This section presents the used pedestrian and bicycle traffic flow datasets and evaluates the forecasting performance of the proposed method. At first, we verify the one-step forecasting performance of the proposed GAHD-VAE model and compare its improvement with the traditional VAE model. Then, we provide a comparison against the baseline deep learning models, namely LSTM, GRU, BiLSTM, and BiGRU. Furthermore, the impact of using different configurations of the attention model, namely, attention type and activation function at a different level of the proposed architecture, is analyzed. Finally, we evaluate the effectiveness of the considered methods for multi-step forecasting.
4.3. Results Analysis and Comparison
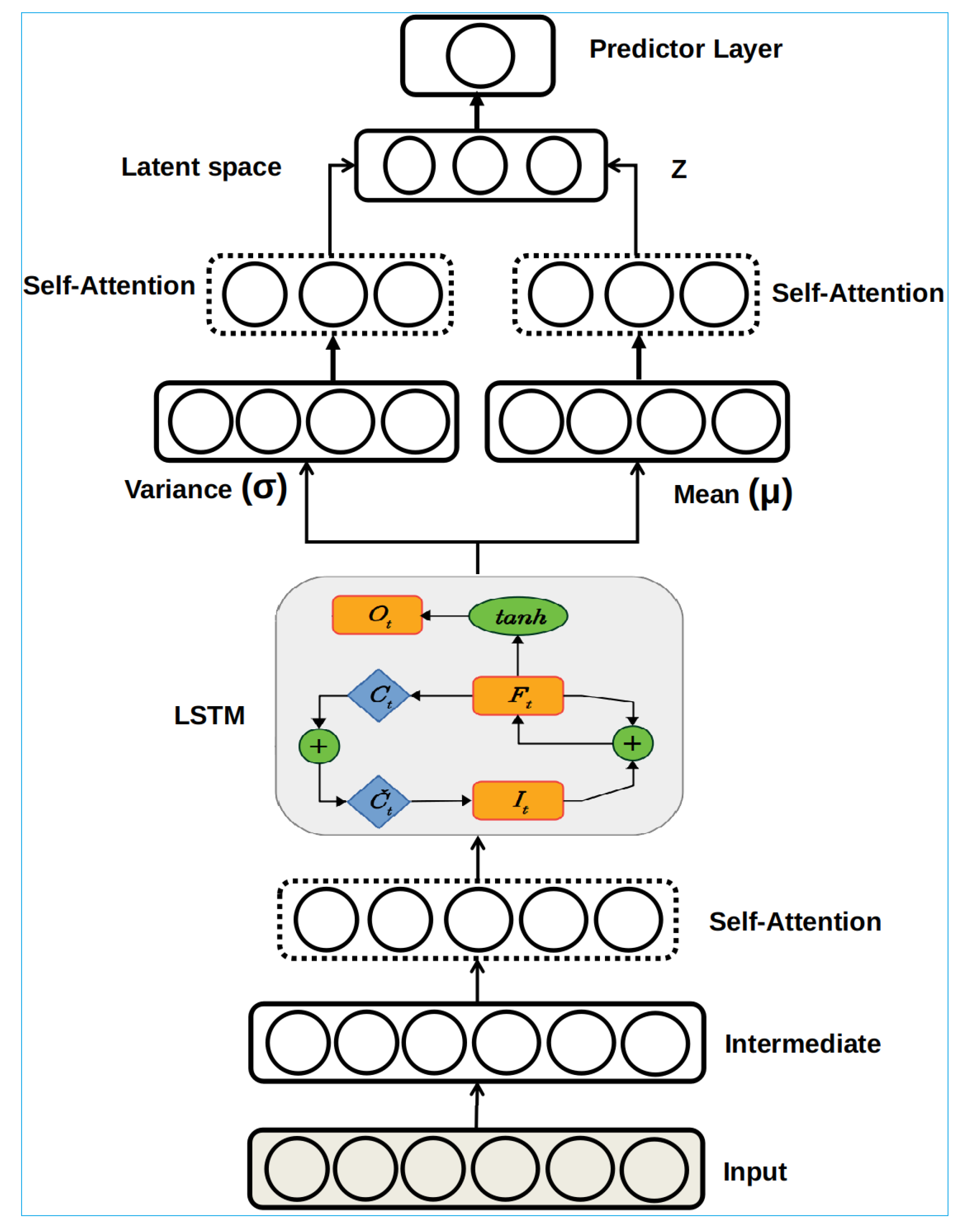
This section first shows the improvement introduced to the traditional VAE by incorporating the self-attention mechanism at the VAE encoder. We compare it with well known recurrent neural networks, LSTM, GRU, BiLSTM, BiGRU, CNN, and ConvLSTM, as well as baseline methods, namely LR, RR, SVR, and Lasso regression, to forecast pedestrian and bicycle traffic flows. The LSTM and GRU are equipped with memory-cell and gating mechanisms, making them powerful models for time-series modeling and suitable for a comparison study. In these experimentations, the set of hyperparameters is fixed for all considered model-based training datasets: optimizer = ‘rmsprop’, loss function = ‘Cross-Entropy’, batch size = 250, epochs = 500, and learning rate = 0.001, activation function = ‘Rectified Linear Unit (ReLU)’. The configuration of the proposed approach is: [Input: 3, Intermediate: 6, Self-Attention: 6, LSTM: 16, Variance: 16, Mean: 16, Z: 16, Self-Attention: 4, Self-Attention: 4, Predictor: 1]. For the considered models GRU, LSTM, BiLSTM, BiGRU, and ConvLSTM, we set the hidden units to 32. Here, deep recurrent neural networks are built by stacking two recurrent layers as deep temporal feature extractors and a dense layer used for the forecasting task. For example, for LSTM, we have a stacked-LSTM network containing two LSTM layers with 32 hidden units for each layer and a fully connected layer. All hyper-parameters are determined based on a grid search approach. Similarly, the same architecture is used for BiLSTM and BiGRU models: Deep bidirectional temporal feature extractors and a dense layer used for the forecasting task. Generally, the bidirectional models allow the input to be processed in the forward and backward direction, making it possible to extract more complex hidden features. We used a linear kernel for the SVR model, with the regularization parameter and gamma = ‘scale’. For the Lasso regression, we set the constant that multiplies the L1 term, , the maximum number of iterations is 1000, and the tolerance for the optimization is . For RR, the value of the regularization strength is chosen as 1, the maximum number of iterations is 1000, and the precision of the solution is chosen to be .
To show the advantage of the proposed GAHD-VAE compared to the traditional VAE, we applied them to the six traffic flow datasets (
Table 3). The proposed approach scored the lowest RMSE for the six considered datasets (
) compared to results achieved by the VAE (
). Furthermore, the averaged
and EV values for the GAHD-VAE are (0.963, 0.968) and for the VAE are (0.919, 0.94), respectively. Results demonstrate the significant improvement attributed to the high learning quality and capability of GAHD-VAE, brought by the deep self-attention mechanism and the deep hybrid architecture that incorporates recurrent neural networks. Results in
Table 3 also revealed that the GAHD-VAE model exhibited superior prediction performance compared to four shallow methods, linear regression, Lasso regression, ridge regression, and support vector regression. This could be attributed to the ability of a deep learning structure to learn complicated patterns from data. Indeed, deep models’ structure enables transforming data multiple times to get the final output, allowing to learn deeper information. On the other hand, shallow methods generally can transform the data only one or two times to reach the output, limiting their ability to learn complicated patterns from input data.
In the next numerical experiments, we compared the performance of the proposed GAHD-VAE approach to that of GRU, LSTM, BiLSTM, BiGRU, CNN, and ConvLSTM models because of their popularity in modeling and forecasting time-series data.
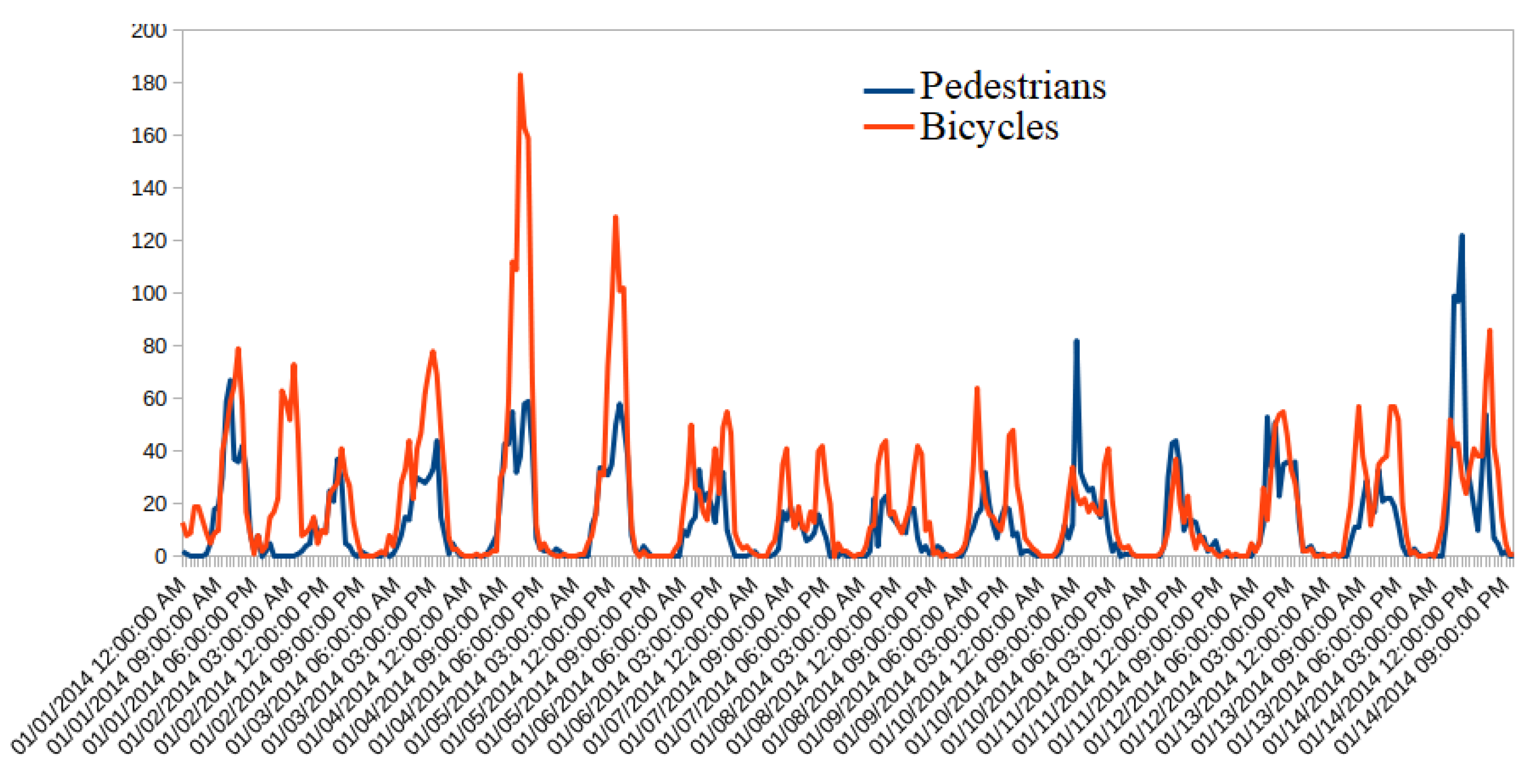
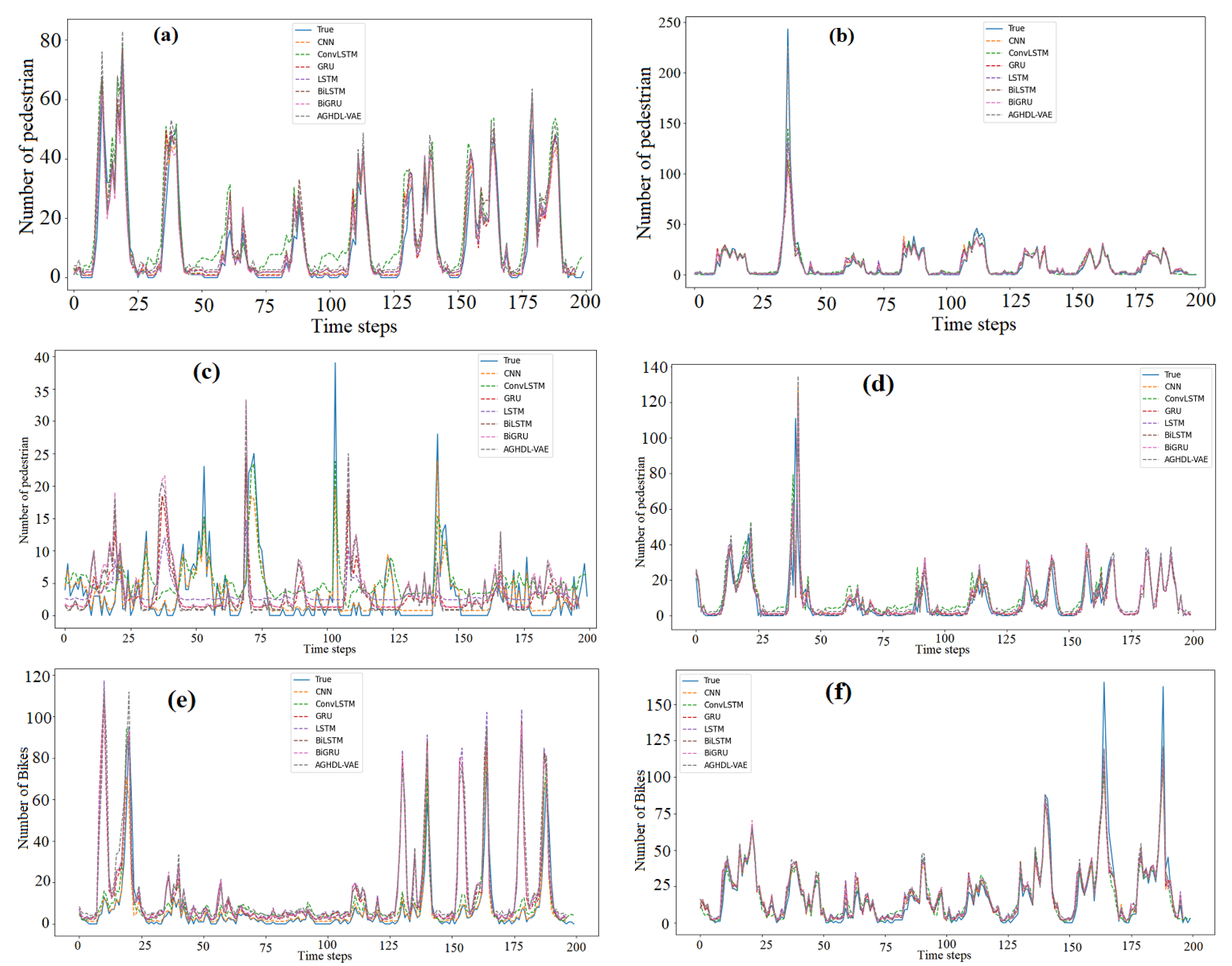
Figure 5a–f displays the measured and the forecasted traffic flow obtained by the proposed GAHD-VAE and the six considered deep learning models when applied to the six traffic datasets. From
Figure 5a–f, we observe that the forecasted traffic flows from the seven models closely followed the measured traffic flow data (solid line) for all test datasets.
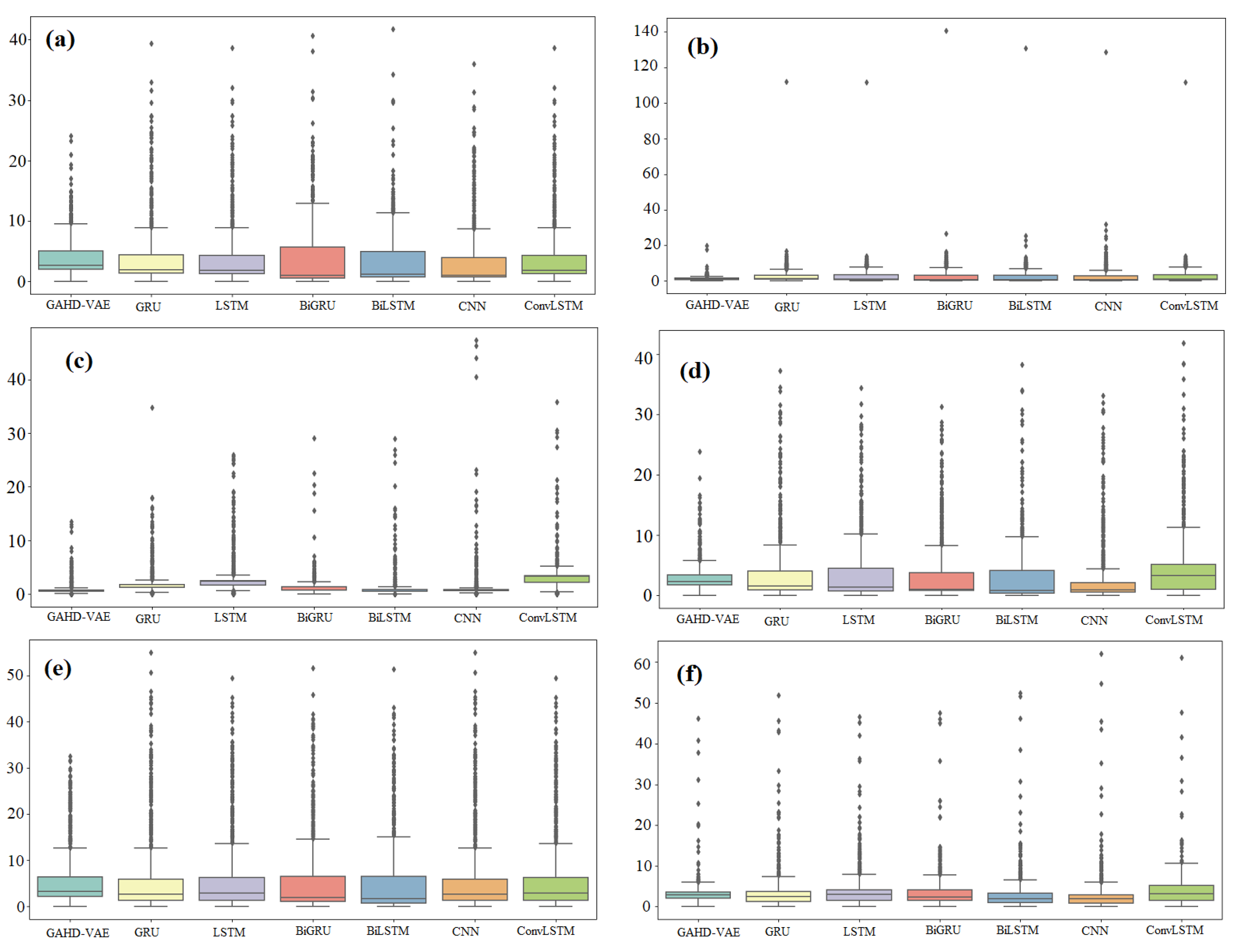
Figure 6a–f present the boxplots of forecasting errors, which is the deviation between the forecasted and the measured traffic flow values. The more the boxplot’s median tends to zero, and the boxplot is compact, the more the model is accurate. As a consequence,
Figure 6 indicates that the GAHD-VAE provides better performance than all the other models.
The obtained forecasting results are tabulated in
Table 4. Results in
Table 4 show that the quality of the forecast of pedestrian and bicycle traffic flows from the seven trained models is promising.
Table 4 indicates that the proposed approach exhibited improved forecasting performance compared to other deep learning methods by achieving the lowest RMSE and MAE values and the highest
and EV values (close to 1). The averaged metrics by datasets of the proposed approach are RMSE of 3.35 and MAE of 2.54; the proposed model has reached a high fitting score with low forecasting error for pedestrians, and bicycle traffic flows using six datasets. This could be attributed to the GAHD-VAE capacity in handling nonlinearity. On the other hand, results demonstrate that bidirectional methods (i.e., BiLSTM and BiGRU) improved the quality of forecasting compared to the uni-directional models (i.e., LSTM and GRU). Moreover, the overall performance of BiLSTM is slightly better than BiGRU. Notably, the GAHD-VAE method shows promising capability for modeling complex temporal features in different datasets, especially pedestrian traffic flow (datasets 2 and 3), which is highly dynamic and nonlinear.
Table 5 summarizes the aggregated performances of each approach.
implies that all deep learning approaches are providing good forecasting. In terms of all metrics computed, the proposed GAHD-VAE approach achieves the best forecasting with high efficiency and satisfying accuracy (i.e.,
, RMSE =
). It is followed by BiGRU and BiLSTM, which achieve
. Notice that a significant forecasting improvement was obtained using the GAHD-VAE approach compared to the other deep learning models. This could be attributed to its capacity to capture relevant information and dynamics from traffic flow time series.
To further assess the performance of the GAHD-VAE, we investigate the impact of the attention mechanism setting used in the proposed GAHD-VAE model on the forecasting accuracy. An important point to highlight is that the activation function changes how data is transformed (or processed) at the layer unit level and significantly impacts the neural network’s overall performance. Mainly, we evaluate the impact of the used activation function in the attention mechanism on the proposed approach’s forecasting performance.
Table 6 shows the forecasting results obtained through different configurations of the activation function used on each attention layer: Rectified Linear Unit (ReLU), Hyperbolic Tangent (tanh), and Logistic Sigmoid. We also evaluate the impact of the attention type, namely multiplicative and additive, on the forecasting accuracy. Moreover, these experiments are based on four traffic flow datasets for the proposed approach with a self-attention mechanism (
Table 6). Note here that the highlighted rows in
Table 6 represent the results obtained with default attention configuration (activation function: Tanh; attention type: Additive), while the results in bold are the enhanced forecasting metrics. The term ’None’ in
Table 6 represents the case where the multiplicative self-attention is based only on matrix multiplications without the activation function.
Results in
Table 6 show that the GAHD-VAE model with the Sigmoid activation function, when applied to dataset 1, provides the best results for both attention types (i.e., multiplicative and additive). Specifically, it achieves the lowest RMSE and MAE values (i.e., 1.812 and 1.224, respectively) and describes 98.8% of the traffic flow variance. We also observe that adjusting the attention layer significantly improves the forecasting quality by reducing RMSE from 3.336 to 1.812 and MAE from 2.81 to 1.224 and improving
to more than 0.98. Moreover,
Table 6 shows that the multiplicative type with Tanh and additive with Sigmoid offers the most favorable result for the traffic data set 4 (i.e., RMSE = 1.18, MAE = 0.761, and
= 0.986). The best forecasting accuracy when applying GAHD-VAE to Data Set 5 is obtained by using multiplicative type with Sigmoid activation function, where RMSE was reduced from 5.641 to 2.743 and MAE from 4.853 to 1.969, compared to the additive type with Tanh (i.e., default configuration). From
Table 6, we also observe that there is no improvement on Dataset 6; the default configuration scored the best results. Overall, it is not obvious to automatically decide the best attention configuration for any dataset. On average, the use of GAHD-VAE with the Sigmoid activation function provides suitable forecasting performance.
Table 7 displays the aggregated performances of GAHD-VAE per configurations of the attention mechanism (i.e., additive attention mode and multiplicative attention mode).
implies that the use of the two configurations in the GAHD-VAE approach results in good forecasting performance. Overall, forecasts based on the additive attention mode outperform those based on the multiplicative attention mode.
The following experiments are devoted to assessing the proposed approach’s daily forecasting performance against the other recurrent models.
Table 8 summarized the results of forecasting daily pedestrian and bicycle traffic flows using the seven deep learning models based on the six datasets. Results indicate that the proposed approach scored the lowest averaged forecasting error (i.e., RMSE = 42 and MAE = 32) and the highest determination factor (i.e.,
= 0.9 and EV = 0.9). Moreover, results in
Table 8 indicate that the bi-directional recurrent neural networks (BiLSTM and BiGRU) exhibit higher accuracy compared to the uni-directional (LSTM, GRU). This could be due to the capability of BiLSTM and BiGRU in processing data in the forward and backward direction, which enable them to discover more complex features. We also observe that BiLSTM outperforms BiGRU slightly; however, LSTM and GRU recorded mostly the same score. Results confirm the superiority of the proposed GAHD-VAE approach in modeling long-term temporal dependencies and the attention mechanism’s efficiency to highlight the internal correlation between elements. In summary, results in this study showed that the proposed model achieved an improved forecasting quality for both one-step and multi-step pedestrians and bicycle traffic flow forecasting.
To summarize the assessments, the averaged metrics of effectiveness per model computed from
Table 8 are listed in
Table 9. The results support that the GAHD-VAE forecasting approach has higher accuracy overall than the other deep learning models (i.e., VAE, LSTM, GRU, BiLSTM, BiGRU, CNN, and ConvLSTM). Overall, the results indicate that the GAHD-VAE approach has high forecasting accuracy due to the robustness of variational inferences in approximating data probability distribution of traffic flow time-series, in addition to the promising capability of a self-attention mechanism to learn implicit information within data points of a given sequence.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}