
A Toxic Style Transfer Method Based on the Delete–Retrieve–Generate Framework Exploiting Toxic Lexicon Semantic Similarity




Abstract
1. Introduction
2. Related Work
3. Proposed Approach
| Algorithm 1: Similarity-based Toxic Deletion. |
|
4. Experimental Design
4.1. Resources
4.2. Metrics
4.3. Implementation Details
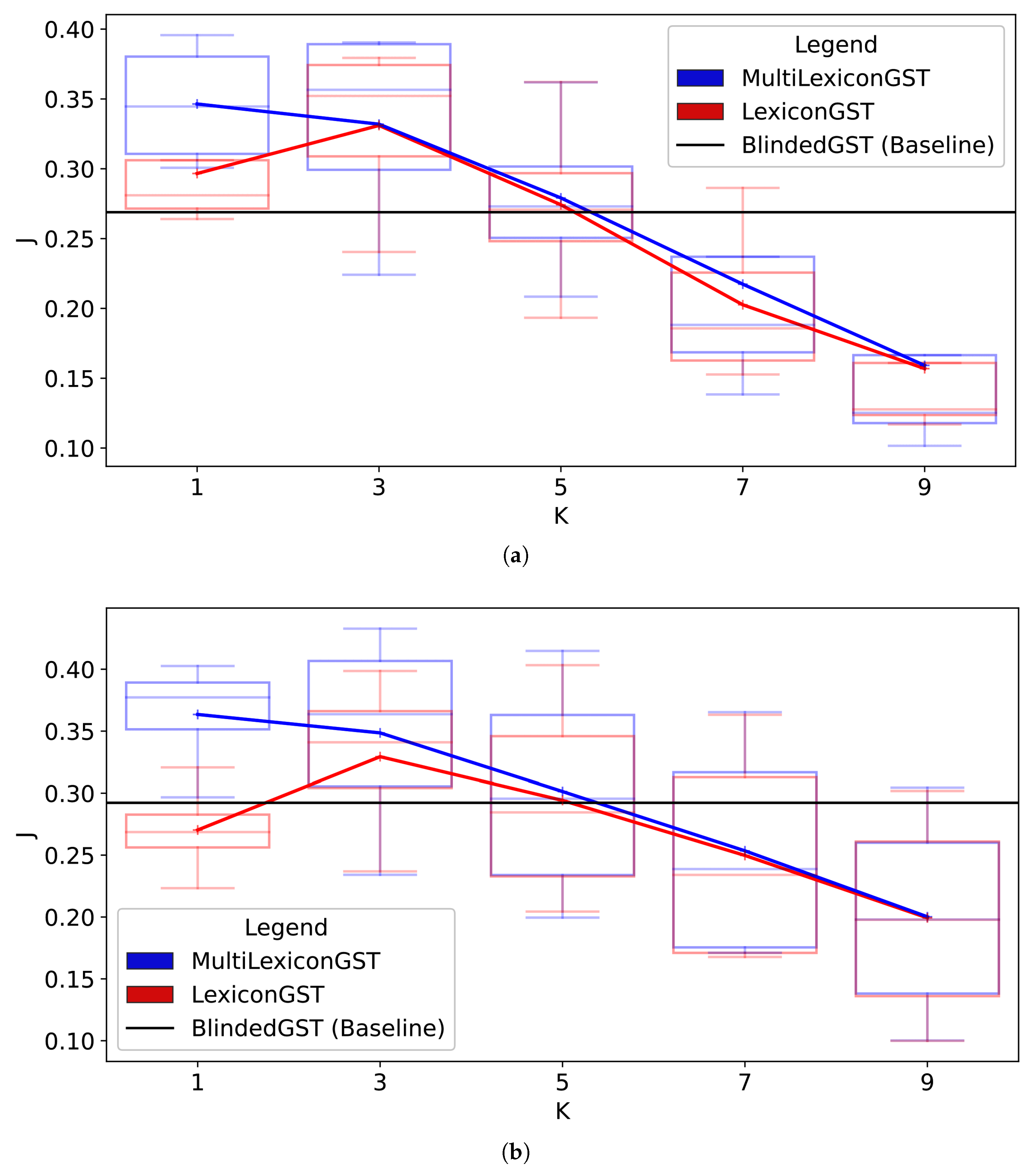
5. Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Sentence-level style accuracy |
| BLEU | Bilingual Evaluation Understudy |
| DLSM | Deep Latent Sequence Model |
| DRG | Delete-Retrieve-Generate |
| GPT | Generative Pre-trained Transformer |
| GST | Generative Style Transformer |
| LM | Language Model |
| LSTM | Long Short-Term Memory |
| MLM | Mask Language Modeling |
| NLG | Natural Language Generation |
| SOTA | State-of-the-Art |
| SST | Stable Style Transformer |
| SOTA | State of the Art |
References
- Jigsaw. The Toxicity Issue. Can Technology Help Improve Conversations Online? Available online: https://jigsaw.google.com/the-current/toxicity/ (accessed on 8 May 2023).
- Zampieri, M.; Nakov, P.; Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Mubarak, H.; Derczynski, L.; Pitenis, Z.; Çöltekin, Ç. SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020). In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Online, 12–13 December 2020; pp. 1425–1447. [Google Scholar] [CrossRef]
- D’Sa, A.G.; Illina, I.; Fohr, D. Towards Non-Toxic Landscapes: Automatic Toxic Comment Detection Using DNN. In Proceedings of the 2nd Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 16 May 2020; pp. 21–25. [Google Scholar]
- Han, X.; Tsvetkov, Y. Fortifying Toxic Speech Detectors Against Veiled Toxicity. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 12 November 2020; pp. 7732–7739. [Google Scholar] [CrossRef]
- Welbl, J.; Glaese, A.; Uesato, J.; Dathathri, S.; Mellor, J.; Hendricks, L.A.; Anderson, K.; Kohli, P.; Coppin, B.; Huang, P.S. Challenges in Detoxifying Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 2447–2469. [Google Scholar] [CrossRef]
- Xu, C.; He, Z.; He, Z.; McAuley, J. Leashing the Inner Demons: Self-Detoxification for Language Models. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 11530–11537. [Google Scholar]
- Nogueira dos Santos, C.; Melnyk, I.; Padhi, I. Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 189–194. [Google Scholar] [CrossRef]
- Tran, M.; Zhang, Y.; Soleymani, M. Towards A Friendly Online Community: An Unsupervised Style Transfer Framework for Profanity Redaction. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Online, 8–13 December 2020; Scott, D., Bel, N., Zong, C., Eds.; International Committee on Computational Linguistics: New York, NY, USA, 2020; pp. 2107–2114. [Google Scholar] [CrossRef]
- Laugier, L.; Pavlopoulos, J.; Sorensen, J.; Dixon, L. Civil Rephrases of Toxic Texts With Self-Supervised Transformers. arXiv 2021, arXiv:2102.05456. [Google Scholar]
- Jin, D.; Jin, Z.; Hu, Z.; Vechtomova, O.; Mihalcea, R. Deep Learning for Text Style Transfer: A Survey. Comput. Linguist. 2022, 48, 155–205. [Google Scholar] [CrossRef]
- Zhou, G.; Luo, P.; Cao, R.; Lin, F.; Chen, B.; He, Q. Mechanism-aware neural machine for dialogue response generation. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Reddy, S.; Knight, K. Obfuscating Gender in Social Media Writing. In Proceedings of the First Workshop on NLP and Computational Social Science, Austin, TX, USA, 5 November 2016; pp. 17–26. [Google Scholar] [CrossRef]
- Rao, S.; Tetreault, J. Dear Sir or Madam, May I Introduce the GYAFC Dataset: Corpus, Benchmarks and Metrics for Formality Style Transfer. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 129–140. [Google Scholar] [CrossRef]
- Yang, C.; Sun, M.; Yi, X.; Li, W. Stylistic Chinese Poetry Generation via Unsupervised Style Disentanglement. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3960–3969. [Google Scholar]
- Hu, Z.; Yang, Z.; Liang, X.; Salakhutdinov, R.; Xing, E.P. Toward Controlled Generation of Text. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; International Convention Centre: Birmingham, UK, 2017; Volume 70, pp. 1587–1596. [Google Scholar]
- Shen, T.; Lei, T.; Barzilay, R.; Jaakkola, T. Style transfer from non-parallel text by cross-alignment. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6830–6841. [Google Scholar]
- Fu, Z.; Tan, X.; Peng, N.; Zhao, D.; Yan, R. Style transfer in text: Exploration and evaluation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, J.; Jia, R.; He, H.; Liang, P. Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 1865–1874. [Google Scholar] [CrossRef]
- Sudhakar, A.; Upadhyay, B.; Maheswaran, A. “Transforming” Delete, Retrieve, Generate Approach for Controlled Text Style Transfer. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 7 November 2019; pp. 3269–3279. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wu, X.; Zhang, T.; Zang, L.; Han, J.; Hu, S. Mask and Infill: Applying Masked Language Model for Sentiment Transfer. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; Kraus, S., Ed.; pp. 5271–5277. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 8 May 2023).
- Wang, Y.; Wu, Y.; Mou, L.; Li, Z.; Chao, W. Harnessing Pre-Trained Neural Networks with Rules for Formality Style Transfer. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 3571–3576. [Google Scholar] [CrossRef]
- Chen, L.; Dai, S.; Tao, C.; Shen, D.; Gan, Z.; Zhang, H.; Zhang, Y.; Carin, L. Adversarial Text Generation via Feature-Mover’s Distance. arXiv 2020, arXiv:1809.06297. [Google Scholar]
- Yin, D.; Huang, S.; Dai, X.; Chen, J. Utilizing Non-Parallel Text for Style Transfer by Making Partial Comparisons. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Luo, F.; Li, P.; Zhou, J.; Yang, P.; Chang, B.; Sun, X.; Sui, Z. A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5116–5122. [Google Scholar] [CrossRef]
- He, J.; Wang, X.; Neubig, G.; Berg-Kirkpatrick, T. A Probabilistic Formulation of Unsupervised Text Style Transfer. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Lee, J. Stable Style Transformer: Delete and Generate Approach with Encoder-Decoder for Text Style Transfer. In Proceedings of the 13th International Conference on Natural Language Generation, INLG 2020, Dublin, Ireland, 15–18 December 2020; pp. 195–204. [Google Scholar]
- Krishna, K.; Wieting, J.; Iyyer, M. Reformulating Unsupervised Style Transfer as Paraphrase Generation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 12 November 2020; pp. 737–762. [Google Scholar] [CrossRef]
- Dale, D.; Voronov, A.; Dementieva, D.; Logacheva, V.; Kozlova, O.; Semenov, N.; Panchenko, A. Text Detoxification using Large Pre-trained Neural Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 7979–7996. [Google Scholar] [CrossRef]
- Krause, B.; Gotmare, A.D.; McCann, B.; Keskar, N.S.; Joty, S.; Socher, R.; Rajani, N.F. GeDi: Generative Discriminator Guided Sequence Generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 4929–4952. [Google Scholar] [CrossRef]
- Logacheva, V.; Dementieva, D.; Ustyantsev, S.; Moskovskiy, D.; Dale, D.; Krotova, I.; Semenov, N.; Panchenko, A. ParaDetox: Detoxification with Parallel Data. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 6804–6818. [Google Scholar] [CrossRef]
- Wieting, J.; Gimpel, K. ParaNMT-50M: Pushing the Limits of Paraphrastic Sentence Embeddings with Millions of Machine Translations. arXiv 2018, arXiv:1711.05732. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Feng, S.; Wallace, E.; Grissom II, A.; Iyyer, M.; Rodriguez, P.; Boyd-Graber, J. Pathologies of Neural Models Make Interpretations Difficult. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3719–3728. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Jigsaw. Toxic Comment Classification Challenge. 2018. Available online: https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge (accessed on 1 March 2021).
- Jigsaw. Jigsaw Unintended Bias in Toxicity Classification. 2019. Available online: https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification (accessed on 1 March 2021).
- Jigsaw. Jigsaw Multilingual Toxic Comment Classification. 2020. Available online: https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification (accessed on 1 March 2021).
- Wiegand, M.; Ruppenhofer, J.; Schmidt, A.; Greenberg, C. Inducing a Lexicon of Abusive Words-–A Feature-Based Approach. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, 1–6 June 2018; pp. 1046–1056. [Google Scholar] [CrossRef]
- Plaza-Del-Arco, F.M.; Molina-González, M.D.; Ureña-López, L.A.; Martín-Valdivia, M.T. Detecting Misogyny and Xenophobia in Spanish Tweets Using Language Technologies. ACM Trans. Internet Technol. TOIT 2020, 20, 1–19. [Google Scholar]
- Palomino, M.; Grad, D.; Bedwell, J. GoldenWind at SemEval-2021 Task 5: Orthrus—An Ensemble Approach to Identify Toxicity. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Online, 5–6 August 2021; pp. 860–864. [Google Scholar] [CrossRef]
- Diaz, G. Stopwords-ISO/Stopwords-en: English Stopwords Collection.
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Wieting, J.; Berg-Kirkpatrick, T.; Gimpel, K.; Neubig, G. Beyond BLEU: Training Neural Machine Translation with Semantic Similarity. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Volume 1: Long Papers; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4344–4355. [Google Scholar] [CrossRef]
- Warstadt, A.; Singh, A.; Bowman, S.R. Neural Network Acceptability Judgments. Trans. Assoc. Comput. Linguist. 2019, 7, 625–641. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Volume 1: Long Papers, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]



{kind=link}
{kind=link}
| Dataset | Style | Train | Dev | Test | Total |
|---|---|---|---|---|---|
| ParaDetox [32] | Toxic | 11,351 | 596 | 671 | 12,618 |
| Neutral | 19,274 | 491 | 671 | 20,436 | |
| Jigsaw [37] | Toxic | 135,390 | 6648 | 10,000 | 152,038 |
| Neutral | 135,390 | 6648 | 10,000 | 152,038 |
| Lexicon | Size | Domains | Method |
|---|---|---|---|
| Abusive [40] | 2961 | Abuse, Hate | Linguistic features |
| Hurtlex [41] | 1160 | Xenophobia, Immigrant, Misogyny, Insults | WordNet, Manual |
| Orthrus [42] | 1929 | Toxicity | Toxic span |
| Paradetox-lex | 503 | Toxicity | Toxic Classifier |
| Jigsaw-Lex | 2371 | Toxicity | Toxic Classifier |
| Stopwords [43] | 1298 | Common words, Stopwords | Crowdsource |
| Dataset | Model | Lexicon | K | ACC | SIM | FL | J | BLEU |
|---|---|---|---|---|---|---|---|---|
| Paradetox | Lexicon GST | Abusive | 5 | 0.70 | 0.89 | 0.75 | 0.47 | 0.77 |
| Hurtlex | 3 | 0.48 | 0.92 | 0.79 | 0.35 | 0.82 | ||
| Orthrus | 1 | 0.78 | 0.85 | 0.69 | 0.47 | 0.73 | ||
| Dataset-specific | 1 | 0.81 | 0.83 | 0.60 | 0.42 | 0.70 | ||
| MultiLexicon GST | Abusive | 1 | 0.80 | 0.83 | 0.71 | 0.48 | 0.72 | |
| Hurtlex | 1 | 0.65 | 0.89 | 0.77 | 0.45 | 0.78 | ||
| Orthrus | 5 | 0.63 | 0.89 | 0.83 | 0.47 | 0.77 | ||
| Dataset-specific | 3 | 0.71 | 0.89 | 0.75 | 0.49 | 0.77 | ||
| Jigsaw | Lexicon GST | Abusive | 3 | 0.52 | 0.85 | 0.66 | 0.30 | 0.75 |
| Hurtlex | 1 | 0.45 | 0.86 | 0.61 | 0.24 | 0.76 | ||
| Orthrus | 3 | 0.75 | 0.80 | 0.55 | 0.32 | 0.69 | ||
| Dataset-specific | 3 | 0.78 | 0.77 | 0.58 | 0.35 | 0.69 | ||
| MultiLexicon GST | Abusive | 1 | 0.64 | 0.80 | 0.65 | 0.34 | 0.72 | |
| Hurtlex | 1 | 0.43 | 0.87 | 0.70 | 0.27 | 0.78 | ||
| Orthrus | 3 | 0.66 | 0.82 | 0.67 | 0.37 | 0.74 | ||
| Dataset-specific | 3 | 0.73 | 0.79 | 0.64 | 0.38 | 0.71 |
| Model | Lexicon | Rank |
|---|---|---|
| MultiLexiconGST | Dataset-specific | 1.0 |
| MultiLexiconGST | Abusive | 3.0 |
| MultiLexiconGST | Orthrus | 3.0 |
| LexiconGST | Orthrus | 4.5 |
| LexiconGST | Abusive | 5.0 |
| LexiconGST | Dataset-specific | 5.0 |
| MultiLexiconGST | Hurtlex | 6.75 |
| BlindedGST | - | 8.25 |
| LexiconGST | Hurtlex | 8.5 |
| Dataset | Jigsaw | Paradetox | ||||||
|---|---|---|---|---|---|---|---|---|
| Model | ACC | SIM | FL | J | ACC | SIM | FL | J |
| MultiLexiconGST w/K = 3 and w/Dataset-specific Lexicon | 0.73 | 0.79 | 0.64 | 0.38 | 0.71 | 0.89 | 0.75 | 0.49 |
| Mask and Infill [21] | 0.78 | 0.80 | 0.49 | 0.31 | 0.91 | 0.82 | 0.63 | 0.48 |
| BlindedGST [19] | 0.55 | 0.79 | 0.61 | 0.27 | 0.72 | 0.89 | 0.56 | 0.32 |
| SST [28] | 0.80 | 0.55 | 0.12 | 0.05 | 0.86 | 0.57 | 0.19 | 0.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iglesias, M.; Araque, O.; Iglesias, C.Á. A Toxic Style Transfer Method Based on the Delete–Retrieve–Generate Framework Exploiting Toxic Lexicon Semantic Similarity. Appl. Sci. 2023, 13, 8590. https://doi.org/10.3390/app13158590
Iglesias M, Araque O, Iglesias CÁ. A Toxic Style Transfer Method Based on the Delete–Retrieve–Generate Framework Exploiting Toxic Lexicon Semantic Similarity. Applied Sciences. 2023; 13(15):8590. https://doi.org/10.3390/app13158590
Chicago/Turabian StyleIglesias, Martín, Oscar Araque, and Carlos Á. Iglesias. 2023. "A Toxic Style Transfer Method Based on the Delete–Retrieve–Generate Framework Exploiting Toxic Lexicon Semantic Similarity" Applied Sciences 13, no. 15: 8590. https://doi.org/10.3390/app13158590
APA StyleIglesias, M., Araque, O., & Iglesias, C. Á. (2023). A Toxic Style Transfer Method Based on the Delete–Retrieve–Generate Framework Exploiting Toxic Lexicon Semantic Similarity. Applied Sciences, 13(15), 8590. https://doi.org/10.3390/app13158590