
Genetic Programming-Based Feature Construction for System Setting Recognition and Component-Level Prognostics

 ,
,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
- First, an initial population of individuals is randomly generated
- Then, the following steps are performed until a specific termination criterion is met
- A fitness value is assigned to each individual
- The individuals with the best fitness value are selected and reproduced for the next generation
- A new population is created through genetic operators
- The result of genetic operators represents a possible solution to the generation
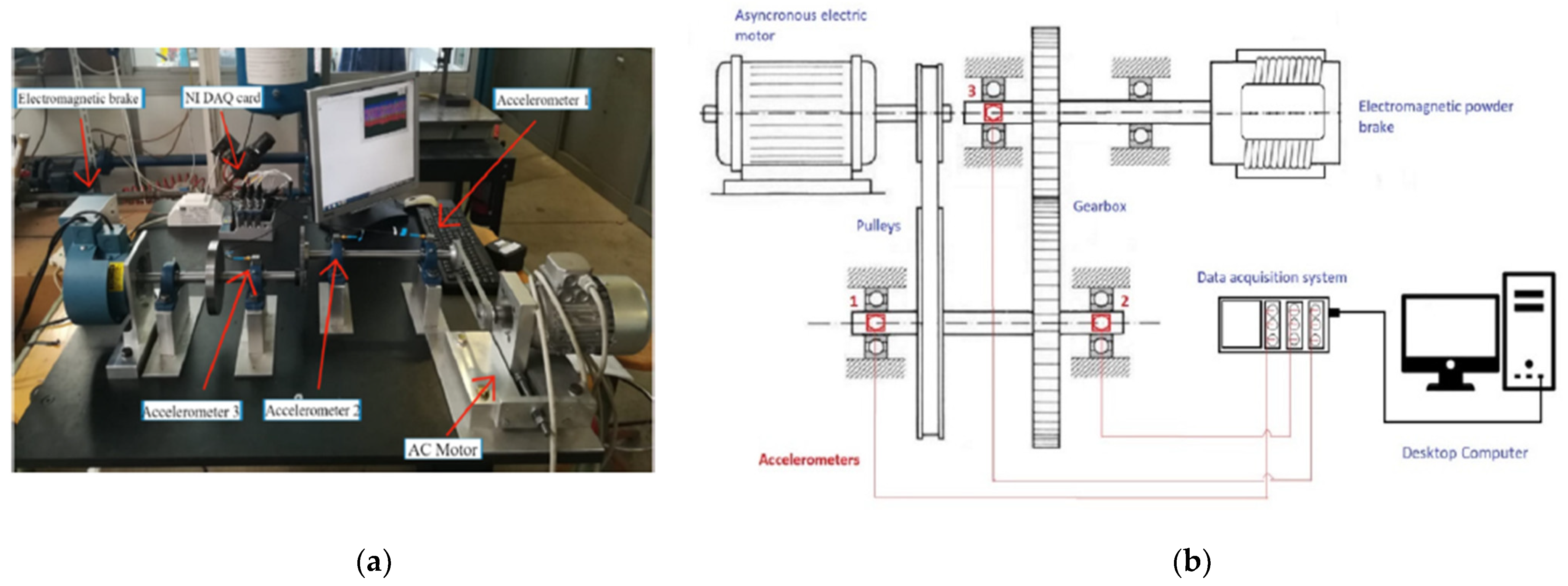
2.1. Test Rig Description and Data Collection
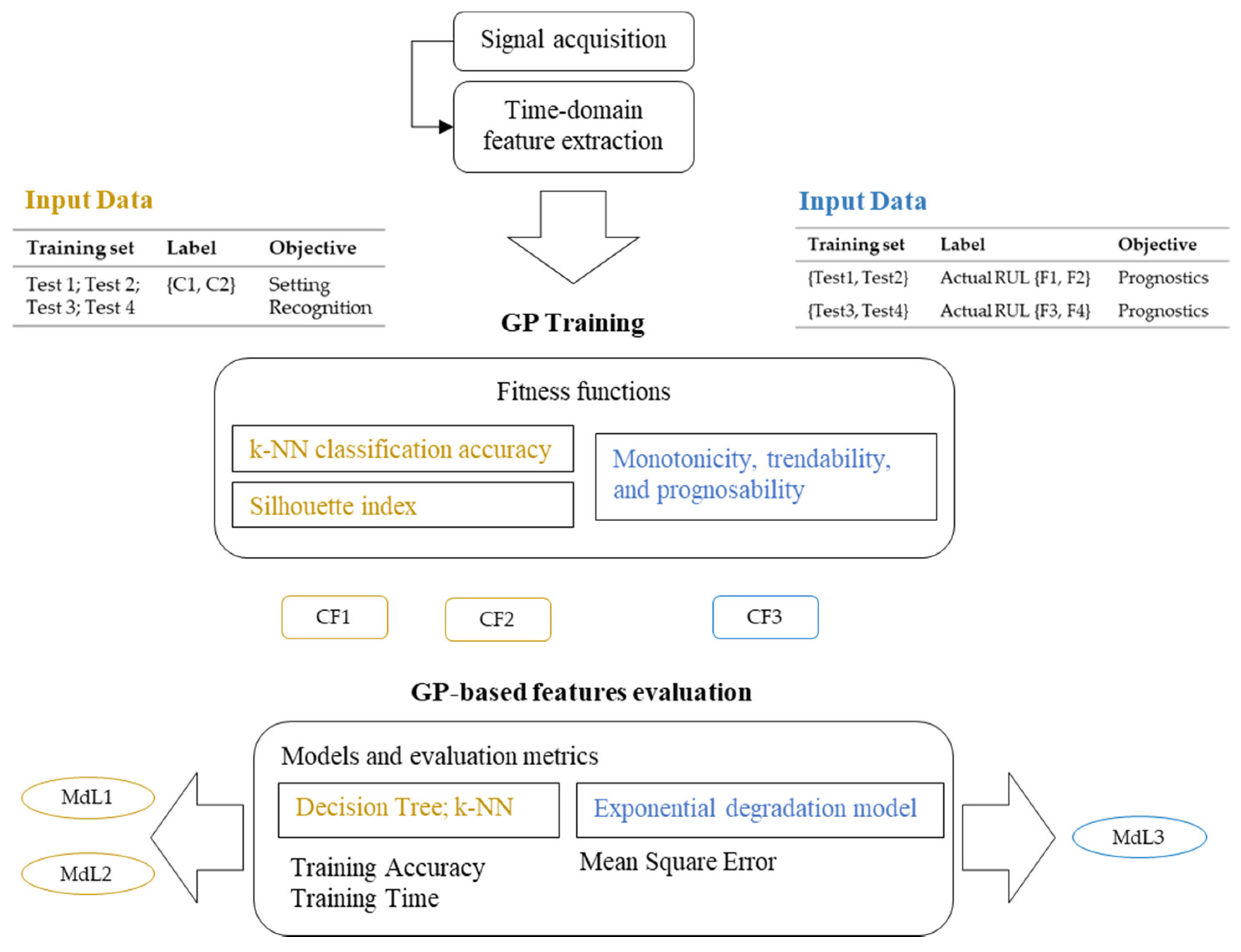
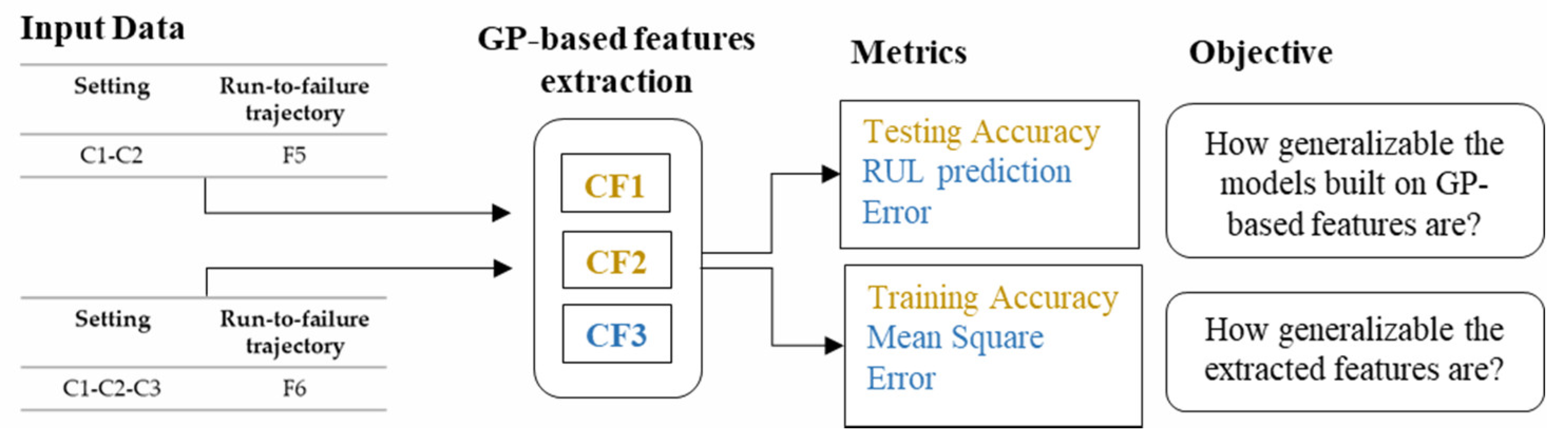
2.2. The Methodology
2.3. GP Fitness Functions
- is the silhouette value of the point
- is the average distance from the ith point to the other points in the same cluster as
- is the minimum average distance from the ith point to points belonging to other clusters
- is the total number of observations
3. Results
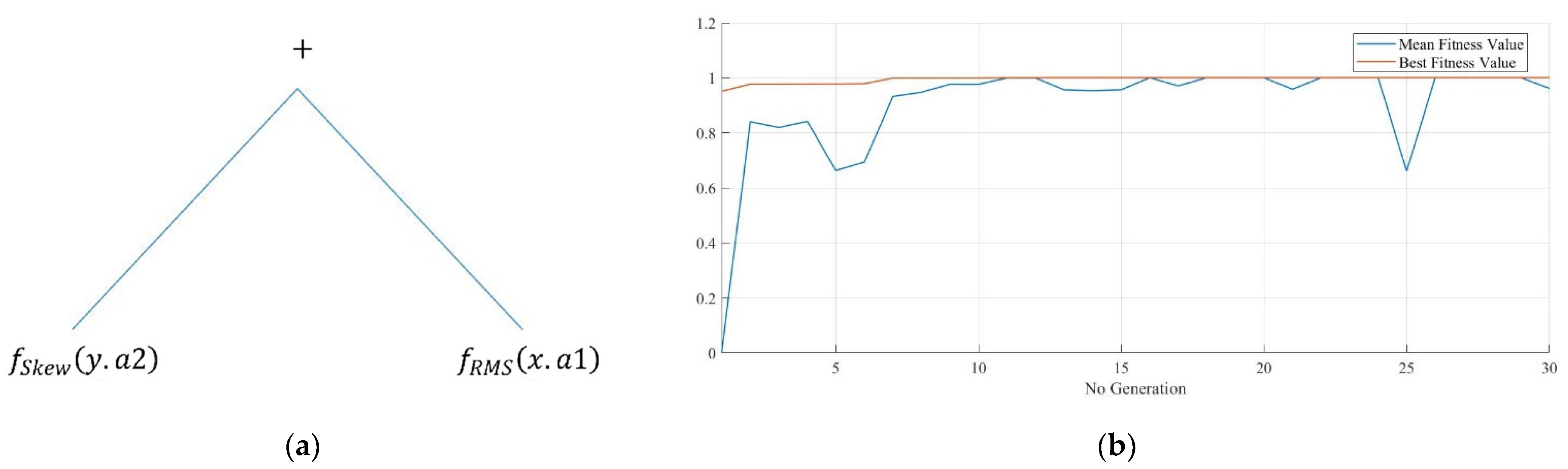
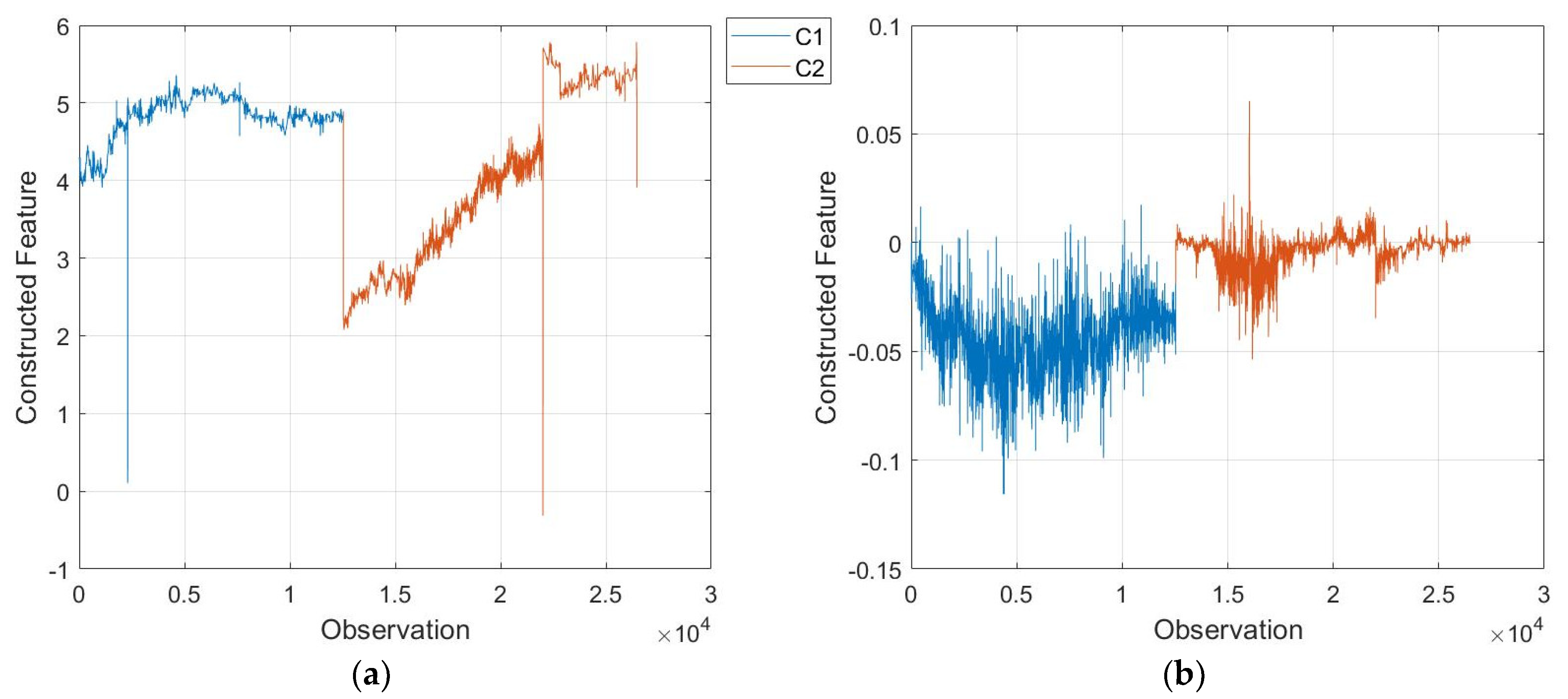
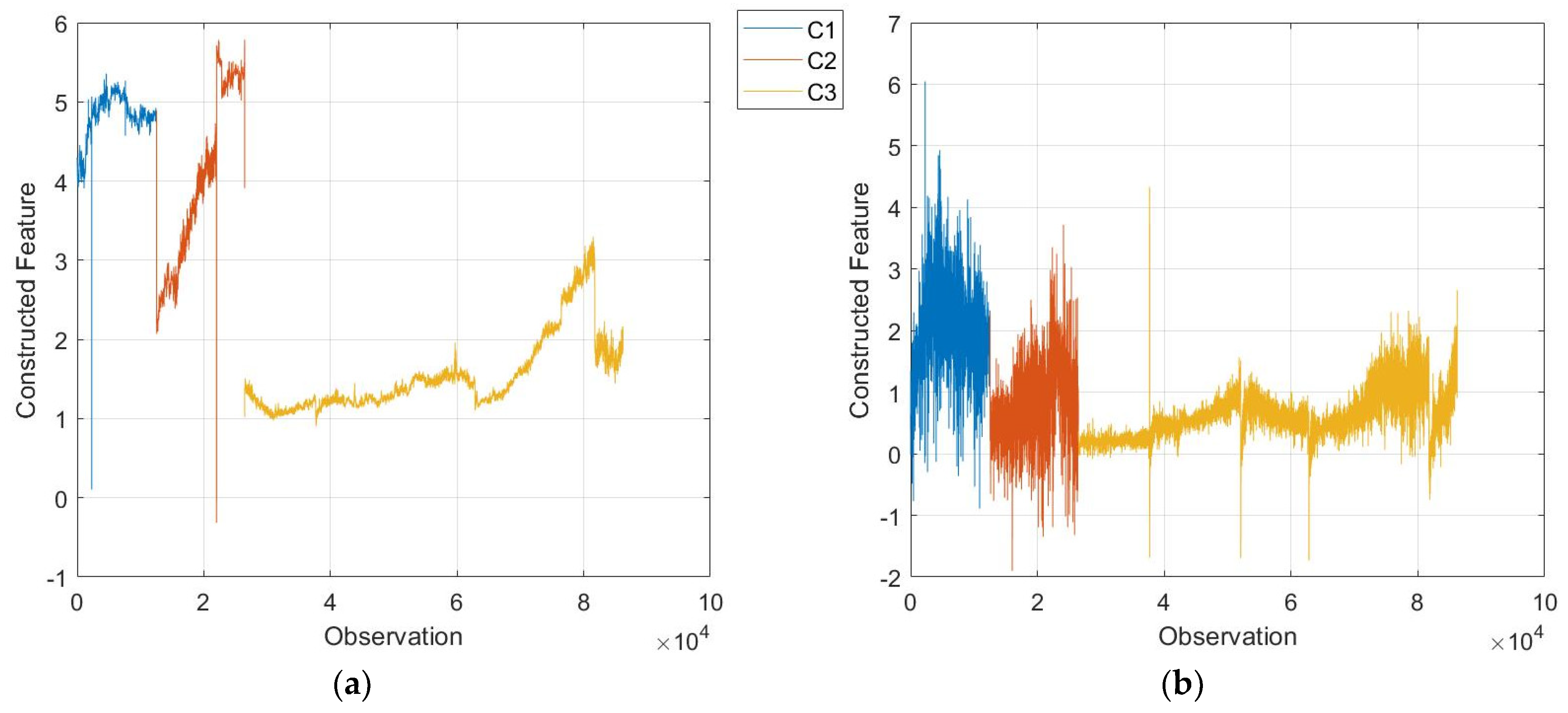
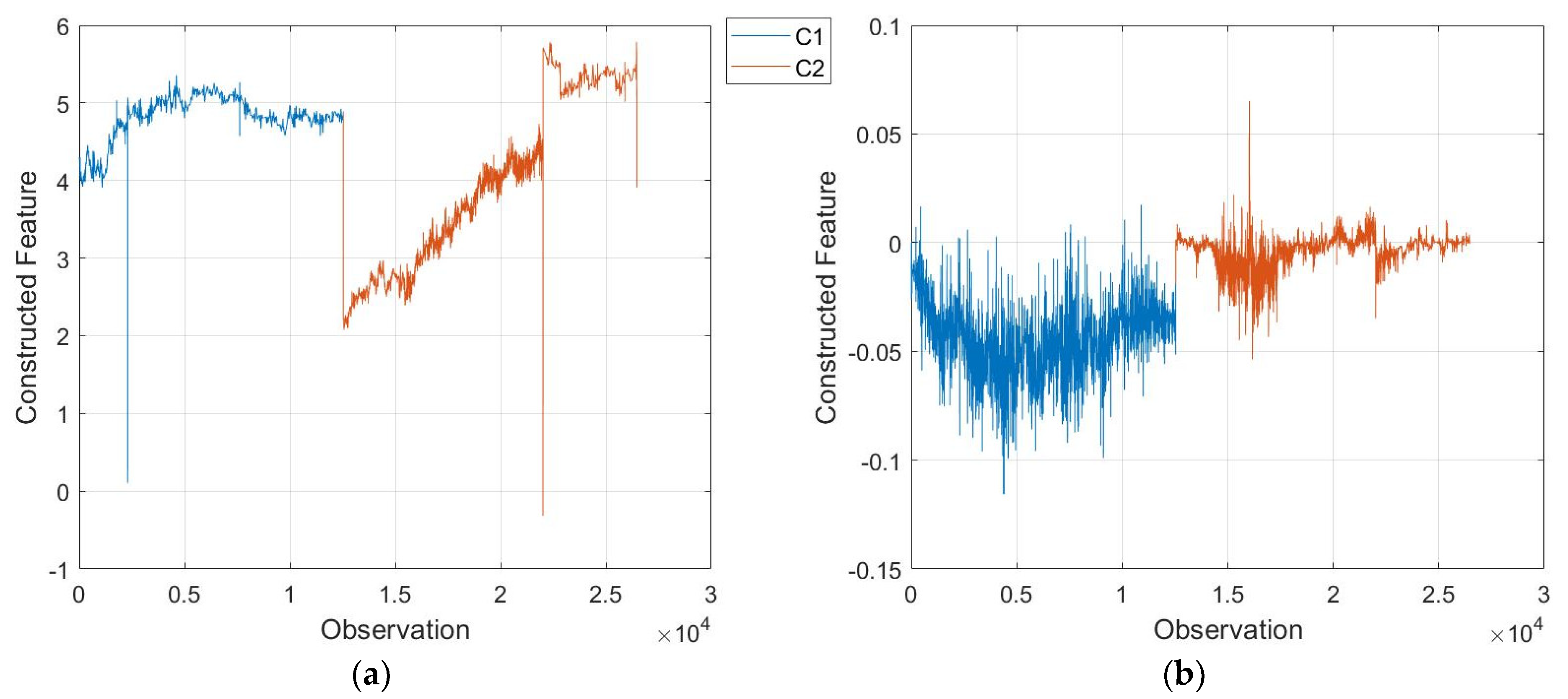
3.1. GP for System Setting Recognition
3.2. GP for Belt Prognostics
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Characteristics | Values | Component | Characteristics | Values |
|---|---|---|---|---|---|
| Pulley 1 | Number of teeth | 30 | Spur gear 1 | Number of teeth | 60 |
| Pitch | 5 mm | Module | 1 | ||
| To suit belt width | 10 mm | Pitch | 60 mm | ||
| Bore | 8 mm | Bore | 10 mm | ||
| Material | Aluminum | Material | Steel | ||
| Pulley 2 | Number of teeth | 40 | Spur gear 2 | Number of teeth | 120 |
| Pitch | 5 mm | Module | 1 | ||
| To suit belt width | 10 mm | Pitch | 120 mm | ||
| Bore | 8 mm | Bore | 12 mm | ||
| Material | Aluminum | Material | Steel | ||
| Belt | Number of teeth Pitch Length Width Maximum speed Material | 122 1.2 5 mm 610 mm 10 mm 80 m/s Polyurethan | Ball-bearing | Inside diameter Outside diameter Static load rating Material | 20 mm 47 mm 6.55 kN Steel |
| Long Closed Bush Shaft | Length | 1 m | |||
| Diameter | 20 mm | ||||
| Hardness | 60→64 HRC | ||||
| Tolerance | h6 | ||||
| Material | Steel |
References
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Sarih, H.; Tchangani, A.P.; Medjaher, K.; Pere, E. Data preparation and preprocessing for broadcast systems monitoring in PHM framework. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies, CoDIT 2019, Paris, France, 23–26 April 2019; pp. 1444–1449. [Google Scholar]
- Atamuradov, V.; Medjaher, K.; Camci, F.; Zerhouni, N.; Dersin, P.; Lamoureux, B. Machine Health Indicator Construction Framework for Failure Diagnostics and Prognostics. J. Signal Process. Syst. 2020, 92, 591–609. [Google Scholar] [CrossRef]
- Del Buono, F.; Calabrese, F.; Baraldi, A.; Paganelli, M.; Regattieri, A. Data-driven predictive maintenance in evolving environ- ments: A comparison between machine learning and deep learning for novelty detection. In Proceedings of the International Conference on Sustainable Design and Manufacturing, Split, Croatia, 15–17 September 2021; ISBN 0000000181198. [Google Scholar]
- Calabrese, F.; Regattieri, A.; Bortolini, M.; Galizia, F.G. Fault diagnosis in industries: How to improve the health assessment of rotating machinery. In Proceedings of the International Conference on Sustainable Design and Manufacturing, Split, Croatia, 15–17 September 2021; pp. 1–10. [Google Scholar]
- Tang, J.; Alelyani, S.; Liu, H. Feature Selection for Classification: A Review. In Data Classification Algorithms and Applications; Aggarwal, C.C., Ed.; CRC Press: New York, NY, USA, 2014; pp. 2–28. ISBN 9780429102639. [Google Scholar]
- Cheng, X.; Ellefsen, A.L.; Li, G.; Holmeset, F.T.; Zhang, H.; Chen, S. A Step-wise Feature Selection Scheme for a Prognostics and Health Management System in Autonomous Ferry Crossing Operation. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation, ICMA 2019, Tianjin, China, 4–7 August 2019; pp. 1877–1882. [Google Scholar]
- Aremu, O.O.; Cody, R.A.; Hyland-Wood, D.; McAree, P.R. A relative entropy based feature selection framework for asset data in predictive maintenance. Comput. Ind. Eng. 2020, 145, 106536. [Google Scholar] [CrossRef]
- Toma, R.N.; Prosvirin, A.E.; Kim, J.M. Bearing fault diagnosis of induction motors using a genetic algorithm and machine learning classifiers. Sensors 2020, 20, 1884. [Google Scholar] [CrossRef] [Green Version]
- Khumprom, P.; Yodo, N.; Grewell, D. Neural networks based feature selection approaches for prognostics of aircraft engines. In Proceedings of the Annual Reliability and Maintainability Symposium, Palm Springs, CA, USA, 27–30 January 2020. [Google Scholar]
- Akuruyejo, M.; Kowontan, S.; Ali, J.B.E.N. A Data-Driven Approach Based Health Indicator for Remaining Useful Life Estimation of Bearings. In Proceedings of the 2017 18th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Munastir, Tunisia, 21–23 December 2017. [Google Scholar]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Liu, C.; Sun, J.; Liu, H.; Lei, S.; Hu, X. Complex engineered system health indexes extraction using low frequency raw time-series data based on deep learning methods. Meas. J. Int. Meas. Confed. 2020, 161, 107890. [Google Scholar] [CrossRef]
- Chen, J.; Lin, C.; Peng, D.; Ge, H. Fault Diagnosis of Rotating Machinery: A Review and Bibliometric Analysis. IEEE Access 2020, 8, 224985–225003. [Google Scholar] [CrossRef]
- Ma, J.; Gao, X. A filter-based feature construction and feature selection approach for classification using Genetic Programming. Knowl.-Based Syst. 2020, 196, 105806. [Google Scholar] [CrossRef]
- Chen, S.; Wen, P.; Zhao, S.; Huang, D.; Wu, M.; Zhang, Y. A Data Fusion-Based Methodology of Constructing Health Indicators for Anomaly Detection and Prognostics. In Proceedings of the 2018 International Conference on Sensing, Diagnostics, Prognostics, and Control, SDPC 2018, Xi’an, China, 15–17 August 2019; pp. 570–576. [Google Scholar]
- Tran, B.; Xue, B.; Zhang, M. Genetic programming for multiple-feature construction on high-dimensional classification. Pattern Recognit. 2019, 93, 404–417. [Google Scholar] [CrossRef]
- Calabrese, F.; Regattieri, A.; Pilati, F.; Bortolini, M. Streaming-based Feature Extraction and Clustering for Condition Detection in Dynamic Environments: An Industrial Case. In Proceedings of the 5th European Conference of the Prognostics and Health Management Society 2020, Turin, Italy, 27–31 July 2020; pp. 1–14. [Google Scholar]
- Calabrese, F.; Regattieri, A.; Bortolini, M.; Gamberi, M.; Pilati, F. Predictive maintenance: A novel framework for a data-driven, semi-supervised, and partially online Prognostic Health Management application in industries. Appl. Sci. 2021, 11, 3380. [Google Scholar] [CrossRef]
- Muni, D.P.; Pal, N.R.; Das, J. A novel approach to design classifiers using genetic programming. IEEE Trans. Evol. Comput. 2004, 8, 183–196. [Google Scholar] [CrossRef] [Green Version]
- Guo, L.; Rivero, D.; Dorado, J.; Munteanu, C.R.; Pazos, A. Automatic feature extraction using genetic programming: An application to epileptic EEG classification. Expert Syst. Appl. 2011, 38, 10425–10436. [Google Scholar] [CrossRef]
- Vanneschi, L.; Poli, R. Genetic Programming—Introduction, Applications, Theory and Open Issues. In Handbook of Natural Computing; Springer: Berlin/Heidelberg, Germany, 2012; pp. 709–739. ISBN 9783540929109. [Google Scholar]
- Wang, H.; Dong, G.; Chen, J. Application of Improved Genetic Programming for Feature Extraction in the Evaluation of Bearing Performance Degradation. IEEE Access 2020, 8, 167721–167730. [Google Scholar] [CrossRef]
- Folino, G. Algoritmi Evolutivi e Programmazione Genetica: Strategie di Progettazione e Parallelizzazione Algoritmi Evolutivi e Programmazione Genetica: Strategie di Progettazione e Parallelizzazione; ICAR-CNR: Quattromiglia, Italy, 2003. [Google Scholar]
- Neshatian, K.; Zhang, M.; Andreae, P. A filter approach to multiple feature construction for symbolic learning classifiers using genetic programming. IEEE Trans. Evol. Comput. 2012, 16, 645–661. [Google Scholar] [CrossRef]
- Smith, M.G.; Bull, L. Genetic programming with a genetic algorithm for feature construction and selection. Genet. Program. Evolvable Mach. 2005, 6, 265–281. [Google Scholar] [CrossRef]
- Lensen, A.; Xue, B.; Zhang, M. New Representations in Genetic Programming for Feature Construction in k-Means Clustering. In Simulated Evolution and Learning; Shi, Y., Tan, K.C., Zhang, M., Tang, K., Li, X., Zhang, Q., Tan, Y., Middendorf, M., Jin, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 543–555. ISBN 978-3-319-68759-9. [Google Scholar]
- Schofield, F.; Lensen, A. Evolving Simpler Constructed Features for Clustering Problems with Genetic Programming. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation, CEC 2020, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Firpi, H.; Vachtsevanos, G. Genetically programmed-based artificial features extraction applied to fault detection. Eng. Appl. Artif. Intell. 2008, 21, 558–568. [Google Scholar] [CrossRef]
- Peng, B.; Wan, S.; Bi, Y.; Xue, B.; Zhang, M. Automatic Feature Extraction and Construction Using Genetic Programming for Rotating Machinery Fault Diagnosis. IEEE Trans. Cybern. 2020, 51, 4909–4923. [Google Scholar] [CrossRef]
- Qin, A.; Zhang, Q.; Hu, Q.; Sun, G.; He, J.; Lin, S. Remaining Useful Life Prediction for Rotating Machinery Based on Optimal Degradation Indicator. Shock Vib. 2017, 2017. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, K.T.P.; Medjaher, K. An automated health indicator construction methodology for prognostics based on multi-criteria optimization. ISA Trans. 2020, 113, 81–96. [Google Scholar] [CrossRef]
- Liao, L. Discovering prognostic features using genetic programming in remaining useful life prediction. IEEE Trans. Ind. Electron. 2014, 61, 2464–2472. [Google Scholar] [CrossRef]
- Wen, P.; Zhao, S.; Chen, S.; Li, Y. A generalized remaining useful life prediction method for complex systems based on composite health indicator. Reliab. Eng. Syst. Saf. 2021, 205, 107241. [Google Scholar] [CrossRef]
- Calabrese, F.; Casto, A.; Regattieri, A.; Piana, F. Components monitoring and intelligent diagnosis tools for Prognostic Health Management approach. Proc. Summer Sch. Fr. Turco 2018, 2018, 142–148. [Google Scholar]
- Calabrese, F.; Regattieri, A.; Bortolini, M.; Galizia, F.G.; Visentini, L. Feature-based multi-class classification and novelty detection for fault diagnosis of industrial machinery. Appl. Sci. 2021, 11, 9580. [Google Scholar] [CrossRef]
- Janos, A. Genetic Programming MATLAB Toolbox. MATLAB Central File Exchange. Available online: https://www.mathworks.com/matlabcentral/fileexchange/47197-genetic-programming-matlab-toolbox (accessed on 29 March 2022).
- Baraldi, P.; Bonfanti, G.; Zio, E. Differential evolution-based multi-objective optimization for the definition of a health indicator for fault diagnostics and prognostics. Mech. Syst. Signal Process. 2018, 102, 382–400. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, X.; Wang, R.; Zheng, W.; Zhu, Y. Self-representation and PCA embedding for unsupervised feature selection. World Wide Web 2018, 21, 1675–1688. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Chen, M.; Sun, Y.; Qin, X.; Li, H. A two-stage feature selection and intelligent fault diagnosis method for rotating machinery using hybrid filter and wrapper method. Neurocomputing 2018, 275, 2426–2439. [Google Scholar] [CrossRef]
- Medjaher, K.; Zerhouni, N.; Baklouti, J. Data-driven prognostics based on health indicator construction: Application to PRONOSTIA’s data. In Proceedings of the 2013 European Control Conference, ECC 2013, Zurich, Switzerland, 17–19 July 2013; pp. 1451–1456. [Google Scholar]






| Kind of Primitives | Example(s) |
|---|---|
| Arithmetic | Add, Multiplication, Division |
| Mathematical | Sin, Cos, Exp |
| Boolean | AND, OR, NOT |
| Conditional | IF-THEN-ELSE |
| Looping | FOR, REPEAT |
| References | Feature Extraction | Fitness Function | |
|---|---|---|---|
| Features Construction | HI Construction | ||
| [30] | - | Fisher ratio | - |
| [31] | Embedded in the function set | k-NN | - |
| [32] | 7 Time-domain features | - | Monotonicity |
| [33] | 11 Time-domain features | - | Monotonicity, trendability, failure consistency, scale similarity, robustness, mutual information Spearman correlation with RUL, F-test |
| [34] | 68 Time- and frequency-domain features | - | Monotonicity |
| [35] | - | Weighted sum of failure consistency and the average range | |
| [24] | 21 Time, frequency, and time–frequency domain features | - | Arithmetic mean of monotonicity, trendability, and deviation quantity |
| This paper | 81 Time-domain features | k-NN Silhouette index | Weighted mean of monotonicity, trendability, and prognosability |
| Operating Condition | AC Motor Speed (rpm) | Braking Force (Nm) |
|---|---|---|
| C1 | 710 | 0.1 |
| C2 | 710 | 0.2 |
| C3 | 910 | 0.2 |
| Test | Setting | Run-to-Failure Trajectories | Duration (min) |
|---|---|---|---|
| 1 | C1 | F1 | 38.4 |
| 2 | C1 | F2 | 170.5 |
| 3 | C2 | F3 | 157.9 |
| 4 | C2 | F4 | 74.2 |
| 5 | C1-C2 | F5 | 328.1 + 667.1 |
| 6 | C1-C2-C3 | F6 | 208.9 + 232.2 + 995.5 |
| Feature Name | Feature Formula |
|---|---|
| Peak | |
| Peak-to-peak | |
| Mean | |
| Root mean square (RMS) | |
| Crest factor (CF) | |
| Kurtosis | |
| Skewness | |
| Shape factor | |
| Impulse factor |
| Parameter | Value |
|---|---|
| Function set | Add, Subtraction, Protected division, Multiplication, Logarithm, Power, Exponential |
| Terminal set | Peak, Peak-to-peak, Mean, RMS, Crest factor, Kurtosis, Skewness, Shape factor, Impulse Factor |
| Population size | 100 |
| Max tree depth | 10 |
| Generation gap | 0.9 |
| 0.9 | |
| 0.1 | |
| Parents selection method | Tournament selection |
| Type of crossover | One point crossover |
| Replacement | Elitism |
| Number of generations | 30 |
| Termination criteria | Max. number of generations (iterations) |
| Iter. | Classification | Clustering | ||||
|---|---|---|---|---|---|---|
| Mean Fitness Value | Best Fitness Value | FC1 | Mean Fitness Value | Best Fitness Value | FC2 | |
| 1 | - | 0.950801 | - | 0.720651 | ||
| 2 | 0.840463 | 0.977063 | 0.711219 | 0.720651 | ||
| 3 | 0.819037 | 0.977063 | 0.711219 | 0.720651 | ||
| 4 | 0.841445 | 0.977517 | 0.741445 | 0.757926 | ||
| 5 | 0.662749 | 0.977517 | 0.753748 | 0.777517 | ||
| 6 | 0.693168 | 0.978424 | 0.753748 | 0.785372 | ||
| 7 | 0.931907 | 0.998413 | 0.753748 | 0.795372 | ||
| 8 | 0.947476 | 0.998526 | 0.767290 | 0.815372 | ||
| 9 | 0.976685 | 0.998526 | 0.734272 | 0.815372 | ||
| 10 | 0.976421 | 0.998526 | 0.746396 | 0.823728 | ||
| 11 | 0.998602 | 0.999698 | 0.745824 | 0.823728 | ||
| 12 | 0.998451 | 0.999698 | 0.797367 | 0.823728 | ||
| 13 | 0.956545 | 0.999811 | 0.796293 | 0.823728 | ||
| 14 | 0.952766 | 0.999811 | 0.817364 | 0.839811 | ||
| 15 | 0.956734 | 0.999811 | 0.826378 | 0.840800 | ||
| 16 | 0.999773 | 0.999849 | 0.826738 | 0.840800 | ||
| 17 | 0.970602 | 0.999849 | 0.826647 | 0.840800 | ||
| 18 | 0.999849 | 0.999887 | 0.826849 | 0.840800 | ||
| 19 | 0.999735 | 0.999887 | 0.826354 | 0.840800 | ||
| 20 | 0.999811 | 0.999924 | 0.826354 | 0.840800 | ||
| 21 | 0.958472 | 0.999924 | 0.826937 | 0.840800 | ||
| 22 | 0.999849 | 0.999924 | 0.826929 | 0.840800 | ||
| 23 | 0.999849 | 0.999924 | 0.825289 | 0.840800 | ||
| 24 | 0.999849 | 0.999924 | 0.817839 | 0.840800 | ||
| 25 | 0.661087 | 0.999924 | 0.826273 | 0.840800 | ||
| 26 | 0.999887 | 0.999924 | 0.826142 | 0.840800 | ||
| 27 | 0.999735 | 0.999924 | 0.826039 | 0.840800 | ||
| 28 | 0.999887 | 0.999924 | 0.826377 | 0.840800 | ||
| 29 | 0.999849 | 0.999924 | 0.826371 | 0.840800 | ||
| 30 | 0.961797 | 0.999924 | 0.826352 | 0.840800 | ||
| Method for Feature Extraction | Model | Training Accuracy (%) | Training Time (s) | Testing Accuracy (%) |
|---|---|---|---|---|
| Classification-based GP | DT | 90.4 | 2.6 | 67.03 |
| k-NN | 90.8 | 1.25 | 67.03 | |
| Clustering-based GP | DT | 96.0 | 0.71 | 67.30 |
| k-NN | 94.5 | 0.72 | 66.85 | |
| No feature selection | DT | 99.99 | 3.53 | 31.52 |
| k-NN | 100 | 56.94 | 61.14 | |
| PCA | DT | 81.9 | 1.78 | 61.30 |
| k-NN | 74.9 | 1.63 | 57.44 | |
| ReliefF | DT | 74.8 | 1.93 | 61.79 |
| k-NN | 64.1 | 1.57 | 52.86 |
| Model | Classification-Based GP | Clustering-Based GP | PCA | ReliefF |
|---|---|---|---|---|
| DT | 92.8% | 81.1% | 92.2% | 76.4% |
| k-NN | 90.8% | 70.8% | 89.3% | 69.1% |
| Constructed HI | Fitting Function | Mean Error (%) |
|---|---|---|
| 0.89 | 14.2 | |
| 0.87 | 33.4 | |
| 0.78 | 40.5 | |
| 0.94 | 130.1 | |
| 0.985 | 36.6 | |
| 0.87 | 10.5 | |
| 0.99 | 30.5 | |
| 0.78 | 35 |
| Health Indicator | Monotonicity | Trendability | Prognosability |
|---|---|---|---|
| 0.3999 | 0.1042 | 0.9095 | |
| 0.2637 | 0.7599 | 0.7599 |
| Run-to-Failure Trajectory | Nominal (s) | Fault (s) |
|---|---|---|
| F1 | 763 | 763 |
| F2 | 1.389 | 6.945 |
| F3 | 1.531 | 6.124 |
| F4 | 1.088 | 4.352 |
| Setting | Metric | X-a1 | Y-a1 | Z-a1 | X-a2 | Y-a2 | Z-a2 | X-a3 | Y-a3 | Z-a3 |
|---|---|---|---|---|---|---|---|---|---|---|
| C1 | Monotonicity | 0.0045 | 0.0154 | 0.0036 | 0.0041 | 0.0035 | 0.0080 | 0.0138 | 0.0147 | 0.0160 |
| Trendability | 0.0040 | 0.0077 | 0.0011 | 0.0311 | 0.0241 | 0.0262 | 0.0074 | 0.0083 | 0.0173 | |
| Prognosability | 0.1997 | 0.8400 | 0.8152 | 0.8247 | 0.9104 | 0.3104 | 0.6745 | 0.8328 | 0.4767 | |
| C2 | Monotonicity | 0.0133 | 0.0060 | 0.0301 | 0.0093 | 0.0031 | 0.0071 | 0.0041 | 0.0072 | 0.0033 |
| Trendability | 0.0503 | 0.0222 | 0.1513 | 0.0090 | 0.0414 | 0.0589 | 0.0242 | 0.0313 | 0.0150 | |
| Prognosability | 0.2828 | 0.3350 | 0.2577 | 0.2569 | 0.0632 | 0.3011 | 0.2316 | 0.8701 | 0.3361 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calabrese, F.; Regattieri, A.; Piscitelli, R.; Bortolini, M.; Galizia, F.G. Genetic Programming-Based Feature Construction for System Setting Recognition and Component-Level Prognostics. Appl. Sci. 2022, 12, 4749. https://doi.org/10.3390/app12094749
Calabrese F, Regattieri A, Piscitelli R, Bortolini M, Galizia FG. Genetic Programming-Based Feature Construction for System Setting Recognition and Component-Level Prognostics. Applied Sciences. 2022; 12(9):4749. https://doi.org/10.3390/app12094749
Chicago/Turabian StyleCalabrese, Francesca, Alberto Regattieri, Raffaele Piscitelli, Marco Bortolini, and Francesco Gabriele Galizia. 2022. "Genetic Programming-Based Feature Construction for System Setting Recognition and Component-Level Prognostics" Applied Sciences 12, no. 9: 4749. https://doi.org/10.3390/app12094749
APA StyleCalabrese, F., Regattieri, A., Piscitelli, R., Bortolini, M., & Galizia, F. G. (2022). Genetic Programming-Based Feature Construction for System Setting Recognition and Component-Level Prognostics. Applied Sciences, 12(9), 4749. https://doi.org/10.3390/app12094749