Traditional methods for QAC accomplish the task in two steps. The first step involves extracting candidates to increase recall. MPC [
8] expands each query to a high-dimensional feature vector and uses cosine similarity to find the top N candidates from historical queries with the same prefix. Other approaches generate query suggestions from additional corpora to offer more accurate recommendations [
9,
10]. The second step involves re-ranking the candidates with additional features to increase precision [
11]. Several kinds of additional information have been exploited for this task, including context or session information [
8,
12], personalization [
8,
13], time/popularity sensitivity [
8,
14,
15], user behaviors [
16,
17,
18,
19], and click-through logs [
20]. To overcome traditional methods’ insufficient feature extraction ability, neural network methods have been adopted in recent years. Neural language models can seamlessly incorporate additional features, such as user ID embeddings to model personalization [
21,
22]. Time-aware [
11] and spelling-error-aware models [
23] have also been developed under this framework to increase the accuracy rate. Deep neural networks, such as ELMo [
24] and BERT, learn high-quality, deep contextualized word representations using deep neural models that can be directly integrated into various tasks for performance boosting. However, these models contain millions of parameters, making their application in practice difficult when computational resources are limited.
Knowledge distillation [
25] is a promising framework for reducing the size of models. Several methods have been developed to leverage linguistic knowledge to make the distillation process more informative. Cui et al. proposed a method, where the student layer can learn from multiple consecutive teacher layers to obtain more comprehensive supervision information [
26]. A soft-attention mechanism is used to determine the impact of different layers on the learning process. Similarly, Jiao et al. developed three types of loss functions that encourage the effective transfer of linguistic knowledge from teacher layers to the student model [
27]. The losses are applied to different parts of the network, including the embedding layer, the transformer layer, and the prediction layer. The ultimate goal of these knowledge-distillation methods is to enable the student model to accurately mimic the characteristics of the teacher model, such as its hidden representations [
28], output probabilities [
25], or even the generated sentences themselves [
29].
In contrast to the previous approaches, this paper proposes a novel approach to simultaneously address both critical and challenging problems by introducing a discriminator into the knowledge-distillation framework. Notably, our framework offers an easy extension to the existing distillation methods mentioned above.
2.1. Details of the Model
In this section, we introduce a standard knowledge-distillation method for compressing GPT-2 and present our proposed Dis-KD in detail.
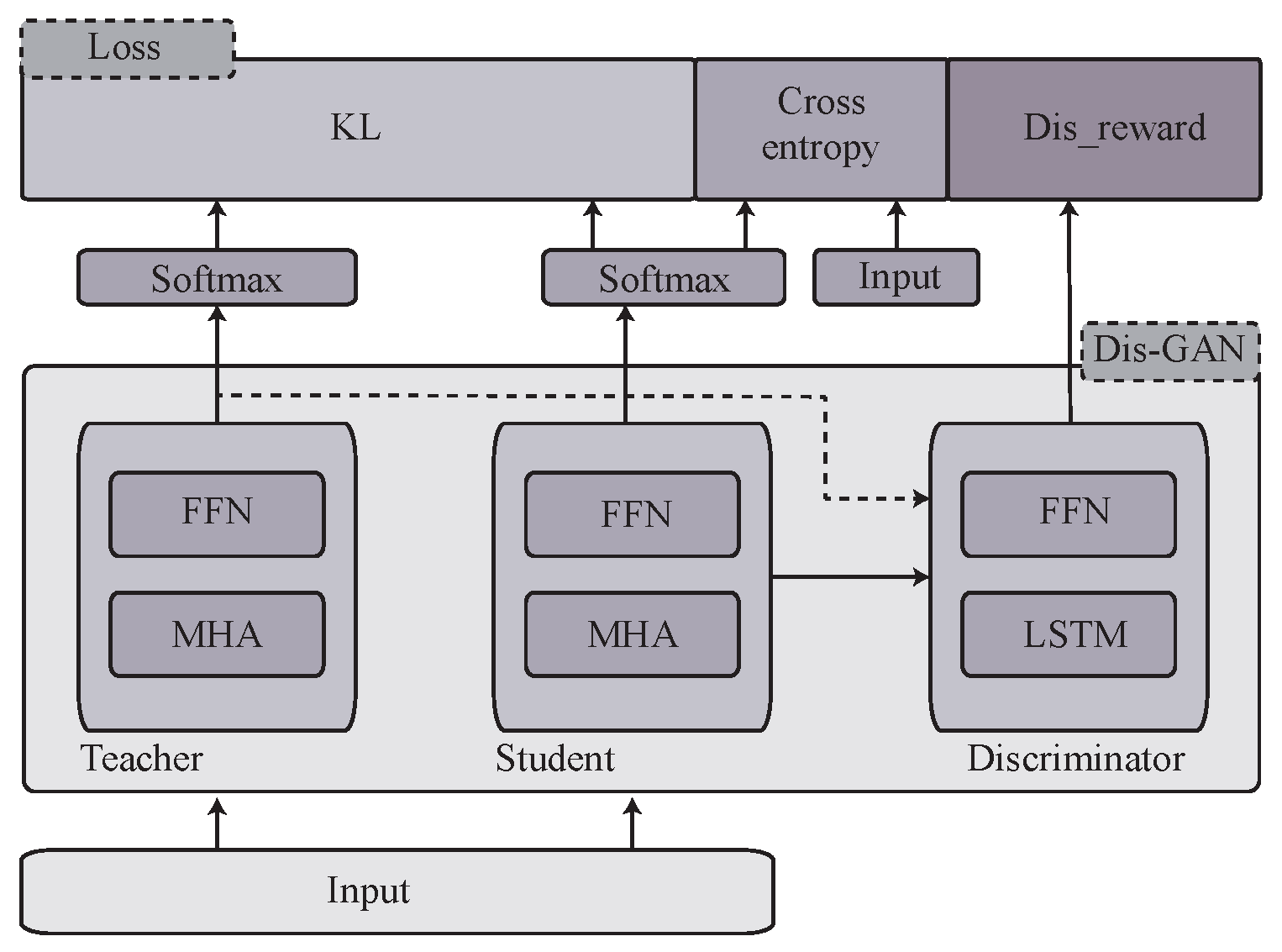
Problem Definition The original large teacher network is represented by a function , where the x is the input to the network, and denotes the model parameters. The goal of knowledge distillation is to learn a new set of parameters such that the student network can achieve similar performance to the teacher, with a much lower computational cost. The traditional strategy is to force the student model to imitate outputs from the teacher model on the training dataset with a KL divergence. We add an additional discriminator signal to enhance this process.
In our experimental configuration, we employ a teacher network denoted as , a deep language model, such as GPT-2. On the other hand, the student network is a lighter model comprising fewer layers. We utilize the QAC dataset, which contains a set of sequences denoted as . Here, each corresponds to a word, subword, or character in the sequence. The input instance for GPT-2 is constructed as , while the corresponding ground truth for the language modeling task is obtained as .
The input sequence is fed into the GPT-2 model, which generates a contextualized embedding denoted as
, where
d represents the dimension of the contextualized embedding. Furthermore, the model computes the output probability of the last words based on the preceding sequence using a softmax layer.
W is a weight matrix to be learned:
To implement knowledge distillation, we begin by training a teacher network. For instance, in the case of training a 6-layer GPT-2 model as the teacher network, the parameters of the teacher model are represented by the superscript
t in the following equation. The objective during training is to maximize the likelihood of the equation given below:
Upon training the teacher network, we employ it to guide the student network. However, while using the teacher model for inference to guide the student model, we need to modify Equation (
2) as follows:
Here,
represents the probability output generated by the teacher model. This probability distribution is considered the soft label of the student model and is fixed during the knowledge-distillation process. Additionally, we use temperature parameter
T during knowledge distillation, which controls the extent to which the student model relies on the teacher’s soft predictions. A higher value of temperature leads to a more diverse probability distribution over classes as suggested in previous studies [
25].
To evaluate the difference between the probability distribution generated by the teacher model and the corresponding distribution produced by the student model, we employ cross-entropy loss. This approach encourages the student model to imitate the behavior of the teacher model.
Let and represent the parameters of the student and teacher models, respectively. Moreover, and denote the corresponding probability outputs from the student and teacher models, respectively. Additionally, N represents the length of the sequence, and W is the vocabulary size of the model.
Therefore, we define the distance between the predictions of the teacher and student models as follows:
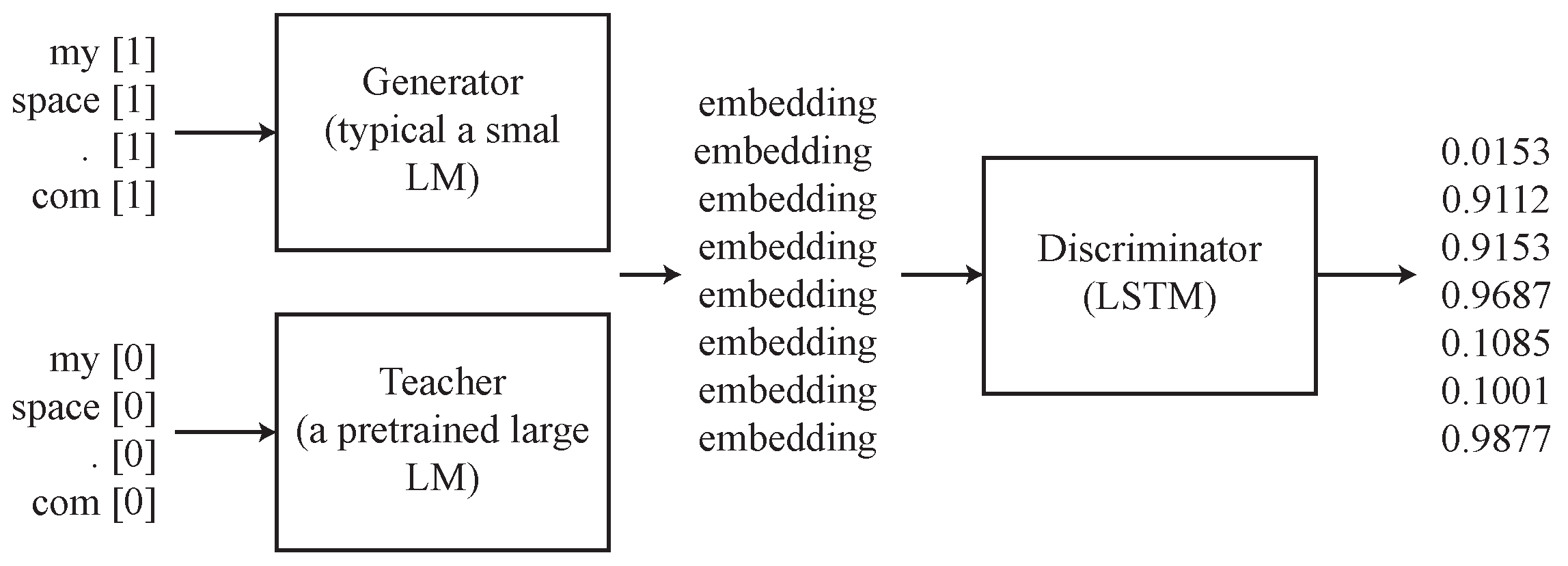
To enhance the effectiveness of knowledge distillation, we aim to develop a discriminator that evaluates the entire sentence rather than individual words. To achieve this goal, we introduce an encoder, such as a bidirectional LSTM network, which reads the sequence of contextualized vector representations generated by the language model (either the student or the teacher GPT-2).
The objective of the discriminator is to differentiate between
generated by the student and teacher models. We aim to train the student model to generate representations that can successfully fool the discriminator. We define the signal received from the discriminator as
s:
Taking inspiration from Sutton et al. [
30], we simplified the reward computation process in SeqGAN [
7] by employing a Monte Carlo search with a roll-out policy to calculate the reward at each time step. In our proposed framework, we use the discriminator not only to evaluate the entire sequence but also to assess sub-sequences generated after each word. For instance, in the sequence “Say hello world”, we evaluate “Say”, “Say hello”, and “Say hello world”. Furthermore, we consider evaluating the potential generation probability of each word. The reward for the entire sequence is then defined as
The training of the proposed framework involves two steps of backpropagation.
In the first step, the discriminator is optimized as a binary classifier. Once the discriminator is trained, Equation (
6) is used to calculate the score of the student’s output and the teacher’s output. A smaller difference between the scores indicates that the output of the student model more closely resembles that of the teacher model. To optimize the generation of the entire sequence, the loss function is defined as follows:
The discriminator’s output is designed to yield a value of 0 if the input is determined to be the output of the teacher network, and 0 if it is deemed the output of the student network. To address the simple dichotomous task, we employ Equation (
7) as a straightforward cross-entropy loss measure to optimize the discriminator.
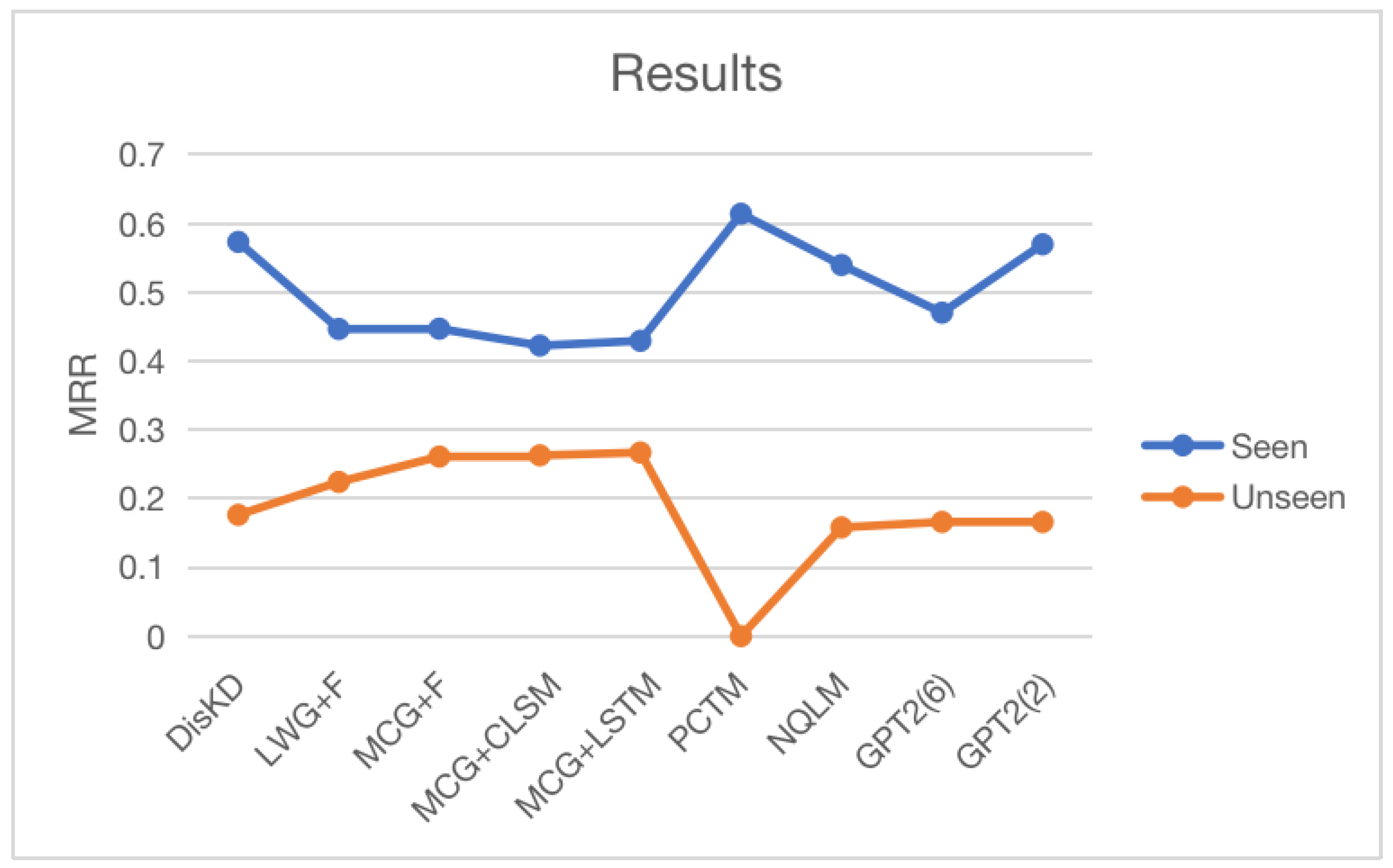
Next, we go back to training the discriminator, and this cycle iterates several times. Even though the policy is simplified, the 2-layer distilled model outperforms the 6-layer teacher model. The data flow is described in
Appendix A.2. The additional loss used for the student model is the language model loss, which is the same as the loss used in GPT:
Combined with the traditional knowledge-distillation loss, the final objective function can be formulated as follows:
where
and
are hyper-parameters that balance the importance of different objective functions;
is 0.6 and
is 0.35 in our model.




{kind=link}
{kind=link}
{kind=link}