
Attention-Based Mechanisms for Cognitive Reinforcement Learning

Abstract
:1. Introduction
2. Research on Multi-Intelligence Reinforcement Learning Methods
2.1. Application of Reinforcement Learning to Multi-Intelligent Collaboration
2.2. Deep Reinforcement Learning for Multi-Intelligence Collaboration
2.3. Cognitive Learning in Multi-Intelligence Collaboration
- I.
- The Concept of Cognitive Learning
- II.
- Application Scenarios of Cognitive Learning in MAC
3. Attention-Enhanced Cognitive Reinforcement Learning (CRL-CBAM)
3.1. Cognitive Learning
3.2. A Mathematical Framework for Attention-Enhancing Cognitive Reinforcement Learning
4. Attention-Enhancing Cognitive Reinforcement Learning Algorithms
5. Experiment
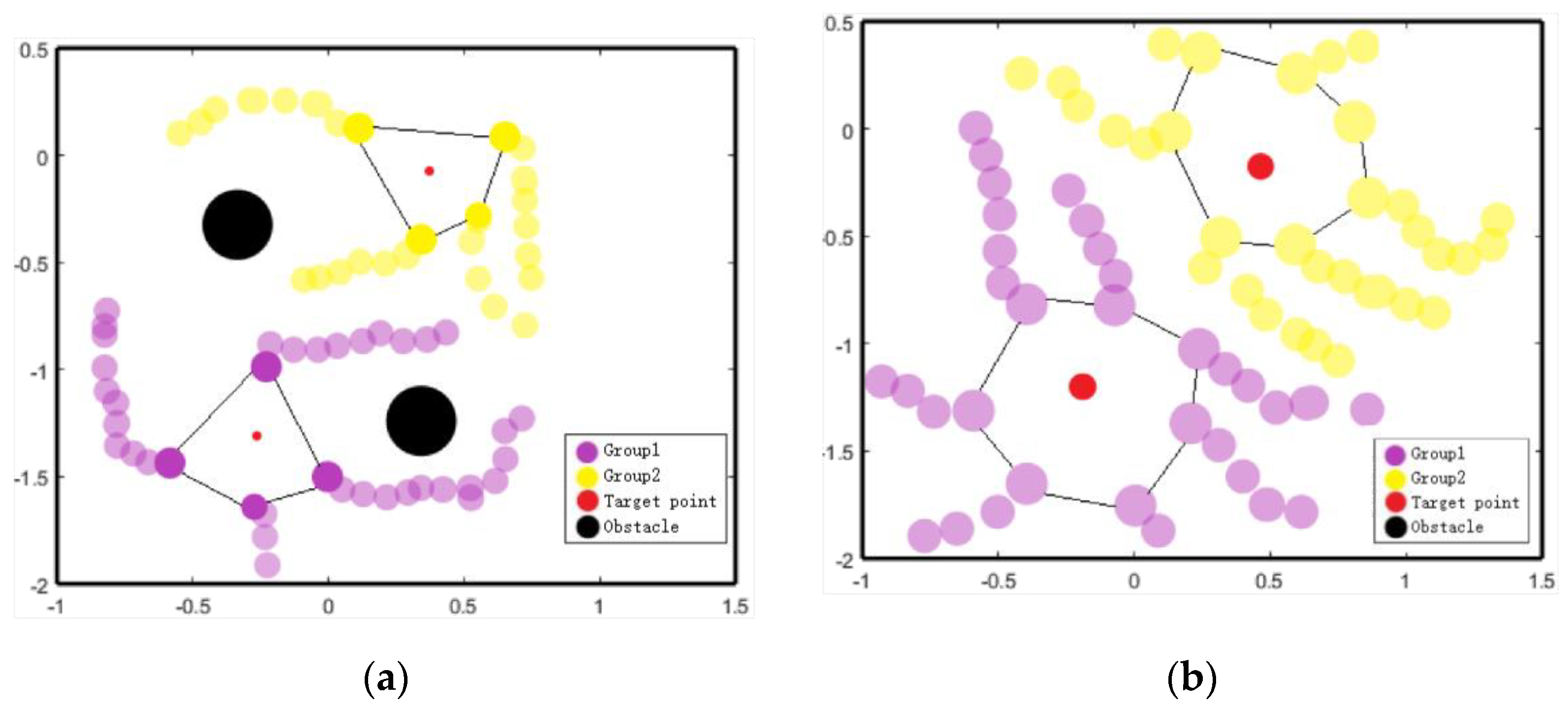
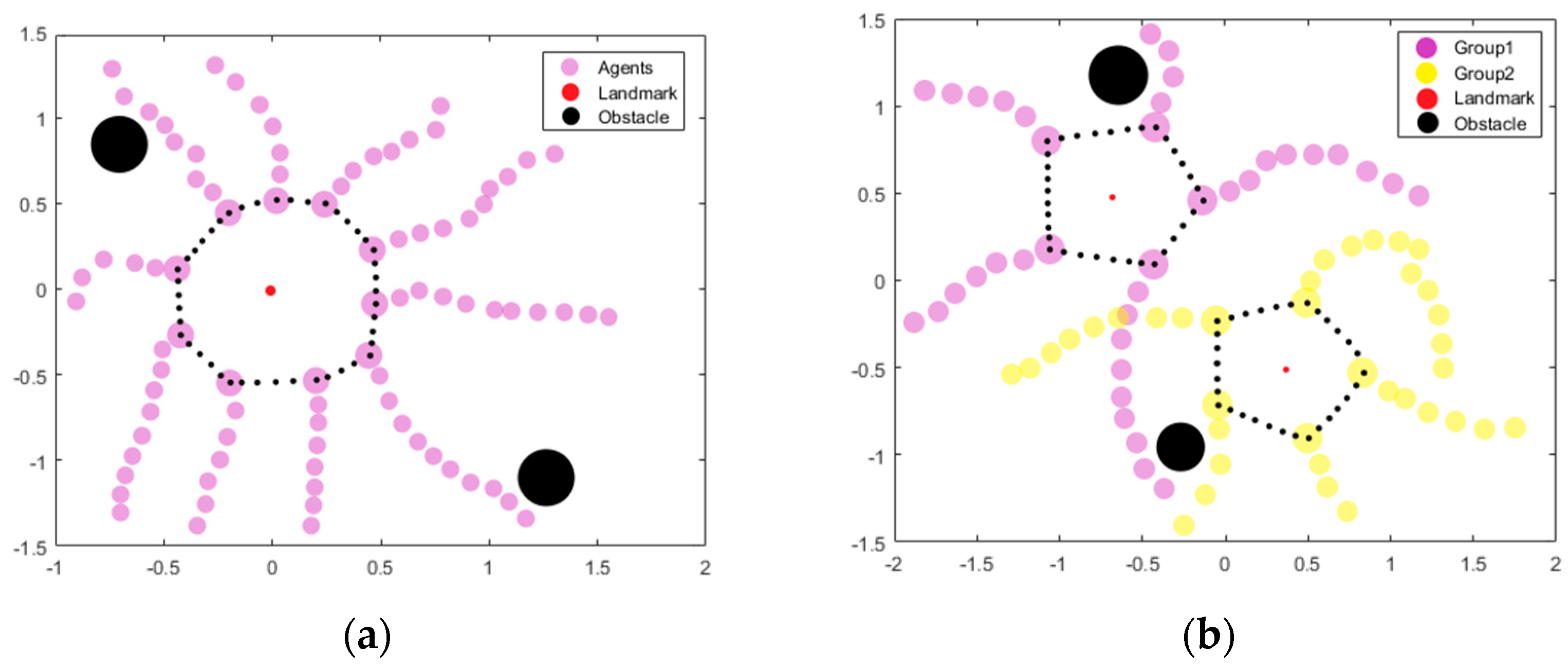
5.1. Formation Control
5.2. Group Containment
5.3. Robustness of CRL-CBAM
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.I.; Abbeel, P. Trust Region Policy Optimization. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1889–1897. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Hassabis, D. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.P.; Kearns, M.J.; Mansour, Y. Nash convergence of gradient dynamics in general-sum games. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial, Stanford, CA, USA, 30 June–3 July 2000. [Google Scholar]
- Hu, J.; Wellman, M.P. Multiagent Reinforcement Learning: Theoretical Framework and an Algorithm; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1999. [Google Scholar]
- Lauer, M.; Riedmiller, M. An Algorithm for Distributed Reinforcement Learning in Cooperative Multi-Agent Systems; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2000. [Google Scholar]
- Littman, M.L. Value-function reinforcement learning in Markov games. Cogn. Syst. Res. 2001, 2, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Anastasios, G.; Sotirios, S.; Nikolaos, K.; Panagiotis, K.; Panagiotis, T. Deep Reinforcement Learning for Energy-Efficient Multi-Channel Transmissions in 5G Cognitive HetNets: Centralized, Decentralized and Transfer Learning Based Solutions. IEEE ACCESS 2021, 9, 129358–129374. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Coles, M. Formats: The Neural Basis of Human Error Processing: Reinforcement Learning, Dopamine, and the Error-Related Negativity. Psychol. Rev. 2002, 109, 679. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, Multi-Agent, Reinforcement Learning for Autonomous Driving. arXiv 2016, arXiv:1610.03295. [Google Scholar]
- Wang, X.; Sandholm, T. Reinforcement Learning to Play an Optimal Nash Equilibrium in Team Markov Games. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002. [Google Scholar]
- Tesauro, G. Extending Q-Learning to General Adaptive Multi-Agent Systems. In Proceedings of the Advances in Neural Information Processing Systems 16, Neural Information Processing Systems, NIPS 2003, Vancouver, BC, Canada, 8–13 December 2003. [Google Scholar]
- Bowling, M.H. Convergence and No-Regret in Multiagent Learning. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2004. [Google Scholar]
- Liu, D.K.; Wang, D.; Dissanayake, G. A Force Field Method Based Multi-Robot Collaboration. In Proceedings of the Robotics, Automation and Mechatronics, Bangkok, Thailand, 1–3 June 2006. [Google Scholar]
- Etesami, S.R. Optimal versus Nash Equilibrium Computation for Networked Resource Allocation. arXiv 2014, arXiv:1404.3442. [Google Scholar]
- Li, H.; Kumar, N.; Chen, R.; Georgiou, P. Deep Reinforcement Learning. In Proceedings of the ICASSP 2018—2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Hüttenrauch, M.; Šošić, A.; Neumann, G. Learning Complex Swarm Behaviors by Exploiting Local Communication Protocols with Deep Reinforcement Learning. arXiv 2017, arXiv:1709.07224. [Google Scholar]
- Mohsin, S.; Zaka, F. A New Approach to Modeling Cognitive Information Learning Process using Neural Networks. In Proceedings of the International Conference on Artificial Intelligence (ICAI), Las Vegas, NV, USA, 16–19 July 2012. [Google Scholar]
- Wu, Q.; Ruan, T.; Zhou, F.; Huang, Y.; Xu, F.; Zhao, S.; Liu, Y.; Huang, X. A Unified Cognitive Learning Framework for Adapting to Dynamic Environment and Tasks. IEEE Wirel. Commun. 2021, 18, 208–216. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Wang, H.; Pu, Z.; Liu, Z.; Yi, J.; Qiu, T. A Soft Graph Attention Reinforcement Learning for Multi-Agent Cooperation. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Agarwal, A.; Kumar, S.; Sycara, K.P.; Lewis, M.J. Learning Transferable Cooperative Behavior in Multi-Agent Teams. arXiv 2020, arXiv:1906.01202. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Online process | 1. Perceive the external environment and the task; |
| 2. Extraction of the external environment and task features; | |
| 3. Selecting algorithms and hyperparameters; | |
| 4. Invoke; | |
| 5. Produce results. | |
| Self-learning process | 1. Store current learning results in the library; |
| 2. Sampling cognitive cases; | |
| 3. Selecting algorithms and hyperparameters; | |
| 4. Call the algorithm and hyperparameters; | |
| 5. Get learning results; | |
| 6. Recall historical learning results for the same case; | |
| 7. Compare the better results and save them; | |
| 8. Update the case library and retrain. |
| Method | N = 8 | N = 14 | ||||
|---|---|---|---|---|---|---|
| Steps | Success Rate | Rewards | Steps | Success Rate | Rewards | |
| CRL-CBAM | 13.8 | 100 | −0.49 | 13.1 | 100 | −0.62 |
| MADDPG | 80.21 | 0 | −1.58 | 80 | 0 | −4.62 |
| R-MADDPG | 31.07 | 70 | −0.94 | 80 | 0 | −2.9 |
| TRANSFER | 17.7 | 95 | −0.67 | 14.58 | 87 | −0.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Li, D.; Chen, X.; Zhu, J. Attention-Based Mechanisms for Cognitive Reinforcement Learning. Appl. Sci. 2023, 13, 7361. https://doi.org/10.3390/app13137361
Gao Y, Li D, Chen X, Zhu J. Attention-Based Mechanisms for Cognitive Reinforcement Learning. Applied Sciences. 2023; 13(13):7361. https://doi.org/10.3390/app13137361
Chicago/Turabian StyleGao, Yue, Di Li, Xiangjian Chen, and Junwu Zhu. 2023. "Attention-Based Mechanisms for Cognitive Reinforcement Learning" Applied Sciences 13, no. 13: 7361. https://doi.org/10.3390/app13137361
APA StyleGao, Y., Li, D., Chen, X., & Zhu, J. (2023). Attention-Based Mechanisms for Cognitive Reinforcement Learning. Applied Sciences, 13(13), 7361. https://doi.org/10.3390/app13137361