
The Improvement of the Honey Badger Algorithm and Its Application in the Location Problem of Logistics Centers

Abstract
:Featured Application
Abstract
1. Introduction
1.1. Current Situation of Urban Logistics Enterprises
1.2. Research Status and Significance at Home and Abroad
2. Research Status and Significance at Home and Abroad
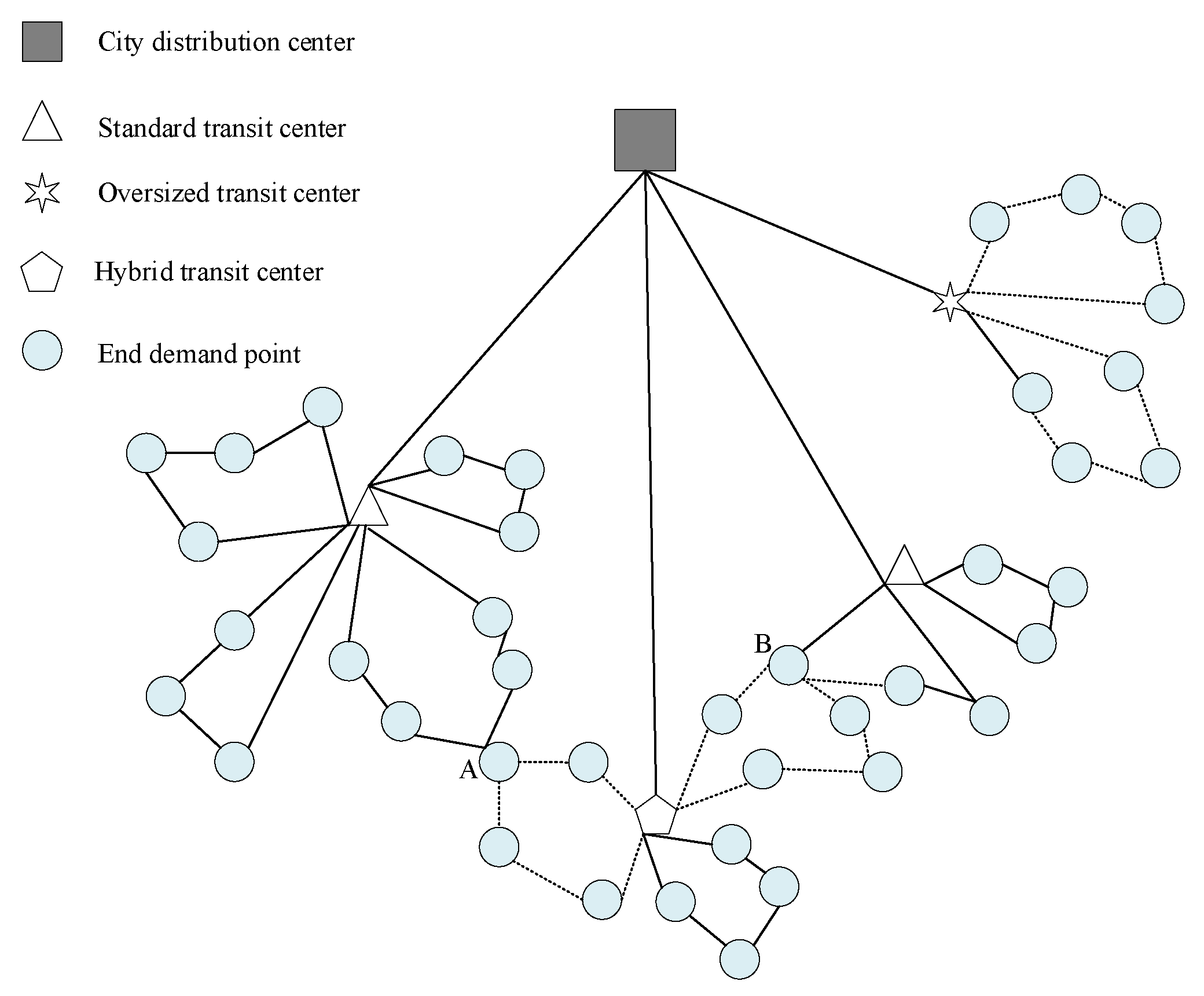
2.1. Describe the Problem
- Threshold setting for bulky parcels and standard parcels;
- The number and location of three types of transit centers: large-size, standard, and mixed;
- The coverage of transit centers of different functional types, that is, the allocation of terminal demand points.
2.2. Model Building
- Model parameters:
- Decision variables:
3. Improved Honey Badger Algorithm
3.1. Honey Badger Algorithm
3.1.1. Population Initialization Phase
3.1.2. Define the Density Factor
3.1.3. Update the Density Factor
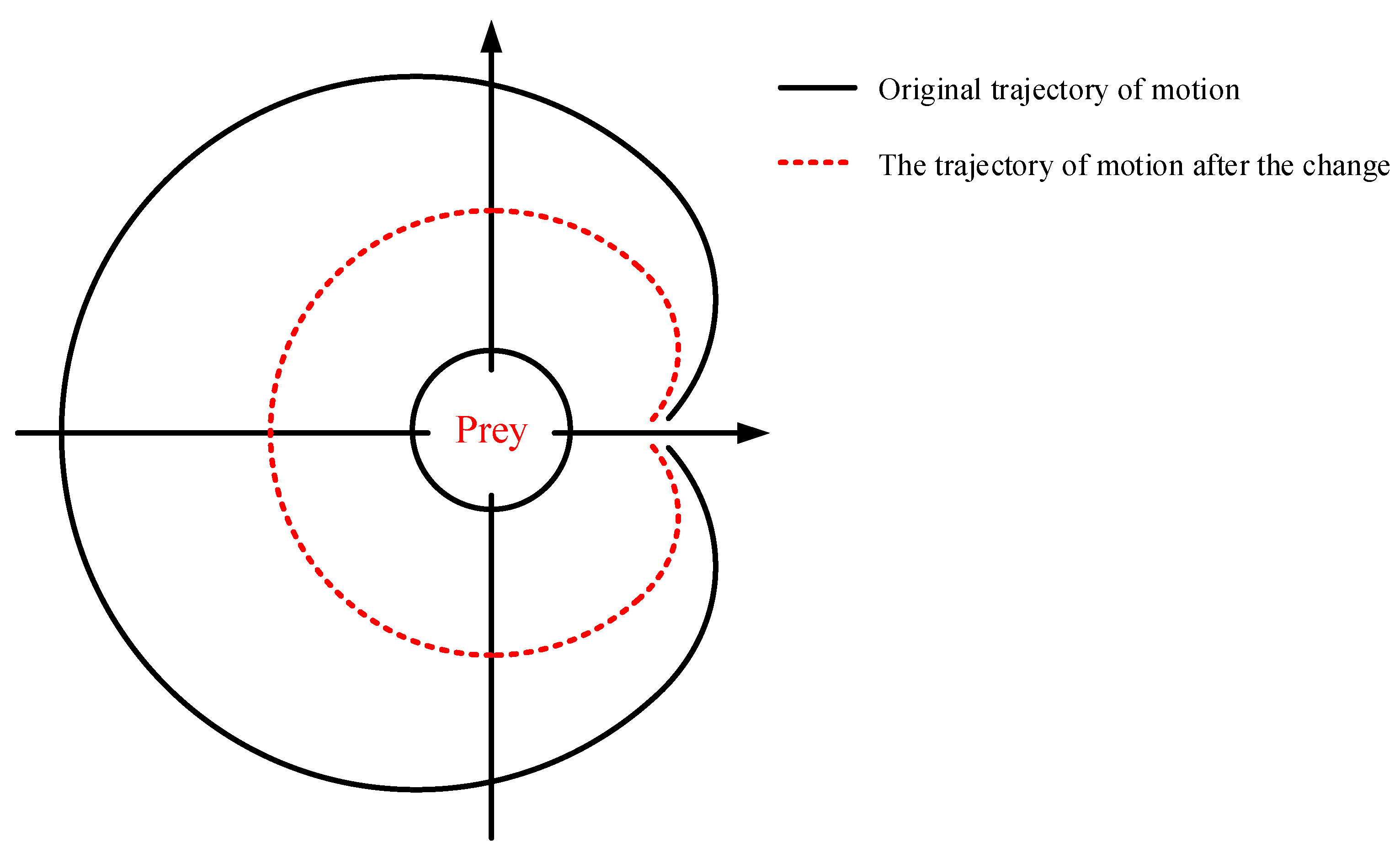
3.1.4. Jump out of the Local Optimal
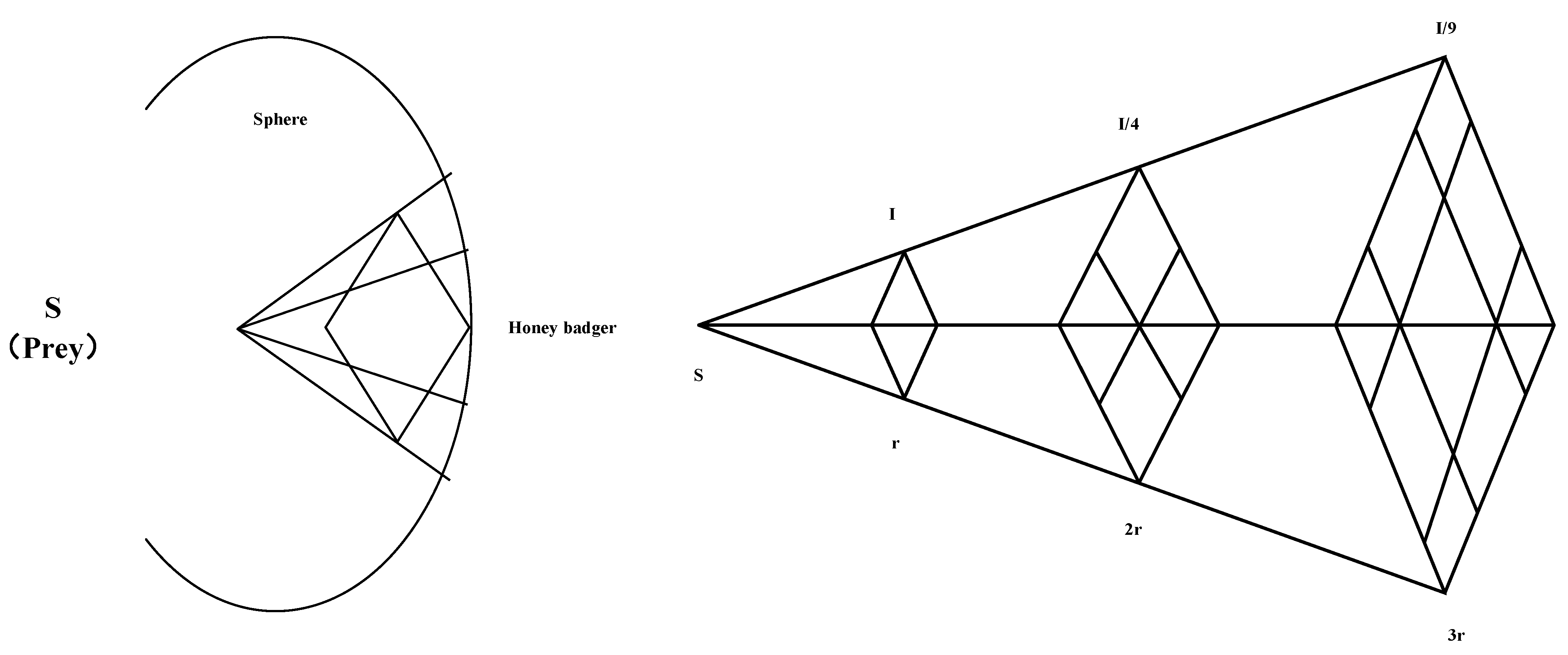
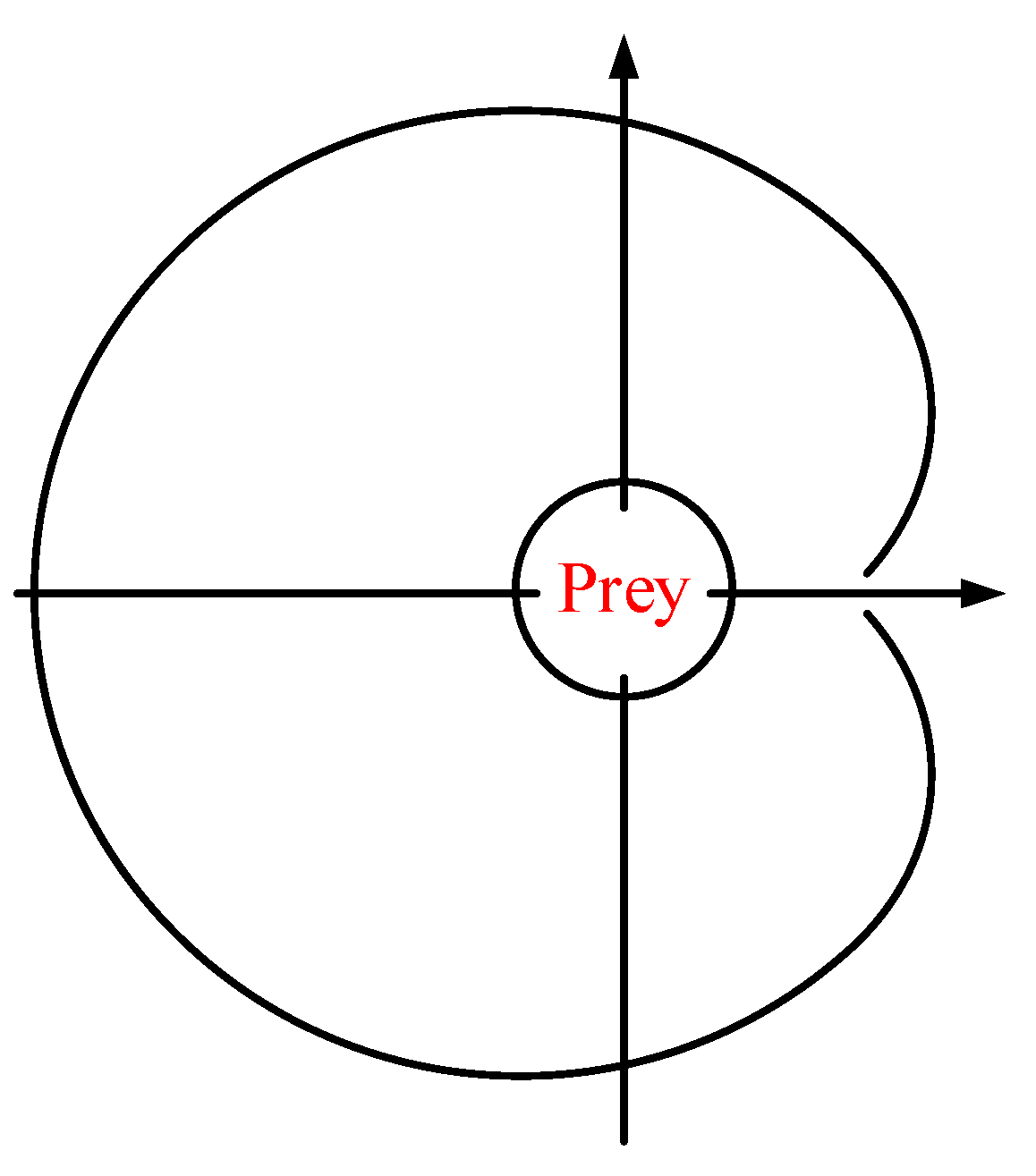
3.1.5. Excavation Phase
3.1.6. Honey Picking Stage
3.2. Improve Policies
3.2.1. Chebyshev Chaos Mapping
- Initialize the honey badger population and initialize the spatial position of the first body in -dimensional space, ;
- Equation (37) is used to change each dimension of individual from generation to generation, new until the remaining honey badger individuals are spawned.
- Further mapping to the initial location of the honey badger individual in the search space:where and are the upper and lower bounds of the search space, .
3.2.2. Mix Golden Sine with Moth-Flame Operator
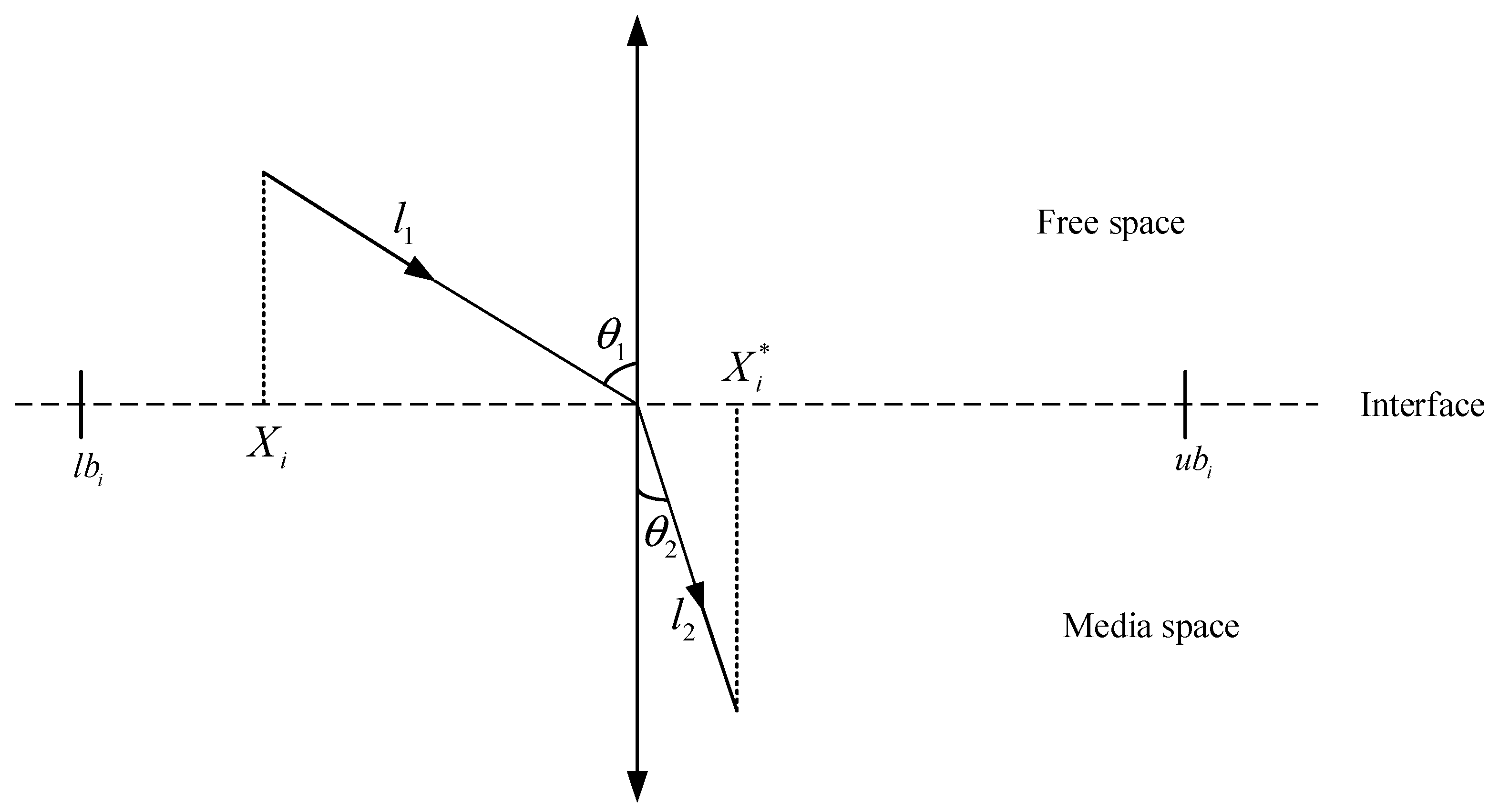
3.2.3. Refraction Mirror Learning Strategy
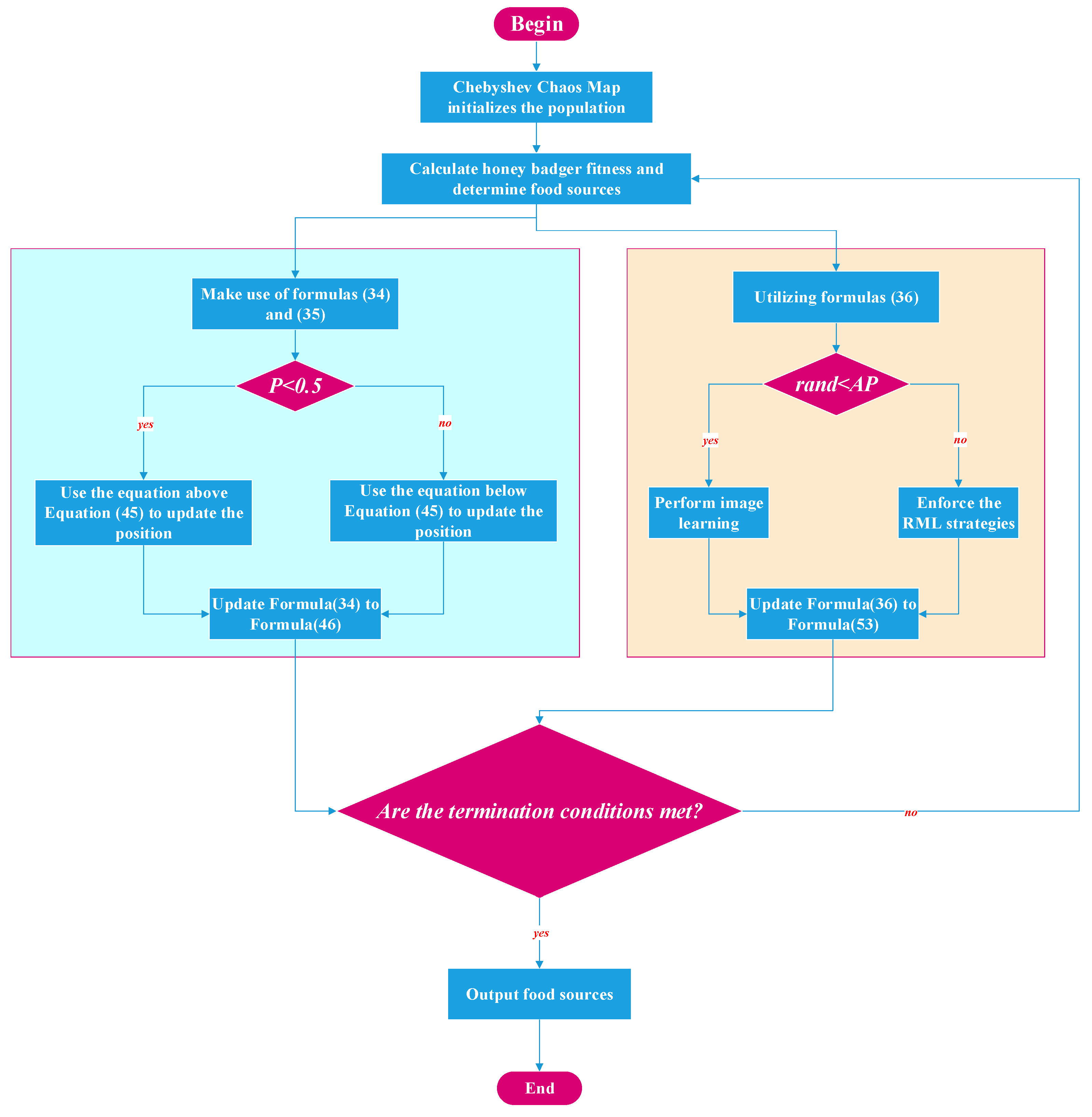
| Algorithm 1 Pseudo code of IHBA. |
| , , , , . |
| Initialize population with random positions. |
| using Chebyshev chaos mapping. |
| using objective function. |
| . |
| while do |
| Update the decreasing factor using Equation (33). |
| for i = 1 to N do |
| using Equation (32). |
| if then |
| using Equation (34). |
| if then |
| . |
| else |
| . |
| end if |
| else |
| using Equation (36). |
| if then |
| Perform image learning. |
| else |
| Enforce the RML strategies. |
| end if |
| for do |
| using Equation (53). |
| end for |
| end if |
| end for |
| end while Stop criteria satisfied. |
| Return |
3.3. Simulation Experiments and Results Analysis
3.3.1. Function Selection and Parameter Setting
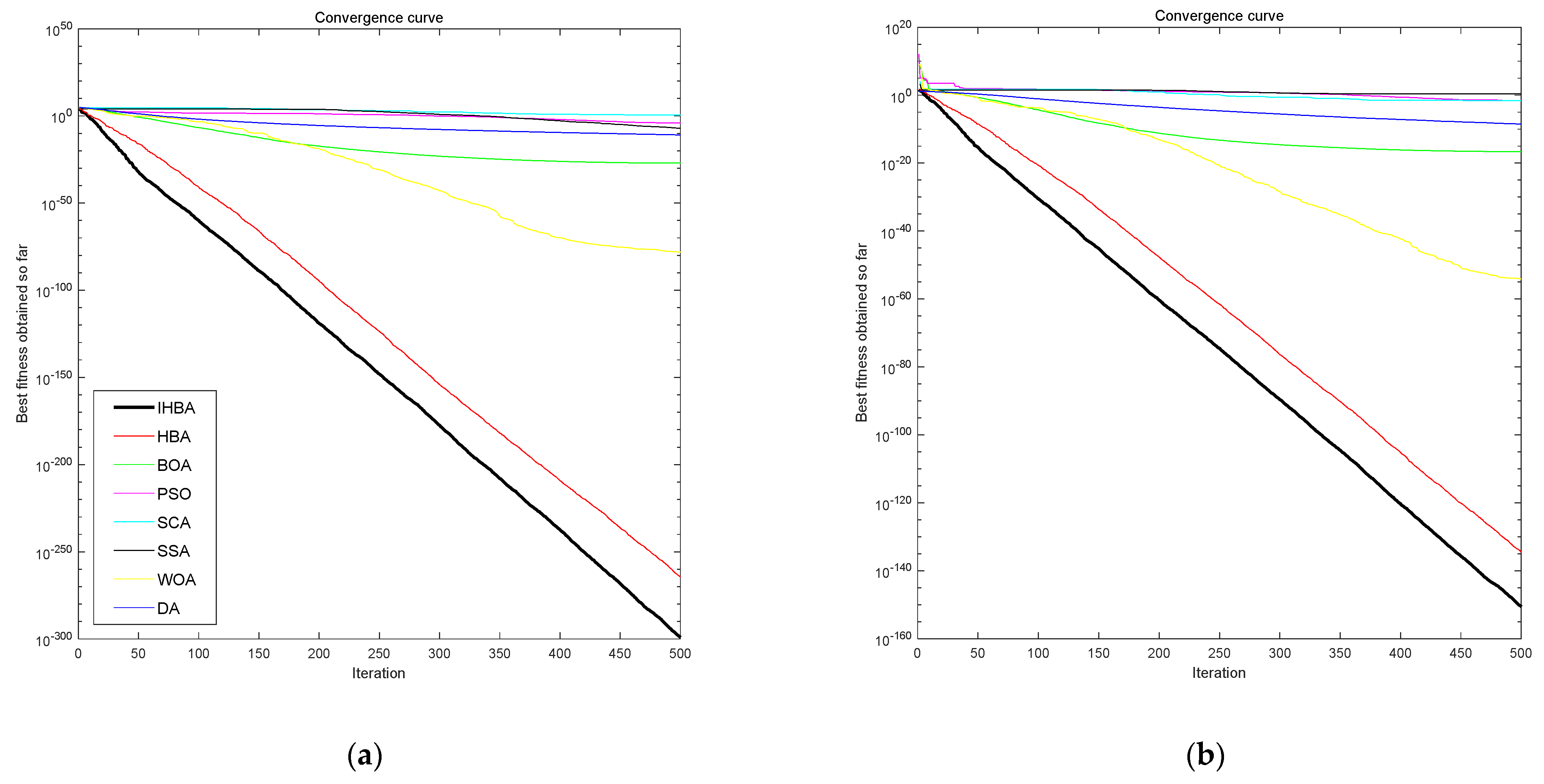
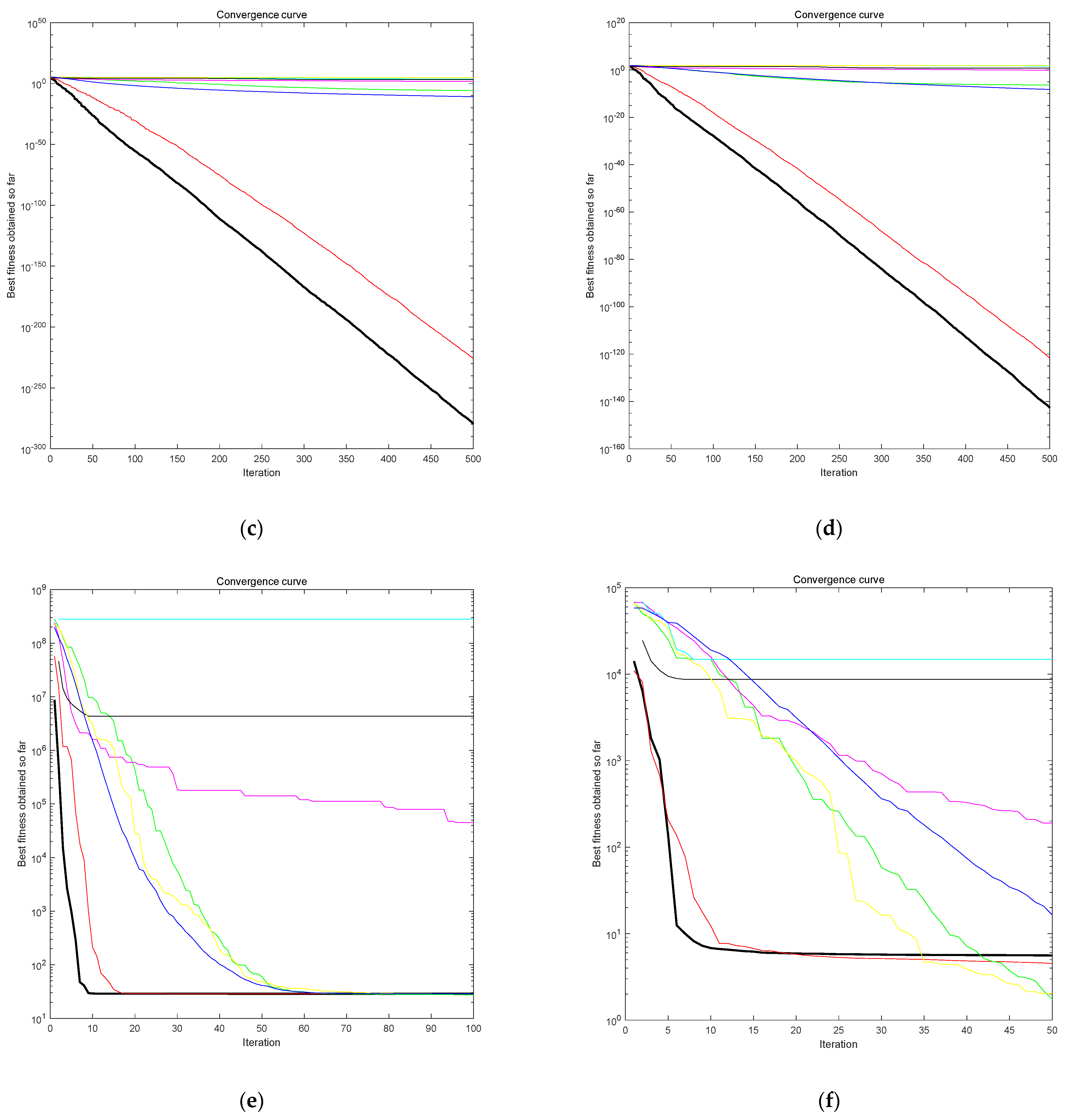
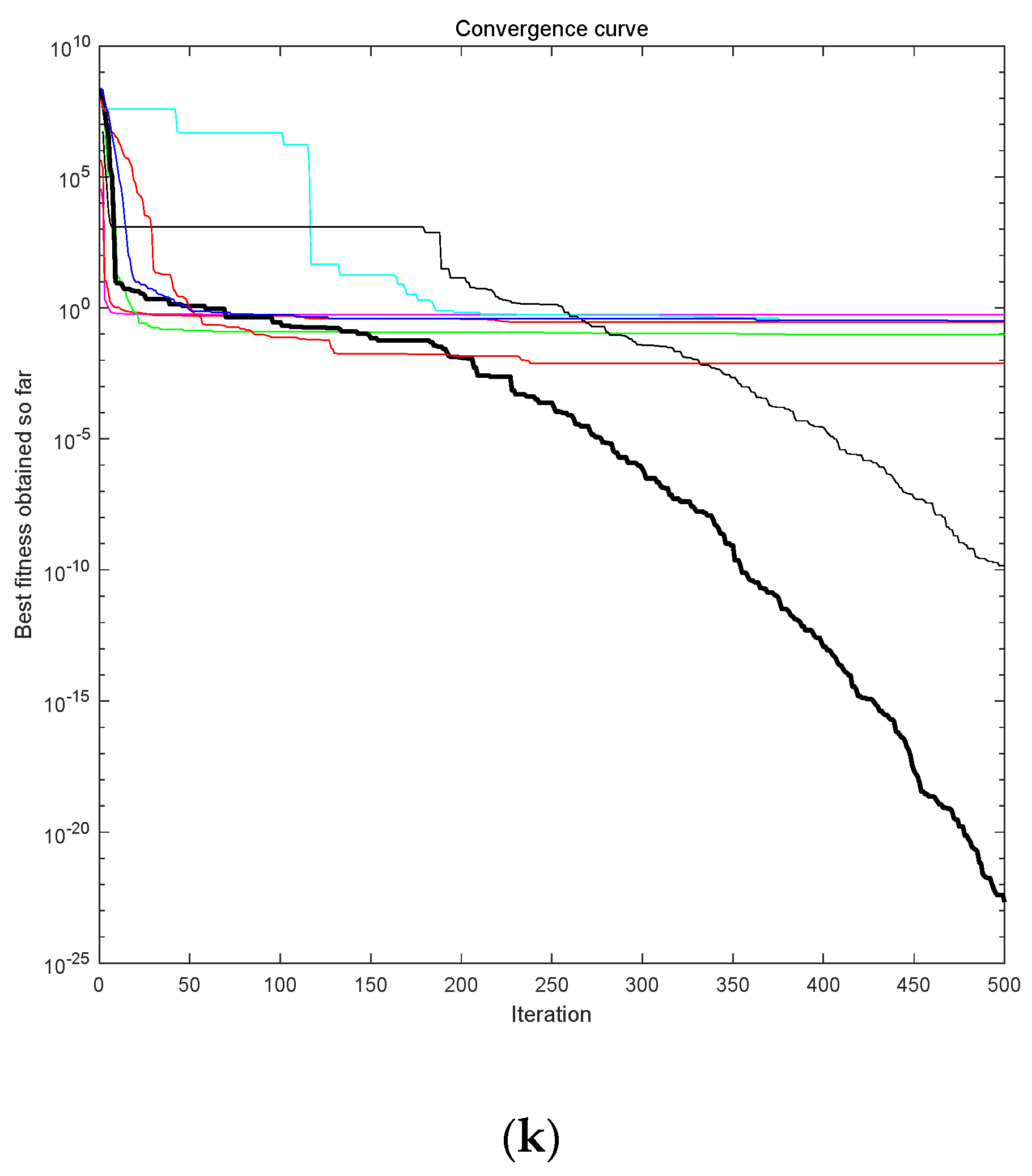
3.3.2. Test the Function Convergence Curve
3.3.3. Wilcoxon Rank Sum Test
4. Apply the Improved Honey Badger Calculation to Optimize the Multi-Functional Logistics Location Model
4.1. Package Threshold Settings
4.2. Open Hybrid Transit Center
- STEP1: FINDING THE NETHER SOLUTION (LB)
- When the transit center is opened as a standard parcel transit center, and the cost item of the bulky package is 0, the sub-problem is simplified to:
- When the transit center is opened as a transit center for large parcels, and the cost item of the bulky package is 0, the sub-problem is simplified to:
- STEP2: Finding the Upper Bound Solution (UB)
- STEP3: Excavation phase
5. Experiments and Results
5.1. Test of the Validity of the Hybrid Algorithm
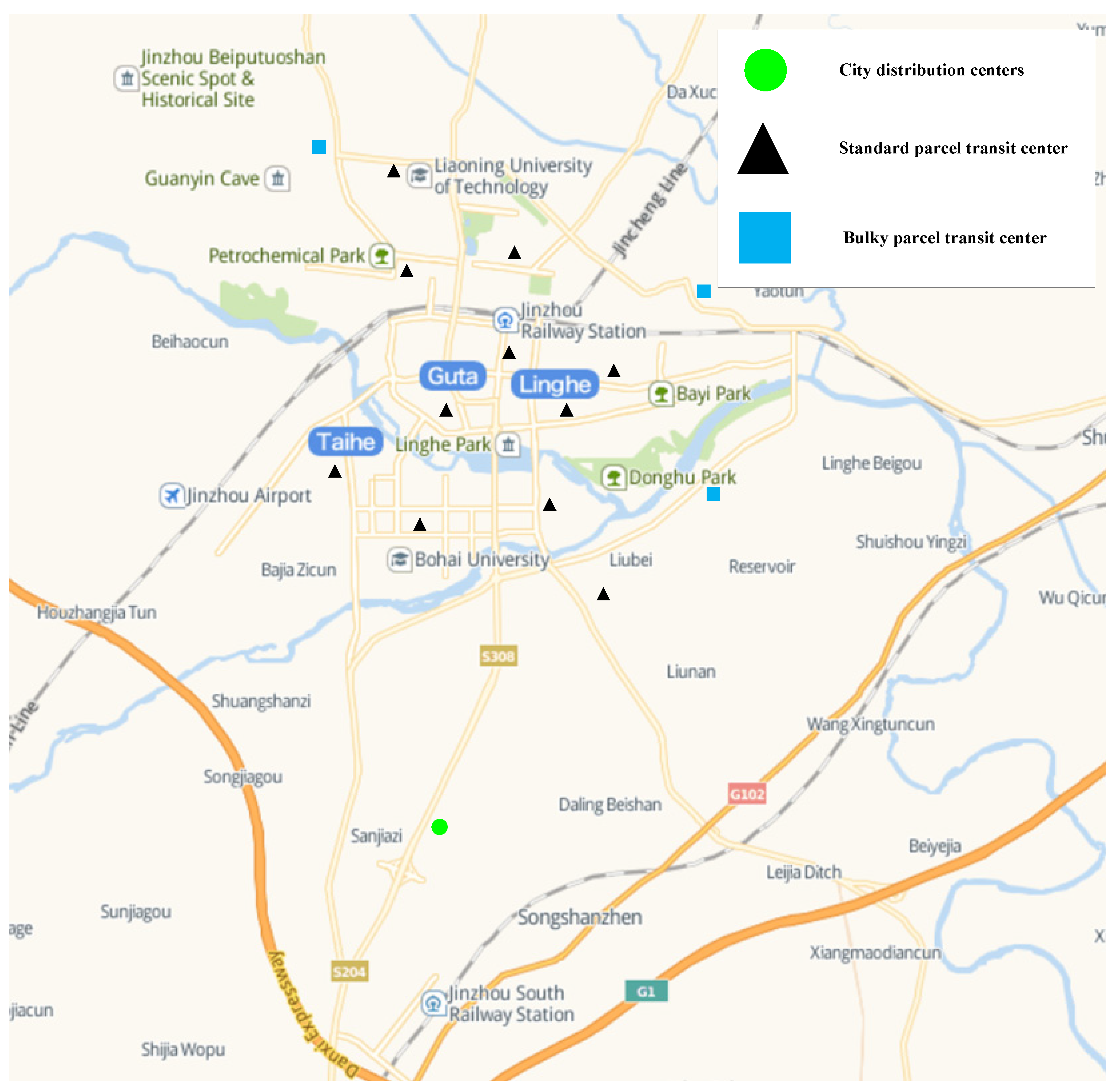
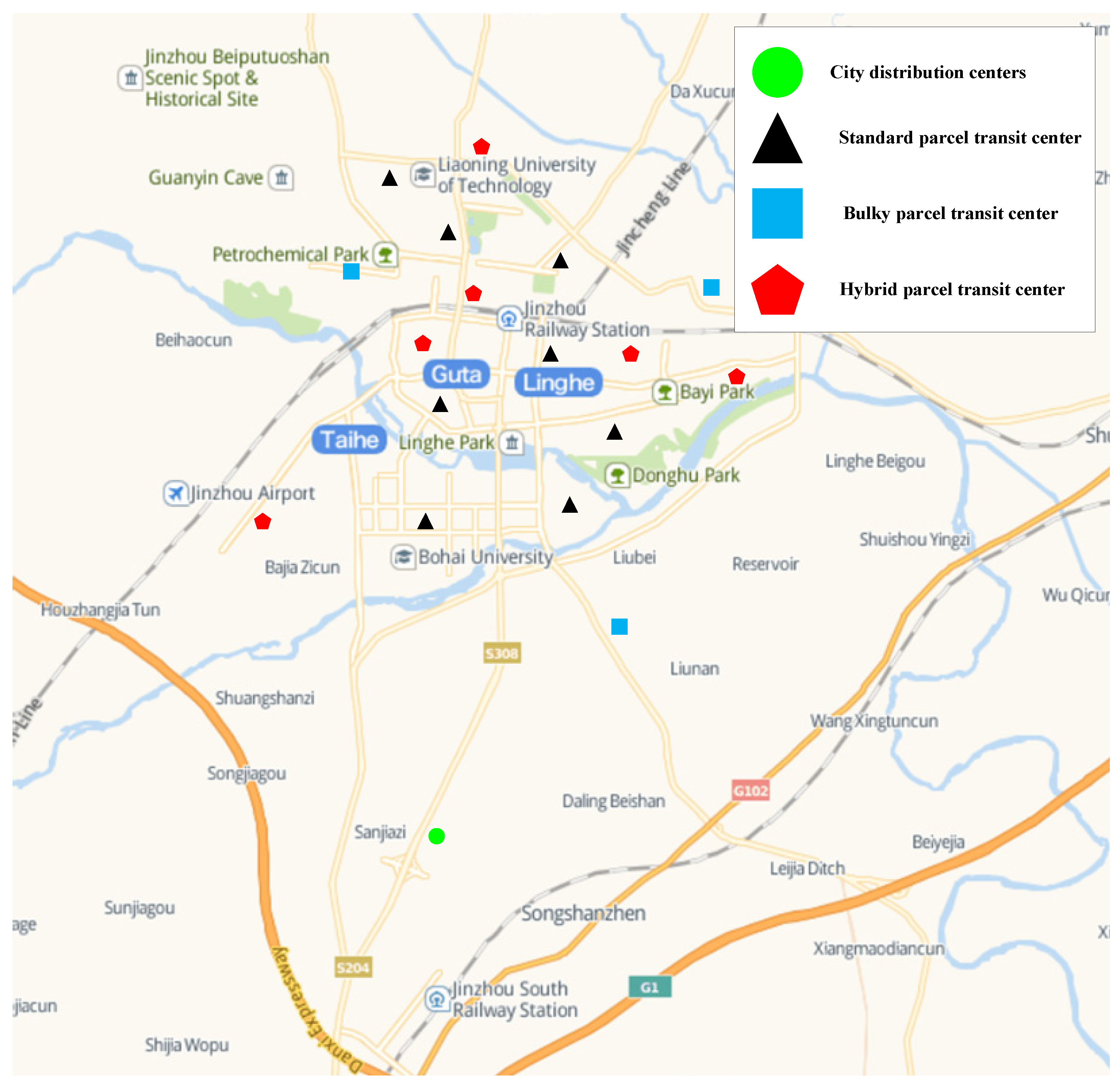
5.2. Example Description and Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Özmen, M.; Aydoğan, E.K. Robust multi-criteria decision making methodology for real life logistics center location problem. Artif. Intell. Rev. Int. Sci. Eng. J. 2020, 53, 725–751. [Google Scholar] [CrossRef]
- Zhang, J.; Weng, Z.; Guo, Y. Distribution Center Location Model Based on Gauss-Kruger Projection and Gravity Method. J. Phys. Conf. Ser. 2021, 1972, 012075. [Google Scholar] [CrossRef]
- Cai, C.; Luo, Y.; Cui, Y.; Chen, F. Solving Multiple Distribution Center Location Allocation Problem Using K-Means Algorithm and Center of Gravity Method Take Jinjiang District of Chengdu as an example. IOP Conf. Ser. Earth Environ. Sci. 2020, 587, 012120. [Google Scholar] [CrossRef]
- Li, J.; Lei, H.; Wang, G.G. Solving Logistics Distribution Center Location with Improved Cuckoo Search Algorithm. Int. J. Comput. Intell. Syst. 2020, 14, 2. [Google Scholar] [CrossRef]
- Mei, Z.; Chi, X.; Chi, R. Research on Logistics Distribution Center Location Based on Hybrid Beetle Antennae Search and Rain Algorithm. Biomimetics 2022, 7, 194. [Google Scholar] [CrossRef] [PubMed]
- Chi, R.; Su, Y.; Qu, Z.; Chi, X. A Hybridization of Cuckoo Search and Differential Evolution for the Logistics Distribution Center Location Problem. Math. Probl. Eng. 2019, 2019, 7051248. [Google Scholar] [CrossRef]
- Zhang, H.; Shi, Y.; Zhang, X. Optimization for Logistics Center Location in Coastal Tourist Attraction Based on Grey Wolf Optimizer. J. Coast. Res. 2019, 94, 823–827. [Google Scholar] [CrossRef]
- Yang, L.; Song, X. High-Performance Computing Analysis and Location Selection of Logistics Distribution Center Space Based on Whale Optimization Algorithm. Comput. Intell. Neurosci. 2022, 2022, 2055241. [Google Scholar] [CrossRef]
- Liu, D.; Hu, X.; Jiang, Q. Design and optimization of logistics distribution route based on improved ant colony algorithm. Optik 2023, 273, 170405. [Google Scholar] [CrossRef]
- Zhang, S.; Zheng, Y.; Li, G. Research on distribution center layout optimization based on genetic algorithm. J. Phys. Conf. Ser. 2021, 1976, 012010. [Google Scholar] [CrossRef]
- Wei, Y.; Zhou, L. Soft Time Windows Associated Vehicles Routing Problems of Logistics Distribution Center Using Genetic Simulated Annealing Algorithm. J. Comput. Inf. Technol. 2014, 22, 31–39. [Google Scholar] [CrossRef]
- Wu, X. Design of logistics distribution center location method based on particle swarm optimization. Acad. J. Eng. Technol. Sci. 2023, 6. [Google Scholar] [CrossRef]
- Hua, X.; Hu, X.; Yuan, W. Research optimization on logistics distribution center location based on adaptive particle swarm algorithm. Optik 2016, 127, 8443–8450. [Google Scholar] [CrossRef]
- Liu, X.L.; Zhang, W.Y. Application of Composite Ant Colony Optimization in Logistics Distribution Center Location. Appl. Mech. Mater. 2012, 253, 1476–1481. [Google Scholar] [CrossRef]
- Li, Y.G. An Improved Bat Algorithm and its Application in the Logistics Distribution Center Location Problem. Appl. Mech. Mater. 2013, 404, 738–743. [Google Scholar] [CrossRef]
- Shihab, I.F.; Oishi, M.M.; Islam, S.; Banik, K.; Arif, H. A Machine Learning Approach to Suggest Ideal Geographical Location for New Restaurant Establishment. In Proceedings of the 2018 IEEE 6th Region 10 Humanitarian Technology Conference (R10-HTC), Malambe, Sri Lanka, 6–8 December 2018. [Google Scholar]
- Dai, X.; Chen, M.; Zhou, Y. Optimal logistics transportation and route planning based on fpga processor real-time system and machine learning. Microprocess. Microsyst. 2021, 80, 103621. [Google Scholar] [CrossRef]
- Song, F.; Lu, X.; Li, K. Research on Location Model of Shanghai Express Outlets Based on Big Data and Machine Learning. In Proceedings of the 8th International Symposium on Project Management, China (ISPM2020), Beijing, China, 4 July 2020; pp. 1430–1436. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Arora, S.; Singh, S. Butterfly optimization algorithm: A novel approach for global optimization. Soft Comput. 2019, 23, 715–734. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Trojovský, P.; Dehghani, M. Pelican Optimization Algorithm: A Novel Nature-Inspired Algorithm for Engineering Applications. Sensors 2022, 22, 855. [Google Scholar] [CrossRef]
- Zervoudakis, K.; Tsafarakis, S. A mayfly optimization algorithm. Comput. Ind. Eng. 2020, 145, 106559. [Google Scholar] [CrossRef]
- Tanyildizi, E.; Demir, G. Golden Sine Algorithm: A Novel Math-Inspired Algorithm. Adv. Electr. Comput. Eng. 2017, 17, 71–78. [Google Scholar] [CrossRef]
- Askarzadeh, A. A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 2016, 169, 1–12. [Google Scholar] [CrossRef]
- Meraihi, Y.; Gabis, A.B.; Mirjalili, S.; Ramdane-Cherif, A. Grasshopper Optimization Algorithm: Theory, Variants, and Applications. IEEE Access 2021, 9, 50001–50024. [Google Scholar] [CrossRef]
- Mirjalili, S. The Ant Lion Optimizer. Adv. Eng. Softw. 2015, 83, 80–98. [Google Scholar] [CrossRef]
- Alomari, A.; Phillips, W.; Aslam, N.; Comeau, F. Swarm Intelligence Optimization Techniques for Obstacle-Avoidance Mobility-Assisted Localization in Wireless Sensor Networks. IEEE Access 2017, 6, 22368–22385. [Google Scholar] [CrossRef]
- Szczepański, E.; Jachimowski, R.; Izdebski, M.; Jacyna-Gołda, I. Warehouse location problem in supply chain designing: A simulation analysis. Arch. Transp. 2019, 50, 101–110. [Google Scholar] [CrossRef]
- Pyza, D.; Jacyna-Gołda, I.; Gołda, P. Problems of Deliveries in Urban Agglomeration Distribution Systems. In Directions of Development of Transport Networks and Traffic Engineering; Macioszek, E., Sierpiński, G., Eds.; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2018; Volume 51, pp. 174–183. [Google Scholar] [CrossRef]
- Hashim, F.A.; Houssein, E.H.; Hussain, K.; Mabrouk, M.S.; Al-Atabany, W. Honey Badger Algorithm: New metaheuristic algorithm for solving optimization problems. Math. Comput. Simul. 2021, 192, 84–110. [Google Scholar] [CrossRef]
- Long, W.; Wu, T.; Jiao, J.; Tang, M.; Xu, M. Refraction-learning-based whale optimization algorithm for high-dimensional problems and parameter estimation of PV model. Eng. Appl. Artif. Intell. 2020, 89, 103457. [Google Scholar] [CrossRef]
- Dunia, S.; Ali, R. Chaotic Sine-Cosine Optimization Algorithms. Int. J. Soft Comput. 2018, 13, 108–122. [Google Scholar]
- Wu, H.; Wu, P.; Xu, K.; Li, F. Finite element model updating using crow search algorithm with Levy flight. Int. J. Numer. Methods Eng. 2020, 121, 2916–2928. [Google Scholar] [CrossRef]
- Sankaranarayanan, S.; Swaminathan, G.; Sivakumaran, N.; Radhakrishnan, T.K. A novel hybridized grey wolf optimzation for a cost optimal design of water distribution network. In Proceedings of the 2017 Computing Conference, London, UK, 18–20 July 2017. [Google Scholar]
- Chen, S. Chaotic particle swarm optimization fusion FCM clustering algorithm based on chebyshev mapping. Comput. Appl. Softw. 2015, 32, 255–258. [Google Scholar]
- Zhang, Y.; Wang, P.; Yang, H.; Cui, Q. Optimal dispatching of microgrid based on improved moth-flame optimization algorithm based on sine mapping and Gaussian mutation. Syst. Sci. Control Eng. 2022, 10, 115–125. [Google Scholar] [CrossRef]
- Yuan, P.; Zhang, T.; Yao, L.; Lu, Y.; Zhuang, W. A Hybrid Golden Jackal Optimization and Golden Sine Algorithm with Dynamic Lens-Imaging Learning for Global Optimization Problems. Appl. Sci. 2022, 12, 9709. [Google Scholar] [CrossRef]
- Li, J.; Le, M. Improved whale optimization algorithm based on image selection. Trans. Nanjing Univ. Aeronaut. Astronaut. 2020, 37, 115–123. [Google Scholar]
- Deb, K.; Deb, D. Analysing mutation schemes for realparameter genetic algorithms. Int. J. Artif. Intell. Soft Comput. 2014, 4, 1–28. [Google Scholar]
- Deb, K.; Mohan, M.; Mishra, S. Evaluating the ε-Domination Based Multi-Objective Evolutionary Algorithm for a Quick Com-putation of Pareto-Optimal Solutions. Evol. Comput. 2005, 13, 501–525. [Google Scholar] [CrossRef]
- Perolat, J.; Couso, I.; Loquin, K.; Strauss, O. Generalizing the Wilcoxon rank-sum test for interval data. Int. J. Approx. Reason. 2015, 56, 108–121. [Google Scholar] [CrossRef]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function Name | Function Formulas | Dimension | Search Compartments | Theoretical Value | Function Type |
|---|---|---|---|---|---|
| Sphere | 20 | [−100, 100] | 0 | Unimodal | |
| Schwefel’s 2.22 | 100 | [−10, 10] | 0 | Unimodal | |
| Schwefel’s 1.2 | 10 | [−100, 100] | 0 | Unimodal | |
| Schwefel’s 2.21 | 60 | [−100, 100] | 0 | Unimodal | |
| Rosenbrock’s | 30 | [−30, 30] | 0 | Unimodal | |
| Step | 30 | [−100, 100] | 0 | Unimodal | |
| Quartic | 10 | [−1.28, 1.28] | 0 | Unimodal | |
| Rastrigin | 200 | [−5.12, 5.12] | 0 | Multimodal | |
| Ackley | 50 | [−32, 32] | 0 | Multimodal | |
| Girwank | 20 | [−600, 600] | 0 | Multimodal | |
| Penalized | 30 | [−50, 50] | 0 | Multimodal |
| Algorithm | Main Parameter Settings |
|---|---|
| IHBA | |
| HBA | , |
| BOA | p = 0.8, c = 0.01, a = 0.1 |
| PSO | |
| SCA | |
| SSA | - |
| WOA | |
| DA | - |
| Algorithm | Function Optimum | Function Worst | Function Average | Standard Deviation | Time Elapsed | |
|---|---|---|---|---|---|---|
| F1 | IHBA | 0 | 0 | 0 | 0 | 0.2688 |
| HBA | 2.84 × 10−209 | 3.10 × 10−217 | 8.32 × 10−208 | 0 | 0.2778 | |
| BOA | 1.64 × 10−14 | 2.02 × 10−14 | 1.81 × 10−14 | 1.01 × 10−15 | 0.0942 | |
| PSO | 9.18 × 10−8 | 2.07 × 10−10 | 2.31 × 10−6 | 5.89 | 0.0549 | |
| SCA | 2.21 × 10−6 | 1.47 | 1.21 × 10−1 | 3.51 × 10−1 | 0.1147 | |
| SSA | 6.28 × 10−9 | 2.11 × 10−8 | 1.21 × 10−8 | 3.14 × 10−9 | 0.1259 | |
| WOA | 1.20 × 10−167 | 1.20 × 10−151 | 1.10 × 10−152 | 2.80 × 10−152 | 0.05088 | |
| DA | 4.45 × 102 | 2.37 × 103 | 1.04 × 103 | 4.36 × 102 | 18.927 | |
| F2 | IHBA | 0 | 0 | 0 | 0 | 0.2622 |
| HBA | 6.02 × 10−106 | 3.99 × 10−108 | 8.54 × 10−105 | 1.69 × 10−105 | 0.2938 | |
| BOA | 9.89 × 10−12 | 1.22 × 10−11 | 1.10 × 10−11 | 6.09 × 10−13 | 0.1013 | |
| PSO | 9.41 | 2.23 × 101 | 1.50 × 101 | 3.10 | 0.0584 | |
| SCA | 1.26 × 10−4 | 7.81 × 10−9 | 1.26 × 10−4 | 4.15 × 10−4 | 0.1166 | |
| SSA | 7.17 × 10−3 | 3.25 | 8.28 × 10−1 | 8.28 × 10−1 | 0.1258 | |
| WOA | 3.70 × 10−115 | 1.20 × 10−100 | 3.80 × 10−102 | 2.10 × 10−101 | 0.0530 | |
| DA | 2.89 × 10−1 | 2.17 × 101 | 1.12 × 101 | 4.89 | 21.807 | |
| F3 | IHBA | 0 | 0 | 0 | 0 | 0.4797 |
| HBA | 6.65 × 10−200 | 2.77 × 10−209 | 2.00 × 10−198 | 0 | 0.5254 | |
| BOA | 1.63 × 10−14 | 2.09 × 10−14 | 1.82 × 10−14 | 1.05 × 10−15 | 0.4253 | |
| PSO | 8.36 × 101 | 2.78 × 102 | 1.74 × 102 | 4.75 × 101 | 0.2191 | |
| SCA | 1.69 × 102 | 1.10 × 104 | 3.48 × 103 | 2.93 × 103 | 0.2765 | |
| SSA | 7.27 × 101 | 6.78 × 102 | 2.67 × 102 | 1.50 × 102 | 0.2956 | |
| WOA | 4.86 × 103 | 4.38 × 104 | 2.17 × 104 | 9.53 × 103 | 0.2192 | |
| DA | 2.57 × 103 | 2.12 × 104 | 1.15 × 104 | 5.54 × 103 | 22.809 | |
| F4 | IHBA | 0 | 0 | 0 | 0 | 0.2321 |
| HBA | 1.43 × 10−102 | 5.14 × 10−107 | 2.96 × 10−101 | 5.68 × 10−102 | 0.2428 | |
| BOA | 1.10 × 10−11 | 1.38 × 10−11 | 1.22 × 10−11 | 6.47 × 10−13 | 0.0959 | |
| PSO | 1.99 | 2.88 × 102 | 2.43 | 2.22 × 10−1 | 0.0570 | |
| SCA | 1.59 | 3.95 × 101 | 1.91 × 101 | 1.05 × 101 | 0.1125 | |
| SSA | 2.93 | 1.55 × 101 | 8.70 | 3.45 | 0.1282 | |
| WOA | 5.40 × 10−2 | 8.95 × 101 | 3.70 × 101 | 3.04 × 101 | 0.0561 | |
| DA | 1.38 × 101 | 3.58 × 101 | 2.25 × 101 | 5.99 | 16.682 | |
| F5 | IHBA | 2.66 × 101 | 2.56 × 101 | 2.73 × 101 | 1.13 × 10−3 | 0.2752 |
| HBA | 2.88 × 101 | 2.84 × 101 | 2.89 × 101 | 1.20 × 10−1 | 0.2806 | |
| BOA | 2.89 × 101 | 2.90 × 101 | 2.89 × 101 | 3.00 × 10−2 | 0.1355 | |
| PSO | 2.16 × 103 | 1.48 × 104 | 6.07 × 103 | 2.92 × 103 | 0.0751 | |
| SCA | 2.77 × 101 | 8.24 × 103 | 5.47 × 102 | 1.59 × 103 | 0.1328 | |
| SSA | 1.81 × 101 | 1.79 × 103 | 2.41 × 102 | 4.20 × 102 | 0.1484 | |
| WOA | 2.84 × 101 | 2.90 × 101 | 2.88 × 101 | 1.21 × 10−1 | 0.4616 | |
| DA | 4.23 × 103 | 6.25 × 105 | 1.11 × 105 | 1.28 × 105 | 18.916 | |
| F6 | IHBA | 4.01 × 10−14 | 1.52 × 10−9 | 8.45 × 10−11 | 2.78 × 10−10 | 0.2376 |
| HBA | 1.50 × 10−1 | 2.19 × 10−1 | 6.26 | 6.10 × 10−1 | 0.2327 | |
| BOA | 4.51 | 6.65 | 5.83 | 4.89 × 10−1 | 0.0928 | |
| PSO | 7.19 | 2.66 × 101 | 1.66 × 101 | 5.50 | 0.0558 | |
| SCA | 3.77 | 7.54 | 4.58 | 6.45 × 10−1 | 0.1110 | |
| SSA | 7.91 × 10−9 | 2.18 × 10−8 | 1.31 × 10−8 | 3.39 × 10−9 | 0.1251 | |
| WOA | 1.11 × 10−2 | 3.69 × 10−1 | 9.47 × 10−2 | 9.76 × 10−2 | 0.0515 | |
| DA | 2.89 × 102 | 3.76 × 103 | 1.09 × 103 | 6.41 × 103 | 18.836 | |
| F7 | IHBA | 6.82 × 10−7 | 1.88 × 10−4 | 5.71 × 10−5 | 4.54 × 10−5 | 0.2389 |
| HBA | 2.81 × 10−4 | 3.26 × 10−5 | 1.81 × 10−3 | 3.54 × 10−4 | 0.2285 | |
| BOA | 2.28 × 10−4 | 1.11 × 10−3 | 6.57 × 10−4 | 2.33 × 10−4 | 0.2854 | |
| PSO | 2.77 × 101 | 1.10 × 102 | 5.93 × 101 | 2.36 × 101 | 0.1543 | |
| SCA | 3.46 × 10−3 | 2.11 × 10−1 | 4.06 × 10−2 | 4.64 × 10−2 | 0.2094 | |
| SSA | 4.46 × 10−2 | 2.13 × 10−1 | 1.09 × 10−1 | 4.30 × 10−2 | 0.2251 | |
| WOA | 1.17 × 10−4 | 1.19 × 10−2 | 2.22 × 10−3 | 2.84 × 10−3 | 0.1478 | |
| DA | 1.15 × 10−1 | 6.20 × 10−1 | 2.83 × 10−1 | 1.32 × 10−1 | 16.723 | |
| F8 | IHBA | 0 | 0 | 0 | 0 | 0.7173 |
| HBA | 0 | 0 | 0 | 0 | 0.7798 | |
| BOA | 0.00E+00 | 2.04 × 102 | 3.16 × 101 | 7.20 × 10−1 | 0.1235 | |
| PSO | 1.70 × 102 | 2.70 × 102 | 2.17 × 102 | 2.89 × 101 | 0.0756 | |
| SCA | 3.25 × 10−5 | 1.44 × 102 | 2.25 × 101 | 4.13 × 101 | 0.1237 | |
| SSA | 2.29 × 101 | 8.86 × 101 | 6.10 × 101 | 1.83 × 101 | 0.1409 | |
| WOA | 0 | 0 | 0 | 0 | 0.0570 | |
| DA | 8.69 × 101 | 2.40 × 102 | 1.58 ×102 | 3.86 × 101 | 18.460 | |
| F9 | IHBA | 8.88 × 10−16 | 8.88 × 10−16 | 8.88 × 10−16 | 0 | 0.2738 |
| HBA | 8.88 × 10−16 | 4.44 × 10−15 | 2.90 × 10−15 | 1.79 × 10−15 | 0.3914 | |
| BOA | 1.13 × 10−11 | 1.46 × 10−11 | 1.29 × 10−11 | 9.03 × 10−13 | 0.1133 | |
| PSO | 3.59 | 5.37 | 4.39 | 3.66 × 10−1 | 0.0780 | |
| SCA | 4.91 × 10−4 | 2.03 × 10−1 | 1.34 ×10−1 | 8.86 | 0.1382 | |
| SSA | 2.18 × 10−5 | 2.96 | 1.93 | 7.33 ×10−1 | 0.1437 | |
| WOA | 8.88 × 10−16 | 7.99 × 10−15 | 4.20 × 10−15 | 2.07 × 10−15 | 0.0593 | |
| DA | 0 | 1.18 × 10−1 | 5.24 × 10−3 | 2.24 × 10−2 | 0.0753 | |
| F10 | IHBA | 0 | 0 | 0 | 0 | 0.2535 |
| HBA | 0 | 0 | 0 | 0 | 0.3989 | |
| BOA | 0 | 6.44 × 10−15 | 1.64 × 10−15 | 1.79 × 10−15 | 0.1459 | |
| PSO | 3.35 × 10−1 | 7.95 × 10−1 | 5.27 × 10−1 | 1.21 × 10−1 | 0.0890 | |
| SCA | 6.15 × 10−5 | 7.24 × 10−1 | 3.08 × 10−1 | 2.14 × 10−1 | 0.1446 | |
| SSA | 3.30 × 10−8 | 4.44 × 10−2 | 1.00 × 10−2 | 1.07 × 10−2 | 0.1597 | |
| WOA | 5.06 | 1.17 | 8.60 | 1.89 | 18.383 | |
| DA | 3.19 | 2.82 × 101 | 1.26 × 101 | 6.57 | 19.235 | |
| F11 | IHBA | 6.91 × 10−3 | 2.63 × 10−3 | 1.18 × 10−2 | 1.06 × 10−2 | 0.5501 |
| HBA | 7.09 × 10−1 | 3.28 × 10−1 | 1.18 × 101 | 2.06 × 10−1 | 0.6714 | |
| BOA | 4.01 × 10−1 | 1.00 | 6.61 × 10−1 | 1.51 × 10−1 | 0.8359 | |
| PSO | 1.72 × 10−2 | 3.00 × 10−8 | 2.07 × 10−1 | 4.78 × 10−2 | 0.3696 | |
| SCA | 5.78 × 10−1 | 1.44 × 106 | 6.86 × 104 | 2.66 × 105 | 0.4443 | |
| SSA | 1.59 | 1.86 × 101 | 7.33 | 3.40 | 0.4133 | |
| WOA | 2.31 × 10−2 | 6.16 ×10−3 | 9.91 × 10−2 | 1.98 × 10−2 | 0.3538 | |
| DA | 1.34 × 103 | 5.67 | 2.36 × 104 | 4.76 × 103 | 25.125 |
| Algorithm | HBA | BOA | PSO | SCA | SSA | WOA | DA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | S | P | S | P | S | P | S | P | S | P | S | P | S | |
| F1 | 1.18 × 10−12 | + | 1.21 × 10−12 | + | 1.21 × 10−12 | + | 1.16 × 10−13 | + | 1.04 × 10−12 | + | 1.21 × 10−12 | + | 7.95 × 10−13 | + |
| F2 | 1.08 × 10−12 | + | 1.21 × 10−12 | + | 1.11 × 10−12 | + | 1.53 × 10−12 | + | 4.91 × 10−13 | + | 1.21 × 10−12 | + | 7.33 × 10−13 | + |
| F3 | 1.04 × 10−12 | + | 1.21 × 10−12 | + | 1.17 × 10−12 | + | 2.80 × 10−12 | + | 3.11 × 10−12 | + | 1.05 × 10−12 | + | 3.77 × 10−13 | + |
| F4 | 1.15 × 10−12 | + | 1.21 × 10−12 | + | 1.21 × 10−12 | + | 1.17 × 10−13 | + | 4.91 × 10−13 | + | 5.35 × 10−13 | + | 3.16 × 10−13 | + |
| F5 | 2.92 × 10−11 | + | 3.02 × 10−11 | + | 2.92 × 10−11 | + | 4.56 × 10−11 | + | 3.02 × 10−11 | + | 3.02 × 10−11 | + | 2.05 × 10−11 | + |
| F6 | 2.99 × 10−11 | + | 3.02 × 10−11 | + | 3.02 × 10−11 | + | 1.20 × 10−10 | + | 1.72 × 10−10 | + | 3.02 × 10−11 | + | 2.60 × 10−11 | + |
| F7 | 2.92 × 10−11 | + | 3.02 × 10−11 | + | 9.31 × 10−12 | + | 4.56 × 10−11 | + | 2.01 × 10−10 | + | 2.89 × 10−11 | + | 2.61 × 10−11 | + |
| F8 | 1.17 × 10−12 | + | 9.23 × 10−13 | + | 6.81 × 10−13 | + | 1.17 × 10−13 | + | 1.27 × 10−12 | + | 1.20 × 10−12 | + | 4.17 × 10−13 | + |
| F9 | 1.19 × 10−12 | + | 1.11 × 10−12 | + | 1.19 × 10−12 | + | 2.36 × 10−11 | + | 8.75 × 10−12 | + | 1.21 × 10−12 | + | 6.29 × 10−13 | + |
| F10 | 1.16 × 10−12 | + | 1.21 × 10−12 | + | 1.10 × 10−12 | + | 1.17 × 10−13 | + | 1.53 × 10−12 | + | 1.21 × 10−12 | + | 6.96 × 10−13 | + |
| F11 | 3.63 × 10−2 | + | 2.90 × 10−11 | + | 1.18 × 10−12 | + | 2.37 × 10−11 | + | 7.87 × 10−12 | + | 3.17 × 10−4 | + | 1.26 × 10−11 | + |
| Alternate Points | Demand Points | Improved Honey Badger Algorithm | CPLEX | Relative Error (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Threshold (kg) | The Objective Function Value (RMB) | Elapsed Time (s) | Threshold (kg) | The Objective Function Value (RMB) | Elapsed Time (s) | |||
| 2 | 10 | 2 | 2751.72 | 0.517 | 2 | 2621.87 | 0.532 | 0.95 |
| 15 | 2 | 2976.98 | 0.782 | 2 | 2876.91 | 1.365 | 0.81 | |
| 20 | 2 | 3112.76 | 1.873 | 2 | 3091.83 | 31.276 | 1.91 | |
| 3 | 10 | 2 | 3087.09 | 0.687 | 2 | 3079.88 | 0.754 | 0.05 |
| 15 | 2 | 3221.87 | 0.853 | 2 | 3228.21 | 78.376 | 0.15 | |
| 20 | 2 | 3412.91 | 1.138 | 2 | 3409.32 | 932.76 | 0.52 | |
| 4 | 10 | 2 | 3076.19 | 0.737 | 2 | 3082.23 | 3.873 | 0.40 |
| 15 | 2 | 3298.13 | 0.962 | 2 | 3184.54 | >1800 | 0.44 | |
| 20 | 2 | - | 1.238 | 2 | - | >1800 | - | |
| Fixed Cost (RMB) | Unit Transportation Cost (RMB/km) | ||||||
|---|---|---|---|---|---|---|---|
| Standard Package | Bulky Packages | ||||||
| 300 | 800 | 1000 | 1500 | 800 | 10 | 2 | 5 |
| Threshold (kg) | Transit Center (Piece) | Cost (RMB) | |||||
|---|---|---|---|---|---|---|---|
| Standard Type | Large Type | Hybrid Type | Fixed Cost | Shipping Cost | Total Cost | Average Unit Price | |
| 2 | 0 | 17 | 0 | 13,600 | 35,872.87 | 49,472.87 | 4.73 |
| 5 | 1 | 12 | 2 | 11,900 | 31,498.21 | 43,398.21 | 4.98 |
| 10 | 4 | 6 | 5 | 11,000 | 27,981.89 | 38,981.89 | 3.73 |
| 15 | 8 | 3 | 6 | 10,800 | 23,268.98 | 34,068.98 | 2.54 |
| 20 | 33 | 0 | 1 | 10,900 | 29,763.73 | 40,663.73 | 3.12 |
| 30 | 46 | 0 | 0 | 13,800 | 32,873.81 | 46,673.81 | 5.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, C.; Li, S.; Zhang, L.; Zhang, D. The Improvement of the Honey Badger Algorithm and Its Application in the Location Problem of Logistics Centers. Appl. Sci. 2023, 13, 6805. https://doi.org/10.3390/app13116805
Jin C, Li S, Zhang L, Zhang D. The Improvement of the Honey Badger Algorithm and Its Application in the Location Problem of Logistics Centers. Applied Sciences. 2023; 13(11):6805. https://doi.org/10.3390/app13116805
Chicago/Turabian StyleJin, Chuwei, Shanhong Li, Linna Zhang, and Damin Zhang. 2023. "The Improvement of the Honey Badger Algorithm and Its Application in the Location Problem of Logistics Centers" Applied Sciences 13, no. 11: 6805. https://doi.org/10.3390/app13116805
APA StyleJin, C., Li, S., Zhang, L., & Zhang, D. (2023). The Improvement of the Honey Badger Algorithm and Its Application in the Location Problem of Logistics Centers. Applied Sciences, 13(11), 6805. https://doi.org/10.3390/app13116805