1. Introduction
The spreading rate of false information across digital and traditional news platforms has become a serious problem over the past few years, with the principal contributing factor being the distorted nature of the data. Individuals face challenges in distinguishing between reliable and denatured media sources. The ability of individuals to differentiate between real news and false news is directly affected by the amount of genuine information available on different media platforms. The way the human mind works is influenced by the existence of reliable references across all domains. The high volume of fake news determines major changes in the level of trust people have in media sources.
Fake news refers to the manufactured information created to distort people’s understanding of events. The spread of fake information has made specialists from different domains determined to implement fake news detection methods to identify and mark information that aims to affect people’s understanding of reality.
In this context, Natural Language Processing (NLP) has become an important technique for the fake news detection process. NLP is a subfield of Artificial Intelligence that allows computers to understand and process human languages. Over recent years, NLP has proved its efficiency for multiple tasks such as text summarization, question answering, machine translation, text classification, etc. [
1]. Unfortunately, there is one big challenge that frequently occurs in the context of certain NLP tasks involving not-so-common languages—the lack of large and reliable data sets. To overcome this problem, augmentation techniques for text data have gained interest. Data augmentation is a well-known method for improving Machine Learning (ML) models by creating data out of data; the scope is to increase the quantity and diversity of training data sets [
2]. Text data augmentation is the process of creating new text data that are similar to the original text information. Increasing the size of data sets is important for NLP tasks because it allows ML models to increase their robustness.
One of the common problems in the field of NLP tasks when considering languages that are less commonly used is the lack of reliable data sets. This is a well-known challenge that has a negative impact on training the supervised ML algorithms and implicitly affects the process of making accurate predictions when it comes to NLP tasks. Another challenge in this area is related to the size, origin, and reliability of the data. Another point involves the difficulties that researchers encounter when trying to identify sources of annotated data that align with their specific problems and can be used further for data set creation. Annotated data are challenging to identify and represent the key to obtaining good results from supervised learning techniques. The most common approach to data set creation involves careful analysis of online data sources to address certain problems, rigorous data collection processes, and complex preprocessing steps to ensure that the data are suitable for applying computational algorithms. Unfortunately, these steps do not fully overcome this common challenge. Usually, more techniques are required to obtain larger data sets that can be used to train ML algorithms. The size of the data sets can be increased by using text data augmentation methods, such as translation, back translation, synonym word replacement, generative models, random insertion, swapping, or deletion. These methods have been successfully proven to enrich training data sets, and, furthermore, they can solve other common problems, such as data imbalance, by generating additional samples for the minority output class.
This article focusses on text data augmentation techniques for the Romanian language to improve the efficiency of fake news detection tasks. The original data set is extracted from a fact-checking site that evaluates and labels the political declarations of Romanian politicians. Furthermore, the obtained data set is enriched in the experimental section by applying text data augmentation methods.
The goal of our paper is to investigate the text data augmentation methods that are applicable for improving fake news detection in the Romanian language. We address the following research questions:
RQ1: What are the text data augmentation methods that can be applied to improve fake news detection in the Romanian language?
RQ2: What is the impact of text data augmentation on the performance of models for fake news detection in the Romanian language?
RQ3: How do the models perform when considering the context of the political statement as additional information to the content of the statement?
By addressing the above-mentioned research questions, the major contribution of this study is the analysis of text data augmentation performances, which led to the creation of a robust and reliable Romanian data set that can be further used for fake news detection tasks. Both data sets, content-based and context-based, have been shown to increase the efficiency of supervised learning techniques. We met the objective of this study by demonstrating that both text data enhancement methods, BT and EDA, considerably improved the performance of all classifiers included in our experiments.
The augmentation techniques presented in this paper are EDA and BT; both techniques are thoroughly described in
Section 2. The rest of the paper is structured as follows:
Section 3 presents related works;
Section 4 presents the methodology, followed by the results and discussion in
Section 5. The final conclusions are given in
Section 6.
2. Background
This paper presents and applies augmentation techniques for text data in the Romanian language. Data augmentation is a process that overcomes the limitation of training data by artificially increasing the size of training data with label-preserving transformations [
3]. Text data augmentation generates synthetic text data that are not identical to the original set. The main objective is to enhance the ability of a learning model without corrupting the meaning of the original information [
2]. Some of the common methods that aim to enhance text data sets are BT and EDA. BT and EDA are widely studied in the field of NLP and have demonstrated their effectiveness in improving the performance of various NLP tasks. Consequently, we decided to assess the applicability of these two methods in the context of detecting fake news in the Romanian language. The techniques mentioned above are explained in the following sections and applied in the experimental section of this paper.
2.1. Back Translation
The application of BT as a text data augmentation method has been shown to be effective in various NLP tasks such as text classification, hate speech detection, sentiment analysis, and neural machine translation [
4,
5,
6,
7,
8,
9]. The method consists of translating the original sentences into a target language and then back into the original language. The result provides a larger data set that can be used to improve the results of a training model. After the BT process, the obtained text data set is different from the source text in terms of words and grammatical structures. The resulting text data consists of different paraphrases, synonym replacements, substitution of syntactic structure, or deletion of irrelevant words [
4]. All the changes supported in the BT process preserve the meaning of the original text data, so the semantic differences do not affect the modeling techniques.
The origin of the BT method is related to statistical machine translation, and it has been used for semi-supervised learning and self-training [
8]. This method has proven to be effective in improving the quality of translation tasks by mitigating the problem of overfitting and exploiting new data in the target language [
6]. A neural machine translation approach shows that the synthetic data obtained with BT can be close to the accuracy of the real text [
9]. One of the well-known problems related to negative content on social media platforms addresses the area of hate speech detection. Beddiar et al. [
5] propose a Deep Learning (DL) method that includes BT for data augmentation to automatically detect offensive content. Their proposal for hate speech detection, including BT for text augmentation, overcomes some of the related state-of-the-art methods. For text classification tasks, data set size has a great influence on the performance of classification models. For example, in the context of Chinese text classification, the use of BT for data set augmentation proved to be helpful for small data sets and reduced the unbalanced distribution of samples, overall improving classification performance [
4]. The good performance of a classification model is directly affected by the amount of input text data. Considering its proven effectiveness, in this study we decided to apply BT as a method to enhance the original fact-checking data set. In this paper, the problem of the small data set for fake news detection tasks was an important factor that motivated us to apply BT in different languages and assess the performance of the ML models.
2.2. Easy Data Augmentation
Another well-known approach for text enrichment is EDA. EDA is a technique that boosts the performance of text classification tasks and is based on four powerful operations: synonym replacement (SR), random insertion (RI), random swap (RS), and random deletion (RD). These four processes are explained in more detail [
10]:
Synonym replacement: n words (that are not stop words) are chosen randomly from a sentence and replaced with synonyms;
Random insertion: a random synonym of a random word (that is not a stop word) is found in a sentence and inserted in a random position in the sentence; the process is repeated n times;
Random swap: two words in a sentence are randomly chosen, their positions are swapped, and the process is repeated n times;
Random deletion: each word in a sentence is randomly removed with probability p.
In the case of text classification tasks, applying EDA as a method to overcome the problem of small data sets has proven to be very efficient. For example, Wei et al. [
10] systematically evaluated EDA in five benchmark classification tasks and demonstrated that the method is particularly helpful for small data sets by improving the performance of convolutional and recurrent neural networks.
In this study, we encountered the common challenge of small training data sets, which usually occurs in the context of text classification tasks. To overcome this problem, we ran text data augmentation experiments over a Romanian fact-checking data set. In this scope, we used BT and EDA to solve the problem of small data sets. We only considered two augmentation methods because applying BT and EDA helped us enrich the training data set from 744 entries to 1488 entries and from 744 entries to 3720 entries, respectively. The results obtained with these methods along with careful data preprocessing are encouraging for the ML models that we applied.
3. Related Work
The common problem of fake news has gained popularity due to the great impact that false information has on people. Fabricated data is created more and more easily, so it becomes a challenge to distinguish between true information and false information. A solution to this negative phenomenon is to develop strategies that automatically identify and filter fake news across online platforms. Similar approaches for the English language are very popular; therefore, in this section, we investigate previous studies that address this problem in different languages, and in the second part of this section, we present similar approaches for the Romanian language.
In [
11], Kuzmin et al. present a fake news detection approach in the Russian language. At a certain level, the strategy that we present in this study is similar to their proposal. The ML models and the data set structure are common ground in these studies. The authors experimented with baseline models, such as Logistic Regression and Support Vector Machine, and they applied TF–IDF to vectorize the data. The fake news data set in Russian was divided into two non-overlapping classes, satire and fake news, while our data set is simply divided into true and false political declarations. To improve the results, Kuzmin et al. [
11] used language features such as bag-of-n-grams and bag-of-Rhetorical-Structure-Theory features, and BERT embeddings. In our study, we mainly focused on text data augmentation techniques for the training data set to improve our results. Another important difference between these studies is the data set size; the Russian data set size exceeds the Romanian data set size, even after we apply both data augmentation methods. Results were as expected; the best model achieved a 0.889 F1 score in the test set for two classes in the Russian study (~10,000 input records), and our best model achieved an F1 score of 0.8065 for the content-based data set and the BT approach (1674 input records). Despite the differences in data set size, the variations in the results are relatively minor.
The paper [
12] addresses the problem of detecting fake news in Spanish using ML and DL techniques. For further comparison, we will use the ML approach of this study as a reference [
12]. The authors used Support Vector Machine and Random Forest Classifier, and applied TF–IDF for word embedding. The Spanish corpus consisted of 2571 samples, balanced between true and false output classes. In this approach, the size of the data set is closer to that of our approach. For the Spanish data preprocessing, the authors removed stop words, but did not apply stemming. In our experiments, we also removed stop words and applied lemmatization. We share the same strategy in terms of the split between the training and test data set: 80% for training, and 20% for testing. The accuracy obtained for the Spanish fake news classification was 0.798 for the Support Vector Machine and 0.802 for the Random Forest [
12]. After we applied BT and doubled the original data set (1674 records after BT), we obtained 0.7957 for Support Vector Machine and 0.7581 for Random Forest, considering the content-based data set. Given the sizes and structures of the data sets, the observed similarities in the results are expected.
In the paper [
13], the authors present a fake news detection approach for the Hindi language. The common ML algorithms used in the Hindi study were Logistic Regression, Random Forest Classifier, and Support Vector Machine. In terms of preprocessing methods, we share in common the stop word removal, punctuation and special character removal, tokenization and stemming, and TF–IDF for data vectorization. The Hindi data set is made up of 2178 records, balanced between the two output classes. As a reference, we compare the results that we obtained using BT as a data augmentation method since with this method the data set sizes are close. We obtained the best results. The detection of fake news for Hindi obtained an F1 score of 0.68 in the case of the Random Forest Classifier and the Support Vector Machine, and better results were obtained for Logistic Regression, with an F1 score of 0.875. For our experiment, the results are lower in the case of the context-based data set, with an F1 score of 0.78 for the Support Vector Machine and Logistic Regression, and a small increase to 0.81 for the Random Forest Classifier. The slight difference of 6% in the results can be explained by language structure and characteristics or by differences in the number of words per record (but we are not aware of this aspect for the Hindi data set).
Another interesting study presents a Persian stance detection approach that includes data augmentation as a method to improve the training data set [
14]. The authors applied EDA to solve the problem of small data sets in Persian stance detection tasks. However, the fake news detection in the Persian study is different from our approach because it applied DL methods. It is worth mentioning that the authors investigated the effect of data augmentation and the ParsBERT pre-training model and concluded that EDA obtained better results than in previous works. A similar situation was observed in the case of fake news detection based on posture using pre-trained BERT [
15]. For that study, the authors experimented with random swap augmentation and synonym replacement techniques separately and demonstrated that swap augmentation provided the best result. In the paper [
16], Salah et al. investigated the use of text data augmentation for the stance task and fake news detection. The authors concluded that the text augmentation approach achieves promising predictive performances. Data augmentation was applied to detect antisocial behavior along with DL methods [
17]. However, the DL approach is different from our approach; it is interesting to observe that EDA is used to overcome problems such as class imbalance. The authors stated that EDA is very task-dependent and has limitations; the method was not suitable enough to improve the results in the case of toxic comment classification, but significantly improved the performance in the prediction of the minor class for the detection of fake news [
17]. The application of a specific process from the EDA method has also proven to be efficient. For example, the study [
18] presents a synonyms-based augmentation approach to improve the detection of fake news using Bidirectional LSTM. Even if the architecture is different from the one we present in the current study, it is important to mention that applying the synonym augmentation process increased the prediction capability of the system compared to the experiment that does not include data augmentation. Furthermore, the authors aim to develop better text augmentation processes to improve model prediction [
18]. There are novel approaches to text augmentation that aim to solve the same problems. These approaches include DL or transformer-based methods, and, in general, they manage to outperform some of the current methods [
19,
20,
21,
22,
23]. Future investigations related to transformer-based augmentation methods can be conducted to develop high-performance models for fake news detection.
For the Romanian language, we have identified similar approaches that aim to automatically detect fake news. For example, Buzea et al. [
24] propose a supervised ML system to detect fake news in online sources published in Romanian. They compare the results obtained for recurrent neural networks and BERT to the results achieved by two basic classification algorithms, namely, Naive Bayes and Support Vector Machine. Thus, the results of the Support Vector Machine approach will be compared with the performances obtained in our experiment. The Romanian data set constructed by Buzea et al. [
24] consists of 25,841 true records and 13,064 false records. The data set was collected from multiple sources between 2016 and 2021 and was validated by 12 employees in a public institution in Romania. Reliable news is based on trusted news sources such as Agerpres or Mediafax, and fake news is collected from untrusted sources such as Fluierul or CunoasteLumea. Some of the common preprocessing steps were applied: stop words removal, punctuation removal, and the TF–IDF method for feature extraction. The experiment achieved an F1 score of 0.94 for the Support Vector Machine. As a comparison to our best results obtained with Support Vector Machine and BT method on the context-based data set, an F1 score of 0.77, the differences in the results are related to the major difference in data set size. The data set employed is 22 times larger than the data set we generated using the text augmentation technique.
Busioc et al. [
25] propose an interesting approach for the detection of false news in the Romanian language [
25]. In this experiment, the authors used the same news source for data collection (Factual.ro), but the data set construction and the classification problem are slightly different from our proposal. To construct our data set, we considered multiple input attributes: topic statement, content statement, date, author’s name, political affiliation, and source of the statement. Furthermore, we enhanced the content statement with context. On the other hand, for the construction of the data set, Busioc et al. [
25] considered the content statement along with the first and last paragraphs from the context of the statement. Another difference from our approach is the classification problem. The authors initially addressed a multiclass classification by keeping the partly true and partly false labels and, lastly, trying to improve the performance by replacing partly true with true and partly false with false. As a classification method, Busioc et al. [
25] considered a transformer-based technique, RoBERT. However, the results are not outstanding; the authors reported an initial accuracy of 0.39 before label replacement and 0.65 after label replacement. Comparing the powerful BERT-based model with the basic ML classifiers and the data augmentation methods that we applied, we can say that the Random Forest Classifier outperformed their proposed approach with an accuracy of 0.81 for the context-based data set in the case of BT text augmentation.
4. Methodology
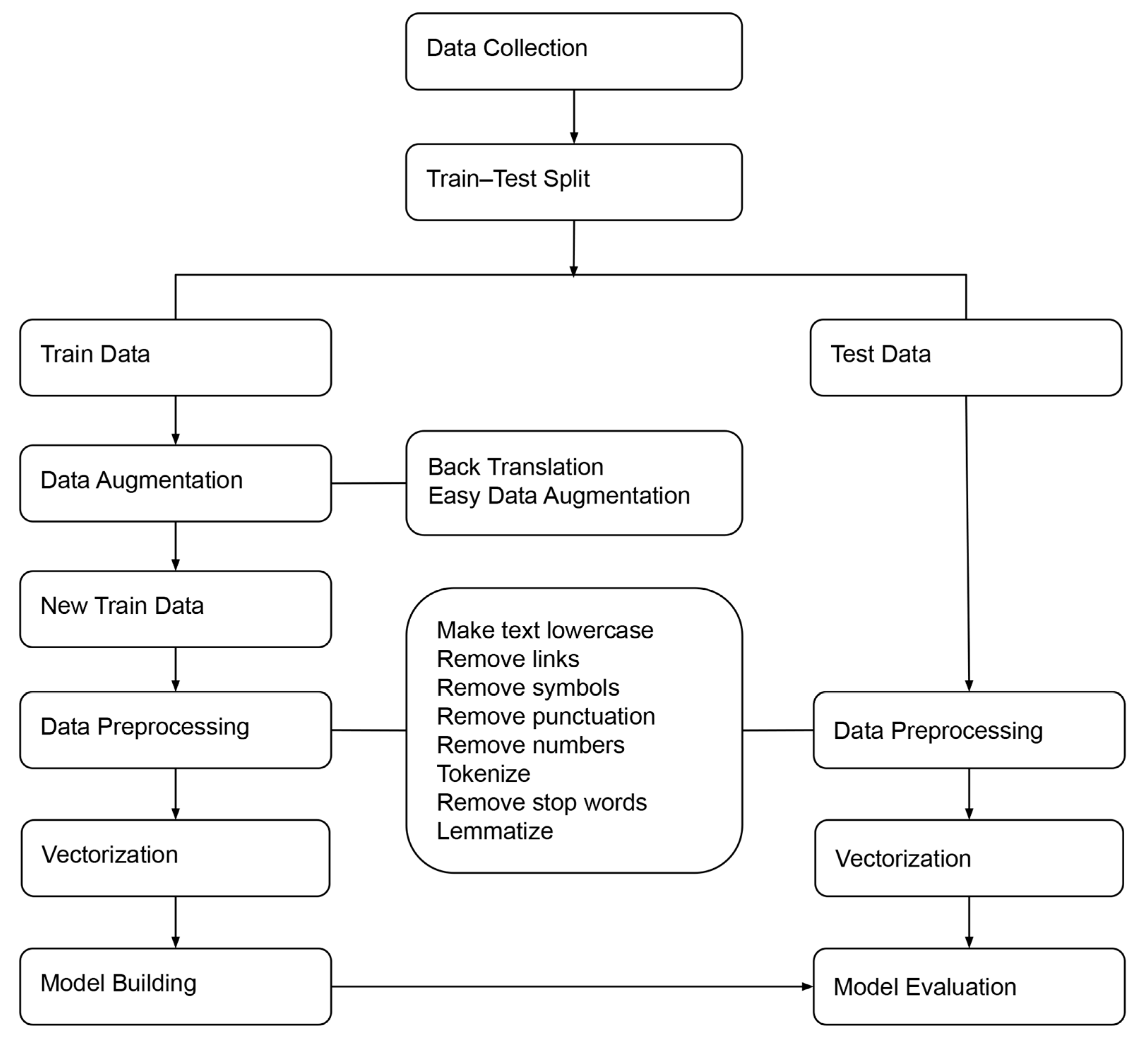
The proposed fake news detection system using data augmentation techniques consists of five main steps, as illustrated in
Figure 1. The first step is data collection. This involves collecting the necessary data for the system. The second step is data augmentation, which involves adding new data to the existing data set. This can help to improve the results of the model. The third step is data preprocessing, which involves cleaning and preparing the data for the model. The fourth step is model building, which involves creating a model to detect fake news. Finally, the fifth step is model evaluation, which involves testing the model to assess its effectiveness. By following these steps, the system should be able to identify fake news more accurately.
This study used the Scikit-learn software package [
26] in the data cleaning and exploration phase, the feature vectorization process, the implementation of various models and the evaluation of the performance of the model. Scikit-learn was used for its easy-to-use interface and access to supervised algorithms. The use of Scikit-learn was justified by its wide use in the machine learning community due to its attractive features and comprehensive documentation [
27].
4.1. Data Collection
Fake news is an increasing concern in our digital era, with fact-checking platforms arising as an answer to counter it. Fact-checking platforms have been developed to raise awareness about articles that contain fabricated information [
28]. These platforms play a critical role in the detection of false news by verifying the accuracy of news articles [
29].
Factual.ro is a Romanian fact-checking platform that uses independent experts to fact-check shared news and content. The platform was formally launched in May 2014 by an enthusiastic group of NGOs, entrepreneurs, and policy consultants interested in good governance. Factual.ro was designed to verify the accuracy of news stories, social media posts, and other types of media content made by political representatives [
30]. The Factual.ro monitoring team searches daily for decisions and statements from the public sphere in media sources: press agencies, newspapers, blogs, official Facebook pages, press releases and statements from state institutions, transcripts from parliament sessions, government meetings, debates, press conferences, etc. According to Factual.ro, a fact-checking subject can be, but is not limited to, statements attributed to decision makers, procedures of public institutions that appear to have not been respected, and decisions or policies that may not be backed by evidence. A team of independent, expert fact-checkers reviews and assesses the accuracy of the content. Any fact-checked article published by the Factual.ro editorial staff is subject to the principles set out in the Factual.ro methodology, published within the platform. Once they review the content of an article, the Factual.ro experts include it in one of the following categories: true, partially true, false, partially false, truncated, impossible to check, or changing one’s mind.
The Factual.ro platform provides a valuable resource for implementing a fake news detection system in the Romanian language using machine learning techniques. As we found from our discussion with the representatives of the Factual.ro platform, this resource is not available in the form of a data set, which led us to propose the implementation of our first version of the Factual.ro data set in [
31]. In this paper, we extend the initial data set by extracting all available statements from the Factual.ro platform between 2014 and 2023.
We used Python and BeautifulSoup to develop an automated data extraction method to obtain content from the Factual.ro fact-checking platform. Python is an effective scripting language for data extraction. BeautifulSoup is a useful Python library for web scraping and collecting data from various websites. By writing a script with Python and BeautifulSoup, data can be automatically collected from a fact-checking platform. This script (Algorithm 1) can be used to capture information such as the context of statements, the author’s name, affiliation, source name, and the date of publication of the statement. Additionally, the script can retrieve the statement’s context. Afterwards, we transferred these data to a structured format, such as a CSV file, for further analysis.
| Algorithm 1 The process of web scraper design |
Input: URL for the Factual.ro website assigned to the base_url variable.
Output: A CSV file containing information on the articles from the input URL. |
Set the base_url to ‘https://www.factual.ro/toate-declaratiile/’ (accessed on 17 June 2023).
Set links to an empty set.
Use BeautifulSoup to get the text of the page at base_url.
For each statement element on the page:
Add the value of its href attribute to the links set.
Set the result to an empty list.
For each link in the links list:
Try the following:
Use BeautifulSoup to get the text of the page on the current link.
Find the topic element, get its text, and assign it to the topic.
Find the content element, get its text, and assign it to the content.
Find the context element, get its text, and assign it to context.
Find the author element, get its text, and assign it to the author.
Find the affiliation element, get its text, and assign it to the affiliation.
Find the date element, get its text, and assign it to the date.
Find the source element, get its text, and assign it to the source.
Find the label element, get its text, and assign it to the label.
Append a list of topic, content, date, author, affiliation, source, context, and
label to the result.
If there is an exception, do not do anything and proceed to the next link.
Write the result to a CSV file in the specified path. |
The resulting data set included eight attributes that can be used to build a prediction model. First, the data set includes the detailed topic (1) under which the statement was classified on Factual.ro. Additionally, it contains the main text of the statement—content (2)—along with the relevant background information needed to frame it properly—context (3). Furthermore, it contains the exact date (4) on which the statement was published or posted online. The data set also includes the author’s name (5), which refers to the individual who made the statement. It also includes their political affiliation (6), such as a party. Additionally, each statement can include the source name (7), which refers to the media platform where the statement was published or identified. Lastly, the label attribute (8) indicates whether the statement is true/real or false/fake.
The data set obtained by scraping the Romanian fact-checking platform Factual.ro includes only Romanian content. This Factual.ro data set contains 1164 unique records. Records were labeled as follows: false—374, true—314, truncated—204, partially true—187, partially false—55, impossible to check—23, and others—7.
Figure 2 illustrates the distribution of statements in the Factual.ro data set by date. The graph shows a steady growth in the number of statements stored in the Factual.ro data set. The last spike in statement releases occurred at the end of 2022. This is likely due to the increased public attention to the Romanian political environment during this period. Furthermore, the highest number of statements in the data set was recorded in September 2020 and April 2021. From this we can deduce that the Factual.ro data set is an effective tool for examining changes in Romanian politics over the last few years.
The distribution of data between categories is crucial to the performance of classification algorithms [
32]. An unbalanced data set, where the number of instances in each category is significantly different, can lead to poor classification results. The class imbalance occurs when the distribution of classes between the majority and minority classes is different [
33]. In the case of our data set consisting of seven unbalanced categories, removing categories with little data (truncated, impossible to check, and other) and replacing partially true categories with true and partially false categories with false ones is a valid approach to balancing the data set. After these operations, the data set contained 930 entries, divided into two classes: 501 true records (53.87%) and 429 false records (46.13%).
We selected three fake news records and three real news records from the Factual.ro data set developed for this study. For each entry, we then noted the source where the statement was published. We also noted the publication date and the topic to which the statement belongs. We include the statement author and his/her political affiliation, and the statement itself.
Table 1 shows examples of real news and fake news.
At the data-set level, we should note the difference between content and context attributes. Content refers to the main premise of a statement that is being fact-checked. It is the factual assertion or the assertion of opinion being made. The content of the statement is typically composed of one or more factual claims or opinions, true or false. The context refers to the circumstances surrounding a statement. At the context level, elements such as the speaker or author, the target audience, the source, the time frame, and any other related information can also be specified. In
Table 2 we have specified for comparison the values of the content and context attributes corresponding to the examples of real and fake news from the Factual.ro data set specified above.
The difference between the average values of the number of characters, words, and sentences of fake and real statements in the content of the data set is relatively small (around 5%). However, in terms of context, the values are more than 20 per cent higher for fake statements than for real statements.
Table 3 presents the distribution of characters, words, and sentences in the content and context of the statements of the data set.
In
Figure 3, a word cloud of the most common words that appear only in fake news or real news, extracted from the 100 most common words in the content and context of the statements, is presented. This was done to identify terms that appear exclusively in fake news in content (a), fake news in context (b), real news in content (c), or real news in context (d).
4.2. Data Augmentation
Adding text data can significantly improve the performance of a classifier by increasing the volume of training data available. This can reduce overfitting and improve the generalization of the model [
34]. Augmentation techniques such as BT or EDA can be used to generate more data that can aid in a better training of the model [
35]. These techniques can help the classifier learn more complex relationships between words and increase the accuracy of the classifier.
We implemented two data augmentation techniques, BT and EDA, for the Romanian language data set to improve classification performance. First, we implemented the BT technique. This involved translating the data into another language, in our case English, and then translating them back into the original language (Romanian), thus creating new entries with similar words while preserving the original context. We implemented this technique using the deep_translator module of the Google Translator library. As can be seen in
Table 4, the two statements that appear within this technique are not identical, even if the meaning of the statement after BT is the same.
The train–test split was made by randomly splitting the data into two separate sets of data, with 744 records (80%) in the training set and 186 records (20%) in the test set. As the augmentation technique was only applied to the training data, after this process we obtained a new set of training data. When the BT data augmentation method was applied, the original training data set doubled in size. The initial training data set had 744 records, and after BT the new training data set had 1488 records. After applying this technique, the total number of records in the data set increased from 930 to 1674 entries, with 1488 entries in the training set and 186 entries in the test set.
The second data augmentation technique we applied in this paper is called EDA [
10]. EDA is a process of synthetically creating more data by applying different augmentations to the existing data set.
When applying EDA to our training data set, the number of records in the new training set increased from 744 to 3720. This was achieved by applying the four operations to each entry in the original data set. For example, the original sentence “The red quarantined areas are mainly in the counties led by the yellow barons” was augmented four times by applying SR, RI, RS, and RD operations to create four different variations of the statement. In
Table 4, we present an example of how we applied this approach to the EDA technique for the Romanian language.
The Factual.ro data set that we implemented and used in this paper has only Romanian content. The application of EDA to the data was relatively straightforward. All that was required was to install the TextAttack library, create an EasyDataAugmenter object, and then apply it to the English version of the training data. This generated a new augmented version of the training data that was then translated back into Romanian.
The distribution of each class in training and testing data before and after data augmentation is presented in
Table 5. By using the BT and EDA techniques, we created a range of different semantically similar data points, which we used to improve the accuracy and generalizability of the original data.
Considering the strategy mentioned above regarding the train–test split process, the overfitting problem was managed by applying data augmentation methods for the training data set only, for both BT and EDA. Our proposed strategy aligns with the principles of text data augmentation to improve models’ performance in the field of NLP. Given that the augmented text data used for model training were not included in the test data set, we ensured that the overfitting problem was bypassed in the classification experiment. However, the phenomenon of overfitting is a complex problem, and it is not our intention to underestimate it. For this study, we consider that applying text data augmentation to training data sets has overcome this problem to a considerable extent.
4.3. Data Preprocessing
To apply data preprocessing for our Factual.ro data set, we first employed normalization techniques to handle diacritics and other special characters in Romanian text. Secondly, we cleaned the text by implementing a function that makes the text lowercase, removes text in square brackets and links, and removes punctuation and words containing numbers.
Additionally, we performed commonly used NLP operations, such as removing stop words, tokenization, and lemmatizing the text. This was done by using the Romanian stop words list and the tokenizer from the Natural Language Toolkit (NLTK) library and the Stanza library for lemmatization. Finally, we used the Stanza library to apply the lemmatization to Romanian text. This library has been evaluated in multiple languages, including Romanian, and performed well compared to other widely used toolkits [
36].
Term Frequency–Inverse Document Frequency (TF–IDF) is a widely used technique in NLP for vectorizing text data. We used TF–IDF as a measure that reflects the importance of a word in a document or corpus by considering both its frequency in the document and its rarity in the corpus. We computed the TF–IDF score by multiplying the term frequency (TF) of a word in a statement by the inverse statement frequency (IDF) of the word in the whole corpus. In this way, we used TF–IDF to extract features from text data that we can then use in ML models.
4.4. Classification Models
In this paper, we used two versions of our constructed data set to carry out the experiments. The first version, the content-based data set (CO-DS), contained the attributes topic, author name, affiliation, and source name along with the content of each statement. The second version, the context-based data set (CX-DS), contained the same attributes plus the context of each statement. Two experiments were proposed to assess the impact of these two features: a content-based approach and a context-based approach.
In each experiment, we applied two text data augmentation techniques (BT and EDA) on the initial training data to generate corresponding synthetic records, which were then added to the initial training data to construct a new set of augmented training data. The initial training data set was obtained by splitting the original data sets (CO-DS, CX-DS) into 80% training data and 20% test data.
Following completion of the augmentation process, each experiment received three sets of training material data. The first was free of augmented data. The second was generated using the BT data augmentation technique on the initial training data set. The third was from the initial training data set but was constructed using the EDA technique.
The next step was to train our models on the augmented data sets. The models were trained using traditional Scikit-learn [
26] classification approaches, such as an Extra Trees Classifier, which randomly selects attributes and cut points when creating a tree [
37], a Random Forest Classifier, which uses the perturb-and-combine technique with decision trees [
38], a Logistic Regression Classifier, which uses a logistic function for classification [
39], and a Support Vector Machine (C-Support Vector Classification), which uses LIBSVM for classification [
40].
We selected these models based on the state-of-the-art literature [
41,
42] in the field of fake news detection and the most popular machine learning algorithms. We searched for models that consistently showed positive results in fake news detection tasks implemented in non-English languages [
11,
12,
13,
14,
24]. Moreover, the Extra Trees Classifier and the Random Forest Classifier are popular approaches that have been applied to many text-based tasks, while Support Vector Machines and Logistic Regression are two of the most widely used supervised learning models.
We employed the models we received to make predictions with test data. Subsequently, we computed and utilized metrics such as accuracy, precision, recall, the F1 score, the area under the curve, and Cohen’s kappa score to assess the models’ performance.
5. Results and Discussion
This research provides two approaches for the detection of fake news based on the content and context features found in the Factual.ro data set. The data set consisted of statements from Romanian political actors that were validated and labeled by the Factual.ro team. Four well-known algorithms, the Extra Trees Classifier, the Random Forest Classifier, the Support Vector Machine, and Logistic Regression, were used for comparative analysis. The results were measured for accuracy (Acc), precision (Pre), recall (Rec), F1 score (F1), the area under the curve (AUC), and Cohen’s kappa score (Kappa). We compared the performance of our models with and without data augmentation. We report the outcome of the two different approaches in
Table 6 and
Table 7.
Based on the data of our content-based approach, accuracy, precision, F1 score, and Kappa were all highest when using an Extra Trees Classifier model, with or without data augmentation. The Random Forest Classifier had a high recall score when BT was used as a data augmentation technique, while it achieved a high AUC score without data augmentation. The Support Vector Machine performed well in terms of recall, both without augmentation and when augmented with EDA. The Logistic Regression performed relatively poorly across all columns. The complexity of the problem and the nature of the data could be contributing factors to this.
With an accuracy of 0.8065, a precision of 0.8269, an F1 score of 0.8065, and a Kappa of 0.6074, the Extra Trees Classifier model with BT yielded the best results. Furthermore, AUC scores were highest when using the combination of the Extra Trees Classifier with BT and EDA.
The data also reveal that Logistic Regression models achieved the lowest accuracy, precision, F1 score, AUC, and Kappa for both augmentation types, regardless of whether it was EDA or BT.
Grouped by augmentation type, the BT augmentation performed better than no augmentation or EDA for the four classification models. With the application of BT, the average accuracy score was 0.7782, which was 0.0229 points higher than the EDA result and 0.0699 points higher than the result of no augmentation. This indicates that BT is a very effective technique for improving accuracy scores and can be used to increase the performance of an ML model.
Analyzing the results of the context-based experiment across all models, the Random Forest Classifier with BT achieved the highest overall performance. In this case, the accuracy (0.8118), recall (0.8750), F1 score (0.8103), and the Kappa (0.6138) are the highest. This model was followed by the Extra Trees Classifier with BT, which achieved an accuracy of 0.7903, and an impressive AUC score of 0.8773.
An improvement in accuracy is evident when comparing the models with and without augmentation; the Random Forest Classifier and Logistic Regression models using BT achieved accuracies of 0.8118 and 0.7796, respectively, while the same models without augmentation had accuracies of 0.6828 and 0.6613, respectively.
In general, enhancements can have a significant impact on the performance of fake news detection models in the Romanian language. BT augmentation achieved the highest overall performance across all models. On the other hand, if we consider models that were trained on data without augmentation, the Extra Trees Classifier achieved the highest performance of all models, while the Logistic Regression model achieved the lowest performance.
Analysis of AUC scores for classification models used to detect fake news in the Factual.ro data set has shown that data augmentation (BT and EDA) has led to an increase in AUC scores for all models in both content-based and context-based data sets (
Figure 4). Especially notable is the improvement in the Extra Trees Classifier AUC score in context-based data sets, which increased from 0.8214 to 0.8773. This finding is consistent with the existing literature [
43,
44], which has established the effectiveness of incorporating context-based features into ML models for the detection of fake news.
Our results show that BT augmentation is more effective than EDA in improving the accuracy scores of our fake news detection models in the Romanian language. We believe that the better results of BT compared to EDA are because BT augmentation preserves more of the semantics and structure of the original data compared to EDA, which is a more random approach. The BT technique translates text data into different languages and then back again. This creates additional data with different words from the original text, while keeping the same context and meaning [
5]. EDA breaks down a given sample into its tokens, analyzing each one independently [
45], without considering the overall structure, which could lead to the loss of important context.
Data augmentation can help models better recognize patterns in the data and better generalize to new data. In the case of fake news detection, data augmentation can aid models in detecting the subtle differences between real and fake news by providing them with a wider range of examples. Furthermore, data augmentation techniques have been found to improve the performance of fake news detection models in the Romanian language.
6. Conclusions
Our study achieved its objectives, as it provided an extensive analysis of the performance of different text data augmentation methods when applied to fake news detection in the Romanian language. Data augmentation methods demonstrated their efficiency in improving the detection of fake news in the Romanian language. The results indicate that the implementation of the BT technique and EDA successfully enhanced the performance of the classical ML algorithms employed in our study.
We found that the BT technique led to better performance in all four classification models compared to both EDA augmentation and no augmentation. In our content-based approach, the BT scored an average accuracy of 0.7782, which was 0.0229 higher than the EDA and 0.0699 higher than with no augmentation. Furthermore, in the context-based approach, with the application of BT, we found that the average accuracy score was 0.7903, which was 0.0201 points better than the EDA result and 0.094 points better than the result of no augmentation.
Regarding the performance of the model when incorporating the contextual information of the political statements alongside the context itself, it can be observed that the contextual information did not significantly overcome the performance achieved by considering only the political statement. However, further evaluation is required to map the potential influence of incorporating context information during the classification task. The context refers to additional information and explanations from the journalist, with no additional information from the author of the statement. Taking this into account, the context does not include any text patterns or language patterns that can outline key linguistic information for fraudulent expressions. This aspect regarding context information does not contribute any value towards the classifiers’ training process and implicitly affects the capacity of the models to accurately identify and predict the correct labels.
For future work, given the promising results that generative transformers demonstrate across various tasks, we aim to investigate the effectiveness of transformer-based approaches in the text data augmentation process specifically in the Romanian language. Our future goal is to address the limitations encountered in supervised learning tasks and enrich the Romanian text data sets with generative language models by generating text samples for certain class labels. Taking advantage of robust generative models and their versatility, we hope to overcome common NLP challenges encountered in Romanian text data, including imbalanced output classes, limited data set sizes, and limited availability of resources for Romanian data sets.








{kind=link}
{kind=link}
{kind=link}
{kind=link}