
Deformation Energy Estimation of Cherry Tomato Based on Some Engineering Parameters Using Machine-Learning Algorithms



Abstract
1. Introduction
2. Materials and Methods
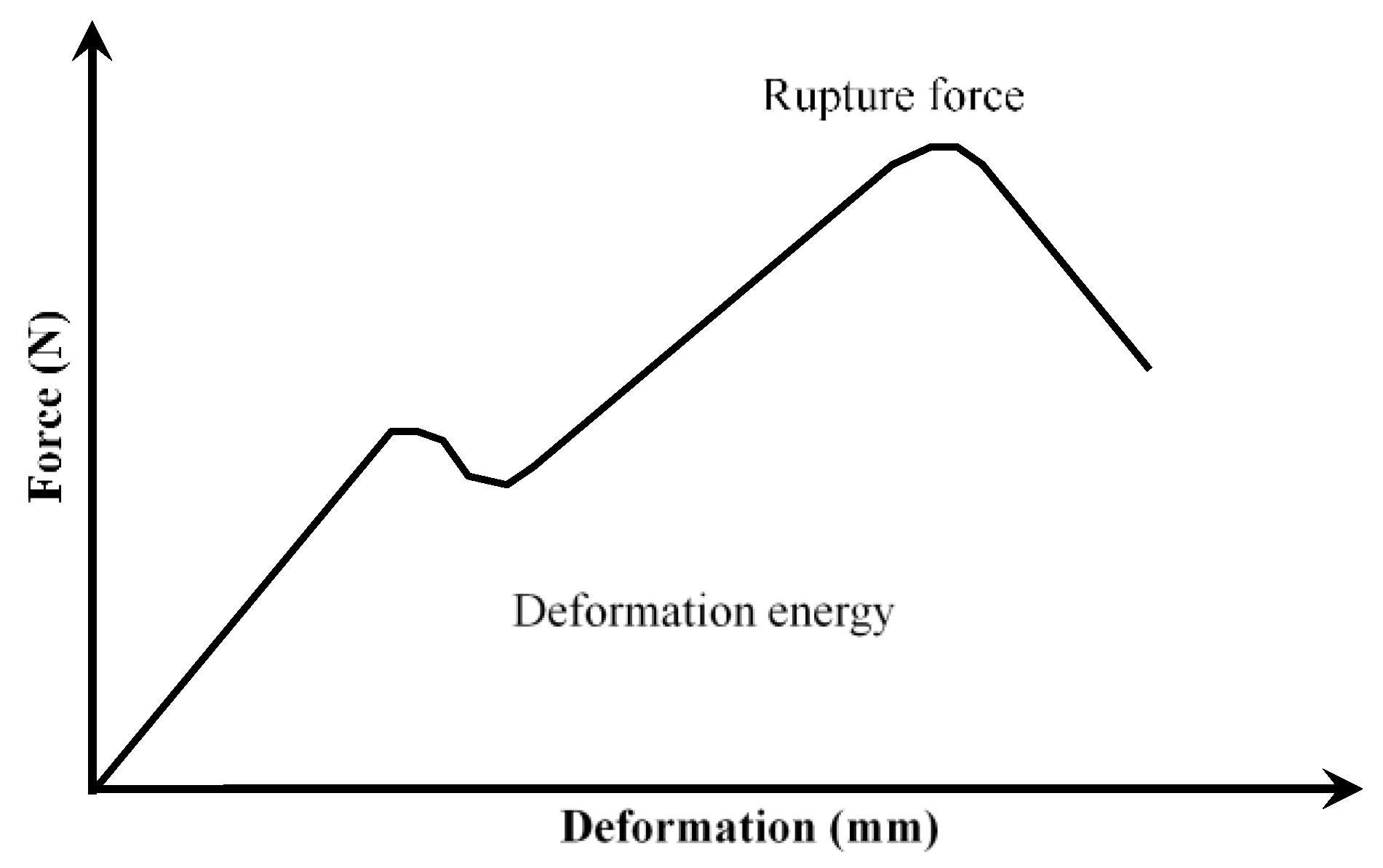
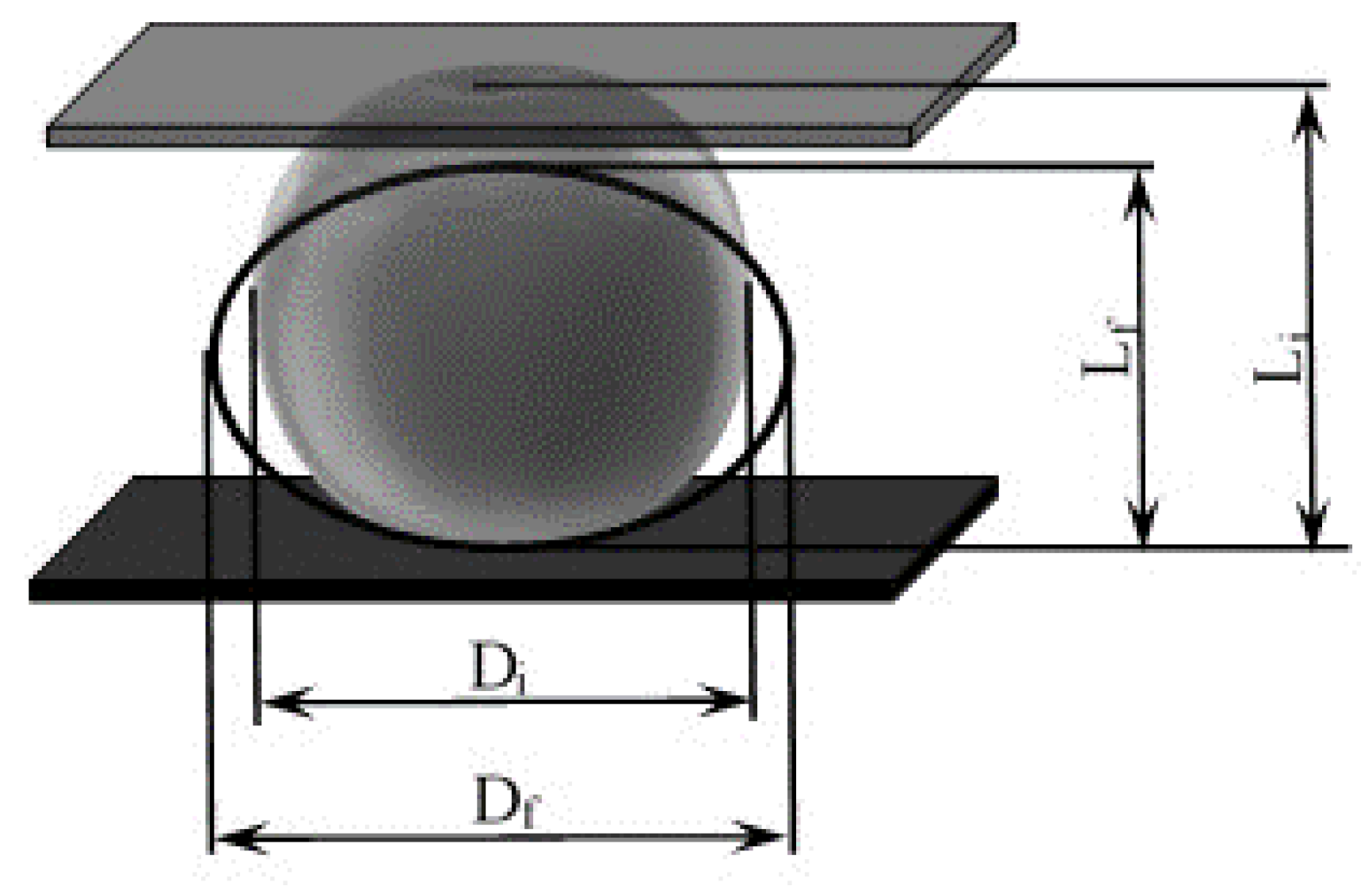
2.1. Data Set
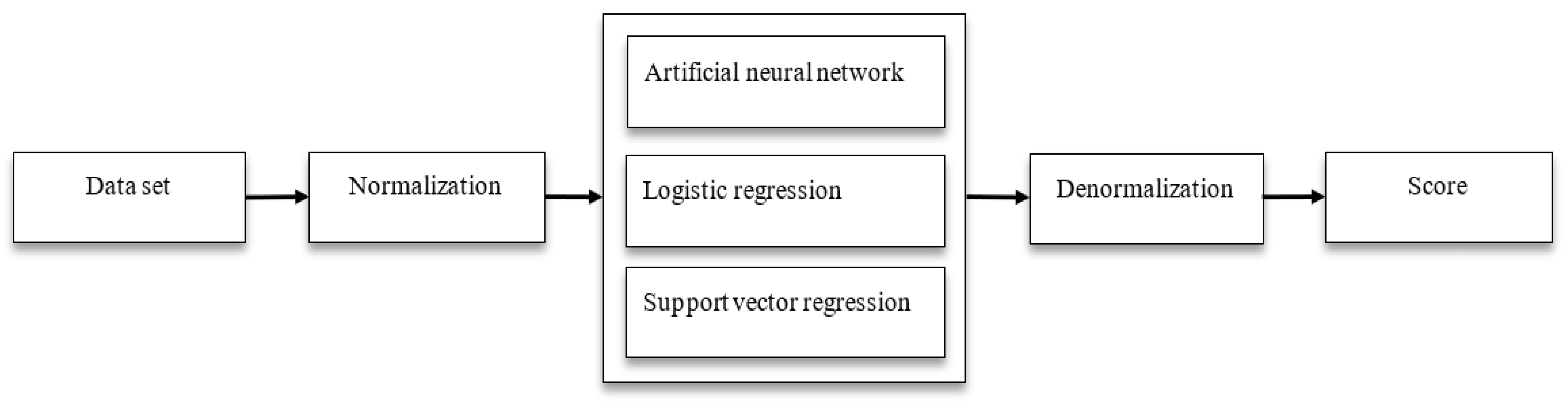
2.2. Machine Learning Methods
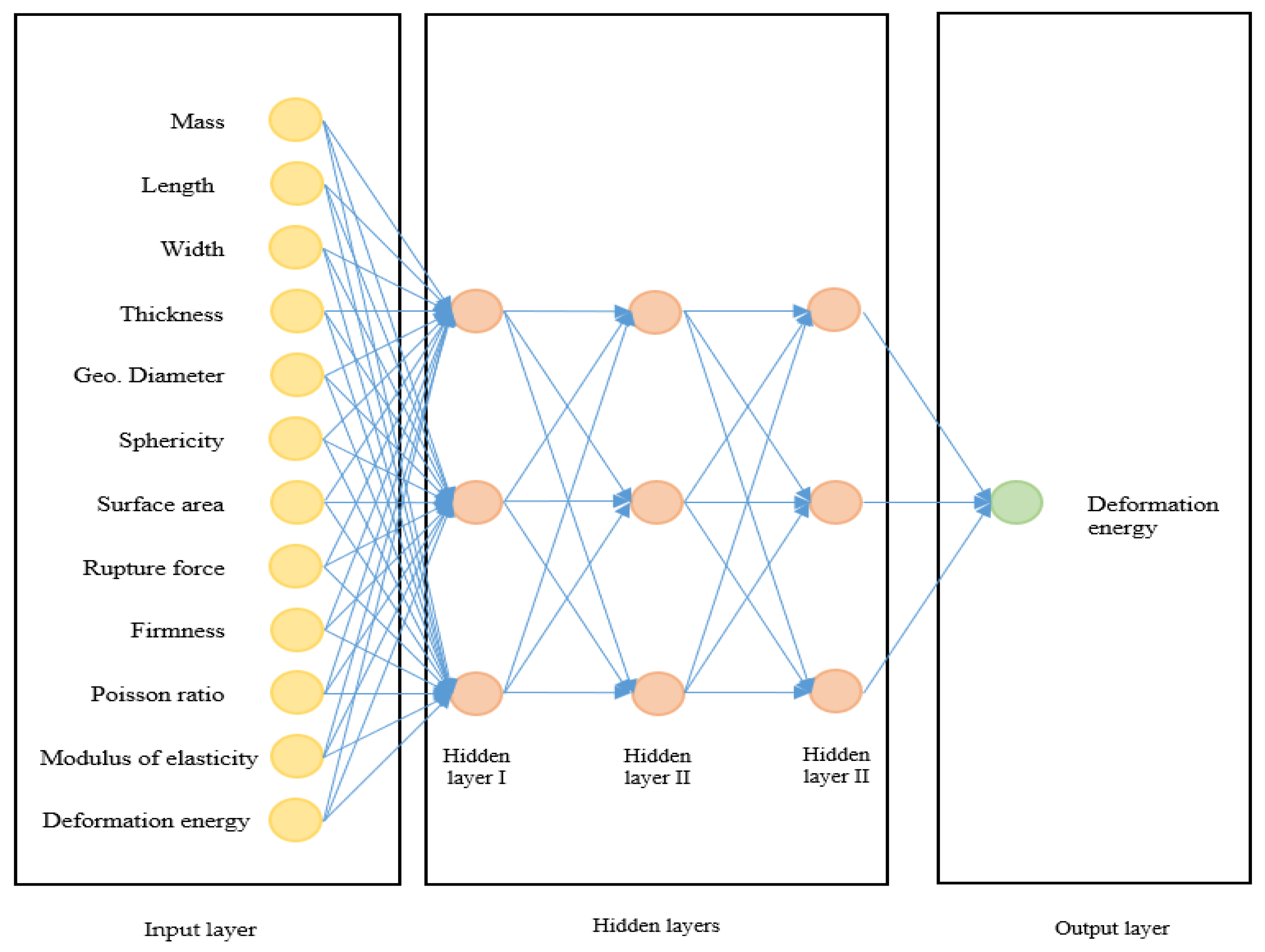
2.2.1. Artificial Neural Networks
2.2.2. Logistic Regression
2.2.3. Decision Trees Regression
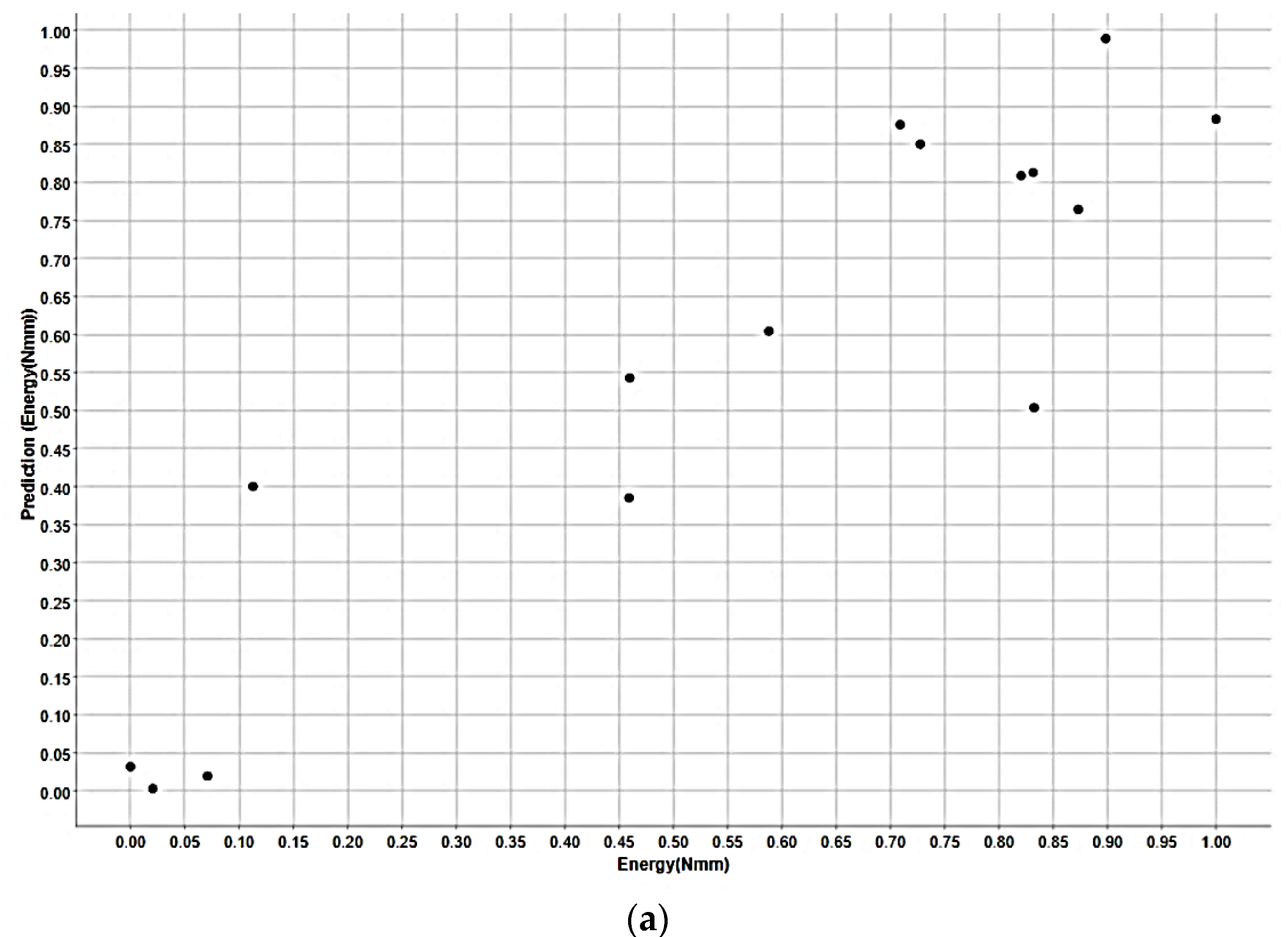
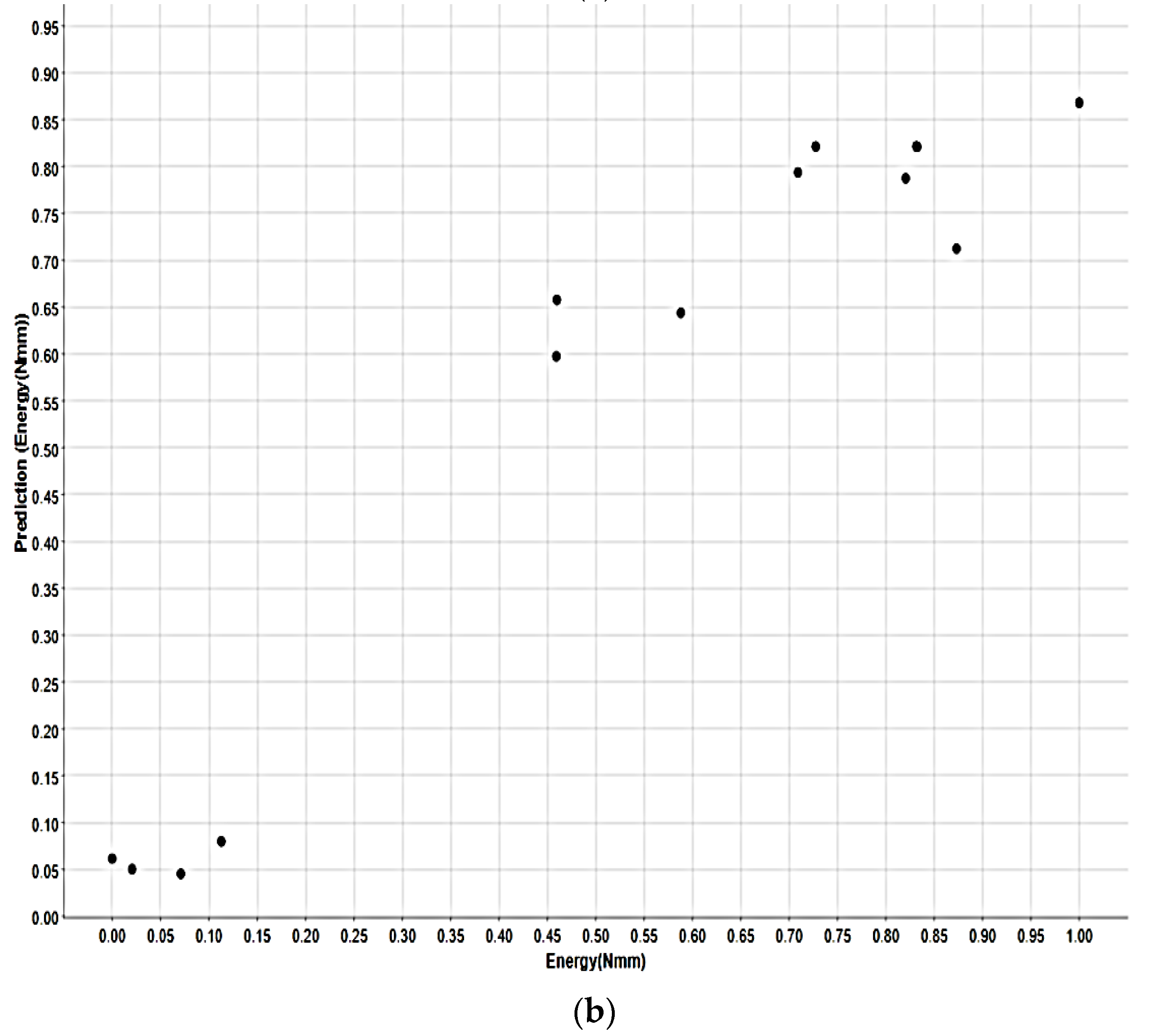
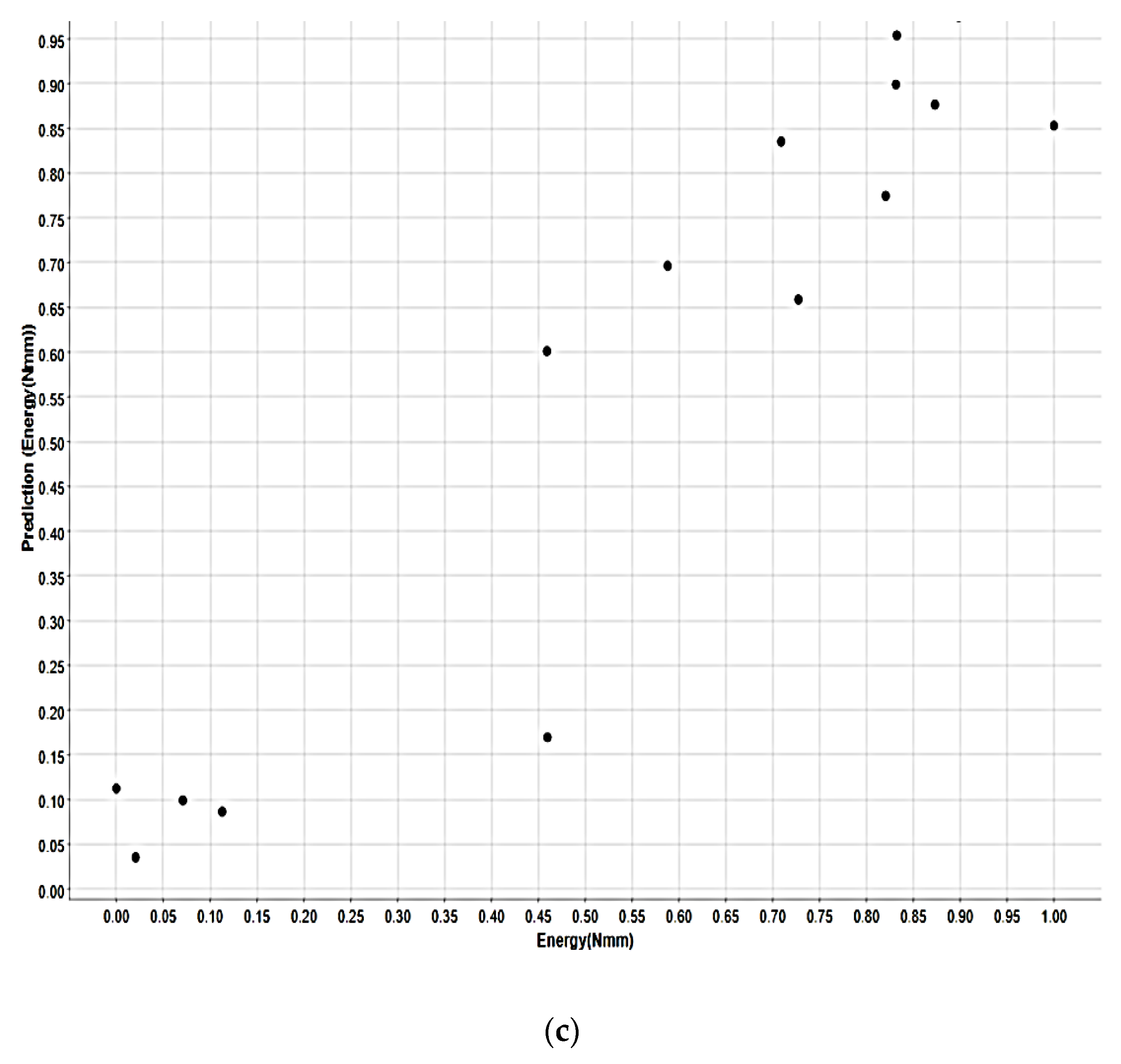
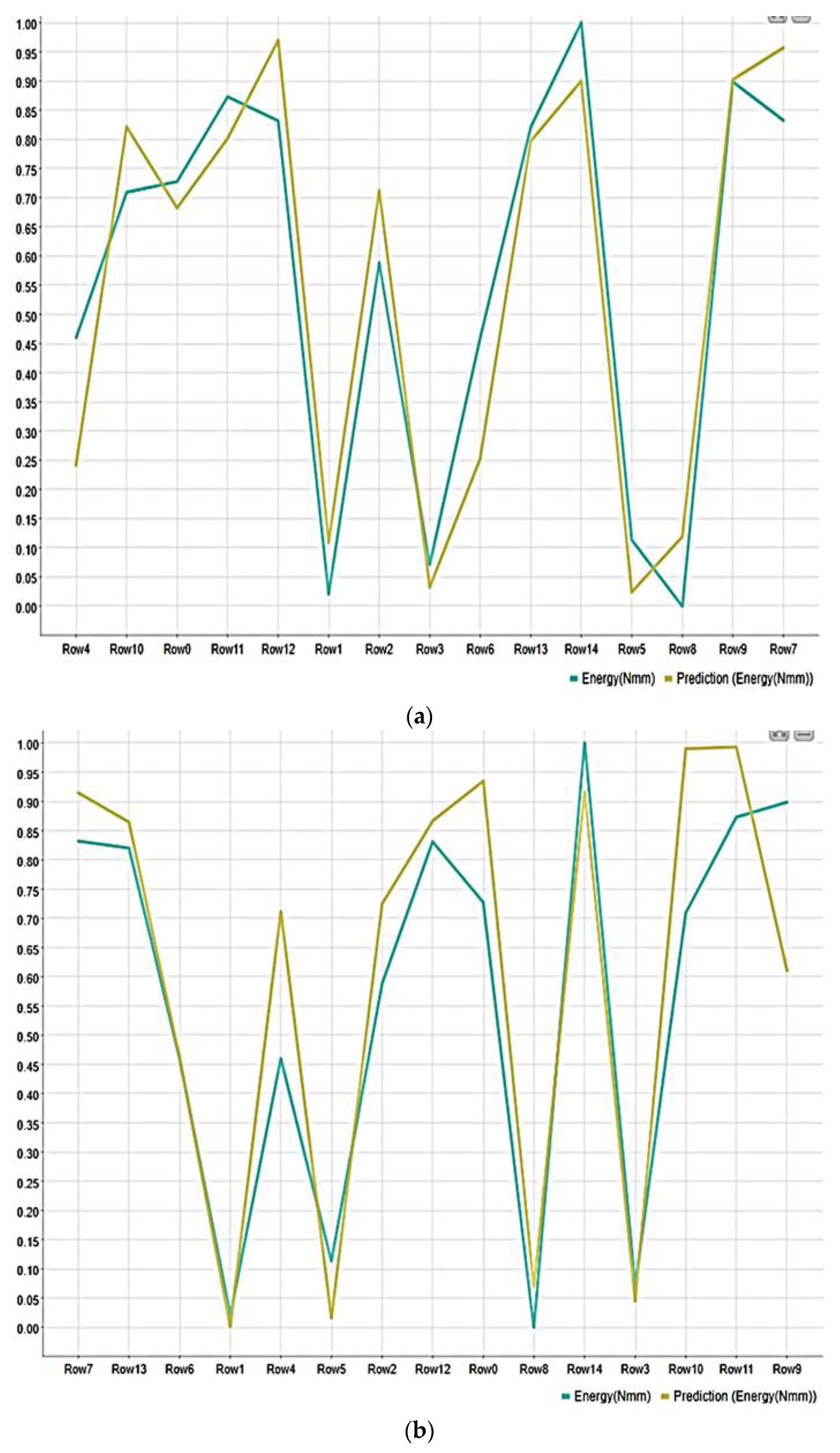
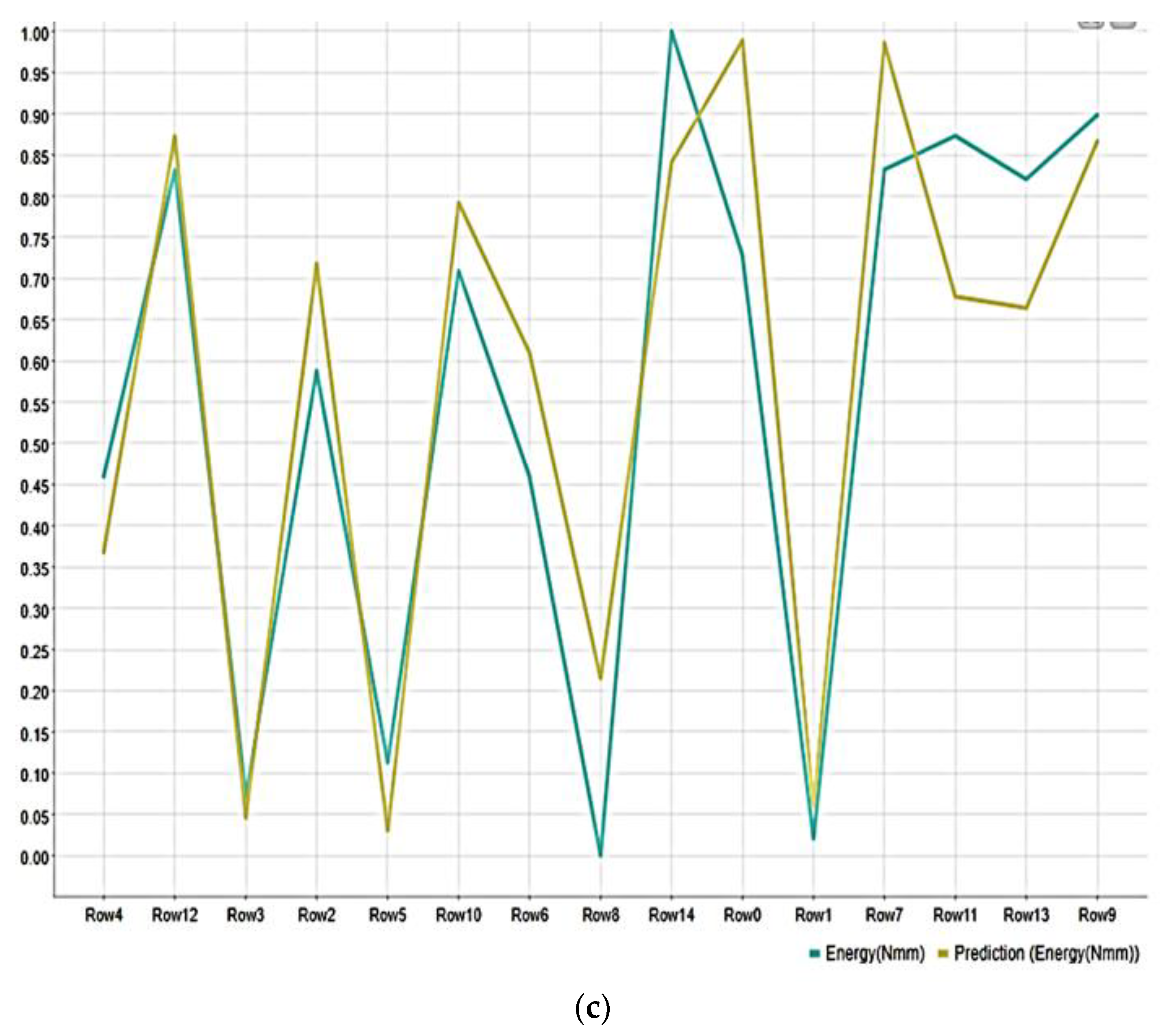
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Safitri, Y.; Bintoro, N.; Karyadi, J.N.W. Effect of maturity level and fruit size on mechanical properties of tomato fruit (Solanum lycopersicum). IOP Conf. Ser. Earth Environ. Sci. 2022, 1083, 012063. [Google Scholar] [CrossRef]
- Hussein, Z.; Fawole, O.A.; Opara, U.L. Harvest and postharvest factors affecting bruise damage of fresh fruits. Hortic. Plant J. 2020, 6, 1–13. [Google Scholar] [CrossRef]
- Kabas, O.; Ozmerzi, A. Determining the mechanical properties of cherry tomato varieties for handling. J. Texture Stud. 2008, 39, 199–209. [Google Scholar] [CrossRef]
- Akbarnejad, A.; Azadbakht, M.; Asghari, A. Studies of the selected mechanical properties of banana (Cavendish Var.). Int. J. Fruit Sci. 2017, 17, 93–101. [Google Scholar] [CrossRef]
- Stopa, R.; Szyjewicz, D.; Komarnicki, P.; Kuta, Ł. Determining the resistance to mechanical damage of apples under impact loads. Postharvest Biol. Technol. 2018, 146, 79–89. [Google Scholar] [CrossRef]
- Polat, R.; Turkoglu, H.; Atay, U.; Pakyurek, A.Y. Some physico-mechanical and chemical properties of cherry tomatoes (Lycopersicon esculentum cv. Forme) grown under greenhouse. Former. Philipp. Agric. 2007, 90, 75–80. [Google Scholar]
- Li, Z.G.; Li, P.P.; Yang, H.L.; Liu, J.Z.; Xu, Y.F. Mechanical properties of tomato exocarp, mesocarp and locular gel tissues. J. Food Eng. 2012, 111, 82–91. [Google Scholar] [CrossRef]
- Mahmoud, W.A.E.M.; Mahmoud, R.K.; Eissa, A.S. Determining of some physical and mechanical properties for designing tomato fruits cutting machine. Agric. Eng. Int. CIGR J. 2022, 24, 131–142. [Google Scholar]
- Hetzroni, A.; Vana, A.; Mizrach, A. Biomechanical characteristics of tomato fruit peels. Postharvest Biol. Technol. 2011, 59, 80–84. [Google Scholar] [CrossRef]
- Alkali, B.; Osunde, Z.E.; Sadiq, I.O.; Eramus, C.U. Applications of artificial neural network in determining the mechanical properties of melon fruits. IOSR J. Agric. Vet. Sci. 2014, 6, 12–16. [Google Scholar]
- Li, D.D.; Li, Z.G.; Tchuenbou-Magaia, F. An extended finite element model for fracture mechanical response of tomato fruit. Postharvest Biol. Technol. 2021, 174, 111468. [Google Scholar] [CrossRef]
- Liu, J.; Li, Z.; Li, P. The physical and mechanical properties of tomato fruit and stem. In Rapid Damage-Free Robotic Harvesting of Tomatoes; Springer: Singapore, 2021; pp. 127–195. [Google Scholar]
- Cevher, E.Y.; Yıldırım, D. Using artificial neural network application in modeling the mechanical properties of loading position and storage duration of pear fruit. Processes 2022, 10, 2245. [Google Scholar] [CrossRef]
- Akmeşe, Ö.F.; Kör, H.; Erbay, H. Use of machine learning techniques for the forecast of student achievement in higher education. Inf. Technol. Learn. Tools 2021, 82, 297–311. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Sitkei, G. Mechanics of Agricultural Materials; Akademiai Kiado: Budapest, Hungary, 1986. [Google Scholar]
- Kabas, O.; Celik, H.K.; Ozmerzi, A.; Akinci, I. Drop test simulation of a sample tomato with finite element method. J. Sci. Food Agric. 2008, 88, 1537–1541. [Google Scholar] [CrossRef]
- Mohsenin, N.N. Physical Properties of Plant and Animal Materials; Gordon and Breach Press: New York, NY, USA, 1986. [Google Scholar]
- ASAE S368.2; Agricultural Engineers Yearbook. Compression Test of Food Materials of Convex Shape. ASAE: St. Joseph, MI, USA, 1994; pp. 472–475.
- Vursavuş, K.; Özgüven, F. Fracture resistance of pine nut to compressive loading. Biosyst. Eng. 2005, 90, 185–191. [Google Scholar] [CrossRef]
- Bell, J. What is Machine Learning? Machine Learning and the City: Applications in Architecture and Urban Design; John Wiley & Sons: Hoboken, NJ, USA, 2022. [Google Scholar]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Islam, M.M.; Murase, K. A new algorithm to design compact two-hidden-layer artificial neural networks. Neural Netw. 2001, 14, 1265–1278. [Google Scholar] [CrossRef]
- Basterretxea, K.; Tarela, J.M.; Del Campo, I. Digital design of sigmoid approximator for artificial neural networks. Electron. Lett. 2002, 38, 35–37. [Google Scholar] [CrossRef]
- Goldman, M.S. Memory without feedback in a neural network. Neuron 2009, 61, 621–634. [Google Scholar] [CrossRef]
- Schumacher, M.; Roßner, R.; Vach, W. Neural networks and logistic regression: Part I. Comput. Stat. Data Anal. 1996, 21, 661–682. [Google Scholar] [CrossRef]
- Sperandei, S. Understanding logistic regression analysis. Biochem. Med. 2014, 24, 12–18. [Google Scholar] [CrossRef] [PubMed]
- Donnelly, S.; Verkuilen, J. Empirical logit analysis is not logistic regression. J. Mem. Lang. 2017, 94, 28–42. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C.C. Classification and Regression Trees; Taylor & Francis: New York, NY, USA, 1984. [Google Scholar]
- Suárez, A.; Lutsko, J.F. Globally optimal fuzzy decision trees for classification and regression. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1297–1311. [Google Scholar] [CrossRef]
- Milanović, M.; Stamenković, M. CHAID decision tree: Methodological frame and application. Economic Themes 2016, 54, 563–586. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, D.; Zhang, H.; Zhang, W.; Chen, J. Application of relative entropy and gradient boosting decision tree to fault prognosis in electronic circuits. Symmetry 2018, 10, 495. [Google Scholar] [CrossRef]
- Saranya, C.; Manikandan, G. A study on normalization techniques for privacy preserving data mining. Int. J. Eng. Technol. 2013, 5, 2701–2704. [Google Scholar]
- Bengio, Y.; Goodfellow, I.; Courville, A. Chapter 1 “Machine learning basics”. In Deep Learning; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Jones, D.T. Setting the standards for machine learning in biology. Nat. Rev. Mol. Cell Biol. 2019, 20, 659–660. [Google Scholar] [CrossRef]
- Ozer, D.J. Correlation and the coefficient of determination. Psychol. Bull. 1985, 97, 307. [Google Scholar] [CrossRef]
- Wallach, D.; Goffinet, B. Mean squared error of prediction as a criterion for evaluating and comparing system models. Ecol. Model. 1989, 44, 299–306. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average | Maximum | Minimum | SD | |
|---|---|---|---|---|
| Mass (g) | 4.82 | 7.36 | 2.48 | 1.34 |
| Length (mm) | 20.90 | 26.23 | 16.63 | 3.43 |
| Width (mm) | 17.80 | 23.27 | 14.72 | 3.40 |
| Thickness (mm) | 18.43 | 24.32 | 15.47 | 3.08 |
| Geo. Diameter (mm) | 18.96 | 24.50 | 15.82 | 3.28 |
| Sphericity (%) | 90.65 | 95.15 | 86.19 | 2.58 |
| Surface area (mm2) | 1163.61 | 1886.56 | 786.94 | 414.48 |
| Rupture force (N) | 23.38 | 27.61 | 20.79 | 1.78 |
| Firmness (N mm−1) | 4.97 | 5.87 | 4.08 | 0.64 |
| Poisson ratio | 0.29 | 0.32 | 0.26 | 0.02 |
| Modulus of elasticity (N mm−2) | 2.59 | 3.26 | 1.76 | 0.51 |
| Deformation energy (N mm) | 56.34 | 70.45 | 38.36 | 10.92 |
| Artificial Neural Networks | Logistic Regression | Decision Trees Regression | |
|---|---|---|---|
| R2 | 0.968 | 0.911 | 0.813 |
| MAE | 0.051 | 0.091 | 0.097 |
| MSE | 0.005 | 0.011 | 0.013 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabas, O.; Kayakus, M.; Ünal, İ.; Moiceanu, G. Deformation Energy Estimation of Cherry Tomato Based on Some Engineering Parameters Using Machine-Learning Algorithms. Appl. Sci. 2023, 13, 8906. https://doi.org/10.3390/app13158906
Kabas O, Kayakus M, Ünal İ, Moiceanu G. Deformation Energy Estimation of Cherry Tomato Based on Some Engineering Parameters Using Machine-Learning Algorithms. Applied Sciences. 2023; 13(15):8906. https://doi.org/10.3390/app13158906
Chicago/Turabian StyleKabas, Onder, Mehmet Kayakus, İlker Ünal, and Georgiana Moiceanu. 2023. "Deformation Energy Estimation of Cherry Tomato Based on Some Engineering Parameters Using Machine-Learning Algorithms" Applied Sciences 13, no. 15: 8906. https://doi.org/10.3390/app13158906
APA StyleKabas, O., Kayakus, M., Ünal, İ., & Moiceanu, G. (2023). Deformation Energy Estimation of Cherry Tomato Based on Some Engineering Parameters Using Machine-Learning Algorithms. Applied Sciences, 13(15), 8906. https://doi.org/10.3390/app13158906