
YOLOv5s-D: A Railway Catenary Dropper State Identification and Small Defect Detection Model

Abstract
:1. Introduction
- (1)
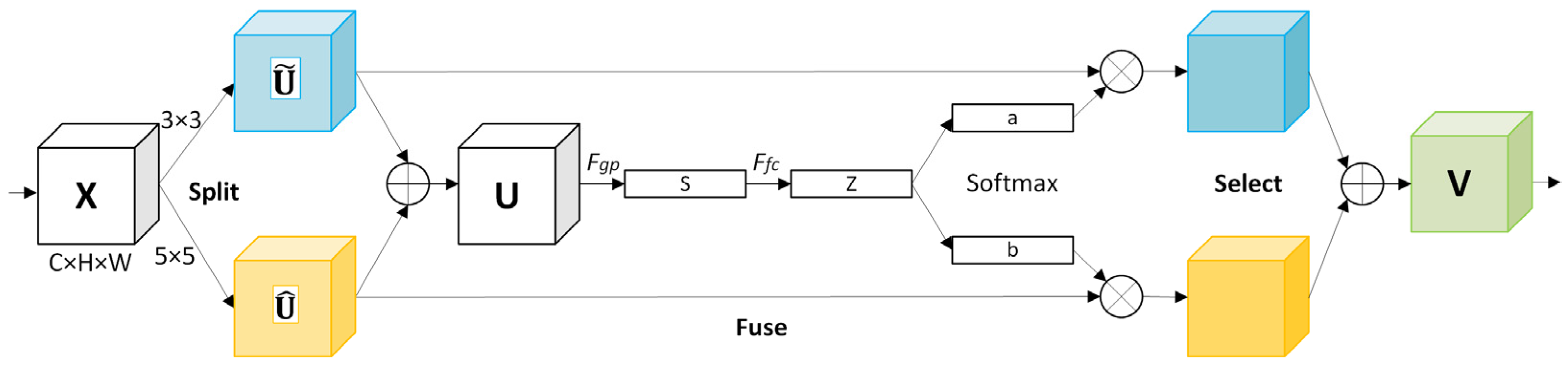
- The SK attention module was optimized, resulting in reduced module complexity and improved performance, and further increasing the focus on small-target features.
- (2)
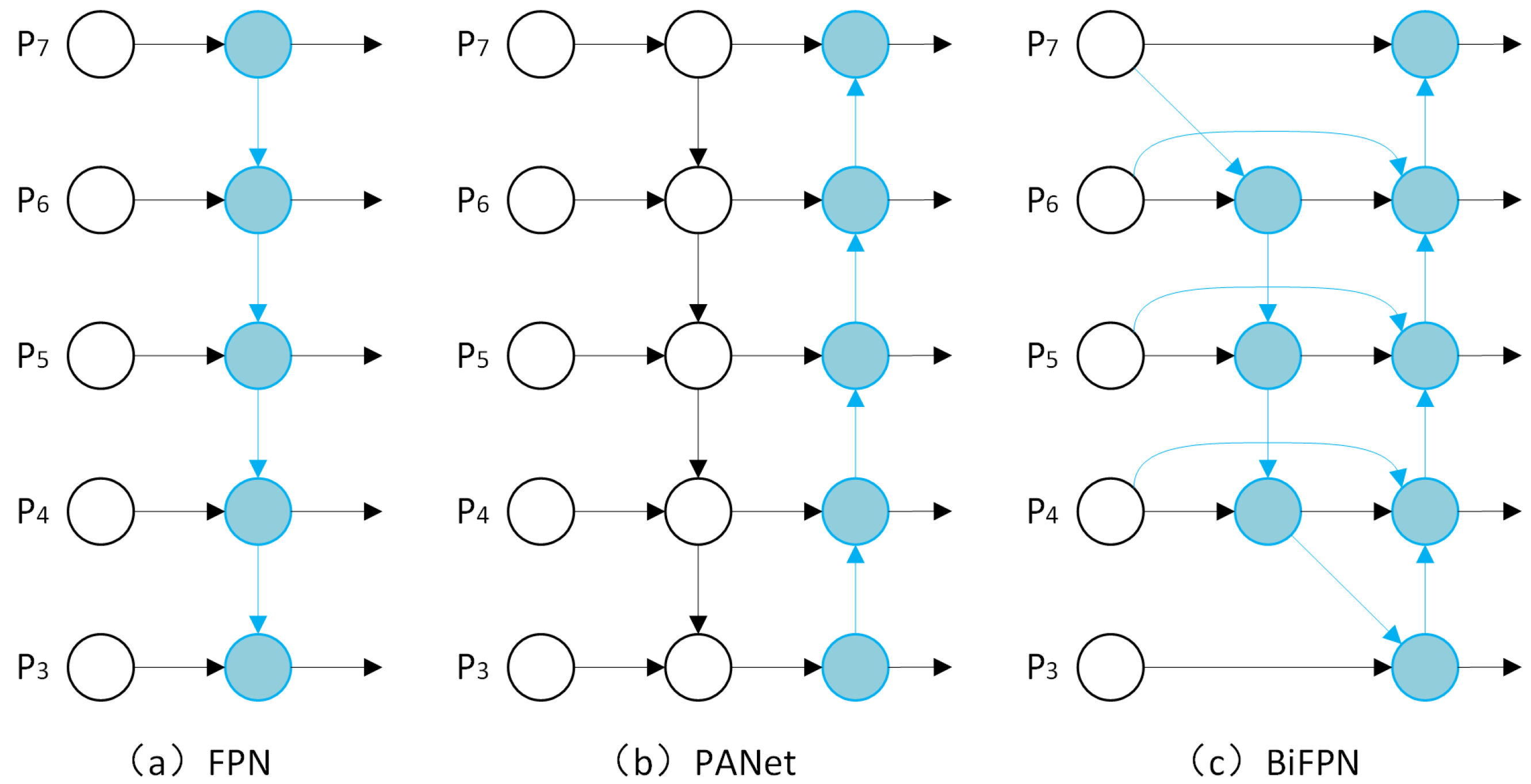
- The feature fusion network structure of the YOLOv5 model was optimized by utilizing BiFPN for multi-scale feature fusion, enabling a better balance of information across different scales.
- (3)
- The detection head of YOLOv5 was improved by replacing the original YOLO head with an enhanced decoupled head, leading to an improved detection accuracy and the faster convergence of the model.
2. Methods
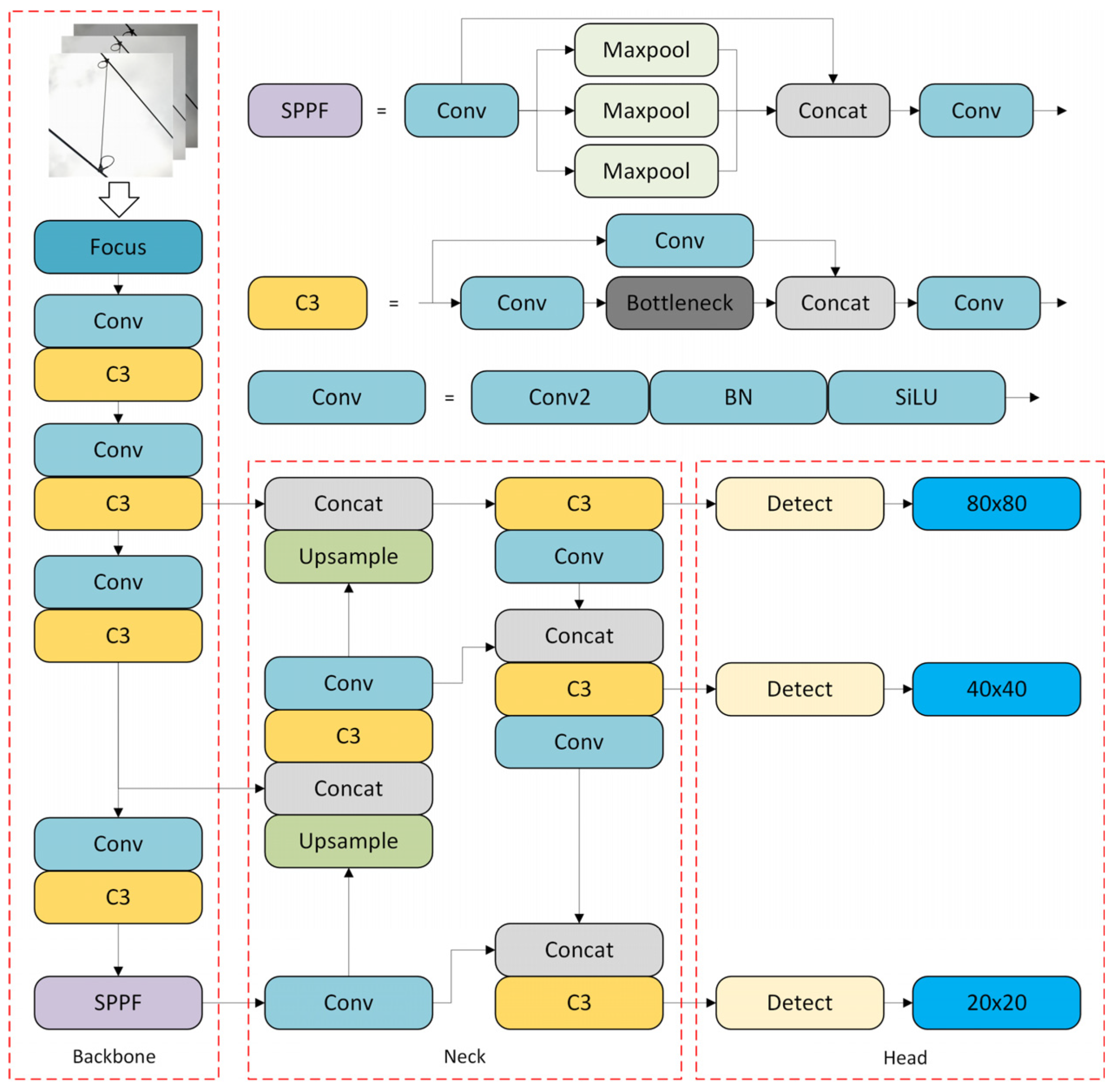
2.1. YOLOv5 Network
2.2. SK Attention Module
2.3. Bidirectional Feature Pyramid Network
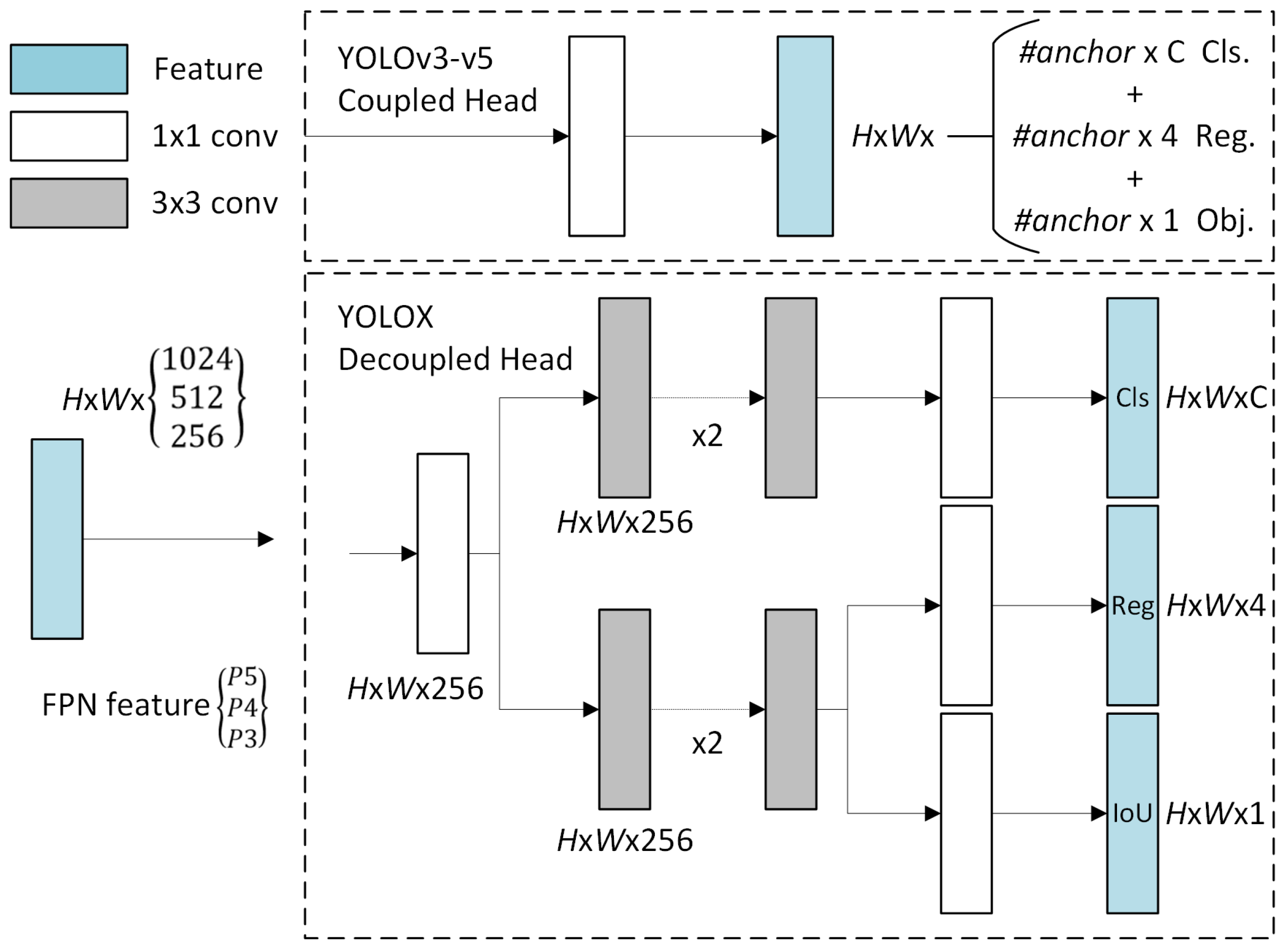
2.4. Decoupled Head
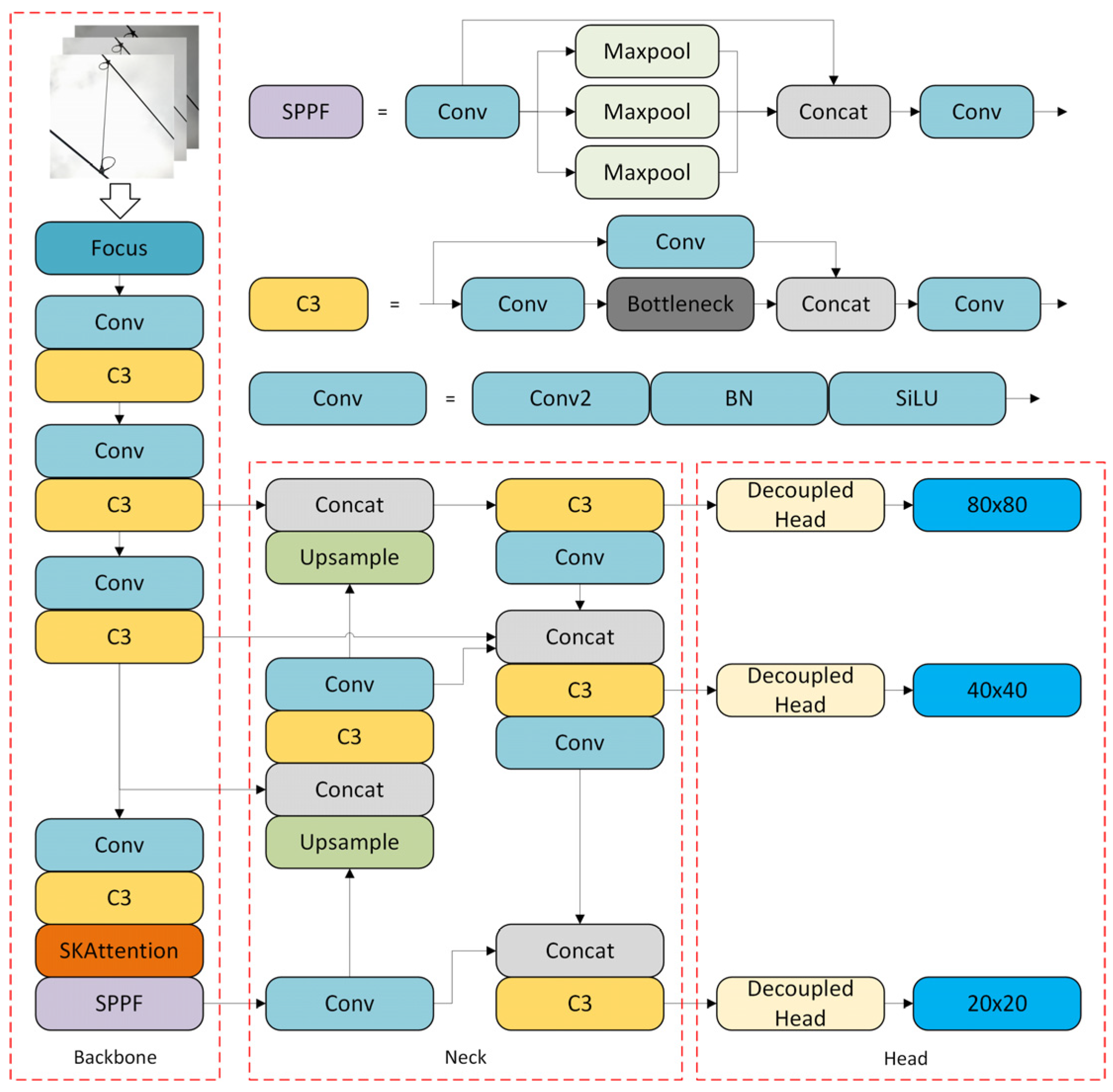
2.5. YOLOv5s-D Network Structure
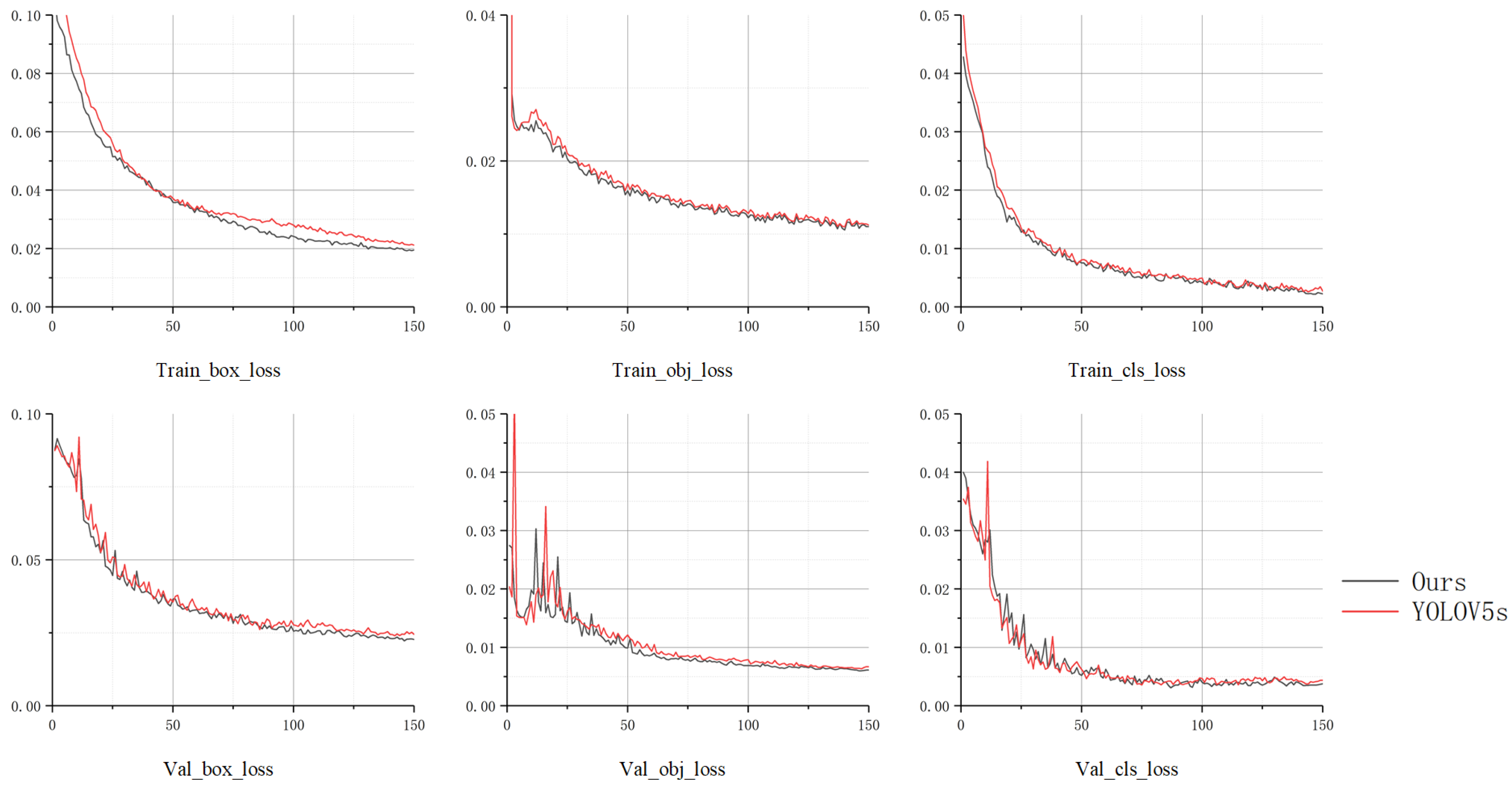
3. Experiments
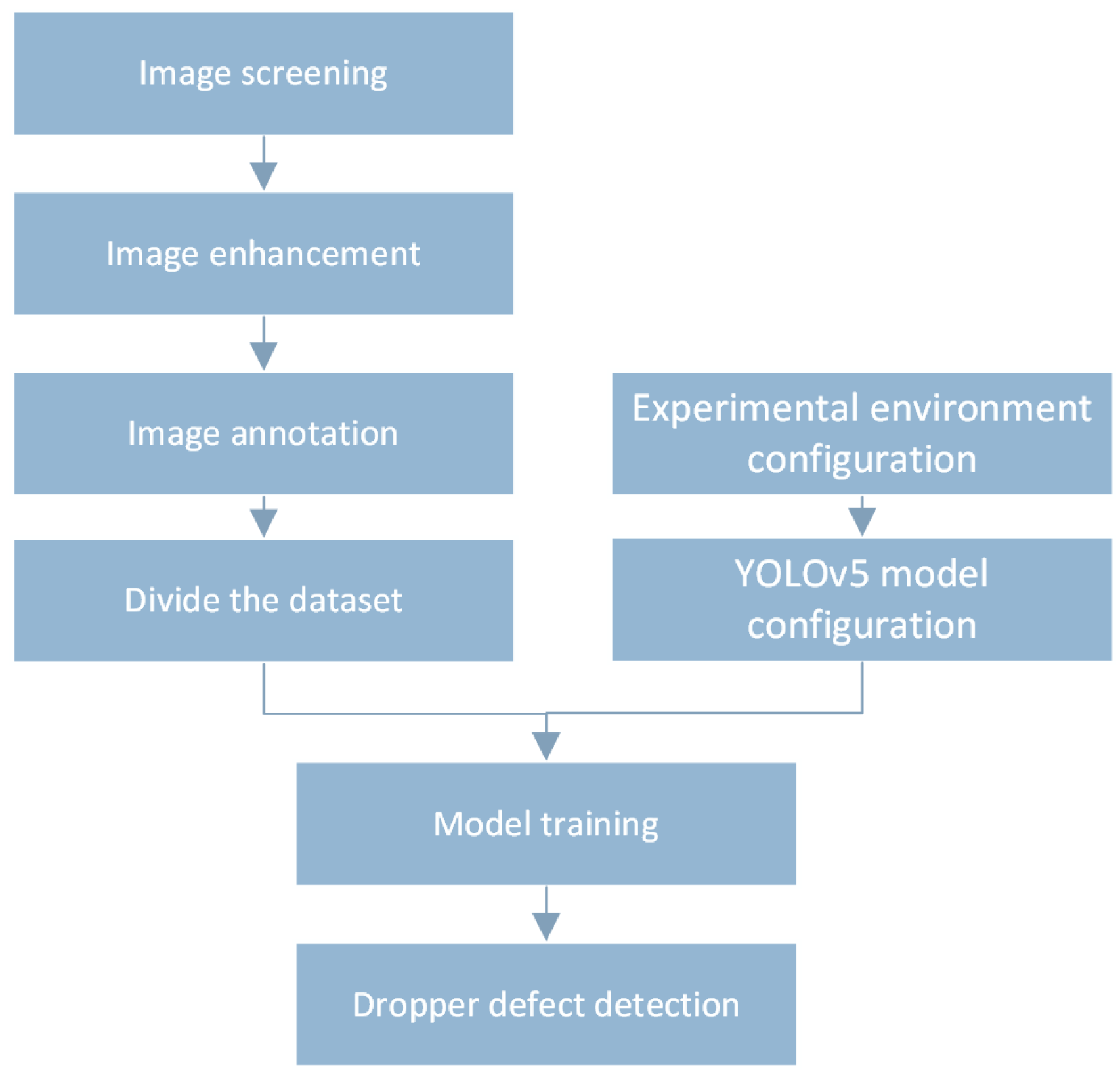
3.1. Dataset Preparation
3.2. Experimental Comparison of Different Attention Modules in YOLOv5s
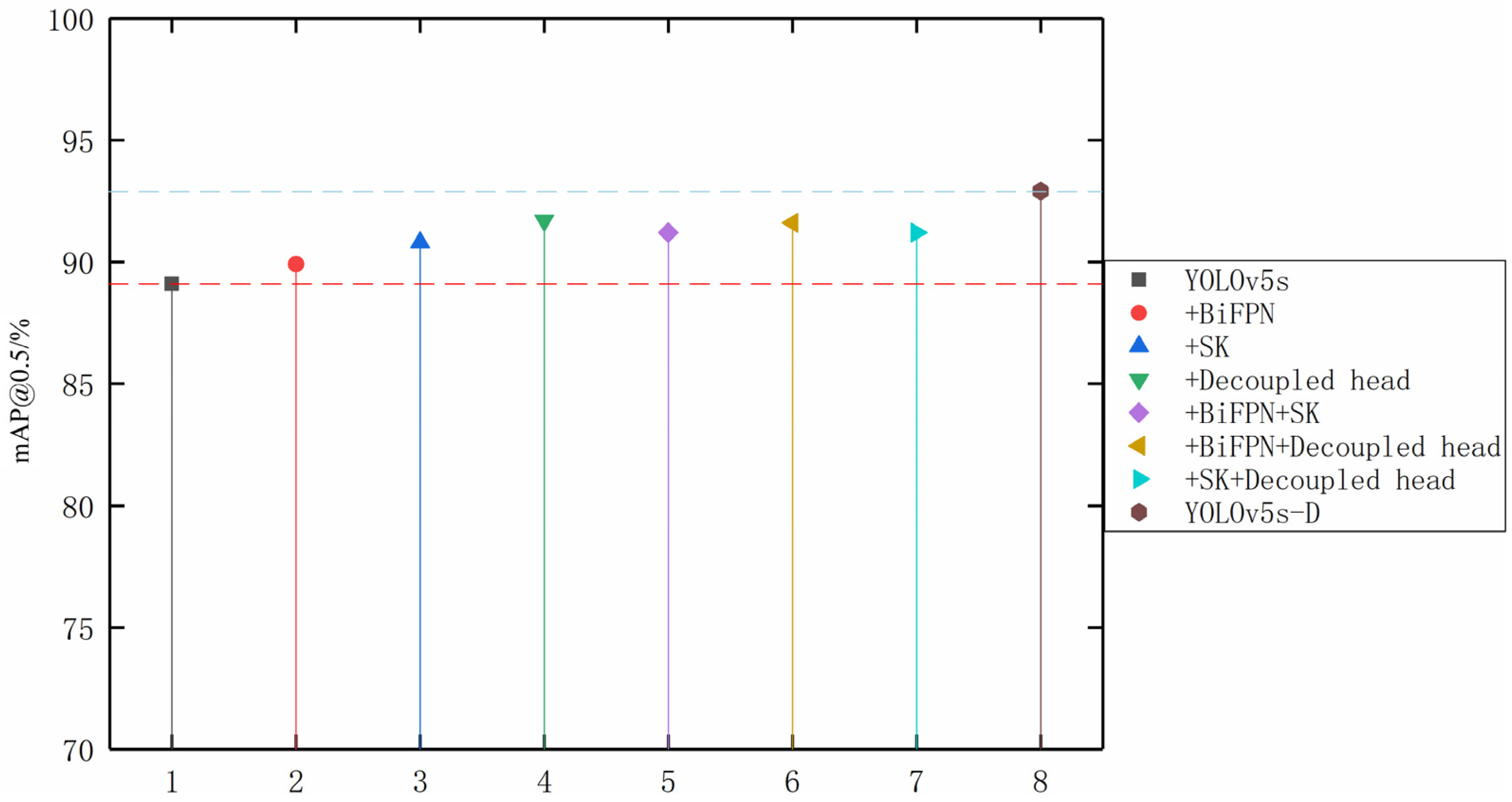
3.3. Ablation Experiments
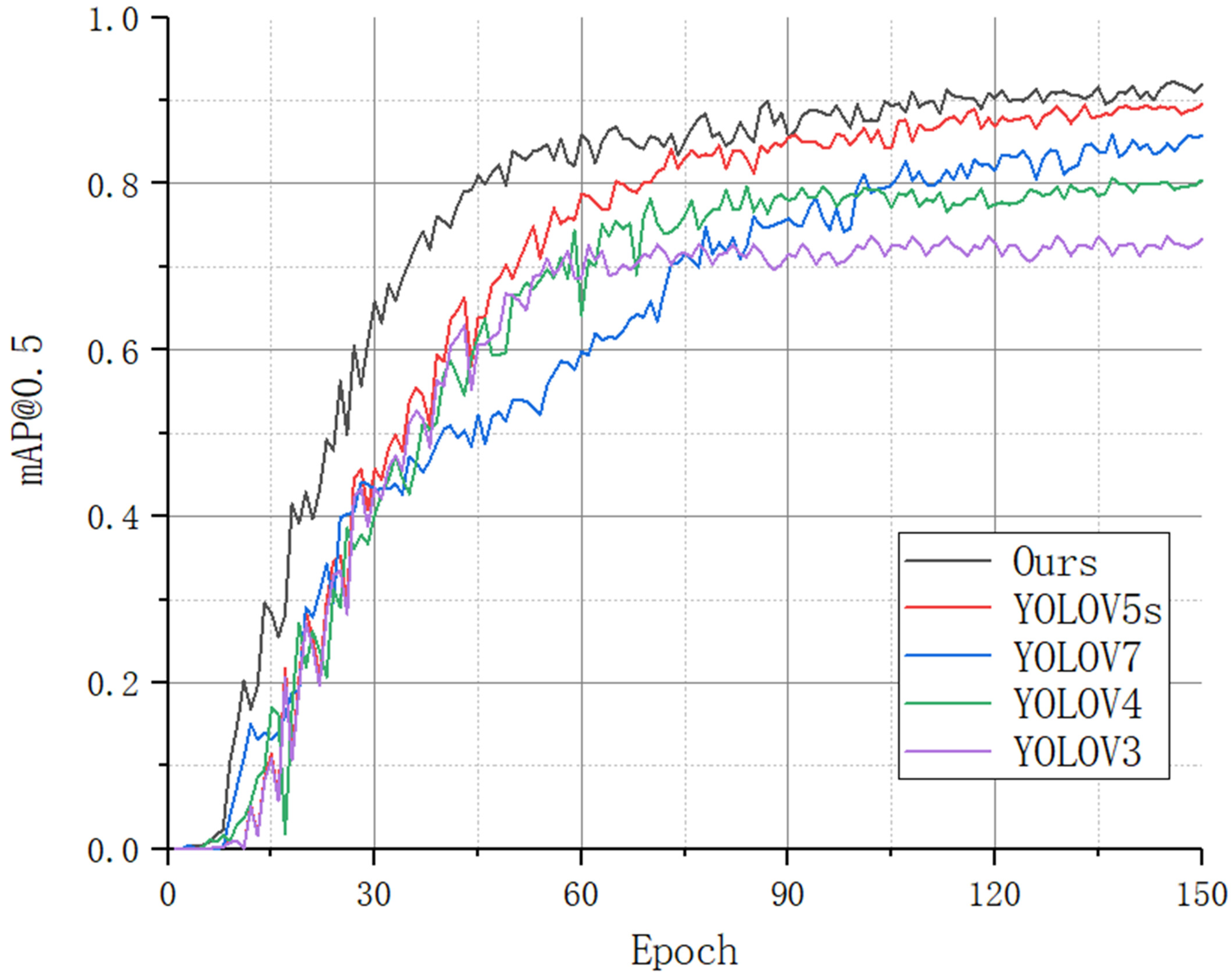
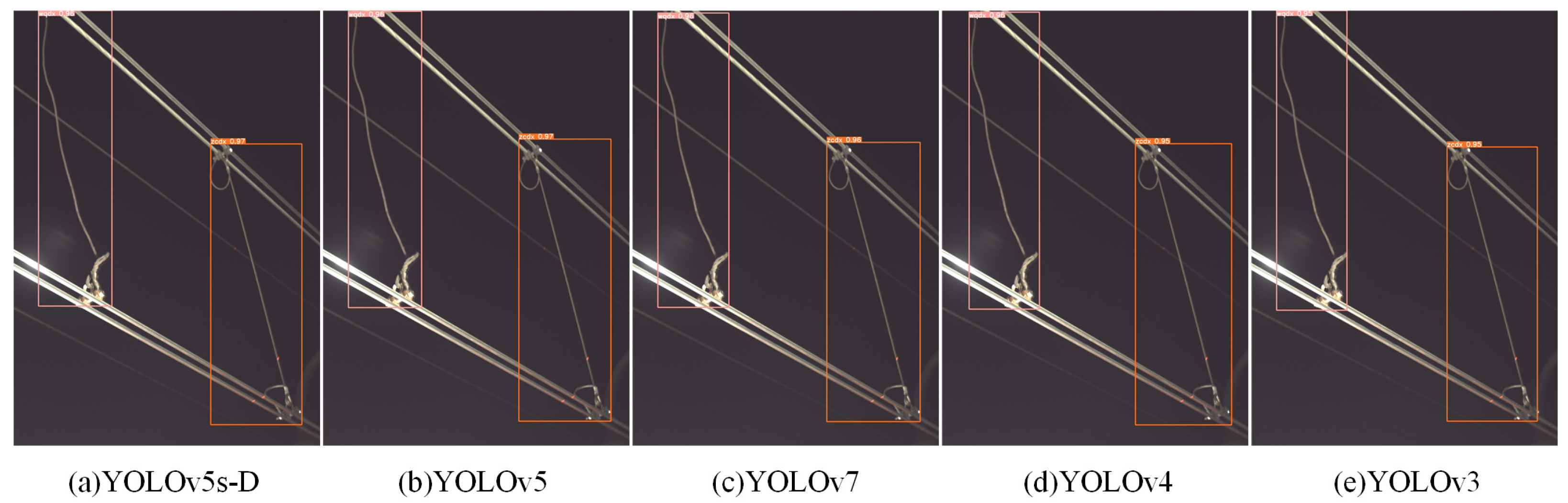
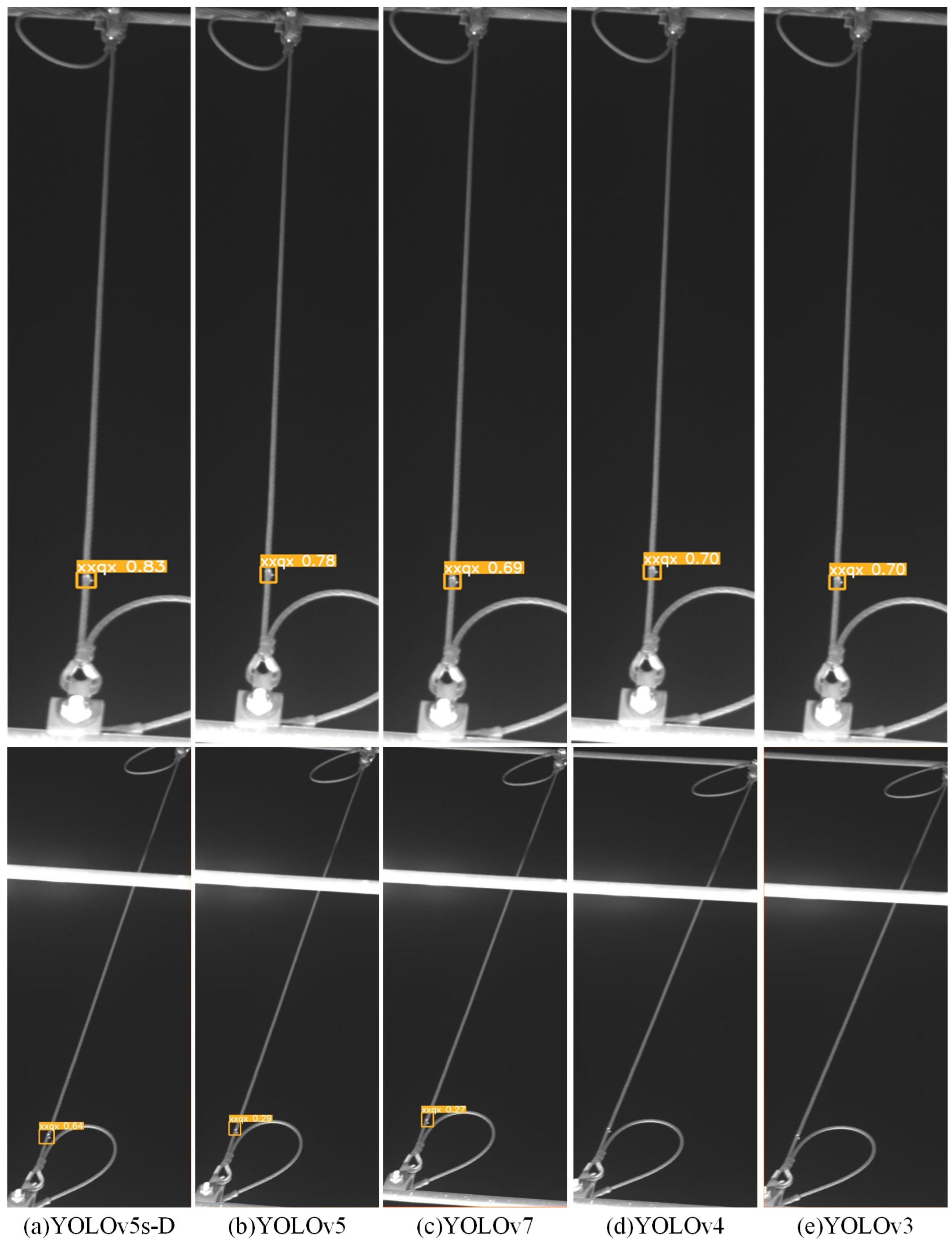
3.4. Comparative Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, Y.; Wang, Z.; Liu, Z.; Wang, R. A spatial coupling model to study dynamic performance of pantograph-catenary with vehicle-track excitation. Mech. Syst. Signal Process. 2021, 151, 107336. [Google Scholar] [CrossRef]
- Duan, F.; Song, Y.; Gao, S.; Liu, Y.; Chu, W.; Lu, X.; Liu, Z. Study on aerodynamic instability and galloping response of rail overhead contact line based on wind tunnel tests. IEEE Trans. Veh. Technol. 2023, 1–11. [Google Scholar] [CrossRef]
- Song, Y.; Liu, Z.; Ronnquist, A.; Navik, P.; Liu, Z. Contact wire irregularity stochastics and effect on high-speed railway pantograph–catenary interactions. IEEE Trans. Instrum. Meas. 2020, 69, 8196–8206. [Google Scholar] [CrossRef]
- Tan, P.; Li, X.; Ding, J.; Cui, Z.; Ma, J.; Sun, Y.; Huang, B.; Fang, Y. Mask R-CNN and multifeature clustering model for catenary insulator recognition and defect detection. J. Zhejiang Univ. Sci. A 2022, 23, 745–756. [Google Scholar] [CrossRef]
- Li, T.; Hao, T. Damage Detection of Insulators in Catenary Based on Deep Learning and Zernike Moment Algorithms. Appl. Sci. 2022, 12, 5004. [Google Scholar] [CrossRef]
- Han, Y.; Liu, Z.; Lyu, Y.; Liu, K.; Li, C.; Zhang, W. Deep learning-based visual ensemble method for high-speed railway catenary clevis fracture detection. Neurocomputing 2020, 396, 556–568. [Google Scholar] [CrossRef]
- Wu, X.; Yuan, P.; Peng, Q.; Ngo, C.W.; He, J.Y. Detection of bird nests in overhead catenary system images for high-speed rail. Pattern Recognit. 2016, 51, 242–254. [Google Scholar] [CrossRef]
- Liu, W.; Liu, Z.; Li, Y.; Wang, H.; Yang, C.; Wang, D.; Zhai, D. An automatic loose defect detection method for catenary bracing wire components using deep convolutional neural networks and image processing. IEEE Trans. Instrum. Meas. 2021, 70, 5016814. [Google Scholar] [CrossRef]
- Huang, S.; Zhai, Y.; Zhang, M.; Hou, X. Arc detection and recognition in pantograph–catenary system based on convolutional neural network. Inf. Sci. 2019, 501, 363–376. [Google Scholar] [CrossRef]
- Sun, J.; Hu, K.; Fan, Y.; Liu, J.; Yan, S.; Zhang, Y. Modeling and Experimental Analysis of Overvoltage and Inrush Current Characteristics of the Electric Rail Traction Power Supply System. Energies 2022, 15, 9308. [Google Scholar] [CrossRef]
- Chen, L.; Guo, D.; Pan, L.; He, F. The influence of wind load on the stress characteristics of dropper for a high-speed railway. Adv. Mech. Eng. 2022, 14, 16878132221097833. [Google Scholar] [CrossRef]
- Chen, L.; Sun, J.; Pan, L.; He, F. Analysis of Dropper Stress in a Catenary System for a High-Speed Railway. Math. Probl. Eng. 2022, 2022, 9663767. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, Z.; Song, Y. Study on the Dynamic Performance of High-Speed Railway Catenary System With Small Encumbrance. IEEE Trans. Instrum. Meas. 2022, 71, 3518810. [Google Scholar] [CrossRef]
- Bryja, D.; Hyliński, A. Droppers’ stiffness influence on dynamic interaction between the pantograph and railway catenary. Probl. Kolejnictwa 2019, 183, 89–98. [Google Scholar]
- Gregori, S.; Tur, M.; Nadal, E.; Fuenmayor, F.J. An approach to geometric optimisation of railway catenaries. Veh. Syst. Dyn. 2018, 56, 1162–1186. [Google Scholar] [CrossRef]
- Song, Y.; Zhang, M.; Wang, H. A response spectrum analysis of wind deflection in railway overhead contact lines using pseudo-excitation method. IEEE Trans. Veh. Technol. 2021, 70, 1169–1178. [Google Scholar] [CrossRef]
- Liu, X.; Peng, J.; Tan, D.; Xu, Z.; Liu, J.; Mo, J.; Zhu, M. Failure analysis and optimization of integral droppers used in high speed railway catenary system. Eng. Fail. Anal. 2018, 91, 496–506. [Google Scholar] [CrossRef]
- Yu, X.; Gu, G.; Wang, Y.; Zhang, C. Catenary Dropper Fault Detection Method Based on Faster R-CNN. J. Lanzhou Jiaotong Univ. 2021, 40, 58–65. [Google Scholar]
- Zhang, X.; Jing, W. Fault detection of overhead contact systems based on multi-view Faster R-CNN. J. Intell. Fuzzy Syst. 2022, 43, 397–407. [Google Scholar] [CrossRef]
- Zhang, X.; Gong, Y.; Qiao, C.; Jing, W. Multiview deep learning based on tensor decomposition and its application in fault detection of overhead contact systems. Vis. Comput. 2022, 38, 1457–1467. [Google Scholar] [CrossRef]
- Guo, Q.; Liu, L.; Xu, W.; Gong, Y.; Zhang, X.; Jing, W. An improved faster R-CNN for high-speed railway dropper detection. IEEE Access 2020, 8, 105622–105633. [Google Scholar] [CrossRef]
- Zhang, M.; Jin, W.; Tang, P.; Li, L. A YOLOv3 and ODIN Based State Detection Method for High-speed Railway Catenary Dropper. In Proceedings of the 2021 IEEE International Conference on Progress in Informatics and Computing (PIC), Shanghai, China, 17–19 December 2021; pp. 72–76. [Google Scholar]
- Liu, S.; Tang, P.; Jin, W. Study on Catenary Dropper and Support Detection Based on Intelligent Data Augmentation and Improved YOLOv3. Comput. Sci. 2020, 47, 178–182. [Google Scholar]
- Li, J.; Zhang, X.; Zhang, C.; Tian, T. Simulation Research on High-Speed Railway Dropper Fault Detection and Location Based on Time-Frequency Analysis. J. Phys. Conf. Ser. 2020, 1631, 012100. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Mahaur, B.; Mishra, K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, X.; Wan, Y.; Wang, J.; Lyu, H. An Improved YOLOv5 Method for Small Object Detection in UAV Capture Scenes. IEEE Access 2023, 11, 14365–14374. [Google Scholar] [CrossRef]
- Wang, M.; Yang, W.; Wang, L.; Chen, D.; Wei, F.; KeZiErBieKe, H.; Liao, Y. FE-YOLOv5: Feature enhancement network based on YOLOv5 for small object detection. J. Vis. Commun. Image Represent. 2023, 90, 103752. [Google Scholar] [CrossRef]
- Deng, T.; Liu, X.; Mao, G. Improved YOLOv5 Based on Hybrid Domain Attention for Small Object Detection in Optical Remote Sensing Images. Electronics 2022, 11, 2657. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
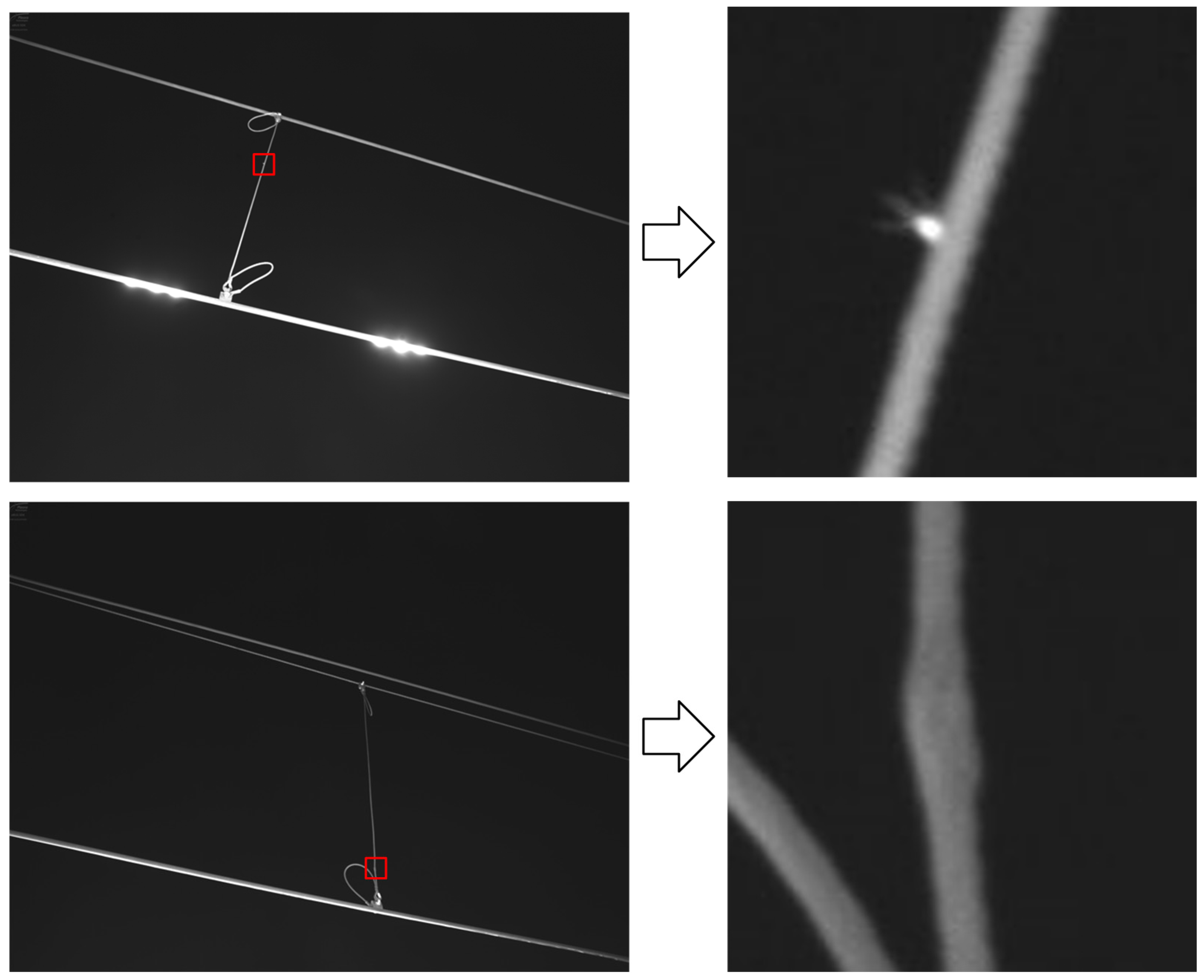





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Learning Rate | Momentum | Weight Decay | Batch Size | Epoch |
|---|---|---|---|---|---|
| Value | 0.01 | 0.937 | 0.0005 | 32 | 150 |
| Module | dxdx (AP%) | wqdx (AP%) | zcdx (AP%) | xxqx (AP%) | mAP@0.5% |
|---|---|---|---|---|---|
| YOLOv5s | 98.3 | 93.1 | 96.3 | 68.5 | 89.1 |
| +SK attention | 98.8 | 94.4 | 95.2 | 74.8 | 90.8 |
| +GAM attention | 98.3 | 92.1 | 94.6 | 68.9 | 88.5 |
| +CBAM | 98.4 | 93.1 | 95.9 | 71.4 | 89.6 |
| +CA | 98.9 | 92.0 | 96.7 | 72.2 | 89.9 |
| Module | dxdx (AP%) | wqdx (AP%) | zcdx (AP%) | xxqx (AP%) | mAP@0.5% |
|---|---|---|---|---|---|
| YOLOv5s | 98.3 | 93.1 | 96.3 | 68.5 | 89.1 |
| +BiFPN | 98.7 | 94.5 | 96.1 | 71.9 | 89.9 |
| +SK | 98.8 | 94.4 | 95.2 | 74.8 | 90.8 |
| +Decoupled head | 99.3 | 94.1 | 96.4 | 76.8 | 91.7 |
| +BiFPN+SK | 99.2 | 93.1 | 96.7 | 75.6 | 91.2 |
| +BiFPN+Decoupled head | 99.1 | 94.3 | 95.1 | 77.9 | 91.6 |
| +SK+Decoupled head | 98.7 | 92.6 | 97.3 | 76.5 | 91.2 |
| YOLOv5s-D | 99.5 | 95.7 | 97.1 | 79.2 | 92.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Rao, Z.; Ding, L.; Ding, B.; Fang, J.; Ma, X. YOLOv5s-D: A Railway Catenary Dropper State Identification and Small Defect Detection Model. Appl. Sci. 2023, 13, 7881. https://doi.org/10.3390/app13137881
Li Z, Rao Z, Ding L, Ding B, Fang J, Ma X. YOLOv5s-D: A Railway Catenary Dropper State Identification and Small Defect Detection Model. Applied Sciences. 2023; 13(13):7881. https://doi.org/10.3390/app13137881
Chicago/Turabian StyleLi, Ziyi, Zhiqiang Rao, Lu Ding, Biao Ding, Jianjun Fang, and Xiaoning Ma. 2023. "YOLOv5s-D: A Railway Catenary Dropper State Identification and Small Defect Detection Model" Applied Sciences 13, no. 13: 7881. https://doi.org/10.3390/app13137881
APA StyleLi, Z., Rao, Z., Ding, L., Ding, B., Fang, J., & Ma, X. (2023). YOLOv5s-D: A Railway Catenary Dropper State Identification and Small Defect Detection Model. Applied Sciences, 13(13), 7881. https://doi.org/10.3390/app13137881