





Intelligent TCP Congestion Control Policy Optimization


Abstract
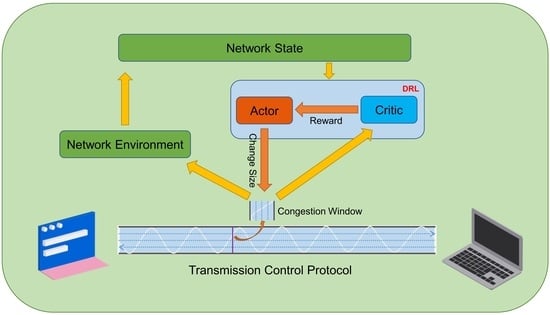
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Related Work
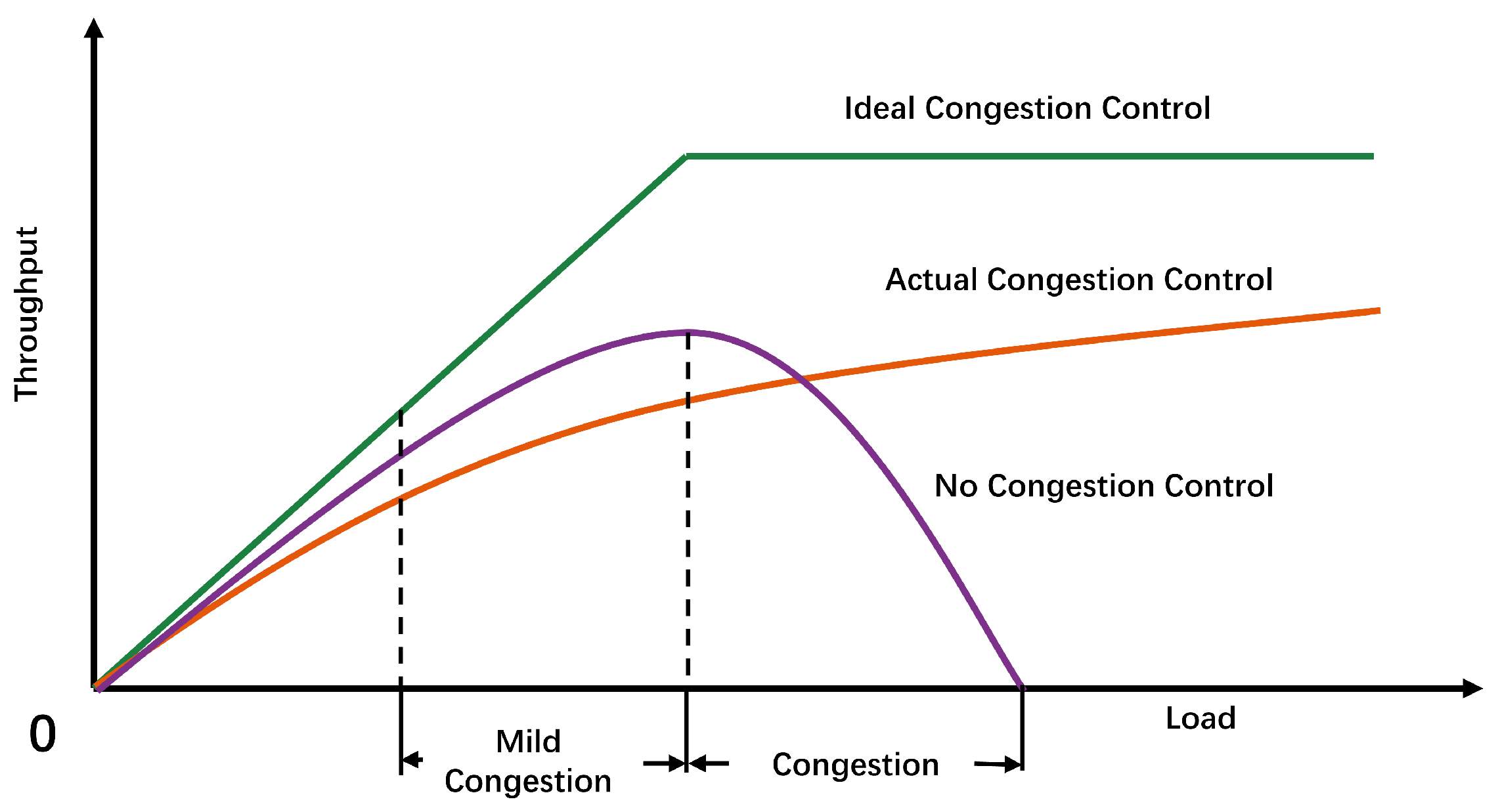
2.1. Fundamentals of Congestion Control
2.2. Deep Reinforcement Learning-Based Congestion Control
3. Methods
3.1. Deep Reinforcement Learning
3.1.1. Background
3.1.2. Proximal Policy Optimization Algorithms
- S—is a state space.
- A—is an action space.
- P—is state transition probability.
- R—is the reward function.
3.1.3. Policy Gradient
3.1.4. Trust Region Methods
3.1.5. Proximal Policy Optimization Algorithm
3.1.6. PPO2 Principle
3.2. State Space Design
- (1)
- The current relative time . Described as the amount of time that has passed when TCP first established the connection up to the present. In algorithms such as CUBIC, the window length is designed as a third-degree function of time . Consequently, plays a crucial role in determining the congestion window.
- (2)
- The size of the current congestion window. The adjustment of the new window value in the congestion control algorithm should be based on the present congestion window length, which can be increased at a faster rate if the current congestion window length is small, and stopped or increased more slowly if the window is large.
- (3)
- The number of bytes is not acknowledged. Defined as the number of bytes transmitted but not yet acknowledged by the receiver. The unacknowledged bytes can be metaphorically compared to water stored in a pipe, where the network link is similar to the pipe. This parameter is also an important parameter that the congestion control algorithm needs to refer to. If the amount of water in the pipe is sufficient, it should stop or reduce the injection of water into the pipe; if the amount of water in the pipe is small, the amount of water injection into the pipe should be increased, and the volume of water in the pipe may be used to calculate the water injection rate (congestion window duration).
- (4)
- The quantity of ACK packets obtained. When the normal amount of ACK packets is received, the network is functioning well without congestion and the congestion window length can gradually be increased. If the network is congested, with a reduced number of ACK packets received, the congestion window length should either be kept constant or reduced.
- (5)
- RTT. Latency refers to the total time it takes for a packet to be sent to the receiving acknowledgment packet, which can be figuratively understood as the time it takes for the data to make a round trip from the sender to the receiver. Network congestion and latency are strongly associated, and when network congestion is bad, latency increases a lot. As a result, the delay can be an indicator of network congestion, and the congestion control algorithm can modify the congestion window in response to the delay.
- (6)
- Throughput rate. Described as the number of data bytes the receiver acknowledges each second. A high throughput rate indicates that enough packets have been transmitted in the present connection; alternatively, it shows that there is more available network capacity and that more packets may be sent to the link. This parameter directly reflects the network circumstances.
- (7)
- The number of packet losses. The higher the number of packet losses, the more serious the current network congestion is, and the congestion window size needs to be reduced; a small number of packet losses suggests that the current network is not congested, and the congestion window length should be increased.
3.3. Action Space Design
3.4. Reward Function Design
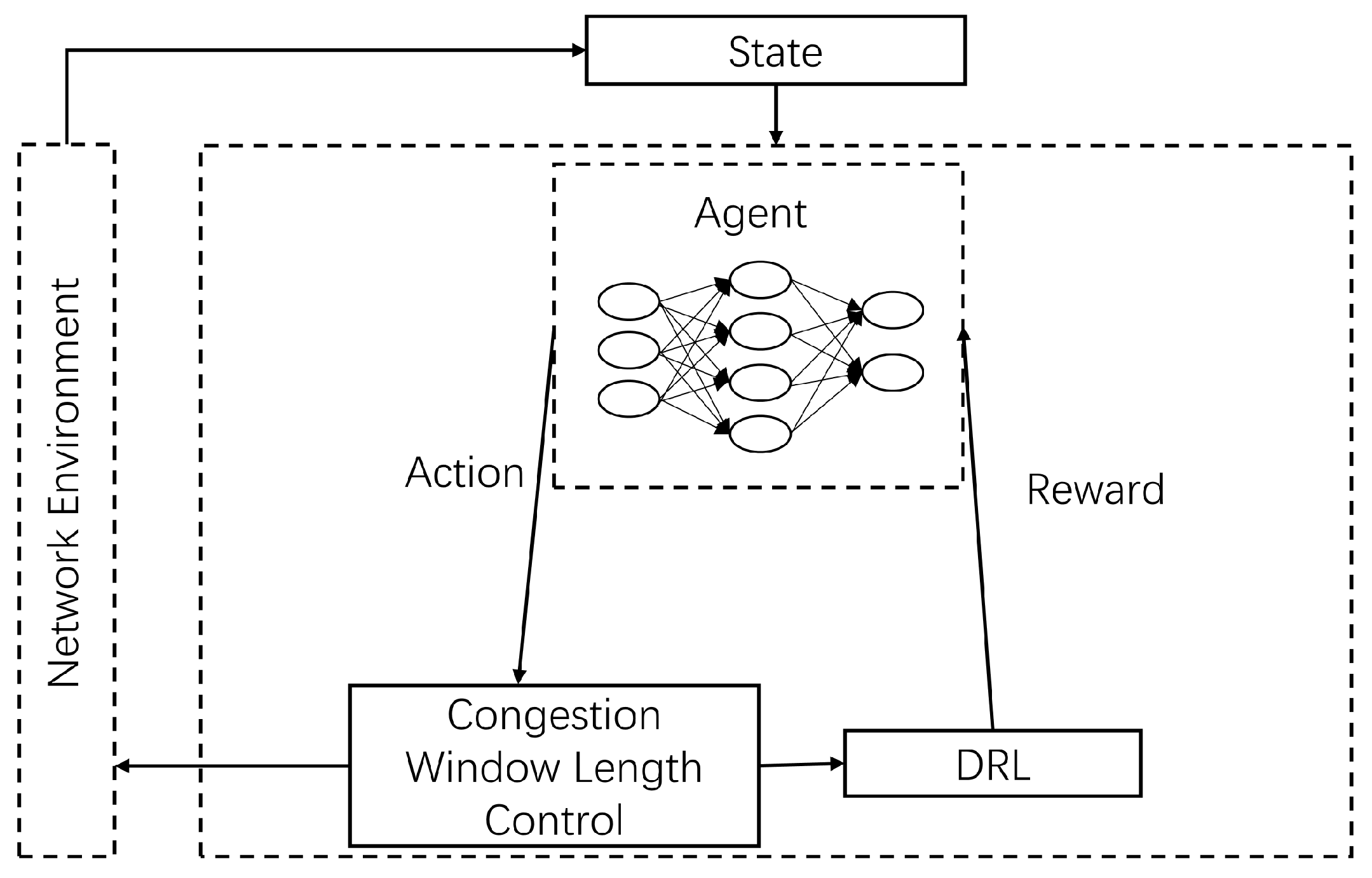
3.5. Algorithm Description
| Algorithm 1. PPO2 |
| 1. Input: = {congestion window length, the number of ACK packets, latency, throughput rate, packet loss rate}. 2. Initialize the policy parameters . 3. Run strategy for a total of T time steps, collect {}. 4. 5. . 6. . 7. . 8. Update the parameter θ by the gradient ascent method so that is the maximum. 9. Output: The length of the new congestion window after adjustment is . |
4. Experiment
4.1. Experimental Environment
4.1.1. Hardware and Software Environment
4.1.2. PPO Algorithm Parameter Settings
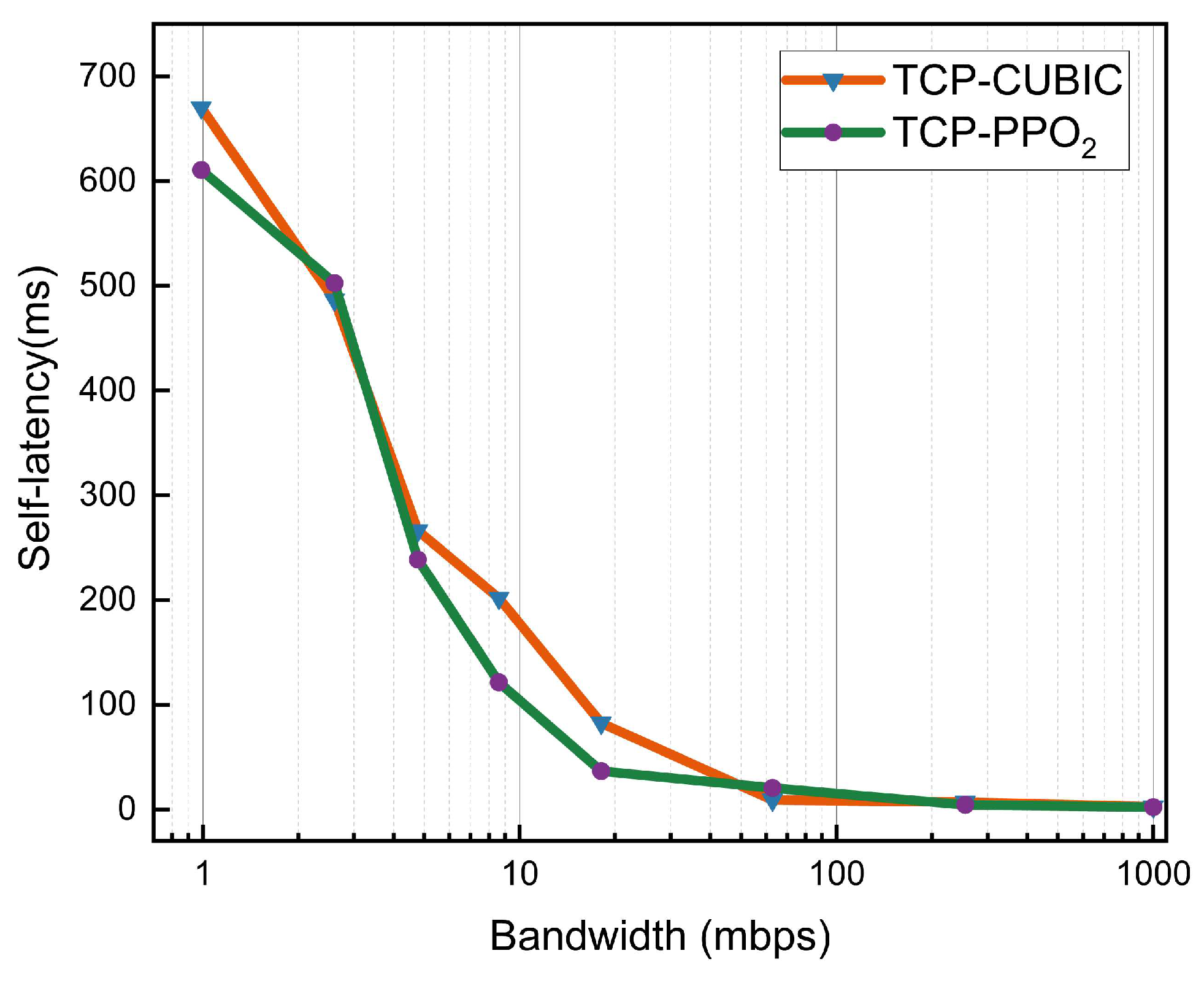
4.2. Bandwidth Sensitivity Comparison
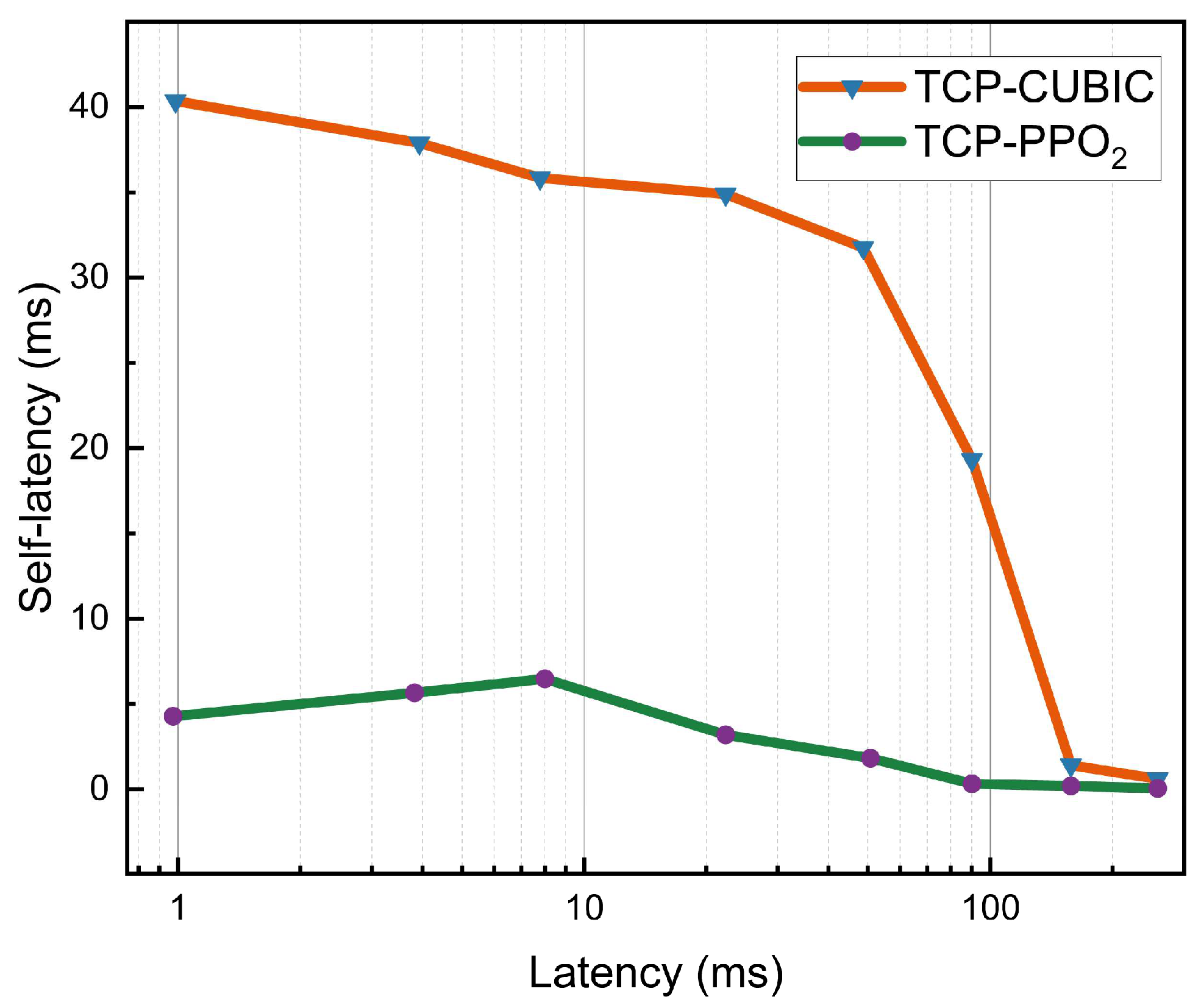
4.3. Latency Sensitivity
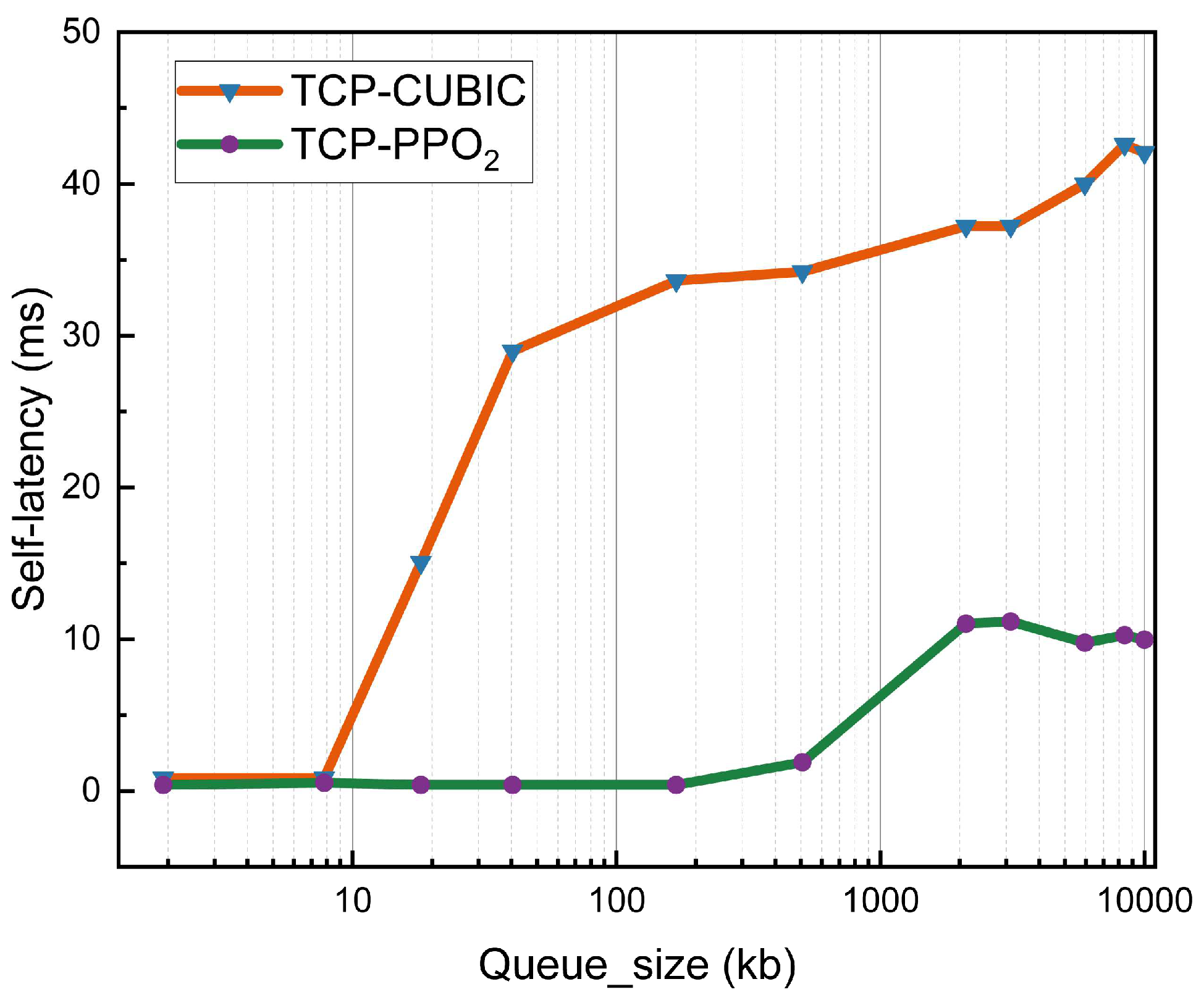
4.4. Queue Sensitivity
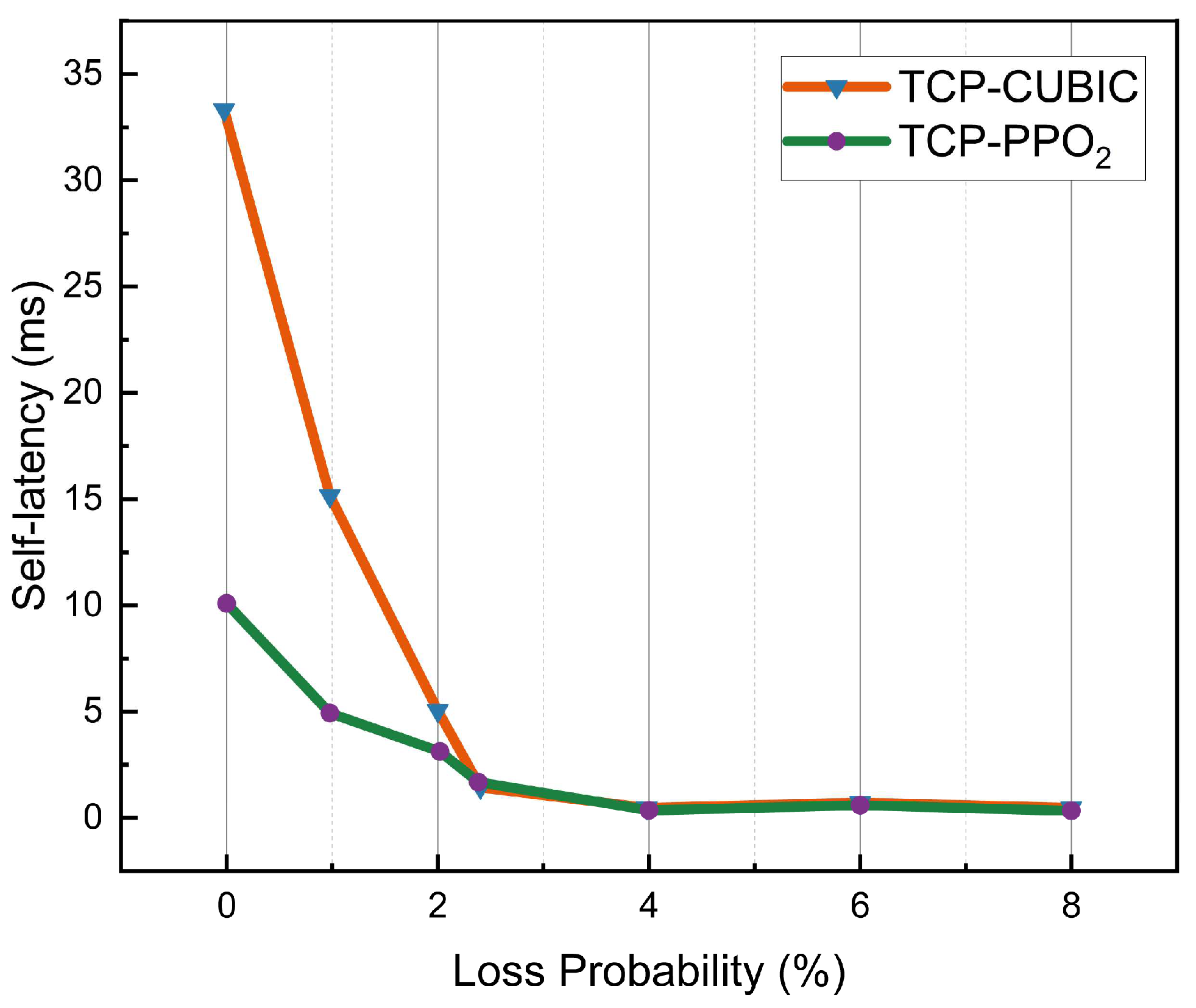
4.5. Packet Loss Sensitivity
5. Conclusions
- (1)
- Optimize the traditional TCP congestion control strategy by using the near-end policy optimization algorithm, map the system’s send rate to the behavior of deep reinforcement learning, set the reward function by balancing throughput, latency, and packet loss, and use a simple deep neural network to approximate the final strategy. Through the comparison of a large number of experimental data, the parameters such as the number of neural network layers, the number of neurons, and the length of the history were determined, and the optimization of TCP-PPO2 was successfully realized.
- (2)
- Through Mininet simulation experiments, it is determined that the TCP congestion control algorithm based on the proximity policy optimization adapts to network changes faster than the traditional TCP congestion control algorithm, changes the real-time congestion window size, improves transmission efficiency, and reduces the data transmission delay by 11.7–87.5%.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Henderson, T.; Floyd, S.; Gurtov, A. The NewReno Modification to TCP’s Fast Recovery Algorithm. 2012. Available online: https://www.rfc-editor.org/rfc/rfc6582.html (accessed on 12 April 2023).
- Ha, S.; Rhee, I.; Xu, L. CUBIC: A new TCP-friendly high-speed TCP variant. ACM SIGOPS Oper. Syst. Rev. 2008, 42, 64–74. [Google Scholar] [CrossRef]
- Mascolo, S.; Casetti, C.; Gerla, M.; Sanadidi, M.Y.; Wang, R. TCP Westwood: Bandwidth estimation for enhanced transport over wireless links. In Proceedings of the 7th Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 16 July 2001. [Google Scholar]
- Van Der Hooft, J.; Petrangeli, S.; Claeys, M.; Famaey, J.; Turck, F. A learning-based algorithm for improved bandwidth-awareness of adaptive streaming clients. In Proceedings of the 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015. [Google Scholar]
- Cui, L.; Yuan, Z.; Ming, Z.; Yang, S. Improving the congestion control performance for mobile networks in high-speed railway via deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 5864–5875. [Google Scholar] [CrossRef]
- Gu, L.; Zeng, D.; Li, W.; Guo, S.; Zomaya, A. Intelligent VNF orchestration and flow scheduling via model-assisted deep reinforcement learning. IEEE J. Sel. Areas Commun. 2019, 38, 279–291. [Google Scholar] [CrossRef]
- Xie, R.; Jia, X.; Wu, K. Adaptive online decision method for initial congestion window in 5G mobile edge computing using deep reinforcement learning. IEEE J. Sel. Areas Commun. 2019, 38, 389–403. [Google Scholar] [CrossRef]
- Xiao, K.; Mao, S.; Tugnait, J.K. TCP-Drinc: Smart congestion control based on deep reinforcement learning. IEEE Access 2019, 7, 11892–11904. [Google Scholar] [CrossRef]
- Bachl, M.; Zseby, T.; Fabini, J. Rax: Deep reinforcement learning for congestion control. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019. [Google Scholar]
- Li, W.; Zhou, F.; Chowdhury, K.R.; Meleis, W. QTCP: Adaptive congestion control with reinforcement learning. IEEE Trans. Netw. Sci. Eng. 2018, 6, 445–458. [Google Scholar] [CrossRef]
- Watkins, C.J.; Daya, P. Technical Note: Q-Learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Ha, T.; Masood, A.; Na, W.; Cho, S. Intelligent Multi-Path TCP Congestion Control for Video Streaming in Internet of Deep Space Things Communication. 2023. Available online: https://www.sciencedirect.com/science/article/pii/S2405959523000231 (accessed on 12 April 2023).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge: Cambridge, UK, 1994. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Andrei, A.; Rusu, J.; Marc, B.; Alex, G.; Martin, R.; Andreas, F.; Georg, O.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2016. [Google Scholar]
- Puterman, M.L. Markov decision processes. Handb. Oper. Res. Manag. Sci. 1990, 2, 331–434. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the International Conference On Machine Learning. 2015. Available online: https://proceedings.mlr.press/v37/schulman15.html (accessed on 12 April 2023).
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:150602438. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, H.; Wang, J. Intelligent TCP Congestion Control Policy Optimization. Appl. Sci. 2023, 13, 6644. https://doi.org/10.3390/app13116644
Shi H, Wang J. Intelligent TCP Congestion Control Policy Optimization. Applied Sciences. 2023; 13(11):6644. https://doi.org/10.3390/app13116644
Chicago/Turabian StyleShi, Hanbing, and Juan Wang. 2023. "Intelligent TCP Congestion Control Policy Optimization" Applied Sciences 13, no. 11: 6644. https://doi.org/10.3390/app13116644
APA StyleShi, H., & Wang, J. (2023). Intelligent TCP Congestion Control Policy Optimization. Applied Sciences, 13(11), 6644. https://doi.org/10.3390/app13116644