



Frame-Based Phone Classification Using EMG Signals †


Abstract
1. Introduction
2. Materials and Methods
2.1. Acquisition Setup
2.1.1. Recording Procedure
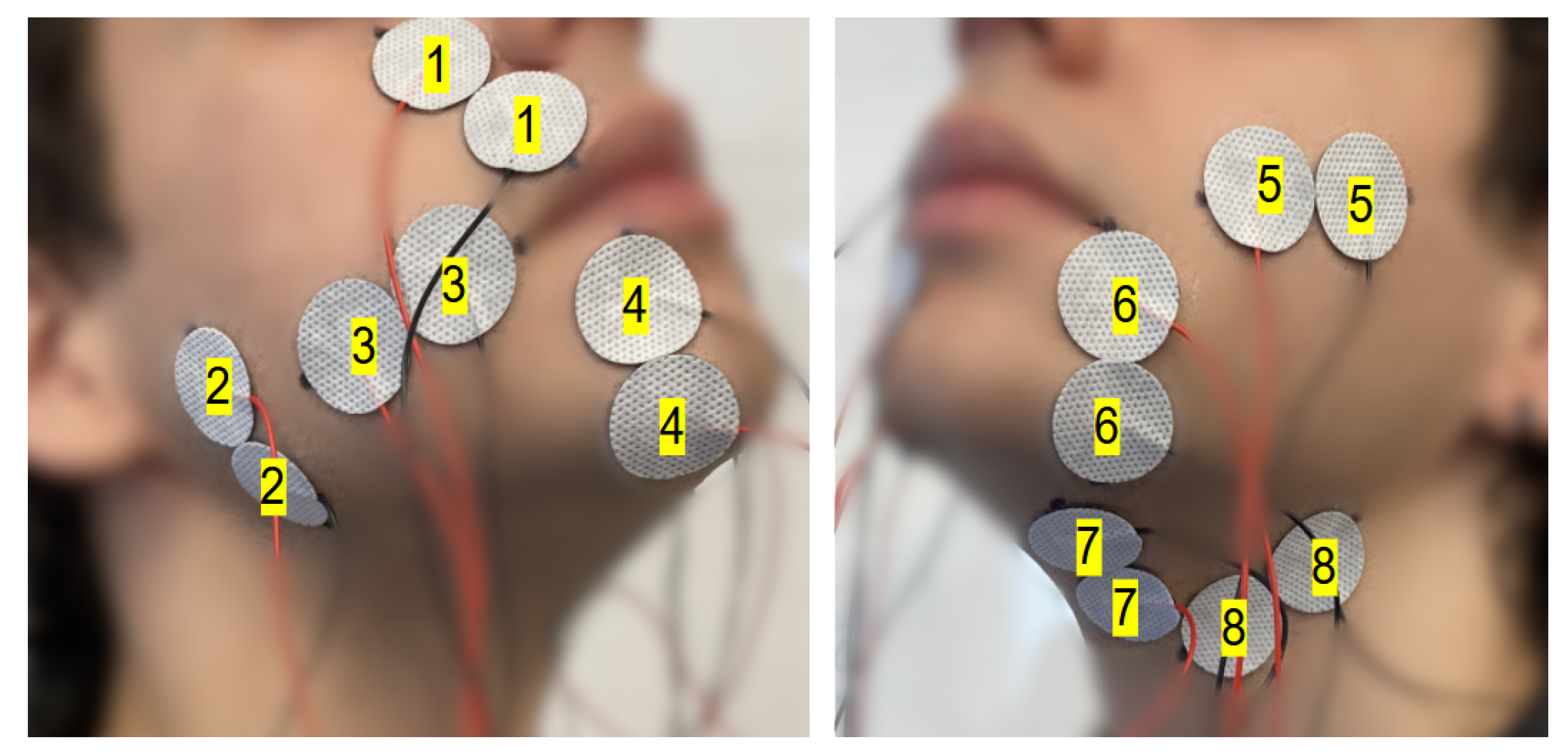
2.1.2. Electrode Setup
- 1
- Levator labii superioris (channel 1)
- 2
- Masseter (channel 2)
- 3
- Risorius (channel 3)
- 4
- Depressor labii inferioris (channel 4)
- 5
- Zygomaticus major (channel 5)
- 6
- Depressor anguli oris (channel 6)
- 7
- Anterior belly of the digastric (channel 7)
- 8
- Stylohyoid (channel 8)
2.2. The ReSSInt-EMG Database
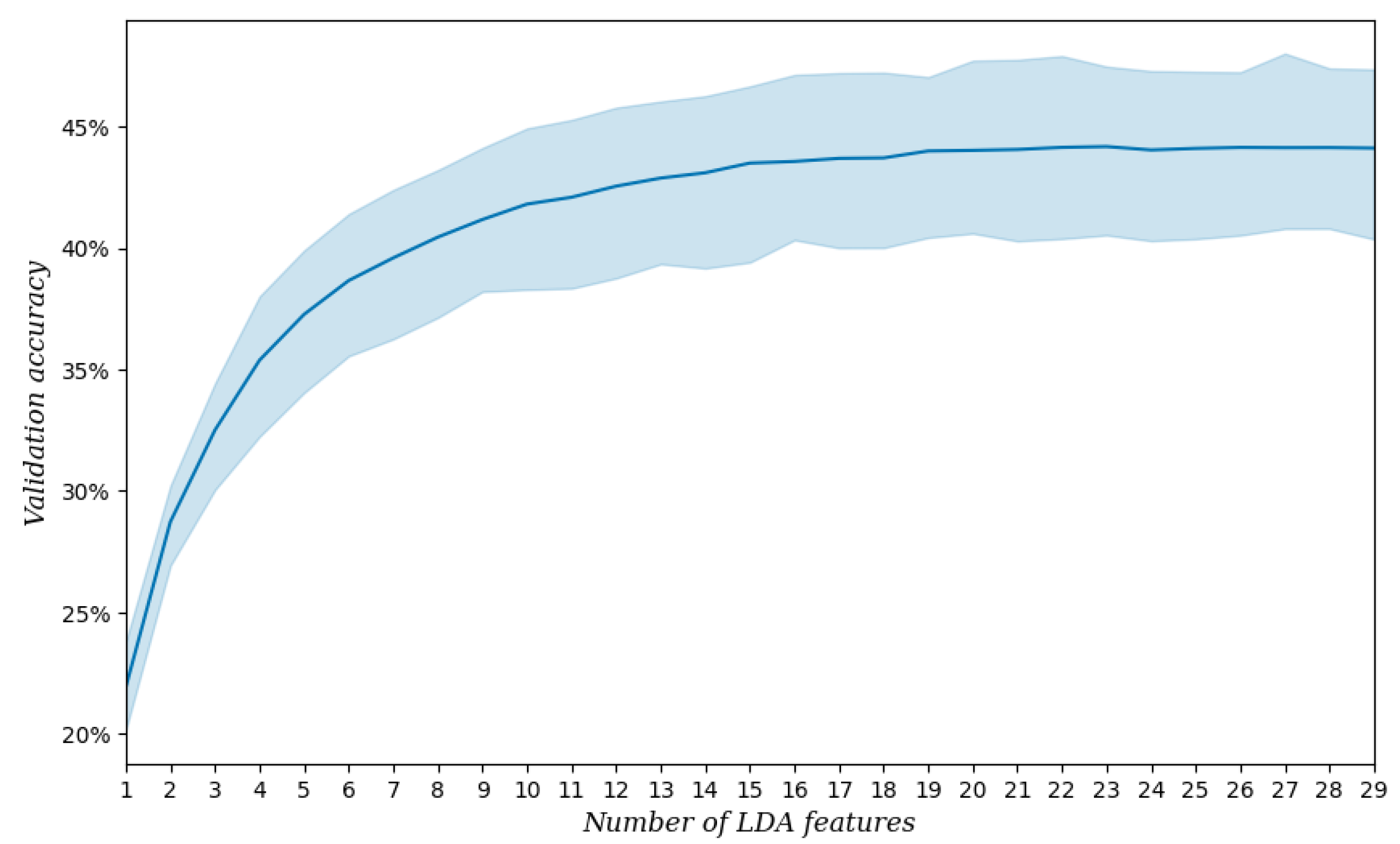
2.3. Feature Extraction
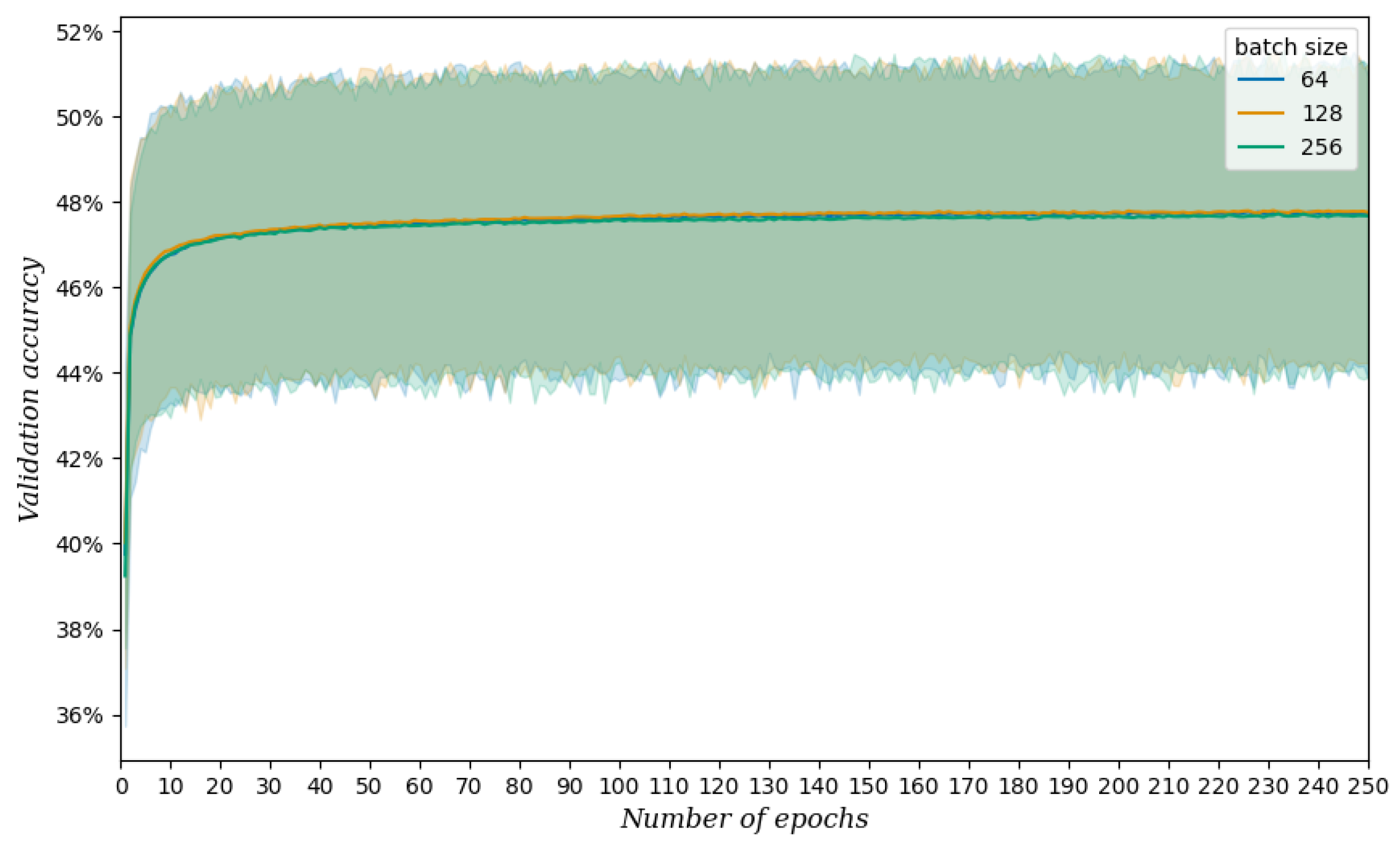
2.4. Experiments
2.4.1. Classification Method
2.4.2. Speaker and Session Dependency
2.4.3. Cross-Validation
3. Results
3.1. Speaker-Dependent, Session-Dependent Classification
3.2. Speaker-Dependent, Session-Independent Classification
3.3. Speaker-Independent, Session-Independent Classification
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EMG | Electromyography |
| LDA | Linear Discriminant Analysis |
| SSI | Silent Speech Interface |
| TD | Time-Domain |
| TTS | Text-to-Speech |
| VCV | Vowel–Consonant–Vowel |
References
- Hernaez, I.; Gonzalez Lopez, J.A.; Navas, E.; Pérez Córdoba, J.L.; Saratxaga, I.; Olivares, G.; Sanchez de la Fuente, J.; Galdón, A.; Garcia, V.; Castillo, J.d.; et al. ReSSInt project: Voice restoration using Silent Speech Interfaces. In Proceedings of the IberSPEECH 2022, ISCA, Granada, Spain, 14–16 November 2022; pp. 226–230. [Google Scholar] [CrossRef]
- Tang, C.G.; Sinclair, C.F. Voice Restoration after Total Laryngectomy. Otolaryngol. Clin. N. Am. 2015, 48, 687–702. [Google Scholar] [CrossRef] [PubMed]
- Zieliński, K.; Rączaszek-Leonardi, J. A Complex Human-Machine Coordination Problem: Essential Constraints on Interaction Control in Bionic Communication Systems. In Proceedings of the CHI Conference on Human Factors in Computing Systems Extended Abstracts, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Wand, M.; Janke, M.; Schultz, T. The EMG-UKA corpus for electromyographic speech processing. In Proceedings of the Interspeech 2014, Singapore, 14–18 September 2014; pp. 1593–1597. [Google Scholar] [CrossRef]
- Gaddy, D.; Klein, D. Digital voicing of silent speech. arXiv 2020, arXiv:2010.02960. [Google Scholar]
- Diener, L.; Roustay Vishkasougheh, M.; Schultz, T. CSL-EMG_Array: An Open Access Corpus for EMG-to-Speech Conversion. In Proceedings of the INTERSPEECH 2020, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Freitas, J.; Teixeira, A.; Dias, J. Multimodal corpora for silent speech interaction. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 4507–4511. [Google Scholar]
- Safie, S.I.; Yusof, M.I.; Rahim, R.; Taib, A. EMG database for silent speech Ruqyah recitation. In Proceedings of the 2016 IEEE EMBS Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 4–8 December 2016; pp. 712–715. [Google Scholar] [CrossRef]
- Lopez-Larraz, E.; Mozos, O.M.; Antelis, J.M.; Minguez, J. Syllable-based speech recognition using EMG. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 4699–4702. [Google Scholar] [CrossRef]
- Ma, S.; Jin, D.; Zhang, M.; Zhang, B.; Wang, Y.; Li, G.; Yang, M. Silent Speech Recognition Based on Surface Electromyography. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 4497–4501. [Google Scholar] [CrossRef]
- Lee, K.S. EMG-Based Speech Recognition Using Hidden Markov Models with Global Control Variables. IEEE Trans. Biomed. Eng. 2008, 55, 930–940. [Google Scholar] [CrossRef] [PubMed]
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent speech interfaces. Speech Commun. 2010, 52, 270–287. [Google Scholar] [CrossRef]
- Gonzalez-Lopez, J.A.; Gomez-Alanis, A.; Martin Donas, J.M.; Perez-Cordoba, J.L.; Gomez, A.M. Silent Speech Interfaces for Speech Restoration: A Review. IEEE Access 2020, 8, 177995–178021. [Google Scholar] [CrossRef]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip Reading Sentences in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3444–3453. [Google Scholar] [CrossRef]
- Gonzalez, J.A.; Cheah, L.A.; Gomez, A.M.; Green, P.D.; Gilbert, J.M.; Ell, S.R.; Moore, R.K.; Holdsworth, E. Direct Speech Reconstruction From Articulatory Sensor Data by Machine Learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2362–2374. [Google Scholar] [CrossRef]
- Anumanchipalli, G.K.; Chartier, J.; Chang, E.F. Speech Synthesis from Neural Decoding of Spoken Sentences. Nature 2019, 568, 493–498. [Google Scholar] [CrossRef] [PubMed]
- Toth, A.R.; Wand, M.; Schultz, T. Synthesizing speech from electromyography using voice transformation techniques. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Janke, M.; Wand, M.; Nakamura, K.; Schultz, T. Further investigations on EMG-to-speech conversion. In Proceedings of the ICASSP, Kyoto, Japan, 25–30 March 2012; pp. 365–368. [Google Scholar] [CrossRef]
- Li, H.; Lin, H.; Wang, Y.; Wang, H.; Zhang, M.; Gao, H.; Ai, Q.; Luo, Z.; Li, G. Sequence-to-Sequence Voice Reconstruction for Silent Speech in a Tonal Language. Brain Sci. 2022, 12, 818. [Google Scholar] [CrossRef] [PubMed]
- Meltzner, G.S.; Heaton, J.T.; Deng, Y.; De Luca, G.; Roy, S.H.; Kline, J.C. Silent Speech Recognition as an Alternative Communication Device for Persons with Laryngectomy. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2386–2398. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Zhao, T.; Zhang, Y.; Xie, L.; Yan, Y.; Yin, E. Parallel-inception CNN approach for facial sEMG based silent speech recognition. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Online, 1–5 November 2021; pp. 554–557. [Google Scholar]
- Gaddy, D. Voicing Silent Speech. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2022. [Google Scholar]
- De Luca, C.J. Surface Electromyography: Detection and Recording; Technical Report; DelSys Incorporated: Natick, MA, USA, 2002. [Google Scholar]
- Zhou, Q.; Jiang, N.; Hudgins, B. Improved phoneme-based myoelectric speech recognition. IEEE Trans. Biomed. Eng. 2009, 56, 2016–2023. [Google Scholar] [CrossRef] [PubMed]
- Wand, M.; Schultz, T. Analysis of phone confusion in EMG-based speech recognition. In Proceedings of the ICASSP, Prague, Czech Republic, 22–27 May 2011; pp. 757–760. [Google Scholar]
- Wand, M.; Schultz, T. Session-independent EMG-based Speech Recognition. In Proceedings of the Biosignals, Rome, Italy, 26–29 January 2011; pp. 295–300. [Google Scholar]
- Wand, M.; Schmidhuber, J. Deep Neural Network Frontend for Continuous EMG-Based Speech Recognition. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3032–3036. [Google Scholar]
- Diener, L.; Amiriparian, S.; Botelho, C.; Scheck, K.; Küster, D.; Trancoso, I.; Schuller, B.W.; Schultz, T. Towards Silent Paralinguistics: Deriving Speaking Mode and Speaker ID from Electromyographic Signals. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 3117–3121. [Google Scholar] [CrossRef]
- Khan, M.U.; Choudry, Z.A.; Aziz, S.; Naqvi, S.Z.H.; Aymin, A.; Imtiaz, M.A. Biometric Authentication based on EMG Signals of Speech. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Zahner, M.; Janke, M.; Wand, M.; Schultz, T. Conversion from facial myoelectric signals to speech: A unit selection approach. In Proceedings of the Interspeech 2014, Singapore, 14–18 September 2014; pp. 1184–1188. [Google Scholar]
- Diener, L.; Janke, M.; Schultz, T. Direct conversion from facial myoelectric signals to speech using Deep Neural Networks. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Janke, M.; Diener, L. EMG-to-Speech: Direct Generation of Speech From Facial Electromyographic Signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2375–2385. [Google Scholar] [CrossRef]
- Salomons, I.; del Blanco, E.; Navas, E.; Hernáez, I. Accepted for publication—Spanish Phone Confusion Analysis for EMG-Based Silent Speech Interfaces. In Proceedings of the 24th Annual Conference of the International Speech Communication Association (INTERSPEECH), Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Del Blanco, E.; Salomons, I.; Navas, E.; Hernáez, I. Phone classification using electromyographic signals. In Proceedings of the IberSPEECH 2022, ISCA, Granada, Spain, 14–16 November 2022; pp. 31–35. [Google Scholar] [CrossRef]
- Chan, A.D.C.; Englehart, K.; Hudgins, B.; Lovely, D.F. Myo-Electric Signals to Augment Speech Recognition. Med. Biol. Eng. Comput. 2001, 39, 500–504. [Google Scholar] [CrossRef] [PubMed]
- Maier-Hein, L.; Metze, F.; Schultz, T.; Waibel, A. Session independent non-audible speech recognition using surface electromyography. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Cancun, Mexico, 27 November–1 December 2005; pp. 331–336. [Google Scholar] [CrossRef]
- Schultz, T.; Wand, M. Modeling coarticulation in EMG-based continuous speech recognition. Speech Commun. 2010, 52, 341–353. [Google Scholar] [CrossRef]
- Jou, S.C.; Schultz, T.; Walliczek, M.; Kraft, F.; Waibel, A. Towards continuous speech recognition using surface electromyography. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Zhu, M.; Zhang, H.; Wang, X.; Wang, X.; Yang, Z.; Wang, C.; Samuel, O.W.; Chen, S.; Li, G. Towards Optimizing Electrode Configurations for Silent Speech Recognition Based on High-Density Surface Electromyography. J. Neural Eng. 2021, 18, 016005. [Google Scholar] [CrossRef] [PubMed]
- Aubanel, V.; Lecumberri, M.L.G.; Cooke, M. The Sharvard Corpus: A phonemically-balanced Spanish sentence resource for audiology. Int. J. Audiol. 2014, 53, 633–638. [Google Scholar] [CrossRef] [PubMed]
- Sainz, I.; Erro, D.; Navas, E.; Hernáez, I.; Sanchez, J.; Saratxaga, I.; Odriozola, I. Versatile Speech Databases for High Quality Synthesis for Basque. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- McAuliffe, M.; Socolof, M.; Mihuc, S.; Wagner, M.; Sonderegger, M. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; Volume 2017, pp. 498–502. [Google Scholar]
- Wand, M. Advancing Electromyographic Continuous Speech Recognition: Signal Preprocessing and Modeling; KIT Scientific Publishing: Karlsruhe, Germany, 2015. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Bridle, J. Training stochastic model recognition algorithms as networks can lead to maximum mutual information estimation of parameters. In Proceedings of the 2nd International Conference on Neural Information Processing System, Denver, CO, USA, 27–30 November 1989; Volume 2. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Speaker | Gender | Age | Session | Duration | Train | Test |
|---|---|---|---|---|---|---|
| 001 | M | 29 | 101 | 16:51 | 13:28 | 03:23 |
| 102 | 17:32 | 14:04 | 03:28 | |||
| 103 | 17:00 | 13:48 | 03:12 | |||
| 104 | 19:22 | 15:14 | 04:08 | |||
| 002 | F | 29 | 101 | 25:25 | 20:20 | 05:05 |
| 102 | 30:34 | 24:27 | 06:07 | |||
| 103 | 22:36 | 18:17 | 04:19 | |||
| 104 | 27:06 | 21:18 | 05:48 | |||
| 003 | M | 51 | 101 | 24:38 | 19:50 | 04:48 |
| 102 | 21:43 | 17:27 | 04:16 | |||
| 004 | F | 46 | 101 | 26:04 | 20:46 | 05:18 |
| 102 | 24:09 | 19:17 | 04:52 | |||
| 005 | M | 45 | 101 | 23:39 | 18:56 | 04:43 |
| 102 | 22:31 | 18:00 | 04:31 | |||
| 006 | F | 61 | 101 | 32:57 | 26:21 | 06:36 |
| 102 | 29:01 | 23:21 | 05:40 |
| Session | Corpus |
|---|---|
| all | 110 VCV combinations |
| 100 isolated words | |
| Sharvard sentences 1-100 | |
| 101 | Sharvard sentences 101-400 |
| 102 | Sharvard sentences 401-700 |
| 103 | Ahosyn sentences 1-150 |
| 104 | Ahosyn sentences 151-300 |
| Speaker | Session | Validation Accuracy | Testing Accuracy |
|---|---|---|---|
| 001 | 101 | 50.48 ± 1.01 | 46.42 |
| 102 | 49.12 ± 0.86 | 47.15 | |
| 103 | 45.80 ± 0.66 | 45.53 | |
| 104 | 50.41 ± 1.05 | 50.54 | |
| 002 | 101 | 43.71 ± 0.48 | 42.61 |
| 102 | 42.80 ± 0.96 | 42.52 | |
| 103 | 38.76 ± 1.35 | 38.05 | |
| 104 | 39.39 ± 0.77 | 39.64 | |
| 003 | 101 | 46.73 ± 1.12 | 45.27 |
| 102 | 42.41 ± 1.07 | 39.45 | |
| 004 | 101 | 43.22 ± 1.50 | 38.44 |
| 102 | 41.29 ± 1.37 | 39.62 | |
| 005 | 101 | 43.61 ± 1.56 | 41.19 |
| 102 | 51.45 ± 0.54 | 50.40 | |
| 006 | 101 | 35.92 ± 1.17 | 35.27 |
| 102 | 28.39 ± 1.31 | 24.72 | |
| Average | 43.34 ± 5.80 | 41.68 ± 6.14 |
| Speaker | Training Session(s) | Testing Session | Validation Accuracy | Testing Accuracy |
|---|---|---|---|---|
| 001 | 102 | 101 | 49.12 ± 0.86 | 23.40 |
| 102,103 | 45.08 ± 0.89 | 27.89 | ||
| 102,103,104 | 42.50 ± 0.74 | 30.41 | ||
| 101 | 102 | 50.48 ± 1.01 | 19.57 | |
| 101,103 | 46.85 ± 1.07 | 22.11 | ||
| 101,103,104 | 43.81 ± 0.70 | 24.54 | ||
| 101 | 103 | 50.48 ± 1.01 | 14.19 | |
| 101,102 | 48.16 ± 1.14 | 18.09 | ||
| 101,102,104 | 45.00 ± 0.34 | 18.25 | ||
| 101 | 104 | 50.48 ± 1.01 | 15.86 | |
| 101,102 | 48.16 ± 1.14 | 22.38 | ||
| 101,102,103 | 44.49 ± 0.37 | 24.93 | ||
| 002 | 102 | 101 | 42.80 ± 0.96 | 10.00 |
| 102,103 | 39.69 ± 0.53 | 18.32 | ||
| 102,103,104 | 37.90 ± 0.61 | 21.93 | ||
| 101 | 102 | 43.71 ± 0.48 | 20.90 | |
| 101,103 | 41.23 ± 1.09 | 23.81 | ||
| 101,103,104 | 37.79 ± 0.80 | 24.19 | ||
| 101 | 103 | 43.71 ± 0.48 | 17.79 | |
| 101,102 | 42.46 ± 1.02 | 18.03 | ||
| 101,102,104 | 39.63 ± 0.53 | 16.73 | ||
| 101 | 104 | 43.71 ± 0.48 | 19.01 | |
| 101,102 | 42.46 ± 1.02 | 20.84 | ||
| 101,102,103 | 39.42 ± 0.51 | 22.92 | ||
| 003 | 102 | 101 | 42.41 ± 1.07 | 20.66 |
| 101 | 102 | 46.73 ± 1.12 | 15.05 | |
| 004 | 102 | 101 | 41.29 ± 1.37 | 10.95 |
| 101 | 102 | 43.22 ± 1.50 | 8.63 | |
| 005 | 102 | 101 | 51.45 ± 0.54 | 11.83 |
| 101 | 102 | 43.61 ± 1.56 | 23.61 | |
| 006 | 102 | 101 | 28.39 ± 1.31 | 16.02 |
| 101 | 102 | 35.92 ± 1.17 | 8.30 |
| Training Speaker | Training Sessions | Testing Session | Testing Speaker | Testing Accuracy |
|---|---|---|---|---|
| 001 | 102,103,104 | 101 | 002 | 19.47 |
| 003 | 14.47 | |||
| 004 | 12.08 | |||
| 005 | 9.33 | |||
| 006 | 8.41 | |||
| 101,103,104 | 102 | 002 | 18.28 | |
| 003 | 15.10 | |||
| 004 | 6.91 | |||
| 005 | 19.90 | |||
| 006 | 8.51 | |||
| 101,102,104 | 103 | 002 | 8.36 | |
| 101,102,103 | 104 | 002 | 10.47 | |
| 002 | 102,103,104 | 101 | 001 | 14.07 |
| 003 | 15.71 | |||
| 004 | 14.78 | |||
| 005 | 8.11 | |||
| 006 | 10.53 | |||
| 101,103,104 | 102 | 001 | 15.95 | |
| 003 | 18.09 | |||
| 004 | 10.26 | |||
| 005 | 16.90 | |||
| 006 | 7.21 | |||
| 101,102,104 | 103 | 001 | 16.79 | |
| 101,102,103 | 104 | 001 | 20.43 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salomons, I.; del Blanco, E.; Navas, E.; Hernáez, I.; de Zuazo, X. Frame-Based Phone Classification Using EMG Signals. Appl. Sci. 2023, 13, 7746. https://doi.org/10.3390/app13137746
Salomons I, del Blanco E, Navas E, Hernáez I, de Zuazo X. Frame-Based Phone Classification Using EMG Signals. Applied Sciences. 2023; 13(13):7746. https://doi.org/10.3390/app13137746
Chicago/Turabian StyleSalomons, Inge, Eder del Blanco, Eva Navas, Inma Hernáez, and Xabier de Zuazo. 2023. "Frame-Based Phone Classification Using EMG Signals" Applied Sciences 13, no. 13: 7746. https://doi.org/10.3390/app13137746
APA StyleSalomons, I., del Blanco, E., Navas, E., Hernáez, I., & de Zuazo, X. (2023). Frame-Based Phone Classification Using EMG Signals. Applied Sciences, 13(13), 7746. https://doi.org/10.3390/app13137746