


Emotional State Detection Using Electroencephalogram Signals: A Genetic Algorithm Approach

 , ,
, ,  , ,
, ,  , , , and
, , , and 
Abstract
1. Introduction
2. Materials and Methods
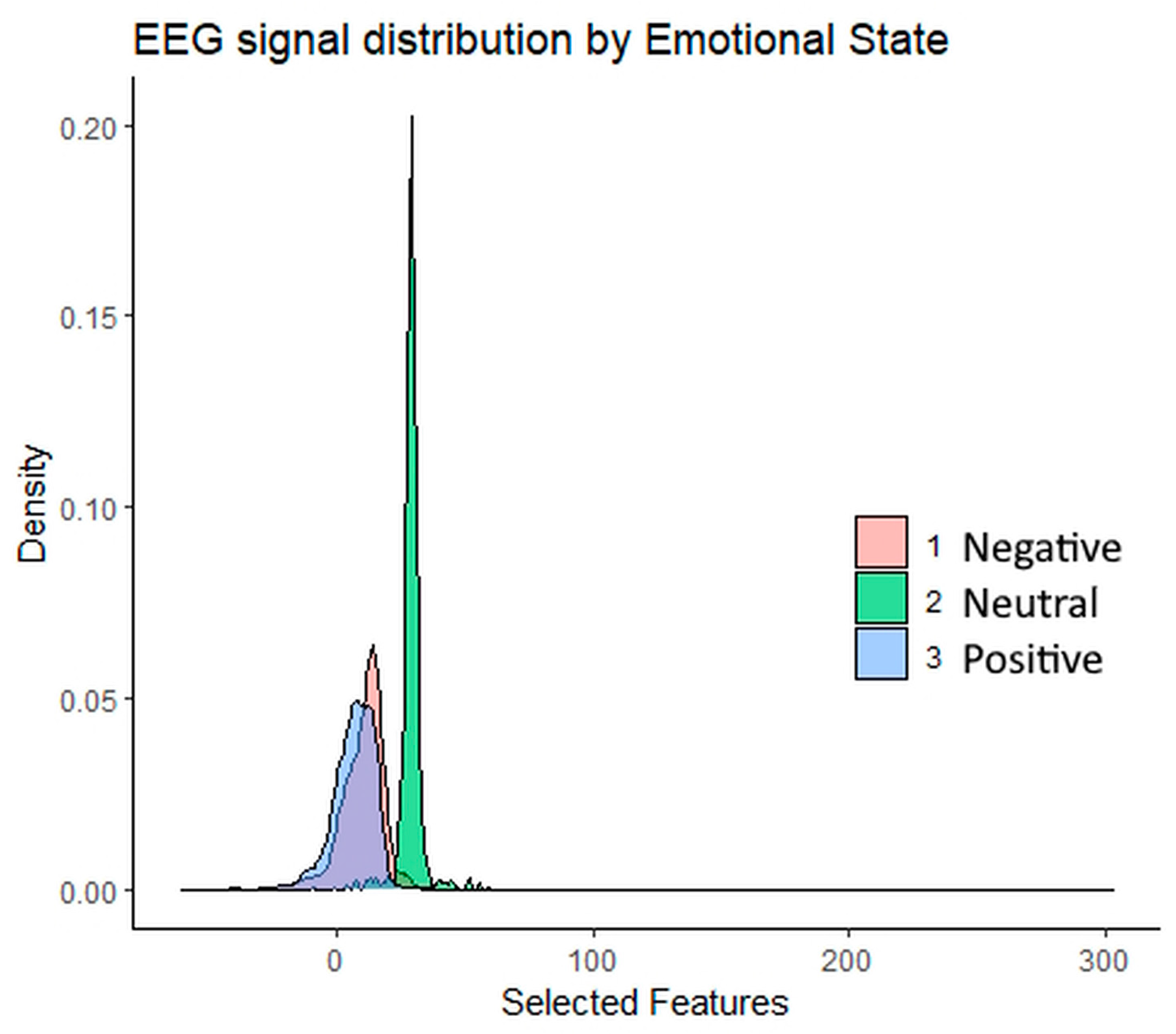
2.1. Data Description
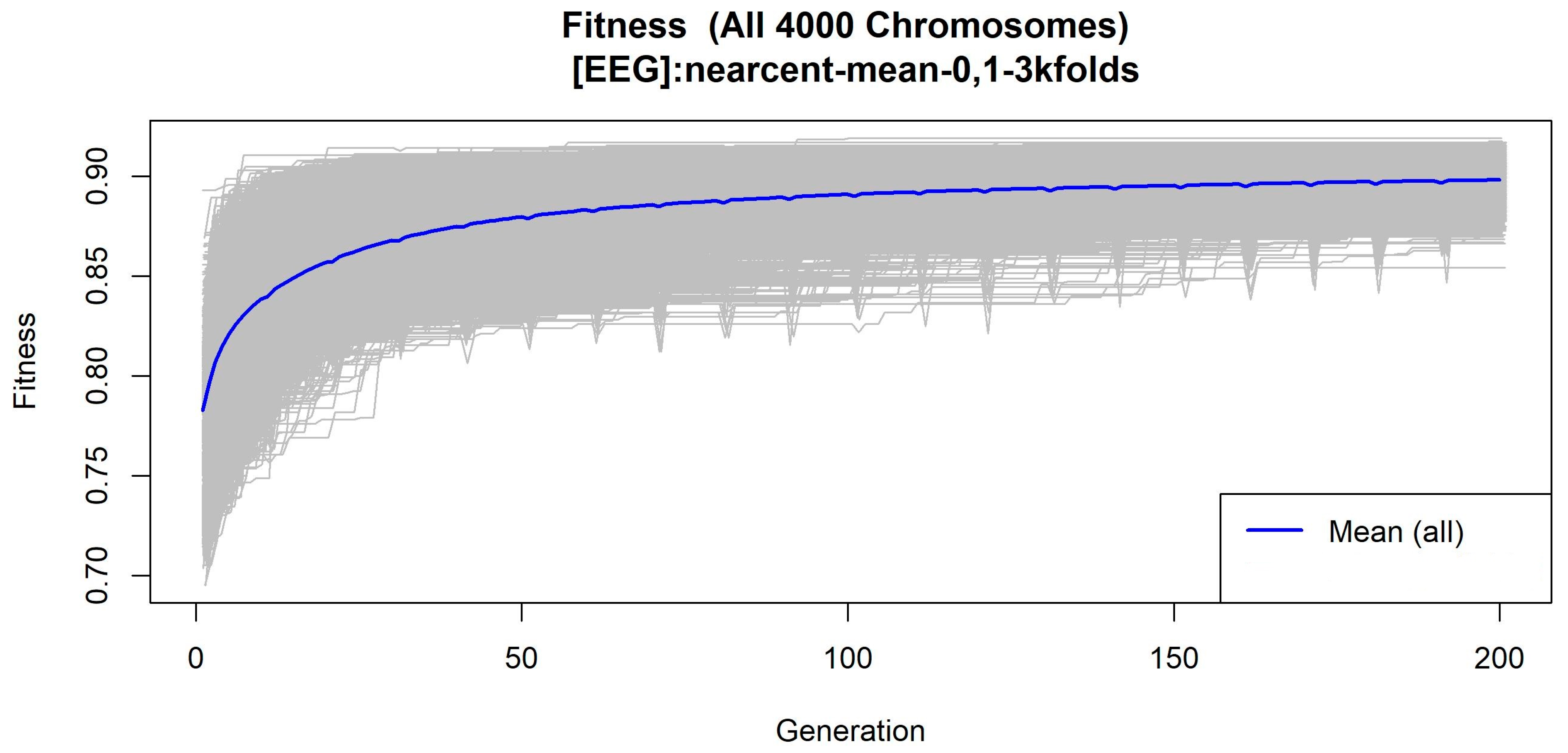
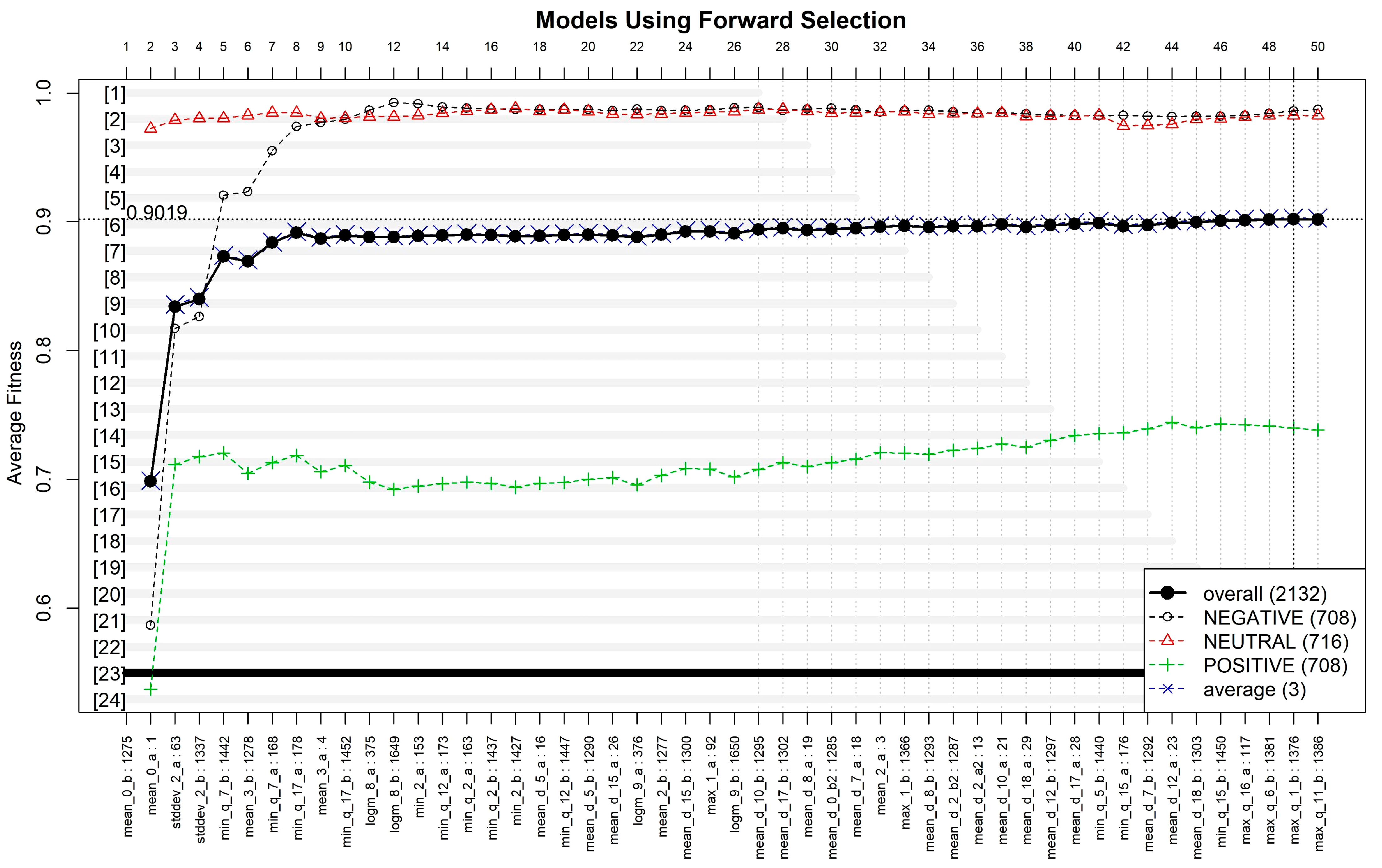
2.2. Feature Selection
- Step 1: creation of a random initial population of chromosomes, which in this case are sets of 5 genes or features.
- Step 2: consisting in the evaluation of the capability of the chromosomes to predict the different emotional states, with this creating a statistical model, the GA assigns a score to each chromosome, and this score is proportional to the resulting accuracy of the model. In this study, the nearest centroid classifier is used in the model.
- Step 3: if the score in the previous step is higher than that of the defined fitness goal, the chromosome is selected; if it is not, the process continues.
- Step 4: the chromosomes best suited to the problem are replicated; the higher the score, the bigger the offspring.
- Step 5: the crossover consists of a recombination of pairs of good chromosomes from the genetic information of the replicated parents.
- Step 6: the mutations created in Step 5 are now included in the new population, allowing new genes to be included in the chromosomes.
- Step 7: the process is repeated from Step 2 onwards until a solution is found; each cycle from Step 4 to Step 6 is referred to as a generation.

2.3. ML Model Implementation
2.3.1. Random Forest
2.3.2. k-Nearest Neighbor
2.3.3. Artificial Neural Networks
2.4. Model Validation
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, J.H.; Poulose, A.; Han, D.S. The Extensive Usage of the Facial Image Threshing Machine for Facial Emotion Recognition Performance. Sensors 2021, 21, 2026. [Google Scholar] [CrossRef] [PubMed]
- Canal, F.Z.; Müller, T.R.; Matias, J.C.; Scotton, G.G.; de Sa Junior, A.R.; Pozzebon, E.; Sobieranski, A.C. A Survey on Facial Emotion Recognition Techniques: A State-of-the-Art Literature Review. Inf. Sci. 2022, 582, 593–617. [Google Scholar] [CrossRef]
- Karnati, M.; Seal, A.; Bhattacharjee, D.; Yazidi, A.; Krejcar, O. Understanding Deep Learning Techniques for Recognition of Human Emotions Using Facial Expressions: A Comprehensive Survey. IEEE Trans. Instrum. Meas. 2023, 72, 1–31. [Google Scholar] [CrossRef]
- Kakuba, S.; Poulose, A.; Han, D.S. Deep Learning-Based Speech Emotion Recognition Using Multi-Level Fusion of Concurrent Features. IEEE Access 2022, 10, 125538–125551. [Google Scholar] [CrossRef]
- Yan, Y.; Shen, X. Research on Speech Emotion Recognition Based on AA-CBGRU Network. Electronics 2022, 11, 1409. [Google Scholar] [CrossRef]
- Soman, G.; Vivek, M.V.; Judy, M.V.; Papageorgiou, E.; Gerogiannis, V.C. Precision-Based Weighted Blending Distributed Ensemble Model for Emotion Classification. Algorithms 2022, 15, 55. [Google Scholar] [CrossRef]
- Lin, W.; Li, C. Review of Studies on Emotion Recognition and Judgment Based on Physiological Signals. Appl. Sci. 2023, 13, 2573. [Google Scholar] [CrossRef]
- Awais, M.; Raza, M.; Singh, N.; Bashir, K.; Manzoor, U.; Islam, S.U.; Rodrigues, J.J.P.C. LSTM-Based Emotion Detection Using Physiological Signals: IoT Framework for Healthcare and Distance Learning in COVID-19. IEEE Internet Things J. 2021, 8, 16863–16871. [Google Scholar] [CrossRef]
- AlZoubi, O.; D’Mello, S.K.; Calvo, R.A. Detecting Naturalistic Expressions of Nonbasic Affect Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 298–310. [Google Scholar] [CrossRef]
- Albraikan, A.; Tobon, D.P.; El Saddik, A. Toward User-Independent Emotion Recognition Using Physiological Signals. IEEE Sens. J. 2019, 19, 8402–8412. [Google Scholar] [CrossRef]
- Chao, H.; Dong, L. Emotion Recognition Using Three-Dimensional Feature and Convolutional Neural Network from Multichannel EEG Signals. IEEE Sens. J. 2021, 21, 2024–2034. [Google Scholar] [CrossRef]
- Egger, M.; Ley, M.; Hanke, S. Emotion Recognition from Physiological Signal Analysis: A Review. Electron. Notes Theor. Comput. Sci. 2019, 343, 35–55. [Google Scholar] [CrossRef]
- Santamaria-Granados, L.; Munoz-Organero, M.; Ramirez-Gonzalez, G.; Abdulhay, E.; Arunkumar, N. Using Deep Convolutional Neural Network for Emotion Detection on a Physiological Signals Dataset (AMIGOS). IEEE Access 2019, 7, 57–67. [Google Scholar] [CrossRef]
- Saganowski, S.; Perz, B.; Polak, A.; Kazienko, P. Emotion Recognition for Everyday Life Using Physiological Signals from Wearables: A Systematic Literature Review. IEEE Trans. Affect. Comput. 2022, 12, 1. [Google Scholar] [CrossRef]
- Bota, P.J.; Wang, C.; Fred, A.L.N.; Placido Da Silva, H. A Review, Current Challenges, and Future Possibilities on Emotion Recognition Using Machine Learning and Physiological Signals. IEEE Access 2019, 7, 140990–141020. [Google Scholar] [CrossRef]
- Sepúlveda, A.; Castillo, F.; Palma, C.; Rodriguez-Fernandez, M. Emotion Recognition from ECG Signals Using Wavelet Scattering and Machine Learning. Appl. Sci. 2021, 11, 4945. [Google Scholar] [CrossRef]
- Sedik, A.; Marey, M.; Mostafa, H. WFT-Fati-Dec: Enhanced Fatigue Detection AI System Based on Wavelet Denoising and Fourier Transform. Appl. Sci. 2023, 13, 2785. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A Review on Genetic Algorithm: Past, Present, and Future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Salih, O.; Duffy, K.J. Optimization Convolutional Neural Network for Automatic Skin Lesion Diagnosis Using a Genetic Algorithm. Appl. Sci. 2023, 13, 3248. [Google Scholar] [CrossRef]
- Al-Tawil, M.; Mahafzah, B.A.; Al Tawil, A.; Aljarah, I. Bio-Inspired Machine Learning Approach to Type 2 Diabetes Detection. Symmetry 2023, 15, 764. [Google Scholar] [CrossRef]
- Lin, Z.-H.; Woo, J.-C.; Luo, F.; Chen, Y.-T. Research on Sound Imagery of Electric Shavers Based on Kansei Engineering and Multiple Artificial Neural Networks. Appl. Sci. 2022, 12, 10329. [Google Scholar] [CrossRef]
- Yu, S.-N.; Chen, S.-F. Emotion State Identification Based on Heart Rate Variability and Genetic Algorithm. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 538–541. [Google Scholar]
- Abuqaddom, I.; Mahafzah, B.A.; Faris, H. Oriented Stochastic Loss Descent Algorithm to Train Very Deep Multi-Layer Neural Networks without Vanishing Gradients. Knowl.-Based Syst. 2021, 230, 107391. [Google Scholar] [CrossRef]
- Ragot, M.; Martin, N.; Em, S.; Pallamin, N.; Diverrez, J.-M. Emotion Recognition Using Physiological Signals: Laboratory vs. Wearable Sensors. In Proceedings of the AHFE 2017 International Conference on Advances in Human Factors and Wearable Technologies, Los Angeles, CA, USA, 17–21 July 2017; pp. 15–22. [Google Scholar]
- Bird, J.J.; Manso, L.J.; Ribeiro, E.P.; Ekart, A.; Faria, D.R. A Study on Mental State Classification Using EEG-Based Brain-Machine Interface. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal, Portugal, 25–27 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 795–800. [Google Scholar]
- Bird, J.J.; Ekart, A.; Buckingham, C.D.; Faria, D.R. Mental Emotional Sentiment Classification with an Eeg-Based Brain-Machine Interface. In Proceedings of the International Conference on Digital Image and Signal Processing, Oxford, UK, 29–30 April 2019. [Google Scholar]
- Ashford, J.; Bird, J.J.; Campelo, F.; Faria, D.R. Classification of EEG Signals Based on Image Representation of Statistical Features. In Advances in Computational Intelligence Systems: Contributions Presented at the 19th UK Workshop on Computational Intelligence, Portsmouth, UK, 4–6 September 2019; Springer: Cham, Switzerland, 2020; pp. 449–460. [Google Scholar]
- Liu, Z.T.; Xie, Q.; Wu, M.; Cao, W.H.; Li, D.Y.; Li, S.H. Electroencephalogram Emotion Recognition Based on Empirical Mode Decomposition and Optimal Feature Selection. IEEE Trans. Cogn. Dev. Syst. 2019, 11, 517–526. [Google Scholar] [CrossRef]
- Xu, H.; Wang, X.; Li, W.; Wang, H.; Bi, Q. Research on EEG Channel Selection Method for Emotion Recognition. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, ROBIO 2019, Dali, China, 6–8 December 2019; pp. 2528–2535. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Holland, J.H. Genetic Algorithms and Machine Learning. Mach. Learn. 1988, 3, 95–99. [Google Scholar] [CrossRef]
- Trevino, V.; Falciani, F. GALGO: An R Package for Multivariate Variable Selection Using Genetic Algorithms. Bioinformatics 2006, 22, 1154–1156. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Houssein, E.H.; Hammad, A.; Ali, A.A. Human Emotion Recognition from EEG-Based Brain–Computer Interface Using Machine Learning: A Comprehensive Review. Neural Comput. Appl. 2022, 34, 12527–12557. [Google Scholar] [CrossRef]
- Fausett, L.V. Fundamentals of Neural Networks: Architectures, Algorithms and Applications; Pearson Education: Chennai, India, 2006. [Google Scholar]
- Irizarry, R.A. Introduction to Data Science: Data Analysis and Prediction Algorithms with R; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Pilnenskiy, N.; Smetannikov, I. Feature Selection Algorithms as One of the Python Data Analytical Tools. Future Internet 2020, 12, 54. [Google Scholar] [CrossRef]
- Fabian, P. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Classification method | Nearcent |
| Chromosome size | 5 |
| Solutions | 4000 |
| Generations | 200 |
| Goal fitness | 1 |
| Actually Positive | Actually Negative | |
|---|---|---|
| Predicted Positive | True positives (TP) | False positives (FP) |
| Predicted Negative | False negatives (FN) | True negatives (TN) |
| Model 23′s Features |
|---|
| “mean_0_b”, “mean_0_a”, “stddev_2_a”, “stddev_2_b”, “min_q_7_b”, “mean_3_b”, “min_q_7_a”, “min_q_17_a”, “mean_3_a”, “min_q_17_b”, “logm_8_a”, “logm_8_b”, “min_2_a”, “min_q_12_a”, “min_q_2_a”, “min_q_2_b”, “min_2_b”, “mean_d_5_a”, “min_q_12_b”, “mean_d_5_b”, “mean_d_15_a”, “logm_9_a”, “mean_2_b”, “mean_d_15_b”, “max_1_a”, “logm_9_b”, “mean_d_10_b”, “mean_d_17_b”, “mean_d_8_a”, “mean_d_0_b2”, “mean_d_7_a”, “mean_2_a”, “max_1_b”, “mean_d_8_b”, “mean_d_2_b2”, “mean_d_2_a2”, “mean_d_10_a”, “mean_d_18_a”, “mean_d_12_b”, “mean_d_17_a”, “min_q_5_b”, “min_q_15_a”, “mean_d_7_b”, “mean_d_12_a”, “mean_d_18_b”, “min_q_15_b”, “max_q_16_a”, “max_q_6_b”, “max_q_1_b”. |
| KNN | RF | ANN | |
|---|---|---|---|
| Overall Accuracy | 90.43% | 93.43% | 95.87% |
| KNN | Reference | RF | Reference | ANN | Reference | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Neg. | Neu. | Pos. | Neg. | Neu. | Pos. | Neg. | Neu. | Pos. | ||||||
| Prediction | Neg. | 160 | 10 | 1 | Prediction | Neg. | 170 | 8 | 0 | Prediction | Neg. | 166 | 5 | 6 |
| Neu. | 0 | 184 | 1 | Neu. | 0 | 170 | 0 | Neu. | 0 | 177 | 2 | |||
| Pos. | 22 | 17 | 138 | Pos. | 1 | 26 | 150 | Pos. | 4 | 5 | 168 | |||
| Neg. | Neu. | Pos. | |
|---|---|---|---|
| KNN Sensitivity | 0.8791 | 0.8720 | 0.9857 |
| RF Sensitivity | 0.9942 | 0.8396 | 1.0000 |
| ANN Sensitivity | 0.9765 | 0.9465 | 0.9545 |
| Neg. | Neu. | Pos. | |
| KNN Specificity | 0.9687 | 0.9969 | 0.9008 |
| RF Specificity | 0.9779 | 1.0000 | 0.9295 |
| ANN Specificity | 0.9697 | 0.9942 | 0.9748 |
| Autor’s | Overall Accuracy | Observations |
|---|---|---|
| This Study | 95.87% | 49 out of 2548 features selected with genetic algorithms and ANN ML model for classification. |
| Bird J. et al. [25] | 87.16% | 44 out of 2100 features were used with classification models such as Bayesian networks, support vector machine and random forest, the last one being the most accurate. |
| Bird J. et al. [26] | 97.89% | 63 out of 2548 features selected via information gain measurement. Classification method: random forest ensemble classifier. |
| Ashford et al. [27] | 89.38% | 256 out of 2479 features selected based on information gain measurement from gray-scale image representation of statistical features. Classification method: deep convolutional neural network. |
| GA Feature Selection | KNN | RF | ANN |
|---|---|---|---|
| Overall Accuracy | 90.43% | 93.43% | 95.87% |
| Sequential Feature Selection | KNN | RF | ANN |
| Overall Accuracy | 74.11% | 92.68% | 84.98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García-Hernández, R.A.; Celaya-Padilla, J.M.; Luna-García, H.; García-Hernández, A.; Galván-Tejada, C.E.; Galván-Tejada, J.I.; Gamboa-Rosales, H.; Rondon, D.; Villalba-Condori, K.O. Emotional State Detection Using Electroencephalogram Signals: A Genetic Algorithm Approach. Appl. Sci. 2023, 13, 6394. https://doi.org/10.3390/app13116394
García-Hernández RA, Celaya-Padilla JM, Luna-García H, García-Hernández A, Galván-Tejada CE, Galván-Tejada JI, Gamboa-Rosales H, Rondon D, Villalba-Condori KO. Emotional State Detection Using Electroencephalogram Signals: A Genetic Algorithm Approach. Applied Sciences. 2023; 13(11):6394. https://doi.org/10.3390/app13116394
Chicago/Turabian StyleGarcía-Hernández, Rosa A., José M. Celaya-Padilla, Huizilopoztli Luna-García, Alejandra García-Hernández, Carlos E. Galván-Tejada, Jorge I. Galván-Tejada, Hamurabi Gamboa-Rosales, David Rondon, and Klinge O. Villalba-Condori. 2023. "Emotional State Detection Using Electroencephalogram Signals: A Genetic Algorithm Approach" Applied Sciences 13, no. 11: 6394. https://doi.org/10.3390/app13116394
APA StyleGarcía-Hernández, R. A., Celaya-Padilla, J. M., Luna-García, H., García-Hernández, A., Galván-Tejada, C. E., Galván-Tejada, J. I., Gamboa-Rosales, H., Rondon, D., & Villalba-Condori, K. O. (2023). Emotional State Detection Using Electroencephalogram Signals: A Genetic Algorithm Approach. Applied Sciences, 13(11), 6394. https://doi.org/10.3390/app13116394