1. Introduction
A new concept called “Knowledge Plane for Internet” was given by D. Clark et al. [
1], which involves machine learning to operate the networks. According this concept, the Knowledge plane (KP) is considered as the potential candidate for computer network reforms, as it can bring automation and recommendation to the existing networks and changes the way we trouble shoot these data networks.
One of the biggest challenges encountered when applying machine learning to the traditional networks is their inherently distributed nature, i.e., each and every node (switches and routers) can only see a small portion of a network. Therefore, it is a very complex job to obtain knowledge from the nodes that have very little knowledge about the whole network, particularly when the global control over the network is required. The emerging trend that promises logical centralized control will simplify the application of ML in traditional distributed setting. In particular, the Software Defined Networking architecture entirely separates the two planes, namely, the data and control plane, and provides the logical central control plane which can be considered as central station in the network with knowledge [
2,
3].
Newer data plane elements (switches and routers) are now equipped with better computing and storage capabilities, hence providing packet and flow information in the real time to the centralized Network Analytics (NA), which enables the NA platform to provide a very rich view of the network [
4], which gives it an edge over the traditional network management techniques.
In this work, we take advantage of the centralized control offered by SDN, combined with the information provided by the NA about the network, to help us apply ML [
1,
5]. In this context, the knowledge plane can benefit from various machine learning techniques already available in the literature to control the network [
6]. In the rest of the paper, the SDN combined with network analytics and KP will be referred to as SDN-with-knowledge [
3]. Recently, a similar architecture inspired from the knowledge plane [
1] called “Knowledge Defined Networking” is proposed by Mestres et al. [
7], which explains how such an ecosystem can be exploited with the help of ML to provide automated control to the network. The architecture proposed by Mestres et al. further investigated the allocation of resources in Network Function Virtualization (NFV) [
7].
NFV is an emerging paradigm which separates the network functions (such as firewalls, proxies, load balancers, etc.) from the physical hardware on which they are executed. These network functions which are decoupled from physical hardware are called virtual network functions, which now require virtual resources (Virtual Machines (VMs)) to execute [
8,
9]. Allocation of resources in NFV is also investigated by [
10,
11]. Management of resources in NFV is most challenging because of the limited resources available for the VNFs [
12,
13].
In static networks, the ideal placement of VNFs has been comprehensively studied [
10]. However, the dynamic network environment requires advance algorithms to effectively allocate resources to VNFs, so it can deal the fluctuating real time traffic. However, VNFs are complex and dynamic entities, therefore accurate modeling of its behavior is really challenging task. In this context, ML models are very encouraging to solve this problem, which is briefly addressed in [
7], but the area still has a lot of potential and requires in-depth research. The contributions of this paper are summarized as follow:
A comprehensive survey has been carried out for existing ML techniques used for resource management in NFV environment.
The experiments are carried out using a real traffic trace, to first validate the data set already published by [
7].
Based on experimental testing and related literature, we have modeled multiple linear regression and support-vector-machine-based regression model to optimally estimate the CPU consumption of different VNFs.
Finally, we compared our adopted models with the artificial-neural-network-based approach proposed by Mestres et al. [
7].
The results show that our proposed ML model is more efficient and superior in estimating the resource requirement of VNFs compared to the state of art.
The rest of
Section 1 describes the background and the SDN-with-knowledge model and how it operates.
Section 2 defines the problem statement and the proposed models.
Section 3 describes methodology and experimental setup.
Section 4 presents experimental results, comparison, and analysis.
Section 5 is the discussion, and
Section 6 concludes and summarizes the paper.
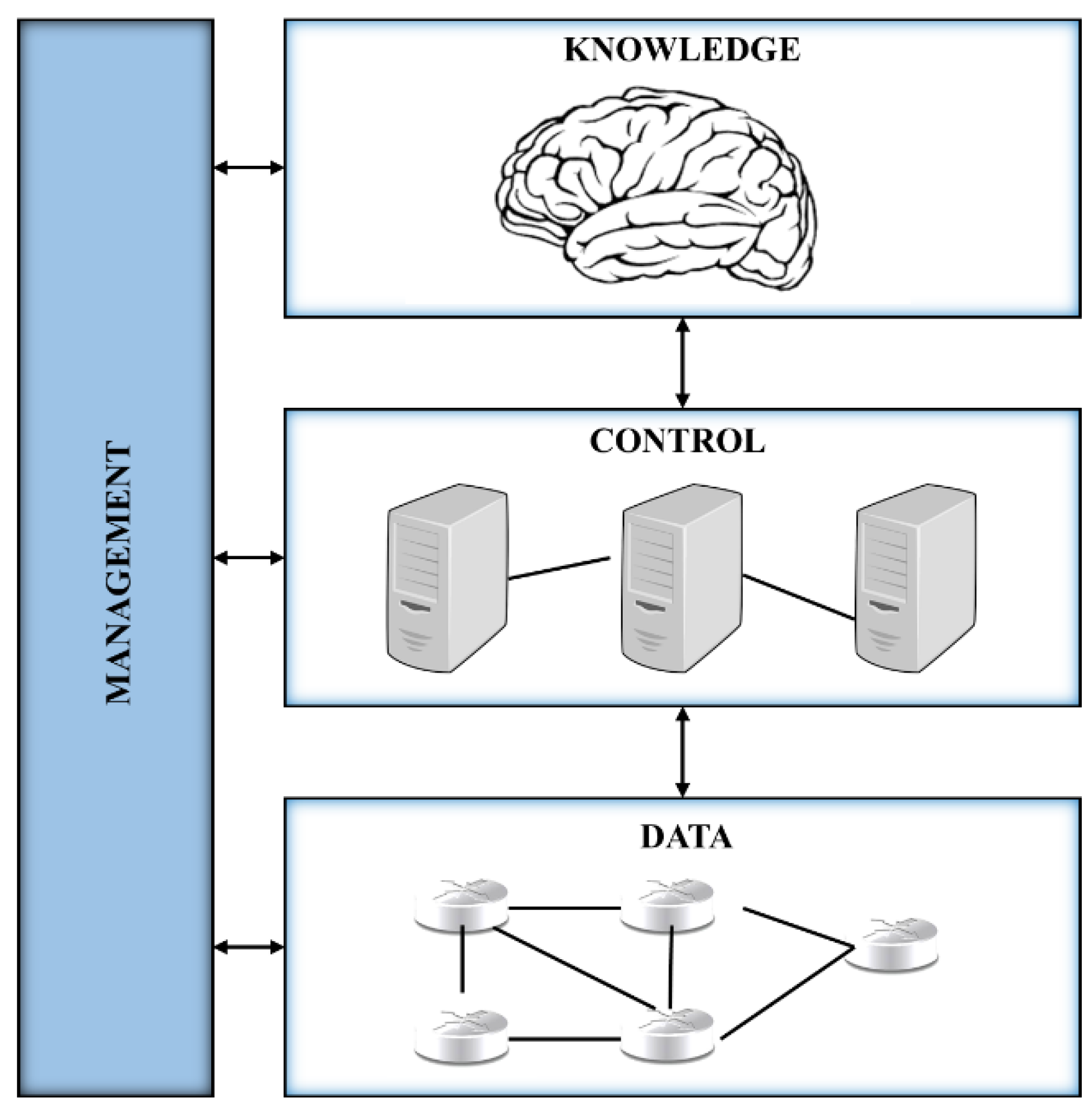
1.1. SDN Model
The Data Plane forwards the data packets. In SDN, the data plane is composed of network devices that can be easily programmed for forwarding via south-bound Application Programming Interface (API) from the controller.
The Control Plane is responsible for the exchange of operational states that enables the data plane to update via south-bound API accordingly. In the SDN setup, it is performed by the centralized controller.
The Management Plane monitors the reliable operation of the network. It helps in configuring data plane elements and outlines the network topology. In the SDN setup, this task is also controlled by the logical centralized controller. The data provided by NA come from the management plane.
To take control over the network the knowledge plane obtains knowledge from the control and network layer. When the KP learns the behavior of the network it can automatically operate the network. Basically, the knowledge plane processes network analytics provided by the management plane, using machine learning to transform it into knowledge; furthermore, this knowledge is used to make decisions [
3,
5].
Figure 1 illustrates the SDN-with-Knowledge plane.
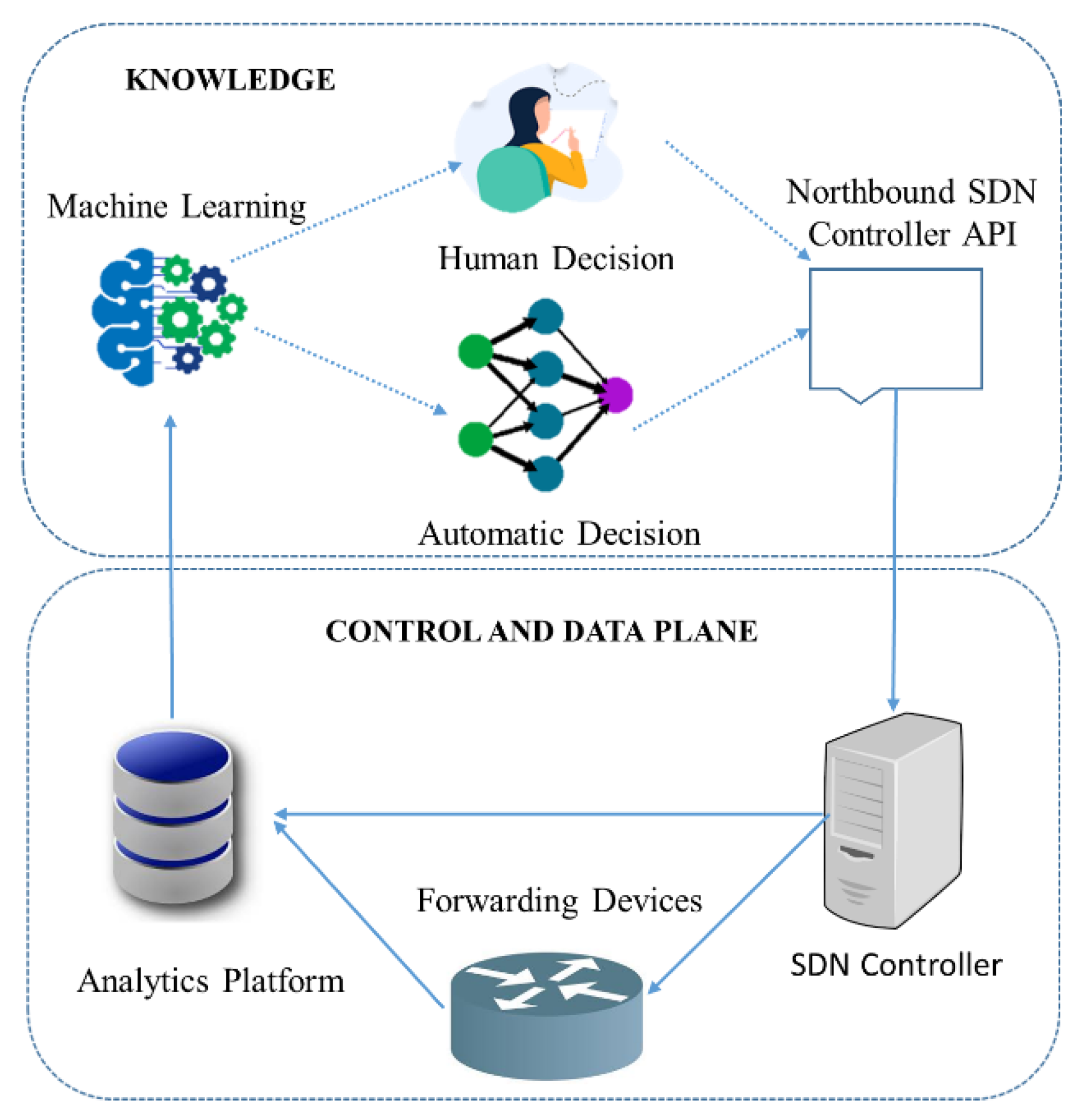
1.2. SDN-with-Knowledge Operation
SDN-with-knowledge borrows some of its ideas from other research areas [
1,
2,
5]. It operates in a control loop, which in turn provides recommendation, optimization, and estimation. A similar approach is also highlighted by other research areas such as neural networks in feedback control systems and automatic network management [
14,
15]. In addition, the feasibility of our approach is supported by paper [
16]. The basic operation of SDN-with-Knowledge is shown in
Figure 2, and all entities and their functions are described as follow.
The Analytics Platform is responsible for the collection of information form the network data plane elements such as forwarding devices, switches and routers, and the SDN controller.
Machine learning algorithms play a vital role in KP as they learn the behavior of the network. The information collected by the analytics platform is used by the ML to generate knowledge. Furthermore, ML aids the north-bound controller API to give instructions to the SDN controller on how to operate the network. In the SDN-with-knowledge paradigm, this process is partially assigned to the knowledge plane, which takes advantage of machine learning, makes decisions, and offers recommendations [
5].
The SDN controller is responsible for giving control instructions to the forwarding devices via the south-bound protocol, based on the knowledge learned at the KP [
5].
1.3. Research Objectives
The objective of this work is to focus on one particular application of the SDN-with-knowledge paradigm and the benefits a knowledge plane combined with machine learning may bring to common networking problems (i.e., resource management in network function virtualization).
1.4. Resource Management in Network Function Virtualization
Here, a use-case is presented which can utilize the concept of the SDN-with-knowledge paradigm in a network setting called network function virtualization [
12]. It is a relatively new approach in which network applications, such as firewalls and load balancers, are implemented virtually, called as virtual network functions, without the use of extra hardware [
10]; in fact, they are implemented utilizing general hardware.
The management of resources in NFV is very difficult and one of the most researched topics because of its vast applications in Data Centers [
12]. The SDN-with-knowledge paradigm has the potential to address resource management problems in NFV [
7]. KP with the aid of machine learning techniques can be considered as a new pillar in modeling the resource requirement of VNFs, hence improving the overall performance of the system.
1.5. Machine Learning
ML techniques can be categorized on the basis of the output they produce: Classification and Regression models; furthermore, they can be divided on the basis of the input data they use: Supervised or Unsupervised techniques [
6,
17].
In classification, the model tries to classify the input in different classes or categories. So, the output value is usually 0 or 1 representing a particular class. On the other hand, the regression models try to learn the continues function for the given input [
17]. Similarly, we can say that the regression-based ML model tries to map multiple output continuos functions for the given input. Supervised learning uses labeled input and output data, whereas an unsupervised learning algorithm does not require labeled data. A labeled datum has tags in data fields, such as name, serial number, type, etc., whereas unlabeled data do not contain any tags.
2. Problem Definition and Proposed Models
The considered problem is to check the feasibility of machine learning for accurately estimating the CPU consumption of different virtual network functions deployed in SDN environment, when trained with only traffic features as an input. The CPU needs of a particular VNF depending upon many known and unknown interacting parameters, which is the key motivation factor of using ML-based techniques. Once the ML model is trained, then the CPU’s estimated value can be used by resource allocation schemes [
10], which can dynamically assign the required resources to a particular VNF. To solve this resource requirement problem, we preset supervised ML models, Multiple linear regression (MLR), and Support Vector Machine (SVM) in comparison with Artificial Neural Network (ANN). All of the said models are implemented to solve an estimation problem, so they will be termed as multiple linear regression, support vector regression, and fitting neural network, respectively. Furthermore, they are evaluated against each other considering which model best fits the data represented by features.
The main idea is to use a dataset for training our ML models, which can then estimate CPU value for each incoming traffic. For this purpose, first, the dataset must be constructed. Since our proposed models are based on supervised learning, therefore, the dataset must contain a pair of inputs (traffic vector) and outputs (real CPU utilization). The traffic vectors in dataset describes the incoming traffic to the VNFs, while the CPU utilization is the real-world CPU usage of these VNFs when the traffic is processed by them. The traffic is represented by 86 features (number of packets, IP address, total bytes, source and destination address, ports, etc., are a few mentions among others), which are extracted offline in 20 s batches (detail setup in
Section 3). Once the dataset is constructed, it is further used to train our proposed ML models, which aim to learn the function that can accurately map the traffic features to CPU consumption.
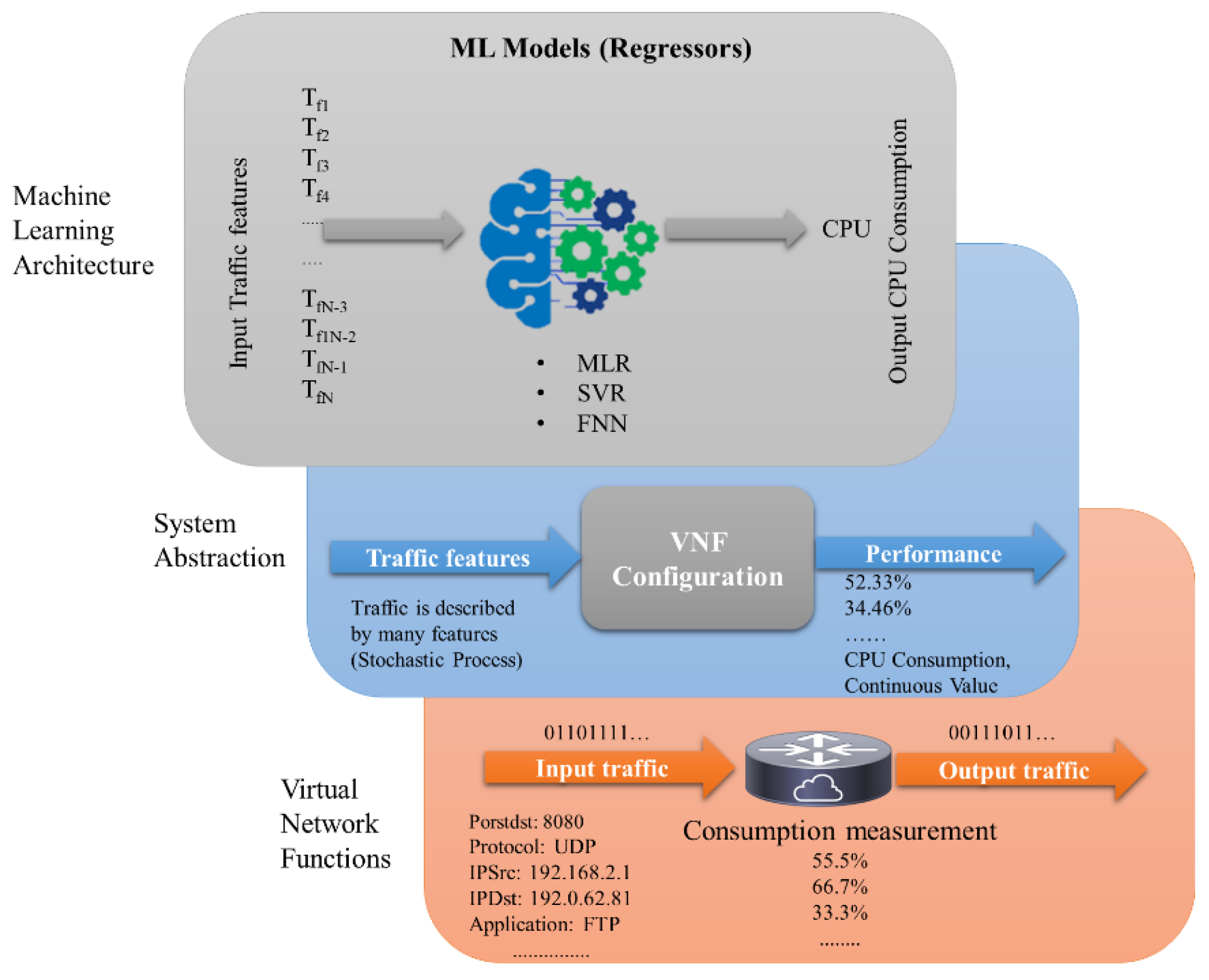
Figure 3 defines the considered problem in three layers.
In this work, we modeled the behavior of real-world virtual network function that is shown on the bottom layer in
Figure 3. It has been observed that the behavior of a particular VNF depends on different parameters, particularly its configuration, which, in our study, is considered to be constant. In system abstraction, which is the middle layer, the VNF is considered as block box, where the traffic represented by features enters the box and leaves the box, which in turn alters the VNF’s resource requirements. The top layer represents machine learning architecture, where different regressors such as MLR, SVR, and FNN are used to estimate the CPU consumption of VNF. The considered ML models are only trained for CPU estimates of VNF because the exact configuration of VNF is hidden. The following section details the proposed models.
2.1. Multiple Linear Regression
Multiple linear regression analysis is one of the most powerful tools used to model the association between problem variables (i.e., input and output). Modeling the association between these variables can predict future trends [
17]. Furthermore, it is used to model the complex relation between dependent variable and multiple independent variables. Assuming
is the dependent variable and
are independent variables, then the MLR regression model can be expressed as follows:
where
is a constant, and
represent regression coefficients.
The main aim of MLR is to minimize the sum of squares of error
by using the Least Square (LS) method [
17]. It has been observed that with a large number of dataset observations, this technique gives more robust solutions, but if we have a small number of observations in the dataset, then we obtain poor results.
2.2. Support Vector Machines
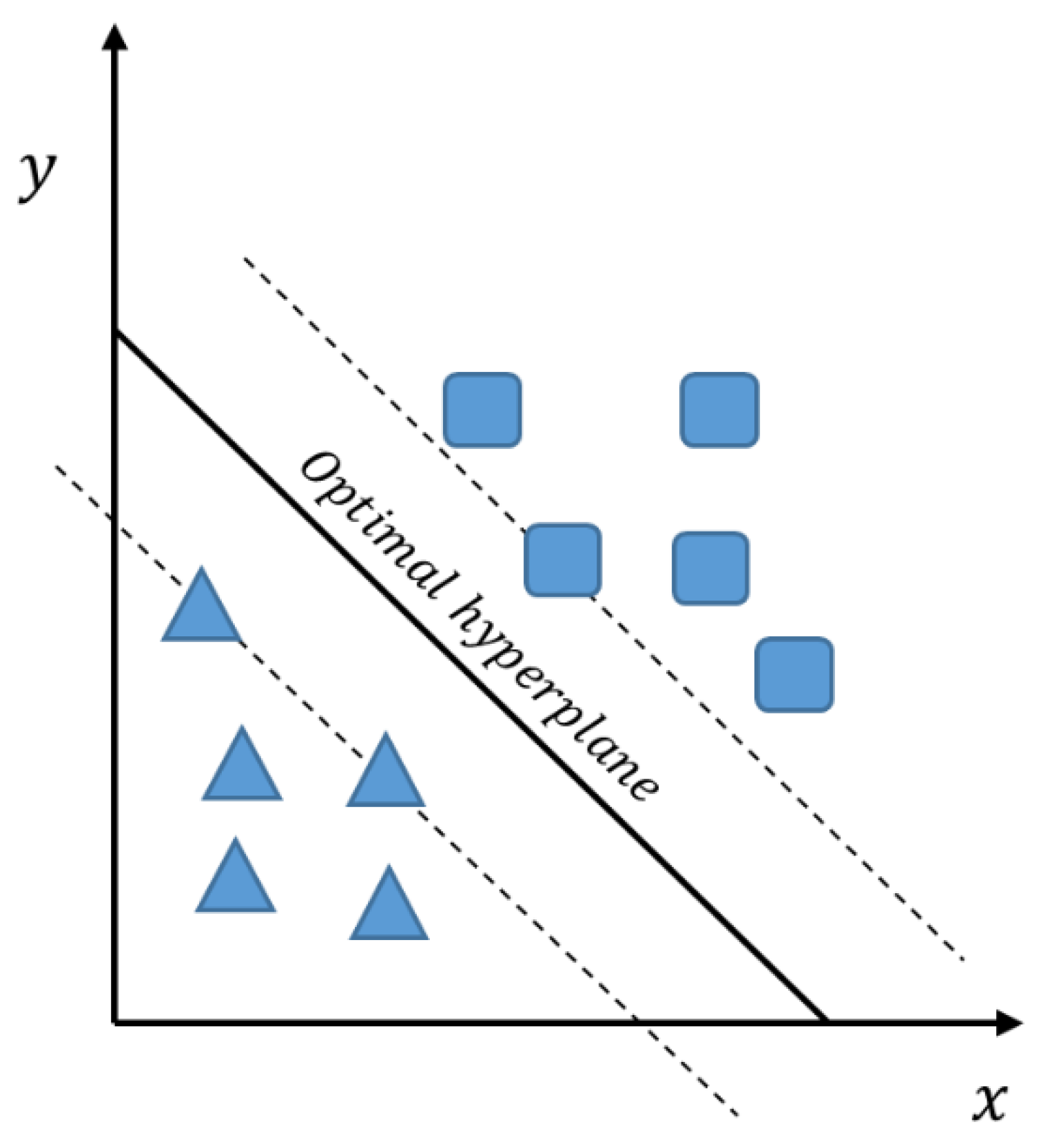
SVM is a supervised machine learning model widely used for solving regression and classification problems. It was introduced by Vladimir Vapnik et al. at AT&T and Bell Laboratories [
18]. SVM maps the training data into higher dimensional space with the help of a nonlinear mapping function also called the kernel function and then applies linear regression to separate data in high-dimensional space [
19]. Data Separation is achieved by finding optimum hyperplanes, also called support vectors, that have maximum margins from the separated classes, as shown in
Figure 4.
The version of SVM used to solve the estimation problem is called SVR, which is an excellent choice and an efficient method as demonstrated by other related research [
19]. Equations (2)–(12) show the principle workings of SVR from a mathematical perspective.
While modelling, the objective of SVM is to find a linear decision function as shown in Equation (2):
Here,
represents the weight vector and
is a constant that has to be estimated from the considered dataset, whereas
is a kernel function or nonlinear mapping function. For the regression problem, the following risk function needs to be minimized:
where
is the
, which is given by the following equation:
For the attainment of acceptable degree of error, slack variables
and
are used, which makes it a constrained minimum optimization problem, as shown in Equation (5):
subject to:
where
is a regularized constant, which is greater than zero, and provides equilibrium between training error and flatness of model.
is also a penalty for the estimation of error (i.e., greater than
).
and
are slack variables that represent the distance of actual values to corresponding boundary values of
. SVM tries to minimize
and
. A quadratic programming problem can be achieved by converting the above optimization with constraint to Lagrangian multipliers as follows:
where
and
are Lagrange multipliers. Equation (7) is subject to following conditions:
where
and
Here,
represents the kernel function, and its value can be obtained from the inner product of
and
in feature spaces
and
respectively, which satisfies Mercer’s rule. Therefore:
In general, SVM has an advantage over MLR and ANN in high-dimensional space, especially when then the size of training data set is small because the support vectors rely only on a small subset of training data, hence giving a computational advantage to SVM over other classical techniques.
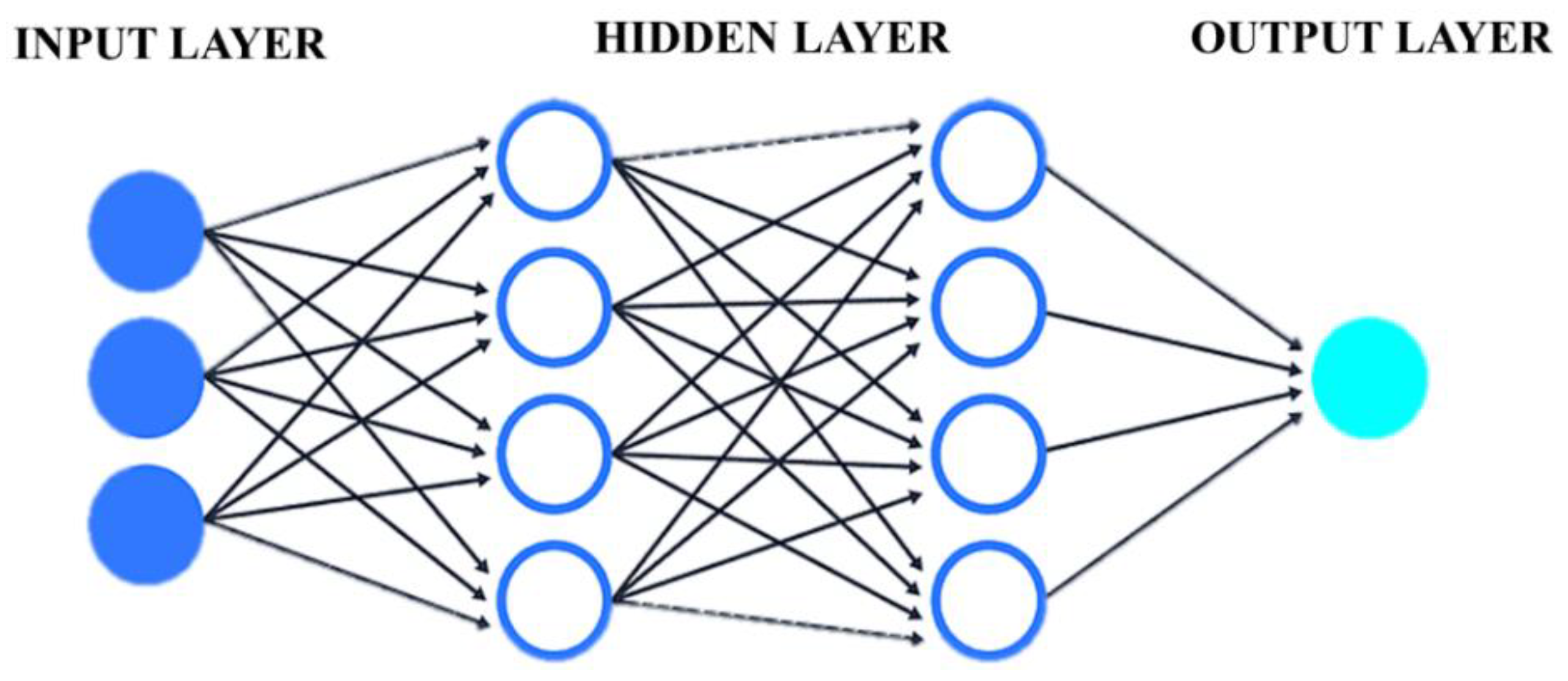
2.3. Artificial Neural Networks
ANNs are ML tools which work on the concept of biological neurons and their inter-connections. ANNs are composed of multiple units in which each unit is called a neuron that takes multiple input signals and converts it to a single output signal with the help of the activation function [
20,
21]. Therefore, it can be used to solve classification, pattern recognition, and estimation problems [
20,
21,
22]. Interconnections of neurons form a network; in fact, they form a layered structured network, in which the first one is the input layer, the last one is the output layer, and in-between any number of layers are called hidden layers [
20,
22], as shown in
Figure 5.
The mathematical function which is repeatedly performed inside ANN is given by Equation (10):
where
denotes the activation function applied to the weighted sum of all inputs from this layer, whereas
is corresponding weights of this layer.
is the input of this layer, and
is the bias of this layer. During the “learning” phase, the aim is to find the optimal value of
and
parameters for each layer, which is attained by minimizing the cost function called the mean squared error (
MSE) as follows:
where
represents the actual output (target), and
is the estimated or predicted value by ANN.
The performance of ANN depends on combination of multiple parameters such as the learning rate, number of neurons, hidden layers, optimization algorithm, and activation function [
20]. In this work, ANN is implemented using the same configuration provided by paper [
7], so the results from this model can be compared with our proposed regression models, namely, MLR and SVR. The ANN in [
7] has three layers: the input, the output layer, and only one hidden layer in-between. Furthermore, the backpropagation algorithm is used for optimization. The activation function used in this work is sigmoid, which is given by Equation (12):
2.4. Evaluation Criterion
In order to assess the performance and accuracy of proposed models, two evaluation criteria are used to measure how close the predicted value by these models are to the real value (target value). Firstly, the “regression accuracy” of these models are calculated by means of correlation coefficient
given by Equation (13).
is a correlation coefficient, between the actual outputs and the predictions of each model. A correlation coefficient of
shows
prediction accuracy, i.e., prediction equals target value:
where
is the actual output or desired output,
is the value estimated by our ML models, and
represents the total number of observations.
Furthermore, the accuracy of the predictions for the three ML models in terms of cumulative distribution function (CDF) of “percentage prediction error” is used. Accuracy results in the form of CDFs of error are perhaps more useful from a design and analysis perspective. Typically, the prediction performance of the ML tools is interpreted with a target or admissible prediction error
3. Methodology
To assess the performance of our proposed solution, the whole experimental setup provided by [
7] was reproduced using a real traffic trace. The purpose was to further validate the data set already publicly available [
23]. The traffic represented by features, was processed by different VNFs, and the averaged CPU consumption was monitored in 20 s batches [
7]. A set of network, transport, and application layer attributes (total 86 features) were used to describe the traffic. The data set was made by using these traffic features as an input, while the average central processing unit was used as an output.
Once the data set was generated, it was further used to train supervised ML models (i.e., MLR, SVR, and FNN). Then, the accuracy of these frameworks were evaluated using the cross-validation technique. The data set was further split into two sets: the training set contained 70% of the total samples, while the remaining 30% of the samples were assigned to the test set.
The training set as used to train the ML model during the training phase, while the test set was used to further validate the model. Finally, the CPU consumption estimated by the ML technique was compared with the actual measurements.
3.1. Virtual Network Functions VNFs
The experiment was performed by deploying Virtual Machines (VMs), which implements two different VNFs: Open virtual switch (OVS) [
24,
25] and Snort [
25,
26]. OVS is an open source implementation of SDN multilayer switch, while Snort is a network anomaly detection and prevention system, which can analyze the traffic.
In this work, OVS was implemented using two different configurations. The first implementation used the default settings, which forwards most of the packets and sometimes forward the packets to the SDN controller when necessary, so the controller can inspect the packets and install new forwarding rules in the OVS, which expires every 20 s. The second implementation does not forward the packets to the controller, and OVS acts as a firewall by implementing more than 300 rules. For Snort VNF, only a single configuration was used, which is the default setting and detects most of the anomalies in the network.
3.2. Traffic Preprocessing
Preprocessing of the data was usually carried out to make the data compatible with the desired ML models. The raw data were synthesized and converted to a form which could be easily utilized by our proposed ML models. The real traffic trace is used to test the performance of different VNFs. From the on-campus interconnection link, which was 10 Gbps (both incoming and outgoing), 2 traffic traces, each 5 min long, were captured at two different moments. These traffic traces were then used to reproduce the traffic in experimental environment, which was further sent to virtual network functions, and the respective CPU consumption was monitored.
For synthesis of the data in the test environment, the speed of the link as considered too high. Therefore, we scaled it by dividing the rate by 10 for day time and 40 for the night time, which resulted in approximately 2000 packets/s. The traffic was described by a set of 86 features from the network to transport layers.
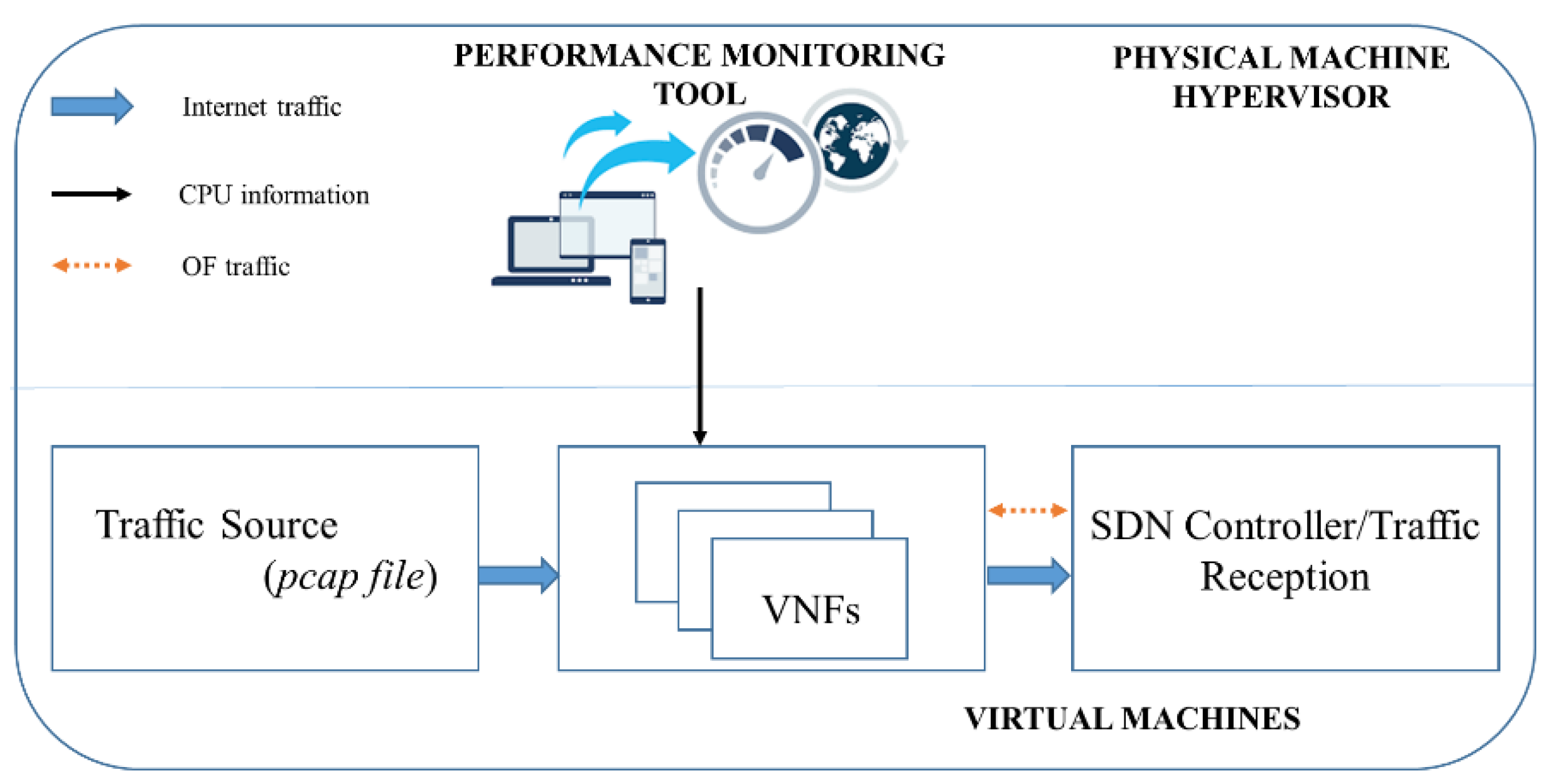
Components needed for the completion of our experiments were deployed in the single physical machine monitored by hypervisor. All the virtual machines (VMware ESXi v5.5) deployed under the hypervisor were connected with virtual links (gigabit). Traffic was generated from one virtual machine and sent to another VM where the VNF was installed. TCPreplay (v 3.4.4) was used to replay the traffic. Each VNF (Firewall, OVS, Snort) was installed on separate virtual machines, and CPU consumption was monitored with the performance monitoring tool of the hypervisor. Another VM was installed as SDN controller, which receives the traffic from VNF working as OVS, when necessary.
Figure 6 shows the complete configuration setup.
The hypervisor performance monitoring tool (Virtualization manager v2020.2.1) was used to manage and analyze the VMs performance under a single umbrella. Virtualization manger is a very powerful tool developed by SolarWinds which can monitor the CPU, memory, and storage needs in real time with good accuracy [
27]. Out of various output parameters available, only the CPU load was used because the results need to be compared and analyzed with the state-of-the-art, which uses the same parameter. This will help us to adopt the best ML model in the current scenario.
The data set was generated by collecting traffic features as an input while the average central processing unit utilization as the output. A total of 755 data points were collected for firewall, 1172 for OVS, and 1359 for Snort VNF. Our collected data set showed exactly the same behavior when applied to ML models, with the one that is publicly available at [
23], which further validates the data set, but for fair comparison with the state-of-the-art, we used the same data set publicly available at [
23].
3.3. Machine Learning Training
In this work, we have selected MLR and SVR, which are compared and analyzed against state-of-the-art FNN to identify the best estimator which can accurately predict CPU load for VNF. To train MLR and SVR, we have used MATLAB Statistics and Machine Learning Toolbox 11.5 while Deep Learning toolbox 12.1 is used to train the FNN. The traditional technique MLR model requires little to no parameter tweaking, which means the default settings of the toolbox, with preset and term parameters set to linear and robust parameters set to off, were used. Furthermore, the mathematical function performed by MLR technique on the data set was be based on Equation (14), which can be written as following.
The LS estimation function was used to estimate the values of parameter , which gave us optimal values for parameters .
For developing the SVM model, the main aim was to minimize the on the training data set, which can be achieved by selecting the appropriate kernel function. For this purpose, all the well-known kernel functions (Linear, quadratic, Gaussian, and cubic) in the MATLAB Statistics and Machine Learning Toolbox were first tested, and finally, SVM with polynomial cubic kernel was used to develop our model, since it outperformed all the other models for our considered data set. Furthermore, parameters such as kernel scale, box constraint, and Epsilon are set to automatic, which is the default setting. Cubic kernel has many advantages over other kernel functions, such as it can easily map non-linearity in the training data.
The FNN was implemented using the same configuration provided by paper [
7], which had three layers. The input layer consisted of 86 inputs neurons, while the output layer had only 1 output neuron, in-between only 1 hidden layer with 5 neurons. We also tested the FNN with different numbers of neurons, but empirically, we have learned that the best number of neurons in the hidden layers is five because this number provided the minimum value of MSE in the training and testing phase. In addition, different activation functions were tested in the hidden layer, and sigmoid was selected, which gave the best results among others. Further increasing the number of neurons in the hidden layer gave rise to the overfitting problem in FNN. The Levenberg–Marquardt algorithm was used for the weight optimization of FNN. The next section details the overall system performance of MLR, SVR, and FNN in terms of regression accuracy and percentage error.
5. Discussion
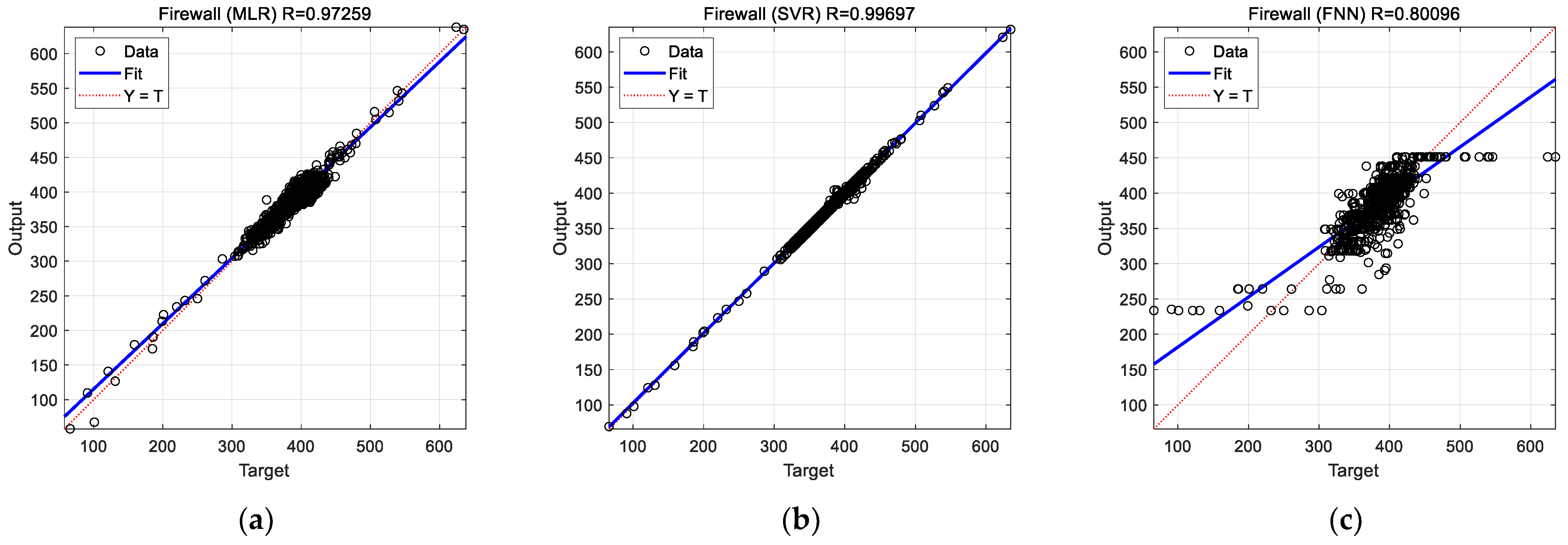
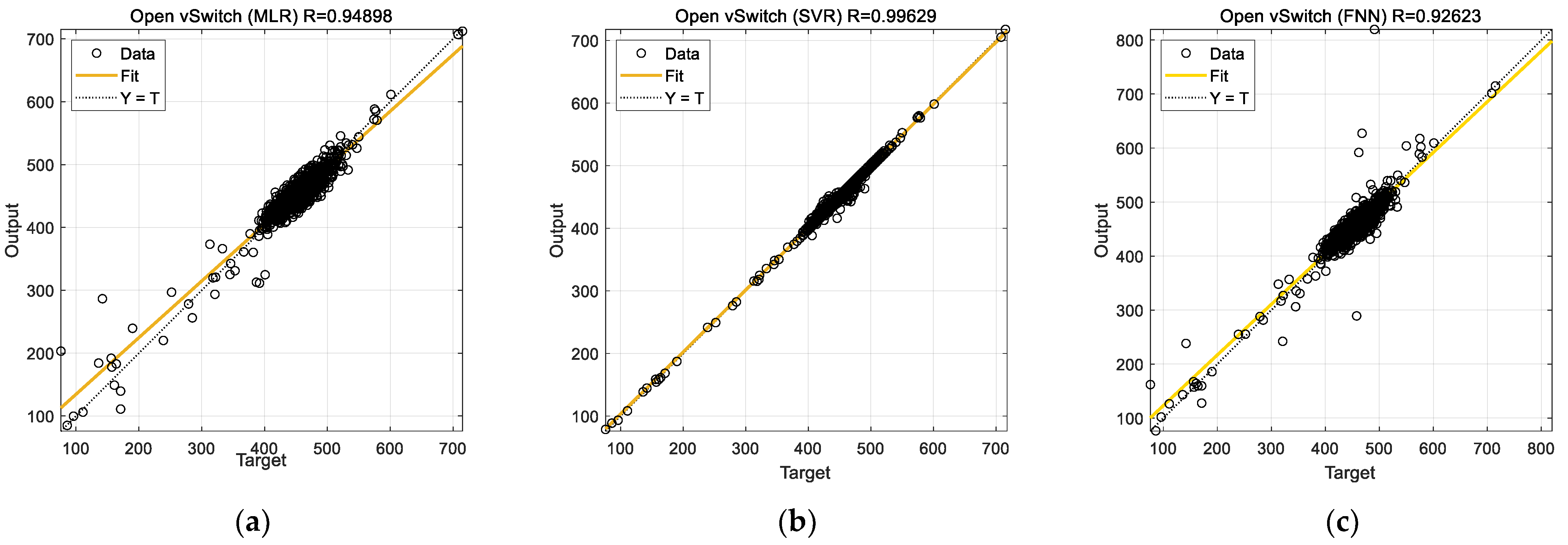
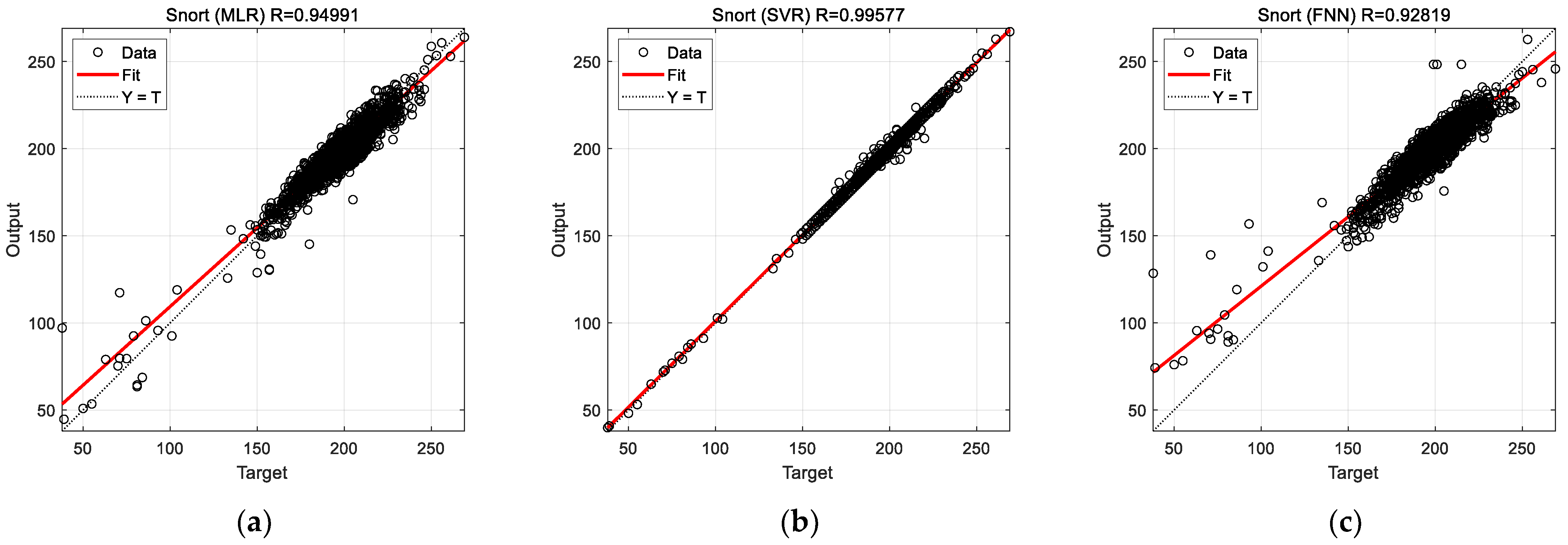
In this section, experimental results from the previous section are discussed. The results concerned prediction of the CPU usage of three VNFs, namely, firewall, OVS, and Snort via different ML models (MLR, SVR, and FNN). The regression plots for predictions (cf.
Figure 7,
Figure 8 and
Figure 9) suggest the superiority of the SVR model in terms of prediction accuracy for the considered VNFs. The prediction accuracy of the FNN for the firewall function is considerably low. Especially, the FNN is very inaccurate in predicting extreme (both low and high) CPU usage (cf.
Figure 7c). Although prediction accuracy of FNN improves significantly for the OVS and Snort functions, it remains inferior to MLR and SVR in all the studied cases.
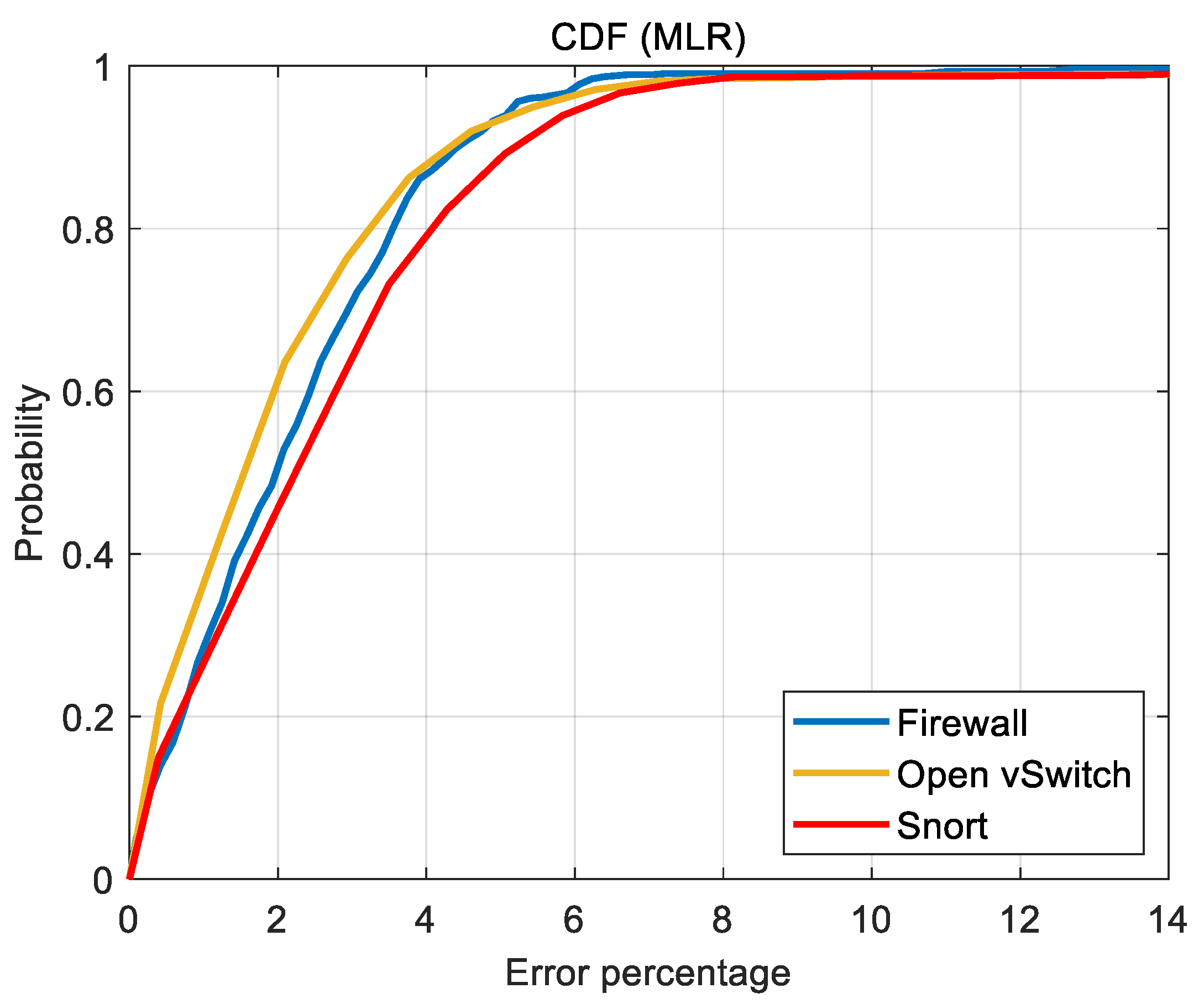
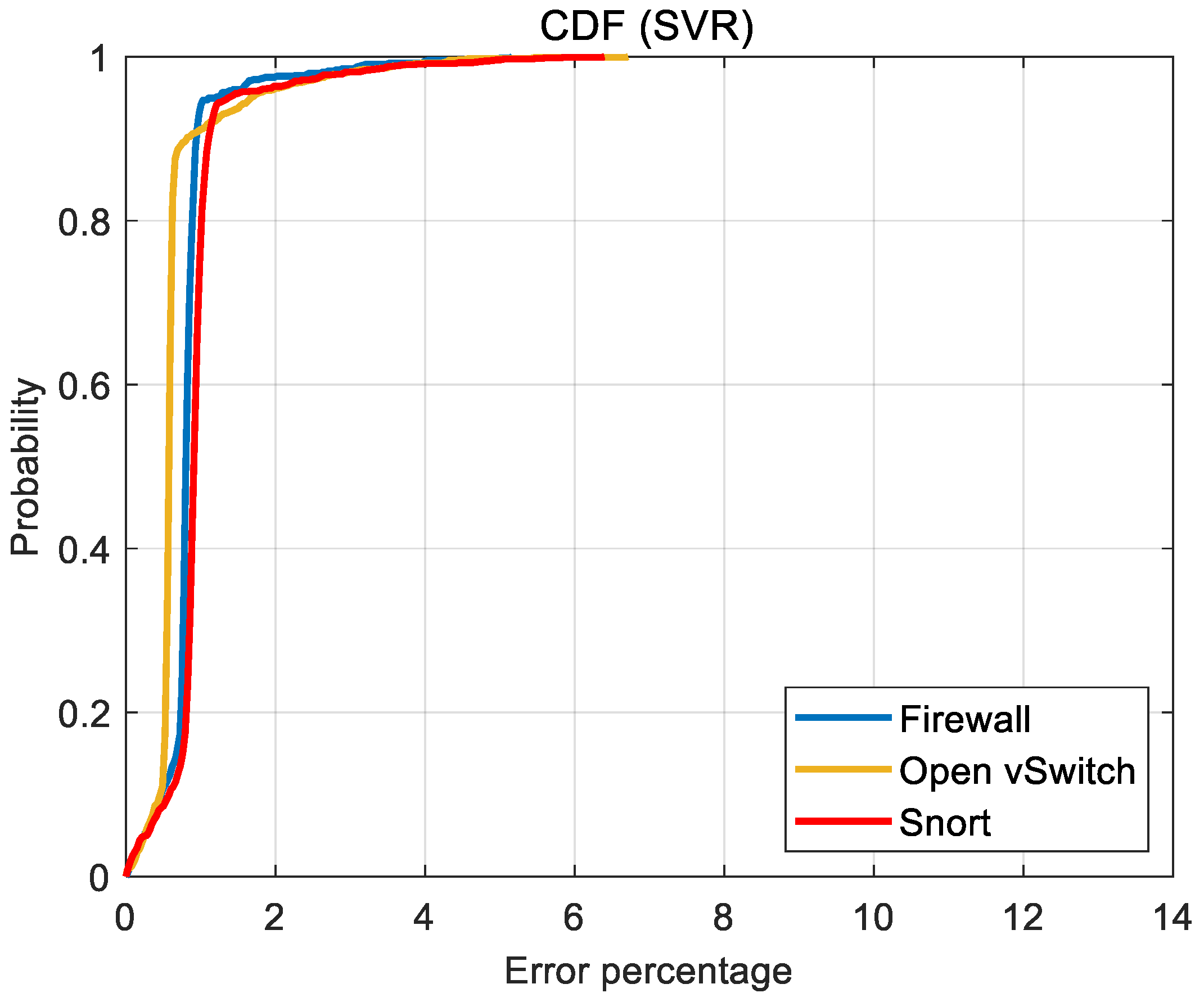
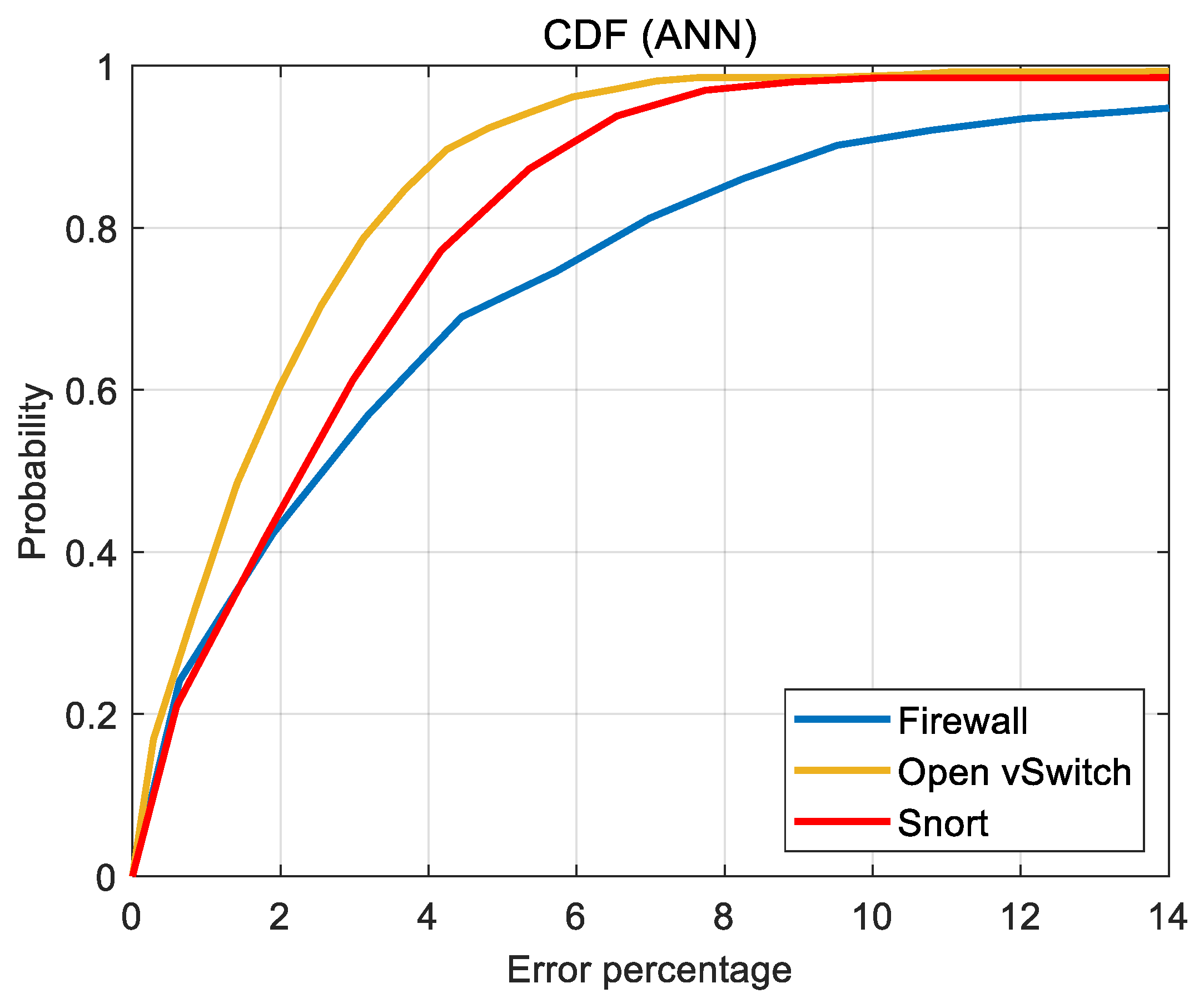
Accuracy results in the form of the CDFs of error (
Figure 10,
Figure 11 and
Figure 12) are perhaps more useful for the design and analysis of SDN. Typically, the prediction performance of the ML tools is interpreted with a target or admissible prediction error. For the following discussion, it is assumed that up to a 2% prediction error is admissible. Then, it is of interest to see how frequent the error in the ML predictions is admissible. For the SVR, the prediction error is admissible at least approximately 95% of the time for all the studied VNFs. On the other hand, both the MLR and FNN produce acceptable predictions only 60% of the time for their best cases, i.e., OVS.
The computational nature or data set size of the VNF appears to have negligible effect on the prediction accuracy of the SVR. On the other hand, prediction accuracy of FNN shows significant variations with data set size. Moreover, for the acceptable error of up to 2%, MLR prediction accuracy improves as the computational intensity of the VNF increases i.e., predictions of OVS are more accurate than those of Snort (cf.
Figure 10). However, such a clear trend with respect to computational intensity of the VNF cannot be seen in the FNN predictions (cf.
Figure 12).
The poorer prediction performance of FNN, especially in the case of firewall, can be attributed to the relatively small data set size for firewall CPU usage. The prediction performance of FNN can be improved by deploying a deeper ANN with multiple hidden layers. Moreover, the FNN can be complemented with principal component analysis for improving its prediction accuracy. Nevertheless, exploiting the true potential of an ANN typically requires a sufficiently large data set. Therefore, it will be an interesting future work to compare the prediction accuracy of the ML models for a larger and equal-sized data sets for each VNF.
6. Conclusions
In this work, we investigated supervised ML techniques, namely, MLR, SVR, and FNN, to model resource requirements, particularly the CPU consumption of complex network entities such as virtual network functions deployed in software defined networks. A total of 86 input features from the transport to application layer were used to model the association of these input to corresponding output, which is CPU consumption. The feasibility of such an approach is validated by the obtained results and other research work, mentioned in the related work. Our experiments demonstrated that ML techniques can be used to model the resource requirements of different VNF. The results obtained suggest the superiority of the SVR model in terms of prediction accuracy for the considered VNFs over MLR and FNN, which is further validated by CDFs of the percentage prediction error.
Moreover, the prediction performance of FNN can be improved by deploying a deeper ANN with multiple hidden layers. Exploiting the true potential of an ANN typically requires a sufficiently large data set. Therefore, it will be an interesting future work to compare prediction accuracy of the ML models for a larger and equal sized data sets for each VNF. In this study, only the CPU load of different VNFs is modeled using ML techniques; however, in the future, the study can be extended to model and investigate other computer resources such as memory usage, secondary memory usage, or storage requirements.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}