
Object Detection-Based Video Compression



Abstract
:1. Introduction
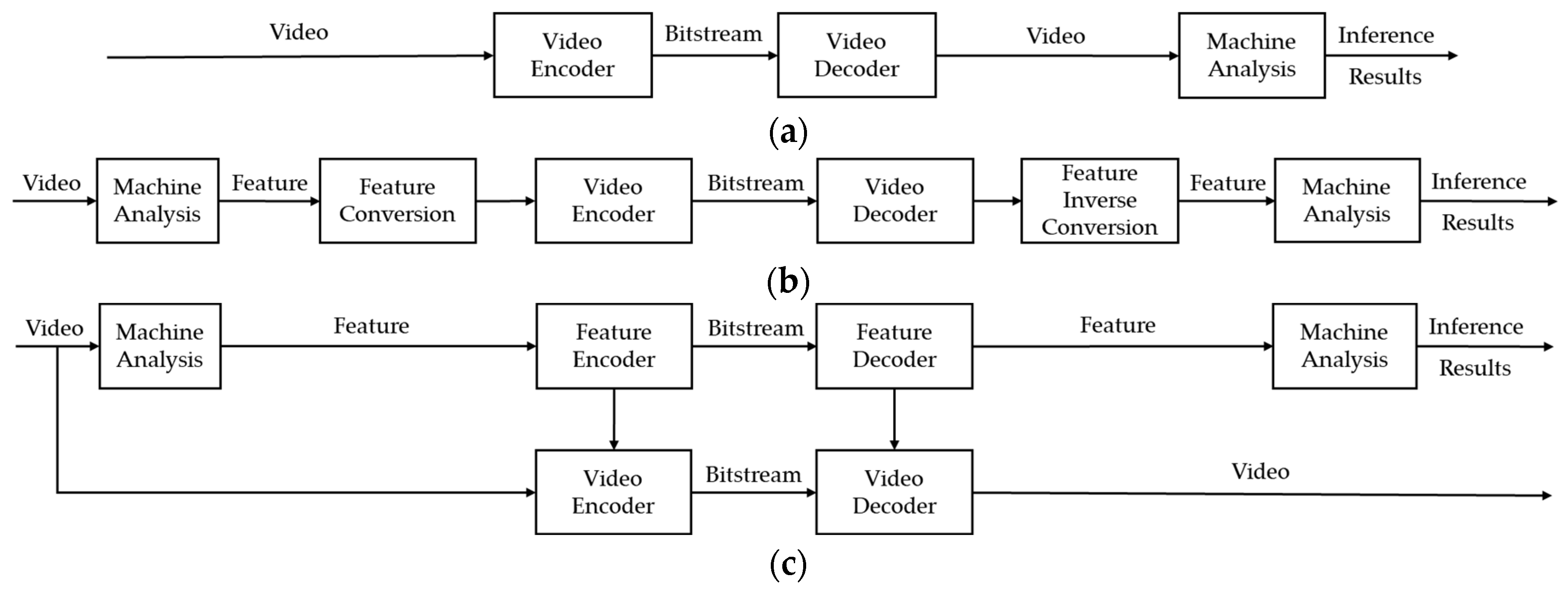
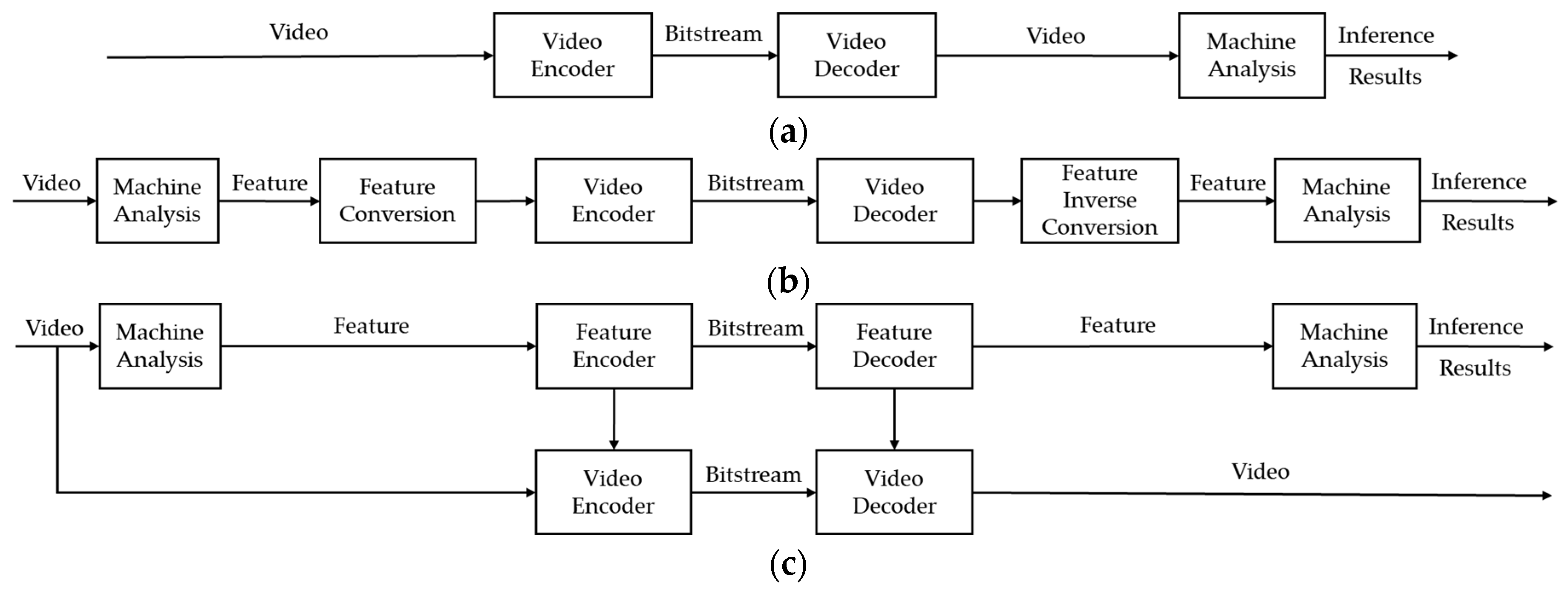
2. Related Works
- Efficient compression of bitstreams: It should have a higher compression rate than VVC-compressed bitstreams with similar performance.
- Varying degrees of performance should be supported: The goal is to support different optimizations for scenarios supporting single and multiple missions.
- Both machine-only and hybrid machine and human applications should be supported.
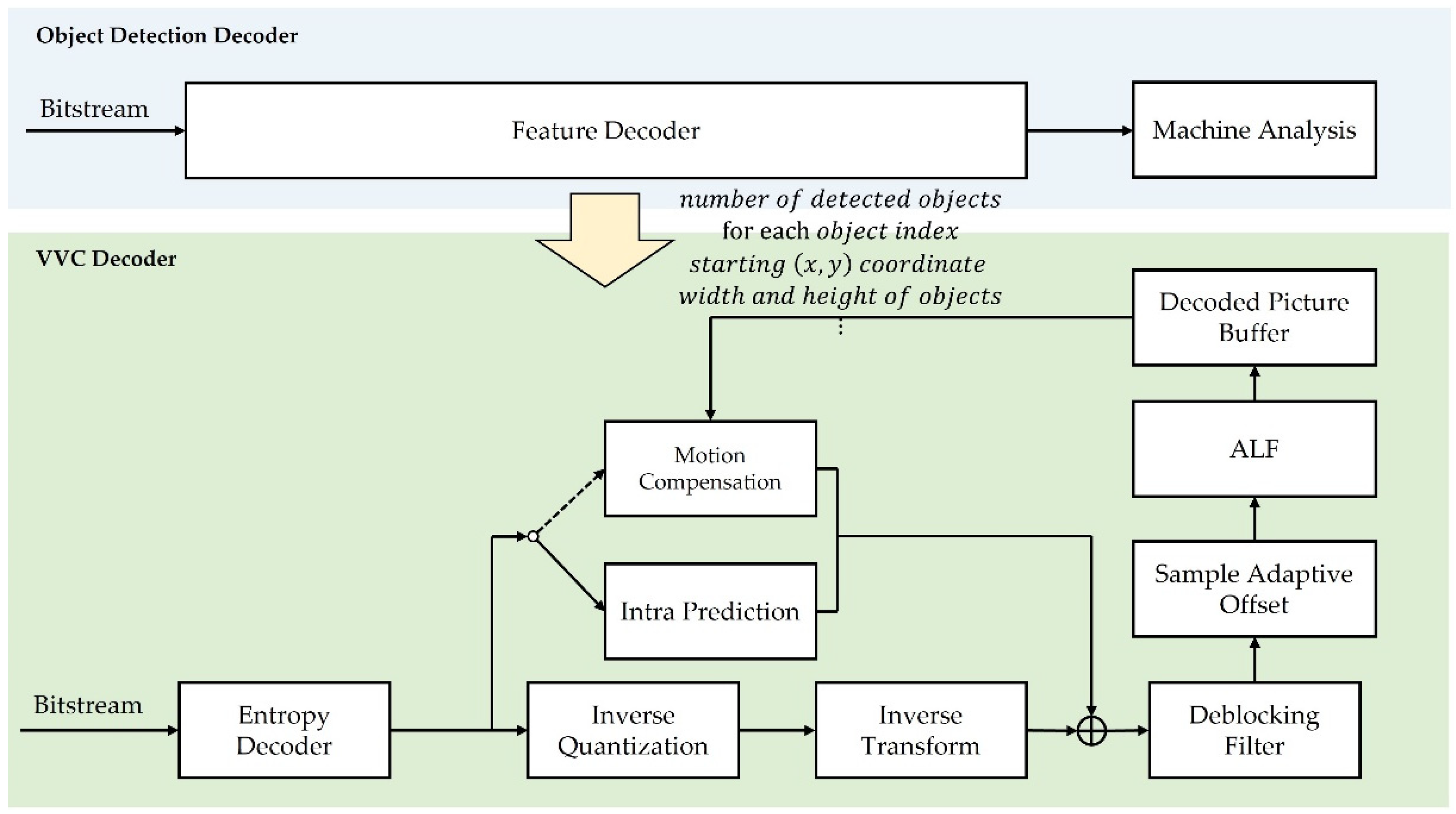
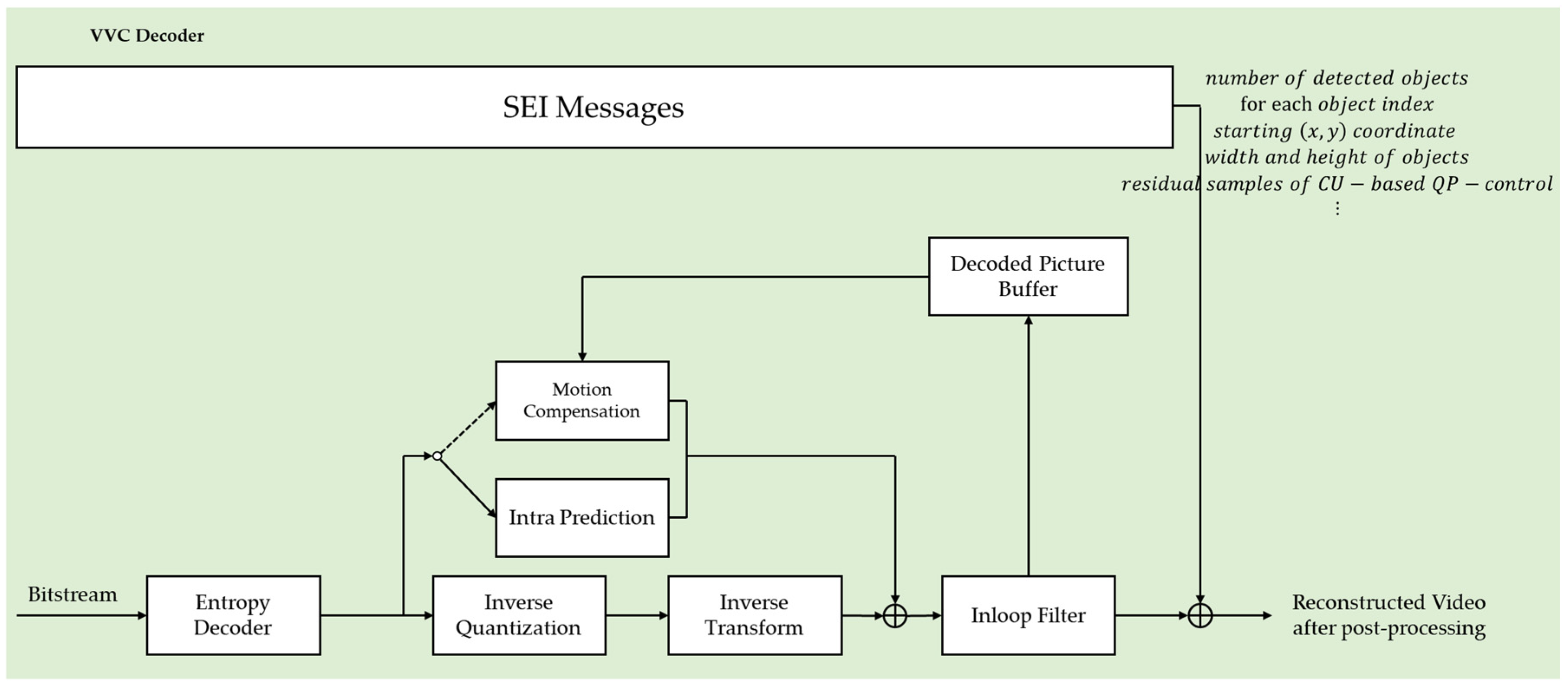
3. Proposed Methods
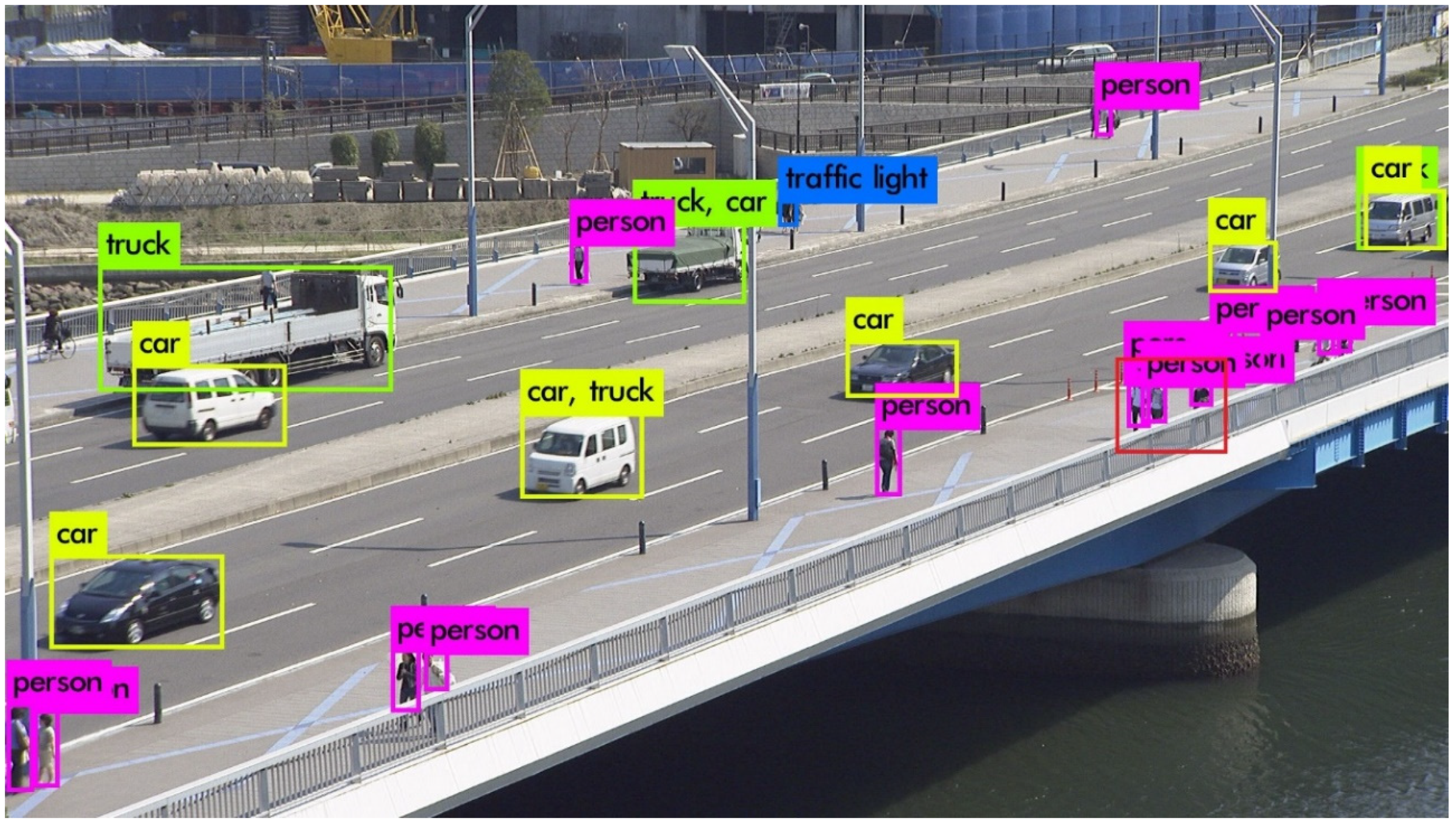
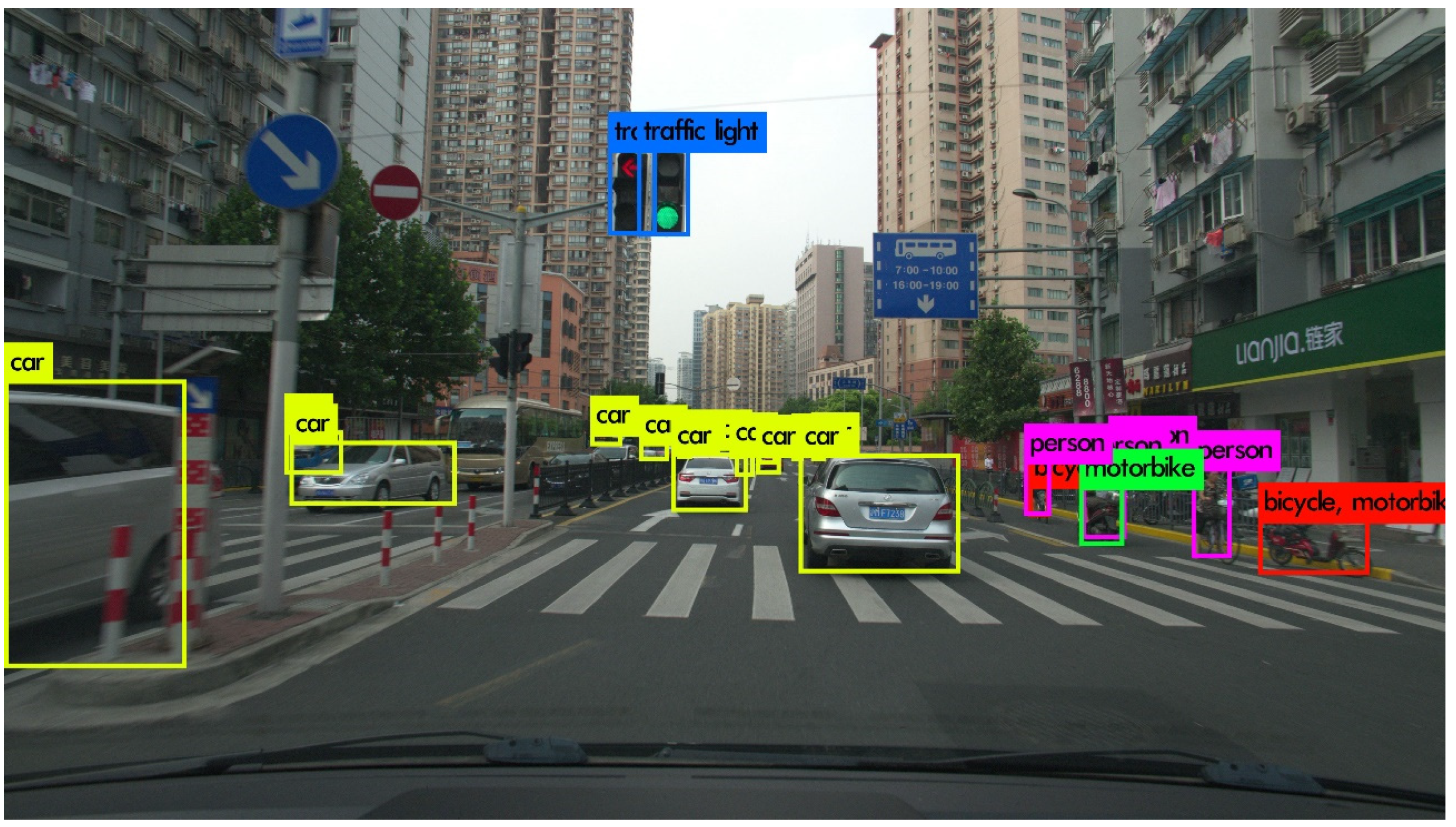
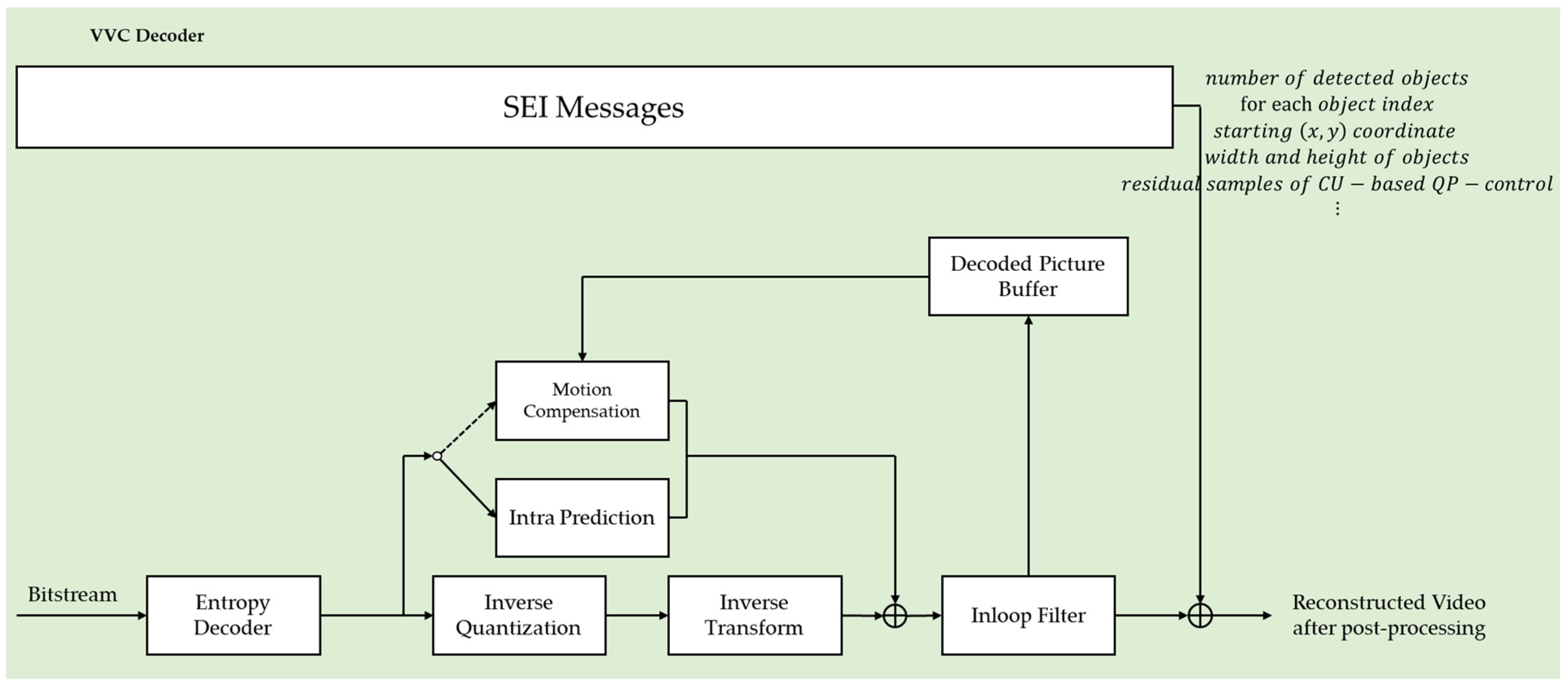
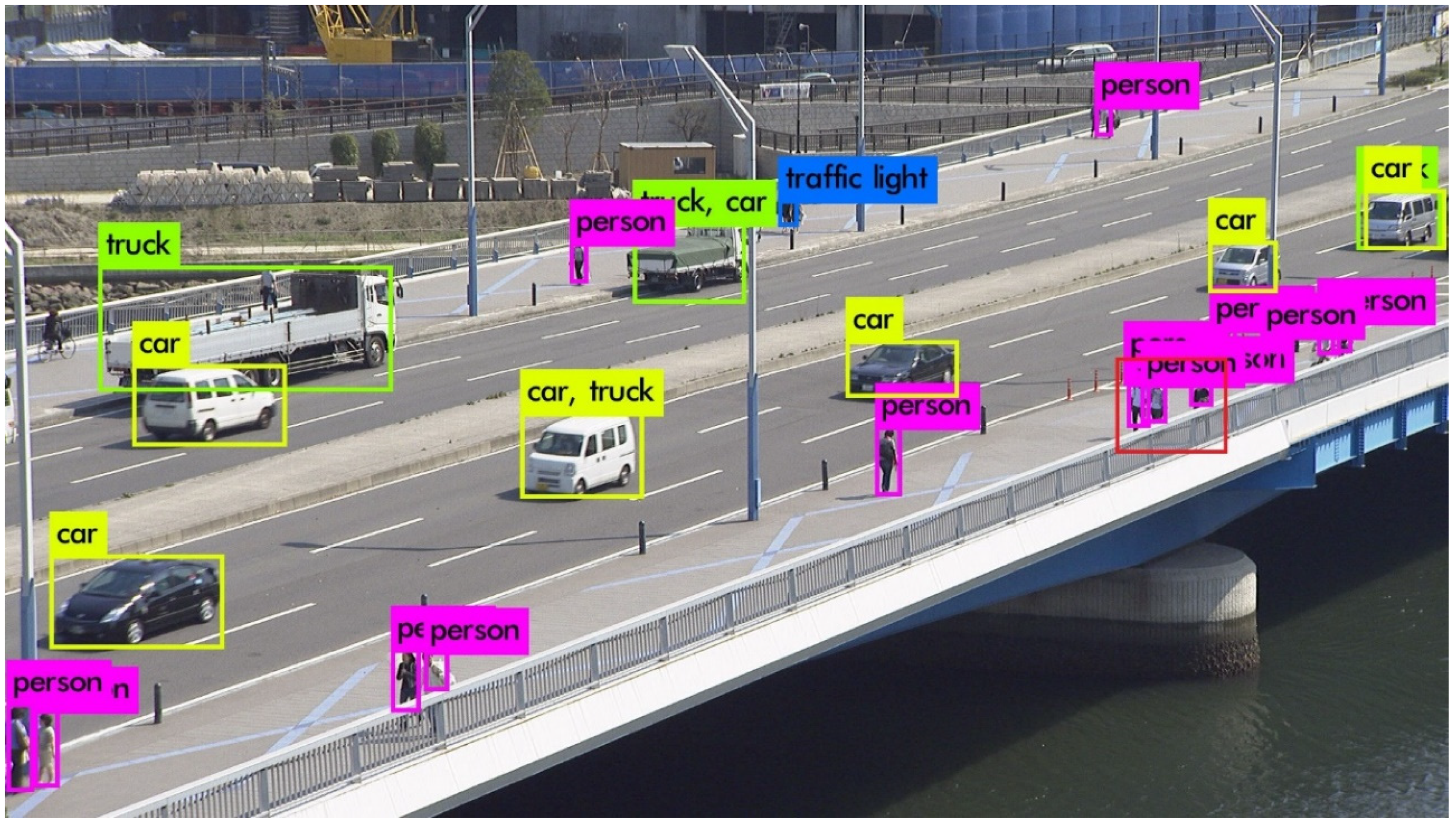
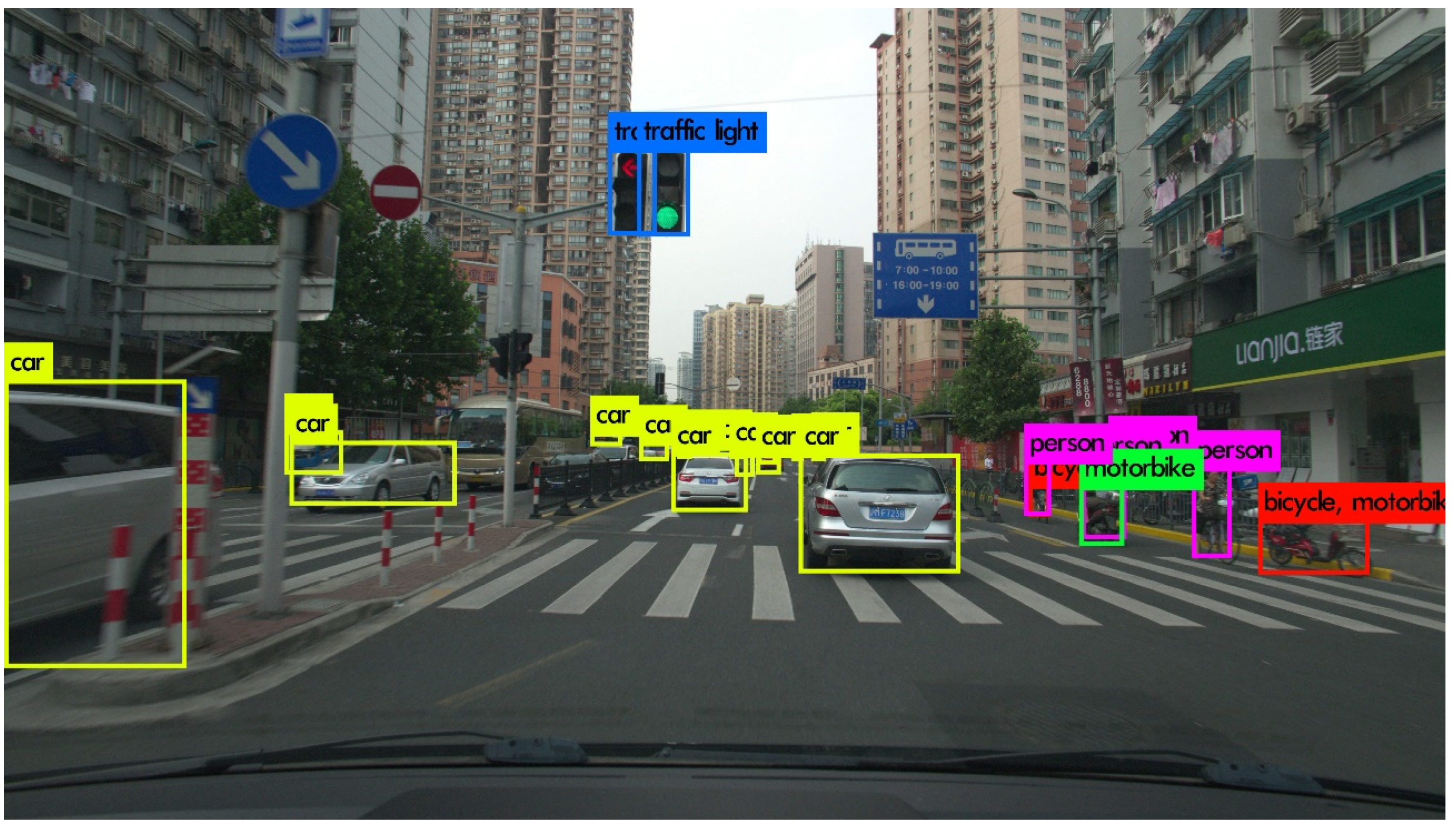
3.1. Object Detection-Based Video Compression
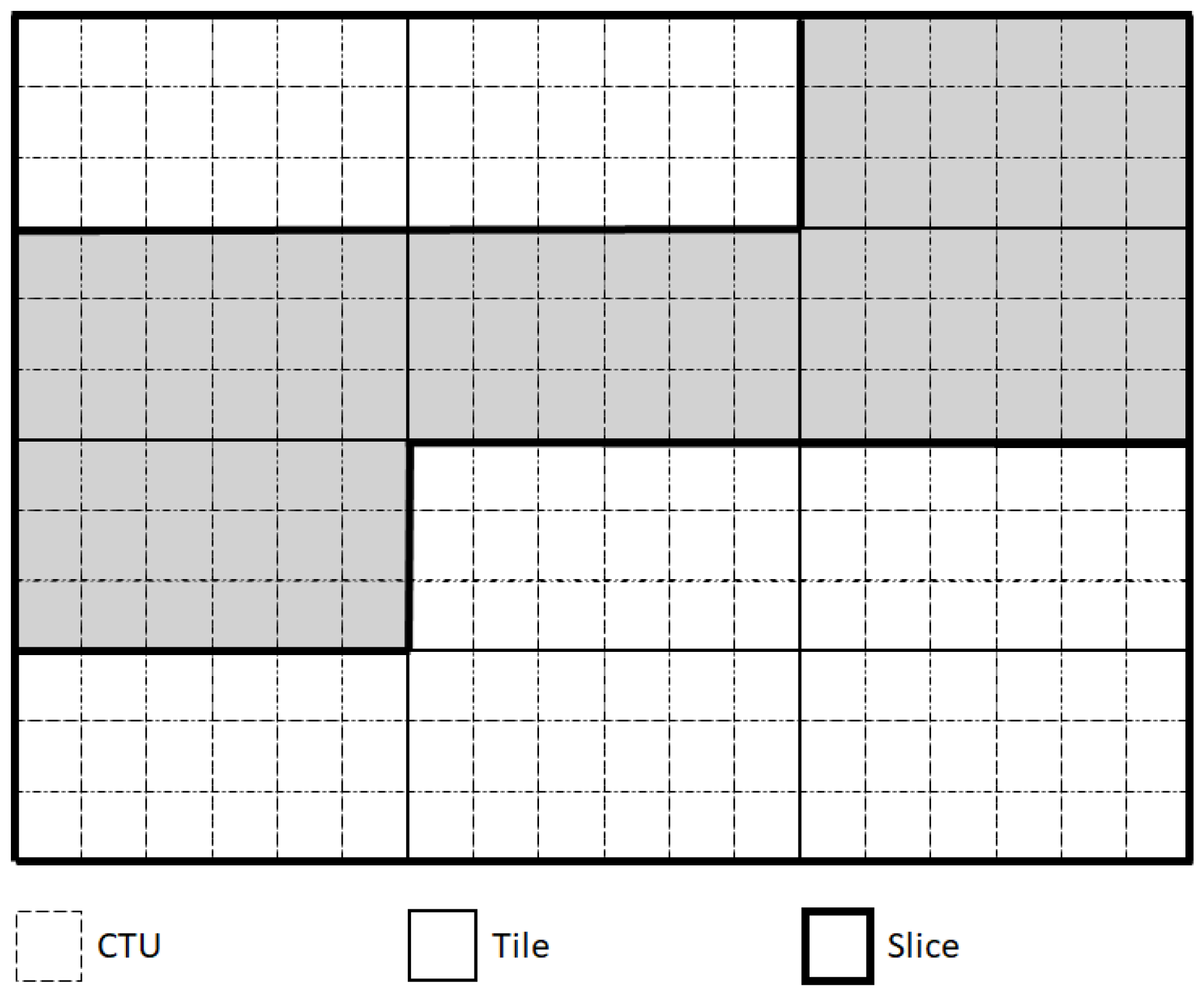
3.2. CU-Based QP-Control
4. Experimental Results
4.1. Experimental Conditions
4.2. Experimental Results
- Even if the PSNR is high in the object-detected areas, background areas that do not include object areas usually take up more area than the detected object areas in a picture, so the PSNR decreased due to a high QP value in the background areas, and the bitrates increased to compensate for the distortion.
- In the case of intra prediction, the already-decoded reference samples with a high QP value that were used to encode the current block had relatively higher quantization errors than those samples decoded with a low QP value, so that the coding efficiency dropped due to the high intra prediction error.
- In the case of inter prediction using the P (Predictive) and B (Bi-directional predictive) pictures, the background areas in the previous reference pictures were decoded with a high QP value, which was used to predict that each block in the current picture would have relatively higher quantization errors than those areas decoded with a low QP value; thus, the coding efficiency dropped due to the high inter prediction error, i.e., when the proposed object detection-based video coding was applied, the PSNRs of the previously decoded pictures were lower than those of the previously decoded pictures in VVC.
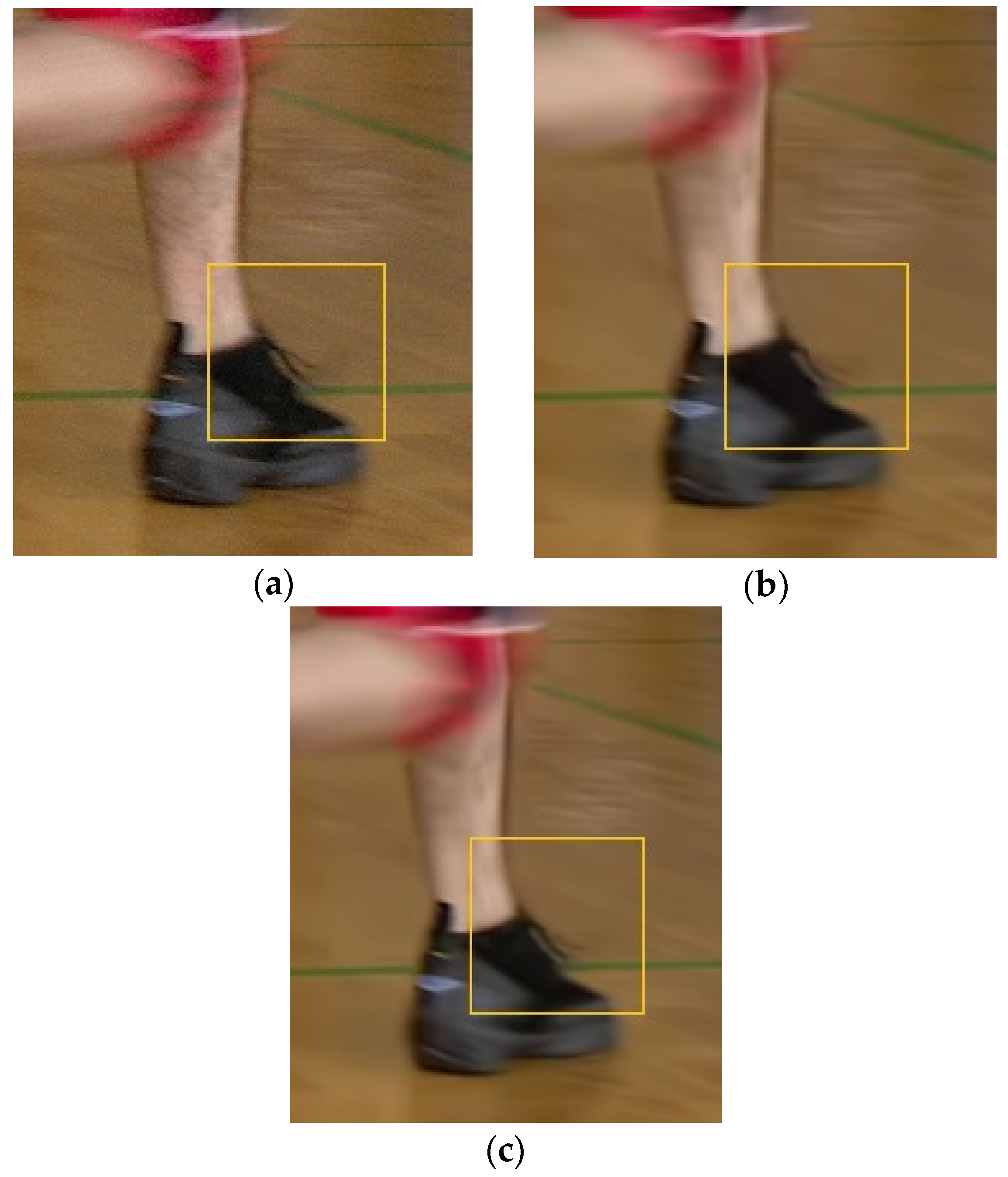
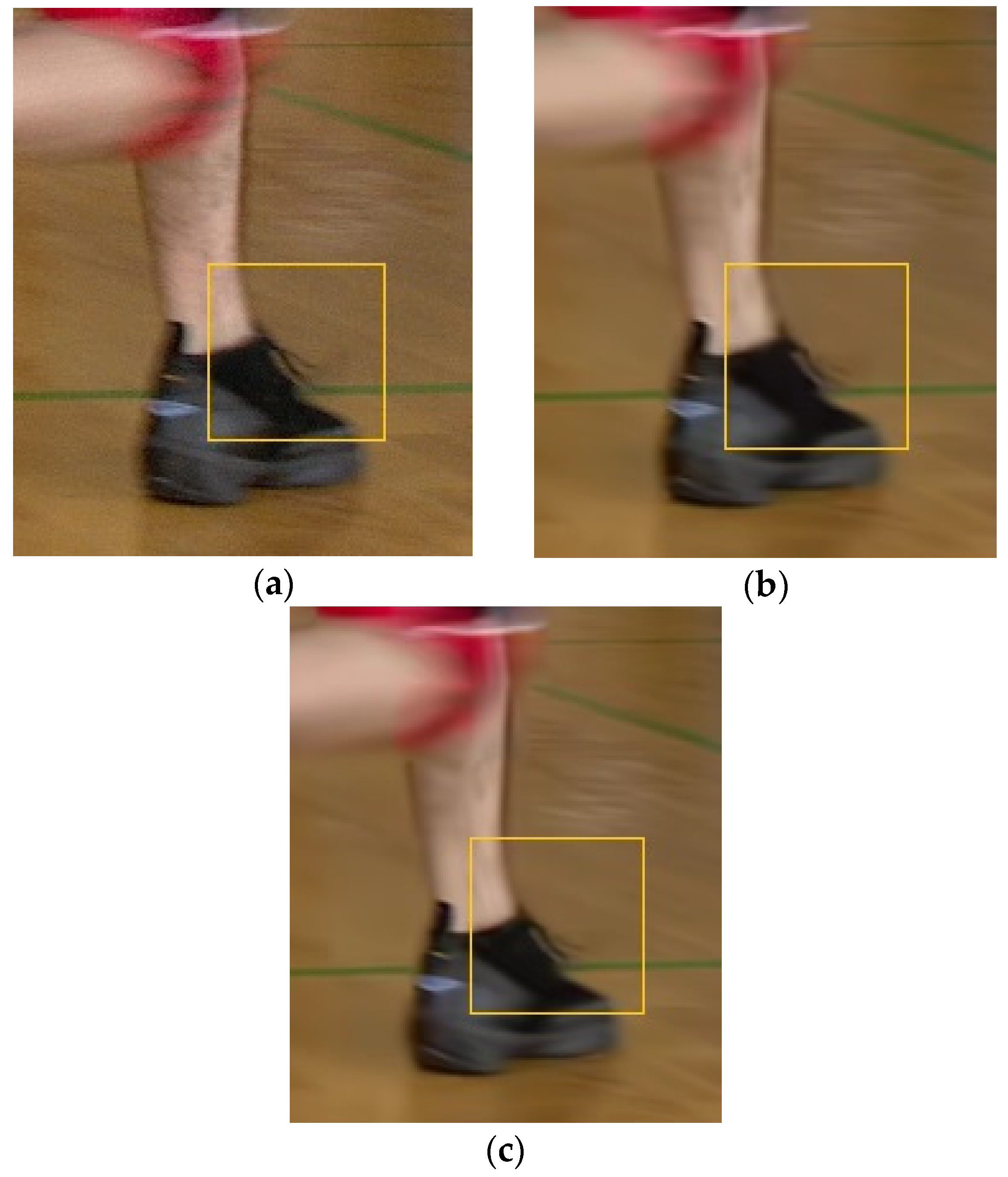
- The object detection algorithm, YOLOv3, sometimes fails to detect objects that should be detected; fast motion and rapid zooming in and out of the camera are the main issues that lower the detection accuracy. When the size and shape of objects change quickly, the object detection algorithm has difficulty detecting objects properly. These issues result in a false-alarm area, where the object should be accurately detected but is not. High quantization error occurs in the false-alarm area due to the high QP value. For this reason, high inter prediction errors occur due to the low quality of the false alarm areas to be used as the reference picture. Therefore, the PSNR and BD-rate performance in the RA configuration that uses inter and intra predictions are worse than those in the AI configuration that use only intra prediction. In particular, the average Y BD-rates decreased to 4.10%, 3.54%, and 3.74%, respectively, in the BasketballDrill, BasketballDrive, and BQMall sequences, due to their fast object movements.
- In Table 5, the BD-rates of the DaylightRoad2 and BQMall sequences in the AI configuration show improvement despite the poor PSNR quality in the background areas.
5. Conclusions
6. Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cisco Annual Internet Report. Cisco Annual Internet Report (2018–2023) White Paper. 2020. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 28 September 2020).
- Bross, B.; Chen, J.; Liu, S.; Wang, Y.-K. Versatile Video Coding (Draft 10), document JVET-S2001 of Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 19th JVET Meeting, Geneva, Switzerland, 22 June–1 July 2020. [Google Scholar]
- High Efficient Video Coding (HEVC), Standard ITU-T Recommendation H.265 and ISO/IEC 23008-2. April 2013. Available online: https://www.itu.int/rec/T-REC-H.265 (accessed on 28 April 2022).
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Advanced Video Coding (AVC), Standard ITU-T Recommendation H.264 and ISO/IEC 14496-10. May 2003. Available online: https://www.itu.int/rec/T-REC-H.264 (accessed on 20 April 2022).
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Ye, Y.; Kim, S.H. Algorithm description for Versatile Video Coding and Test Model 10 (VTM 10), document JVET-S2001 of Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 19th JVET Meeting, Geneva, Switzerland, 22 June–1 July 2020. [Google Scholar]
- Lainema, J.; Bossen, F.; Han, W.-J.; Min, J.; Ugur, K. Intra Coding of the HEVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1792–1801. [Google Scholar] [CrossRef]
- Flierl, M.; Wiegand, T.; Girod, B. Rate-constrained multihypothesis prediction for motion-compensated video compression. IEEE Trans. Circuits Syst. Video Technol. 2002, 12, 957–969. [Google Scholar] [CrossRef]
- Sole, J.; Joshi, R.; Nguyen, N.; Ji, T.; Karczewicz, M.; Clare, G.; Henry, F.; Duenas, A. Transform Coefficient Coding in HEVC. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1765–1777. [Google Scholar] [CrossRef]
- Norkin, A.; Bjontegaard, G.; Fuldseth, A.; Narroschke, M.; Ikeda, M.; Andersson, K.; van der Auwera, G. HEVC Deblocking Filter. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1746–1754. [Google Scholar] [CrossRef]
- Fu, C.-M.; Alshina, E.; Alshin, A.; Huang, Y.-W.; Chen, C.-Y.; Tsai, C.-Y.; Hsu, C.-W.; Lei, S.-M.; Park, J.-H.; Han, W.-J. Sample Adaptive Offset in the HEVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1755–1764. [Google Scholar] [CrossRef]
- Tsai, C.-Y.; Chen, C.-Y.; Yamakage, T.; Chong, I.S.; Huang, Y.-W.; Fu, C.-M.; Itoh, T.; Watanabe, T.; Chujoh, T.; Karczewicz, M.; et al. Adaptive Loop Filtering for Video Coding. IEEE J. Sel. Top. Signal Process. 2013, 7, 934–945. [Google Scholar] [CrossRef]
- Bjøntegaard, G. Calculation of Average PSNR Differences between RD-Curves, document VCEG-M33, ITU-T SG 16 Q 6 Video Coding Experts Group (VCEG). In Proceedings of the 13th VCEG Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Bjøntegaard, G. Improvements of the BD-PSNR Model, document VCEG-AI11, ITU-T SG 16 Q 6 Video Coding Experts Group (VCEG). In Proceedings of the 35th VCEG Meeting, Berlin, Germany, 16–18 July 2008. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only Look Once: Unified, Real-time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Yu, L.; Lee, J.; Rafie, M.; Liu, S. Draft use cases and requirements for Video Coding for Machines, document N133 of ISO/IEC JTC 1/SC 29/WG 2. In Proceedings of the 136th MPEG Meeting, Online, 11–15 October 2021. [Google Scholar]
- YOLO: Real-Time Object Detection. YOLO Website. Available online: https://pjreddie.com/darknet/yolo/ (accessed on 1 July 2020).
- Gao, W.; Liu, S.; Xu, X.; Rafie, M.; Zhang, Y.; Curcio, I. Recent Standard Development Activities on Video Coding for Machines. arXiv 2021, arXiv:2105.12653. [Google Scholar]
- Rafie, M.; Zhang, Y.; Liu, S. Evaluation Framework for Video Coding for Machines, document N134 of ISO/IEC JTC 1/SC 29/WG 2. In Proceedings of the 136th MPEG Meeting, Online, 11–15 October 2021. [Google Scholar]
- Yang, W.; Huang, H.; Hu, Y.; Duan, L.-Y.; Liu, J. Video Coding for Machine: Compact Visual Representation Compression for Intelligent Collaborative Analytics. arXiv 2021, arXiv:2110.09241. [Google Scholar]
- Fischer, K.; Brand, F.; Herglotz, C.; Kaup, A. Video Coding for Machines with Feature-Based Rate-Distortion Optimization. In Proceedings of the 2020 IEEE 22nd International Workshop on Multimedia Signal Processing, Tampere, Finland, 21–24 September 2020. [Google Scholar]
- Duan, L.-Y.; Liu, J.; Yang, W.; Huang, T.; Gao, W. Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics. arXiv 2020, arXiv:2001.03569v2. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Li, X.; Seregin, V.; Sühring, K. JVET common test conditions and software reference configurations for SDR video, document N1010 of Joint Video Experts Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11. In Proceedings of the 14th JVET Meeting, Geneva, Switzerland, 19–27 March 2019. [Google Scholar]
- Sejong University, Digital Media System Laboratory. DMS Website. Available online: https://dms.sejong.ac.kr/research.htm (accessed on 22 April 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Name of Object | Index | Name of Object |
|---|---|---|---|
| 0 | airplane | 10 | table |
| 1 | bicycle | 11 | dog |
| 2 | bird | 12 | horse |
| … | … | … | … |
| 4 | bottle | 14 | person |
| 8 | chair | 18 | train |
| 9 | cow | 19 | monitor |
| Index | Name of Object | Index | Name of Object |
|---|---|---|---|
| 0 | person | 60 | table |
| 1 | bicycle | 61 | toilet |
| 2 | car | 62 | monitor |
| 3 | motorbike | 63 | laptop |
| … | … | … | … |
| 18 | sheep | 78 | hair drier |
| 19 | cow | 79 | toothbrush |
| Class | Sequence Name | Picture Size | Number of Picture | Frame Rate | Bit Depth |
|---|---|---|---|---|---|
| A1 | Tango2 | 3840 × 2160 | 294 | 60 | 10 |
| FoodMarket4 | 3840 × 2160 | 300 | 60 | 10 | |
| Campfire | 3840 × 2160 | 300 | 30 | 10 | |
| A2 | CatRobot1 | 3840 × 2160 | 300 | 60 | 10 |
| DaylightRoad2 | 3840 × 2160 | 300 | 60 | 10 | |
| ParkRunning3 | 3840 × 2160 | 300 | 50 | 10 | |
| B | MarketPlace | 1920 × 1080 | 600 | 60 | 10 |
| RitualDance | 1920 × 1080 | 600 | 60 | 10 | |
| Cactus | 1920 × 1080 | 500 | 50 | 8 | |
| BasketballDrive | 1920 × 1080 | 500 | 50 | 8 | |
| BQTerrace | 1920 × 1080 | 600 | 60 | 8 | |
| C | RaceHorses | 832 × 480 | 300 | 30 | 8 |
| BQMall | 832 × 480 | 600 | 60 | 8 | |
| PartyScene | 832 × 480 | 500 | 50 | 8 | |
| BasketballDrill | 832 × 480 | 500 | 50 | 8 | |
| D | RaceHorses | 416 × 240 | 300 | 30 | 8 |
| BQSquare | 416 × 240 | 600 | 60 | 8 | |
| BlowingBubbles | 416 × 240 | 500 | 50 | 8 | |
| BasketballPass | 416 × 240 | 500 | 50 | 8 |
| Random Access (RA) | All Intra (AI) | |||||||
|---|---|---|---|---|---|---|---|---|
| Class | Sequence | QP | Average Δ-PSNR | Average ΔCb-PSNR | Average ΔCr-PSNR | Average ΔY-PSNR | Average ΔCb-PSNR | Average ΔCr-PSNR |
| Class A1 4K | Tango2 | 22 | 0.05% | −0.04% | 0.07% | 0.23% | 0.04% | 0.10% |
| 27 | 0.03% | 0.01% | 0.09% | 0.08% | −0.02% | 0.07% | ||
| 32 | 0.08% | 0.13% | 0.08% | 0.10% | −0.03% | 0.01% | ||
| 37 | 0.12% | 0.30% | 0.12% | 0.13% | 0.02% | 0.10% | ||
| FoodMarket4 | 22 | 0.54% | 0.57% | 0.42% | 0.08% | 0.08% | 0.08% | |
| 27 | 0.61% | 0.58% | 0.46% | 0.08% | 0.10% | 0.14% | ||
| 32 | 0.70% | 0.69% | 0.60% | 0.13% | 0.10% | 0.15% | ||
| 37 | 0.79% | 0.70% | 0.55% | 0.22% | 0.17% | 0.22% | ||
| Campfire | 22 | −1.22% | 2.43% | −0.65% | 0.65% | 0.32% | 0.10% | |
| 27 | −0.95% | 3.78% | 0.14% | 0.22% | 0.22% | 0.12% | ||
| 32 | −0.18% | 4.74% | 0.65% | 0.08% | 0.15% | 0.04% | ||
| 37 | 0.80% | 5.13% | 0.94% | 0.12% | 0.06% | 0.16% | ||
| Class A2 4K | CatRobot1 | 22 | 0.19% | 0.11% | 0.18% | 0.45% | 0.07% | 0.19% |
| 27 | 0.14% | 0.09% | 0.16% | 0.17% | 0.05% | 0.17% | ||
| 32 | 0.17% | 0.07% | 0.21% | 0.23% | 0.03% | 0.10% | ||
| 37 | 0.21% | 0.01% | 0.19% | 0.29% | 0.09% | 0.18% | ||
| DaylightRoad2 | 22 | 0.23% | 0.08% | 0.08% | 0.73% | 0.07% | 0.10% | |
| 27 | 0.08% | 0.10% | 0.07% | 0.10% | 0.06% | 0.09% | ||
| 32 | 0.09% | 0.11% | 0.06% | 0.13% | 0.04% | 0.07% | ||
| 37 | 0.09% | 0.23% | 0.13% | 0.19% | 0.06% | 0.07% | ||
| ParkRunning3 | 22 | 0.68% | 0.60% | 0.53% | 0.73% | 0.51% | 0.39% | |
| 27 | 0.51% | 0.35% | 0.27% | 0.68% | 0.43% | 0.28% | ||
| 32 | 0.37% | 0.25% | 0.17% | 0.60% | 0.26% | 0.16% | ||
| 37 | 0.26% | 0.18% | 0.07% | 0.49% | 0.17% | 0.11% | ||
| Class B 1080p | MarketPlace | 22 | −0.45% | −1.90% | −1.15% | 0.44% | 0.14% | 0.14% |
| 27 | −0.47% | −1.98% | −1.16% | 0.36% | 0.13% | 0.14% | ||
| 32 | −0.49% | −2.11% | −1.16% | 0.40% | 0.10% | 0.10% | ||
| 37 | −0.53% | −2.39% | −1.17% | 0.40% | 0.14% | 0.15% | ||
| RitualDance | 22 | −0.25% | −1.23% | −1.01% | 0.54% | 0.16% | 0.18% | |
| 27 | −0.29% | −1.29% | −1.09% | 0.53% | 0.20% | 0.21% | ||
| 32 | −0.35% | −1.33% | −1.12% | 0.45% | 0.19% | 0.12% | ||
| 37 | −0.39% | −1.24% | −1.13% | 0.39% | 0.16% | 0.22% | ||
| Cactus | 22 | 0.24% | 0.09% | 0.10% | 0.85% | 0.17% | 0.25% | |
| 27 | 0.22% | 0.08% | 0.09% | 0.50% | 0.14% | 0.27% | ||
| 32 | 0.21% | 0.06% | 0.10% | 0.56% | 0.12% | 0.19% | ||
| 37 | 0.21% | 0.03% | 0.00% | 0.57% | 0.17% | 0.21% | ||
| BasketballDrive | 22 | 0.33% | 0.12% | 0.22% | 0.94% | 0.23% | 0.38% | |
| 27 | 0.20% | 0.11% | 0.21% | 0.49% | 0.26% | 0.42% | ||
| 32 | 0.18% | 0.13% | 0.18% | 0.39% | 0.21% | 0.30% | ||
| 37 | 0.15% | 0.12% | 0.14% | 0.42% | 0.31% | 0.36% | ||
| BQTerrace | 22 | 0.36% | 0.14% | 0.15% | 2.25% | 0.38% | 0.31% | |
| 27 | 0.21% | 0.15% | 0.14% | 0.97% | 0.29% | 0.22% | ||
| 32 | 0.22% | 0.13% | 0.13% | 0.79% | 0.20% | 0.15% | ||
| 37 | 0.26% | 0.12% | 0.05% | 0.71% | 0.20% | 0.16% | ||
| Class C WVGA | BasketballDrill | 22 | 0.49% | 0.37% | 0.47% | 1.01% | 0.66% | 0.77% |
| 27 | 0.33% | 0.26% | 0.28% | 0.78% | 0.66% | 0.77% | ||
| 32 | 0.24% | 0.30% | 0.27% | 0.64% | 0.54% | 0.46% | ||
| 37 | 0.13% | 0.23% | 0.14% | 0.54% | 0.50% | 0.51% | ||
| BQMall | 22 | 0.41% | 0.25% | 0.27% | 1.17% | 0.40% | 0.43% | |
| 27 | 0.34% | 0.18% | 0.18% | 0.93% | 0.39% | 0.43% | ||
| 32 | 0.28% | 0.24% | 0.22% | 0.74% | 0.27% | 0.27% | ||
| 37 | 0.22% | 0.25% | 0.24% | 0.66% | 0.41% | 0.37% | ||
| PartyScene | 22 | 0.78% | 0.59% | 0.58% | 2.37% | 0.86% | 0.77% | |
| 27 | 0.64% | 0.44% | 0.36% | 1.72% | 0.79% | 0.67% | ||
| 32 | 0.51% | 0.41% | 0.31% | 1.16% | 0.52% | 0.43% | ||
| 37 | 0.38% | 0.29% | 0.24% | 0.75% | 0.47% | 0.40% | ||
| RaceHorses | 22 | 0.57% | 0.23% | 0.20% | 1.38% | 0.72% | 0.49% | |
| 27 | 0.34% | 0.18% | 0.14% | 1.06% | 0.59% | 0.45% | ||
| 32 | 0.29% | 0.16% | 0.15% | 0.93% | 0.37% | 0.35% | ||
| 37 | 0.23% | 0.20% | 0.18% | 0.66% | 0.44% | 0.48% | ||
| Class A1 | 0.11% | 1.58% | 0.29% | 0.18% | 0.10% | 0.11% | ||
| Class A2 | 0.25% | 0.18% | 0.18% | 0.40% | 0.15% | 0.16% | ||
| Class B | −0.02% | −0.61% | −0.37% | 0.65% | 0.20% | 0.22% | ||
| Class C | 0.39% | 0.29% | 0.26% | 1.03% | 0.54% | 0.50% | ||
| All | 0.18% | −0.11% | −0.02% | 0.71% | 0.30% | 0.30% | ||
| Random Access (RA) | All Intra (AI) | ||||||
|---|---|---|---|---|---|---|---|
| Class | Sequence | Average Y BD-Rate | Average Cb BD-Rate | Average Cr BD-Rate | Average Y BD-Rate | Average Cb BD-Rate | Average Cr BD-Rate |
| Class A1 4K | Tango2 | 2.84% | 3.14% | 3.51% | 0.73% | 5.47% | 3.44% |
| FoodMarket4 | 3.72% | 4.92% | 5.63% | 0.83% | 1.60% | 1.50% | |
| Campfire | 1.27% | 1.21% | 1.38% | 0.69% | 0.19% | 1.10% | |
| Class A2 4K | CatRobot1 | 1.49% | 1.67% | 1.32% | 1.01% | 2.32% | 1.19% |
| DaylightRoad2 | 0.48% | 0.74% | 1.14% | −0.17% | 0.06% | −0.15% | |
| ParkRunning3 | 0.91% | 1.14% | 1.15% | 0.24% | 0.90% | 0.95% | |
| Class B 1080p | MarketPlace | 0.61% | 1.16% | 0.96% | −0.01% | 1.69% | 1.14% |
| RitualDance | 3.82% | 4.41% | 5.20% | 0.07% | 0.87% | 1.37% | |
| Cactus | 1.77% | 2.71% | 2.92% | 0.95% | 2.54% | 2.12% | |
| BasketballDrive | 3.54% | 3.96% | 3.39% | 1.07% | 1.34% | 0.84% | |
| Class C WVGA | BQTerrace | 0.88% | 1.08% | 0.49% | 0.07% | 0.33% | 0.26% |
| BasketballDrill | 4.10% | 3.09% | 3.32% | 1.01% | 0.00% | −0.08% | |
| BQMall | 3.74% | 3.84% | 4.13% | −0.55% | 1.21% | 1.33% | |
| PartyScene | 2.41% | 2.27% | 2.65% | 1.13% | 1.68% | 2.16% | |
| Average | Class A1 | 2.61% | 3.09% | 3.50% | 0.75% | 2.42% | 2.01% |
| Class A2 | 0.96% | 1.18% | 1.21% | 0.36% | 1.09% | 0.66% | |
| Class B | 2.12% | 2.66% | 2.59% | 0.43% | 1.35% | 1.14% | |
| Class C | 3.40% | 3.46% | 3.67% | 0.83% | 1.92% | 1.90% | |
| All | 2.33% | 2.67% | 2.78% | 0.59% | 1.66% | 1.42% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.-J.; Lee, Y.-L. Object Detection-Based Video Compression. Appl. Sci. 2022, 12, 4525. https://doi.org/10.3390/app12094525
Kim M-J, Lee Y-L. Object Detection-Based Video Compression. Applied Sciences. 2022; 12(9):4525. https://doi.org/10.3390/app12094525
Chicago/Turabian StyleKim, Myung-Jun, and Yung-Lyul Lee. 2022. "Object Detection-Based Video Compression" Applied Sciences 12, no. 9: 4525. https://doi.org/10.3390/app12094525
APA StyleKim, M.-J., & Lee, Y.-L. (2022). Object Detection-Based Video Compression. Applied Sciences, 12(9), 4525. https://doi.org/10.3390/app12094525