
SFBKT: A Synthetically Forgetting Behavior Method for Knowledge Tracing


Abstract
:1. Introduction
- Our study proposes the Synthetically Forgetting Behavior Knowledge Tracing model, which aims to comprehensively model students’ knowledge levels by incorporating pre-training forgetting information, post-training forgetting behavior, and a group forgetting state. This approach allows for a better prediction of students’ performance in the next stage.
- The Neural Hawkes Process is a seminal article in the field of time series point processes. In this study, we enhance it and transfer the improved model to the field of knowledge tracing as part of SFBKT. This enables us to fully consider the forgetting information implicit in students’ training records, even during irregular continuous time periods. By using the self-exciting multivariate point process, the knowledge levels of students obtained by the neural network dynamically change over time, better aligning with the law of human forgetting.
- Our approach employs the expressive power of neural networks to model individual training records while utilizing traditional collaborative filtering to account for similarities in knowledge levels among groups of students. This approach enables us to combine individual student status with group status and avoid ignoring students’ social attributes.
- We tested our model on four widely used public education datasets, and the results indicate that it outperformed the standard methods used for comparison in all four datasets.
2. Related Work and Motivation
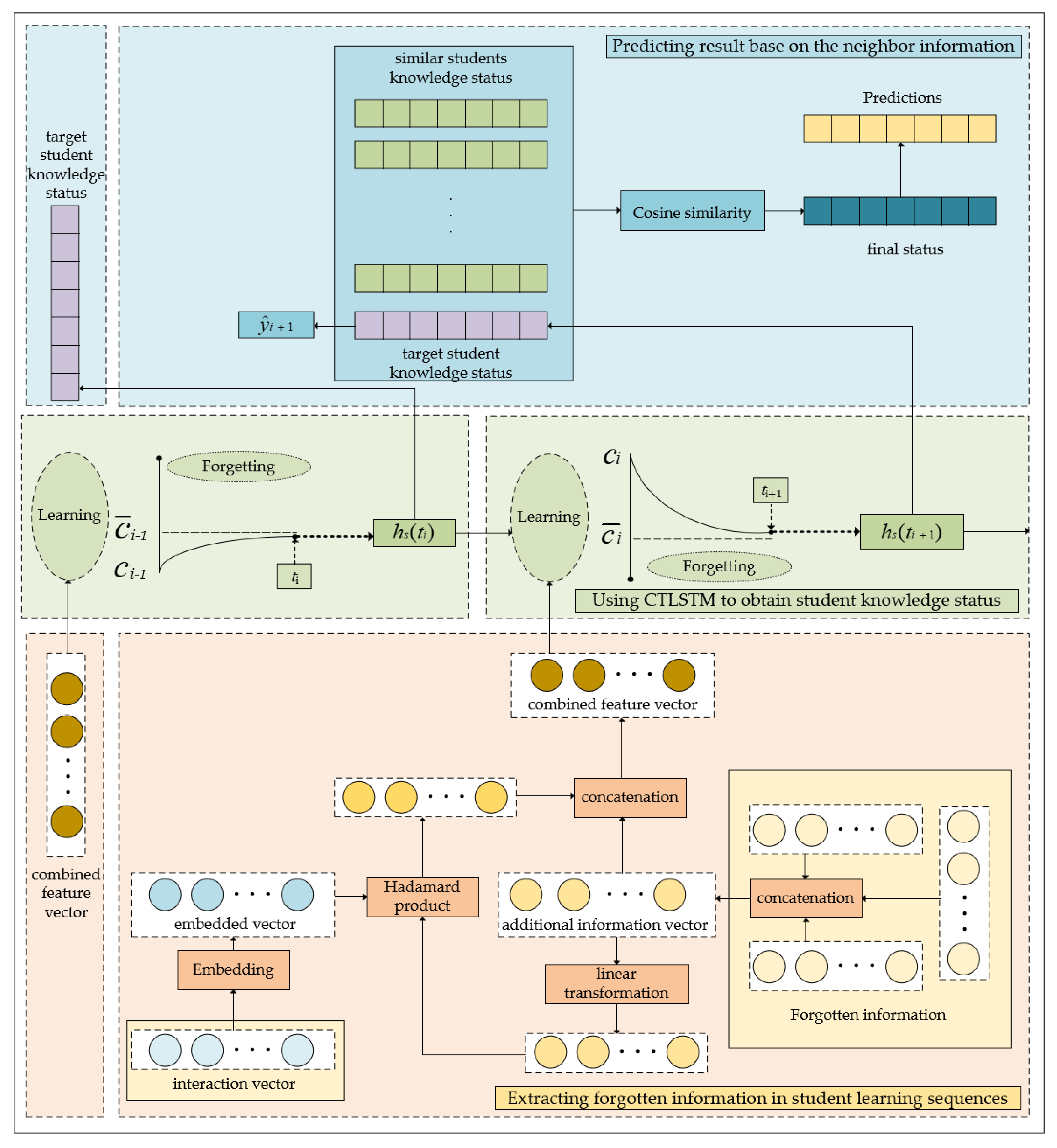
3. Proposed Method
3.1. Problem Definition
3.2. Model Architecture
3.2.1. Extracting Forgotten Information in Student Learning Sequences
- Extracting information related to memory retention from learning sequences. Previous studies have confirmed the existence of temporal cross-effects, which means that each previous interaction has a time-sensitive effect on mastery of the target skill. In our approach, we extract three pieces of information from a student’s learning sequence: the time interval of the same skill, the time interval of the previous skill, and the number of attempts at the same skill in the past.
- Incorporate information into the input space of the model. To model the knowledge acquisition process of students, we utilize a trainable embedding matrix A to calculate the embedding vector of the interaction vector at time , instead of assigning arbitrary values. The above process can be summarized as follows:
3.2.2. Using CTLSTM to Obtain Student Knowledge Status
3.2.3. Predicting Results Based on Neighbor Information
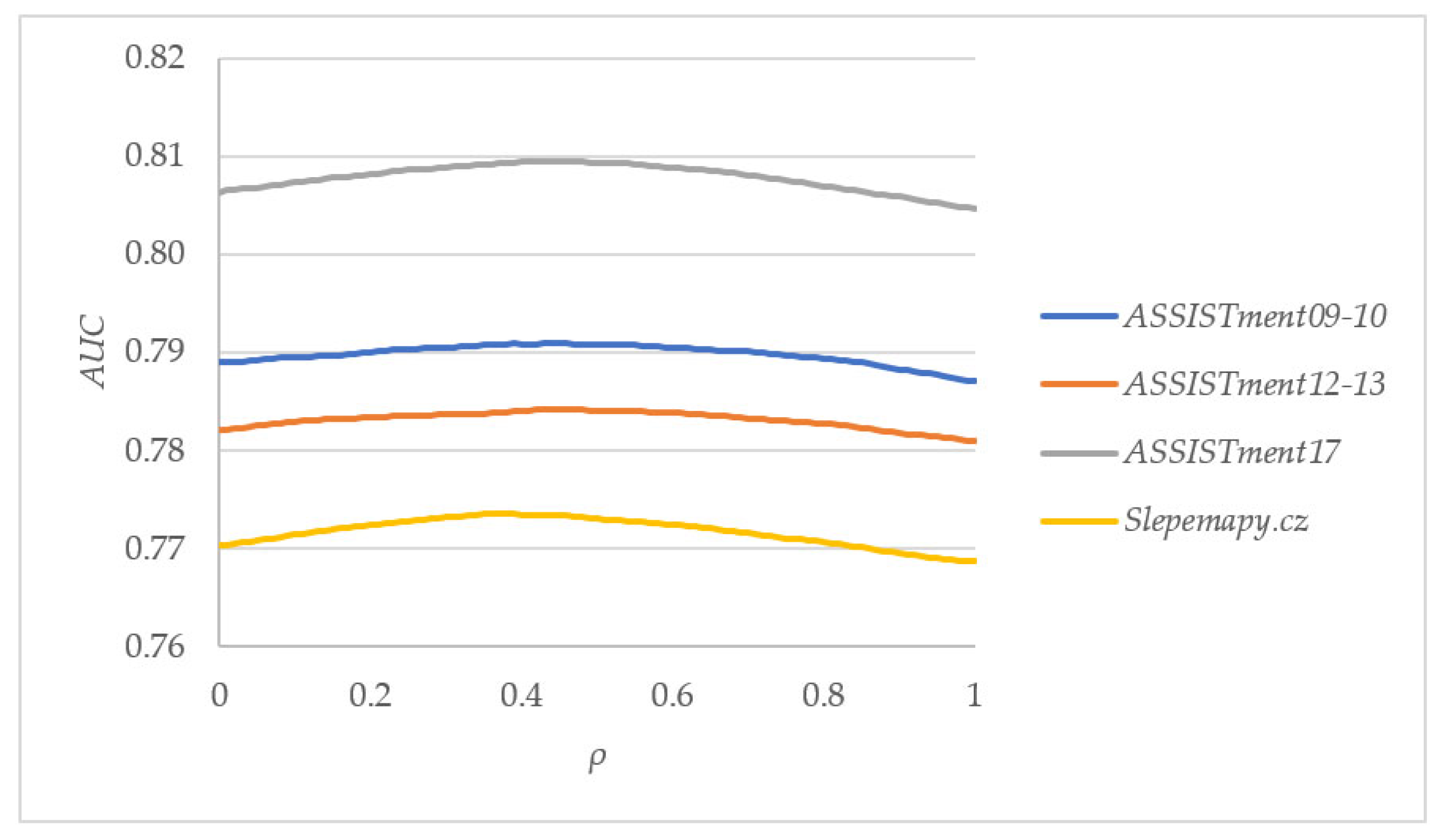
3.3. Optimization
4. Experiments
4.1. Experimental Datasets
4.2. Experimental Environment
4.3. Results and Discussion
- DKT. It was the first to employ deep learning methods to trace knowledge progression. By utilizing the long short-term memory model, it has the capability to monitor changes in students’ proficiency levels over an extended period. This is a conventional technique that has been refined by numerous models in recent years.
- DKT + Forgetting. Although several models have explored the concept of forgetting behaviors in knowledge tracing, DKT-Forgetting stands out as the pioneer in integrating forgetting-related information into deep learning.
- KTM. It employs Factorization Machines to model the interplay between features. The characteristics taken into account in this approach comprise question ID, skill ID, previous responses to diverse skills, and temporal features within DKT + Forgetting.
- HawkesKT. It represents a pioneering category of knowledge-tracing methodologies that resulted from the integration of temporal point processes and knowledge-tracing studies. This approach builds upon the observed temporal crossover effects in the data, where each historical interaction has a continuously changing effect on the target skill, offering fresh perspectives on the incorporation of forgetting behavior.
- AKT. It employs a novel attention mechanism that links a student’s forthcoming responses with their previous responses. This attention mechanism calculates attention weights through exponential decay and a context-sensitive relative distance metric, as well as the resemblance between the questions.
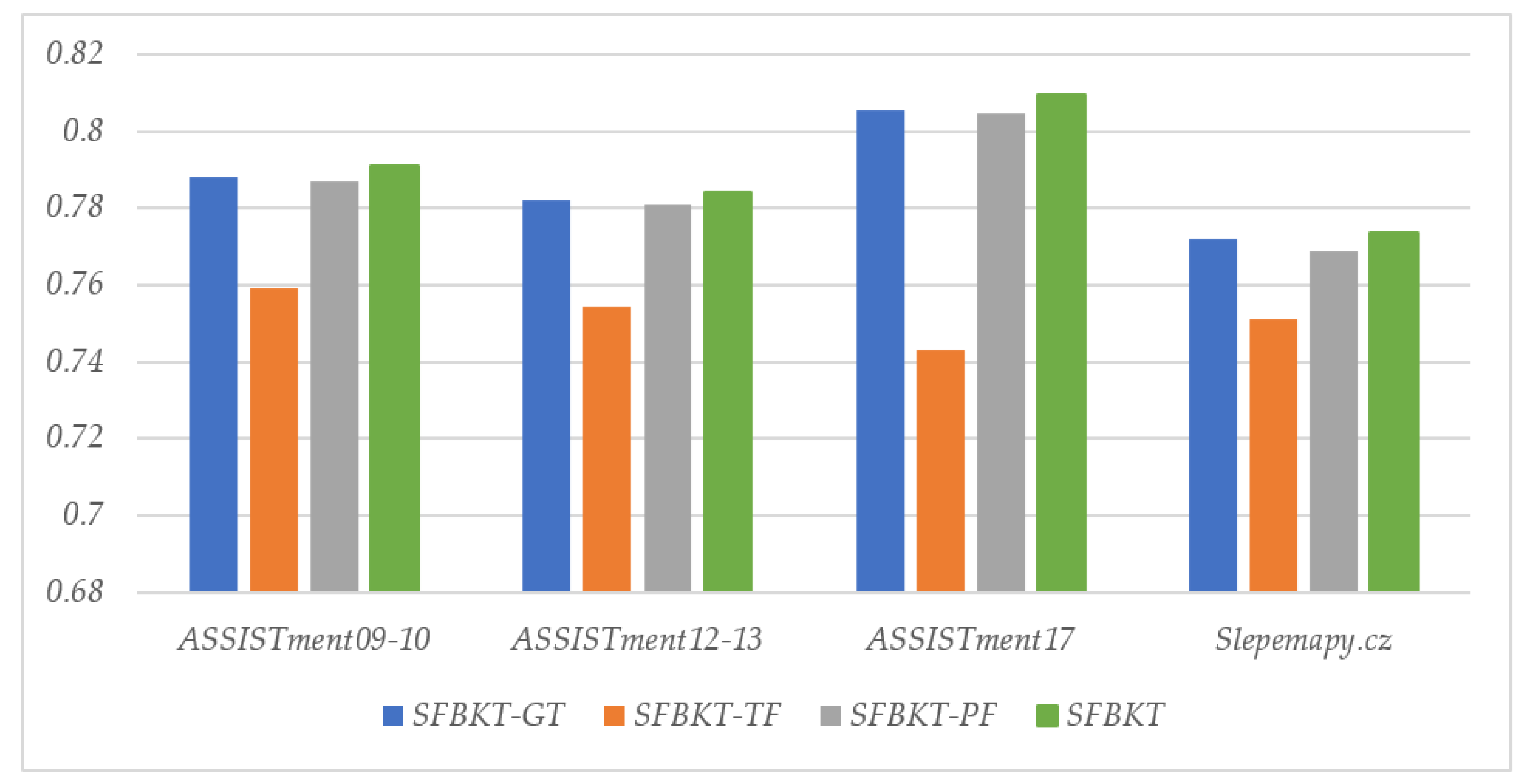
- SFBKT-GF. The SFBKT-Group Forgetting variant model is used to study the influence of personal forgetting information processing in the SFBKT model on prediction. In the input module of SFBKT-GF, the part of extracting students’ past forgetting records is removed. Thus, the variant model maintains the network module and output module of the SFBKT model, while reducing the input data of the CTLSTM network to a series of student exercises. SFBKT-GF can effectively reflect the degree of influence of students’ personal forgotten information on predictions.
- SFBKT-TF. To study the importance of the continuous-time long short-term memory network in the SFBKT model for prediction performance, the SFBKT-TF variant model removes it and compares it with the original model. At this time, the second part of the model becomes the traditional LSTM network, which is called the SFBKT-Traditional Forgetting variant model.
- SFBKT-PF. To investigate how group forgetting impacts the predictive accuracy of the SFBKT model, the SFBKT-Personal Forgetting variant model removes the part of collaborative filtering by considering the state of group knowledge from the SFBKT model. Specifically, the SFBKT-PF model first integrates the students’ forgetting information and the record of doing questions as input. Then, through the CTLSTM network, the time feature is extracted to obtain the student’s knowledge status and predict the result based on this output.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yassine, S.; Kadry, S.; Sicilia, M.A. Measuring learning outcomes effectively in smart learning environments. In Proceedings of the 2016 Smart Solutions for Future Cities, Kuwait City, Kuwait, 7–9 February 2016; pp. 1–5. [Google Scholar]
- Abdelrahman, G.; Wang, Q.; Nunes, B. Knowledge tracing: A survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Zhu, T.Y.; Huang, Z.; Chen, E.; Liu, Q.; Wu, R.; Wu, L.; Hu, G. Cognitive diagnosis based personalized question recommendation. Chin. J. Comput. 2017, 40, 176–191. [Google Scholar]
- Corbett, A.T.; Anderson, J.R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model. User-Adapt. Interact. 1994, 4, 253–278. [Google Scholar] [CrossRef]
- David, Y.B.; Segal, A.; Gal, Y. Sequencing educational content in classrooms using Bayesian knowledge tracing. In Proceedings of the Sixth International Conference on Learning Analytics & Knowledge, Edinburgh, UK, 25–29 April 2016; pp. 354–363. [Google Scholar]
- Adamopoulos, P. What makes a great MOOC? An interdisciplinary analysis of student retention in online courses. In Proceedings of the Thirty Fourth International Conference on Information Systems, Milan, Italy, 15–18 December 2013. [Google Scholar]
- Anderson, J.R.; Boyle, C.F.; Corbett, A.T.L.; Matthew, W. Cognitive Modelling and Intelligent Tutoring; ERIC: Washington, DC, USA, 1986. [Google Scholar]
- Baker, R.S.J.D.; Corbett, A.T.; Aleven, V. More Accurate Student Modeling through Contextual Estimation of Slip and Guess Probabilities in Bayesian Knowledge Tracing. In Intelligent Tutoring Systems: 9th International Conference, ITS 2008, Montreal, Canada, 23–27 June 2008 Proceedings 9; Springer: Berlin/Heidelberg, Germany, 2008; pp. 406–415. Available online: https://link.springer.com/chapter/10.1007/978-3-540-69132-7_44 (accessed on 3 May 2022).
- Villano, M. Probabilistic student models: Bayesian belief networks and knowledge space theory. In Intelligent Tutoring Systems: Second International Conference, ITS’92 Montréal, Canada, 10–12 June 1992 Proceedings 2; Springer: Berlin/Heidelberg, Germany, 1992; pp. 491–498. [Google Scholar]
- Cen, H.; Koedinger, K.; Junker, B. Learning factors analysis—A general method for cognitive model evaluation and improvement. In Intelligent Tutoring Systems: 8th International Conference, ITS 2006, Jhongli, Taiwan, 26–30 June 2006. Proceedings 8; Springer: Berlin/Heidelberg, Germany, 2006; pp. 164–175. [Google Scholar]
- Cen, H.; Koedinger, K.; Junker, B. Comparing two IRT models for conjunctive skills. In Intelligent Tutoring Systems: 9th International Conference, ITS 2008, Montreal, Canada, 23–27 June 2008 Proceedings 9; Springer: Berlin/Heidelberg, Germany, 2008; pp. 796–798. [Google Scholar]
- Pavlik, P.I., Jr.; Cen, H.; Koedinger, K.R. Performance Factors Analysis—A New Alternative to Knowledge Tracing. In Proceedings of the 14th International Conference on Artificial Intelligence in Educatio, Brighton, UK, 6–10 July 2009. [Google Scholar]
- Murray, R.C.; Ritter, S.; Nixon, T.; Schwiebert, R.; Hausmann, R.G.; Towle, B.; Fancsali, S.E.; Vuong, A. Revealing the learning in learning curves. In Artificial Intelligence in Education: 16th International Conference, AIED 2013, Memphis, TN, USA, 9–13 July 2013. Proceedings 16; Springer: Berlin/Heidelberg, Germany, 2013; pp. 473–482. [Google Scholar]
- Pavlik, P.I., Jr.; Anderson, J.R. Practice and forgetting effects on vocabulary memory: An activation-based model of the spacing effect. Cogn. Sci. 2005, 29, 559–586. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Nakagawa, H.; Iwasawa, Y.; Matsuo, Y. Graph-based knowledge tracing: Modeling student proficiency using graph neural network. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, New York, NY, USA, 14–17 October 2019; pp. 156–163. [Google Scholar]
- Pandey, S.; Karypis, G. A self-attentive model for knowledge tracing. arXiv 2019, arXiv:1907.06837. [Google Scholar]
- Shen, S.; Liu, Q.; Chen, E.; Wu, H.; Huang, Z.; Zhao, W.; Su, Y.; Ma, H.; Wang, S. Convolutional knowledge tracing: Modeling individualization in student learning process. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 1857–1860. [Google Scholar]
- Markovitch, S.; Scott, P.D. The role of forgetting in learning. In Machine Learning Proceedings 1988; Morgan Kaufmann: Burlington, MA, USA, 1988; pp. 459–465. [Google Scholar]
- Chen, Y.; Liu, Q.; Huang, Z.; Wu, L.; Chen, E.; Wu, R.; Su, Y.; Hu, G. Tracking knowledge proficiency of students with educational priors. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 989–998. [Google Scholar]
- Nagatani, K.; Zhang, Q.; Sato, M.; Chen, Y.Y.; Chen, F.; Ohkuma, T. Augmenting knowledge tracing by considering forgetting behavior. In Proceedings of the WWW 19: The Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3101–3107. [Google Scholar]
- Wang, C.; Ma, W.; Zhang, M.; Lv, C.; Wan, F.; Lin, H.; Tang, T.; Liu, Y.; Ma, S. Temporal cross-effects in knowledge tracing. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Virtual Event, 8–12 March 2021; pp. 517–525. [Google Scholar]
- Ghosh, A.; Heffernan, N.; Lan, A.S. Context-aware attentive knowledge tracing. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 2330–2339. [Google Scholar]
- Mei, H.; Eisner, J.M. The neural hawkes process: A neurally self-modulating multivariate point process. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Embretson, S.E.; Reise, S.P. Item Response Theory; Psychology Press: London, UK, 2013. [Google Scholar]
- Xiong, X.; Zhao, S.; Van Inwegen, E.G.; Beck, J.E. Going deeper with deep knowledge tracing. In Proceedings of the International Educational Data Mining Society, Raleigh, NC, USA, 29 June–2 July 2016. [Google Scholar]
- Yeung, C.K.; Yeung, D.Y. Addressing two problems in deep knowledge tracing via prediction-consistent regularization. In Proceedings of the Fifth Annual ACM Conference on Learning at Scale, London, UK, 26–28 June 2018; pp. 1–10. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-value memory networks for directly reading documents. arXiv 2016, arXiv:1606.03126. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Choi, Y.; Lee, Y.; Cho, J.; Baek, J.; Kim, B.; Cha, Y.; Shin, D.; Bae, C.; Heo, J. Towards an appropriate query, key, and value computation for knowledge tracing. In Proceedings of the Seventh ACM Conference on Learning@ Scale, Virtual Event, 12–14 August 2020; pp. 341–344. [Google Scholar]
- Shin, D.; Shim, Y.; Yu, H.; Lee, S.; Kim, B.; Choi, Y. Saint+: Integrating temporal features for ednet correctness prediction. In Proceedings of the LAK21: 11th International Learning Analytics and Knowledge Conference, Irvine, CA, USA, 12–16 April 2021; pp. 490–496. [Google Scholar]
- Murre, J.M.J.; Dros, J. Replication and analysis of Ebbinghaus’ forgetting curve. PLoS ONE 2015, 10, e0120644. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Zhang, L.; Xiong, X.; Zhao, S.; Botelho, A.; Heffernan, N.T. Incorporating rich features into deep knowledge tracing. In Proceedings of the Fourth (2017) ACM Conference on Learning@Scale, Cambridge, MA, USA, 20–21 April 2017; pp. 169–172. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Method | Deep Learning |
|---|---|---|
| BKT | Bayesian Knowledge Tracing | × |
| IRT | Factor Analysis Models | × |
| AFM | ||
| PFA | ||
| KTM | ||
| DKT | Sequence Modeling KT Models | √ |
| EERNN | Text-Aware KT Models | √ |
| EKT | ||
| SAKT | Attentive KT Models | √ |
| AKT | ||
| SSAKT | ||
| RKT | ||
| GKT | Graph-Based KT Models | √ |
| GIKT | ||
| SKT | ||
| DKT + Forgetting | Forgetting-Aware KT Models | √ |
| KPT | ||
| HawkesKT | ||
| DGMN | ||
| DKVMN | Memory-Augmented KT Models | √ |
| SKVMN |
| KT Model | Year | Learning Model | Knowledge State | Forgetting |
|---|---|---|---|---|
| IRT | 1993 | LR | Real-valued vector | × |
| BKT | 1994 | HMM | Binary scalar | × |
| AFM | 2008 | LR | Real-valued vector | × |
| DKT | 2015 | RNN/LSTM | Vector | × |
| DKVMN | 2017 | MVNN | matrix | × |
| KTM | 2019 | FM | Real-valued vector | × |
| DKT + Forgetting | 2019 | RNN/LSTM | Vector | √ |
| GKT | 2019 | GNN | Vector | × |
| AKT | 2020 | FFN + MSA | Vector | √ |
| HawkesKT | 2021 | FM | Real-valued vector | √ |
| Dataset | Students | Skills | Records |
|---|---|---|---|
| ASSISTment09-10 | 3700 | 111 | 110,200 |
| ASSISTment12-13 | 25,300 | 245 | 879,500 |
| ASSISTment17 | 1700 | 102 | 9,786,500 |
| Slepemapy.cz | 81,700 | 1473 | 2,877,500 |
| Configuration Environment | Configuration Parameters |
|---|---|
| Operating System | Windows 10 64-bit |
| GPU | RTX 3070 |
| CPU | R7 5800H |
| Memory | 16 GB |
| Programming language | Python3.6 |
| Deep learning framework | Pytorch 1.7.1 |
| Python library | Scikit-learn, Numpy, Pandas |
| Hyperparameters | Value |
|---|---|
| Learning rate | 0.001 |
| Batch size | 1 |
| Hidden size | 64 |
| Embed size | 64 |
| Epochs | 100 |
| Early stop | 5 |
| K-Fold | 5 |
| Method | ASSISTment 09-10 | ASSISTment 12-13 | ASSISTment17 | Slepemapy.cz |
|---|---|---|---|---|
| Metrics | ACC AUC | ACC AUC | ACC AUC | ACC AUC |
| DKT | 0.7396 0.7508 | 0.7275 0.7314 | 0.6981 0.7273 | 0.7971 0.7421 |
| DKT + Forgetting | 0.7402 0.7537 | 0.7388 0.7457 | 0.6993 0.7302 | 0.8009 0.7498 |
| KTM | 0.7327 0.7415 | 0.7439 0.7532 | 0.6935 0.7237 | 0.7967 0.7415 |
| HawkesKT | 0.7472 0.7623 | 0.7513 0.7663 | 0.7063 0.7487 | 0.8028 0.7523 |
| AKT-R | 0.7375 0.7462 | 0.7452 0.7552 | 0.7174 0.7583 | 0.7986 0.7462 |
| SFBKT | 0.7593 0.7909 | 0.7544 0.7842 | 0.7404 0.8095 | 0.8087 0.7736 |
| Method | ASSISTment 09-10 | ASSISTment 12-13 | ASSISTment17 | Slepemapy.cz |
|---|---|---|---|---|
| Metrics | ACC AUC | ACC AUC | ACC AUC | ACC AUC |
| SFBKT-GF | 0.7581 0.7883 | 0.7535 0.7822 | 0.7361 0.8057 | 0.8064 0.7721 |
| SFBKT-TF | 0.7423 0.7592 | 0.7448 0.7544 | 0.7036 0.7431 | 0.8001 0.7512 |
| SFBKT-PF | 0.7566 0.7870 | 0.7518 0.7810 | 0.7345 0.8046 | 0.8026 0.7688 |
| SFBKT | 0.7593 0.7909 | 0.7544 0.7842 | 0.7404 0.8095 | 0.8087 0.7736 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Q.; Luo, W. SFBKT: A Synthetically Forgetting Behavior Method for Knowledge Tracing. Appl. Sci. 2023, 13, 7704. https://doi.org/10.3390/app13137704
Song Q, Luo W. SFBKT: A Synthetically Forgetting Behavior Method for Knowledge Tracing. Applied Sciences. 2023; 13(13):7704. https://doi.org/10.3390/app13137704
Chicago/Turabian StyleSong, Qi, and Wenjie Luo. 2023. "SFBKT: A Synthetically Forgetting Behavior Method for Knowledge Tracing" Applied Sciences 13, no. 13: 7704. https://doi.org/10.3390/app13137704
APA StyleSong, Q., & Luo, W. (2023). SFBKT: A Synthetically Forgetting Behavior Method for Knowledge Tracing. Applied Sciences, 13(13), 7704. https://doi.org/10.3390/app13137704