
Target Selection Strategies for Demucs-Based Speech Enhancement



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Featured Application
Abstract
1. Introduction
- Embedding-based: A type of voice identity signature is computed from a previously captured audio recording of the target speech source. This, in turn, is used as part of the Demucs-Denoiser model to “nudge” its enhancement efforts towards the target speech source.
- Location-based: The target speech source is assumed to be located in front of a two-microphone array. This two-channel signal is then fed to a spatial filter (also known as a beamformer) that aims to amplify the target speech source presence in the mixture to then be enhanced by the Demucs-Denoiser model.
2. The Demucs-Denoiser Model
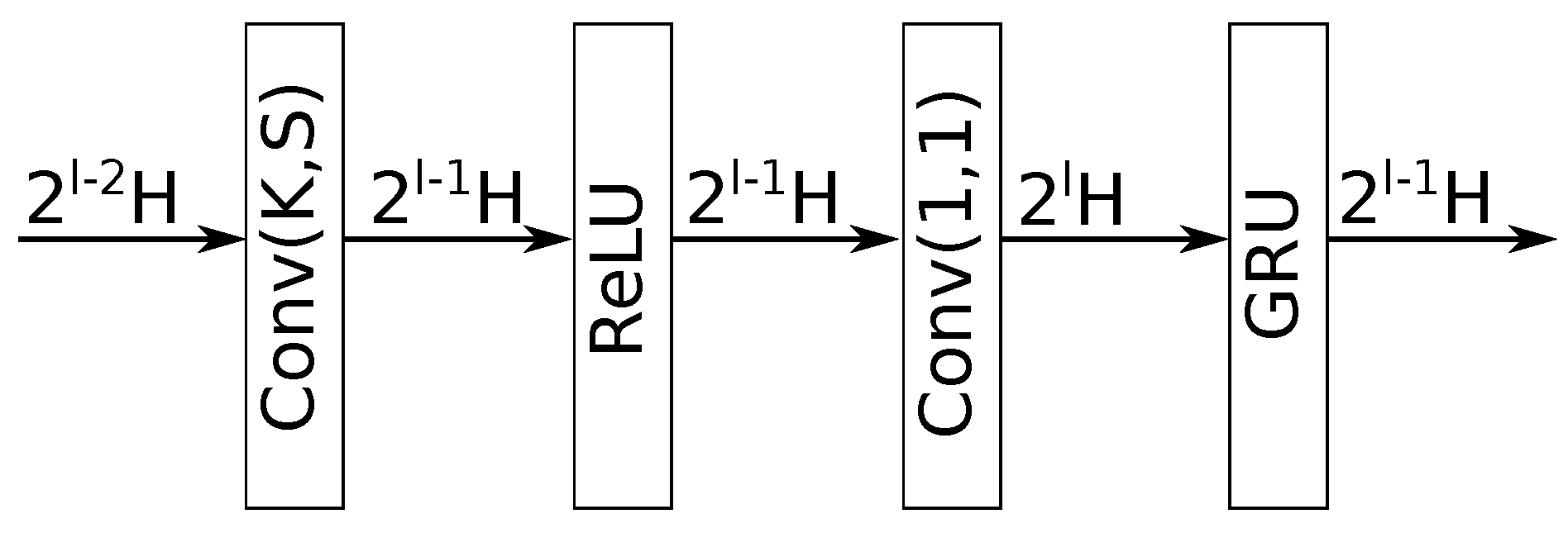
- Encoding stage. This stage consists of a series of L meta-layers, referred to as “encoding layers”, which are described in Figure 2. As can be seen, each encoding layer has (a) a 1-dimensional convolutional layer with a kernel size K, stride S, and output channels (where K, S, and H are all tunable parameters, and l is the encoding layer index); (b) a rectified linear unit (ReLU) layer [16]; (c) another 1-dimensional convolutional layer, with a kernel size of 1, stride of 1, and output channels; and (d) a gated recurrent unit (GRU) layer [17] whose objective is to force it to have output channels (the same as its first convolutional layer). The output of each meta-layer is fed to both the next encoding layer (or, if it is the last one, to the sequence modeling stage), as well as to its corresponding “decoding layer” in the decoding stage of the model. The latter is referred to as a “skip connection”.
- Sequence modeling stage. The output of the last encoding layer (meaning of the encoding stage in general) is a latent representation of the model’s input I (where , where X is the source of interest and N is the noise to be removed). The latent representation is fed to this stage, the objective of which is to predict the latent representation of the enhanced signal . Thus, it is crucial that the dimensions of its output are the same as of its input, so that the decoding stage is applied appropriately. In the causal version of the Demucs-Denoiser model (which is the one of interest for this work), this stage contains a stack of B number of long short-term memory (LSTM) layers, with number of hidden units, meaning that the number of hidden units (considered as the output of the sequence modeling stage) is equivalent to the number of output channels of the last encoding layer (i.e., the output of the decoding stage in general).
- Decoding stage. The objective of this stage is to decode the latent representation (created by the sequence modeling stage) back to the waveform domain, resulting in the enhanced signal . This stage comprises another series of L meta-layers, referred to as “decoding layers”, which are described in Figure 3. As can be seen, each decoding layer carries out the reverse of its corresponding encoding layer, being composed of (a) a 1-dimensional convolutional layer with a kernel size of 1, stride of 1, and output channels, (b) a GRU layer that converts the number of output channels to , (c) a 1-dimensional transposed convolutional layer with a kernel size K, stride S, and output channels, and (d) an ReLU layer. Its input is the element-wise addition of the skip connection from the corresponding lth encoding layer and of the output of the last decoding layer (or the output of the sequence modeling stage, if it is the first one). Additionally, the last decoding layer does not employ an ReLU layer since its corresponding convolutional layer has only one output channel and, thus, is the output of the Demucs-Denoiser model ().
3. Proposed Target Selection Strategies
3.1. Embedding-Based Target Selection
- Pooling channel- and context-dependent statistics to be used as part of its temporal attention mechanism, to focus on speaker characteristics that occur in different time segments.
- Creating a global context by joining local features with the input’s global properties (mean and standard deviation), so that the attention mechanism is more robust against noise.
- Rescaling features from each time segment to benefit from the previously described global context.
- Aggregating all the aforementioned features, as well as the ones from the first layers of the TDNN, and achieving this by way of summation into a static embedding size (in this case, 192 dimensions), regardless of the input size.
3.2. Location-Based Target Selection
4. Training Methodology
- Randomly select an inter-microphone distance between a given inter-microphone distance range of 0.05 and 0.21 m.
- Randomly select a user u from the set of clean recordings.
- Randomly select a recording from user u.
- Randomly select a 5 s segment from recording with an energy level above a given energy threshold of 0.6.
- Establish the location of the source of 1 m away from the microphone array in the simulated room.
- Randomly select a signal-to-noise ratio (SNR) between a given SNR range of 0 and 20 dB.
- Randomly select a noise recording .
- Randomly select a 5 s segment from recording .
- Apply the SNR to the noise segment.
- Randomly select a location of the source of in the simulated room.
- Randomly select a number of interferences E, which are other users from the clean recordings, with a maximum of 2.
- If :
- (a)
- Randomly select an input signal-to-interference ratio (SIR) between a given SIR range of 0 and 20 dB.
- (b)
- Randomly select the users that will act as interferences e, which should be different from u.
- (c)
- For each interference e:
- i.
- Randomly select a recording from user e.
- ii.
- Randomly select a 5 s segment from recording with an energy level above a given energy threshold of 0.6.
- iii.
- Randomly select a location of the source of in the simulated room.
- iv.
- Apply the SIR to the segment of interference e.
- Randomly select a reverberation time between a given reverberation time range of 0.1 and 3.0 s.
- Apply Pyroomacoustics to simulate the environment, with all the given audio segments (clean, noise, and interferences), the result of which is a two-channel recording (one channel for each simulated microphone).
- The simulated microphones are fed to the PFM filter to obtain .
- The clean recording .
- The output of the PFM filter .
- The first channel of the Pyroomacoustics output .
- A text file with the following information:
- –
- The location of the noise recording .
- –
- The location of all interference recordings .
- –
- The location of a randomly selected recording of user u, such that , to create the embedding of user u.
- All the relevant data creation parameters (SNR, E, input SIR, and ) are stored as part of the file name of the recording.
5. Evaluation Methodology
Distance Offset
- Number of interferences: [1, 2].
- Input SIR: 0 dB.
- Input SNR: 19 dB.
- Reverberation time: [0.1, 0.2] s.
- Horizontal distance from center: [−0.1, 0.1] m.
- Vertical distance from center: [−0.05, 0.05] m.
- Absolute distance from center: [0, 0.11] m (stored).
6. Results
- Number of interferences: 0.
- Input SIR:
- –
- Not applicable when there are no interferences.
- –
- Between 0 and 7 dB (inclusive), when there are interferences.
- Input SNR: greater than or equal to 15 dB.
- Reverberation time: less than or equal to 0.2 s.
- Distance from center: 0 m.
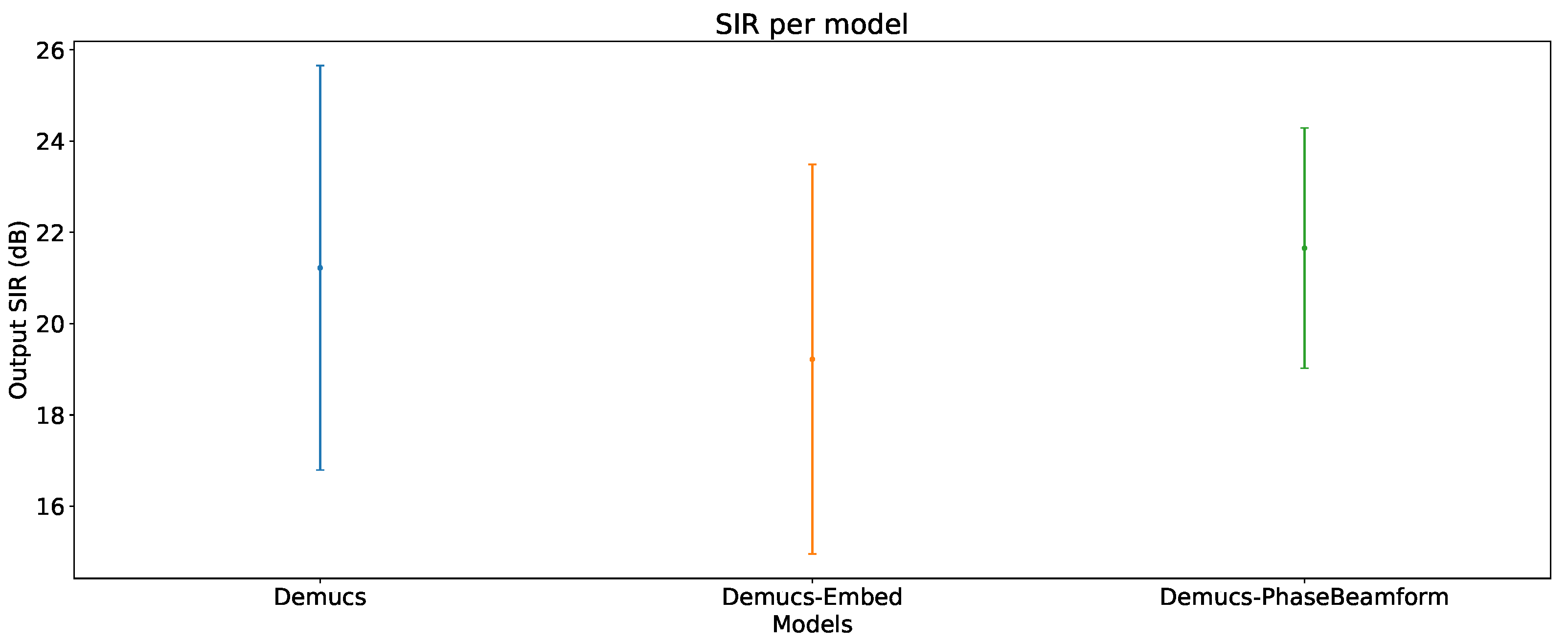
6.1. Overall Output SIR
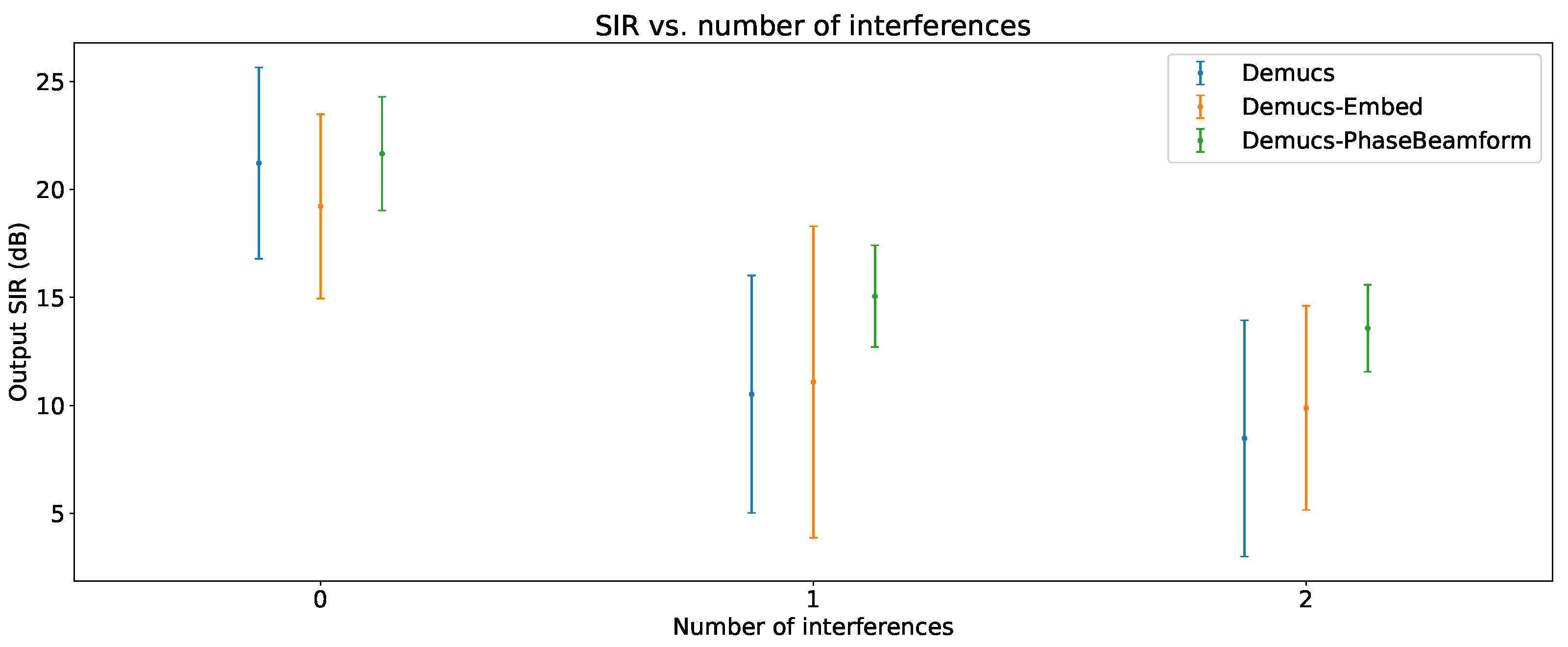
6.2. Output SIR vs. Number of Interferences
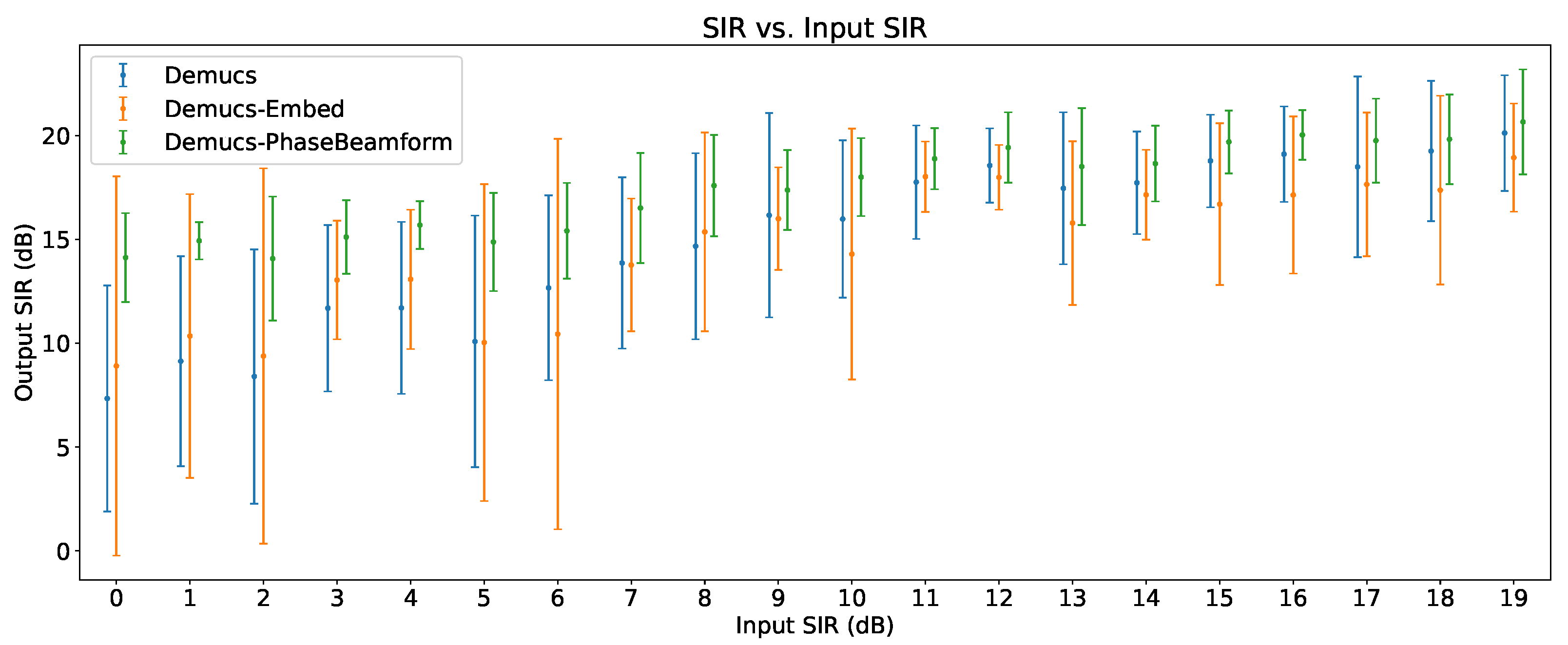
6.3. Output SIR vs. Input SIR
6.4. Output SIR vs. Input SNR
6.5. Output SIR vs. Reverberation Time
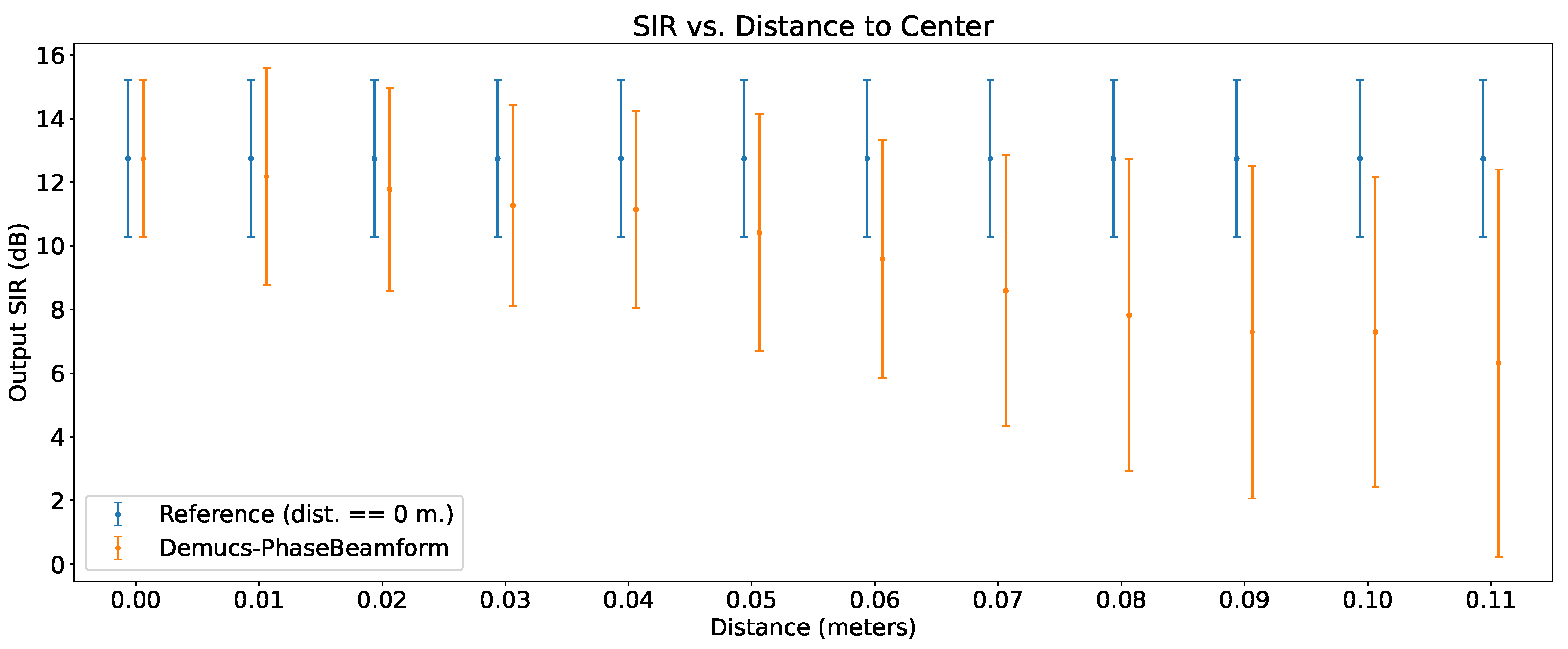
6.6. Output SIR vs. Distance from Center
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Das, N.; Chakraborty, S.; Chaki, J.; Padhy, N.; Dey, N. Fundamentals, present and future perspectives of speech enhancement. Int. J. Speech Technol. 2021, 24, 883–901. [Google Scholar] [CrossRef]
- Eskimez, S.E.; Soufleris, P.; Duan, Z.; Heinzelman, W. Front-end speech enhancement for commercial speaker verification systems. Speech Commun. 2018, 99, 101–113. [Google Scholar] [CrossRef]
- Porov, A.; Oh, E.; Choo, K.; Sung, H.; Jeong, J.; Osipov, K.; Francois, H. Music Enhancement by a Novel CNN Architecture. In Proceedings of the Audio Engineering Society Convention 145, New York, NY, USA, 17–20 October 2018; pp. 1–8, 10036. [Google Scholar]
- Lopatka, K.; Czyzewski, A.; Kostek, B. Improving listeners’ experience for movie playback through enhancing dialogue clarity in soundtracks. Digit. Signal Process. 2016, 48, 40–49. [Google Scholar] [CrossRef]
- Leinbaugh, D.W. Guaranteed response times in a hard-real-time environment. IEEE Trans. Softw. Eng. 1980, SE-6, 85–91. [Google Scholar] [CrossRef]
- Joseph, M.; Pandya, P. Finding response times in a real-time system. Comput. J. 1986, 29, 390–395. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Shi, J.; Zhang, W.; Subramanian, A.S.; Chang, X.; Kamo, N.; Hira, M.; Hayashi, T.; Boeddeker, C.; Chen, Z.; et al. ESPnet-SE: End-to-end speech enhancement and separation toolkit designed for ASR integration. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 785–792. [Google Scholar]
- Rascon, C.; Meza, I. Localization of sound sources in robotics: A review. Robot. Auton. Syst. 2017, 96, 184–210. [Google Scholar] [CrossRef]
- Lai, Y.H.; Zheng, W.Z. Multi-objective learning based speech enhancement method to increase speech quality and intelligibility for hearing aid device users. Biomed. Signal Process. Control. 2019, 48, 35–45. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, D.; Zhao, R.; Yu, Y.; Shen, J. Sensing to hear: Speech enhancement for mobile devices using acoustic signals. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–30. [Google Scholar] [CrossRef]
- Rao, W.; Fu, Y.; Hu, Y.; Xu, X.; Jv, Y.; Han, J.; Jiang, Z.; Xie, L.; Wang, Y.; Watanabe, S.; et al. Conferencingspeech challenge: Towards far-field multi-channel speech enhancement for video conferencing. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 679–686. [Google Scholar]
- Défossez, A.; Synnaeve, G.; Adi, Y. Real Time Speech Enhancement in the Waveform Domain. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3291–3295. [Google Scholar] [CrossRef]
- Rascon, C. Characterization of Deep Learning-Based Speech-Enhancement Techniques in Online Audio Processing Applications. Sensors 2023, 23, 4394. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised Speech Separation Based on Deep Learning: An Overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Hara, K.; Saito, D.; Shouno, H. Analysis of function of rectified linear unit used in deep learning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–8. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1597–1600. [Google Scholar]
- Smith, J.; Gossett, P. A flexible sampling-rate conversion method. In Proceedings of the ICASSP’84. IEEE International Conference on Acoustics, Speech, and Signal Processing, San Diego, CA, USA, 19–21 March 1984; IEEE: Piscataway, NJ, USA, 1984; Volume 9, pp. 112–115. [Google Scholar]
- Bagchi, D.; Plantinga, P.; Stiff, A.; Fosler-Lussier, E. Spectral feature mapping with mimic loss for robust speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5609–5613. [Google Scholar]
- Fu, S.W.; Yu, C.; Hsieh, T.A.; Plantinga, P.; Ravanelli, M.; Lu, X.; Tsao, Y. MetricGAN+: An Improved Version of MetricGAN for Speech Enhancement. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 201–205. [Google Scholar] [CrossRef]
- Desplanques, B.; Thienpondt, J.; Demuynck, K. ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN based speaker verification. In Proceedings of the 21st Annual Conference of the International Speech Communication Association (INTERSPEECH 2020), Shanghai, China, 14–18 September 2020; International Speech Communication Association (ISCA): Grenoble, France, 2020; pp. 3830–3834. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5329–5333. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; McCree, A.; Povey, D.; Khudanpur, S. Speaker recognition for multi-speaker conversations using x-vectors. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5796–5800. [Google Scholar]
- Sugiyama, M.; Sawai, H.; Waibel, A.H. Review of tdnn (time delay neural network) architectures for speech recognition. In Proceedings of the 1991 IEEE International Symposium on Circuits and Systems (ISCAS), Singapore, 11–14 June 1991; IEEE: Piscataway, NJ, USA, 1991; pp. 582–585. [Google Scholar]
- Zhao, Z.; Li, Z.; Wang, W.; Zhang, P. PCF: ECAPA-TDNN with Progressive Channel Fusion for Speaker Verification. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Han, S.; Ahn, Y.; Kang, K.; Shin, J.W. Short-Segment Speaker Verification Using ECAPA-TDNN with Multi-Resolution Encoder. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Xue, J.; Deng, Y.; Han, Y.; Li, Y.; Sun, J.; Liang, J. ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis. In Proceedings of the 2022 13th International Symposium on Chinese Spoken Language Processing (ISCSLP), Singapore, 11–14 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 230–234. [Google Scholar]
- Wang, D.; Ding, Y.; Zhao, Q.; Yang, P.; Tan, S.; Li, Y. ECAPA-TDNN Based Depression Detection from Clinical Speech. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Incheon, Republic of Korea, 18–22 September 2022. [Google Scholar]
- Sheikh, S.A.; Sahidullah, M.; Hirsch, F.; Ouni, S. Introducing ECAPA-TDNN and Wav2Vec2. 0 embeddings to stuttering detection. arXiv 2022, arXiv:2204.01564. [Google Scholar]
- Wang, Q.; Muckenhirn, H.; Wilson, K.; Sridhar, P.; Wu, Z.; Hershey, J.; Saurous, R.A.; Weiss, R.J.; Jia, Y.; Moreno, I.L. Voicefilter: Targeted voice separation by speaker-conditioned spectrogram masking. arXiv 2018, arXiv:1810.04826. [Google Scholar]
- Wang, Q.; Moreno, I.L.; Saglam, M.; Wilson, K.; Chiao, A.; Liu, R.; He, Y.; Li, W.; Pelecanos, J.; Nika, M.; et al. VoiceFilter-Lite: Streaming targeted voice separation for on-device speech recognition. arXiv 2020, arXiv:2009.04323. [Google Scholar]
- Eskimez, S.E.; Yoshioka, T.; Ju, A.; Tang, M.; Parnamaa, T.; Wang, H. Real-Time Joint Personalized Speech Enhancement and Acoustic Echo Cancellation with E3Net. arXiv 2022, arXiv:2211.02773. [Google Scholar]
- Levin, M. Maximum-likelihood array processing. In Seismic Discrimination Semi-Annual Technical Summary Report; Lincoln Laboratory, Massachusetts Institute of Technology: Lexington, MA, USA, 1964; Volume 21. [Google Scholar]
- Habets, E.A.P.; Benesty, J.; Cohen, I.; Gannot, S.; Dmochowski, J. New insights into the MVDR beamformer in room acoustics. IEEE Trans. Audio Speech Lang. Process. 2009, 18, 158–170. [Google Scholar] [CrossRef]
- Griffiths, L.; Jim, C. An alternative approach to linearly constrained adaptive beamforming. IEEE Trans. Antennas Propag. 1982, 30, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Gannot, S.; Cohen, I. Speech enhancement based on the general transfer function GSC and postfiltering. IEEE Trans. Speech Audio Process. 2004, 12, 561–571. [Google Scholar] [CrossRef]
- Rascon, C. A Corpus-Based Evaluation of Beamforming Techniques and Phase-Based Frequency Masking. Sensors 2021, 21, 5005. [Google Scholar] [CrossRef]
- Maldonado, A.; Rascon, C.; Velez, I. Lightweight online separation of the sound source of interest through blstm-based binary masking. Comput. Sist. 2020, 24, 1257–1270. [Google Scholar] [CrossRef]
- Reddy, C.K.; Gopal, V.; Cutler, R.; Beyrami, E.; Cheng, R.; Dubey, H.; Matusevych, S.; Aichner, R.; Aazami, A.; Braun, S.; et al. The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results. arXiv 2020, arXiv:2005.13981. [Google Scholar]
- Scheibler, R.; Bezzam, E.; Dokmanić, I. Pyroomacoustics: A python package for audio room simulation and array processing algorithms. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 351–355. [Google Scholar]
- Bock, S.; Weiß, M. A proof of local convergence for the Adam optimizer. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rascon, C.; Fuentes-Pineda, G. Target Selection Strategies for Demucs-Based Speech Enhancement. Appl. Sci. 2023, 13, 7820. https://doi.org/10.3390/app13137820
Rascon C, Fuentes-Pineda G. Target Selection Strategies for Demucs-Based Speech Enhancement. Applied Sciences. 2023; 13(13):7820. https://doi.org/10.3390/app13137820
Chicago/Turabian StyleRascon, Caleb, and Gibran Fuentes-Pineda. 2023. "Target Selection Strategies for Demucs-Based Speech Enhancement" Applied Sciences 13, no. 13: 7820. https://doi.org/10.3390/app13137820
APA StyleRascon, C., & Fuentes-Pineda, G. (2023). Target Selection Strategies for Demucs-Based Speech Enhancement. Applied Sciences, 13(13), 7820. https://doi.org/10.3390/app13137820