
Exploring the Role of Emotions in Arabic Rumor Detection in Social Media

Abstract
1. Introduction
- RQ1: Are emotional cues and sentiments in news and replies capable of detecting rumors independently, without additional information?
- RQ2: Can emotional cues and sentiments in news and replies improve rumor detection when used as supplementary features for textual content?
- RQ3: How do emotion, sentiments, user, and content features contribute to distinguishing between rumors and true news in Arabic social media?
2. Background
2.1. False News and Rumors
2.2. Pre-Trained Language Models
2.3. Emotion Classification
3. Related Works
3.1. Emotions-Based Rumor Detection Approaches
3.2. Arabic Language Rumor Detection Approaches
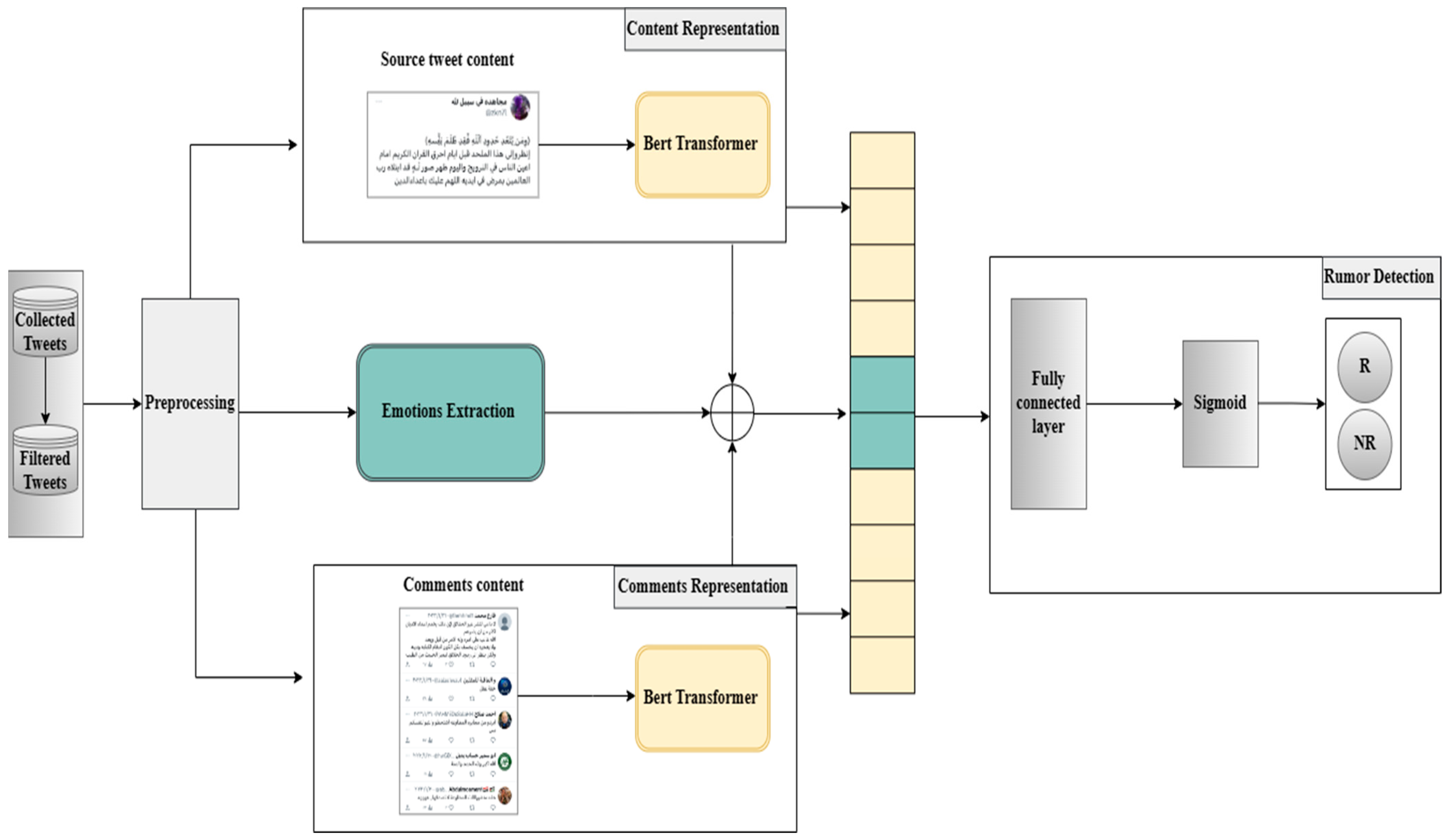
4. Research Methodology
4.1. Dataset Collection
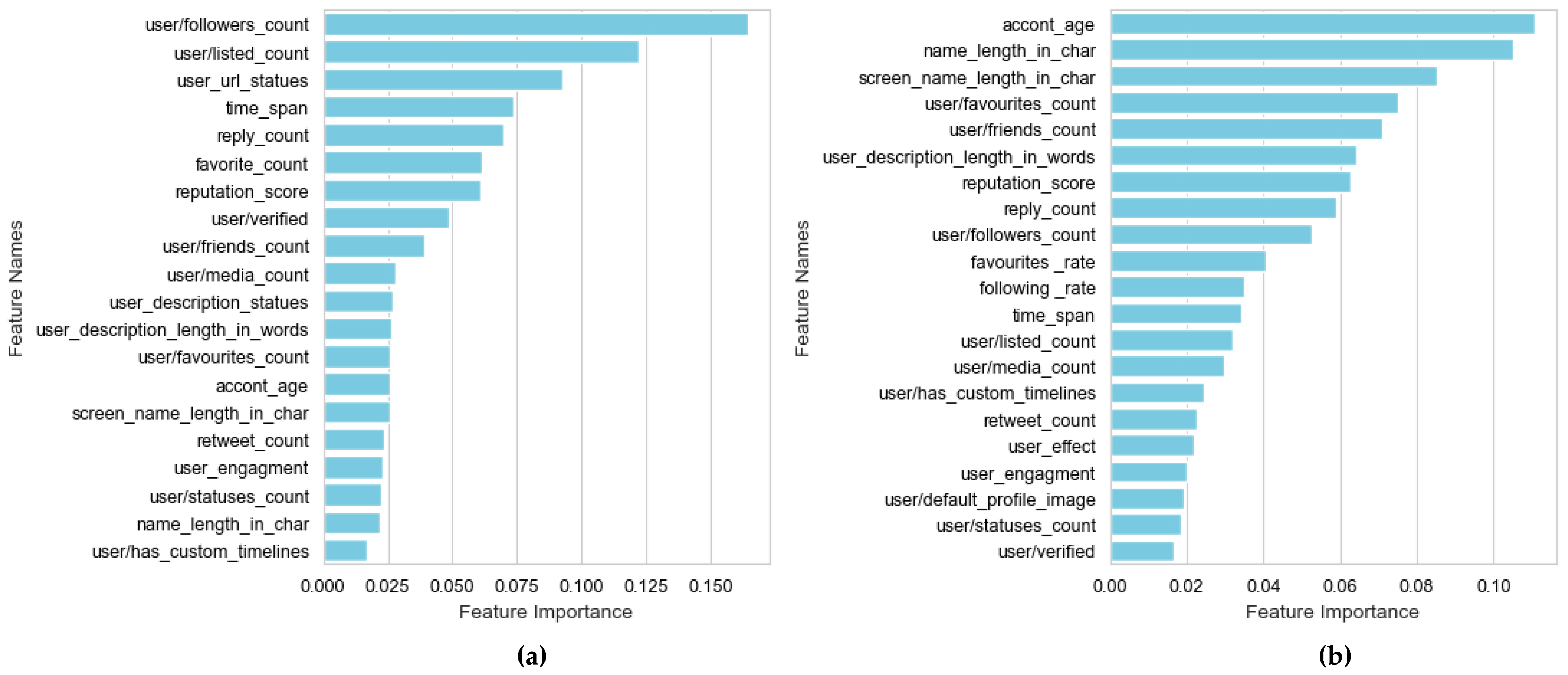
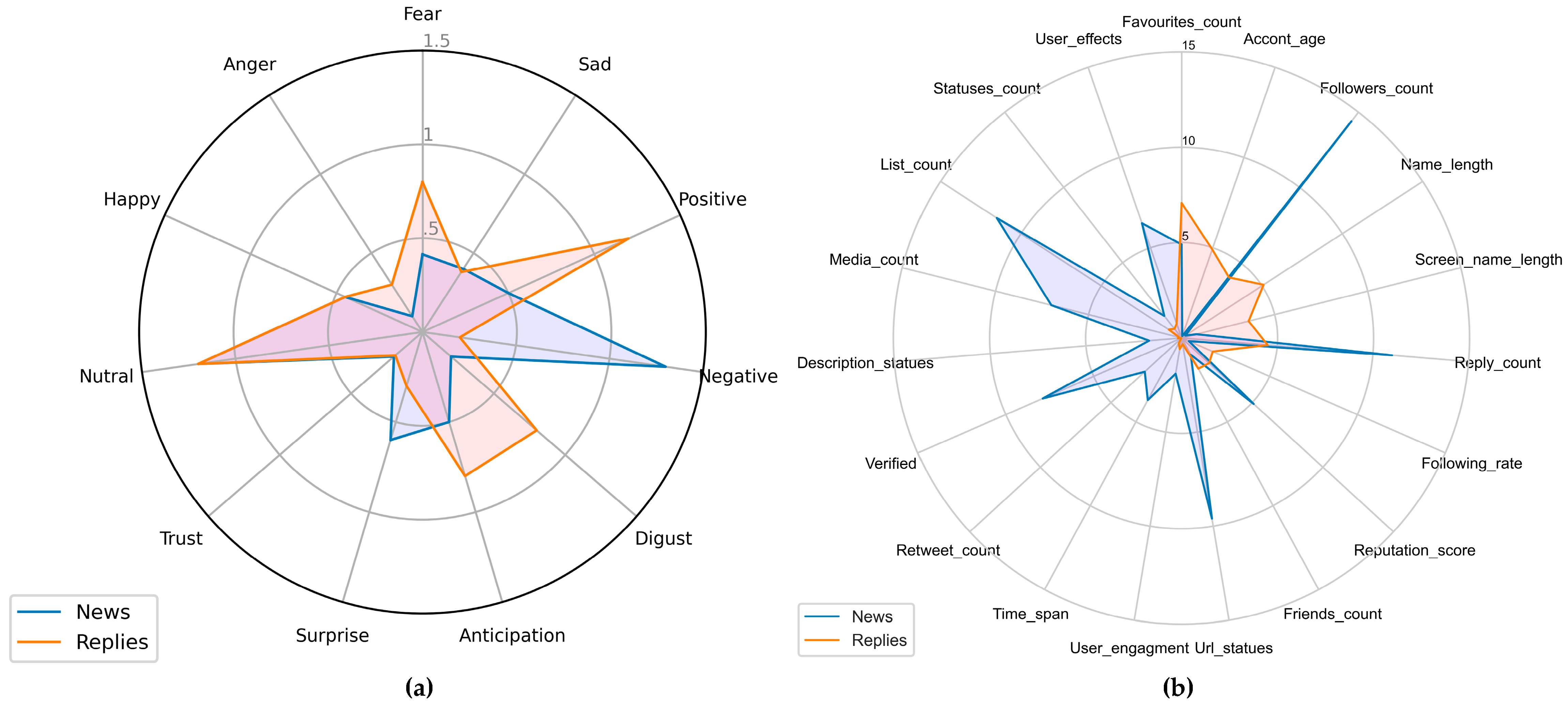
4.2. Feature Extraction
- SenticNet (https://sentic.net/, accessed on 12 January 2023) [75]: SenticNet is a concept-level lexicon that utilizes denotative and connotative information-associated concepts from the WordNet (https://wordnet.princeton.edu/, accessed on 12 January 2023) lexical database to perform emotion recognition. It is employed to extract mood tags at the word level. It covers eight emotions: anger, calmness, eagerness, disgust, fear, joy, pleasantness, and sadness. Additionally, we can extract negative and positive sentiment tags for each word in a sentence.
- NRC Emotion Lexicon (http://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm, accessed on 12 January 2023): The NRC emotion lexicon is used to assign availability statuses to the eight emotions based on the Plutchik model, namely, anger, trust, disgust, fear, joy, sadness, surprise, and anticipation, as well as sentiment. Two Python packages are utilized to extract emotions: the LeXmo and NRCLex packages.
- AraNet tools [36]: AraNet tools support a wide variety of Arabic NLP tasks, including dialect, emotion, and irony prediction. Built on BERT architecture, AraNet provides state-of-the-art performance for these tasks. It covers eight emotions: sadness, anticipation, surprise, anger, fear, happiness, disgust, and trust.
- CAMeL [76]: CAMeL tools are used for extracting sentiments, such as positive, negative, and neutral.
4.3. Pre-Processing Unit
- Diacritical Mark Elimination: We systematically removed diacritical marks from the Arabic text, resulting in a more consistent and standardized representation of the language.
- Exclusion of Non-Arabic Text: Our pre-processing strategy involved the removal of all non-Arabic content, such as hyperlinks, symbols, mentions, usernames, English characters, and numerals. Simultaneously, hashtags and keywords associated with news agencies or anti-rumor organizations were eliminated to prevent the model from favoring accurate tweet recognition.
- Character Normalization: To ensure uniformity in the Arabic text, we normalized specific characters by converting أ, آ, and إ into ا.
- Stop Word Elimination: This phase involved filtering and removing common articles, pronouns, and prepositions from the Arabic text, such as (“في”, “in”) or (“على”, “on”) which typically offer minimal analytical value. However, some essential stop words for our task, such as لا and غير, were retained as they can enhance performance.
4.4. Textual Representation of PLM Unit
4.5. Concatenation Layer
4.6. Dense Layer
4.7. Experimental Setup
- Optimizer: we tested various optimizers: SGD, ADAM, and ADAMW optimizers
- Learning rate: we explored a variety of values between 1 × 10−2 and 1 × 10−6 before deciding that 1 × 10−6 was the best value for fine-tuning and 1 × 10−4 was the best value for feature-based learning.
- Neuron numbers: several numbers were evaluated for the dense layer, including 256, 512, 1024, and 2048 neurons. After multiple tests, we settled on 1024 neurons since it provided the highest accuracy.
- Epoch numbers: we investigated with a range of epoch numbers, from 1 to 50. We employed an early stopping technique. This involves halting the training phase before the validation error arises, and the model’s performance cannot be enhanced to prevent overfitting and underfitting problems.
4.8. Evaluation Measurements
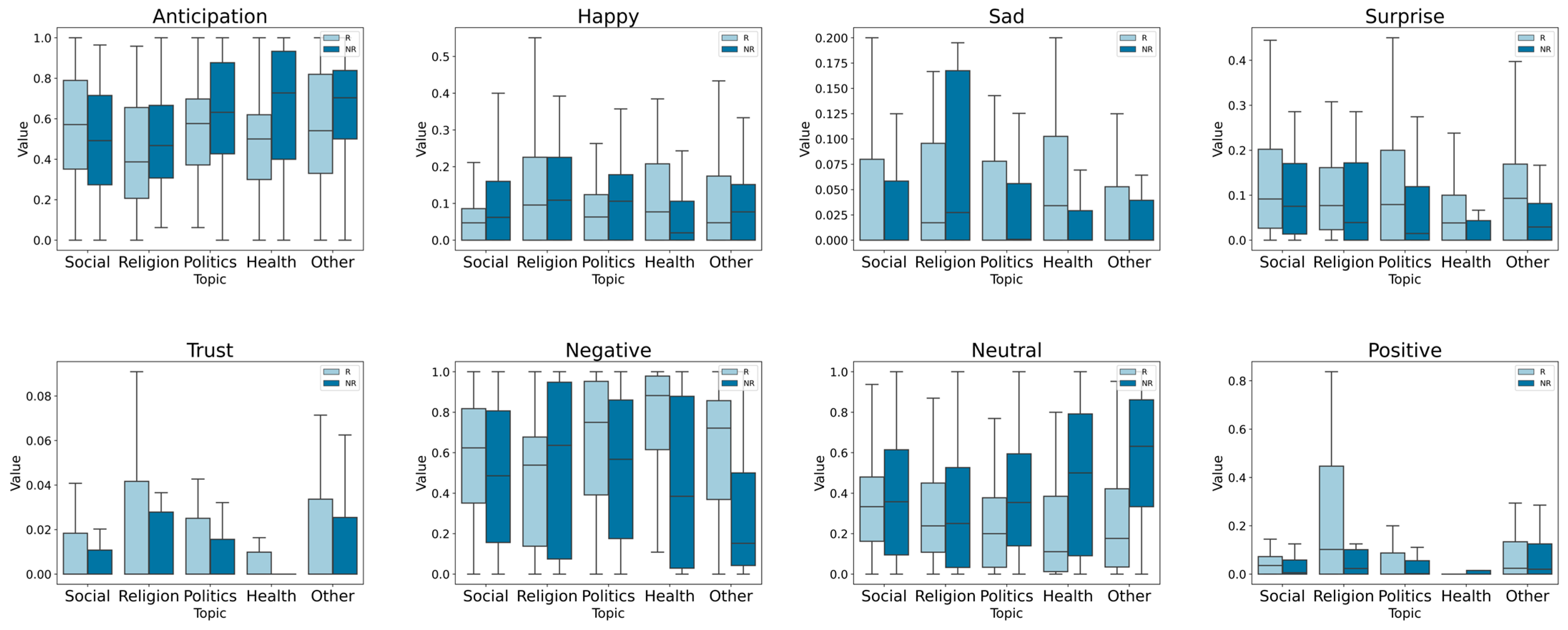
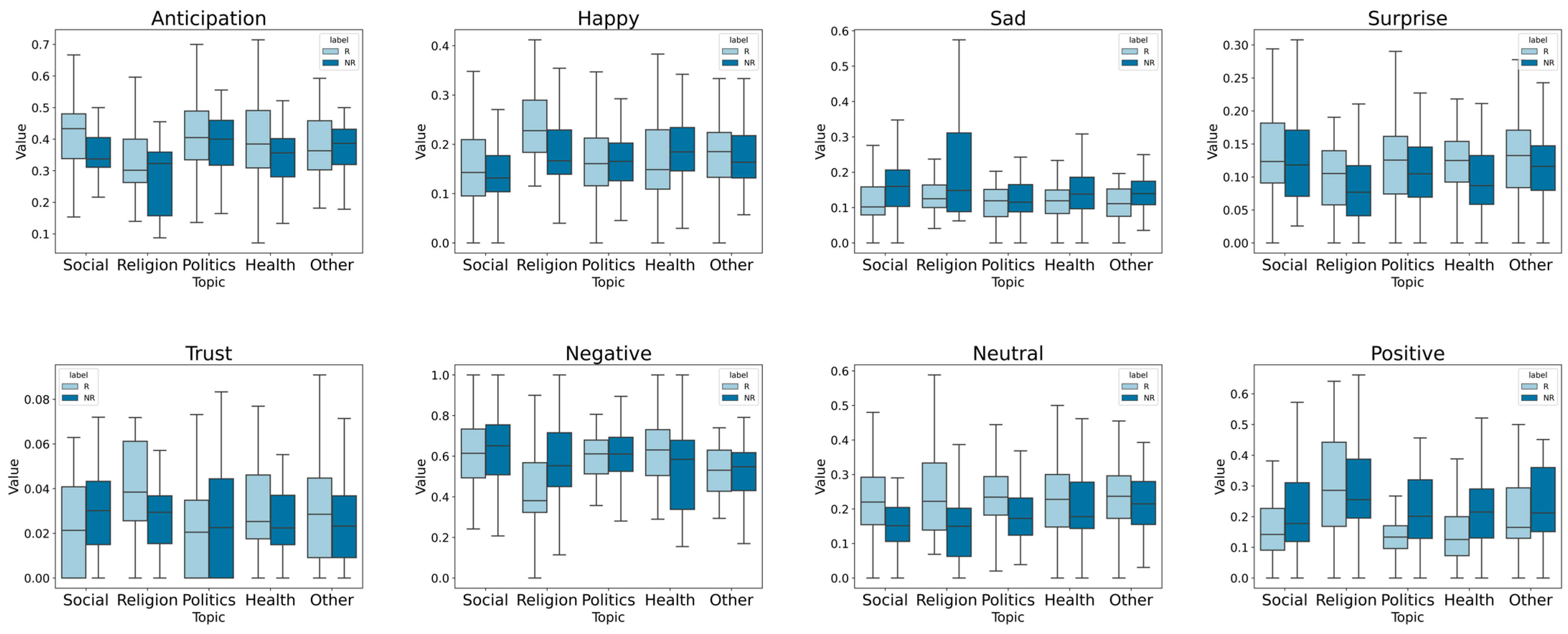
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mason, W.; Katrena, E.M. News Consumption across Social Media in 2021. Available online: http://www.pewresearch.org (accessed on 21 September 2021).
- Antonakaki, D.; Fragopoulou, P.; Ioannidis, S. A survey of Twitter research: Data model, graph structure, sentiment analysis and attacks. Expert. Syst. Appl. 2021, 164, 114006. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Gupta, A.; Kumaraguru, P.; Castillo, C.; Meier, P. Tweetcred: Real-time credibility assessment of content on twitter. Lect. Notes Comput. Sci. 2014, 8851, 228–243. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Nber Working Paper Series Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Tandoc, E.C.; Lim, Z.W.; Ling, R. Defining ‘Fake News’: A typology of scholarly definitions. Digit. J. 2018, 6, 137–153. [Google Scholar] [CrossRef]
- Samy-Tayie, S.; Tejedor, S.; Pulido, C. News literacy and online news between Egyptian and Spanish youth: Fake news, hate speech and trust in the media. Comunicar 2023, 31, 73–87. [Google Scholar] [CrossRef]
- Bovet, A.; Makse, H.A. Influence of fake news in Twitter during the 2016 US presidential election. Nat. Commun. 2019, 10, 1657. [Google Scholar] [CrossRef]
- NY Times. As Fake News Spreads Lies, More Readers Shrug at the Truth. 2016. Available online: https://www.nytimes.com/2016/12/06/us/fake-news-partisan-republican-democrat.html (accessed on 12 January 2023).
- Zubiaga, A.; Kochkina, E.; Liakata, M.; Procter, R.; Lukasik, M. Stance classification in rumours as a sequential task exploiting the tree structure of social media conversations. In Proceedings of the COLING 2016—26th International Conference on Computational Linguistics, Proceedings of COLING 2016: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2438–2448. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 1151, 1146–1151. [Google Scholar] [CrossRef]
- Kumar, S.; Shah, N. False Information on Web and Social. Media: A Survey. arXiv 2018, arXiv:1804.08559. [Google Scholar]
- Ruffo, G.; Semeraro, A.; Giachanou, A.; Rosso, P. Studying fake news spreading, polarization dynamics, and manipulation by bots: A tale of networks and language. Comput. Sci. Rev. 2023, 47, 100531. [Google Scholar] [CrossRef]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert. Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Zannettou, S.; Sirivianos, M.; Blackburn, J.; Kourtellis, N. The web of false information: Rumors, fake news, hoaxes, clickbait, and various other shenanigans. J. Data Inf. Qual. 2019, 11, 1–37. [Google Scholar] [CrossRef]
- Liang, G.; He, W.; Xu, C.; Chen, L.; Zeng, J. Rumor Identification in Microblogging Systems Based on Users’ Behavior. IEEE Trans. Comput. Soc. Syst. 2015, 2, 99–108. [Google Scholar] [CrossRef]
- Zubiaga, A.; Aker, A.; Bontcheva, K.; Liakata, M.; Procter, R. Detection and resolution of rumours in social media: A survey. ACM Comput. Surv. 2017, 51, 1–36. [Google Scholar] [CrossRef]
- Derczynski, L.; Bontcheva, K.; Liakata, M. SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours. In Proceedings of the 11th International Workshop on Semantic Evaluations, Vancouver, BC, Canada, 3–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017. [Google Scholar] [CrossRef]
- Jaeger, M.E.; Anthony, S.; Rosnow, R.L. Who Hears What from Whom and with What Effect: A Study of Rumor. Pers. Soc. Psychol. Bull. 1980, 6, 473–478. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. In preprint. Available online: https://scholar.google.com/scholar?q=Improving+Language+Understanding+by+Generative+Pre-Training&hl=ar&as_sdt=0&as_vis=1&oi=scholart (accessed on 16 May 2023).
- Ott, Y.L.M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Giurgiu, N.H.A.; Jastrzebski, S.; Morrone, B.; Laroussilhe, Q. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar]
- Khandelwal, A.C.K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 8440–8451. [Google Scholar] [CrossRef]
- Agerri, R.; Campos, J.; Barrena, A.; Saralegi, X.; Soroa, A.; Agirre, E. Give your text representation models some Love: The case for Basque. In Proceedings of the LREC 2020—12th International Conference on Language Resources and Evaluation, Conference Proceedings, Marseille, France, 11–16 May 2020; pp. 4781–4788. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the LREC 2020 Workshop Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1 August 2021; pp. 7088–7105. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Plutchic, R. General Psychoevolutionary Theory of Emotion. In Theories of Emotion; Plutchik, R., Kellerman, H., Eds.; Academic Press: Cambridge, MA, USA, 1980; pp. 3–33. [Google Scholar] [CrossRef]
- Al-A’abed, M.; Al-Ayyoub, M. A Lexicon—Based Approach for Emotion Analysis of Arabic Social Media Content. In Proceedings of the International Computer Sciences and Informatics Conference (ICSIC 2016), Amman, Jordan, 12–13 January 2016. [Google Scholar]
- El Jundi, G.B.O.; Khaddaj, A.; Maarouf, A.; Kain, R.; Hajj, H.; El-Hajj, W. EMA at SemEval-2018 Task 1: Emotion Mining for Arabic. In Proceedings of the SemEval@NAACL-HLT, New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Al-Khatib, A.; El-Beltagy, S.R. Emotional tone detection in Arabic tweets. Lect. Notes Comput. Sci. 2018, 10762, 105–114. [Google Scholar] [CrossRef]
- Alswaidan, N.; Menai, M.E.B. Hybrid Feature Model for Emotion Recognition in Arabic Text. IEEE Access 2020, 8, 37843–37854. [Google Scholar] [CrossRef]
- Abdul-Mageed, M.; Zhang, C.; Hashemi, A.; Nagoudi, E.M.B. AraNet: A deep learning toolkit for arabic social media. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2019; European Language Resource Association: Paris, France, 2019; pp. 16–23. [Google Scholar]
- Tian, L.; Zhang, X.; Wang, Y.; Liu, H. Early Detection of Rumours on Twitter via Stance Transfer Learning. Lect. Notes Comput. Sci. 2020, 12035, 575–588. [Google Scholar] [CrossRef]
- Kwon, S.; Cha, M.; Jung, K.; Chen, W.; Wang, Y. Prominent features of rumor propagation in online social media. In Proceedings of the IEEE International Conference on Data Mining, ICDM, Dallas, TX, USA, 7–10 December 2013; pp. 1103–1108. [Google Scholar] [CrossRef]
- Wu, K.; Yang, S.; Zhu, K.Q. False rumors detection on Sina Weibo by propagation structures. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; pp. 651–662. [Google Scholar] [CrossRef]
- Jin, Z.; Cao, J.; Jiang, Y.-G.; Zhang, Y. News Credibility Evaluation on Microblog with a Hierarchical Propagation Model. In Proceedings of the 2014 IEEE International Conference on Data Mining, in ICDM’14, Shenzhen, China, 14–17 December 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 230–239. [Google Scholar] [CrossRef]
- Ghanem, B.; Rosso, P.; Rangel, F. An Emotional Analysis of False Information in Social Media and News Articles. ACM Trans. Internet Technol. 2020, 20, 1–17. [Google Scholar] [CrossRef]
- Guo, C.; Cao, J.; Zhang, X.; Shu, K.; Yu, M. Exploiting emotions for fake news detection on social media. arXiv 2019, arXiv:1903.01728. [Google Scholar]
- Zhang, X.; Cao, J.; Li, X.; Sheng, Q.; Zhong, L.; Shu, K. Mining Dual Emotion for Fake News Detection. In WWW’21: Proceedings of the Web Conference 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3465–3476. [Google Scholar] [CrossRef]
- Anoop, K.; Deepak, P.; Lajish, V. Emotion Cognizance Improves Health Fake News Identification. In Proceedings of the 24th Symposium on International Database Engineering & Applications, Seoul, Republic of Korea, 12–14 August 2020. [Google Scholar]
- Giachanou, A.; Rosso, P.; Crestani, F. Leveraging Emotional Signals for Credibility Detection. In SIGIR’19: Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval; Association for Computing Machinery: New York, NY, USA, 2019; pp. 877–880. [Google Scholar]
- Wu, L.; Rao, Y. Adaptive interaction fusion networks for fake news detection. Front. Artif. Intell. Appl. 2020, 325, 2220–2227. [Google Scholar] [CrossRef]
- Hamed, S.K.; Aziz, M.J.A.; Yaakub, M.R. Fake News Detection Model on Social Media by Leveraging Sentiment Analysis of News Content and Emotion Analysis of Users’ Comments. Sensors 2023, 23, 1748. [Google Scholar] [CrossRef] [PubMed]
- Ghanem, B.; Ponzetto, S.P.; Rosso, P.; Rangel, F. FakeFlow: Fake News Detection by Modeling the Flow of Affective Information. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Kyiv, Ukraine, 19–23 April 2021; pp. 679–689. [Google Scholar]
- United Nations Top Languges. 2021. Available online: https://www.un.org/en/our-work/official-languages (accessed on 12 January 2023).
- Alzanin, S.M.; Azmi, A.M. Rumor detection in Arabic tweets using semi-supervised and unsupervised expectation–maximization. Knowl. Based Syst. 2019, 185, 104945. [Google Scholar] [CrossRef]
- Sabbeh, S.F.; Baatwah, S.Y. Arabic news credibility on twitter: An enhanced model using hybrid features. J. Theor. Appl. Inf. Technol. 2018, 96, 2327–2338. [Google Scholar]
- Jardaneh, G.; Abdelhaq, H.; Buzz, M.; Johnson, D. Classifying Arabic tweets based on credibility using content and user features. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology, JEEIT, Amman, Jordan, 9–11 April 2019; pp. 596–601. [Google Scholar] [CrossRef]
- Gumaei, A.; Al-Rakhami, M.S.; Hassan, M.M.; De Albuquerque, V.H.C.; Camacho, D. An Effective Approach for Rumor Detection of Arabic Tweets Using eXtreme Gradient Boosting Method. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–16. [Google Scholar] [CrossRef]
- Al-Khalifa, H.S.; Al-Eidan, R.M. An experimental system for measuring the credibility of news content in Twitter. Int. J. Web Inf. Syst. 2011, 7, 130–151. [Google Scholar] [CrossRef]
- Al-yahya, M.; Al-khalifa, H.; Al-baity, H.; Alsaeed, D.; Essam, A. Arabic Fake News Detection: Comparative Study of Neural Networks and Transformer-Based Approaches. Complexity 2021, 2021, 5516945. [Google Scholar] [CrossRef]
- Alsudias, L.; Rayson, P. COVID-19 and Arabic Twitter: How can Arab World Governments and Public Health Organizations Learn from Social Media? In Proceedings of the 1st Workshop on NLP for COVID-19 at ACL, Online, 9–10 July 2020; pp. 1–9. [Google Scholar]
- Mahlous, A.R.; Al-Laith, A. Fake News Detection in Arabic Tweets during the COVID-19 Pandemic. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 778–788. [Google Scholar] [CrossRef]
- Fouad, K.M.; Sabbeh, S.F.; Medhat, W. Arabic fake news detection using deep learning. Comput. Mater. Contin. 2022, 71, 3647–3665. [Google Scholar] [CrossRef]
- Amoudi, G.; Albalawi, R.; Baothman, F.; Jamal, A.; Alghamdi, H.; Alhothali, A. Arabic rumor detection: A comparative study. Alex. Eng. J. 2022, 61, 12511–12523. [Google Scholar] [CrossRef]
- Nassif, A.B.; Elnagar, A.; Elgendy, O.; Afadar, Y. Arabic fake news detection based on deep contextualized embedding models. Neural Comput. Appl. 2022, 34, 16019–16032. [Google Scholar] [CrossRef]
- Albalawi, R.M.; Jamal, A.T.; Khadidos, A.O.; Alhothali, A.M. Multimodal Arabic Rumors Detection. IEEE Access 2023, 11, 9716–9730. [Google Scholar] [CrossRef]
- Harrag, F.; Djahli, M.K. Arabic Fake News Detection: A Fact Checking Based Deep Learning Approach. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–34. [Google Scholar] [CrossRef]
- Giachanou, A.; Zhang, G.; Rosso, P. Multimodal Multi-image Fake News Detection. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 647–654. [Google Scholar] [CrossRef]
- Gorrell, G.; Bontcheva, K.; Derczynski, L.; Kochkina, E.; Liakata, M.; Zubiaga, A. RumourEval 2019: Determining rumour veracity and support for rumours. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 845–854. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In WWW ’11: Proceedings of the 20th International Conference on World Wide Web; Association for Computing Machinery: New York, NY, USA, 2011; pp. 675–684. [Google Scholar] [CrossRef]
- Yang, F.; Liu, Y.; Yu, X.; Yang, M. Automatic Detection of Rumor on Sina Weibo. In Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics, Beijing, China, 12–16 August 2012; Volume 2, pp. 13:1–13:7. [Google Scholar]
- Ghanem, B.; Cignarella, A.T.; Bosco, C.; Rosso, P.; Pardo, F.M.R. UPV-28-UNITO at SemEval-2019 Task 7: Exploiting Post’s Nesting and Syntax Information for Rumor Stance Classification. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1125–1131. [Google Scholar] [CrossRef]
- Kochkina, A.Z.E.; Liakata, M.; Procter, R.; Lukasik, M.; Bontcheva, K.; Cohn, T.; Augenstein, I. Discourse-aware rumour stance classification in social media using sequential classifiers. Inf. Process. Manag. 2018, 54, 273–290. [Google Scholar] [CrossRef]
- Alsaif, H.; Aldossari, H. Review of stance detection for rumor verification in social media. Eng. Appl. Artif. Intell. 2023, 119, 105801. [Google Scholar] [CrossRef]
- Singh, V.; Narayan, S.; Akhtar, M.S.; Ekbal, A.; Bhattacharyya, P. IITP at SemEval-2017 Task 8: A Supervised Approach for Rumour Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 497–501. [Google Scholar] [CrossRef]
- Bahuleyan, H.; Vechtomova, O. Detecting Stance towards Rumours with with Topic Independent Features. In Proceedings of the 11th International Workshop on Semantic Evaluations, Vancouver, BC, Canada, 3–4 August 2017; pp. 145–183. [Google Scholar] [CrossRef]
- Baris, I.; Schmelzeisen, L.; Staab, S. CLEARumor at SemEval-2019 Task 7: ConvoLving ELMo against rumors. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 1105–1109. [Google Scholar] [CrossRef]
- Islam, M.R.; Muthiah, S.; Ramakrishnan, N. Rumorsleuth: Joint detection of rumor veracity and user stance. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social. Networks Analysis and Mining, ASONAM 2019, Vancouver, BC, Canada, 27–30 August 2019; pp. 131–136. [Google Scholar] [CrossRef]
- Janchevski, A.; Gievska, S. AndrejJan at SemEval-2019 Task 7: A Fusion Approach for Exploring the Key Factors pertaining to Rumour Analysis. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1083–1089. [Google Scholar] [CrossRef]
- Cambria, E.; Poria, S.; Bajpai, R.; Schuller, B. SenticNet 4: A Semantic Resource for Sentiment Analysis Based on Conceptual Primitives. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 2666–2677. [Google Scholar]
- Zalmout, O.O.N.; Khalifa, S.; Taji, D.; Oudah, M.; Alhafni, B.; Inoue, G.; Eryani, F.; Erdmann, A.; Habash, N. CAMeL Tools: An Open Source Python Toolkit for Arabic Natural Language Processing. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 7022–7032. Available online: http://qatsdemo.cloudapp.net/farasa/ (accessed on 12 January 2023).
- Dror, R.; Baumer, G.; Shlomov, S.; Reichart, R. The Hitchhiker’s Guide to Testing Statistical Significance in Natural Language Processing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1383–1392. [Google Scholar] [CrossRef]
- Giachanou, A.; Rosso, P.; Crestani, F. The impact of emotional signals on credibility assessment. J. Assoc. Inf. Sci. Technol. 2021, 72, 1117–1132. [Google Scholar] [CrossRef]
- Giachanou, A.; Ghanem, B.; Ríssola, E.A.; Rosso, P.; Crestani, F.; Oberski, D. The impact of psycholinguistic patterns in discriminating between fake news spreaders and fact checkers. Data Knowl. Eng. 2022, 138, 101960. [Google Scholar] [CrossRef]
- Lillie, A.E.; Middelboe, E.R.; Derczynski, L. Joint Rumour Stance and Veracity. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; Linköping University Electronic Press: Linköping, Sweden, 2019; pp. 208–221. [Google Scholar] [CrossRef]
- Li, Y.; Scarton, C. Revisiting Rumour Stance Classification: Dealing with Imbalanced Data. In Proceedings of the 3rd International Workshop on Rumours and Deception in Social Media (RDSM), Barcelona, Spain, 13 December 2020; pp. 38–44. Available online: https://www.aclweb.org/anthology/2020.rdsm-1.4 (accessed on 12 January 2023).
- Kumar, S.; Carley, K.M. Tree LSTMs with convolution units to predict stance and rumor veracity in social media conversations. In Proceedings of the ACL 2019—57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2020; pp. 5047–5058. [Google Scholar] [CrossRef]
- Yang, R.; Ma, J.; Lin, H.; Gao, W. A Weakly Supervised Propagation Model for Rumor Verification and Stance Detection with Multiple Instance Learning. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; ACM: New York, NY, USA, 2022; pp. 1761–1772. [Google Scholar] [CrossRef]
- Wei, P.; Xu, N.; Mao, W. Modeling conversation structure and temporal dynamics for jointly predicting rumor stance and veracity. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4787–4798. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wong, K. Detect rumor and stance jointly by neural multi-task learning. In Proceedings of the Companion Proceedings of the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 585–593. [Google Scholar] [CrossRef]
- Xuan, K.; Xia, R. Rumor stance classification via machine learning with text, user and propagation features. In Proceedings of the IEEE International Conference on Data Mining Workshops, ICDMW, Beijing, China, 8–11 November 2019; pp. 560–566. [Google Scholar] [CrossRef]
- Schuff, H.; Barnes, J.; Mohme, J.; Padó, S.; Klinger, R. Annotation, Modelling and Analysis of Fine-Grained Emotions on a Stance and Sentiment Detection Corpus. In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social. Media Analysis, Copenhagen, Denmark, 8 September 2018; pp. 13–23. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Dataset Source | Domain | Languages |
|---|---|---|---|
| Juan Cao, Chuan Guo, Xueyao Zhang. Sheng, Kai Shu, and Miao Yu (2019) [42] | Various domains | Chinese | |
| Juan Cao, Xueyao Zhang, Xirong Li, Qiang Sheng, Kai Shu, and Lei Zhong (2021) [43] | Twitter, Weibo | Various domains | English, Chinese |
| Anoop k, Deepak P and Lajish V (2020) [44] | News | Health | English |
| Lianwei Wu and Yuan Rao (2020) [46] | Various domains | English | |
| Bilal Ghanem, Paolo Rosso, Francisco Rangel (2020) [41] | Twitter, News | Various domains | English |
| Anastasia Giachanou, Paolo Rosso, Fabio Crestani (2019) [45] | News | Political | English |
| Bilal Ghanem, Simone Paolo Ponzetto, Paolo Rosso, Francisco Rangel (202l) [48] | News | Various domains | English |
| Suhaib Kh Hamed, Mohd Juzaiddin Ab Aziz, Mohd Ridzwan Yaakub (2023) [47] | Various domains | English |
| Statistics | Count |
|---|---|
| Events# | 403 |
| Rumor# | 202 |
| Non-rumor# | 201 |
| News Posts# | 20,493 |
| Replies# | 40,759 |
| Type | Feature | Type | Description |
|---|---|---|---|
| User-based features | List count | Float | Number of lists that author participates in |
| Description status | Boolean | Whether user provides a personal description | |
| Char-description length | Integer | Personal description length (in words) | |
| Word-description length | Integer | Personal description length (in char) | |
| User-favorite count | Integer | Number of posts that author favors | |
| Username length | Integer | Number of characters in username | |
| Screenname length | Integer | Number of characters in screenname | |
| User-followers count | Integer | Number of accounts that follow author | |
| User-friends count | Integer | Number of accounts that author follows | |
| Geo-enabled | Boolean | Whether account has enabled geographic location | |
| Media count | Integer | Number of media posted by author | |
| Custom timelines | Boolean | Whether user has a custom timeline | |
| Status count | Integer | Number of posts written by author account | |
| Verified | Boolean | Whether user has verified accounts | |
| URL statues | Integer | Whether author account has a URL in homepage | |
| Protected | Boolean | Whether user has protected their tweets | |
| Consent status | Boolean | Whether account requires consent | |
| Can dm | Boolean | Whether account allows users to send direct messages privately | |
| Profile background tile | Boolean | Whether author account has background profiles tile | |
| Profile background image | Boolean | Whether author account has background profiles images | |
| Default profile | Boolean | Whether author account has not changed theme or background of profiles | |
| Default profile images | Boolean | Whether author account has changed the default profiles images | |
| User engagement | Float | User engagement (# posts/(account age + 1)) | |
| Following rate | Float | Following rate (i.e., followings/(account age + 1)) | |
| Favorite rate | Float | Favorite rate (i.e., user favorites/(account age + 1)) | |
| User effects | Float | Whether the author is a producer or recipient determined by the formula # followers/# following | |
| Reputation score | Float | Reputation score of accounts, calculated by the formula # followers/(# followers + # following + 1) | |
| Account age | Integer | Number of years since account creation | |
| Following | Boolean | Whether author account is followed by authenticated user | |
| Follow request sent | Boolean | Whether author account is requested to follow by authenticated user | |
| Notifications | Boolean | Whether author account has turned on notifications | |
| Contributor-enabled | Boolean | Whether account has enabled contributors | |
| Translation-enabled | Boolean | Whether account has enabled translations | |
| Is translator | Boolean | Whether account has a translator | |
| Timespan | Float | Difference in years between account creation and tweet posted | |
| Promotable | Boolean | Whether account is promotable | |
| Normal followers | Boolean | Number of normal followers | |
| Content-based features | Retweet count | Integer | Total number of post retweets |
| Reply count | Integer | Total number of post replies | |
| Favorite count | Integer | Total number of post favorites | |
| URL presence | Boolean | Whether tweets have a URL | |
| Question mark presence | Boolean | Whether tweets have a question mark | |
| Exclamation mark presence | Boolean | Whether tweets have an exclamation mark | |
| Media presence | Boolean | Whether tweets have media videos or images | |
| Hashtag presence | Boolean | Whether tweets have hashtags | |
| Word length | Integer | Tweet length in char |
| Approach | Features | SVM | LR | RF | |||
|---|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | ||
| News-based emotions | LeXmo | 58% | 55.3% | 56.8% | 58.8% | 58% | 58.8% |
| NRCLex | 49.4% | 64.3% | 60.5% | 64.4% | 63% | 62.5% | |
| SenticNet | 45.7% | 59.3% | 51.9% | 48% | 44.4% | 45.8% | |
| AraNet + CAMeL | 63% | 68.1% | 54.3% | 54.3% | 67.9% | 71.7% | |
| ALL Emotions | 64.2% | 64.2% | 64.2% | 62.8% | 60.5% | 62.8% | |
| comments-based emotions | LeXmo | 59.3% | 60.2% | 54.3% | 56.5% | 58% | 58.5% |
| NRCLex | 55.6% | 62.5% | 59.2% | 62.9% | 64.2% | 62.3% | |
| SenticNet | 48.1% | 51.2% | 53.1% | 52.5% | 58% | 56.4% | |
| AraNet + CAMeL | 64.2% | 63.3% | 59.3% | 60.2% | 65.4% | 64.1% | |
| ALL Emotions | 65.4% | 65% | 56.8% | 58.8% | 67.9% | 69% | |
| Combining-based emotions | LeXmo | 64.2% | 67.4% | 55.6% | 57.1% | 63% | 64.3% |
| NRCLex | 53.1% | 64.8% | 60.5% | 63.6% | 71.6% | 72.3% | |
| SenticNet | 53.1% | 52.5% | 56.8% | 57.8% | 53.1% | 53.7% | |
| AraNet + CAMeL | 63% | 65.9% | 67.9% | 69.8% | 67.6% | 69% | |
| ALL Emotions | 67.9% | 69.8% | 66.7% | 69.7% | 67.9% | 69.7% | |
| ALL + Gap emotions | 67.9% | 70.5% | 69.1% | 71.3% | 69.1% | 70.6% | |
| Approach | Model | Features | Last Layer (cls) | Concatenation | Mean Pooling | |||
|---|---|---|---|---|---|---|---|---|
| Accuracy | F-Score | Accuracy | F-Score | Accuracy | F-Score | |||
| Fine-tuning approach | AraBERT-Twitter | News Features | 66.66% | 64.01% | 62.96% | 59.71% | 65.43% | 61.79% |
| News + Comments Features | 77.77% | 78.81% | 82.71% | 82.59% | 79.01% | 78.54% | ||
| (+) Basic Features | 85.18% | 85.13% | 82.71% | 82.59% | 81.48% | 80.91% | ||
| (+) All Features | 74.04% | 72.73% | 83.95% | 83.79% | 70.37% | 67.77% | ||
| MARBERT | News Features | 59.25% | 51.72% | 56.79% | 46.15% | 69.13% | 66.17% | |
| News + Comments Features | 87.65% | 87.64% | 87.65% | 87.64% | 85.18% | 85.18% | ||
| (+) Basic Features | 87.65% | 87.64% | 88.88% | 88.86% | 88.88% | 88.86% | ||
| (+) All Features | 87.65% | 87.64% | 88.88% | 88.86% | 86.41% | 86.41% | ||
| Features-based approach | AraBERT-Twitter | News Features | 66.66% | 66.15% | 69.13% | 68.44% | 69.13% | 65.59% |
| News + Comments Features | 77.77% | 77.77% | 77.77% | 77.5% | 81.48% | 81.38% | ||
| (+) Basic Features | 81.48% | 81.48% | 80.24% | 80.24% | 82.71% | 82.65% | ||
| (+) All Features | 80.24% | 80.24% | 81.48% | 81.47% | 82.71% | 82.65% | ||
| MARBERT | News Features | 65.43% | 61.79% | 65.43% | 61.79% | 65.43% | 61.79% | |
| News + Comments Features | 79.01% | 78.81% | 69.13% | 66.68% | 83.95% | 83.79% | ||
| (+) Basic Features | 83.95% | 83.86% | 76.54% | 75.59% | 70.37% | 68.65% | ||
| (+) All Features | 83.95% | 83.91% | 83.95% | 83.91% | 82.71% | 82.26% | ||
| Approach | Model | Features | Accuracy | F-Score |
|---|---|---|---|---|
| Fine-tuning approach | AraBERT-Twitter | Emotion-based model | 74.04% | 72.73% |
| (+) user and contents feature | 86.41% | 86.34% | ||
| MARBERT | Emotion-based model | 87.65% | 87.64% | |
| (+) user and contents feature | 85.18% | 85.13% | ||
| Features-based approach | AraBERT-Twitter | Emotion-based model | 80.24% | 80.24% |
| (+) user and contents feature | 81.48% | 81.44% | ||
| MARBERT | Emotion-based model | 83.95% | 83.91% | |
| (+) user and contents feature | 88.88% | 88.83% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Saif, H.F.; Al-Dossari, H.Z. Exploring the Role of Emotions in Arabic Rumor Detection in Social Media. Appl. Sci. 2023, 13, 8815. https://doi.org/10.3390/app13158815
Al-Saif HF, Al-Dossari HZ. Exploring the Role of Emotions in Arabic Rumor Detection in Social Media. Applied Sciences. 2023; 13(15):8815. https://doi.org/10.3390/app13158815
Chicago/Turabian StyleAl-Saif, Hissa F., and Hmood Z. Al-Dossari. 2023. "Exploring the Role of Emotions in Arabic Rumor Detection in Social Media" Applied Sciences 13, no. 15: 8815. https://doi.org/10.3390/app13158815
APA StyleAl-Saif, H. F., & Al-Dossari, H. Z. (2023). Exploring the Role of Emotions in Arabic Rumor Detection in Social Media. Applied Sciences, 13(15), 8815. https://doi.org/10.3390/app13158815