
Generalized Spoof Detection and Incremental Algorithm Recognition for Voice Spoofing

Abstract
:1. Introduction
- (1)
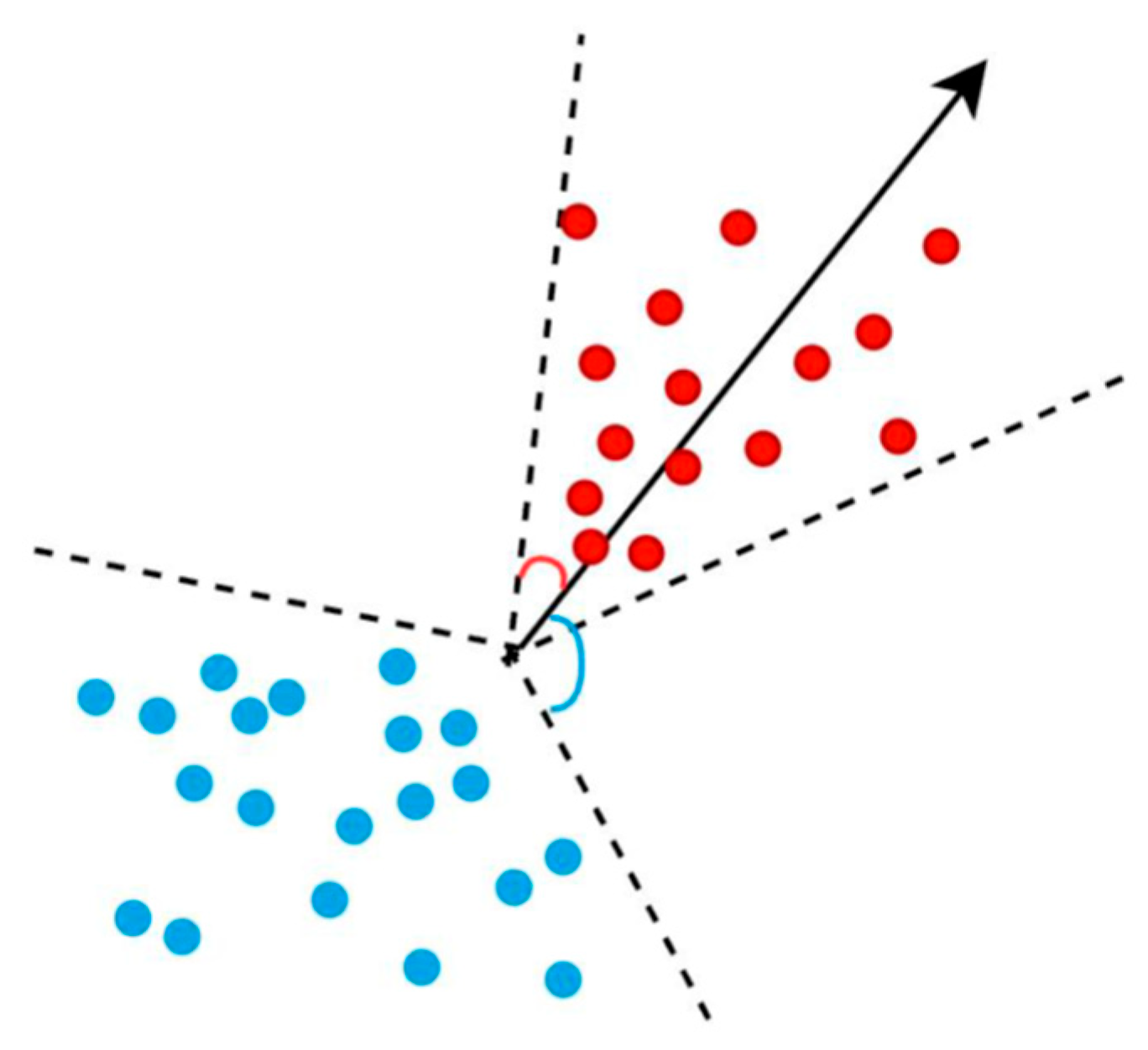
- The generalizability of the spoof detection model is discussed from the perspective of the embedding space and decision boundaries. The embedding space of real voices is compactly distributed, whereas that of the spoofing voices is more dispersed. A highly generalized decision boundary is learned to maintain them at a certain distance from each other.
- (2)
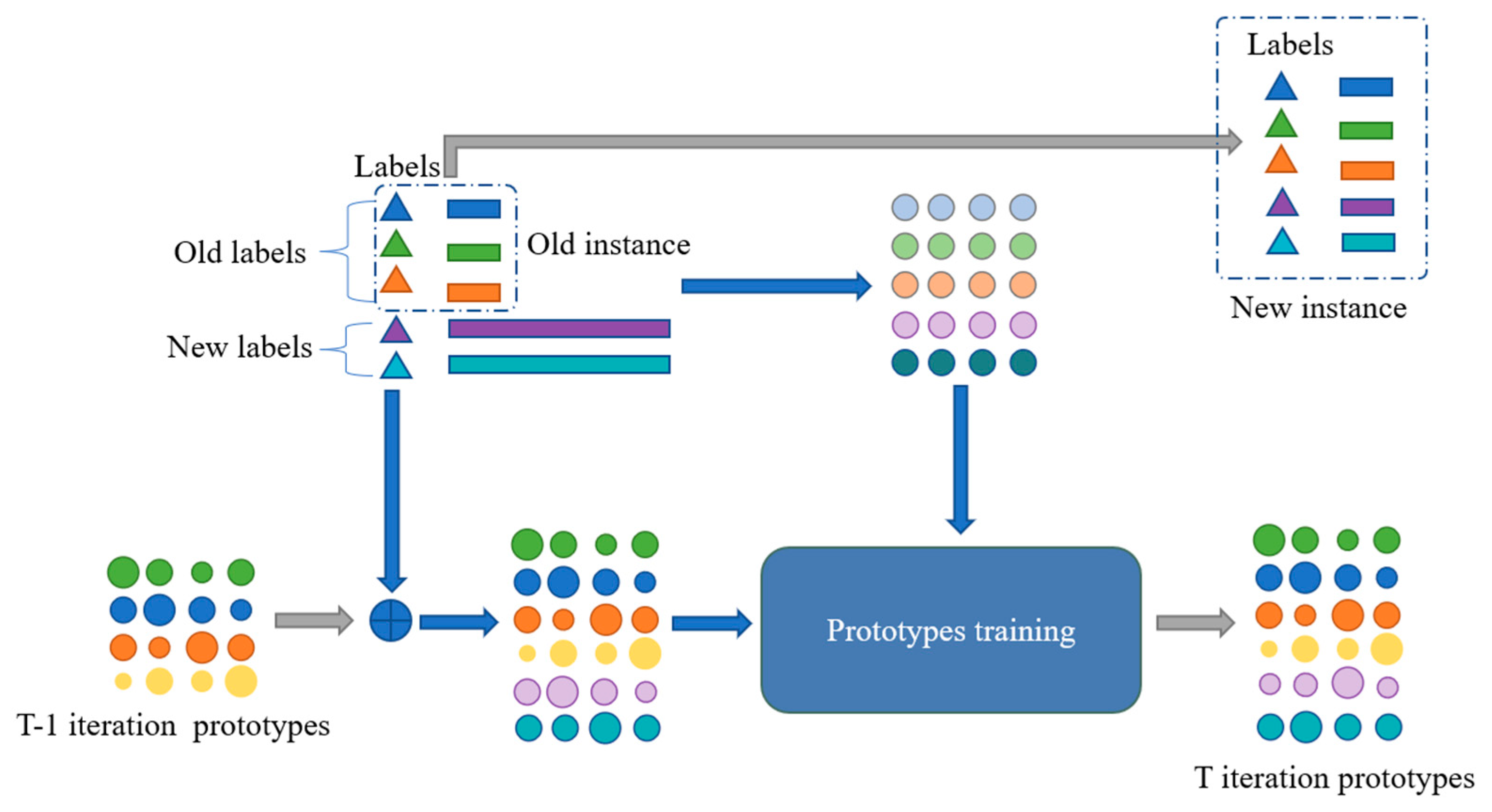
- A method for voice spoof algorithm recognition based on incremental learning is presented, which can adapt to the feature distribution of the new algorithms for spoofing voices without having an excessive impact on the feature distribution of the old algorithms.
- (3)
- A system combining spoof detection and algorithm recognition is first proposed, which facilitates the traceability of spoofing voices by implementing spoof algorithm recognition following detection. The experimental results demonstrate the effectiveness of the proposed system.
2. Related Work
2.1. Domain Adaptation
2.2. One-Class Learning Method
2.3. Prototype Learning
2.4. Incremental Learning
3. Voice Spoof Detection and Algorithm Recognition System
3.1. Generalized Voice Spoof Detection
3.1.1. Domain Adaptation Based on Decision Boundary Maximization
3.1.2. Domain Adaptation Based on Decision Boundary Maximization
3.2. Incremental Spoof Algorithms Recognition
3.2.1. Prototype Learning
3.2.2. Incremental Learning Module
4. Experimental Methods
4.1. Dataset
4.2. Training Details
4.2.1. Training Parameters for Voice Spoof Detection
4.2.2. Training Parameters for Spoof Algorithm Recognition
4.2.3. Evaluation Metrics
4.3. Experimental Results
4.3.1. Results of Spoof Detection
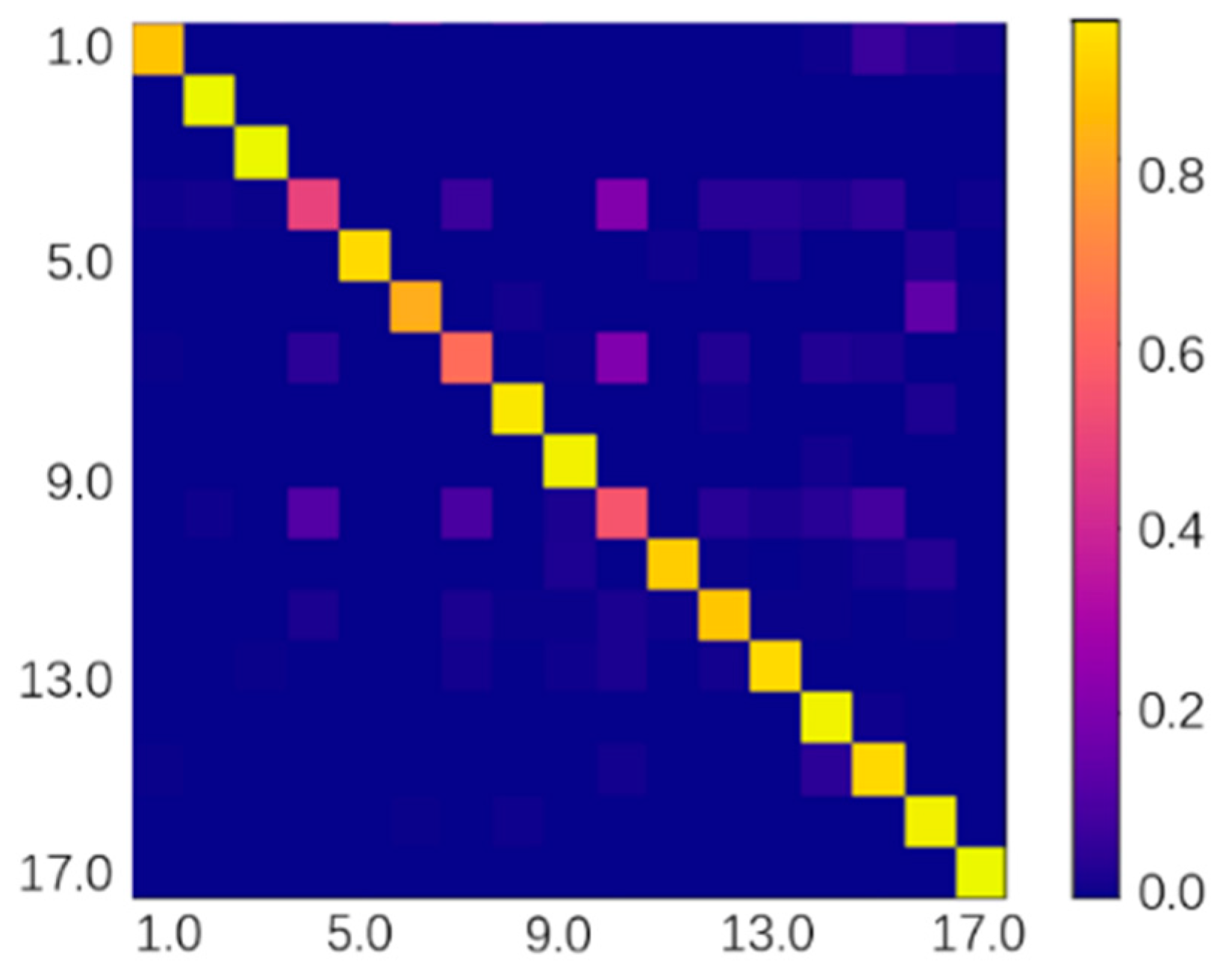
4.3.2. Results of Spoof Algorithm Recognition
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Z.; Evans, N.; Kinnunen, T.; Yamagishi, J.; Alegre, F.; Li, H. Spoofing and countermeasures for speaker verification: A survey. Speech Commun. 2015, 66, 130–153. [Google Scholar] [CrossRef] [Green Version]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.H.; Lee, K.A. ASVspoof 2019: Future horizons in spoofed and fake audio detection. Proc. Interspeech. 2019, 2019, 1008–1012. [Google Scholar]
- Kamble, M.R.; Sailor, H.B.; Patil, H.A.; Li, H. Advances in antispoofing: From the perspective of ASVspoof challenges. APSIPA Trans. Signal Inf. Process. 2020, 9, 21. [Google Scholar] [CrossRef] [Green Version]
- Das, R.K.; Kinnunen, T.; Huang, W.-C.; Ling, Z.-H.; Yamagishi, J.; Yi, Z.; Tian, X.; Toda, T. Predictions of subjective ratings and spoofing assessments of voice conversion challenge 2020 submissions. arXiv 2020, arXiv:2009.03554. [Google Scholar]
- Wu, Z.; Kinnunen, T.; Evans, N.; Yamagishi, J.; Hanilçi, C.; Sahidullah; Sizov, A. ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; Volume 2015, pp. 2037–2041. [Google Scholar]
- Kinnunen, T.; Sahidullah; Delgado, H.; Todisco, M.; Evans, N.; Yamagishi, J.; Lee, K.A. The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection. Proc. Interspeech. 2017, 2–6. [Google Scholar]
- Zhang, C.; Yu, C.; Hansen, J.H. An investigation of deep-learning frameworks for speaker verification antispoofing. IEEE J. Sel. Topics Signal Process. 2017, 11, 684–694. [Google Scholar] [CrossRef]
- Gomez-Alanis, A.; Peinado, A.M.; Gonzalez, J.A.; Gomez, A.M. A light convolutional GRU-RNN deep feature extractor for ASV spoofing detection. Proc. Interspeech. 2019, 2019, 1068–1072. [Google Scholar]
- Wu, Z.; Das, R.K.; Yang, J.; Li, H. Light convolutional neural network with feature genuinization for detection of synthetic speech attacks. Proc. Interspeech. 2020, 2020, 1101–1105. [Google Scholar]
- Khan, S.S.; Madden, M.G. A Survey of Recent Trends in One Class Classification. In Artificial Intelligence and Cognitive Science. AICS 2009. Lecture Notes in Computer Science; Coyle, L., Freyne, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 6206, pp. 188–197. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Hadsell, R. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA. 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Liu, C.L. Robust Classification with Convolutional Prototype Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3474–3482. [Google Scholar]
- Zhang, Y.; Bai, G.; Li, X.; Curtis, C.; Chen, C.; Ko, R.K.L. PrivColl: Practical Privacy-Preserving Collaborative Machine Learning. In Lecture Notes in Computer Science, Proceedings of the Computer Security–ESORICS 2020, Guildford, UK, 14–18 September 2020; Chen, L., Li, N., Liang, K., Schneider, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12308, pp. 399–418. [Google Scholar]
- Peng, X.; Huang, Z.; Zhu, Y.; Saenko, K. Federated adversarial domain adaptation. arXiv 2019, arXiv:1911.02054. [Google Scholar]
- Bejiga, M.B.; Melgani, F. Gan-Based Domain Adaptation for Object Classification. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1264–1267. [Google Scholar]
- Paris, C.; Bruzzone, L. A sensor-driven domain adaptation method for the classification of remote sensing images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 185–188. [Google Scholar]
- Alegre, F.; Amehraye, A.; Evans, N. A one-class classification approach to generalised speaker verification spoofing countermeasures usinglocal binary patterns. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013. [Google Scholar]
- Zhang, Y.; Jiang, F.; Duan, Z. One-Class Learning Towards Synthetic Voice Spoofing Detection. IEEE Signal Process. Lett. 2021, 28, 937–941. [Google Scholar] [CrossRef]
- Liu, C.-L.; Nakagawa, M. Evaluation of prototype learning algorithms for nearest-neighbor classifier in application to handwritten character recognition. Pattern Recognit. 2001, 34, 601–615. [Google Scholar] [CrossRef]
- Sato, A.; Yamada, K. A formulation of learning vector quantization using a new misclassification measure. In Proceedings of the Fourteenth International Conference on Pattern Recognition, Brisbane, QLD, Australia, 20 August 1998; Volume 1, pp. 322–325. [Google Scholar]
- Bonilla, E.; Robles-Kelly, A. Discriminative probabilistic prototype learning. arXiv 2012, arXiv:1206.4686. [Google Scholar]
- Divvala, S.K.; Farhadi, A.; Guestrin, C. Learning Everything about Anything: Webly-Supervised Visual Concept Learning. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3270–3277. [Google Scholar]
- Xiao, T.; Zhang, J.; Yang, K.; Peng, Y.; Zhang, Z. Error-driven incremental learning in deep convolutional neural network for large-scale image classification. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 177–186. [Google Scholar]
- Han, S.; Meng, Z.; Khan, A.S.; Tong, Y. Incremental boosting convolutional neural network for facial action unit recognition. Adv. Neural Inf. Process. Syst. 2017, 29, 109–117. [Google Scholar]
- Wang, Z.; Kong, Z.; Changra, S.; Tao, H.; Khan, L. Robust High Dimensional Stream Classification with Novel Class Detection. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1418–1429. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A large-scale public database of synthetized, converted and replayed speech. Comput. Speech Lang. 2020, 64, 101114. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Kinnunen, T.; Lee, K.A.; Delgado, H.; Evans, N.; Todisco, M.; Sahidullah; Yamagishi, J.; Reynolds, D.A. t-DCF: A detection cost function for the tandem assessment of spoofing countermeasures and automatic speaker verification. In Proceedings of the Speaker Odyssey 2018 The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018; pp. 312–319. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | EER (%) | Min t-DCF |
|---|---|---|
| LFCC-GMM | 8.090 | 0.21160 |
| LFCC-LCNN—AM-Softmax | 4.647 | 0.08278 |
| LFCC-LCNN—Sigmoid | 2.869 | 0.07248 |
| LFCC-LCNN—Domain adaptation | 2.638 | 0.08844 |
| LFCC-LCNN—OC-Softmax | 2.530 | 0.0682 |
| Method | 0 Iters | 1 Iters | 2 Iters | 3 Iters | 4 Iters |
|---|---|---|---|---|---|
| Avg (%) | Avg (%) | Avg (%) | Avg (%) | Avg (%) | |
| iCaRL | 99.03 | 87.97 | 84.86 | 83.20 | 76.58 |
| prototype | 98.78 | 85.38 | 84.51 | 82.02 | 68.77 |
| prototype + weight | 98.78 | 87.17 | 85.31 | 88.35 | 79.89 |
| Attacks | Prototype + Weight |
|---|---|
| A1 | 87.30 |
| A2 | 99.73 |
| A3 | 99.89 |
| A4 | 49.56 |
| A5 | 92.65 |
| A6 | 81.36 |
| A7 | 62.63 |
| A8 | 95.97 |
| A9 | 98.09 |
| A10 | 55.20 |
| A11 | 89.60 |
| A12 | 88.18 |
| A13 | 92.71 |
| A14 | 98.44 |
| A15 | 92.14 |
| A16 | 98.09 |
| A17 | 99.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Zhao, Y.; Wang, H. Generalized Spoof Detection and Incremental Algorithm Recognition for Voice Spoofing. Appl. Sci. 2023, 13, 7773. https://doi.org/10.3390/app13137773
Guo J, Zhao Y, Wang H. Generalized Spoof Detection and Incremental Algorithm Recognition for Voice Spoofing. Applied Sciences. 2023; 13(13):7773. https://doi.org/10.3390/app13137773
Chicago/Turabian StyleGuo, Jinlin, Yancheng Zhao, and Haoran Wang. 2023. "Generalized Spoof Detection and Incremental Algorithm Recognition for Voice Spoofing" Applied Sciences 13, no. 13: 7773. https://doi.org/10.3390/app13137773
APA StyleGuo, J., Zhao, Y., & Wang, H. (2023). Generalized Spoof Detection and Incremental Algorithm Recognition for Voice Spoofing. Applied Sciences, 13(13), 7773. https://doi.org/10.3390/app13137773