
Performance Analysis of University Collaborative Innovation Center Based on BPNN-Dominated K-Means–Random Forest Unsupervised Factor Importance Analysis Model

Abstract
1. Introduction
2. Material and Methods
2.1. Building an Evaluation Index System for the Construction of Universities’ Collaborative Innovation Center
2.2. Unsupervised Factor Importance Analysis Model for the Construction of Universities’ Collaborative Innovation Centers
2.2.1. Data Preprocessing Based on BPNN
Principles of Neural Network and BPNN
Optimize Data Validity Using the BPNN Training Model
2.2.2. K-Means and K-Means++ Clustering Algorithms
K-Means Algorithm
- Randomly select k centroids in .
- Calculate the distance from to each centroid , select the centroid with the minimum distance from to each centroid, and update the cluster .
- Calculate the mean within each cluster and update the centroids.
- Repeat steps 2 and 3 to obtain the cluster .
K-Means++ Algorithm
- Randomly choose an initial centroid .
- Calculate the minimum distance from to the selected centroid.
- Select the next centroid according to the probability; the sample with larger has a greater probability of being selected.
- Repeat steps 2 and 3 until k centroids are selected.
Method for Determining Cluster Number K
- For of cluster , calculate the dissimilarity within the cluster:
- 2.
- Calculate the inter-cluster dissimilarity of of the cluster :
- 3.
- Calculate the silhouette coefficient of :
- 4.
- The average of the silhouette coefficients of all samples is calculated as the silhouette coefficient of the clustering result. A larger silhouette coefficient of the clustering result indicates a more reasonable clustering result.
2.2.3. Random Forest Algorithm
Decision Tree
Random Forest
- Let N represent the number of training cases (samples), and M represent the number of features. The number of input features m is used to determine the decision result of a node on the decision tree, where m should be much smaller than M.
- From the N training samples in the way of sampling with replacement, sampling N times to form a training set, and using the unsampled samples as predictions to evaluate the error.
- For each node, m features are randomly selected, and the decision of each node on the decision tree is determined based on these features. According to the m features, calculate the optimal splitting method.
- Each tree grows fully without pruning.
Feature Importance Evaluation Based on Random Forest Algorithm
- First train a random forest classifier and calculate .
- Apply random perturbation to the ith feature, that is, , where .
- Train a random forest classifier and calculate .
|
| Input: Sample data and evaluation indicators. Output: Evaluate the importance results of each feature. |
|
2.2.4. Major Limitations of the Model and Wider Applicability
Major Limitations of the Model
The Wide Applicability of the Model
3. Results and Discussion
3.1. Data Source and Preprocessing
3.2. Unsupervised Data Clustering with K-Means++
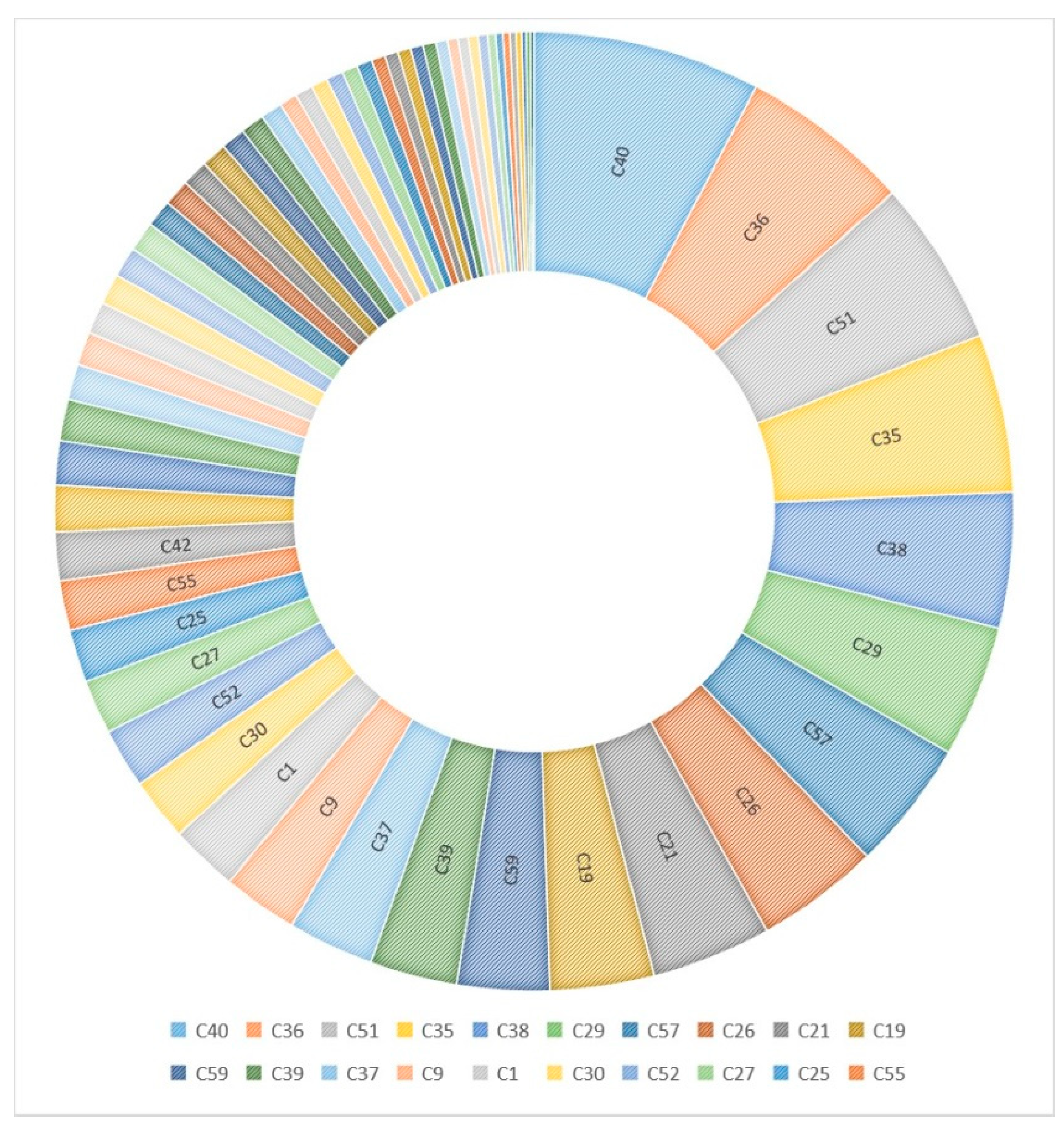
3.3. Random Forest Algorithm Feature Importance Analysis
3.4. Analysis of the Construction of Universities’ Collaborative Innovation Center in Jiangsu
- Scientific research innovation and output are important first-level indicators for evaluating collaborative innovation centers. The results of the analysis indicate that the significance levels of multiple three-level indicators based on this indicator are relatively high. In particular, all the third-level indicators under the second-level indicators of scientific research projects are higher than the average level. These findings suggest that in the later construction process, the collaborative innovation center should further improve the quantity and quality of scientific research projects. Moreover, the government should continue to promote research and development as well as provide financial support for the project. In addition, the importance of the scientific research awards of the leading universities is relatively high, indicating that these universities should maintain their leading role, ensure collaborative work with the member universities, and continue to produce high-quality output. This output should constitute not only academic papers but also independent intellectual property rights.
- Funding input and output are crucial to the operation of any collaborative innovation center. The support of industries and local governments constitutes an important funding source. To ensure the development of an innovative country, industries and local governments should establish a reasonable funding scale and cycle for the project based on current reality. Additionally, they should strengthen the macro-control of the project discipline layout. It is essential to provide guidance for the unpopular, weak, and “shrinking” disciplines and areas that are significant in the context of long-term economic and social development. For the collaborative innovation center, establishing a long-term mechanism and a relatively clear policy funding period scheme can create a stable and predictable environment, which is more conducive to the strategic design of collaborative innovation and the selection of a long-term roadmap.
- In terms of talent training and team building, each collaborative innovation center should pay attention to the talent plan at the provincial, ministerial, and higher levels, as well as focus on the talents that are the source of continuous innovation within the collaborative innovation center. This is because the essence of the collaborative innovation drive is talent. Each collaborative innovation center should take responsibility for the introduction and cultivation of talents, break the constraints of the original system, continuously enhance the vitality and competitiveness of the center in terms of scientific research, condense the research direction, and form a high-level team.
- A modern university collaborative innovation center should have an international vision. Aiming for high-level results on an international scale can improve the quality and global recognition of the research at the collaborative innovation center. Moreover, actively organizing and conducting major international collaborative research projects and obtaining advanced experience through exchange programs can further improve the quality of the collaborative innovation center.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lohman, L. Evaluation of university teaching as sound performance appraisal. Stud. Educ. Eval. 2021, 70, 101008. [Google Scholar] [CrossRef]
- Morley, M.J.; Murphy, K.R.; Cleveland, J.N.; Heraty, N.; McCarthy, J. Home and host distal context and performance appraisal in multinational enterprises: A 22 country study. Hum. Resour. Manag. 2021, 60, 715–736. [Google Scholar] [CrossRef]
- Ullah, Z.; Alvarez-Otero, S.; Sulaiman, M.A.; Bait, A.; Sial, M.S.; Ahmad, N.; Scholz, M.; Omhand, K. Achieving organizational social sustainability through electronic performance appraisal systems: The moderating influence of transformational leadership. Sustainability 2021, 13, 5611. [Google Scholar] [CrossRef]
- Chang, D.Y. Applications of the extent analysis method on fuzzy AHP. Eur. J. Oper. Res. 1996, 95, 649–655. [Google Scholar] [CrossRef]
- Fashoto, S.G.; Amaonwu, O.; Afolorunsho, A. Development of A Decision Support System on Employee Performance Appraisal using AHP Model. JOIV: Int. J. Inform. Vis. 2018, 2, 262–267. [Google Scholar] [CrossRef]
- Pohan, A.B.; Hadi, S.W.; Rahmatullah, S.; Zuama, R.A.; Rifai, A.; Gunawan, D. Employee Performance Apparaisal Using Decision Support System by AHP and TOPSIS Methods. J. Tek. Komput. 2021, 7, 100–105. [Google Scholar] [CrossRef]
- Rajabpour, E.; Mohammad, R.F.; Mohsen, T. Analysis of factors affecting the implementation of green human resource management using a hybrid fuzzy AHP and type-2 fuzzy DEMATEL approach. Environ. Sci. Pollut. Res. 2022, 29, 48720–48735. [Google Scholar] [CrossRef] [PubMed]
- Anowar, F.; Samira, S.; Bassant, S. Conceptual and empirical comparison of dimensionality reduction algorithms (pca, kpca, lda, mds, svd, lle, isomap, le, ica, t-sne). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Lv, J. Research on the Construction of Scientific Research Evaluation System for Teachers in Higher Vocational Colleges Based on Computer PCA and ANP. In Proceedings of the EAI International Conference, Virtual Event, 1–3 August 2021; pp. 327–335. [Google Scholar]
- Wu, T.; Chung, Y.F.; Huang, S.W. Evaluating global energy security performances using an integrated PCA/DEA-AR technique. Sustain. Energy Technol. Assess. 2021, 45, 101041. [Google Scholar] [CrossRef]
- Kumar, A.; Pant, S. Analytical hierarchy process for sustainable agriculture: An overview. MethodsX 2022, 10, 101954. [Google Scholar] [CrossRef] [PubMed]
- Rawat, S.S.; Pant, S.; Kumar, A.; Ram, M.; Sharma, H.K.; Kumar, A. A State-of-the-Art Survey on Ana-lytical Hierarchy Process Applications in Sustainable Development. Int. J. Math. Eng. Manag. Serv 2022, 7, 883–917. [Google Scholar]
- Cui, X.Y.; Zhao, T.; Wang, J. Allocation of carbon emission quotas in China’s provincial power sector based on entropy method and ZSG-DEA. J. Clean. Prod. 2021, 284, 124683. [Google Scholar] [CrossRef]
- Archer, B.B.; Tetteh, A. Can entropy and TOPSIS be used to analyse personnel effectiveness appraisal scheme in an organization? Int. J. Decis. Sci. 2021, 10, 78–92. [Google Scholar]
- Chen, D.; Xiang, P.C.; Jia, F.Y. Performance Measurement of Operation and Maintenance for Infrastructure Mega-Project Based on Entropy Method and DS Evidence Theory. Ain Shams Eng. J. 2022, 13, 101591. [Google Scholar] [CrossRef]
- Feng, L.; Li, W.; Zhao, L.; Yang, Y.; Zhang, W.; Liu, Y.J.; Li, M.Y. Investment Performance Model of Regional Power Grid Based on Entropy Weight Fuzzy Comprehensive Evaluation. In Innovative Computing; Springer: Singapore, 2022; pp. 1275–1287. [Google Scholar]
- Zhong, K.Y.; Wang, Y.F.; Pei, J.M.; Tang, S.M.; Han, Z.L. Super efficiency SBM-DEA and neural network for performance evaluation. Inf. Process. Manag. 2021, 58, 102728. [Google Scholar] [CrossRef]
- Deng, W.J.; Chen, W.C.; Pei, W. Back-propagation neural network based importance-performance analysis for determining critical service attributes. Expert Syst. Appl. 2008, 34, 1115–1125. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding; Stanford University: Santa Clara, CA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. A J. Chemom. Soc. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First-Level Indicators | Second-Level Indicators | Third-Level Indicators |
|---|---|---|
| A1: Operation and Guarantee | B1: Employee | C1: Total number |
| C2: Full-time | ||
| C3: Part-time and double employment | ||
| C4: Visiting and mobile | ||
| C5: Academicians | ||
| C6: Yangtze River scholars | ||
| C7: Distinguished youths | ||
| C8: National Overseas High-Level Talent Program | ||
| C9: Talent plan for provincial, ministerial, and higher levels | ||
| B2: Condition guarantee | C10: Construction area | |
| C11: Existing provincial and ministerial level and above base platforms | ||
| C12: The number of large equipment | ||
| C13: Value of large equipment | ||
| B3: Publicity reports | C14: Provincial and ministerial level and above publicity reports | |
| C15: Jiangsu University Collaborative Innovation Program Briefing Released | ||
| A2: Funds input and expenditure | B4: Funds input | C16: Total funds input |
| C17: Provincial Special Funds | ||
| C18: National funds for education, science, and technology | ||
| C19: Industry Departments and Local Government Support Funds | ||
| C20: Enterprise Input, University Self-raising, and International Cooperation Funds | ||
| B5: Funds expenditure | C21: Total funds expenditure | |
| C22: Provincial special funds | ||
| A3: Scientific research innovation and output | B6: Research awards | C23: Winning the national scientific research achievement award |
| C24: National awards for scientific research achievements hosted by leading universities | ||
| C25: Winning the provincial and ministerial level scientific research achievement awards | ||
| C26: Provincial and ministerial scientific research achievements hosted by leading universities | ||
| B7: Academic papers | C27: International authoritative journal papers | |
| C28: Top-ranking domestic periodical papers | ||
| B8: Intellectual property | C29: Number of authorized patents | |
| C30: Patents for intentions | ||
| C31: International patents for inventions | ||
| C32: Transfer or license patents | ||
| C33: Amount of patent contract for assignment or license | ||
| C34: Lay down a criterion | ||
| B9: Research project | C35: New research projects | |
| C36: New research project funds | ||
| C37: New major research projects | ||
| C38: National research projects | ||
| C39: Provincial and ministerial research projects | ||
| C40: Total funds for research projects at or above the provincial level | ||
| B10: Base Platform | C41: New Key Research Platform | |
| C42: Research platforms for provincial, ministerial, and higher levels | ||
| A4: Social services and contributions | B11: Achievement transformation | C43: Transfer and transformation of major scientific research achievements |
| C44: Directly driving new industrial output value | ||
| B12: Social services | C45: Carrying out industrial technology training | |
| C46: Provision of think tanks for decision-making and addressing critical issues | ||
| A5: Talent Training and Team Building | B13: Training and Importing Talents | C47: Academicians |
| C48: Yangtze River scholars | ||
| C49: Distinguished youths | ||
| C50: National Overseas High-Level Talent Program | ||
| C51: Talent plan for provincial and ministerial levels and above | ||
| B14: Personnel training | C52: Train students with master’s or above degrees | |
| B15: New Innovation Team | C53: New Innovation Team | |
| C54: Innovation Teams at and above the provincial level | ||
| A6: International Cooperation and Exchange | B16: New Major International Cooperation Studies | C55: New Major International Cooperation Studies |
| B17: To host (undertake) international academic conferences | C56: To host (undertake) international academic conferences | |
| B18: New positions in international academic institutions and international academic journals | C57: Total numbers | |
| C58: New positions in international academic institutions | ||
| C59: New positions in international academic journals | ||
| B19: International exchange and mutual visits of personnel | C60: Dispatch personnel | |
| C61: Visitors |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Wang, S. Performance Analysis of University Collaborative Innovation Center Based on BPNN-Dominated K-Means–Random Forest Unsupervised Factor Importance Analysis Model. Appl. Sci. 2023, 13, 6818. https://doi.org/10.3390/app13116818
Zhang D, Wang S. Performance Analysis of University Collaborative Innovation Center Based on BPNN-Dominated K-Means–Random Forest Unsupervised Factor Importance Analysis Model. Applied Sciences. 2023; 13(11):6818. https://doi.org/10.3390/app13116818
Chicago/Turabian StyleZhang, Daopan, and Sihua Wang. 2023. "Performance Analysis of University Collaborative Innovation Center Based on BPNN-Dominated K-Means–Random Forest Unsupervised Factor Importance Analysis Model" Applied Sciences 13, no. 11: 6818. https://doi.org/10.3390/app13116818
APA StyleZhang, D., & Wang, S. (2023). Performance Analysis of University Collaborative Innovation Center Based on BPNN-Dominated K-Means–Random Forest Unsupervised Factor Importance Analysis Model. Applied Sciences, 13(11), 6818. https://doi.org/10.3390/app13116818