Abstract
To investigate the issue of multi-entry bus priority at intersections, an intelligent priority control method based on deep reinforcement learning was constructed in the bus network environment. Firstly, a dimension reduction method for the state vector based on the key lane was proposed, which contains characteristic parameters such as the bus states, the flow states, and the signal timing. Secondly, a control action method that can adjust phase sequence and phase green time at the same time was proposed under the constraints of maximum green and minimum green. Furthermore, a reward function, which can be uniformly converted into the number of standard cars, was established focusing on the indexes such as the busload and maximum waiting time. Finally, through building an experimental environment based on SUMO simulation, a real-time bus signal priority control method based on deep reinforcement learning was constructed. The results show that the algorithm can effectively reduce the waiting time of buses without affecting overall traffic efficiency. The findings can provide a theoretical basis for the signal control method considering bus priority and improve the operation efficiency of public transport.
1. Introduction
With the continued growth of motorized mobility in recent years, the passenger flow of public transport has declined year by year, and the lack of competitiveness of buses is one of the important reasons. This is reflected in two aspects: On the one hand, bus travel is unreliable, reflected in the low speed and punctuality; on the other hand, the imbalance between supply and demand leads to poor service and a waste of supply surplus. As for the unreliability of bus travel, studies have shown that bus delays at intersections account for 10–20% of the total bus travel time, and this bus delay is more than half of the entire delay time [1]. Therefore, improving public transport operation efficiency at intersections is one of the critical choices to enhance public transport competitiveness.
The traditional bus priority control is mainly divided into passive priority control, active priority control, and adaptive priority control [2,3,4]. These methods are usually designed for specific traffic flow scenarios and periods. They use an optimization mathematical model with traffic flow theory and solve the model based on optimization theory. However, traffic flow has substantial spatiotemporal variability, so this method usually cannot be used at different periods at the same intersection, nor can it be used at other intersections at the same period. In addition, these methods mainly focus on a single entrance direction of bus signal priority with green extension, red light shortening, and special bus phase insertion, so it is too limited for all entrance direction bus priority [5]. However, according to the advantages of closed-loop feedback control and global optimization for reinforcement learning, which does not rely on mathematical models [6], a series of achievements has been made in traffic signal control optimization [7,8,9], which is mainly reflected in optimizing the state space, behavior action, reward function, and the solution method. Due to the complex traffic flow characteristics, there are several apparent hurdles in the bus signal priority control method based on deep reinforcement learning.
Firstly, how is state space represented in fewer dimensions? The current research mainly focuses on three points: pixel matrix representation based on images [10,11,12,13], DTSE (discrete traffic state encoding) based on each lane [14], and vector representation based on each lane [15,16]. The indexes involved mainly include queue length [17], vehicle location parameters [18], density, speed [19], and current signal phase time [20], etc. However, the construction of the traffic state space with the lane as the unit is prone to redundant information, leading to the curse of dimensionality and difficulty in solving problems.
Secondly, how can the control action design be more flexible? The current research mainly focuses on two types of methods: one is the adjustable phase sequence and the fixed green time [15,16,18,21,22]; one is a fixed phase sequence and has adjustable green time [23,24]. Meanwhile, the frequency of adjustment of the green time can be divided into two types: (1) adjust once a cycle; (2) adjust once a phase [25,26]. Generally, the above action design method lacks flexibility, and cannot adjust phase sequence and phase green time at the same time.
Thirdly, how can an action reward function considering multi-objective optimization be designed? The previous research mainly focused on the design of the reward function with a single optimization objective, the optimization objective involved mainly includes delay, vehicle waiting time, queue length, number of stops, traffic volume, vehicle emissions, etc. [13,20,27,28,29,30]. Given that urban traffic signal control needs to consider multi-objective optimization control problems such as safety, efficiency, and order [31], it is difficult to meet the application scenarios only with the improvement of a single objective as an action reward. Many researchers have also designed a multi-objective reward function based on weight [16,31,32,33,34]. However, the objective weight setting is mainly based on artificial experience, which is difficult to effectively calibrate, resulting in a certain degree of influence on the training convergence speed and stability of the algorithm. At the same time, the scale of different objectives is inconsistent, leading to poor interpretability.
Finally, how can this model be solved? Traditional reinforcement learning is mainly based on the Q-value table learning algorithm [35] and SARSA algorithm [36], which is not good at dealing with high-dimensional and continuous traffic-state information, restricting further application. Thus, many studies have begun to take advantage of deep learning in data processing to carry out research on deep reinforcement learning in the field of signal control [37,38].
The current research on bus signal priority control based on reinforcement learning exhibits the above problems to different degrees [39,40,41,42]. To address these issues, a new method for bus signal priority control based on deep reinforcement learning is proposed. The main contributions of this study can be summarized as follows:
- (1)
- We propose a unified framework for bus signal priority real-time control, which is able to migrate to different intersections and different time periods quickly;
- (2)
- By using key lanes to characterize traffic states, the dimension of the state space is effectively reduced, and the rapid training ability of the model can be improved;
- (3)
- The design of the action space is more flexible, which can adjust phase sequence and phase green time at the same time;
- (4)
- Under the multi-objective optimization, we establish a reward function that can be uniformly converted into the number of standard cars, which effectively solves the problem of weight calibration. Accordingly, the rest of this article is structured as follows. Section 2 provides a model description for bus signal priority control based on reinforcement learning. Section 3 introduces the reinforcement learning agent training process to achieve the proposed method. Section 4 presents the simulated experiment results to verify the effectiveness of the proposed method. Lastly, conclusions and recommendations for future research are made in Section 5.
2. Model of Bus Signal Priority Control Reinforcement Learning Agent
A traffic light controller is defined as an “Agent”, which can assign the access right to traffic flows.
2.1. Traffic State Space Construction
Considering that signal timing is the core principle of green time allocation based on the characteristics of traffic flow in key lanes [43,44], this paper built the state space based on the key lanes, in which the state parameters are composed of the information of buses, the flow characteristics of intersections, and the information of signal timing. Bus information is represented by two parameters: bus location and passenger capacity, which are aggregated by the phase key lanes and 6 m per cell. The flow characteristics of intersections are selected based on the number of queuing vehicles and aggregated by the phase key lanes. The signal timing contains four parameters, that is, the current vehicle phase number, the current vehicle release time, the vehicle phase red light duration, and the pedestrian phase red light waiting time. The intersection state space is expressed as:
where the state vector S is 1 × m vector, merged through vector concatenation; n denotes the number of vehicle phases; k denotes the number of pedestrian phases; si denotes the state space of the motor vehicle phase in phase i; di, ldi, qi, rvi denote the bus running position vector, the busload vector, the queuing vehicles vector in the k lane, and the red light duration vector in phase i of the motor vehicle, respectively; pi indicates the red light waiting time of pedestrians in phase i; la indicates the current vehicle phase number; gl indicates the current vehicle phase green light duration time.
Based on key lanes, the division of cells does not need to consider the number of lanes on the approach, which can reduce feature dimension. Taking the east approach in an intersection as an example, as shown in Figure 1, the east approach consists of five lanes. The length between the parking line of the east approach and the upstream intersection is 180 m, and the length of each cell is 6 m. By using the DTSE method (as shown in Figure 1), there needs to be 30 × 5 = 150 elements to represent the bus position in the east approach. However, there only needs to be 30 elements that represent the bus position by using the proposed method (key lanes-based method, as shown in Figure 2), and the dimension can be reduced by 80%.

Figure 1.
DTSE method represents bus position in the east approach.
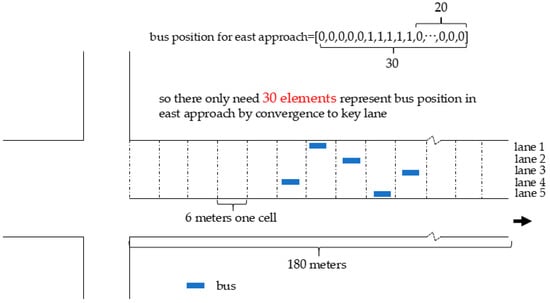
Figure 2.
Key lane-based method represents bus position in the east approach.
2.2. Behavior Action Space Construction
The phase number is used as the action set. When the next phase obtained by the agent decision is the current phase, it means that the current phase extends the unit green light time; when the next phase is not the current phase, the phase transitions are performed, and the switching transitions are made with a fixed yellow light time and full red time. For example, at a four-phase intersection, the action set A = {switch to phase 1, switch to phase 2, switch to phase 3, switch to phase 4}.
At the same time, considering the safety problems caused by insufficient pedestrian crossing time, insufficient motor vehicle passing time, and the long waiting time of pedestrians or vehicles, the minimum green and maximum green of pedestrian crossing or motor vehicle release duration time are rigidly constrained. After the phase duration time meets the minimum green, the action decision is started, and the phase must be switched when the maximum green is exceeded. The values and calculation methods of minimum green and maximum green refer to the results of Liu [45] and Wang [46]. At the same time, the unit extension time is usually taken as 3–5 s [47]. Considering that the saturated time headway of the bus (a time gap between the beginning of one vehicle and the beginning of the next) is larger than the car, the unit extension time is taken as 6 s.
2.3. Action Reward Function Construction
For the bus priority scenario, considering that the main purpose of bus priority is to reduce the bus delay (evaluation index) as much as possible without significantly increasing the vehicle delay (constraint index) as much as possible. Therefore, by balancing the contradiction between them, this paper designs a set of multi-objective reward functions with a unified scale.
In terms of the selection of evaluation indexes, considering that the calculation of delay indexes is lagging, it is difficult to meet the requirements of real-time feedback rewards. Taking into account the real-time availability of indexes, this paper uses the number of vehicles passing in the action execution as the evaluation index. At the same time, by combining the vehicle networking environment of the bus, the busload can be obtained, and the average passenger capacity of the car can be converted into the number of cars with a unified scale:
where , , and denote the number of standard cars, buses and cars passing through the intersection during the period of action execution respectively; indicates the number of passengers on bus i; represents the average passenger capacity of a car, which is taken as two in this paper.
In the selection of constraint indexes, the main factors such as traffic efficiency, safety and fairness are considered. The growth of the number of queuing vehicles , the loss caused by the stop of the bus in front of the queue at the end of the original phase due to phase transition , the maximum red time of motor vehicles , and the maximum red time of pedestrians are selected as constraint indexes:
where denotes the maximum number of queuing vehicles in phase i at time t; denotes the number of lanes corresponding to the release direction in the current release phase at time t; denotes the number of passengers carried by the first bus in lane queue j corresponding to the current release phase at time t; denotes the duration of the red light of the motor vehicle in phase i at time t; denotes the maximum red time of the motor vehicle; denotes the saturation time headway, which is taken as 2 s [17]; denotes the duration of the red light of pedestrians in phase i at time t; denotes the maximum red time of pedestrians.
Therefore, the unified scale multi-index reward function proposed in this paper is designed as:
3. Bus Signal Priority Control Reinforcement Learning Agent Training
Considering that the traffic state space is difficult to be exhaustively characterized by the traditional Q-value table, this paper uses a deep Q network (DQN) to solve the problem of Q-value table storage. At the same time, by employing the mechanism of experience playback [48], the correlation of data in agent training is eliminated, ensuring the fast iterative convergence of the training. The deep Q network adopts a three-layer network structure. The agent training framework is shown in Figure 3.
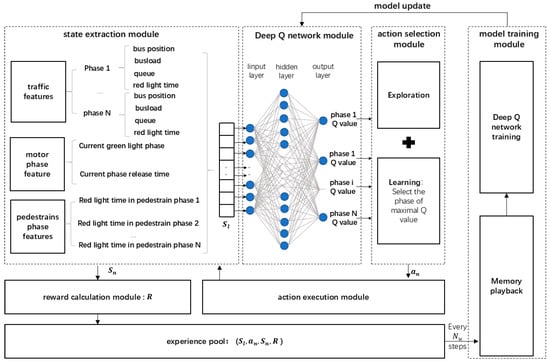
Figure 3.
Bus signal priority control under the deep reinforcement learning framework.
The architecture of this model includes the following modules: state extraction module, Deep Q network module, action selection module, action execution module, reward calculation module, experience pool, and model training module.
Among them, the state extraction module observes the bus state, intersection operation state, and signal timing state at the current moment, and concatenates them as the intersection state vector S, which is taken as the inputs of the Deep Q network module, and the output of the Deep Q network module is the probability Q value for each action (phase). Then, through the action selection module, we select the next phase based on the greedy strategy. At the same time, the signal controller changes the green light duration time through the action execution module. After the execution is completed, the state extraction module observes and extracts the intersection state vector again and runs the cycle according to the above process. After each decision action is executed, the reward value R is calculated through the reward calculation module, and the previous state, action, next state, and reward are saved to the experience pool. In every step, the model training module randomly selects a certain number of samples in the experience pool to train and update the deep Q network.
The detailed training process is shown in the Algorithm 1:
| Algorithm 1: Detailed training process |
| 1: Build SUMO simulation environment 2: Initialize network , the experience pool , observation interval , update interval , iterations N, single simulation duration , decision time point , action 3: For i = 0: N 4: For step = 0: 5: If step = Then 6: Observe the traffic state 7: Compute the next action based on 8: Execute action 9: Update 10: Observe the traffic state 11: Compute the reward 12: Save (, , , R) to the memory pool M 13: Count = Count + 1 14: Step = Step + 1 15: End if 16: If Count > and == 0 Then 17: Randomly select training samples in 18: Using computes predictive Q value for all actions 19: = R + Gamma * Max[Q(Sn, all actions)] 20 Train and update 21: End if 22: End for 23: End for . |
4. The Analysis of Experiments
4.1. Construction of Simulation Test Environment
The simulation experimental intersection is Luotian/Xinhu intersection in Shenzhen, Guangdong Province, China. It is surrounded by Bao’an Stadium and large residential areas, with dense bus lines passing through intersections. The intersection is shown in Figure 4.
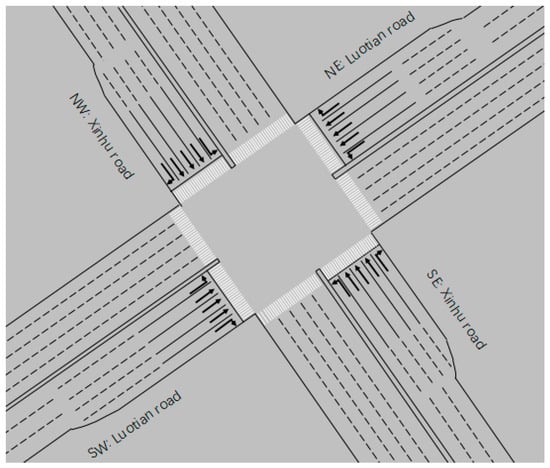
Figure 4.
SUMO simulation environment of Luotian–Xinhu intersection.
As shown in Figure 5, the current existing traffic signal plan of this intersection is a fixed-time signal plan. Due to its proximity to the nearby Bao’an Stadium and large residential areas, the intersection has a large number of pedestrians. So, the traffic signal plan of the intersection should not only consider motor vehicles but also consider cross-street pedestrians. Compared to the control strategy for straight-ahead directions in one phase, and left turns (from opposites approach) in another phase, the current existing traffic signal planning (as shown in Figure 5) has the following advantages: (1) the waiting time for pedestrians to cross the street can be reduced; (2) the waiting time of pedestrians on the central safety island can also be reduced. In Figure 5, the double-arrow dotted line indicates the direction of pedestrians crossing, and pedestrian twice crossing the street, and the single-arrow solid line indicates the direction of motor vehicles passing. In a fixed-time control, the maximum green time of each phase is used as the actual green light time of each phase. This paper still follows the current existing traffic signal planning. On the one hand, the current traffic signal planning is the optimal planning under the long-term practice of professional signal timing social service teams. On the other hand, compared with the current traffic signal planning for a fixed-time control, only the pedestrians in 41P and 31P will increase the waiting time of 31–38 s in the central safety island (1 m × 6 m). It would not significantly increase the risk of pedestrians staying on the central safety island.
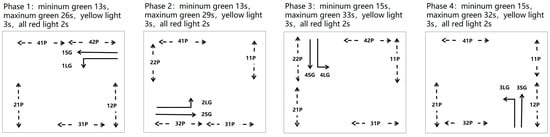
Figure 5.
Signal control scheme.
According to the definition of the traffic state space of the intelligent agent in 2.1, and considering that the maximum vehicle queue length at Luotian/Xinhu intersection in the real world is less than 100 m, to order to reduce the representation dimension of the state space and considering the redundant design, so only describe the traffic state within a range of 180 m in Luotian/Xinhu intersection, and the state vector S can be represented by 1 × 262 vector. And the state parameters, such as bus location and busload, queuing vehicles, the information of signal timing, can be obtained in the bus networking environment. The bus location can be obtained based on the positioning information; the busload can be obtained by counting the on-board camera in the bus; the number of queuing vehicles can be obtained by radar vehicle detectors; and the signal timing state, such as the current phase green time, can be obtained by reading the information from the traffic signal controller.
The experimental traffic data at the intersection were obtained from the manual survey data from 12:00 to 13:00 on 22 November 2021, as shown in Table 1. The busload data were based on the manual statistics of the bus video, as shown in Table 2. In Table 1 and Table 2, column “Direction” is defined as “entrance direction: turn direction”. A, L, S, and R indicate turn around, turn left, go straight, and turn right, respectively.

Table 1.
Intersection traffic flow statistics.
Table 2.
Intersection busload statistics.
The algorithm was built on the Windows 10 operating system with i7-9700 CPU and 16.0 GB memory, implemented on python 3.8.5. The neural network was built by TensorFlow 2.8.0, the traffic operation simulation environment was SUMO 1.8.0. The simulation time is 3600 s for an iteration and there are 600 iterations in total. The deep neural network adopts a three-layer structure, with 262 nodes in the input layer, 200 nodes in the hidden layer, and 4 nodes in the output layer. The neural network parameters are updated every 10 decision steps after 100 decision steps. The capacity of the experience pool is set to 10,000, and 150 samples are randomly sampled to train the neural network each time.
The learning rate of the agent is 0.0001, and the empirical loss rate in the target Q value estimation is 0.9, adopting the greedy strategy in the learning process. The initial exploration probability is set to 0.5, the final exploration probability is set to 0.0001, and the number of attenuation steps is 50,000. The exploration probability is linearly attenuated, and the number of attenuation steps is set to 50,000.
In the simulation, the traffic flow models such as the car-following model and the lane-change model all adopt the default settings in Sumo, and the vehicle parameters such as the speed distribution and acceleration also take the default settings in SUMO. The signal control parameters, such as maximum green time, and minimum green time for each stage were used in Figure 5.
4.2. Training Results Analysis
The simulation time of 3600 s is an iteration. Six indexes are selected as traffic efficiency indexes, namely, the cumulative travel time of all vehicles, cumulative waiting time of all vehicles, cumulative travel time of all buses, cumulative waiting time of all buses, cumulative waiting time of all passengers, and cumulative travel time of all passengers. Figure 6 shows the curve of the prediction error and the number of iterations of the neural network. Figure 7 shows the curve of the six traffic efficiency indexes and the number of iterations. The results show that with the increase in the number of iterations, the prediction error and traffic efficiency index of the neural network shows a downward trend. When the number of iterations reaches 330, the prediction error and six traffic efficiency indexes of the neural network converge, indicating the effectiveness of the method. Through calculation, comparing the first 300 iterations with the last 300 iterations, the cumulative travel time of all vehicles was reduced by 20%, the cumulative waiting time of all vehicles was reduced by 53%, the cumulative travel time of all buses was reduced by 16%, the cumulative waiting time of all buses was reduced by 46%, the cumulative waiting time of all passengers was reduced by 19%, and the cumulative travel time of all passengers reduced by 51%.
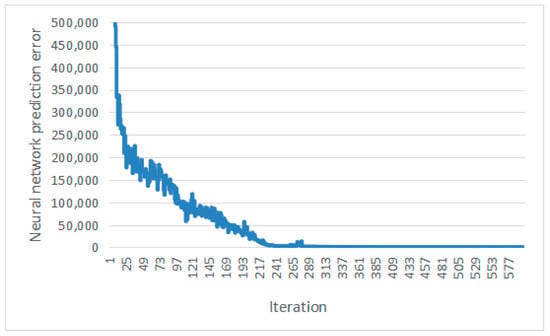
Figure 6.
Training error curve.
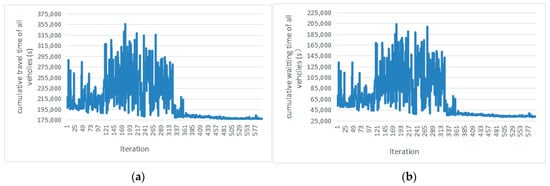
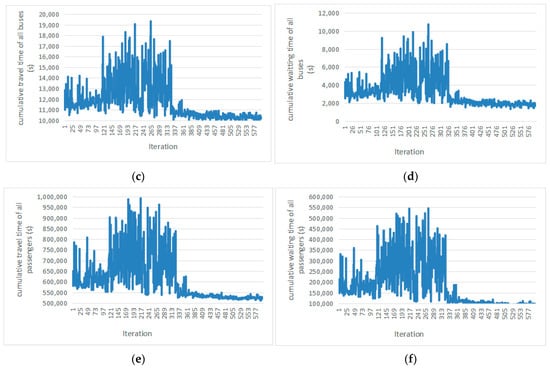
Figure 7.
Traffic efficiency index curve under the training: (a) cumulative travel time of all vehicles; (b) cumulative waiting time of all vehicles; (c) cumulative travel time of buses; (d) cumulative waiting time of buses; (e) cumulative travel time of passengers; (f) cumulative waiting time of passengers.
4.3. Comparison of Intelligent Agent Operation Effect
To verify the effect, the proposed method was compared with a fixed-time control and an actuated control. In the fixed-time control, as shown in Figure 5, the signal planning uses the maximum green time as the duration time of each phase. In the full actuated control, the signal phase, the minimum green time, and the maximum green time are also shown in Figure 5. The green light time of phase changes without changing the sequence of phases. The unit green light extension time is taken as 6 s, and the inductive loop detector is set at the range of 30 m from the stop line. When the bus or other vehicle is detected within a preset time interval of 6 s, the phase will be extended until the maximum green time. When no vehicle is detected within the preset time interval of 6 s, the phase will be changed. In the experiment, 10 groups of random seeds were added to ensure the fairness of the experiment by simulating 10 groups of different departure rules under the specified traffic flow conditions, and the average value of 10 groups of result data was taken to compare the operation effect of three methods (as shown in Figure 8). The results of the proposed method show that the average cumulative travel time of all vehicles is 10.2% less than that of a fixed-time control and 3.4% less than that of an actuated control. The average cumulative waiting time of all vehicles is reduced by 35.9% compared with a fixed-time control and 14.3% with an actuated control. The average cumulative travel time of buses is 9.7% less than a fixed-time control and 6.7% less than an actuated control. The average cumulative waiting time of buses is 36.9% less than a fixed-time control and 27.2% less than an actuated control. The average cumulative waiting time of all passengers is reduced by 9.9% compared with a fixed-time control and 3.9% with an actuated control. The average cumulative travel time of all passengers is reduced by 35.9% compared with a fixed-time control and 16.7% with an actuated control.

Figure 8.
Effect comparison between three methods: fixed-time control method, actuated control method and DQN method: fixed-time control method, actuated: (a) cumulative travel time of all vehicles; (b) cumulative waiting time of all vehicles; (c) cumulative travel time of all buses; (d) cumulative waiting time of all buses; (e) cumulative travel time of all passengers; (f) cumulative waiting time of all passengers.
We designed “high”, “shoulder”, and “low” traffic demand scenarios to verify the adaptability of our algorithm. The traffic flow of “shoulder” traffic demand is shown in Table 1, the traffic flow of “high” and “low” traffic demand increases and decreases by 10% proportionally, respectively on the basis of “shoulder” traffic demand. In “high”, “shoulder”, and “low” traffic demand, the DQN control method proposed in this paper is superior to the fixed-time control method and actuate control method. As shown in Table 3, the average travel time of all vehicles can be reduced by 1.6–10.6%; the average waiting time of all vehicles can be reduced by 12.1–38.3%; the average travel time of buses can be reduced by 5.5–11.9%; the average cumulative waiting time of buses can be reduced by 35.9–37.0%; the average waiting time of passengers can be reduced by 2.4–10.8%; and the average travel time of passengers can be reduced by 15.4–50.7%.
Table 3.
Effect comparison in three traffic demand.
5. Conclusions
This paper proposes a deep Q-learning control method for multi-flow bus signal priority at intersections in the bus networking environment. By taking into account the needs of social vehicles and pedestrians crossing the street, it provides priority access for each traffic flow of buses at intersections. Based on the core objective of bus priority, the proposed method optimizes the design of state, action and reward functions, building a bus signal priority deep Q-learning simulation platform through the COM interface of the SUMO simulation platform and Python programming software. As shown in the simulation experiment, compared with a fixed-time control and an actuated control, the waiting time of buses decreased by 36.9% and 27.2%, respectively, and the average waiting time of all vehicles decreased by 35.9% and 16.7%, respectively.
Although the proposed method has achieved some achievement in addressing the signal control problem considering bus priority, it is still less successful and needs further development. Moreover, there is still a risk that bus priority control can lead to increased emissions and thus be in conflict with sustainability. Therefore, with careful consideration of sustainability, further work will be focused on researching bus priority control as well as trunk and regional bus priority control.
Author Contributions
Conceptualization, W.S.; methodology, W.S.; software, L.Z.; validation, L.Z.; formal analysis, R.D.; investigation, R.D.; resources, H.W.; data curation, H.W.; writing—original draft preparation, W.S.; writing—review and editing, J.W.; visualization, H.W.; supervision, J.W.; project administration, J.W.; funding acquisition, J.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by [the Guangdong Basic and Applied Basic Research Foundation] under grant number [2022A1515111039]. The APC was funded by [the Guangdong Basic and Applied Basic Research Foundation].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare that they have no known competing financial interest or personal relationship that could have appeared to influence the work reported in this paper.
References
- Yu, H. Bus Signal Priority Coordination Control Method Research. Master’s Thesis, Southwest Jiaotong University, Chengdu, China, 2014. [Google Scholar]
- Huang, G.; Xing, J.; Meng, L.; Li, F.; Ma, L. Travel Time Prediction for Bus Rapid Transmit Using a Statistics-based Probabilistic Method. In Proceedings of the 2010 2nd International Conference on Signal Processing Systems, Dalian, China, 5–7 July 2010; Volume 6, pp. 34–37. [Google Scholar] [CrossRef]
- Ma, W.; Yang, X. Review of Priority Signal Strategies for Bus Services. Urban Transp. China 2010, 8, 70–78. [Google Scholar] [CrossRef]
- Wu, Y. Transit Signal Priority Control Approaches of Urban Public Transportation Towards Multiple Buses’ Conflicting Priority Requests. Ph.D. Dissertation, Southeast University, Nanjing, China, 2020. [Google Scholar] [CrossRef]
- Zhang, J. The Design of Transit Signal Priority Simulation System Based on SUMO. Master’s Thesis, Chang’an University, Xi’An, China, 2012. [Google Scholar]
- Abdulhai, B.; Karakoulas, G.J.; Pringle, R. Reinforcement Learning for True Adaptive Traffic Signal Control. J. Transp. Eng. 2003, 129, 278–285. [Google Scholar] [CrossRef]
- Haydari, A.; Yilmaz, Y. Deep Reinforcement Learning for Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2020, 23, 11–32. [Google Scholar] [CrossRef]
- Rasheed, F.; Yau, K.-L.A.; Noor, R.M.; Wu, C.; Low, Y.-C. Deep Reinforcement Learning for Traffic Signal Control: A Review. IEEE Access 2020, 8, 208016–208044. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, L.; Zhu, F. Multi-agent Reinforcement Learning Based Traffic Signal Control for Integrate Urban Network: Survey of State of Art. Appl. Res. Comput. 2018, 35, 6. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2018&filename=JSYJ201806004&uniplatform=NZKPT&v=r8t06qWuBGpFyYvSTdBiHE67VJxx0iP3j4JS9cD3og6eVomJYPmBFPsNza7mv63R (accessed on 24 January 2022).
- Mousavi, S.S.; Schukat, M.; Howley, E. Traffic Light Control Using Deep Policy-Gradient and Value-Function Based Reinforcement Learning. IET Intell. Transp. Syst. 2017, 11, 417–423. [Google Scholar] [CrossRef]
- Wei, H.; Zheng, G.; Yao, H.; Li, Z. IntelliLight: A Reinforcement Learning Approach for Intelligent Traffic Light Control. In Proceedings of the 24th ACM SIGKDD International Conference, London, UK, 19–23 August 2018. [Google Scholar] [CrossRef]
- Li, D.; Zhu, F.; Chen, T.; Wong, Y.D.; Zhu, C.; Wu, J. COOR-PLT: A hierarchical control model for coordinating adaptive platoons of connected and autonomous vehicles at signal-free intersections based on deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2022, 146, 103933. [Google Scholar] [CrossRef]
- Wu, C.; Kim, I.; Ma, Z. Deep Reinforcement Learning Based Traffic Signal Control A Comparative Analysis. Procedia Comput. Sci. 2023, 220, 275–282. [Google Scholar] [CrossRef]
- Shu, L.Z. Research on Urban Traffic Control Algorithm Based on Deep Reinforcement Learning. Ph.D. Dissertation, University of Electronic Science and Technology, Chengdu, China, 2020. [Google Scholar] [CrossRef]
- Liu, J.; Qin, S.; Su, M.; Luo, Y.; Zhang, S.; Wang, Y.; Yang, S. Traffic signal control using reinforcement learning based on the teacher-student framework. Expert Syst. Appl. 2023, 228, 120458. [Google Scholar] [CrossRef]
- Bouktif, S.; Cheniki, A.; Ouni, A.; El-Sayed, H. Deep reinforcement learning for traffic signal control with consistent state and reward design approach. Knowl.-Based Syst. 2023, 267, 110440. [Google Scholar] [CrossRef]
- Guo, M.; Wang, P.; Chan, C.-Y.; Askary, S. A Reinforcement Learning Approach for Intelligent Traffic Signal Control at Urban Intersections. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar] [CrossRef]
- Genders, W.; Razavi, S. Using a Deep Reinforcement Learning Agent for Traffic Signal Control. arXiv 2016, arXiv:1611.01142. [Google Scholar] [CrossRef]
- Genders, W.; Razavi, S. Evaluating Reinforcement Learning State Representations for Adaptive Traffic Signal Control. Procedia Comput. Sci. 2019, 130, 26–33. [Google Scholar] [CrossRef]
- Zhang, R.; Ishikawa, A.; Wang, W.; Striner, B.; Tonguz, O.K. Using Reinforcement Learning with Partial Vehicle Detection for Intelligent Traffic Signal Control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 404–415. [Google Scholar] [CrossRef]
- He, Z.; She, X.; Yang, W.; Chen, N. Self-learning Traffic Signal Control Method of Isolated Intersection Combining Q-learning and Fuzzy Logic. Appl. Res. Comput. 2011, 28, 4. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFD2011&filename=JSYJ201101057&uniplatform=NZKPT&v=jbZR5XmZJrdUuM8KlirQWX9XTHo5b841-bNJxQTvTEOcgsl0ScX6vRj3vA7pp8-m (accessed on 5 February 2022).
- El-Tantawy, S.; Abdulhai, B. An agent-based Learning towards Decentralized and Coordinated Traffic Signal Control. In Proceedings of the International IEEE Conference on Intelligent Transportation Systems, Funchal, Portugal, 19–22 September 2010. [Google Scholar] [CrossRef]
- Li, D.; Wu, J.; Xu, M.; Wang, Z.; Hu, K. Adaptive Traffic Signal Control Model on Intersections Based on Deep Reinforcement Learning. J. Adv. Transp. 2020, 6505893. [Google Scholar] [CrossRef]
- Wan, C.-H.; Hwang, M.-C. Adaptive Traffic Signal Control Methods Based on Deep Reinforcement Learning. In Intelligent Transport Systems for Everyone’s Mobility; Springer: Berlin/Heidelberg, Germany, 2019; pp. 195–209. [Google Scholar] [CrossRef]
- Li, Z.-Q. The Application Study of Based Q-Learning in Traffic Signal Control of Single Intersection. Master’s Thesis, Changsha University of Science & Technology, Changsha, China, 2010. [Google Scholar]
- Touhbi, S.; Babram, M.A.; Nguyen-Huu, T.; Marilleau, N.; Hbid, M.L.; Cambier, C.; Stinckwich, S. Adaptive Traffic Signal Control: Exploring Reward Definition for Reinforcement Learning. Procedia Comput. Sci. 2017, 109, 513–520. [Google Scholar] [CrossRef]
- Nawar, M.; Fares, A.; Al-Sammak, A. Rainbow Deep Reinforcement Learning Agent for Improved Solution of the Traffic Congestion. In Proceedings of the 2019 7th International Japan-Africa Conference on Electronics, Communications, and Computations, (JAC-ECC), Alexandria, Egypt, 15–16 December 2019. [Google Scholar] [CrossRef]
- Li, L.; Lv, Y.; Wang, F.-Y. Traffic signal timing via deep reinforcement learning. IEEE-CAA J. Autom. Sin. 2016, 3, 247–254. [Google Scholar] [CrossRef]
- Zeng, J.; Hu, J.; Zhang, Y. Training Reinforcement Learning Agent for Traffic Signal Control under Different Traffic Conditions. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019. [Google Scholar] [CrossRef]
- Fang, S.; Chen, F.; Hongchao, L. Dueling Double Deep Q-Network for Adaptive Traffic Signal Control with Low Exhaust Emissions in A Single Intersection. IOP Conf. Ser. Mater. Sci. Eng. 2019, 612, 052039. [Google Scholar] [CrossRef]
- Liu, D.; Shu, A.; Yuan, J.; Ma, W. Evaluation System for Traffic Signal Design Based on Scenario Objectives. Urban Transp. China 2021, 19, 8. [Google Scholar] [CrossRef]
- Wang, S.; Xie, X.; Huang, K.; Zeng, J.; Cai, Z. Deep Reinforcement Learning-Based Traffic Signal Control Using High-Resolution Event-Based Data. Entropy 2019, 21, 744. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, H.; Zhu, F. DCL-AIM: Decentralized coordination learning of autonomous intersection management for connected and automated vehicles. Transp. Res. Pt. C-Emerg. Technol. 2019, 103, 246–260. [Google Scholar] [CrossRef]
- Pol, E.; Oliehoek, F.A. Coordinated Deep Reinforcement Learners for Traffic Light Control. In Proceedings of the Learning, Inference and Control of Multi-Agent Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Mikami, S.; Kakazu, Y. Genetic Reinforcement Learning for Cooperative Traffic Signal Control. In Proceedings of the IEEE Conference on Evolutionary Computation, IEEE World Congress on Computational Intelligence, Orlando, FL, USA, 27–29 June 1994. [Google Scholar] [CrossRef]
- Thorpe, T.L.; Anderson, C.W. Traffic Light Control Using SARSA with Three State Representations; IBM Corporation: Armonk, NY, USA, 1996. [Google Scholar]
- Jamil, A.R.; Ganguly, K.K.; Nower, N. Adaptive Traffic Signal Control System Using Composite Reward Architecture Based Deep Reinforcement Learning. IET Intell. Transp. Syst. 2021, 14, 2030–2041. [Google Scholar] [CrossRef]
- Gao, J.; Shen, Y.; Liu, J.; Ito, M.; Shiratori, N. Adaptive Traffic Signal Control: Deep Reinforcement Learning Algorithm with Experience Replay and Target Network. arXiv 2017, arXiv:1705.02755. [Google Scholar] [CrossRef]
- Bo, S.; Damng, L.; Xinliang, Z. Transit Signal Priority Strategy Based on Reinforcement Learning Algorithm. J. Northeast. Univ. (Nat. Sci.) 2012, 33, 4. Available online: http://xuebao.neu.edu.cn/natural/EN/abstract/abstract516.shtml (accessed on 7 February 2022).
- Wang, Y.-P.; Guo, G. Signal Priority Control for Trams Using Deep Reinforcement Learning. Acta Autom. Sin. 2019, 45, 12. [Google Scholar] [CrossRef]
- Xue, P. Research on Bus Priority Signal Control Based on Reinforcement Learning. Ph.D. Dissertation, Xi’an University of Technology, Xi’an, China, 2021. [Google Scholar] [CrossRef]
- Shang, C.; Liu, X.; Tian, Y.; Dong, L. Priority of Dedicated Bus Arterial Control Based on Deep Reinforcement Learning. J. Transp. Syst. Eng. Inf. Technol. 2021, 21, 7. [Google Scholar] [CrossRef]
- Li, R.; Zhang, L. Urban Traffic Signal Control; Tsinghua University Press: Beijing, China, 2015. [Google Scholar]
- Wu, J.; Chen, X.; Bie, Y.; Zhou, W. A co-evolutionary lane-changing trajectory planning method for automated vehicles based on the instantaneous risk identification. Accid. Anal. Prev. 2023, 180, 106907. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Li, K.; Sun, J. Research on Pedestrian’s Waiting Time at Signal Control Intersection. China Saf. Sci. J. 2009, 19, 8. [Google Scholar] [CrossRef]
- Wang, D.; Song, X.; Li, H. Research on Induction Control of Variable Unit Green Light. International Conference on the Application of New Technology in Transportation; Research Institute of the Ministry of Communications of China: Beijing, China, 2004. [Google Scholar]
- Luo, X.; Wang, D.; Jin, S. Traffic Signal Actuated Control at Isolated Intersections for Heterogeneous Traffic. J. Jilin Univ. (Eng. Technol. Ed.) 2019, 49, 10. [Google Scholar] [CrossRef]
- Fang, M.; Li, Y.; Cohn, T. Learning how to Active Learn: A Deep Reinforcement Learning Approach. arXiv 2017, arXiv:1708.02383. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).