Firstly, LogBD and log anomaly detection methods PCA, LogCluster, DeepLog, LogAnomaly, LogBERT, and LogTransfer were tested on two datasets and the results were analyzed. The influence of different log vector representation methods on anomaly detection performance was then analyzed, along with the influence of domain adaptation.
4.2. Results and Analysis
Since PCA, LogCluster, DeepLog, LogAnomaly, and LogBERT are unsupervised models and are not designed for cross-system detection, these models were evaluated in two cases; that is, the training dataset used or did not use the samples of the target system, represented by W/O. Firstly, the Thunderbird dataset was used as the source system, and the BGL dataset was used as the target system. This situation is abbreviated as TB-BGL. The F1 value of 0.880 and the AUC value of 0.880 were obtained on the source system Thunderbird, and the F1 value of 0.938 and the AUC value of 0.973 were obtained on the target system BGL. Then, the BGL dataset was used as the source system and the Thunderbird dataset was used as the target system. This case is abbreviated as BGL-TB. The F1 value of 0.933 and the AUC value of 0.978 were obtained on the source system BGL, and the F1 value of 0.841 and the AUC value of 0.854 were obtained on the target system Thunderbird.
Table 3 and
Table 4 show the experimental results of the six methods except LogTransfer in the case of TB-BGL and BGL-TB. W/O represents the training set using or not using the target system. Firstly, PCA, LogCluster, DeepLog, LogAnomaly, and LogBERT do not use domain adaptation. For Thunderbird as the source system and BGL as the target system (TB→BGL) or BGL as the source system and Thunderbird as the target system (BGL→TB), these five methods could produce good
F1 values and AUC values on the source system even if they did not use the sample training of the target system. When the training dataset used samples from the target system, they could obtain better
F1 and AUC values on the target system, but worse values on the source system, indicating that these five methods do not have cross-system adaptive ability. Using a mixed log sequence of the source system and the target system would only make the training data distribution diverse, whereby the detection model would confuse the distribution of the samples, resulting in poor model detection. Compared with these five methods, LogBD achieved better results in any scenario.
On the source system, the detection performance of LogBD was still better than the five models, which indicates that LogBD captured the pain points of log anomaly detection, i.e., the accuracy of log template analysis, the use of log semantic information, and the method of anomaly detection. It can also be seen that the performance of deep learning methods was better than that of machine learning methods, indicating that the machine learning model only used the log template count vector as the input feature, without considering the log content itself. Machine learning can detect the abnormal information in the log to a certain extent, but it cannot achieve good accuracy and coverage of anomaly detection. For example, PCA is based on the log template index for anomaly detection, only retains the main features of the original data, and loses a lot of key information, making it difficult to learn features from the sparse count matrix. LogCluster is based on clustering for log anomaly detection, but it cannot play a good role in the face of complex log structure, nor can it fully learn the features in the log, and the detection effect is not good. DeepLog regards the log sequence as a digital sequence and replaces the log template with a number. It not only uses the log parameter features but also integrates the log sequence features. However, it does not extract the semantic information in the log template, and it can easily treat the log sequence that has not appeared in the training data as an exception, resulting in lower accuracy and more false alarms. Compared with the machine learning methods PCA and LogCluster, it has a more obvious improvement. The LogAnomaly method uses the semantic and grammatical information of the log template, and then introduces Template2Vec for the synonyms in the log. It uses the word vector weighted average to obtain the vector representation, which makes some improvements on the basis of DeepLog. However, it does not consider the problem of polysemous words, only considers the representation of a single word vector, and does not consider the context information; additionally, the learned feature information is not comprehensive enough. LogBERT uses BERT to capture the pattern of normal log sequence, and uses two self-supervised task training models, mask log template prediction and hypersphere minimization. LogBERT uses the hypersphere objective function as in LogBD, but the performance is not as good as LogBD, because LogBD uses domain adaptation to obtain more data with the same characteristics for training.
LogTransfer is a supervised transfer learning method that uses normal and abnormal labeled data of the source system and the target system to train a cross-system anomaly detection model. LogTransfer achieves good performance when sufficient tag data are available. In this experiment, we tested how many labeled abnormal samples are needed to train LogTransfer for it to have similar performance to LogBD. When using 100 abnormal sequences from the source system and 10 abnormal sequences from the target system to train LogTransfer, LogTransfer could achieve the best performance on the source system. The detection results in the two scenarios are shown in
Table 5 and
Table 6.
For the TB→BGL scenario, training LogTransfer with 10 abnormal sequences of the target system was not enough to be better than LogBD. It was better than LogBD on the source system, but worse on the target system. For the BGL-TB scenario, the performance was comparable on the source system and lower than LogBD on the target system. Therefore, LogBD can provide good performance using only normal data when it is difficult to obtain labeled abnormal samples.
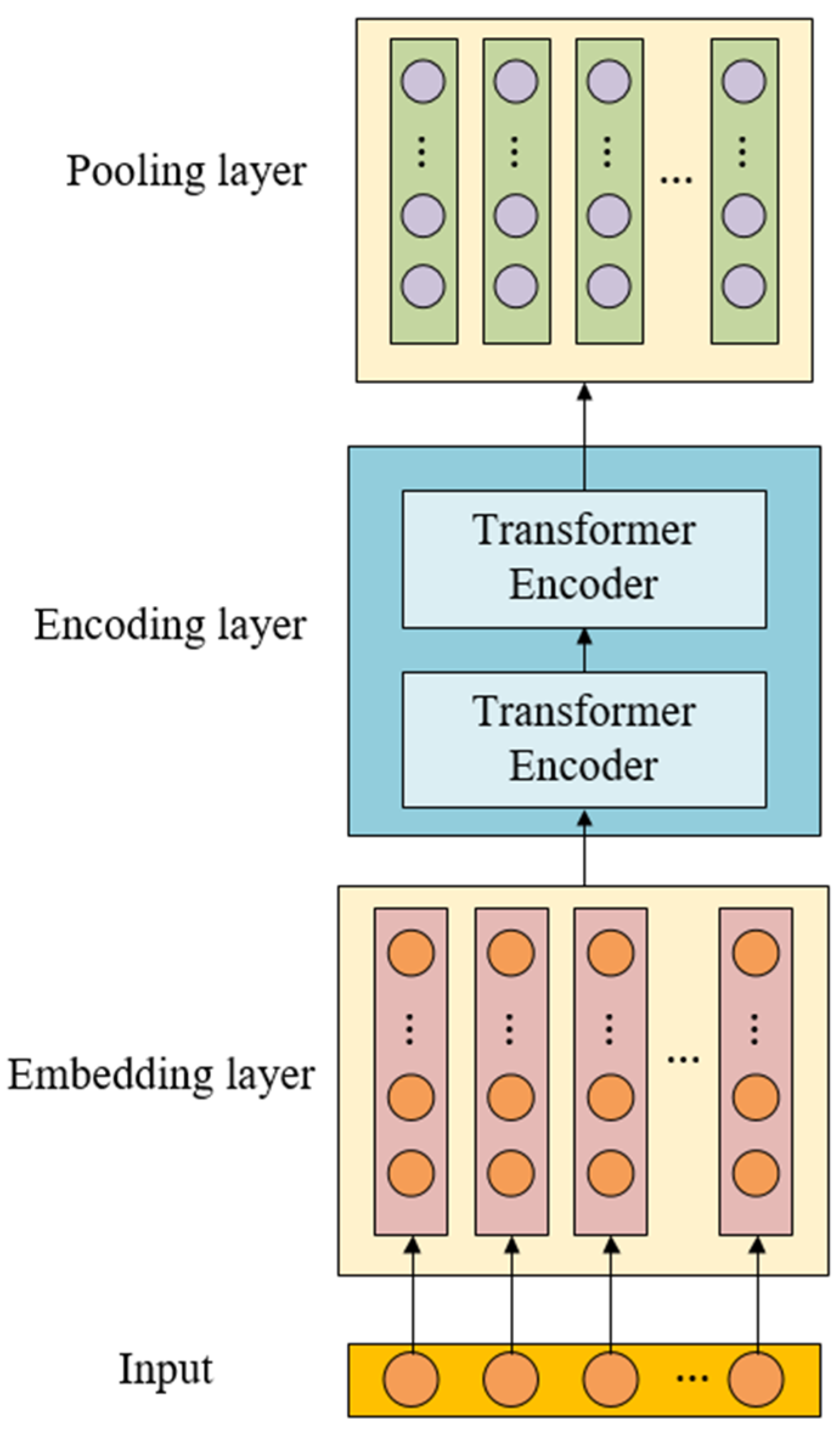
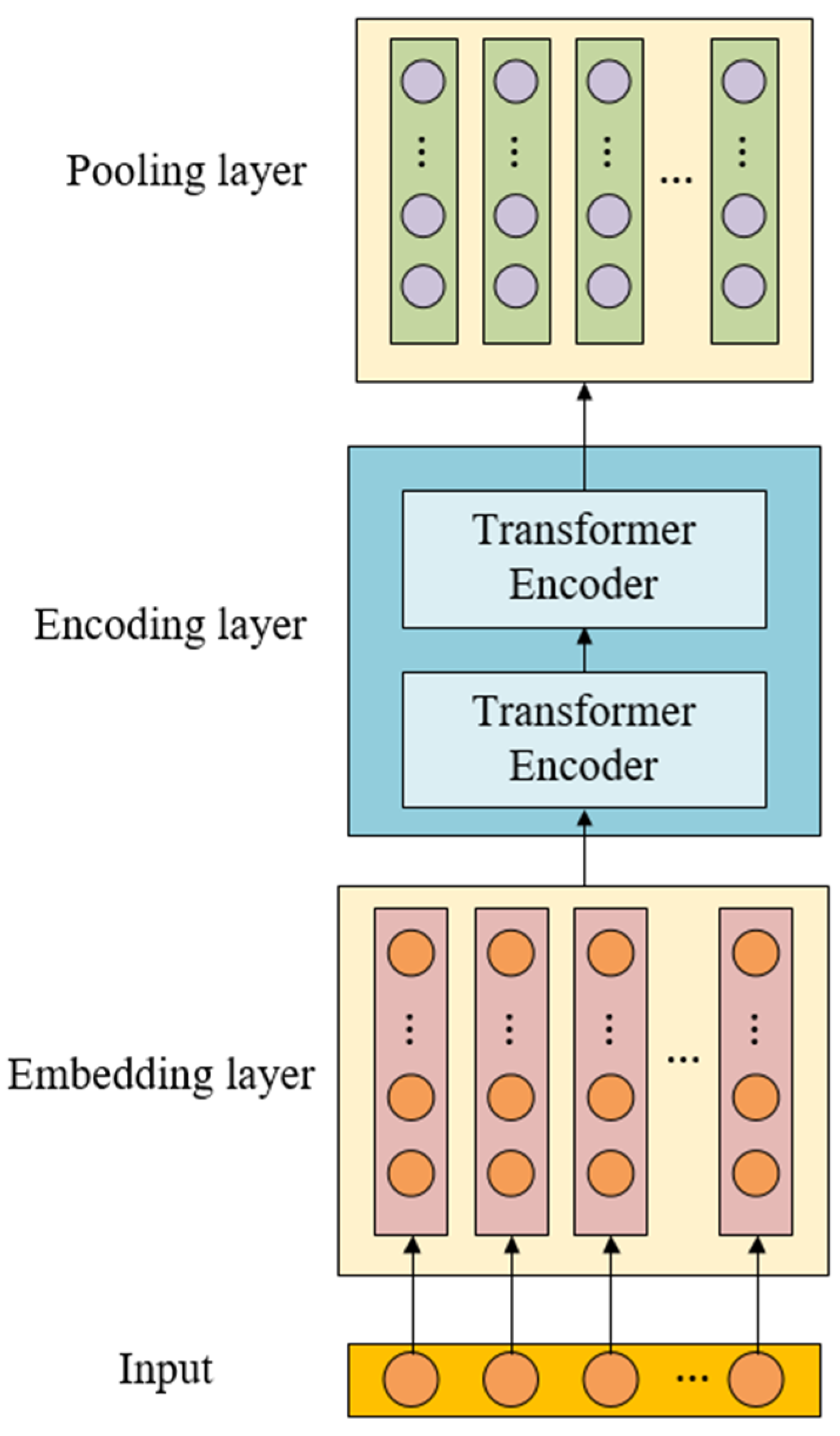
Unlike previous methods, LogBD uses BERT to extract the semantic information of log messages, and uses semantic vectors to represent log templates, rather than the log templates Word2Vec and Glove used in previous methods. This paper compared the model performance using four log template representation methods. The detection results generated by different log template representation methods in two scenarios are shown in
Table 7 and
Table 8. We found that the performance was greatly improved when BERT was used for log template representation. This may be because the method based on the log template ID is to number the log template and represent it by number. This method regards the log template as a number; it does not consider the semantic information contained in the log template. Word2Vec and Glove word vectors are fixed by looking up the dictionary and taking the corresponding word vectors. They cannot dynamically adjust the word vectors according to different context contexts, losing the integrity of the log template semantics. According to the context of the input sentence, BERT returns sentence-level word vectors through model calculation in the model network. Due to the different context of the input context, the returned word vectors are different in order to distinguish polysemous words. Compared with the first three, BERT can learn the deep semantics of sentences and capture the similarity between different log statements.
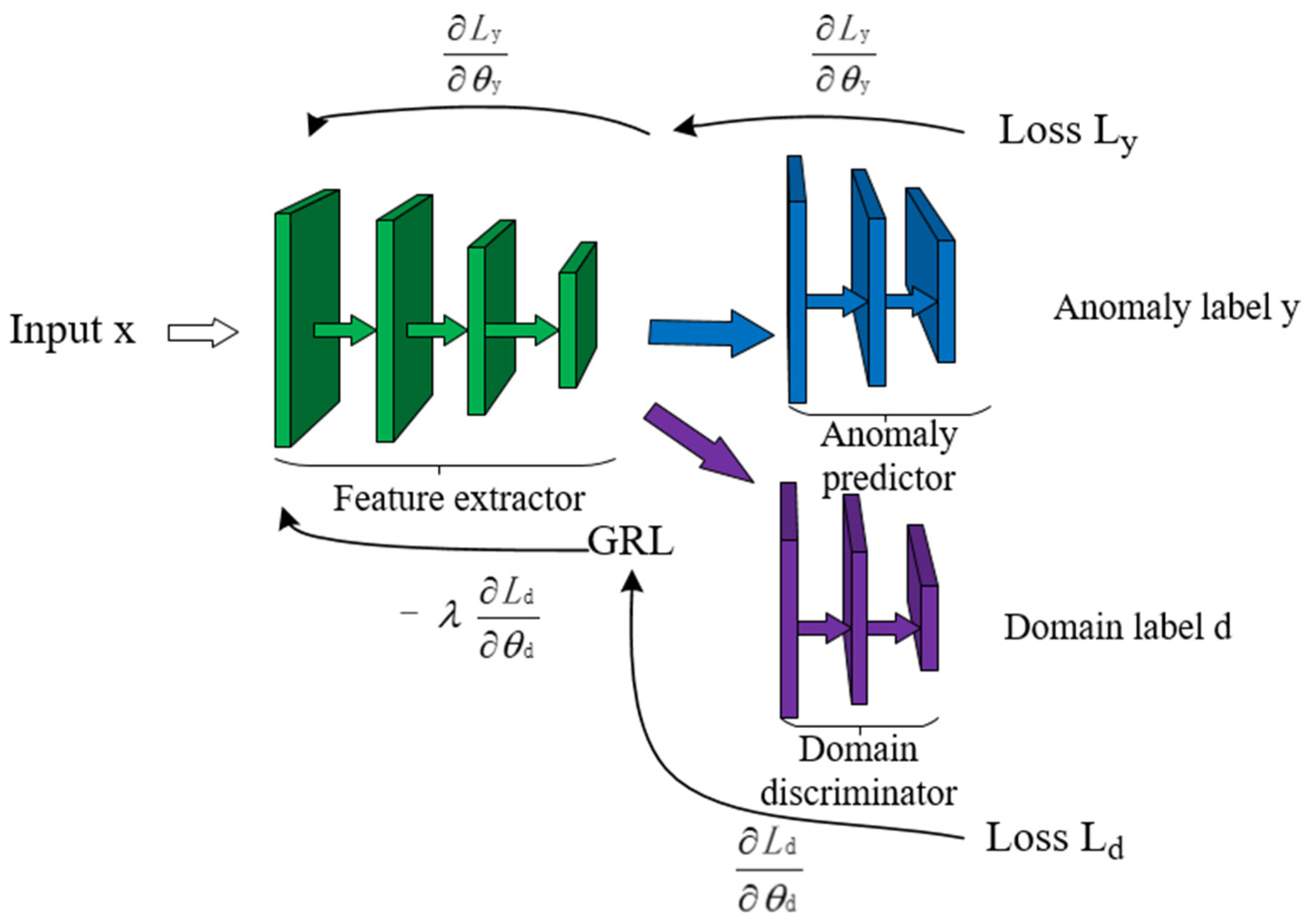
The cross-system log anomaly detection model LogBD proposed in this paper uses the domain adaptation method in transfer learning and achieves excellent performance. In order to prove the effectiveness of the domain adaptation method, a set of comparative experiments was carried out to compare the performance of the model without using the domain adaptation method and using the domain adaptation method. The impact of domain adaptation methods on model performance was evaluated.
The detection results using or not using the domain adaptation method in the two scenarios are shown in
Table 9 and
Table 10. “Without” indicates that the domain adaptation method was not used, while “with” indicates that the domain adaptation method was used. Through observation, it can be seen that the domain adaptive method could greatly improve the performance of the anomaly detection model, because the anomaly detection model could learn the similarities between the two system log data, thereby detecting the anomalies of the two systems.
This experiment also further evaluated the performance of LogBD when training with different numbers of target system normal log sequences. The experimental results are shown in
Figure 9.
It can be observed that LogBD could achieve high anomaly detection performance for the target system by using a small number of normal sequences in the target system. In the TB→BGL scenario, using about 100 normal log sequences in BGL could achieve good performance. For the BGL→TB scenario, only using 10 normal log sequences in Thunderbird was enough to obtain good performance. When the number of log sequences increased, the performance continued to improve. In general, even if the new online system deployment time is short, it is easy to obtain normal log data from the target system; thus, LogBD has strong feasibility and accuracy in detecting anomalies in the new system.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}