
Real-Time Information Fusion System Implementation Based on ARM-Based FPGA


Abstract
:1. Introduction
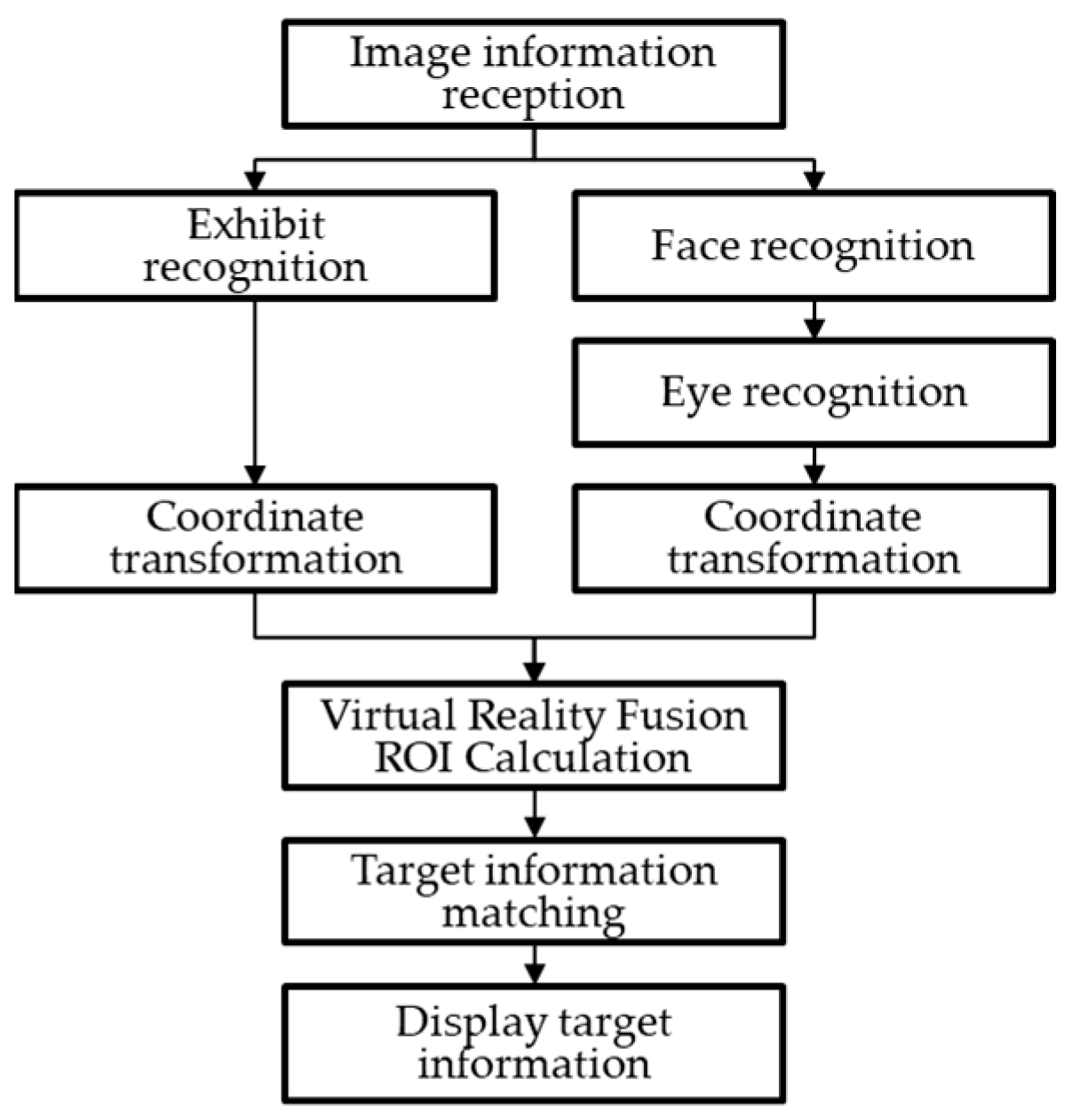
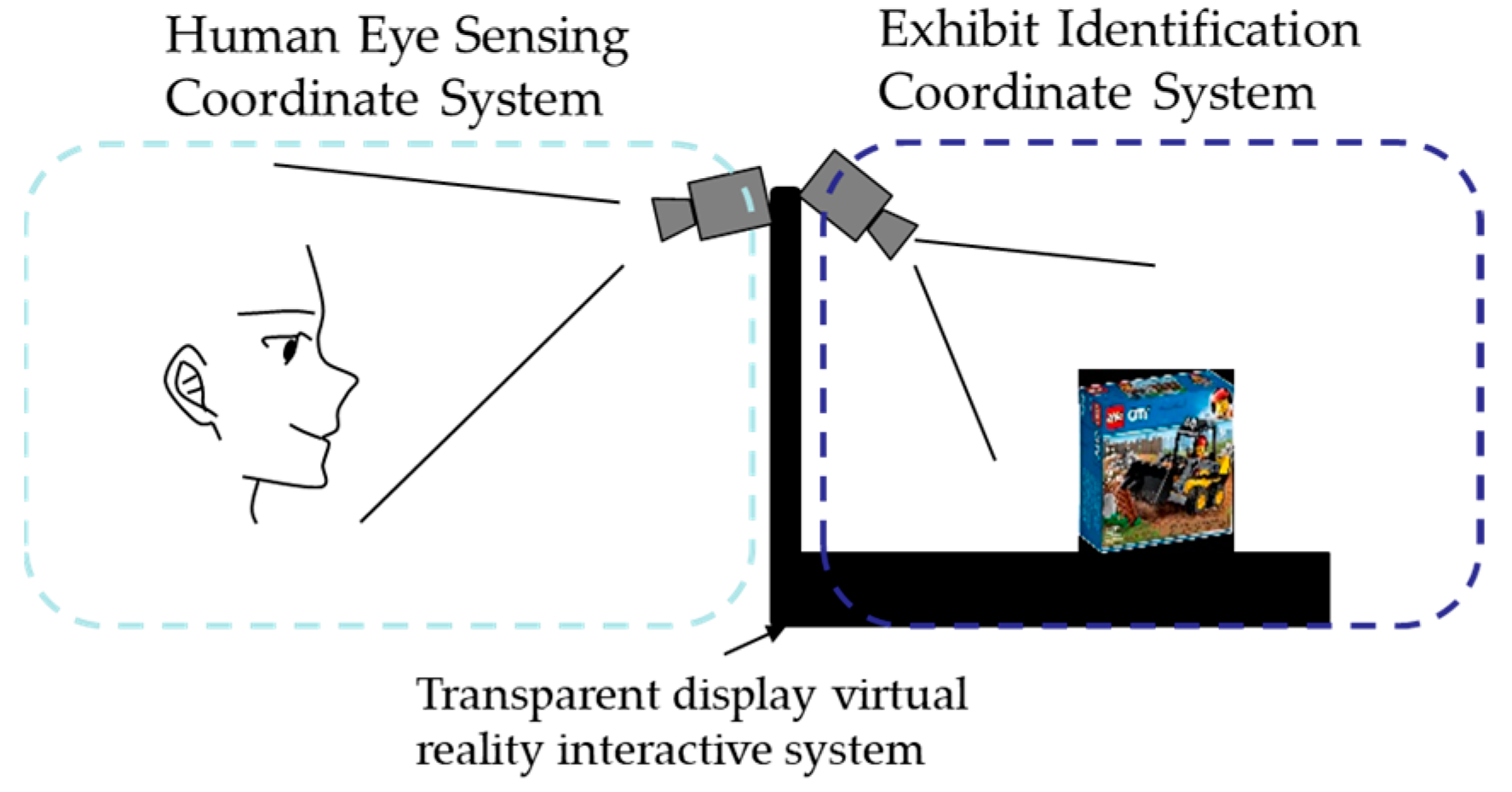
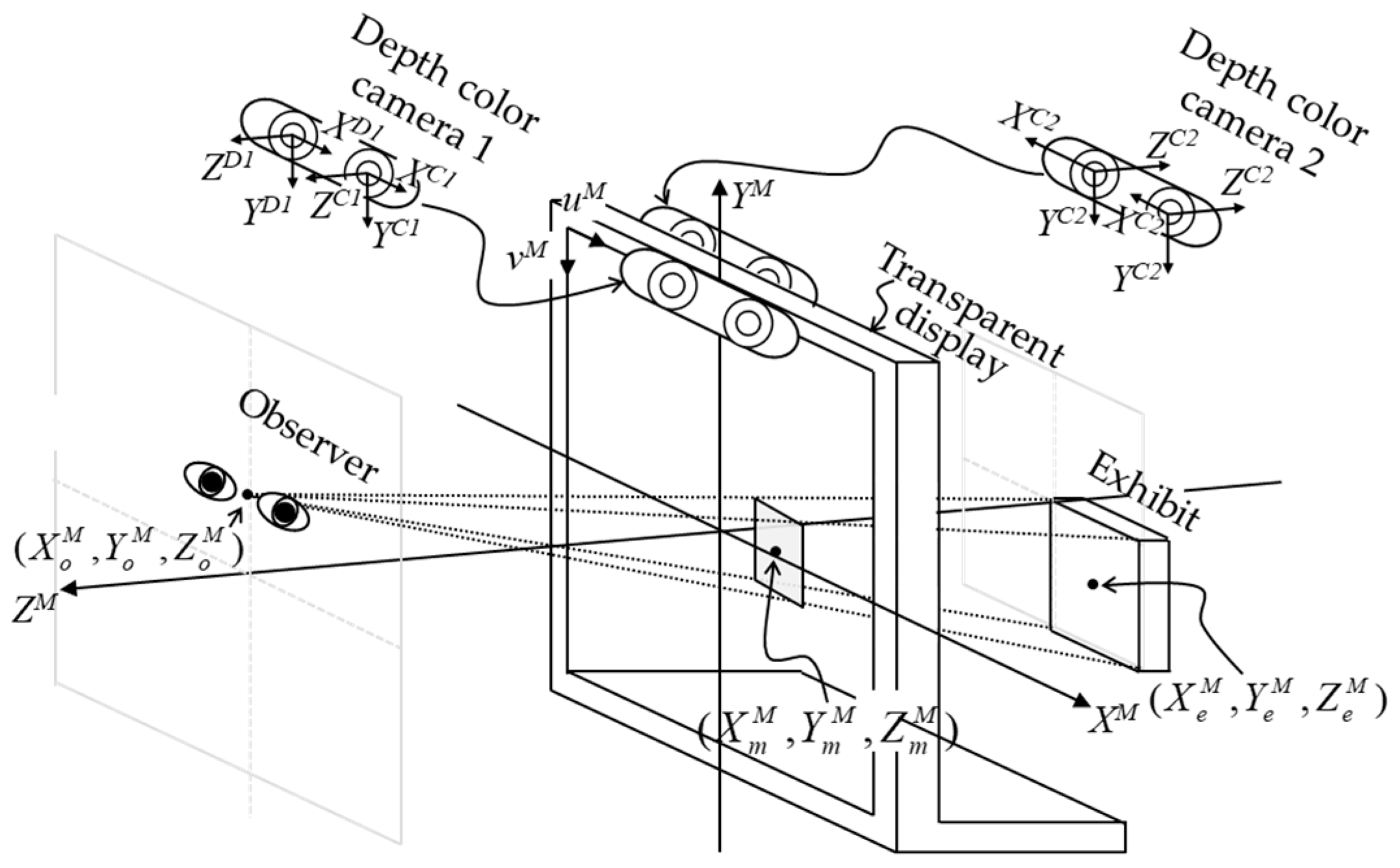
2. Information Fusion Method
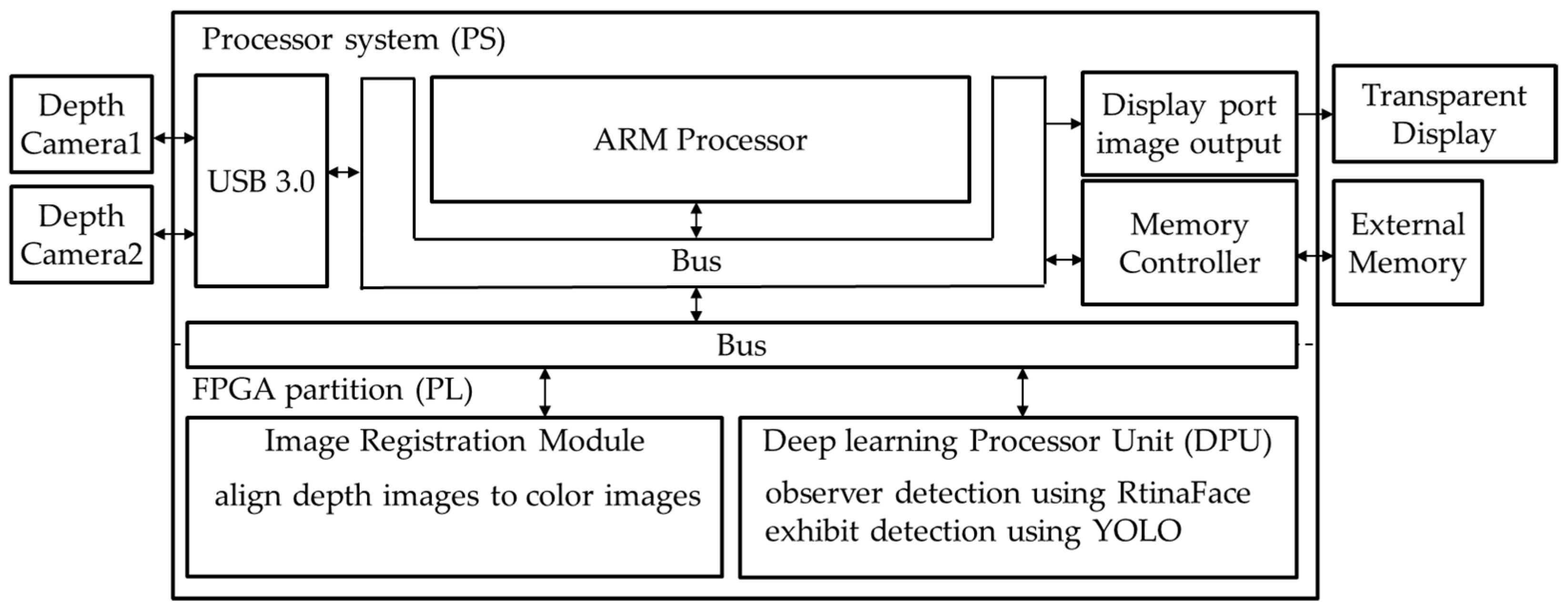
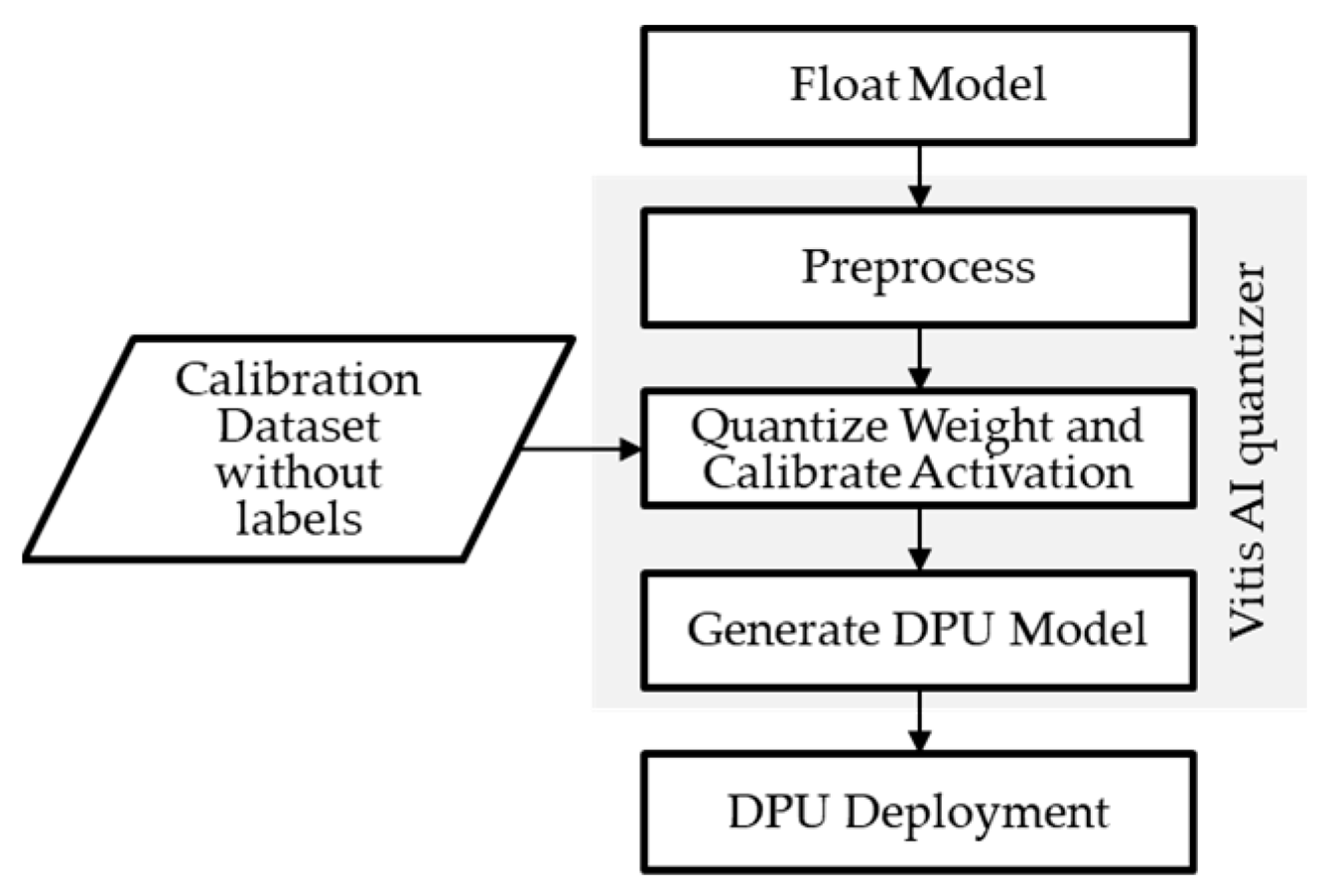
3. Implementation
4. Experimental Setup and Results
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | void align_depth_to_color_2(float intrinsics_color[4], float intrinsics_depth[4], float extrinsics_depth_to_color[12], float depth_scale ,unsigned short int depth[307200], float depth_of_color[640*480]) { |
| 2 | float pd_uv[2]; |
| 3 | float Pd_uv[3]; |
| 4 | float Pc_uv[3]; |
| 5 | unsigned short int pc_uv[2]; |
| 6 | for(int i = 0; i < 480; i++) { |
| 7 | //#pragma HLS pipeline II = 1 |
| 8 | for(int j = 0; j < 640; j++) { |
| 9 | //#pragma HLS pipeline II = 1 |
| 10 | pd_uv[0] = j; |
| 11 | pd_uv[1] = i; |
| 12 | Pd_uv[0] = (pd_uv[0]-intrinsics_depth[2]) * depth[i*640+j]*depth_scale/intrinsics_depth[0]; |
| 13 | Pd_uv[1] = (pd_uv[1]-intrinsics_depth[3]) * depth[i*640+j]*depth_scale/intrinsics_depth[1]; |
| 14 | Pd_uv[2] = depth[i*640+j]*depth_scale; |
| 15 | Pc_uv[0] = extrinsics_depth_to_color[0] * Pd_uv[0] + extrinsics_depth_to_color[1] * Pd_uv[1] + extrinsics_depth_to_color[2] * Pd_uv[2] + extrinsics_depth_to_color[3]; |
| 16 | Pc_uv[1] = extrinsics_depth_to_color[4] * Pd_uv[0] + extrinsics_depth_to_color[5] * Pd_uv[1] + extrinsics_depth_to_color[6] * Pd_uv[2] + extrinsics_depth_to_color[7]; |
| 17 | Pc_uv[2] = extrinsics_depth_to_color[8] * Pd_uv[0] + extrinsics_depth_to_color[9] * Pd_uv[1] + extrinsics_depth_to_color[10] * Pd_uv[2] + extrinsics_depth_to_color[11]; |
| 18 | pc_uv[0] = (unsigned short int)((intrinsics_color[0] * Pc_uv[0]/Pc_uv[2] + intrinsics_color[2])); |
| 19 | pc_uv[1] = (unsigned short int)((intrinsics_color[1] * Pc_uv[1]/Pc_uv[2] + intrinsics_color[3])); |
| 20 | if(pc_uv[0] < 640 && pc_uv[0] ≥ 0 && pc_uv[1] < 480 && pc_uv[0] ≥ 0 ) |
| 21 | depth_of_color[pc_uv[1] * 640 + pc_uv[0]] = Pd_uv[2]; |
| 22 | } |
| 23 | } |
| 24 | } |
References
- Santi, G.M.; Ceruti, A.; Liverani, A.; Osti, F. Augmented Reality in Industry 4.0 and Future Innovation Programs. Technologies 2021, 9, 33. [Google Scholar] [CrossRef]
- Carbone, M.; Cutolo, F.; Condino, S.; Cercenelli, L.; D’Amato, R.; Badiali, G.; Ferrari, V. Architecture of a Hybrid Video/Optical See-through Head-Mounted Display-Based Augmented Reality Surgical Navigation Platform. Information 2022, 13, 81. [Google Scholar] [CrossRef]
- Lex, J.R.; Koucheki, R.; Toor, J.; Backstein, D.J. Clinical applications of augmented reality in orthopaedic surgery: A comprehensive narrative review. Int. Orthop. 2023, 47, 375–391. [Google Scholar] [CrossRef] [PubMed]
- Titov, W.; Keller, C.; Schlegel, T. Augmented Reality Passenger Information on Mobile Public Displays—An Iterative Evaluation Approach. In HCI in Mobility, Transport, and Automotive Systems; Krömker, H., Ed.; HCII 2021; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2021; p. 12791. [Google Scholar] [CrossRef]
- Liu, Y.T.; Liao, K.Y.; Lin, C.L.; Li, Y.L. 66-2: Invited Paper: PixeLED display for transparent applications. Proceeding SID Symp. Dig. Tech. Pap. 2018, 49, 874–875. [Google Scholar] [CrossRef]
- Mohr, P.; Mori, S.; Langlotz, T.; Thomas, B.H.; Schmalstieg, D.; Kalkofen, D. Mixed reality light fields for interactive remote assistance. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar]
- Shawahna, A.; Sait, S.M.; El-Maleh, A. FPGA-based accelerators of deep learning networks for learning and classification: A review. IEEE Access 2018, 7, 7823–7859. [Google Scholar] [CrossRef]
- Rizzatti, L. A Breakthrough in FPGA-Based Deep Learning Inference. Available online: https://www.eeweb.com/a-breakthrough-in-fpga-based-deep-learning-inference/ (accessed on 18 July 2023).
- Farabet, C.; Poulet, C.; Han, J.Y.; LeCun, Y. Cnp: An FPGA-based processor for convolutional networks. In Field Programmable Logic and Applications; IEEE: Prague, Czech Republic, 2009; pp. 32–37. [Google Scholar] [CrossRef]
- Denton, E.L.; Bruna, W.J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 8–11 December 2014; pp. 1269–1277. [Google Scholar]
- LeCun, Y.J.; Denker, S.; Solla, S.A. Optimal brain damage. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1989; pp. 598–605. [Google Scholar]
- Hanson, S.J.; Pratt, L.Y. Comparing biases for minimal network construction with back-propagation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; pp. 177–185. [Google Scholar]
- Hassibi, B.; Stork, D.G. Second order derivatives for network pruning: Optimal brain surgeon. In Proceedings of the Advances in Neural Information Processing Systems, San Francisco, CA, USA, 30 November–3 December 1992; pp. 164–171. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the International Conference on Machine Learning (PMLR 2015), Lille, France, 6–11 July 2015; pp. 1737–1746. [Google Scholar]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-eye: A complete design flow for mapping CNN onto embedded FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 35–47. [Google Scholar] [CrossRef]
- Migacz, S. 8-Bit Inference with TensorRT. Available online: https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf (accessed on 18 July 2023).
- Lyu, S.; Zhao, Y.; Li, R.; Li, Z.; Fan, R.; Li, Q. Embedded Sensing System for Recognizing Citrus Flowers Using Cascaded Fusion YOLOv4-CF + FPGA. Sensors 2022, 22, 1255. [Google Scholar] [CrossRef] [PubMed]
- Pérez, I.; Figueroa, M. A Heterogeneous Hardware Accelerator for Image Classification in Embedded Systems. Sensors 2021, 21, 2637. [Google Scholar] [CrossRef] [PubMed]




| Parameters | Origin | For Xilinx DPU |
|---|---|---|
| Input image weight | 608 | 512 |
| Input image height | 608 | 512 |
| Activation function | mish | leaky |
| Max-pooling size 1 | 9 | 6 |
| Max-pooling size 2 | 13 | 8 |
| Module Name | LUT | LUTAsMem | REG | BRAM | DSP |
|---|---|---|---|---|---|
| DPUCZDX8G_1 | 51,082 | 5680 | 97,940 | 257 | 690 |
| (19.69%) | (3.98%) | (18.86%) | (30.82%) | (27.38%) | |
| DPUCZDX8G_2 | 51,308 | 5680 | 98,128 | 257 | 690 |
| (19.78%) | (3.98%) | (18.90%) | (30.82%) | (27.38%) | |
| Image registration | 11,568 | 981 | 18,923 | 15 | 74 |
| (4.46%) | (0.69%) | (3.64%) | (1.80%) | (2.94%) | |
| sfm_xrt_top | 9638 | 540 | 8142 | 4 | 14 |
| (3.71%) | (0.38%) | (1.57%) | (0.48%) | (0.56%) | |
| Total Utilization | 138,219 | 14,139 | 251,993 | 612 | 1468 |
| (50.00%) | (10.00%) | (46.00%) | (67.00%) | (58.00%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, Y.-H.; Yan, Y.-J.; Hsiao, M.-H.; Yu, T.-Y.; Ou-Yang, M. Real-Time Information Fusion System Implementation Based on ARM-Based FPGA. Appl. Sci. 2023, 13, 8497. https://doi.org/10.3390/app13148497
Tsai Y-H, Yan Y-J, Hsiao M-H, Yu T-Y, Ou-Yang M. Real-Time Information Fusion System Implementation Based on ARM-Based FPGA. Applied Sciences. 2023; 13(14):8497. https://doi.org/10.3390/app13148497
Chicago/Turabian StyleTsai, Yu-Hsiang, Yung-Jhe Yan, Meng-Hsin Hsiao, Tzu-Yi Yu, and Mang Ou-Yang. 2023. "Real-Time Information Fusion System Implementation Based on ARM-Based FPGA" Applied Sciences 13, no. 14: 8497. https://doi.org/10.3390/app13148497
APA StyleTsai, Y.-H., Yan, Y.-J., Hsiao, M.-H., Yu, T.-Y., & Ou-Yang, M. (2023). Real-Time Information Fusion System Implementation Based on ARM-Based FPGA. Applied Sciences, 13(14), 8497. https://doi.org/10.3390/app13148497