
Research and Application of Semi-Supervised Category Dictionary Model Based on Transfer Learning


Abstract
:1. Introduction
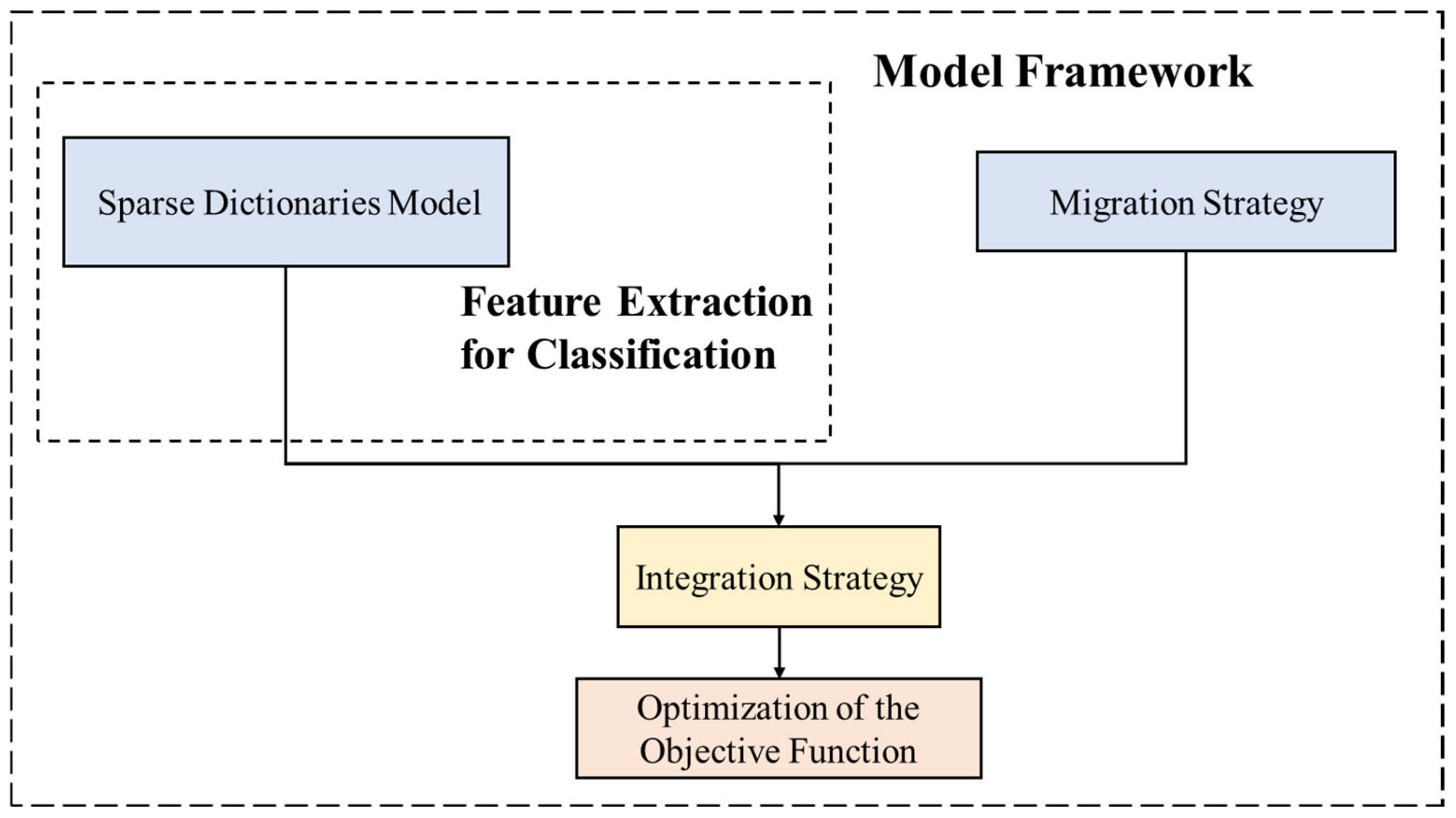
2. Materials and Methods
2.1. Model Principle
2.2. Common Data Symbols
2.3. Sparse Dictionaries Model
2.4. Migration Strategy
2.5. Integration Strategy
2.6. Optimization of the Objective Function
2.6.1. Solve for the Variable
2.6.2. Solve for the Variable
| Algorithm 1: Semi-Supervised Category Dictionary Model Based on Transfer Learning | |
| Input: Dataset , , ; parameter , κ | |
| Output: corresponding labels | |
| 1. | Build data matrix , , . Set , ; |
| 2. | For do |
| 3. | Initialize , , , , , ; |
| 4. | For do |
| 5. | Update ; |
| 6. | ; |
| 7. | For do |
| 8. | Initialize , , , ; |
| 9. | While 1 do |
| 10. | Calculate the coefficient matrix , , ; |
| 11. | Update according to Equation (15); |
| 12. | Update according to Equation (17); |
| 13. | Update and according to Equation (18); |
| 14. | If meet the termination conditions then |
| 15. | Break |
| 16. | End if |
| 17. | End |
| 18. | End |
| 19. | For do |
| 20 | Update according to Equation (19); |
| 21. | End |
| 22. | ; |
| 23. | End |
| 24. | Based on the dictionary , corresponding expression coefficients and category residuals are obtained.; |
| 25. | Transform into the corresponding discrete probability values for each category of residuals and obtain the pseudolabel; |
| 26. | The pseudo-labeled samples with larger probability values within the subcategory are selected to form ; |
| 27. | Update ; |
| 28. | Iter = Iter + 1 |
| 29. | End |
3. Experiments and Results Analysis
3.1. Analysis Object
3.1.1. Data of Vision
3.1.2. Data of Bearing Fault Diagnosis
3.2. Model Settings
- When LabelMe is the source domain, 65 labeled samples are randomly selected per category, resulting in a total of 302 samples. Sun09 and VOC2007 serve as target domains where three labeled samples are chosen at random, constituting an aggregate of 15 samples. The remaining samples in the target domains are used as the test set, and the dictionary size for each category is Im = 35;
- When Sun09 serves as the source domain, 30 labeled samples are randomly selected per category, totaling 140 samples. LabelMe and VOC2007 act as the target domains, with the allocation of labeled samples and test sets remaining identical to the aforementioned settings. The dictionary size for each category is Im = 20;
- When VOC2007 is employed as the source domain, 65 labeled samples are randomly selected per category, amassing 325 samples in total. LabelMe and Sun09 function as target domains, maintaining the same configuration of labeled samples and test sets as previously described. The dictionary size for each category is Im = 35.
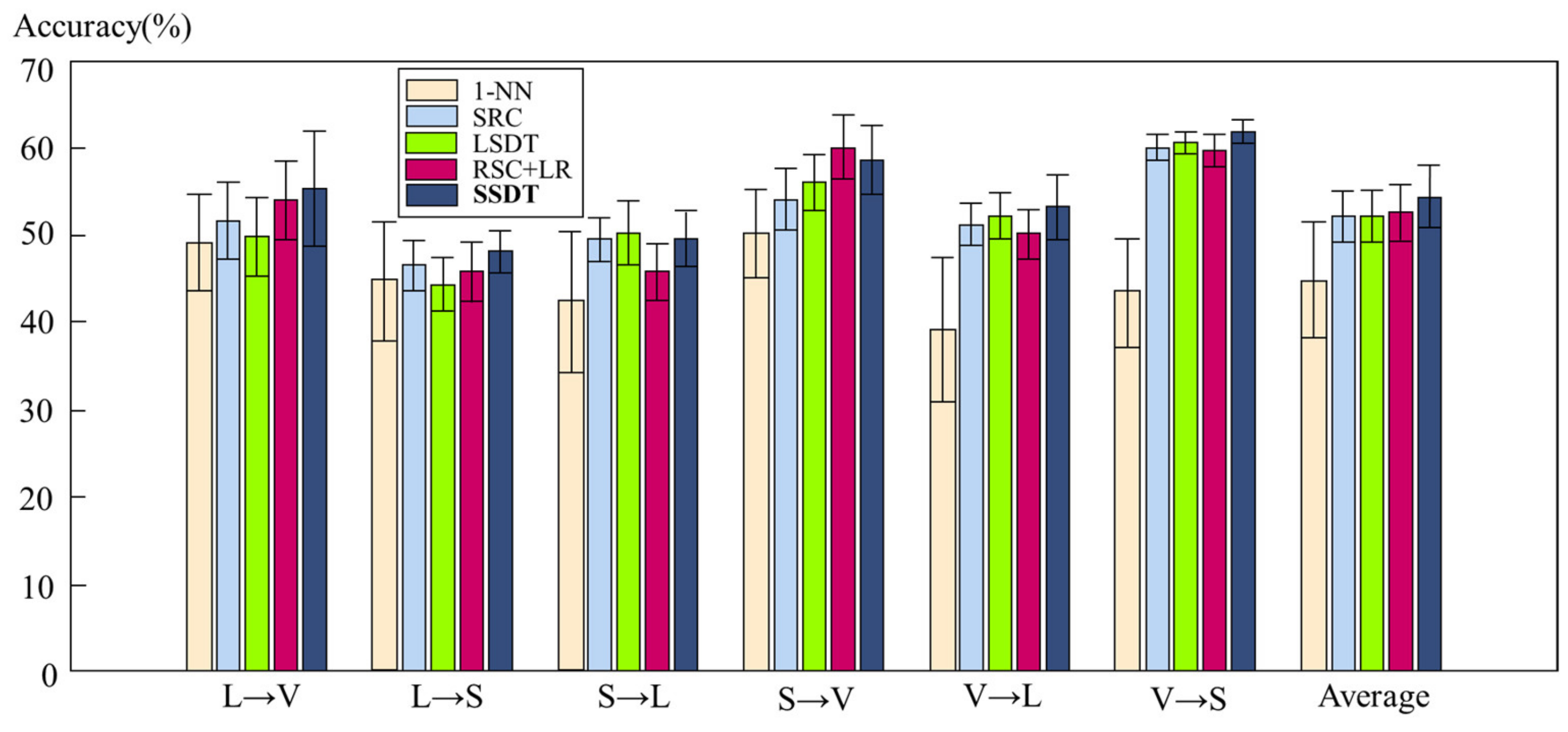
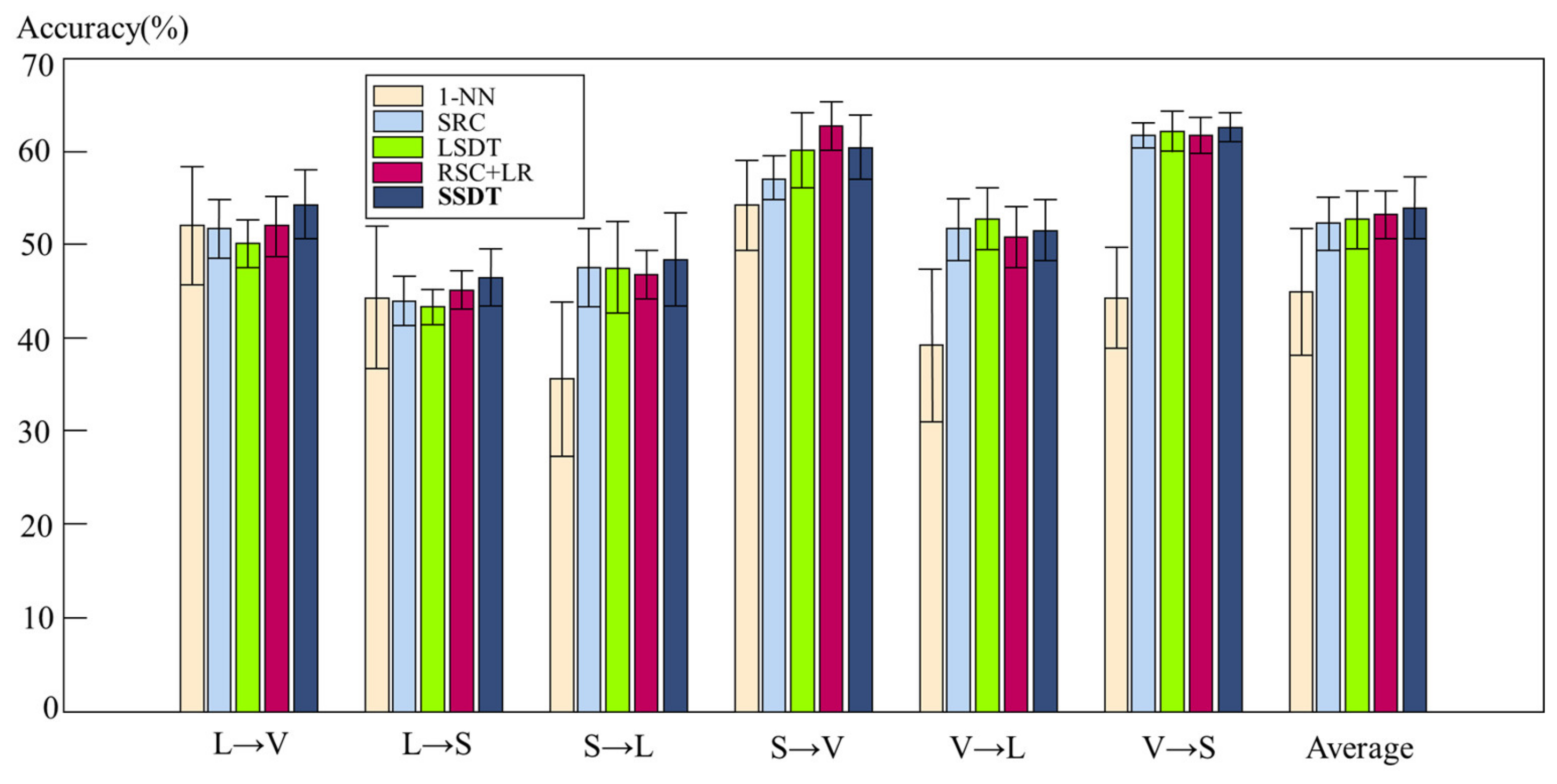
3.3. Results Analysis
3.3.1. Results Analysis of the Vision Data Experiment
3.3.2. Results Analysis of Bearing Fault Diagnosis Data Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shekhar, S.; Patel, V.M.; Nguyen, H.V.; Chellappa, R. Generalized domain-adaptive dictionaries. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 361–368. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE J. Mag. 2010, 22, 1345–1359. Available online: https://ieeexplore.ieee.org/document/5288526 (accessed on 2 February 2023).
- Lu, B.; Chellappa, R.; Nasrabadi, N.M. Incremental Dictionary Learning for Unsupervised Domain Adaptation. In Proceedings of the British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; British Machine Vision Association: Swansea, UK, 2015; pp. 108.1–108.12. [Google Scholar]
- Long, M.; Ding, G.; Wang, J.; Sun, J.; Guo, Y.; Yu, P.S. Transfer Sparse Coding for Robust Image Representation. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 407–414. [Google Scholar]
- Supervised Transfer Sparse Coding. In Proceedings of the AAAI Conference on Artificial Intelligence, held virtually, 22 February–1 March 2022; Available online: https://ojs.aaai.org/index.php/AAAI/article/view/8981 (accessed on 2 February 2023).
- Wang, S.; Zhang, L.; Zuo, W. Class-Specific Reconstruction Transfer Learning via Sparse Low-Rank Constraint. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 949–957. [Google Scholar]
- Pereira, L.A.; da Silva Torres, R. Semi-supervised transfer subspace for domain adaptation. Pattern Recognit. 2018, 75, 235–249. [Google Scholar] [CrossRef]
- Ding, Z.; Shao, M.; Fu, Y. Latent Low-Rank Transfer Subspace Learning for Missing Modality Recognition. In Proceedings of the Twenty-Eighth Aaai Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Assoc Advancement Artificial Intelligence: Palo Alto, CA, USA, 2014; pp. 1192–1198. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. In Proceedings of the 21st International Joint Conference on Artificial Intelligence (ijcai-09), Pasadena, CA, USA, 11–17 July 2009; Boutilier, C., Ed.; Ijcai-Int Joint Conf Artif Intell: Freiburg, Germany, 2009; pp. 1187–1192. [Google Scholar]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic Flow Kernel for Unsupervised Domain Adaptation. In Proceedings of the 2012 Ieee Conference on Computer Vision and Pattern Recognition (cvpr), Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 2066–2073. [Google Scholar]
- Xu, Y.; Fang, X.; Wu, J.; Li, X.; Zhang, D. Discriminative Transfer Subspace Learning via Low-Rank and Sparse Representation. IEEE Trans. Image Process. 2016, 25, 850–863. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Battle, A.; Raina, R.; Ng, A. Efficient sparse coding algorithms. In Proceedings of the Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2006; Volume 19. [Google Scholar]
- Fang, C.; Xu, Y.; Rockmore, D.N. Unbiased metric learning: On the utilization of multiple datasets and web images for softening bias. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1657–1664. [Google Scholar]
- Choi, M.J.; Lim, J.J.; Torralba, A.; Willsky, A.S. Exploiting hierarchical context on a large database of object categories. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 129–136. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image. Int. J. Comput. Vis. 2005, 77, 157–173. [Google Scholar] [CrossRef]
- Tommasi, T.; Tuytelaars, T. A testbed for cross-dataset analysis. In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–7, 12 September 2014; Proceedings Part III 13. Springer: Berlin/Heidelberg, Germany, 2015; pp. 18–31. [Google Scholar]
- Ding, Z.; Fu, Y. Deep domain generalization with structured low-rank constraint. IEEE Trans. Image Process. 2017, 27, 304–313. [Google Scholar] [CrossRef] [PubMed]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D. Domain generalization for object recognition with multi-task autoencoders. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2551–2559. [Google Scholar]
- Data of Vision. Available online: https://www.cs.dartmouth.edu/~chenfang/%20proj_page/FXR_iccv13/%20index.%20php (accessed on 14 May 2023).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Liu, H.; Liu, C.; Huang, Y. Adaptive feature extraction using sparse coding for machinery fault diagnosis. Mech. Syst. Signal Process. 2011, 25, 558–574. [Google Scholar] [CrossRef]
- Lu, W.; Liang, B.; Cheng, Y.; Meng, D.; Yang, J.; Zhang, T. Deep Model Based Domain Adaptation for Fault Diagnosis. IEEE Trans. Ind. Electron. 2017, 64, 2296–2305. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Z.; Zhou, A. Machine Learning and Its Applications; Tsinghua University Press Co.: Beijing, China, 2006; Volume 4. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shao, M.; Castillo, C.; Gu, Z.; Fu, Y. Low-rank transfer subspace learning. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, IEEE, Washington, DC, USA, 10 December 2012; pp. 1104–1109. [Google Scholar]
- Xu, Y.; Li, Z.; Yang, J.; Zhang, D. A Survey of Dictionary Learning Algorithms for Face Recognition. IEEE Access 2017, 5, 8502–8514. [Google Scholar] [CrossRef]
- Yang, A.Y.; Sastry, S.S.; Ganesh, A.; Ma, Y. Fast ℓ1-minimization algorithms and an application in robust face recognition: A review. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1849–1852. [Google Scholar]
- Bearing Test Data. Case Western Reserve University Bearing Data Center. Available online: http://csegroups.case.edu/bearingdatacenter/home (accessed on 29 May 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | 1-NN [25] | SRC [26] | LSDT [27] | TSC + LR [4] | SSDT |
|---|---|---|---|---|---|
| L→V | 49.12 ± 5.58 | 51.71 ± 4.48 | 49.80 ± 4.49 | 53.96 ± 4.51 | 55.37 ± 6.59 |
| L→S | 44.69 ± 6.87 | 46.52 ± 2.92 | 44.42 ± 3.03 | 45.83 ± 3.45 | 48.14 ± 2.38 |
| S→L | 42.40 ± 8.11 | 49.51 ± 2.48 | 50.31 ± 3.67 | 45.73 ± 3.27 | 49.58 ± 3.21 |
| S→V | 50.20 ± 5.09 | 54.13 ± 3.55 | 56.04 ± 3.17 | 60.14 ± 3.62 | 58.57 ± 4.00 |
| V→L | 39.13 ± 8.30 | 51.24 ± 2.43 | 52.27 ± 2.63 | 50.11 ± 2.81 | 53.19 ± 3.74 |
| V→S | 43.43 ± 6.24 | 60.07 ± 1.48 | 60.57 ± 1.18 | 59.75 ± 1.85 | 61.85 ± 1.38 |
| Average | 44.83 ± 6.70 | 52.20 ± 2.89 | 52.23 ± 3.03 | 52.59 ± 3.25 | 54.45 ± 3.55 |
| Task | 1-NN [25] | SRC [26] | LSDT [27] | TSC + LR [4] | SSDT |
|---|---|---|---|---|---|
| L→V | 60.99 | 58.61 | 55.88 | 63.28 | 63.88 |
| L→S | 52.80 | 49.98 | 48.03 | 51.36 | 51.39 |
| S→L | 56.76 | 52.40 | 55.66 | 49.41 | 53.96 |
| S→V | 57.18 | 58.82 | 60.82 | 64.77 | 64.27 |
| V→L | 46.46 | 54.98 | 55.47 | 55.85 | 58.80 |
| V→S | 53.57 | 62.60 | 61.95 | 62.75 | 63.45 |
| Average | 54.63 | 56.23 | 56.30 | 57.90 | 59.29 |
| Task | 1-NN [25] | SRC [26] | LSDT [27] | TSC + LR [4] | SSDT |
|---|---|---|---|---|---|
| L→V | 52.15 ± 6.39 | 51.82 ± 3.13 | 50.24 ± 2.49 | 52.11 ± 3.26 | 54.48 ± 3.69 |
| L→S | 44.44 ± 7.63 | 44.11 ± 2.68 | 43.43 ± 1.90 | 45.31 ± 2.04 | 46.62 ± 3.03 |
| S→L | 35.47 ± 8.26 | 47.67 ± 4.21 | 47.72 ± 4.93 | 46.90 ± 2.60 | 48.59 ± 4.95 |
| S→V | 54.37 ± 4.80 | 57.30 ± 2.34 | 60.27 ± 4.03 | 62.87 ± 2.64 | 60.62 ± 3.42 |
| V→L | 39.32 ± 8.22 | 51.74 ± 3.38 | 52.94 ± 3.35 | 51.03 ± 3.25 | 51.69 ± 3.30 |
| V→S | 44.41 ± 5.42 | 61.87 ± 1.37 | 62.33 ± 2.15 | 61.90 ± 1.94 | 62.77 ± 1.52 |
| Average | 45.07 ± 6.79 | 52.42 ± 2.85 | 52.82 ± 3.14 | 53.35 ± 2.62 | 54.13 ± 3.32 |
| Task | 1-NN [25] | SRC [26] | LSDT [27] | TSC + LR [4] | SSDT |
|---|---|---|---|---|---|
| L→V | 61.02 | 57.69 | 53.47 | 57.42 | 61.74 |
| L→S | 55.86 | 48.00 | 46.74 | 48.39 | 51.70 |
| S→L | 48.47 | 51.04 | 53.09 | 50.78 | 54.71 |
| S→V | 62.93 | 62.04 | 65.90 | 66.50 | 66.97 |
| V→L | 57.06 | 57.18 | 57.29 | 55.05 | 56.83 |
| V→S | 53.23 | 65.04 | 66.79 | 65.38 | 65.78 |
| Average | 56.43 | 56.83 | 57.21 | 57.35 | 59.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y.; Liu, Y.; Song, H.; He, B.; Yuan, H.; Zhang, B. Research and Application of Semi-Supervised Category Dictionary Model Based on Transfer Learning. Appl. Sci. 2023, 13, 7841. https://doi.org/10.3390/app13137841
Dai Y, Liu Y, Song H, He B, Yuan H, Zhang B. Research and Application of Semi-Supervised Category Dictionary Model Based on Transfer Learning. Applied Sciences. 2023; 13(13):7841. https://doi.org/10.3390/app13137841
Chicago/Turabian StyleDai, Yuansheng, Yingyi Liu, Haoyu Song, Bing He, Haiwen Yuan, and Boyang Zhang. 2023. "Research and Application of Semi-Supervised Category Dictionary Model Based on Transfer Learning" Applied Sciences 13, no. 13: 7841. https://doi.org/10.3390/app13137841
APA StyleDai, Y., Liu, Y., Song, H., He, B., Yuan, H., & Zhang, B. (2023). Research and Application of Semi-Supervised Category Dictionary Model Based on Transfer Learning. Applied Sciences, 13(13), 7841. https://doi.org/10.3390/app13137841