
Transformer Fault Diagnosis Method Based on Incomplete Data and TPE-XGBoost

Abstract
:1. Introduction
2. Theory
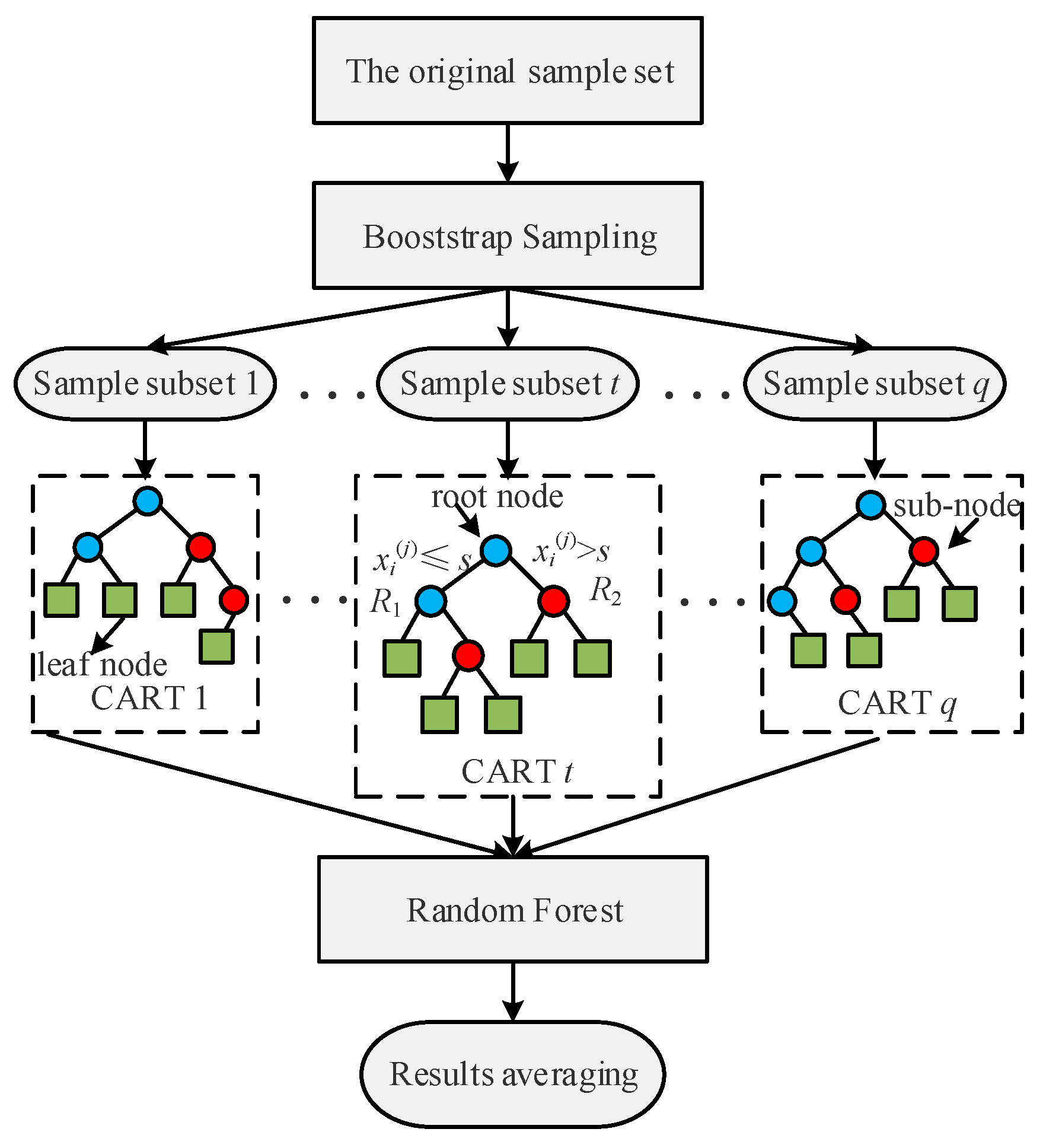
2.1. Random Forest Regression Method
- Construct a root node containing a subset of all samples.
- Iterate over all features and, for feature j, divide the sample set by the intersection point s. First, the values of all features j in the sample subset are ranked from smallest to largest, and s is the average of the two adjacent values after feature ranking. Optimal sample segmentation is the minimization of the objective squared error. By solving for the minimum of Equation (1), the optimal feature and optimal cut-off point of the segmented sample set is obtained.
- 3.
- Continue to repeat step 1 and step 2 for the 2 subunits until the entire decision tree is grown and all samples in the subset are assigned to the leaf nodes. The prediction result corresponds to yi is [21]
2.2. TPE-XGBoost Method
2.3. TPE Optimization Method
3. Transformer Fault Diagnosis Method
3.1. DGA Sample Dataset
3.2. Missing Data Filling Method
- Analyze missing sample data and construct a sample set based on missing values and treat-filled features as labels.
- Select the sample data with the least number of missing values for filling-in priority. The missing values of features other than the feature to be filled are temporarily replaced by their mean.
- Predict the values of the missing data using RFR and insert the predicted results into the original sample set.
- Repeat steps 1–3 until the last feature with the highest number of missing values is predicted by a final regression on it using the original sample after filling.
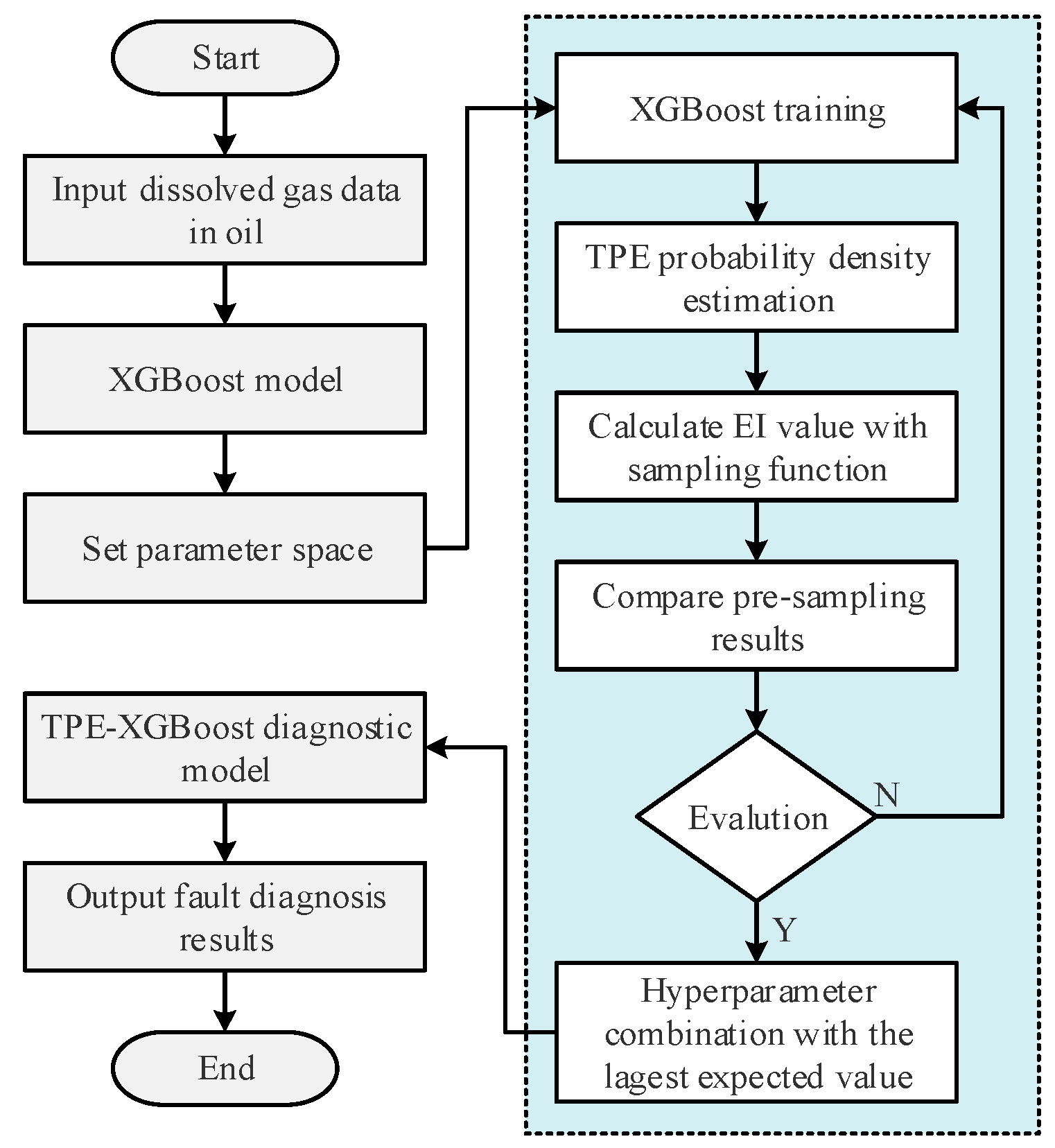
3.3. Transformer Fault Diagnosis Model
- Input dissolved gas data in oil to construct an XGBoost model and set XGBoost parameter ranges.
- Train the XGBoost model and perform TPE probability density estimation. The expected value is calculated by the sampling function, and the next combination of parameters to be evaluated is selected based on the prior expected value.
- Use the combination of parameters with the maximum expected value in the XGBoost model for training to output the prediction results of the model with the current hyperparameters.
- If the error of the newly selected parameter combination meets the requirements, the algorithm will be terminated, and the corresponding parameter combination and model prediction error will be output. If not, the sampling function will be corrected and go back to step (2) until the set requirement is met.
- According to the optimal parameters of XGBoost, the final fault diagnosis model based on TPE-XGBoost is obtained, and the fault diagnosis results are output.
4. Application Results and Analysis
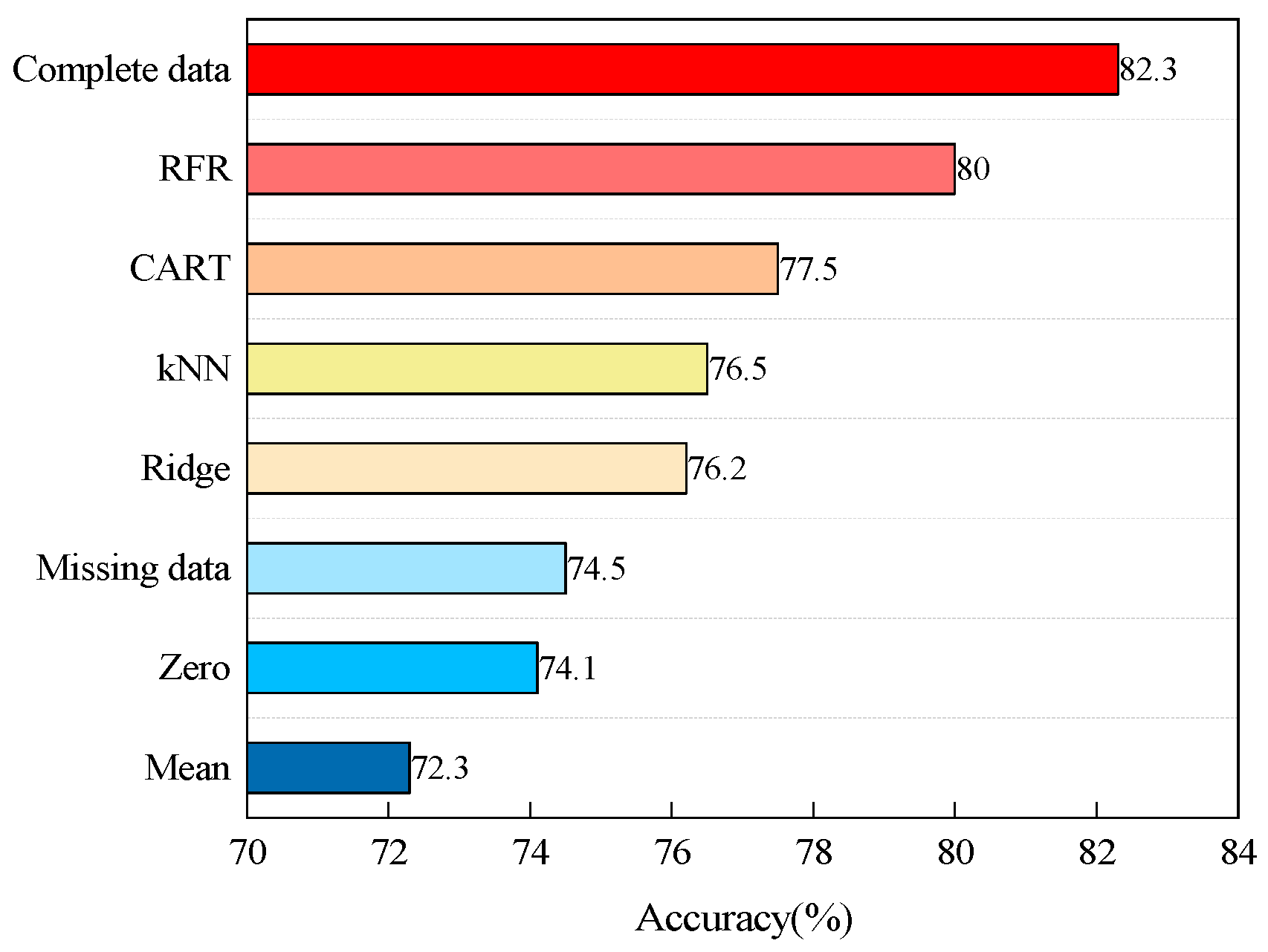
4.1. Analysis of Data Filling Methods
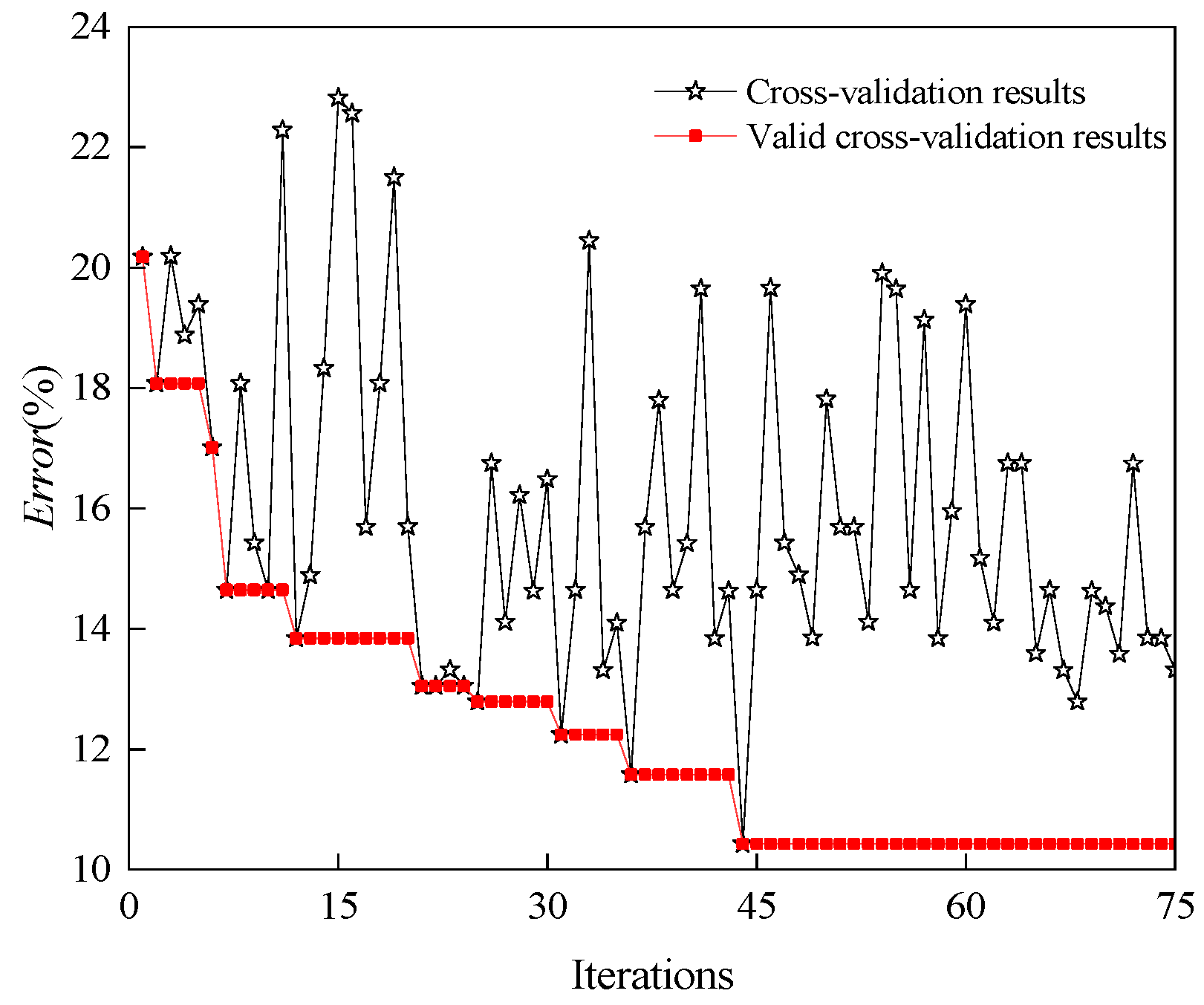
4.2. Parameter Optimization of XGBoost Model
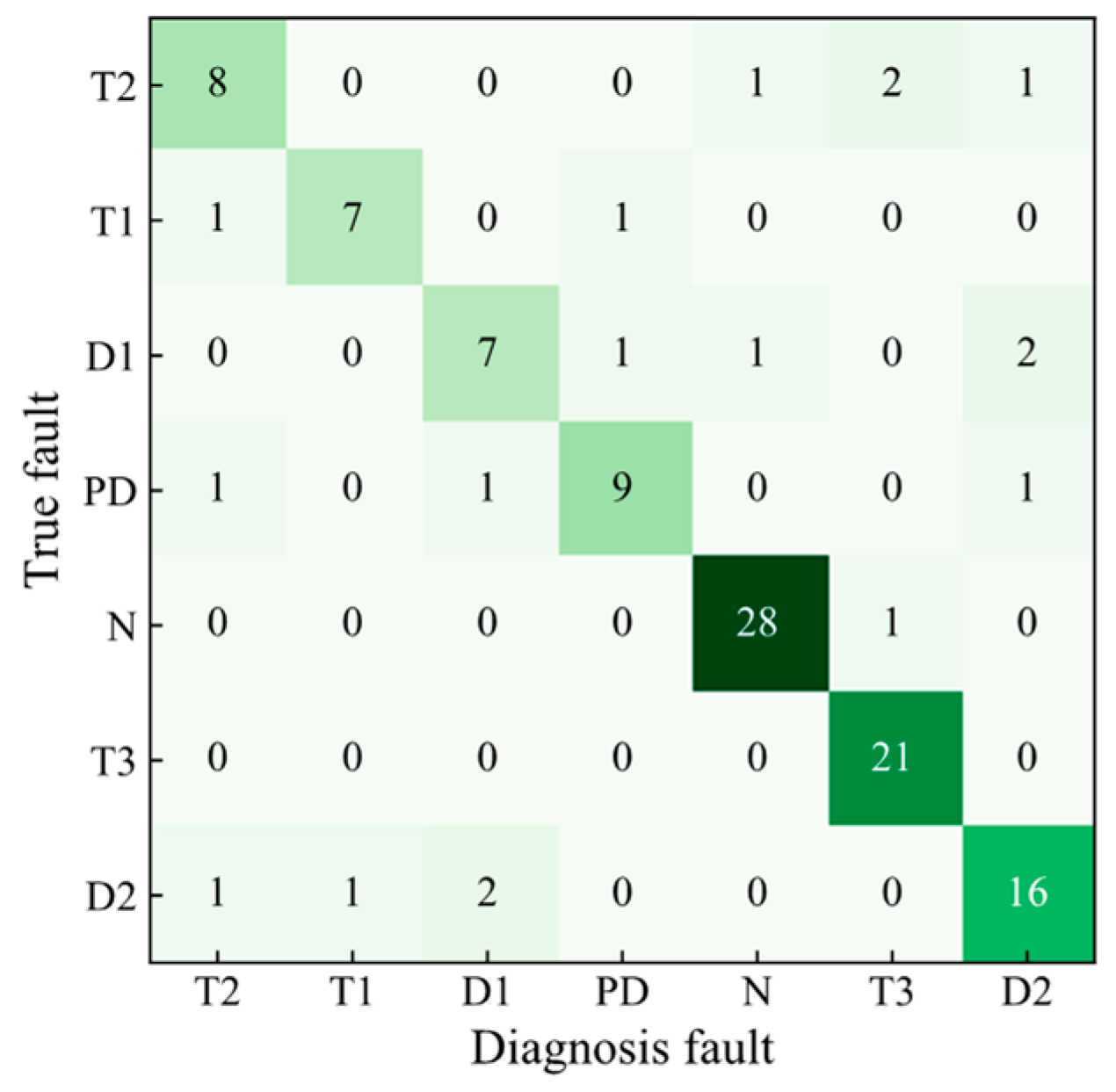
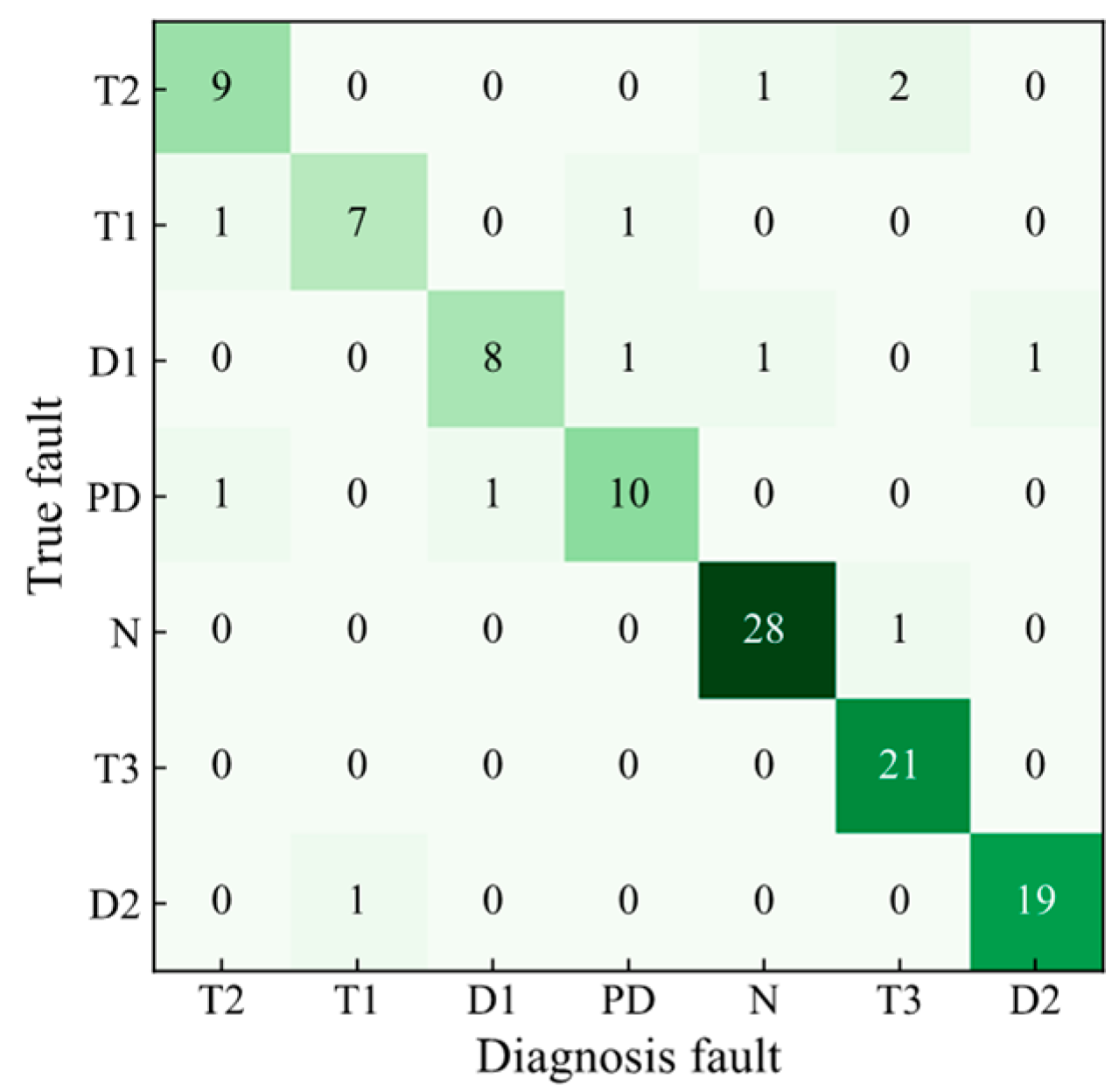
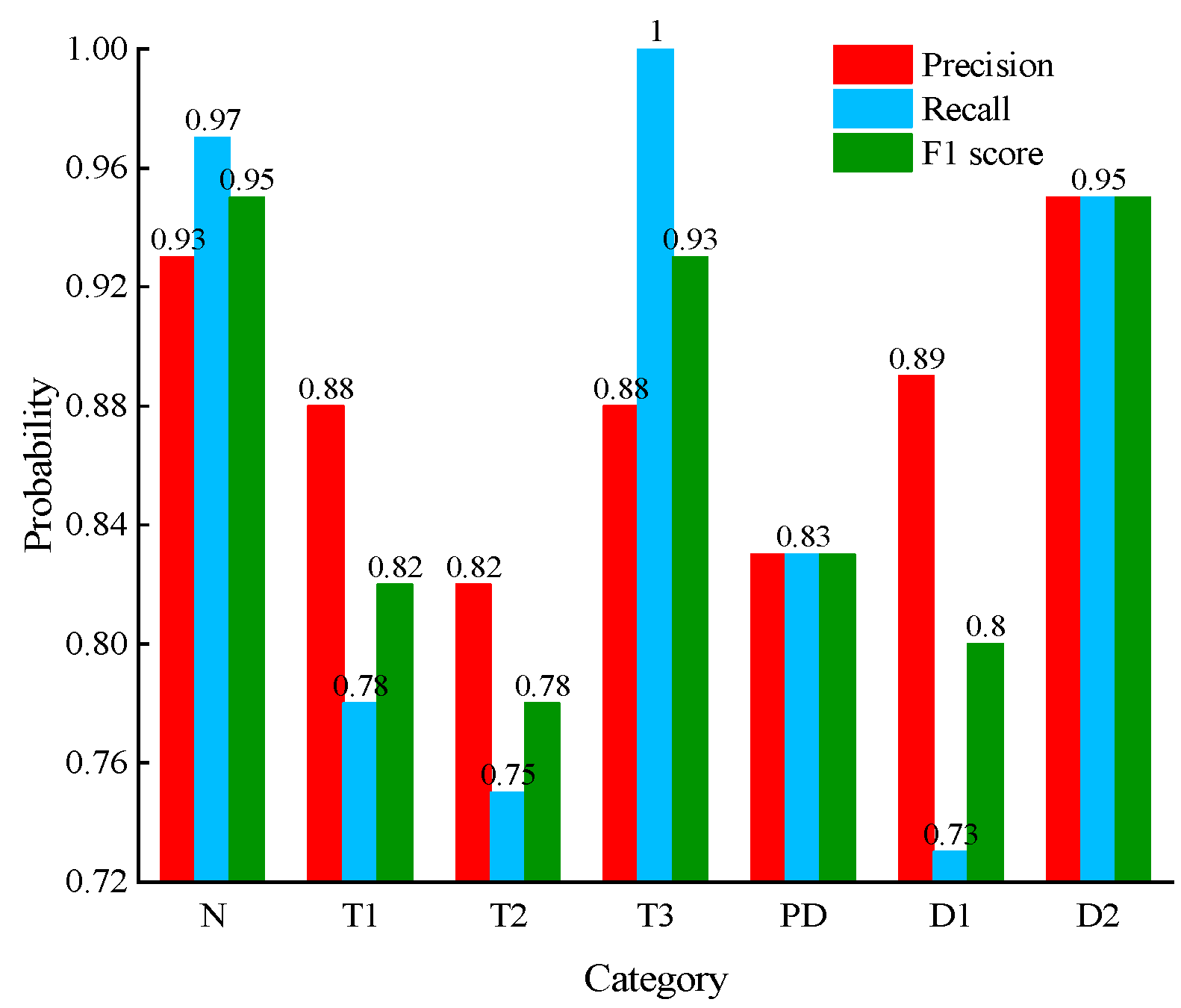
4.3. Analysis of Fault Diagnosis Methods
4.4. Discussion
5. Conclusions
- The RFR algorithm outperformed traditional statistical methods and CART, kNN, and Ridge for the missing data problem of dissolved gas in transformer oil. The accuracy of the RFR model reached 80% when the missing rate of DGA data was 20%, indicating that the RFR-filled values could restore the information of the dissolved gas in the transformer oil to a greater extent.
- Based on the DGA sample database, after the RFR model fills in the missing data, the accuracy of the XGBoost model was improved from 80% to 89.5% after feature derivation and hyper-parameter optimization of the TPE algorithm. The evaluation metric F1-score of the TPE-XGBoost model was 87%, indicating the effectiveness of the TPE-XGBoost diagnostic model.
- The TPE-XGBoost algorithm was compared with kNN, CART, RF and DNN. Based on the DGA sample dataset with 20% missing values, the average accuracy of the TPE-XGBoost model was 89.5% and was much higher than the other algorithms. The superiority of the TPE-XGBoost algorithm in dealing with transformer fault diagnosis problems was demonstrated. The diagnosis results obtained in the case of partially missing data were still credible.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghoneim, S.S.M.; Mahmoud, K.; Lehtonen, M.; Darwish, M.F. Enhancing diagnostic accuracy of transformer faults using teaching-learning-based optimization. IEEE Access 2021, 9, 30817–30832. [Google Scholar] [CrossRef]
- Rao, U.M.; Fofana, I.; Rajesh, K.N.V.P.S.; Picher, P. Identification and application of machine learning algorithms for transformer dissolved gas analysis. IEEE Trans. Dielect. Electr. Insul. 2021, 28, 1828–1835. [Google Scholar] [CrossRef]
- Kahlen, J.N.; Andres, M.; Moser, A. Improving machine-learning diagnostics with model-based data augmentation showcased for a transformer fault. Energies 2021, 14, 6816. [Google Scholar] [CrossRef]
- Tang, L.R.; Wang, R.; Wu, R.; Fan, B. Missing data filling algorithm for uniform data model in panoramic dispatching and control system. Autom. Electr. Power Syst. 2017, 41, 25–30+87. [Google Scholar]
- Santos, M.S.; Pereira, R.C.; Costa, A.F.; Soares, J.P.; Santos, J.; Abreu, P.H. Generating synthetic missing data: A review by missing mechanism. IEEE Access 2019, 7, 11651–11667. [Google Scholar] [CrossRef]
- Cheng, X.; Li, P.; Guo, L.; Zhang, W. Transformer operating state monitoring method based on Bayesian probability matrix decomposition of measurement data. Proc. CSU-EPSA 2022, 34, 100–107. [Google Scholar]
- Wu, L.Z.; Zhu, Y.L.; Yuan, J.H. Novel method for transformer faults integrated diagnosis based on Bayesian network classifier. Trans. China Electrotech. Soc. 2005, 20, 45–51. [Google Scholar]
- Roger, R.R. IEEE and IEC Codes to interpret incipient faults in transformers, using gas in oil analysis. IEEE Trans. Dielect. Electr. Insul. 1978, 13, 349–354. [Google Scholar] [CrossRef]
- Duval, M. Dissolved Gas Analysis: It Can Save Your Transformer. IEEE Electr. Insul. Mag. 1989, 5, 22–27. [Google Scholar] [CrossRef]
- Dornenburg, E.; Strittmatter, W. Monitoring oil-cooled transformers by gas analysis. Brown Boveri Rev. 1974, 61, 238–247. [Google Scholar]
- Duval, M.; Depabla, A. Interpretation of gas-in-oil analysis using new IEC publication 60599 and IEC TC 10 databases. IEEE Electr. Insul. Mag. 2001, 17, 31–41. [Google Scholar] [CrossRef]
- Duval, M.; Lamarre, L. The Duval Pentagon—A new complementary tool for the interpretation of dissolved gas analysis in transformers. IEEE Electr. Insul. Mag. 2014, 30, 9–12. [Google Scholar]
- Taha, I.B.M.; Ghoneim, S.S.M.; Duaywah, A.S.A. Refining DGA methods of IEC code and rogers four ratios for transformer fault diagnosis. IEEE Power Energy Soc. Gen. Meet. 2016, 2016, 7741157. [Google Scholar]
- Tightiz, L.; Nasab, M.; Yang, H.; Addeh, A. An intelligent system based on optimized ANFIS and association rules for power transformer fault diagnosis. ISA Trans. 2020, 103, 63–74. [Google Scholar] [CrossRef]
- Bacha, K.; Souahlia, S.; Gossa, M. Power transformer fault diagnosis based on dissolved gas analysis by support vector machine. Electr. Power Syst. Res. 2012, 83, 73–79. [Google Scholar] [CrossRef]
- Pei, X.; Zheng, X.; Wu, J. Rotating Machinery Fault Diagnosis Through a Transformer Convolution Network Subjected to Transfer Learning. IEEE Trans. Instrum. Meas. 2021, 70, 2515611. [Google Scholar] [CrossRef]
- Haque, N.; Jamshed, A.; Chatterjee, K.; Chatterjee, S. Accurate Sensing of Power Transformer Faults from Dissolved Gas Data Using Random Forest Classifier Aided by Data Clustering Method. IEEE Sens. J. 2022, 22, 5902–5910. [Google Scholar] [CrossRef]
- Das, S.; Paramane, A.; Chatterjee, S.; Rao, U.M. Accurate Identification of Transformer Faults from Dissolved Gas Data Using Recursive Feature Elimination Method. IEEE Trans. Dielectr. Electr. Insul. 2023, 30, 466–473. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Chehreh, S.C.; Nasiri, H.; Tohry, A. Modeling industrial hydrocyclone operational variables by SHAP-CatBoost—A “conscious lab” approach. Powder Technol. 2023, 420, 118416. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Fatahi, R.; Nasiri, H.; Homafar, A. Modeling operational cement rotary kiln variables with explainable artificial intelligence methods—A “conscious lab” development. Part. Sci. Technol. 2023, 40, 715–724. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; Freitas, N.D. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Bardenet, B.R.; Bengio, Y.; Kégl, B. Algorithms for hyperparameter optimization. Proc. Adv. Neural Inf. Process. Syst. 2011, 24, 1–9. [Google Scholar]
- Hoballah, A.; Mansour, D.-E.A.; Taha, I.B.M. Hybrid Grey Wolf Optimizer for Transformer Fault Diagnosis Using Dissolved Gases Considering Uncertainty in Measurements. IEEE Access 2020, 8, 139176–139187. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Ozkale, M.R.; Lemeshow, S.; Sturdivant, R. Logistic regression diagnostics in ridge regression. Comput. Stat. 2018, 33, 563–593. [Google Scholar] [CrossRef]
- Xu, X.; Li, Y.; Yuan, C. Identity bracelets for feep neural networks. IEEE Access 2020, 8, 102065–102074. [Google Scholar] [CrossRef]
- Nasiri, H.; Ebadzadeh, M.M. MFRFNN: Multi-functional recurrent fuzzy neural network for chaotic time series prediction. Neurocomputing 2022, 507, 292–310. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value | H2 | CH4 | C2H6 | C2H4 | C2H2 |
|---|---|---|---|---|---|
| mean | 222.38 | 122.25 | 73.14 | 164.26 | 29.00 |
| standard | 453.83 | 298.97 | 281.79 | 359.65 | 76.18 |
| minimum | 0 | 0 | 0 | 0 | 0 |
| 1st quartile | 18.50 | 10.90 | 2.48 | 2.60 | 0 |
| 2nd quartile | 72.20 | 43.00 | 17.80 | 30.00 | 0.30 |
| 3rd quartile | 191.46 | 136.60 | 54.00 | 147.05 | 13.75 |
| maximum | 3433.00 | 4992.00 | 4836.00 | 3671.00 | 765.20 |
| No. | Features | No. | Features |
|---|---|---|---|
| 1 | M(H2) | 9 | C(C2H4/C2H6) |
| 2 | M(CH4) | 10 | K(H2/(H2 + TH)) |
| 3 | M(C2H6) | 11 | K(C2H4/TH) |
| 4 | M(C2H4) | 12 | K(C2H6/TH) |
| 5 | M(C2H2) | 13 | K(C2H2/TH) |
| 6 | M(TH) | 14 | K((CH4 + C2H4)/TH) |
| 7 | C(C2H2/C2H4) | 15 | K((C2H4 + C2H6)/TH) |
| 8 | C(CH4/H2) | 16 | K((C2H2 + CH4)/TH) |
| Parameter | Range | Step Size | Parameter | Range | Step Size |
|---|---|---|---|---|---|
| num_boost_round | [20, 300] | 1 | eta | [0.1, 1] | 0.05 |
| colsamble_by_tree | [0.3, 1] | 0.05 | booster | [‘gbtree’, ‘dart’] | / |
| colsample_by_node | [0.1, 1] | 0.05 | gamma | [0.5, 2] | 0.1 |
| min_child_weight | [0, 5] | 0.05 | lambda | [0, 3] | 0.1 |
| max_depth | [2, 30] | 1 | subsamples | [0.1, 1] | 0.05 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| num_boost_round | 239 | eta | 0.15 |
| colsamble_by_tree | 0.80 | booster | ‘gbtree’ |
| colsample_by_node | 0.20 | gamma | 1.20 |
| min_child_weight | 1.20 | lambda | 3.10 |
| max_depth | 4 | subsamples | 1 |
| Method | Sample Size | Minimum | Maximum | Mean | Standard Deviation | t Value | p Value |
|---|---|---|---|---|---|---|---|
| kNN | 10 | 0.661 | 0.857 | 0.772 | 0.062 | −4.495 | 0.001 |
| CART | 10 | 0.694 | 0.861 | 0.779 | 0.057 | −4.46 | 0.002 |
| DNN | 10 | 0.639 | 0.917 | 0.792 | 0.097 | −2.231 | 0.053 |
| RF | 10 | 0.75 | 0.895 | 0.834 | 0.049 | −1.68 | 0.127 |
| XGBoost | 10 | 0.767 | 0.943 | 0.861 | 0.056 | 0.048 | 0.963 |
| NGBoost | 10 | 0.768 | 0.956 | 0.877 | 0.063 | 0.852 | 0.417 |
| TPE-XGBoost | 10 | 0.837 | 0.955 | 0.9 | 0.037 | 3.374 | 0.008 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.; Li, Q.; Yang, J.; Xie, T.; Wu, P.; Liang, J. Transformer Fault Diagnosis Method Based on Incomplete Data and TPE-XGBoost. Appl. Sci. 2023, 13, 7539. https://doi.org/10.3390/app13137539
Wang T, Li Q, Yang J, Xie T, Wu P, Liang J. Transformer Fault Diagnosis Method Based on Incomplete Data and TPE-XGBoost. Applied Sciences. 2023; 13(13):7539. https://doi.org/10.3390/app13137539
Chicago/Turabian StyleWang, Tonglei, Qun Li, Jinggang Yang, Tianxi Xie, Peng Wu, and Jiabi Liang. 2023. "Transformer Fault Diagnosis Method Based on Incomplete Data and TPE-XGBoost" Applied Sciences 13, no. 13: 7539. https://doi.org/10.3390/app13137539
APA StyleWang, T., Li, Q., Yang, J., Xie, T., Wu, P., & Liang, J. (2023). Transformer Fault Diagnosis Method Based on Incomplete Data and TPE-XGBoost. Applied Sciences, 13(13), 7539. https://doi.org/10.3390/app13137539