiv 2022, arXiv:cs.CL/2203.13224. [Google Scholar]
- Zeng, H. Measuring Massive Multitask Chinese Understanding. arXiv 2023, arXiv:cs.CL/2304.12986. [Google Scholar]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv 2022, arXiv:cs.CL/2103.10360. [Google Scholar]
- Keskar, N.S.; McCann, B.; Varshney, L.R.; Xiong, C.; Socher, R. CTRL: A Conditional Transformer Language Model for Controllable Generation. arXiv 2019, arXiv:cs.CL/1909.05858. [Google Scholar]
- Zhang, C.; Sedoc, J.; D’Haro, L.F.; Banchs, R.; Rudnicky, A. Automatic Evaluation and Moderation of Open-domain Dialogue Systems. arXiv 2021, arXiv:cs.CL/2111.02110. [Google Scholar]
- Zhang, C.; D’Haro, L.F.; Friedrichs, T.; Li, H. MDD-Eval: Self-Training on Augmented Data for Multi-Domain Dialogue Evaluation. Proc. AAAI Conf. Artif. Intell. 2022, 36, 11657–11666. [Google Scholar] [CrossRef]







| Proposed Topics List | |
|---|---|
| Topics | Subtopics |
| animals | cats, dogs, pets. |
| art | ballet, cinema, museum, painting, theater. |
| books | author, genre, Harry Potter, plot, title. |
| education | history, mark, professor, school, subject, university. |
| family | parents, friends, relatives, marriage, children. |
| fashion | catwalk, clothes, design, dress, footwear, jewel, model. |
| finance | benefits, bitcoins, buy, finances, investment, sell, stock market, taxes. |
| food | drinks, fish, healthy, meal, meat, vegetables, dessert. |
| movies | actor, director, genre, plot, synopsis, title. |
| music | band, dance, genre, lyrics, rhythm, singer, song. |
| news | exclusive, fake news, interview, press, trending. |
| photography | camera, lens, light, optics, zoom. |
| science | math, nature, physics, robots, space. |
| sports | baseball, basketball, coach, exercise, football, player, soccer, tennis. |
| vehicle | bike, boat, car, failure, fuel, parts, plane, public transport, speed. |
| video games | arcade, computer, console, Nintendo, PlayStation, Xbox. |
| weather | cloudy, cold, hot, raining, sunny. |
| other | |
| CoBot Topics List | |||
|---|---|---|---|
| 1. books | 2. general | 3. interactive | 4. inappropriate |
| 5. movies | 6. music | 7. phatic | 8. politics |
| 9. science | 10. sports | 11. other | |
| Question | Paraphrases |
|---|---|
| What is your favorite sport? | Which is the sport you like the most? |
| My favorite sport is basketball, and yours? | |
| What kind of sport do you like? | |
| What is your favorite book? | What is the title of your favorite book? |
| Which book you always like to read? | |
| Hi!! I like reading, which book is your favorite one? | |
| What is your job? | What do you do for a living? |
| What do you do for work? |
| Question | Paraphrases |
|---|---|
| What is your favorite hobby? | What leisure activity do you enjoy the most? |
| Which pastime brings you the most satisfaction? | |
| What is the hobby that you find most appealing? | |
| Who is your favorite superhero? | What superhero character do you admire the most? |
| What is your preferred superhero of all time? | |
| Which fictional hero holds a special place in your heart? | |
| What’s your favorite type of cuisine? | Which cuisine do you find most appealing? |
| Which type of cooking brings you the greatest delight? | |
| What style of food do you consider your favorite? |
| Model | Accuracy (%) | F1 Score | Precision | Recall |
|---|---|---|---|---|
| cross-encoder/nli-deberta-v3-base | 10.08 | 0.08 | 0.22 | 0.15 |
| cross-encoder/nli-deberta-v3-large | 7.55 | 0.06 | 0.18 | 0.15 |
| facebook/bart-large-mnli | 25.98 | 0.26 | 0.30 | 0.29 |
| typeform/distilbert-base-uncased-mnli | 0.83 | 0.01 | 0.09 | 0.02 |
| Scores | Topic Level | Subtopic Level | ||
|---|---|---|---|---|
| Hits | Accuracy (%) | Hits | Accuracy (%) | |
| 2 | 82/200 | 41 | - | |
| 1 | 3/200 | 1.5 | 143/200 | 71.5 |
| 0 | 101/200 | 50.5 | 57/200 | 28.5 |
| −1 | 14/200 | 7 | - | |
| Sentence | Toipic | Subtopic | |
|---|---|---|---|
| Human1: | I know. I’m starting a new diet the day after tomorrow. | food | healthy |
| Human2: | It’s about time. | ||
| Human1: | I have something important to do, can you fast the speed? | vehicle | speed |
| Human2: | Sure, I’ll try my best. Here we are. | ||
| Human1: | Do you know this song? | music | song |
| Human2: | Yes, I like it very much. | ||
| Human1: | Where are you going to find one? | other | — |
| Human2: | I have no idea. | ||
| Human1: | I wish to buy a diamond ring. | finance | investment |
| Human2: | How many carats diamond do you want? | ||
| Human1: | It’s a kitty. | animals | pets |
| Human2: | Oh, Jim. I told you. No pets. It’ll make a mess of this house. | ||
| Model | Accuracy (%) | F1 Score | Precision | Recall |
|---|---|---|---|---|
| Topics | 57.90 | 0.45 | 0.43 | 0.53 |
| Subtopics | 88.95 | 0.67 | 0.70 | 0.68 |
| Chatbot | Avg. No. Responses | Av. Predicted | MSE |
|---|---|---|---|
| BlenderBot2 (400M) | 4.0 ± 1.6 | 4.6 ± 2.2 | 2.4 |
| BlenderBot2 (2.7B) | 3.7 ± 1.6 | 3.3 ± 1.9 | 2.8 |
| DialoGPT-large | 4.3 ± 2.1 | 3.1 ± 2.0 | 5.4 |
| Seeker | 4.0 ± 1.7 | 4.0 ± 1.7 | 3.1 |
| Overall | 4.0 ± 1.7 | 3.8 ± 2.0 | 3.4 |
| Chatbot | Avg. No. Responses | Av. Predicted | MSE |
|---|---|---|---|
| BlenderBot3 (3B) | 3.7 ± 1.2 | 2.5 ± 0.7 | 2.9 |
| ChatGLM | 4.6 ± 1.4 | 3.8 ± 0.8 | 3.2 |
| DialoGPT-large | 5.1 ± 1.5 | 3.3 ± 0.9 | 5.0 |
| GPT-4 | 3.4 ± 1.1 | 3.5 ± 0.8 | 1.8 |
| Overall | 4.2 ± 1.3 | 3.3 ± 0.8 | 3.3 |
| Chatbot | Avg. No. Responses | Av. Predicted | MSE |
|---|---|---|---|
| BlenderBot3 (3B) | 3.7 ± 1.2 | 2.5 ± 0.8 | 3.5 |
| ChatGLM | 4.6 ± 1.4 | 3.7 ± 0.8 | 3.1 |
| DialoGPT-large | 5.1 ± 1.5 | 3.4 ± 1.0 | 4.7 |
| GPT-4 | 3.4 ± 1.1 | 3.5 ± 0.7 | 1.6 |
| Overall | 4.2 ± 1.3 | 3.3 ± 0.9 | 3.2 |
| BlenderBot3 | ChatGLM | DialoGPT-large | GPT-4 | |||||
|---|---|---|---|---|---|---|---|---|
| Type of Question | Human | Pred. | Human | Pred. | Human | Pred. | Human | Pred. |
| Vacation | 3.0 | 2.0 | 3.0 | 3.0 | 4.0 | 2.0 | 2.0 | 3.0 |
| Superhero | 2.0 | 2.0 | 5.0 | 5.0 | 5.0 | 4.0 | 5.0 | 4.0 |
| Unwind | 5.0 | 3.0 | 5.0 | 4.0 | 6.0 | 4.0 | 3.0 | 2.0 |
| Dataset | #Labels | Average Time (ms) |
|---|---|---|
| SGC5 | 11 | 27 |
| DailyDialog Topic | 18 | 39 |
| DailyDialog Subtopic | 6 | 19 |
| Dataset | Average Time (s) |
|---|---|
| BlenderBot3 (3B) | 4.93 ± 0.05 |
| ChatGLM | 4.29 ± 0.03 |
| DialoGPT-large | 4.41 ± 0.08 |
| GPT-4 | 4.40 ± 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Cantelar, M.; Estecha-Garitagoitia, M.; D’Haro, L.F.; Matía, F.; Córdoba, R. Automatic Detection of Inconsistencies and Hierarchical Topic Classification for Open-Domain Chatbots. Appl. Sci. 2023, 13, 9055. https://doi.org/10.3390/app13169055
Rodríguez-Cantelar M, Estecha-Garitagoitia M, D’Haro LF, Matía F, Córdoba R. Automatic Detection of Inconsistencies and Hierarchical Topic Classification for Open-Domain Chatbots. Applied Sciences. 2023; 13(16):9055. https://doi.org/10.3390/app13169055
Chicago/Turabian StyleRodríguez-Cantelar, Mario, Marcos Estecha-Garitagoitia, Luis Fernando D’Haro, Fernando Matía, and Ricardo Córdoba. 2023. "Automatic Detection of Inconsistencies and Hierarchical Topic Classification for Open-Domain Chatbots" Applied Sciences 13, no. 16: 9055. https://doi.org/10.3390/app13169055
APA StyleRodríguez-Cantelar, M., Estecha-Garitagoitia, M., D’Haro, L. F., Matía, F., & Córdoba, R. (2023). Automatic Detection of Inconsistencies and Hierarchical Topic Classification for Open-Domain Chatbots. Applied Sciences, 13(16), 9055. https://doi.org/10.3390/app13169055