
Continuous Latent Spaces Sampling for Graph Autoencoder


Abstract
:1. Introduction
2. Related Work
2.1. Graph Neural Networks
2.2. Graph Contrastive Learning
2.3. Graph AutoEncoders
3. Preliminaries
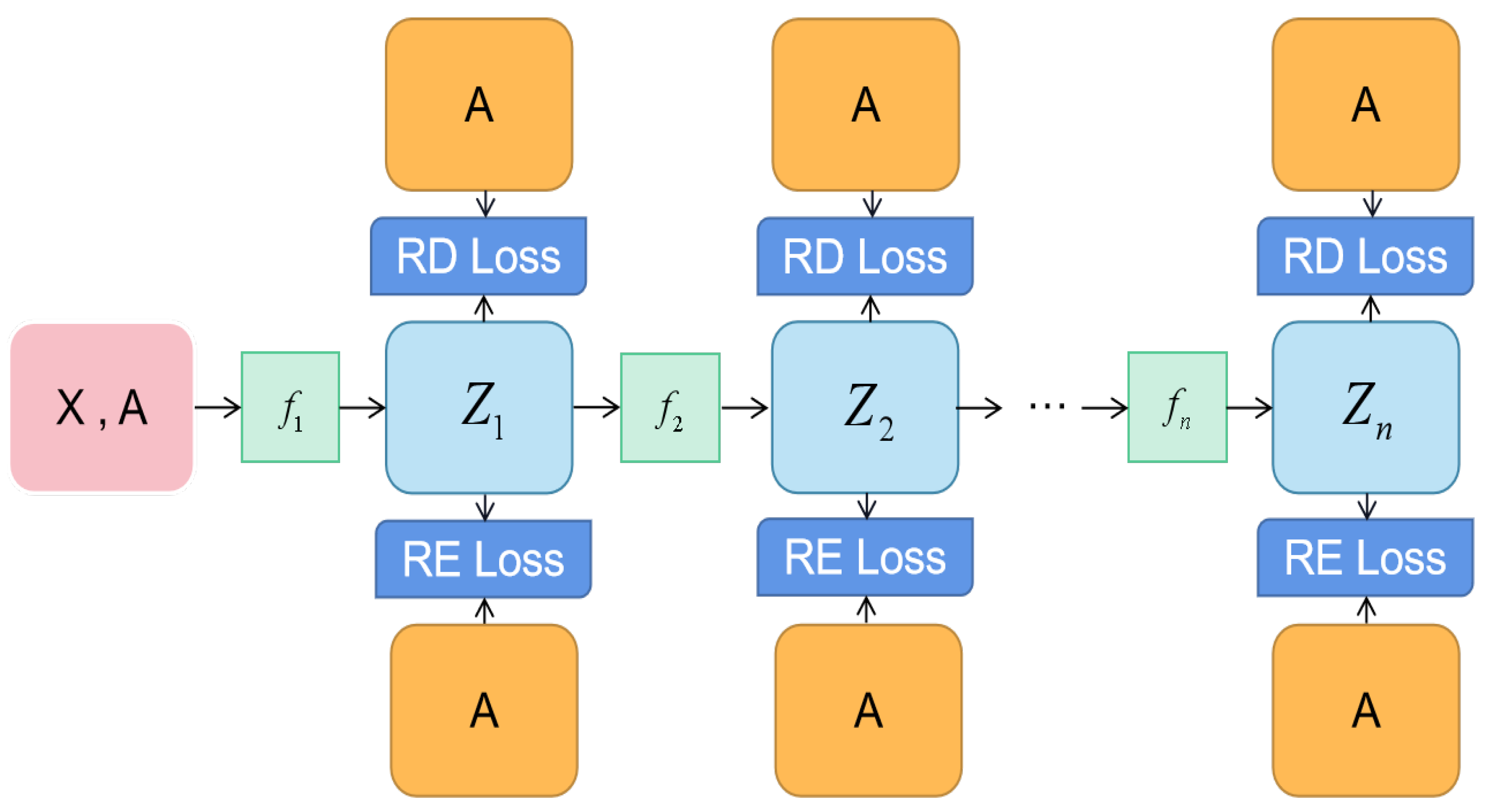
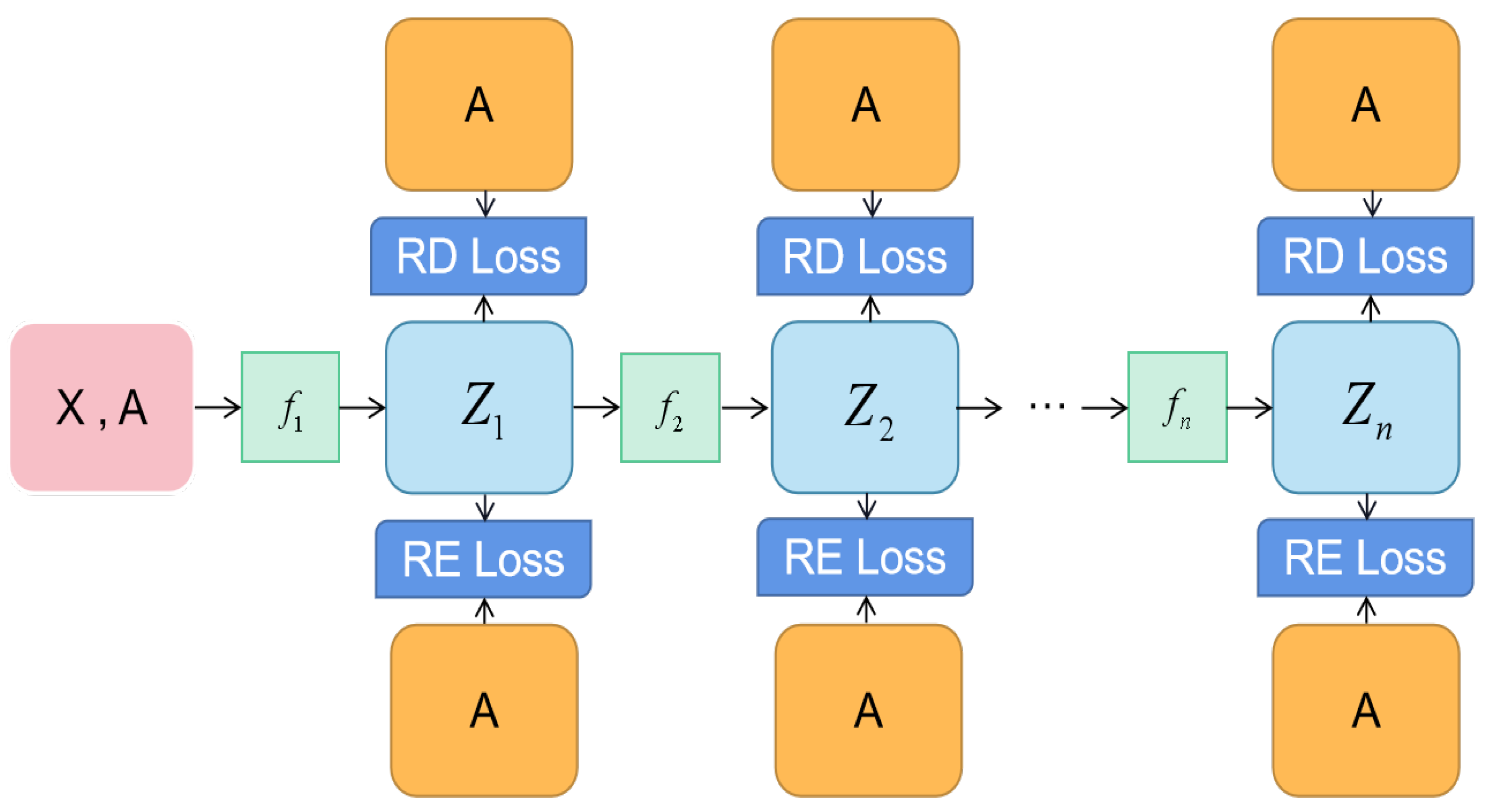
4. Present Work: colaGAE
4.1. Motivation
4.2. Encoder
4.3. Decoder
4.4. Learning Objective
4.5. Reconstruction Loss
4.6. Relative Distance Loss
4.7. Training and Evaluating Setups
| Algorithm 1: Pseudocode of colaGAE in Pytorch-like style. |
# A: adjacency matrix # alpha: coefficient of reconstruction loss # beta: coefficient of relative distance loss # model: GCN + mlp layers class encoder(): def _ _init_ _(self, n_layers = 1): super(encoder, self)._ _init_ _() basic_block = [ Linear(), Sigmoid(), BatchNorm1d() ] basic_block *= n_layers self.proj = nn.Sequential(∗basic_block) def forward(self, x): x = self.proj(x) return x def reconstruction_loss(z,A): zz = z@z.T loss = F.mse_loss(zz,A) loss += F.binary_cross_entropy_with_logits(zz,A) return loss def relative_distance_loss(z,A): distance = z@z.T loss = (distance∗A).sum() / (distance∗(1-A)).sum() return -torch.log(loss) # to deal with large graphs, we need to sample their subGraphs for subGraph in Graph: # transfer subGraphs into low-dimensional representation z0 = GCN(subGraph) z1 = encoder(z0) ; z2 = encoder(z1) z3 = encoder(z2) ; z4 = encoder(z3) z5 = encoder(z4) ; z6 = encoder(z5) z7 = encoder(z6) ; z8 = encoder(z7) loss = 0 for z in [z0,z1,z2,z3,z4]: # A_sub is the adjacency graph of the subGraph re_loss = reconstruction_loss(z,A_sub) rd_loss = relative_distance_loss(z,A_sub) # add losses loss += alpha∗re_loss + beta∗rd_loss # Adam optimizer loss.backward() update(model.params) with torch.no_grad(): evaluation(model) |
5. Experiments
5.1. Datasets
- Cora, Citeseer, and Pubmed: [21]: three standard citation networks in which nodes are documents and edges indicate citation relations. In the experiments, they are employed for node classification (transductive) and clustering tasks.
- Computer and Photo: Amazon Computers and Amazon Photo are segments of the Amazon co-purchase graph, where nodes represent goods, edges indicate that two goods are frequently purchased together, node features are bag-of-words encoded product reviews, and class labels are provided by the product category.
- Coauthor CS: Coauthor CS is co-authorship graph based on the Microsoft Academic Graph from the KDD Cup 2016 challenge. Here, nodes are authors, which are connected by an edge if they co-authored a paper, node features represent paper keywords for each author’s papers, and class labels indicate the most active fields of study for each author.
- arxiv and MAG: The obgn-arxiv and ogbn-mag datasets are two large datasets from Open Graph Benchmark [38]. The datasets are collected from real-world networks belonging to different domains. Each node is associated with a 128-dimensional word2vec feature vector, and all the other types of entities are not associated with input node features.
5.2. Compared Methods
5.3. Training and Evaluating Setups
5.4. Software and Hardware Infrastructures
5.5. Results
6. Performance Comparison on Link Prediction
7. Ablation Study
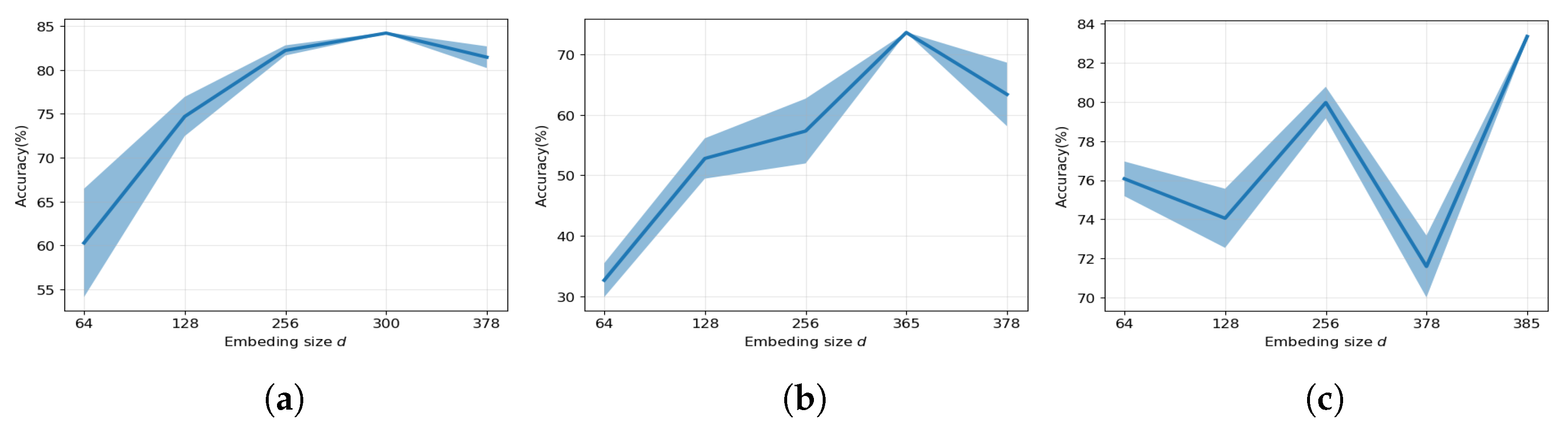
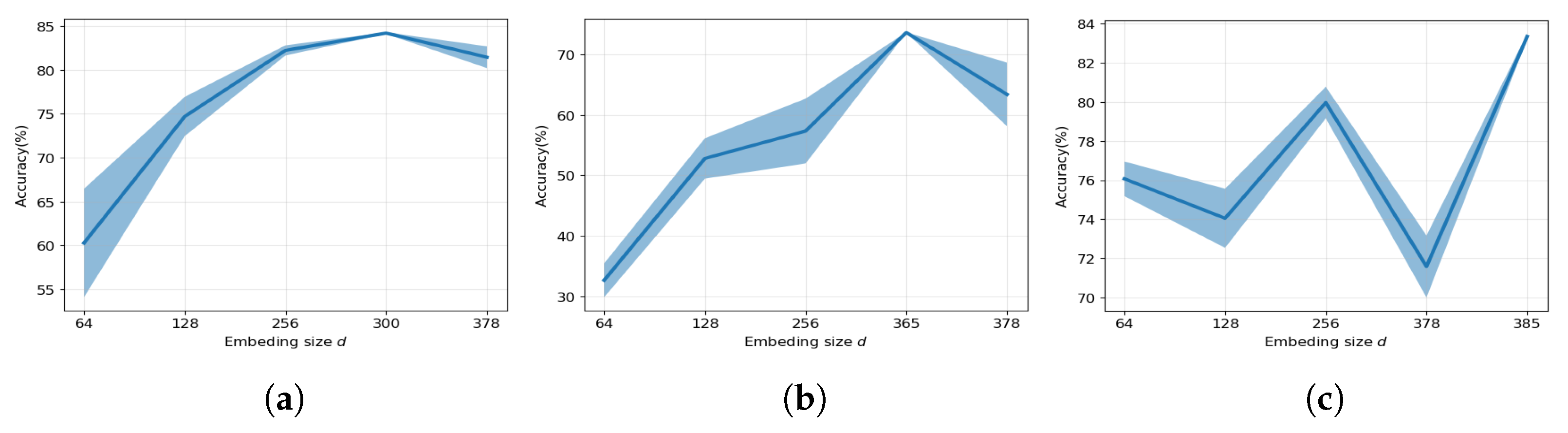
7.1. Effect of Embedding Size
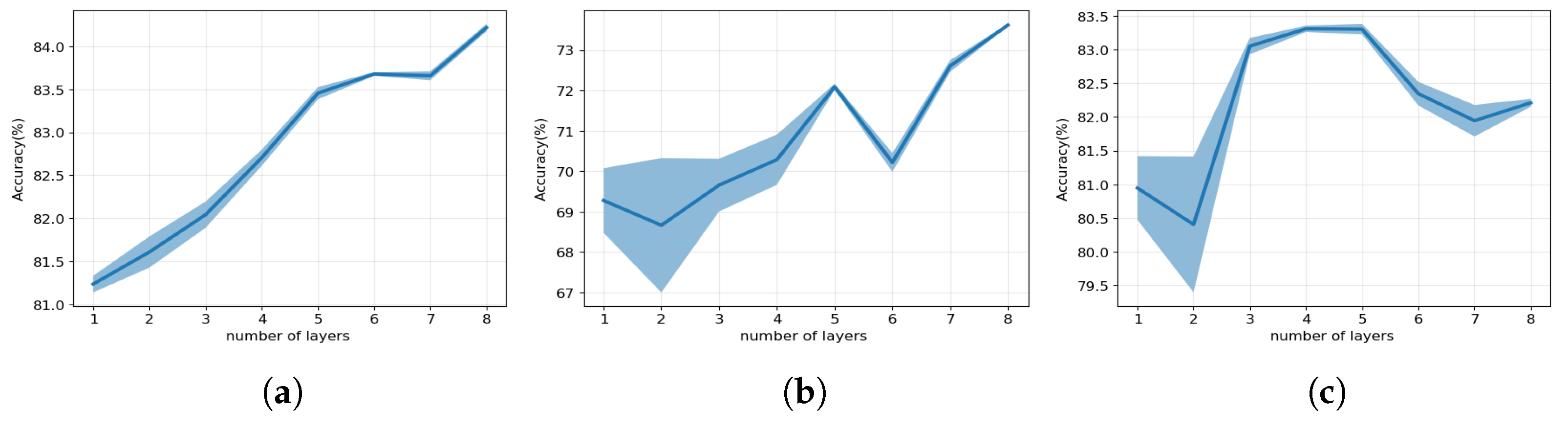
7.2. Effect of the Number of Layers
7.3. Effect of Encoders
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.; Bridgland, A.; et al. Improved protein structure prediction using potentials from deep learning. Nature 2020, 577, 706–710. [Google Scholar] [CrossRef] [PubMed]
- Shlomi, J.; Battaglia, P.; Vlimant, J.R. Graph neural networks in particle physics. Mach. Learn. Sci. Technol. 2020, 2, 021001. [Google Scholar] [CrossRef]
- Hamilton, W.L. Graph Representation Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2020, 14, 1–159. [Google Scholar]
- Zhu, Y.; Xu, Y.; Yu, F.; Liu, Q.; Wu, S.; Wang, L. Deep graph contrastive representation learning. arXiv 2020, arXiv:2006.04131. [Google Scholar]
- Hu, W.; Liu, B.; Gomes, J.; Zitnik, M.; Liang, P.; Pande, V.; Leskovec, J. Strategies for pre-training graph neural networks. arXiv 2019, arXiv:1905.12265. [Google Scholar]
- Sun, F.Y.; Hoffman, J.; Verma, V.; Tang, J. InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. ICLR (Poster) 2019, 2, 4. [Google Scholar]
- Qiu, J.; Chen, Q.; Dong, Y.; Zhang, J.; Yang, H.; Ding, M.; Wang, K.; Tang, J. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. In Proceedings of the KDD, Virtual Event, 23–27 August 2020. [Google Scholar]
- Thakoor, S.; Tallec, C.; Azar, M.G.; Munos, R.; Veličković, P.; Valko, M. Bootstrapped representation learning on graphs. In Proceedings of the ICLR 2021 Workshop on Geometrical and Topological Representation Learning, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zhu, Y.; Xu, Y.; Yu, F.; Liu, Q.; Wu, S.; Wang, L. Graph contrastive learning with adaptive augmentation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2069–2080. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Hou, Z.; Liu, X.; Dong, Y.; Wang, C.; Tang, J.; Wang, C.; Tang, J. GraphMAE: Self-Supervised Masked Graph Autoencoders. arXiv 2022, arXiv:2205.10803. [Google Scholar]
- Li, J.; Wu, R.; Sun, W.; Chen, L.; Tian, S.; Zhu, L.; Meng, C.; Zheng, Z.; Wang, W. MaskGAE: Masked Graph Modeling Meets Graph Autoencoders. arXiv 2022, arXiv:2205.10053. [Google Scholar]
- Pan, S.; Hu, R.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Adversarially regularized graph autoencoder for graph embedding. arXiv 2018, arXiv:1802.04407. [Google Scholar]
- Hassani, K.; Khasahmadi, A.H. Contrastive multi-view representation learning on graphs. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 4116–4126. [Google Scholar]
- Wu, L.; Lin, H.; Tan, C.; Gao, Z.; Li, S.Z. Self-supervised learning on graphs: Contrastive, generative, or predictive. arXiv 2021, arXiv:2105.07342. [Google Scholar] [CrossRef]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhang, H.; Wu, Q.; Yan, J.; Wipf, D.; Yu, P.S. From canonical correlation analysis to self-supervised graph neural networks. In Proceedings of the NeurIPS, Virtual Event, 6–14 December 2021. [Google Scholar]
- Liu, Y.; Jin, M.; Pan, S.; Zhou, C.; Zheng, Y.; Xia, F.; Philip, S.Y. Graph self-supervised learning: A survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 5879–5900. [Google Scholar] [CrossRef]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph contrastive learning with augmentations. In Proceedings of the NeurIPS, Virtual Event, 6–12 December 2020. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1–12. [Google Scholar]
- Xu, B.; Shen, H.; Cao, Q.; Qiu, Y.; Cheng, X. Graph Wavelet Neural Network. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Klicpera, J.; Weißenberger, S.; Günnemann, S. Diffusion improves graph learning. Adv. Neural Inf. Process. Syst. 2019, 32, 13354–13366. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive multiview coding. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 776–794. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and Deep Graph Convolutional Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Jin, M.; Zheng, Y.; Li, Y.F.; Gong, C.; Zhou, C.; Pan, S. Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning. arXiv 2021, arXiv:2105.05682. [Google Scholar]
- Lee, N.; Lee, J.; Park, C. Augmentation-free self-supervised learning on graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2022; Volume 36, pp. 7372–7380. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Chang, K.W.; Sun, Y. Gpt-gnn: Generative pre-training of graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1857–1867. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhang, S.; Liu, Y.; Sun, Y.; Shah, N. Graph-less Neural Networks: Teaching Old MLPs New Tricks Via Distillation. In Proceedings of the ICLR, Virtual Event, 25–29 April 2022. [Google Scholar]
- Hu, W.; Fey, M.; Zitnik, M.; Dong, Y.; Ren, H.; Liu, B.; Catasta, M.; Leskovec, J. Open graph benchmark: Datasets for machine learning on graphs. Adv. Neural Inf. Process. Syst. 2020, 33, 22118–22133. [Google Scholar]
- Peng, Z.; Huang, W.; Luo, M.; Zheng, Q.; Rong, Y.; Xu, T.; Huang, J. Graph representation learning via graphical mutual information maximization. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 259–270. [Google Scholar]
- Mo, Y.; Peng, L.; Xu, J.; Shi, X.; Zhu, X. Simple Unsupervised Graph Representation Learning. In Proceedings of the AAAI, Vancouver, BC, Canada, 22 February 2022. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the JMLR Workshop and Conference Proceedings, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nodes | Edges | Classes | Features | Density |
|---|---|---|---|---|---|
| Cora | 2708 | 10,556 | 7 | 1433 | 0.288% |
| Citeseer | 3327 | 9228 | 6 | 3703 | 0.167% |
| Pubmed | 19,717 | 88,651 | 3 | 500 | 0.046% |
| CS | 18,333 | 327,576 | 15 | 6805 | 0.195% |
| Computer | 13,752 | 574,418 | 10 | 767 | 0.608% |
| Photo | 7650 | 287,326 | 8 | 745 | 0.982% |
| Arxiv | 169,343 | 1,166,243 | 40 | 128 | 0.008% |
| MAG | 1,939,743 | 21,111,007 | 349 | 128 | 0.001% |
| Cora | CiteSeer | PubMed | Photo | Computer | arXiv | MAG | Coauthor-CS | |
|---|---|---|---|---|---|---|---|---|
| MLP | 47.90 | 49.30 | 69.10 | 78.50 | 73.80 | 56.30 | 22.10 | 90.37 |
| GCN | 81.50 | 70.30 | 79.00 | 92.42 | 86.51 | 70.40 | 30.10 | 90.52 |
| GAT | 83.00 | 72.50 | 79.00 | 92.56 | 86.93 | 70.60 | 30.50 | 91.10 |
| DGI | 82.30 | 71.80 | 76.80 | 91.61 | 83.95 | 65.10 | 31.40 | 92.15 |
| GMI | 83.00 | 72.40 | 79.90 | 90.68 | 82.21 | 68.20 | 29.50 | - |
| GRACE | 81.90 | 71.20 | 80.60 | 92.15 | 86.25 | 68.70 | 31.50 | 90.10 |
| GCA | 81.80 | 71.90 | 81.00 | 92.53 | 87.85 | 68.20 | 31.40 | 93.08 |
| MVGRL | 82.90 | 72.60 | 80.10 | 91.70 | 86.90 | 68.10 | 31.60 | 92.11 |
| BGRL | 82.86 | 71.41 | 82.05 | 93.17 | 90.34 | 71.64 | 31.11 | 93.3 |
| SUGRL | 83.40 | 73.00 | 81.90 | 93.20 | 88.90 | 69.30 | 32.40 | 92.20 |
| CCA-SSG | 83.59 | 73.36 | 80.81 | 93.14 | 88.74 | 52.55 | 23.39 | 93.06 |
| GAE | 74.90 | 65.60 | 74.20 | 91.00 | 85.10 | 63.60 | 27.10 | 90.01 |
| VGAE | 76.30 | 66.80 | 75.80 | 91.50 | 85.80 | 64.80 | 27.90 | 92.11 |
| ARGA | 77.95 | 64.44 | 80.44 | 91.82 | 85.86 | 67.34 | 28.36 | 90.09 |
| ARVGA | 79.50 | 66.03 | 81.51 | 91.51 | 86.02 | 67.43 | 28.32 | 91.21 |
| GraphMAE | 84.20 | 73.40 | 81.10 | 92.86 | 88.06 | 71.75 | 31.67 | 92.89 |
| MaskGAE | 84.05 | 73.49 | 83.06 | 93.09 | 89.51 | 70.73 | 32.79 | 93.00 |
| colaGAE | 84.23 | 73.61 | 83.33 | 93.00 | 90.05 | 72.21 | 31.09 | 93.07 |
| Cora | CiteSeer | PubMed | ||||
|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | |
| GAE | 91.09 | 92.83 | 90.52 | 91.68 | 96.40 | 96.50 |
| VGAE | 91.40 | 92.60 | 90.80 | 92.00 | 94.40 | 94.70 |
| ARGA | 92.40 | 93.23 | 91.94 | 93.03 | 96.81 | 97.11 |
| ARVGA | 92.40 | 92.60 | 92.40 | 93.00 | 96.50 | 96.80 |
| SAGE | 86.33 | 88.24 | 85.65 | 87.90 | 89.22 | 89.44 |
| MGAE | 95.05 | 94.50 | 94.85 | 94.68 | 98.45 | 98.22 |
| colaGAE | 96.37 | 96.24 | 98.01 | 97.92 | 98.46 | 98.19 |
| Dataset | MLP | GCN | GAT | GraphSAGE | GRACE |
|---|---|---|---|---|---|
| Cora | 72.51 | 84.23 | 84.43 | 83.97 | 85.14 |
| Citeseer | 65.41 | 73.61 | 72.19 | 73.81 | 74.08 |
| Pubmed | 80.19 | 83.33 | 82.90 | 82.65 | 84.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhao, G.; Ning, H.; Jin, X.; Yu, H. Continuous Latent Spaces Sampling for Graph Autoencoder. Appl. Sci. 2023, 13, 6491. https://doi.org/10.3390/app13116491
Li Z, Zhao G, Ning H, Jin X, Yu H. Continuous Latent Spaces Sampling for Graph Autoencoder. Applied Sciences. 2023; 13(11):6491. https://doi.org/10.3390/app13116491
Chicago/Turabian StyleLi, Zhongyu, Geng Zhao, Hao Ning, Xin Jin, and Haoyang Yu. 2023. "Continuous Latent Spaces Sampling for Graph Autoencoder" Applied Sciences 13, no. 11: 6491. https://doi.org/10.3390/app13116491
APA StyleLi, Z., Zhao, G., Ning, H., Jin, X., & Yu, H. (2023). Continuous Latent Spaces Sampling for Graph Autoencoder. Applied Sciences, 13(11), 6491. https://doi.org/10.3390/app13116491