





K-Means Clustering of 51 Geospatial Layers Identified for Use in Continental-Scale Modeling of Outdoor Acoustic Environments

 , , , and
, , , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Geospatial Layers
2.2. Acoustic Data
2.3. K-Means Clustering
2.4. Subclustering
3. Results and Discussion
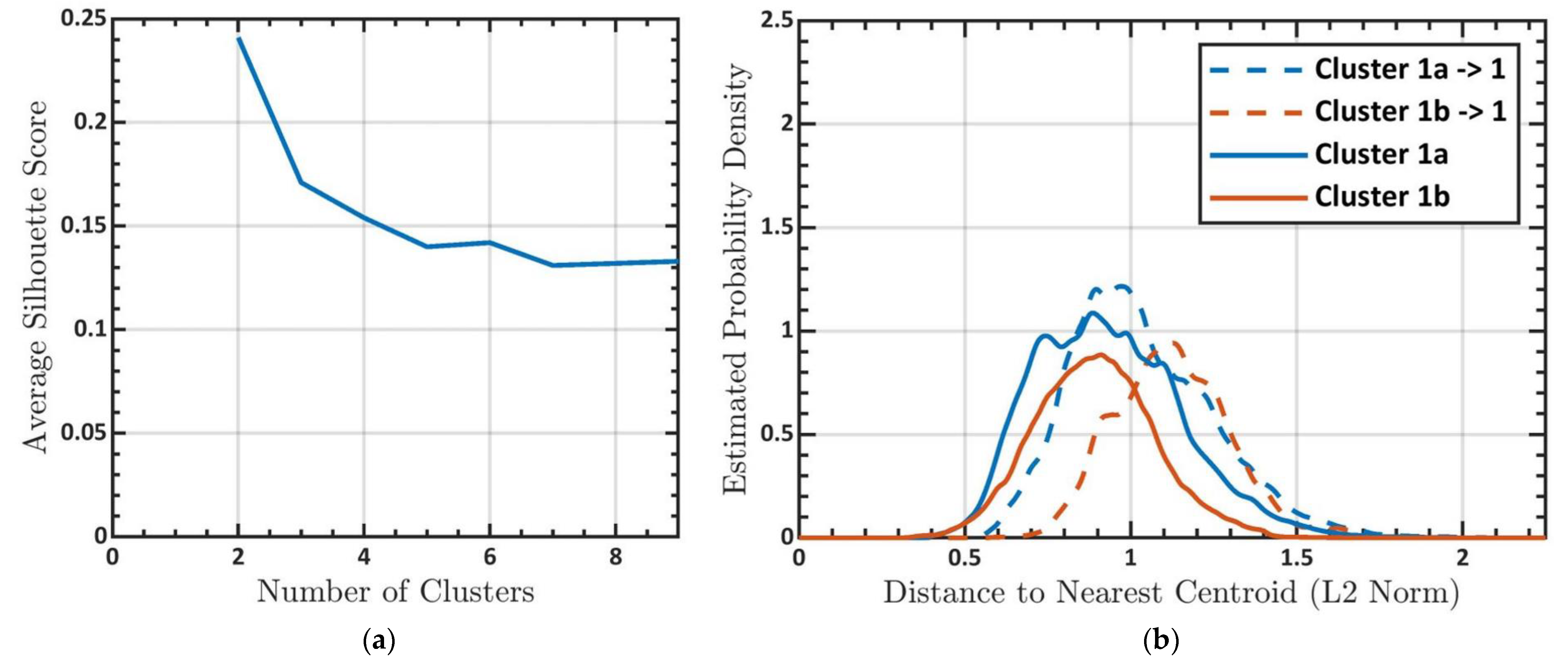
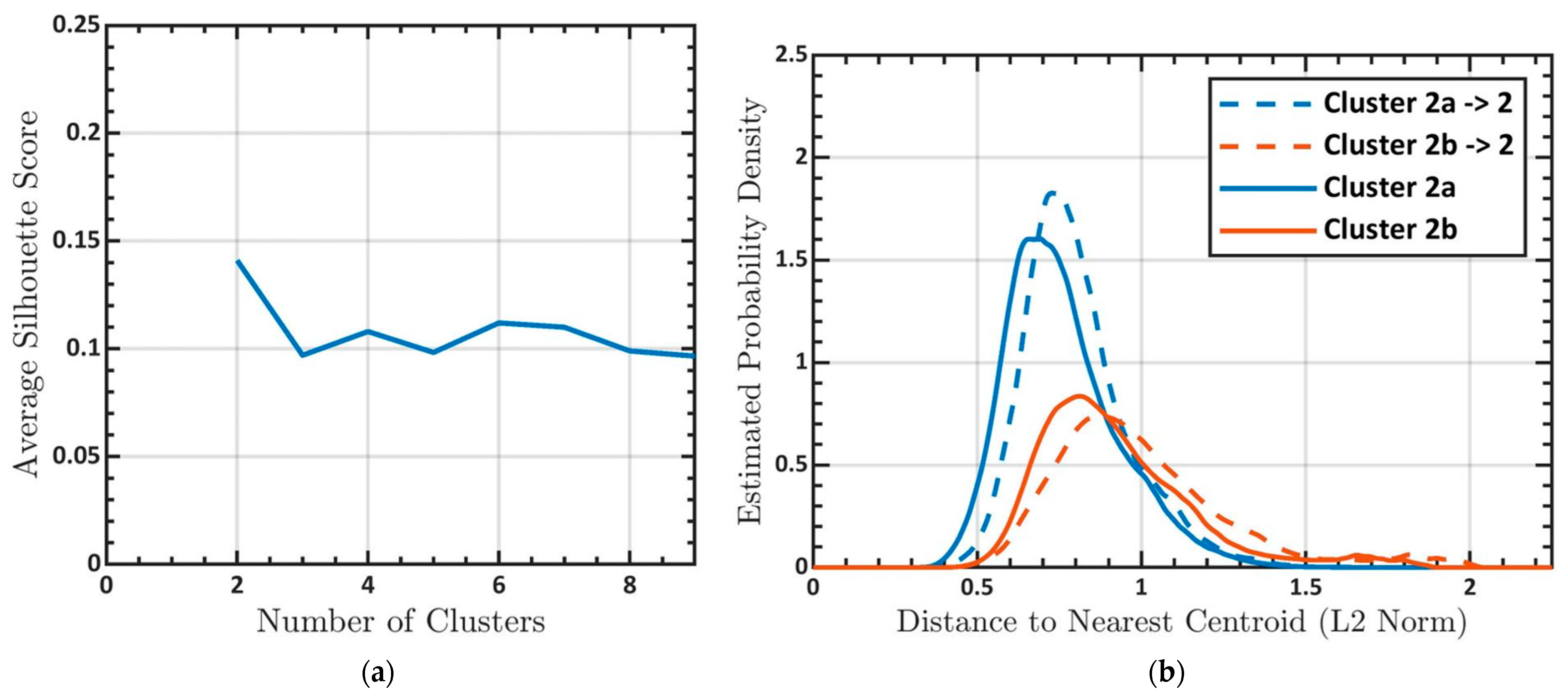
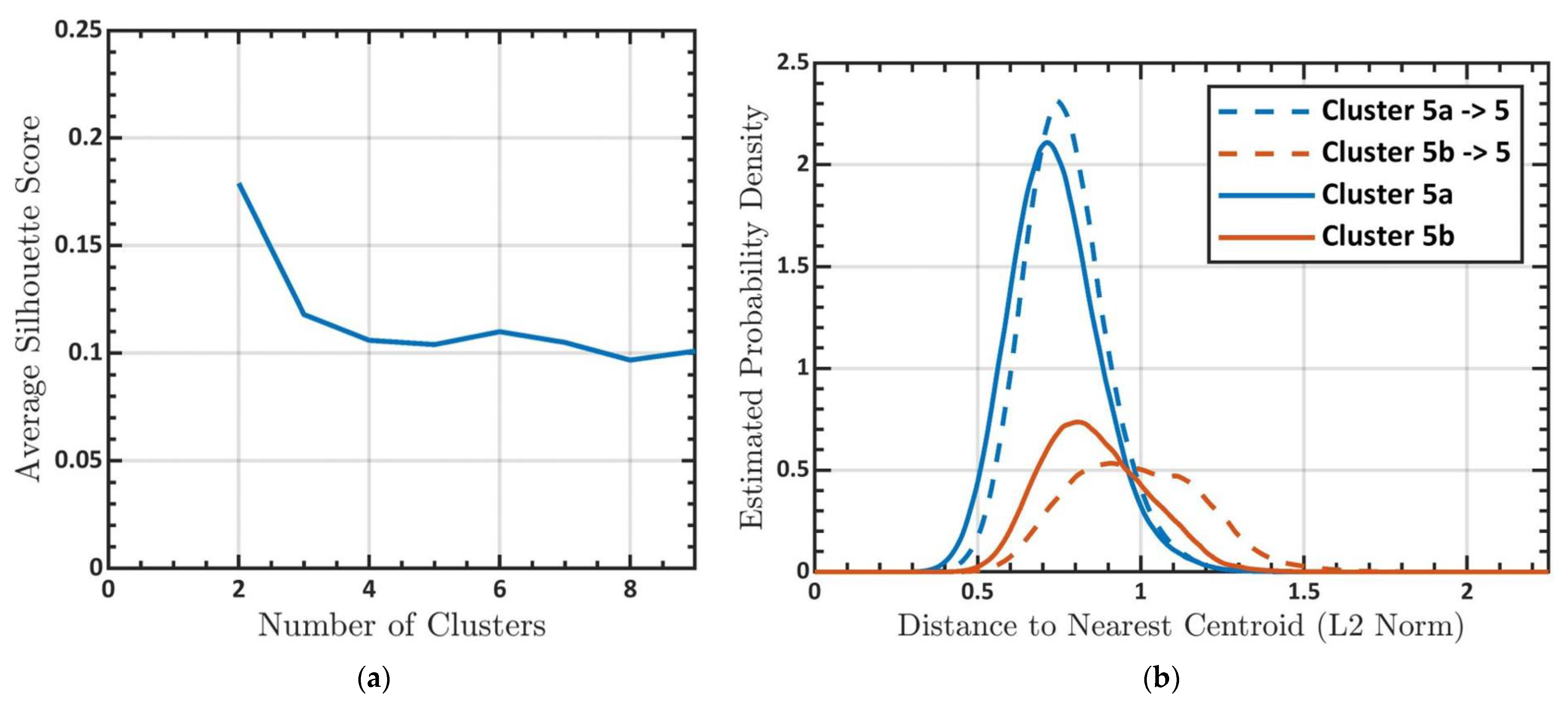
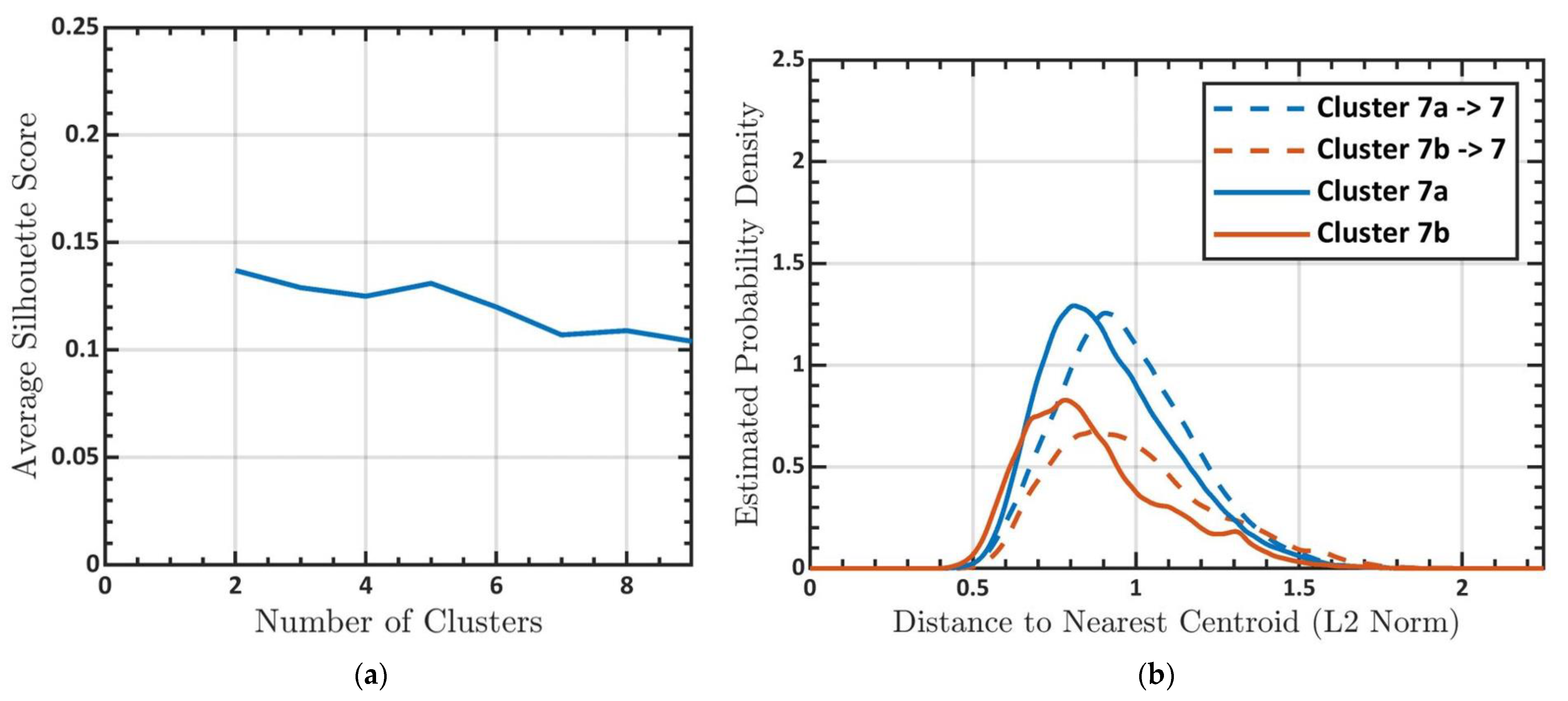
3.1. Determining the Number of Clusters
3.2. Eight-Cluster Model
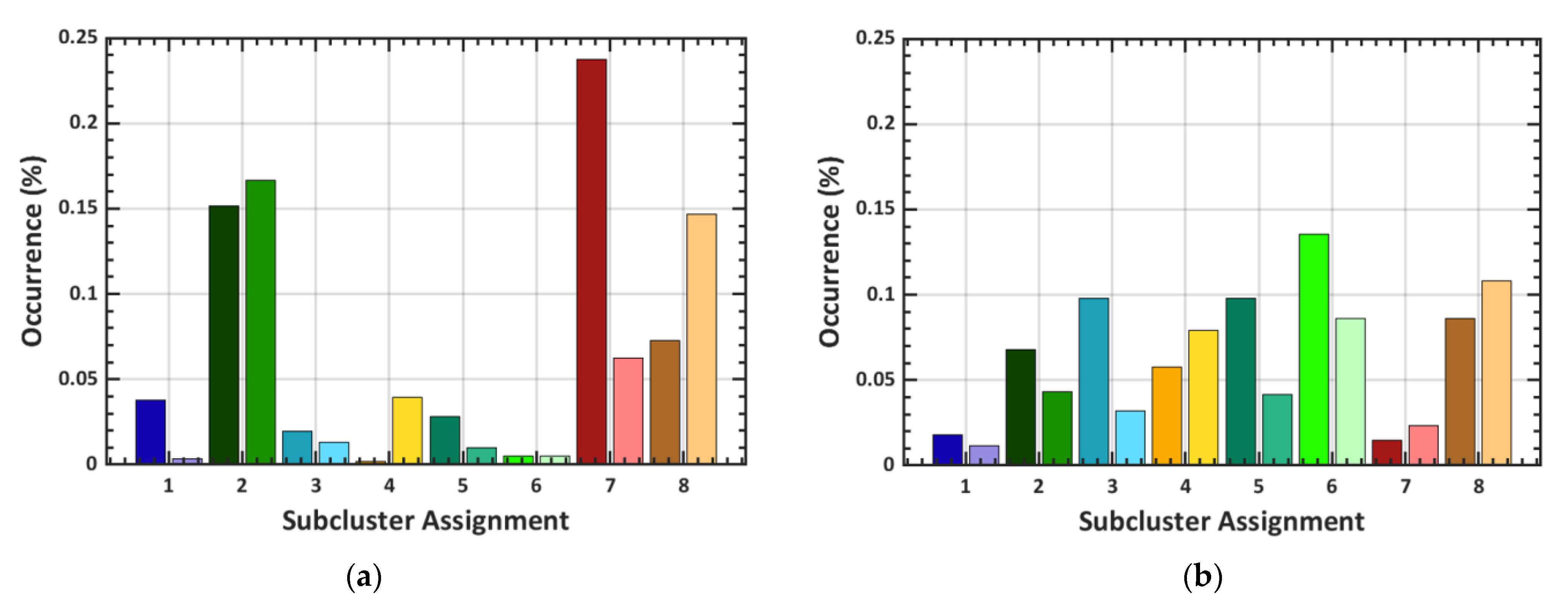
3.3. Subclustering
3.4. General Applications
3.5. Limitations of General Applications
3.6. Application to Outdoor Sound Level Modeling
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Area of Analysis | Description | Units |
|---|---|---|---|
| Topography Elevation Slope | Point Point | Digital elevation, height above sea level Rate of change in elevation | m degrees |
| Climate PPTSummer PPTWinter TMaxSummer TmaxWinter TminSummer TminWinter TdewAvgSummer TdewAvgWinter | Point Point Point Point Point Point Point Point | 10-year average summer precipitation 10-year average winter precipitation 10-year average summer maximum temperature 10-year average winter maximum temperature 10-year average summer minimum temperature 10-year average winter minimum temperature 10-year average summer minimum dew point 10-year average winter maximum dew point | mm mm °C °C °C °C °C °C |
| Land Cover Barren Cultivated Deciduous Developed Evergreen Herbaceous Mixed Forest Shrubland Water Wetlands | 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km 200 m, 5 km | Proportion of barren land cover Proportion of cultivated land cover Proportion of deciduous forest land cover Proportion of developed land cover Proportion of evergreen forest land cover Proportion of herbaceous land cover Proportion of mixed forest land cover Proportion of shrubland land cover Proportion of water (only) land cover Proportion of wetlands land cover | % % % % % % % % % % |
| Hydrology DistCoast DistStreamO | Point Point | Distance to nearest coastline Distance to nearest stream with Strahler order greater than 1, 3, or 4 | m m |
| Anthropogenic DistAirpHeli DistAirpHigh DistAirpLow DistAirpMod DistAirpMoto DistMilitary DistRailroads DistRoadsAll DistRoadsMaj FlightFreq MilitarySum PopDensity RddAll RddMajor VIIRS | Point Point Point Point Point Point Point Point Point 25 km 40 km Point Point, 5 km Point, 5 km 270 m | Distance to nearest heliport Distance to nearest high-volume airport Distance to nearest low-volume airport Distance to nearest moderate-volume airport Distance to nearest airport (any type) Distance to nearest military flight path Distance to nearest rail line Distance to nearest road (all roads) Distance to nearest road (major roads) Total weekly flight observations Sum of designated military flight paths 2010 Census population density data Road density, sum of road lengths (all roads) divided by area of interest Road density, sum of road lengths (major roads only) divided by area of interest Mean upward radiance at night | m m m m m m m m m count count persons/km2 km/km2 km/km2 nW/cm2/sr |
Appendix B









References
- Fink, D. Ambient Noise Is “The New Secondhand Smoke”. Acoust. Today 2019, 15, 38–46. [Google Scholar] [CrossRef]
- Kight, C.R.; Swaddle, J.P. How and why environmental noise impacts animals: An integrative, mechanistic review. Ecol. Lett. 2011, 14, 1052–1061. [Google Scholar] [CrossRef] [PubMed]
- Francis, C.D.; Ortega, C.P.; Cruz, A. Noise pollution changes avian communities and species interactions. Curr. Biol. 2009, 19, 1415–1419. [Google Scholar] [CrossRef] [PubMed]
- Rako-Gospić, N.; Picciulin, M. Underwater noise: Sources and effects on marine life. In World Seas: An Environmental Evaluation, 2nd ed.; Sheppard, C., Ed.; Academic Press: Cambridge, MA, USA, 2019; Volume 3, pp. 367–389. [Google Scholar] [CrossRef]
- Sun, J.W.; Narins, P.M. Anthropogenic sounds differentially affect amphibian call rate. Biol. Conserv. 2005, 121, 419–427. [Google Scholar] [CrossRef]
- Buxton, R.T.; McKenna, M.F.; Mennitt, D.; Brown, E.; Fristrup, K.; Crooks, K.R.; Angeloni, L.M.; Wittemyer, G. Anthropogenic noise in US national parks–sources and spatial extent. Front. Ecol. Environ. 2019, 17, 559–564. [Google Scholar] [CrossRef]
- Jones, N.F.; Pejchar, L.; Kiesecker, J.M. The Energy Footprint: How Oil, Natural Gas, and Wind Energy Affect Land for Biodiversity and the Flow of Ecosystem Services. BioScience 2015, 65, 290–301. [Google Scholar] [CrossRef]
- Sueur, J. Cicada acoustic communication: Potential sound partitioning in a multispecies community from Mexico (Hemiptera: Cicadomorpha: Cicadidae). Biol. J. Linn. Soc. 2002, 75, 379–394. [Google Scholar] [CrossRef]
- Berg, K.S.; Brumfield, R.T.; Apanius, V. Phylogenetic and ecological determinants of the neotropical dawn chorus. Proc. R. Soc. Ser. B Biol. Sci. 2006, 273, 999–1005. [Google Scholar] [CrossRef]
- Aylor, D. Noise reduction by vegetation and ground. J. Acoust. Soc. Am. 1972, 51, 197–205. [Google Scholar] [CrossRef]
- Ayad, Y.M. Remote Sensing and GIS in modeling visual landscape change: A case study of the northwestern arid coast of Egypt. Landscape Urban Plann. 2005, 73, 307–325. [Google Scholar] [CrossRef]
- Statuto, D.; Cillis, G.; Picuno, P. GIS-based Analysis of Temporal Evolution of Rural Landscape: A Case Study in Southern Italy. Nat. Resour. Res. 2019, 28, S61–S75. [Google Scholar] [CrossRef]
- Kobler, A.; Adamic, M. Identifying brown bear habitat by a combined GIS and machine learning method. Ecol. Modell. 2000, 135, 291–300. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Dai, H.; Xu, B.; Yang, H.; Feng, H.; Li, Z.; Yang, X. Modeling maize above-ground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods 2019, 15, 10. [Google Scholar] [CrossRef] [PubMed]
- Aytaç, E. Unsupervised learning approach in defining the similarity of catchments: Hydrological response unit based k-means clustering, a demonstration on Western Black Sea Region of Turkey. Int. Soil Water Conserv. Res. 2020, 8, 321–331. [Google Scholar] [CrossRef]
- Abedi, M.; Norouzi, G.H.; Torabi, S.A. Clustering of mineral prospectivity area as an unsupervised classification approach to explore copper deposit. Arabian J. Geosci. 2013, 6, 3601–3613. [Google Scholar] [CrossRef]
- Grekousis, G.; Manetos, P.; Photis, Y.N. Modeling urban evolution using neural networks, fuzzy logic and GIS: The case of the Athens Metropolitan area. Cities 2013, 20, 193–203. [Google Scholar] [CrossRef]
- Ahmed, K.R.; Akter, S.; Marandi, A.; Schüth, C. A simple and robust wetland classification approach by using optical indices, unsupervised and supervised machine learning algorithms. Remote Sens. Appl. Soc. Environ. 2021, 23, 100569. [Google Scholar] [CrossRef]
- Chang, Z.; Du, Z.; Zhang, F.; Huang, F.; Chen, J.; Li, W.; Guo, Z. Landslide susceptibility prediction based on remote sensing images and GIS: Comparisons of supervised and unsupervised machine learning models. Remote Sens. 2020, 12, 502. [Google Scholar] [CrossRef]
- Rozenstein, O.; Karnieli, A. Comparison of methods for land-use classification incorporating remote sensing and GIS inputs. Appl. Geogr. 2011, 31, 533–544. [Google Scholar] [CrossRef]
- Keyel, A.C.; Reed, S.E.; McKenna, M.F.; Wittemyer, G. Modeling anthropogenic noise propagation using the Sound Mapping Tools ArcGIS toolbox. Environ. Model. Softw. 2017, 97, 56–60. [Google Scholar] [CrossRef]
- Aguilera, I.; Foraster, M.; Basagaña, X.; Corradi, E.; Deltell, A.; Morelli, X.; Phuleria, H.C.; Ragettli, M.S.; Rivera, M.; Thomasson, A.; et al. Application of land use regression modelling to assess the spatial distribution of road traffic noise in three European cities. J. Exposure Sci. Environ. Epidemiol. 2015, 25, 97–105. [Google Scholar] [CrossRef]
- Chang, T.Y.; Liang, C.H.; Wu, C.F.; Chang, L.T. Application of land-use regression models to estimate sound pressure levels and frequency components of road traffic noise in Taichung, Taiwan. Environ. Int. 2019, 131, 104959. [Google Scholar] [CrossRef]
- Xie, D.; Liu, Y.; Chen, J. Mapping Urban Environmental Noise: A Land Use Regression Method. Environ. Sci. Technol. 2011, 45, 7358–7364. [Google Scholar] [CrossRef]
- Mennitt, D.J.; Fristrup, K.M. Influence factors and spatiotemporal patterns of environmental sound levels in the contiguous United States. Noise Control Eng. J. 2016, 64, 342–353. [Google Scholar] [CrossRef]
- Pedersen, K.; Transtrum, M.K.; Gee, K.L.; Lympany, S.V.; James, M.M.; Salton, A.R. Validating two geospatial models of continental-scale environmental sound levels. JASA Express Lett. 2021, 1, 122401. [Google Scholar] [CrossRef] [PubMed]
- Eve, S. The embodied GIS. Using Mixed Reality to explore multi-sensory archaeological landscapes. Internet Archaeol. 2017, 44. [Google Scholar] [CrossRef]
- Primeau, K.E.; Witt, D.E. Soundscapes in the past: Investigating sound at the landscape level. J. Archaeol. Sci. Rep. 2018, 19, 875–885. [Google Scholar] [CrossRef]
- Hong, J.Y.; Jeon, J.Y. Soundscape mapping in urban contexts using GIS techniques. Inter-Noise 2014. [Google Scholar]
- Youssoufi, S.; Houot, H.; Viudel, G.; Pujol, S.; Mauny, F.; Foltete, J.-C. Combining visual and noise characteristics of a neighborhood environment to model residential satisfactions: An application of GIS-based metrics. Landsc. Urban Plan. 2020, 204, 103932. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.-S. Unsupervised K-Means Clustering Algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- DataStore—Geospatial Sound Modeling. Available online: https://irma.nps.gov/DataStore/Reference/Profile/2217356 (accessed on 3 June 2020).
- Nelson, L.; Kinseth, M.; Flowe, T. Explanatory Variable Generation for Geospatial Sound Modeling–Standard Operating Procedure. Natural Resource Report NPS/NRSS/NRR–2015/936. National Park Service, Fort Collins, Colorado. 2015. Available online: https://irma.nps.gov/App/Reference/Profile/2221202 (accessed on 3 June 2020).
- Pedersen, K.; Transtrum, M.K.; Gee, K.L.; Lympany, S.V.; James, M.J.; Salton, A.R. Feature Selection for a Continental-Scale Geospatial Model of Environmental Sound Levels. In Review.
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Bholowalia, P.; Kumar, A. EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Sun, J.; Li, Z.; Zou, F.; Yang, Y. Adaptive Determining for Optimal Cluster Number of K-Means Clustering Algorithm. In Proceedings of the 2012 International Conference on Information Technology and Software Engineering: Information Technology & Computing Intelligence, Beijing, China, 8–10 December 2012; pp. 551–560. [Google Scholar] [CrossRef]
- Huan, D.; Nguyen, D.T. An adaptive method to determine the number of clusters in clustering process. In Proceedings of the 2014 International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 3–5 June 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Patil, C.; Baidari, I. Estimating the Optimal Number of Clusters k in a Dataset Using Data Depth. Data Sci. Eng. 2019, 4, 132–140. [Google Scholar] [CrossRef]
- Moudon, A.V. Real Noise from the Urban Environment: How Ambient Community Noise Affects Health and What Can Be Done About It. Am. J. Prev. Med. 2009, 37, 167–171. [Google Scholar] [CrossRef]






| Cluster Number | Rank 1 | Rank 2 | Rank 3 |
|---|---|---|---|
| 1 | Water (0.91) | DistCoast (−0.44) | DistRoadsAll (0.35) |
| 2 | Evergreen (0.78) | Slope (0.46) | TMinSummer (−0.46) |
| 3 | TdewAvgWinter (0.50) | Wetlands (0.49) | TMinWinter (0.42) |
| 4 | Herbaceous (0.88) | PPTWinter (−0.28) | DistAirpHigh (0.28) |
| 5 | Deciduous (0.84) | MixedForest (0.29) | PPTSummer (0.27) |
| 6 | Cultivated (0.89) | Shrubland (−0.32) | DistRailroads (−0.29) |
| 7 | Developed (0.76) | RddMajor (0.70) | RddAll (0.67) |
| 8 | Shrubland (0.90) | PPTSummer (−0.49) | TdewAvgSummer (−0.44) |
| Subcluster Number | Rank 1 | Rank 2 | Rank 3 |
|---|---|---|---|
| 1a | Water (0.70) | DistCoast (−0.58) | DistRoadsAll (0.34) |
| 1b | Water (0.60) | DistRoadsAll (0.14) | TMaxWinter (−0.08) |
| 2a | Evergreen (0.78) | Slope (0.38) | TMinSummer (−0.34) |
| 2b | Elevation (0.31) | Evergreen (0.30) | TMinSummer (−0.29) |
| 3a | TdewAvgWinter (0.43) | TMaxWinter (0.37) | TMinWinter (0.37) |
| 3b | Wetlands (0.79) | PPTSummer (0.27) | TdewAvgWinter (0.23) |
| 4a | Herbaceous (0.57) | DistMilitary (−0.18) | TMaxSummer (0.15) |
| 4b | Herbaceous (0.63) | DistAirpHigh (0.31) | TMinWinter (−0.27) |
| 5a | Deciduous (0.78) | PPTSummer (0.25) | FlightFreq_25km (0.25) |
| 5b | MixedForest (0.39) | Deciduous (0.29) | TMaxWinter (−0.27) |
| 6a | Cultivated (0.65) | DistAirpHeli (−0.28) | Elevation (−0.27) |
| 6b | Cultivated (0.53) | TMinWinter (−0.31) | TMaxWinter (−0.27) |
| 7a | Developed (0.44) | RddAll (0.31) | RddMajor (0.30) |
| 7b | RddMajor (0.74) | Developed (0.74) | RddAll (0.67) |
| 8a | Shrubland (0.59) | TMaxSummer (0.41) | TMaxWinter (0.36) |
| 8b | Shrubland (0.62) | TdewAvgSummer (−0.48) | Elevation (0.45) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pedersen, K.; Jensen, R.R.; Hall, L.K.; Cutler, M.C.; Transtrum, M.K.; Gee, K.L.; Lympany, S.V. K-Means Clustering of 51 Geospatial Layers Identified for Use in Continental-Scale Modeling of Outdoor Acoustic Environments. Appl. Sci. 2023, 13, 8123. https://doi.org/10.3390/app13148123
Pedersen K, Jensen RR, Hall LK, Cutler MC, Transtrum MK, Gee KL, Lympany SV. K-Means Clustering of 51 Geospatial Layers Identified for Use in Continental-Scale Modeling of Outdoor Acoustic Environments. Applied Sciences. 2023; 13(14):8123. https://doi.org/10.3390/app13148123
Chicago/Turabian StylePedersen, Katrina, Ryan R. Jensen, Lucas K. Hall, Mitchell C. Cutler, Mark K. Transtrum, Kent L. Gee, and Shane V. Lympany. 2023. "K-Means Clustering of 51 Geospatial Layers Identified for Use in Continental-Scale Modeling of Outdoor Acoustic Environments" Applied Sciences 13, no. 14: 8123. https://doi.org/10.3390/app13148123
APA StylePedersen, K., Jensen, R. R., Hall, L. K., Cutler, M. C., Transtrum, M. K., Gee, K. L., & Lympany, S. V. (2023). K-Means Clustering of 51 Geospatial Layers Identified for Use in Continental-Scale Modeling of Outdoor Acoustic Environments. Applied Sciences, 13(14), 8123. https://doi.org/10.3390/app13148123