
Prediction of Machine Failure in Industry 4.0: A Hybrid CNN-LSTM Framework




Abstract
:1. Introduction
- We propose a hybrid deep learning model (CNN-LSTM) for PdM. The model uses CNN to extract features from the time series and LSTM for prediction. It uses a time sequence of different errors and analyses the correlation between different input variables for better prediction.
- We introduce a novel temporal skip connection component for LSTM that enables them to capture long length dependencies and makes optimization easier and efficient.
- On comparing the evaluation indexes of CNN, LSTM, and hybrid CNN-LSTM, we found that our hybrid CNN-LSTM has the highest prediction accuracy and is more reliable and suitable for PdM forecasting.
2. Related Work
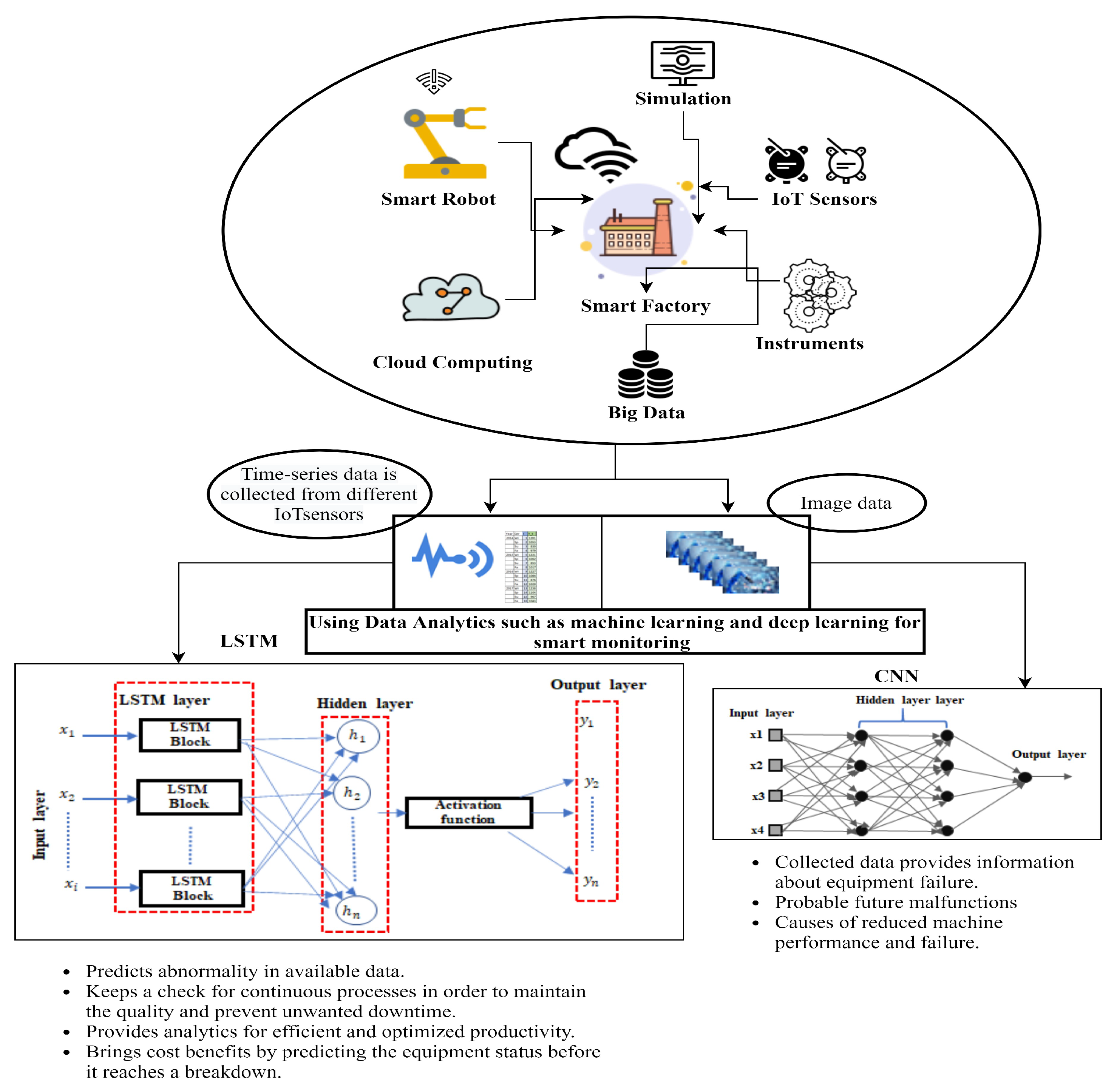
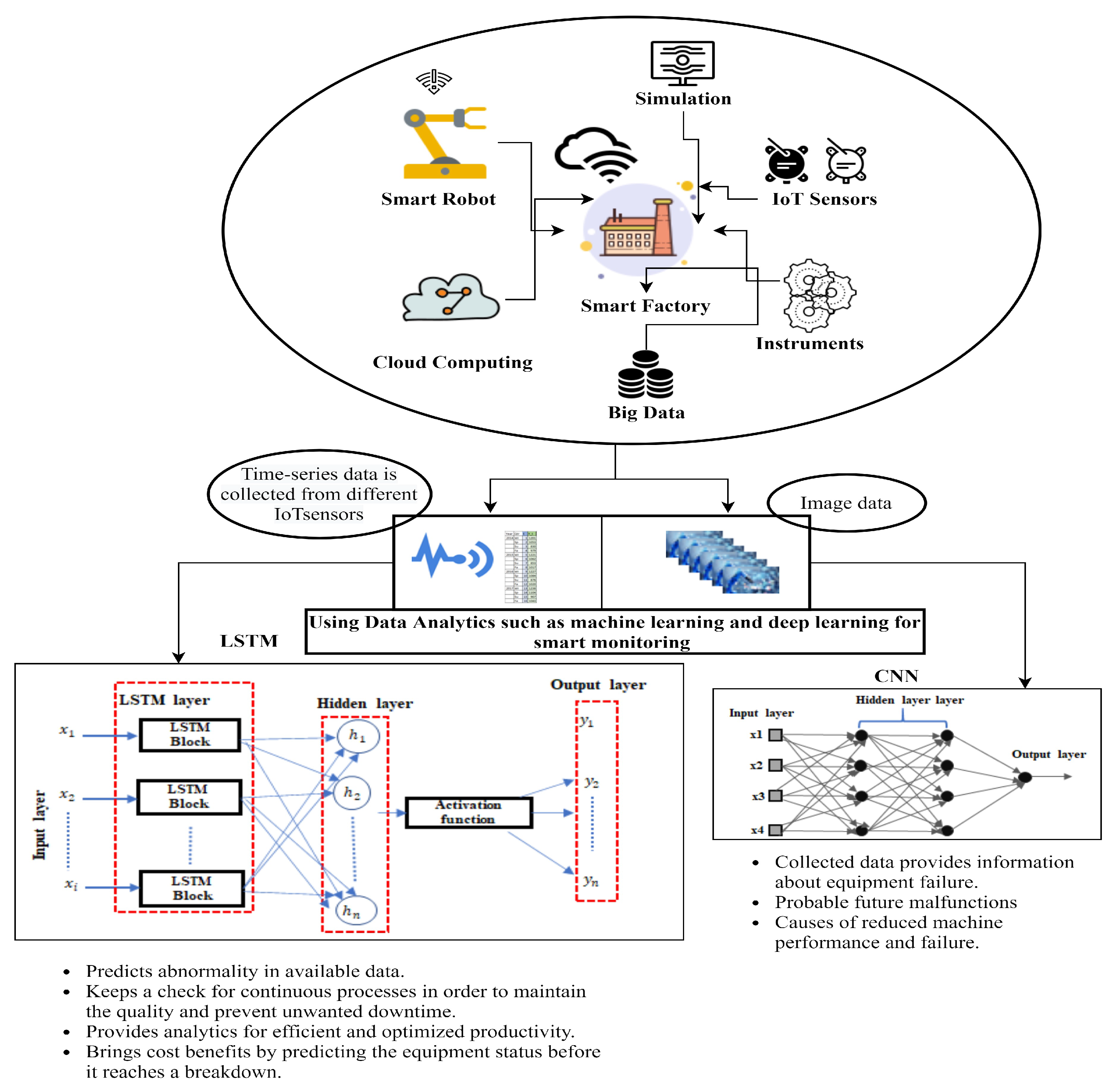
3. Industry 4.0 Use Case
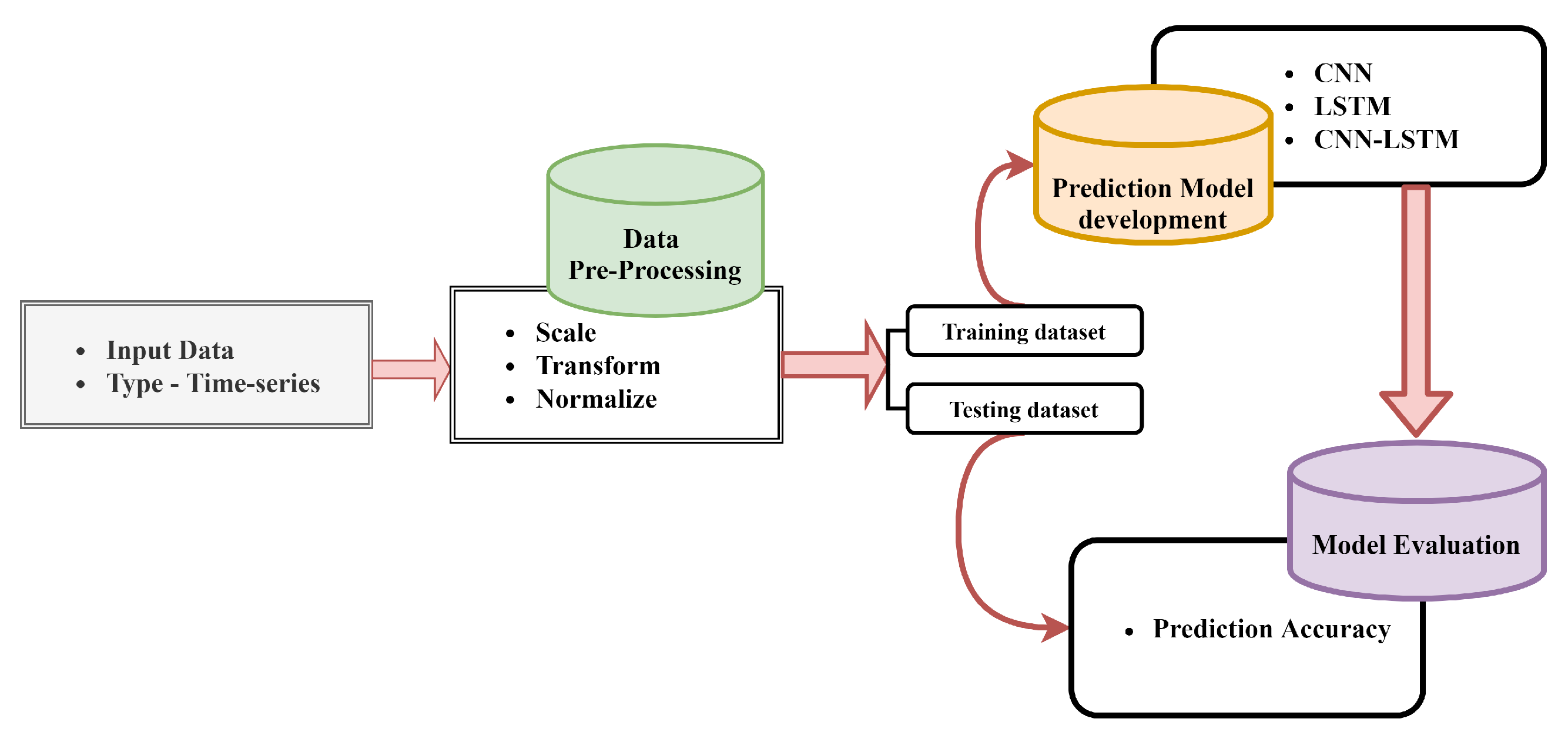
4. Framework
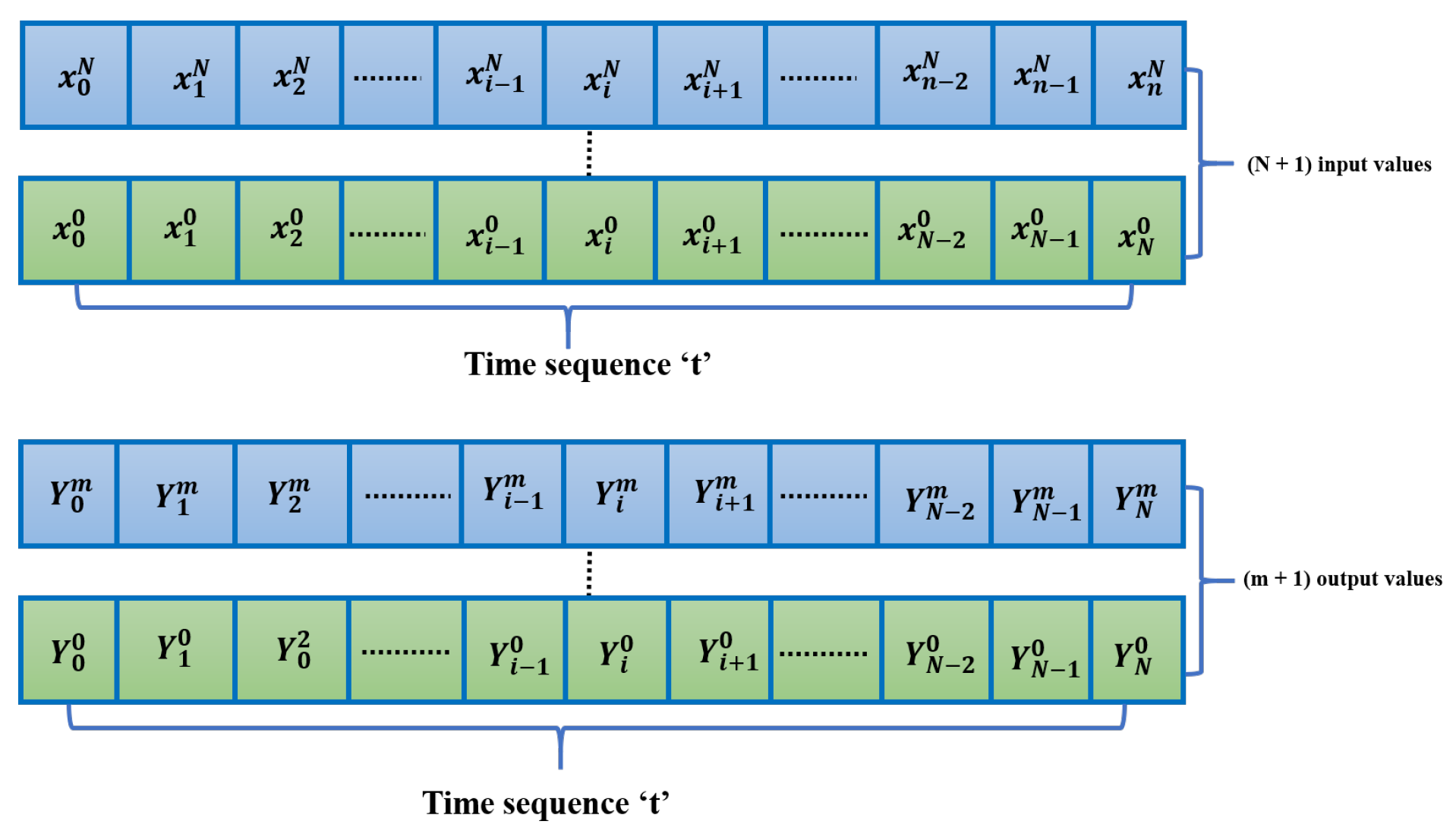
4.1. Problem Formulation
4.2. Convolutional Neural Networks (CNN)
4.3. Long Short-Term Memory (LSTM)
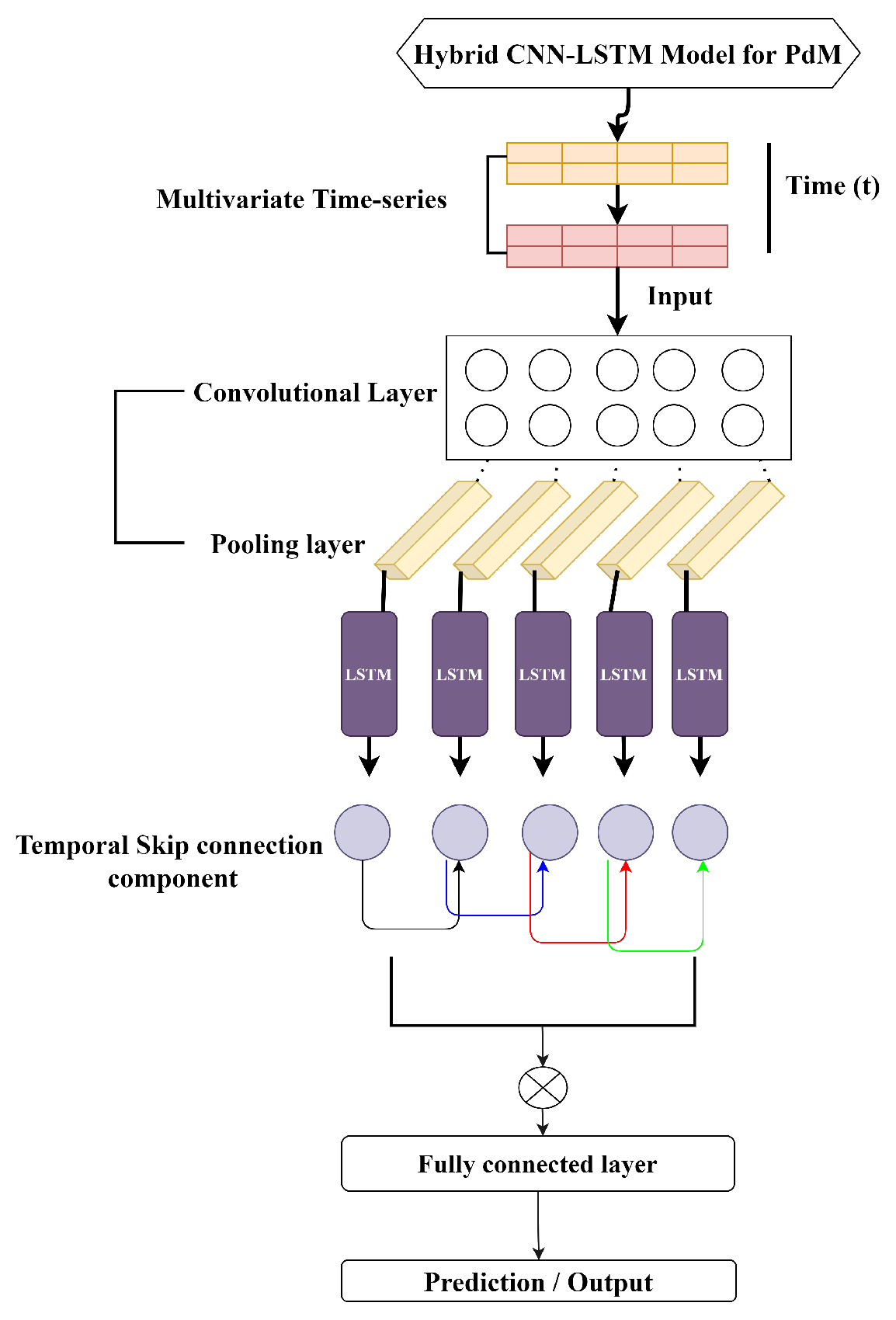
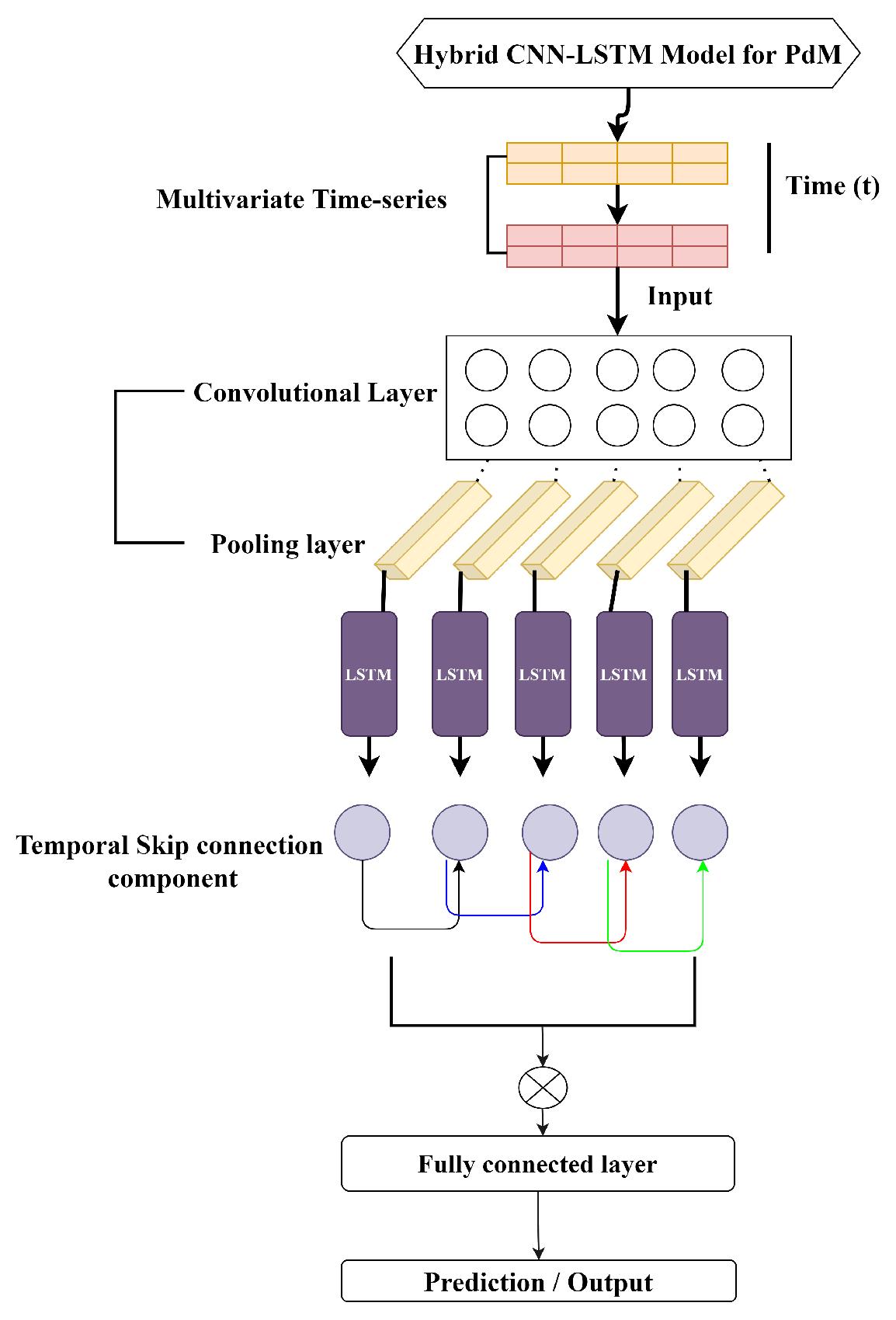
5. Hybrid CNN-LSTM Model for PdM
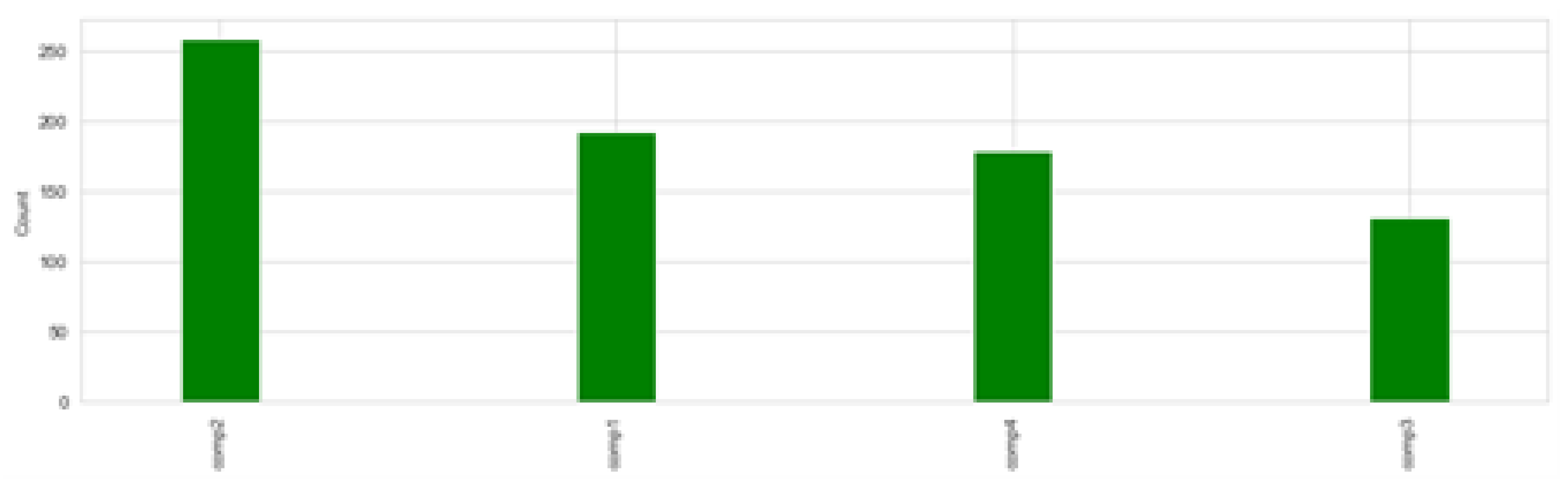
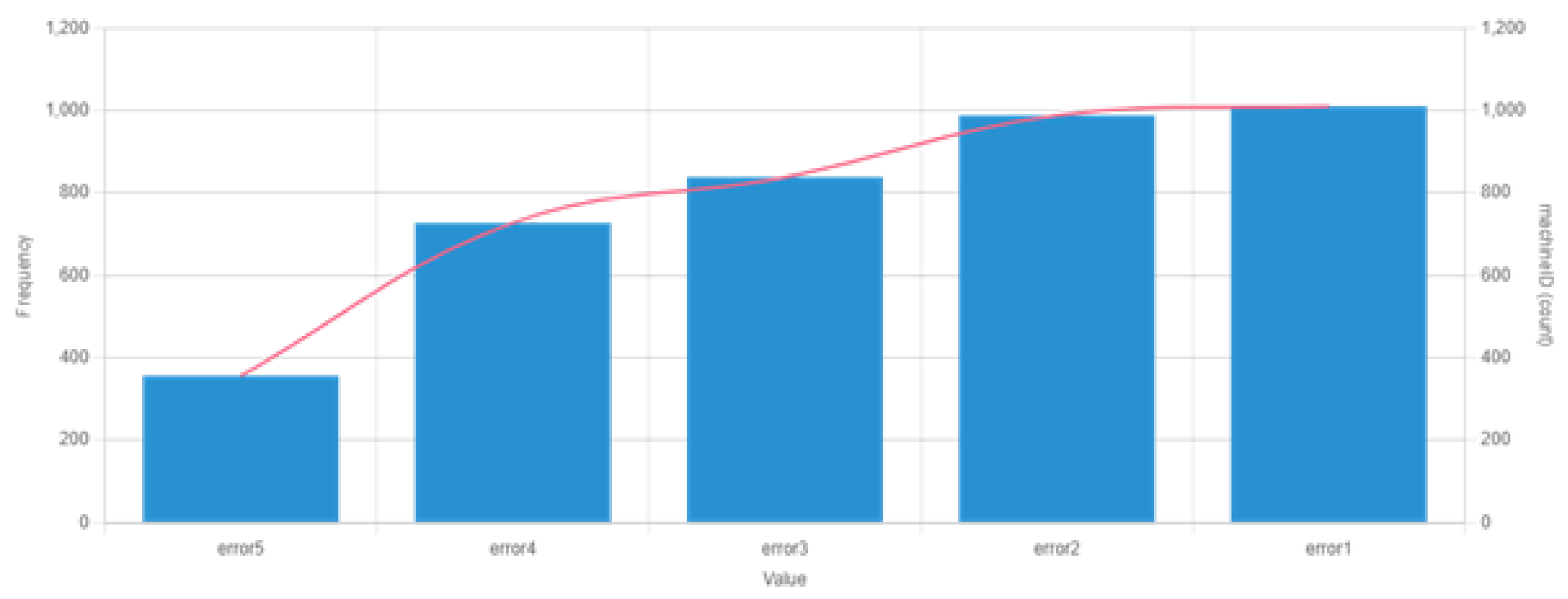
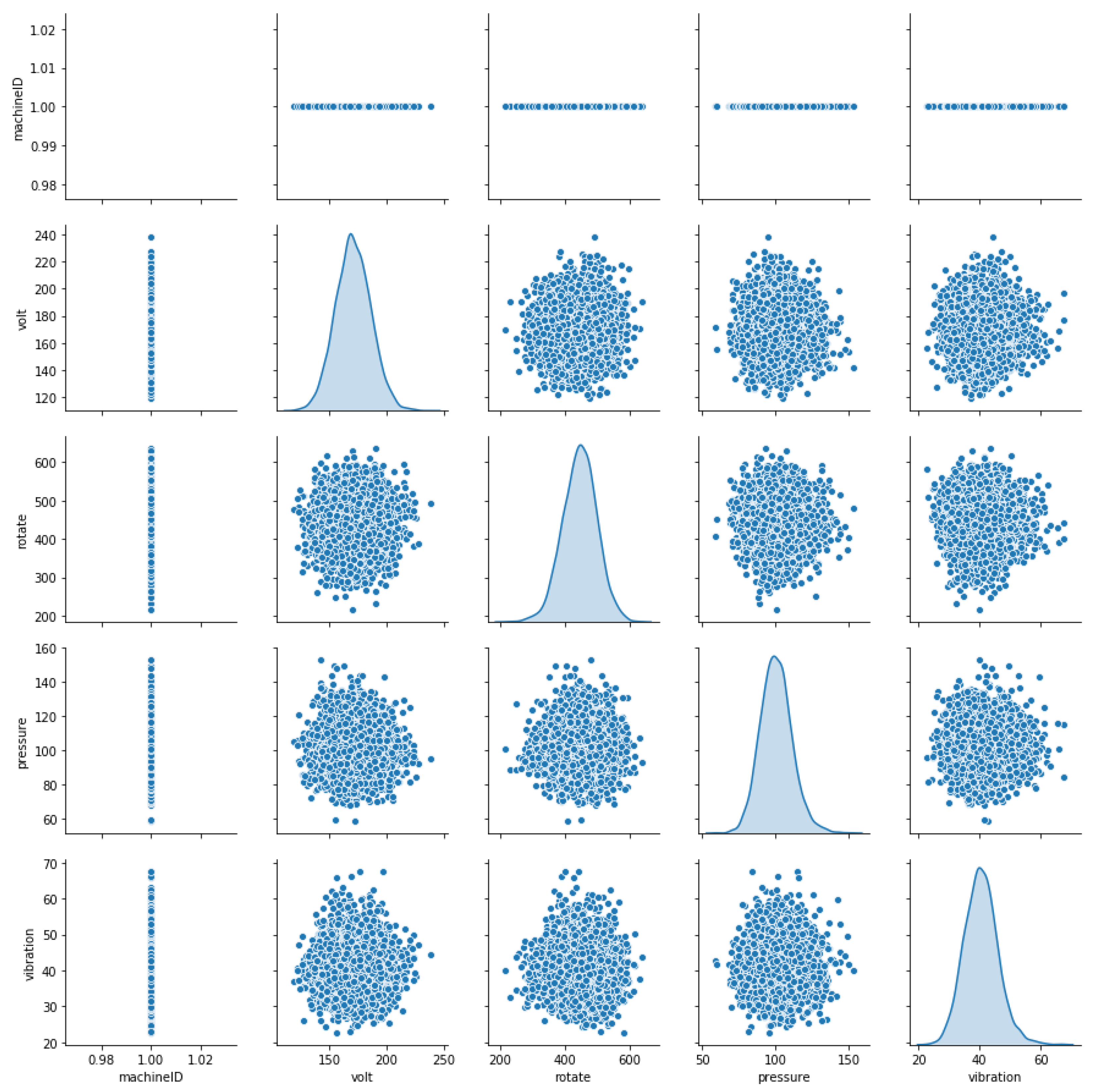
5.1. Dataset
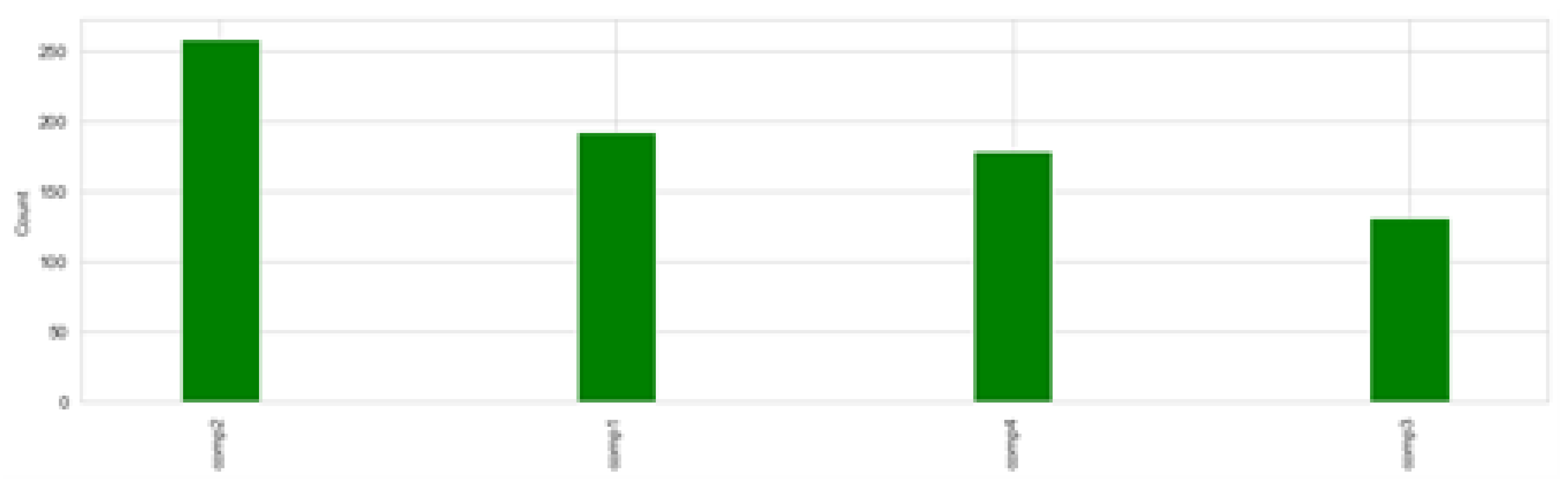
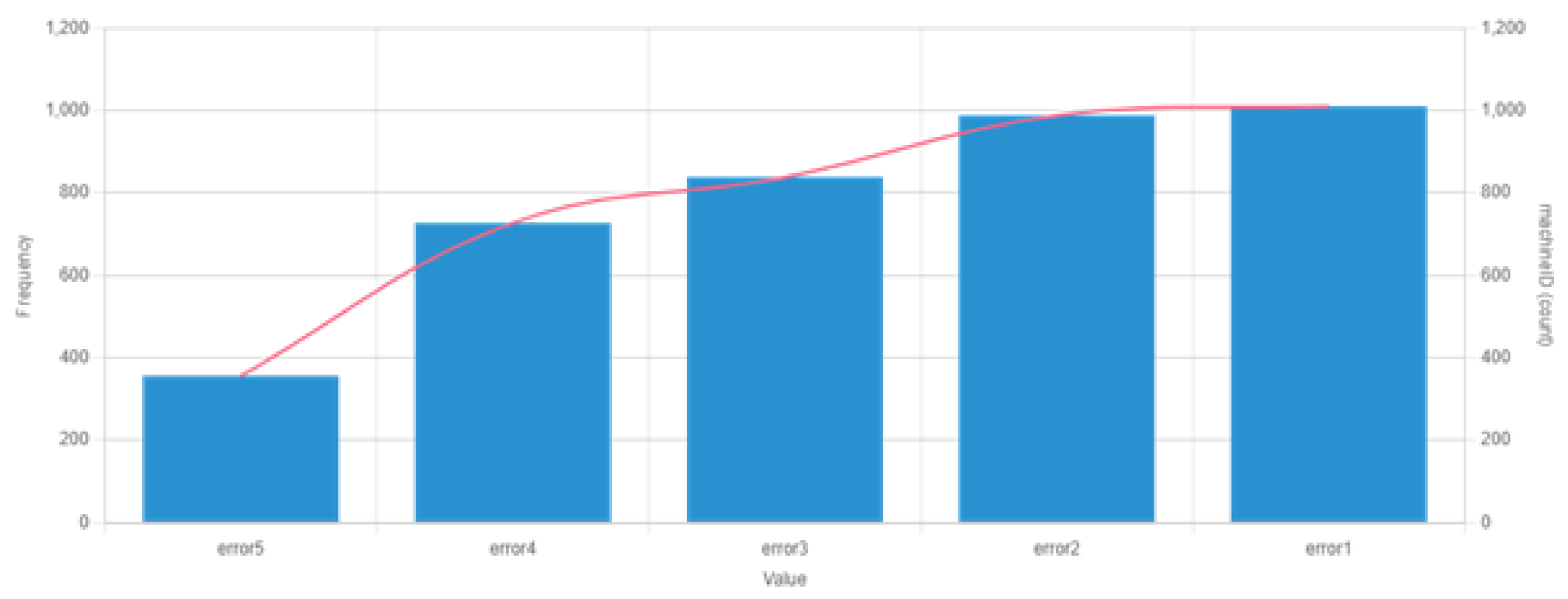
5.2. Label Generation
5.3. Feature Engineering
5.4. Hybrid CNN-LSTM
5.5. Optimization Approach
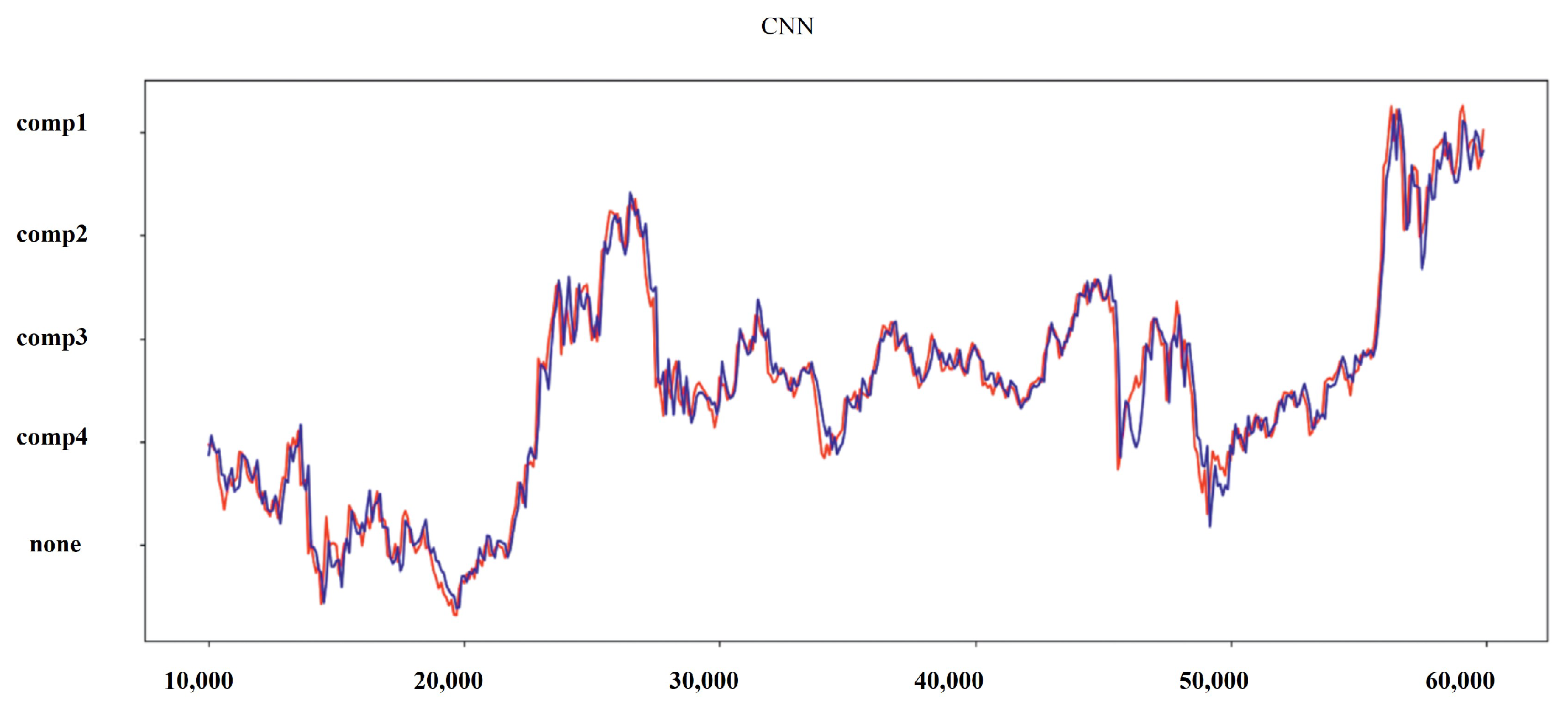
6. Experiments and Results
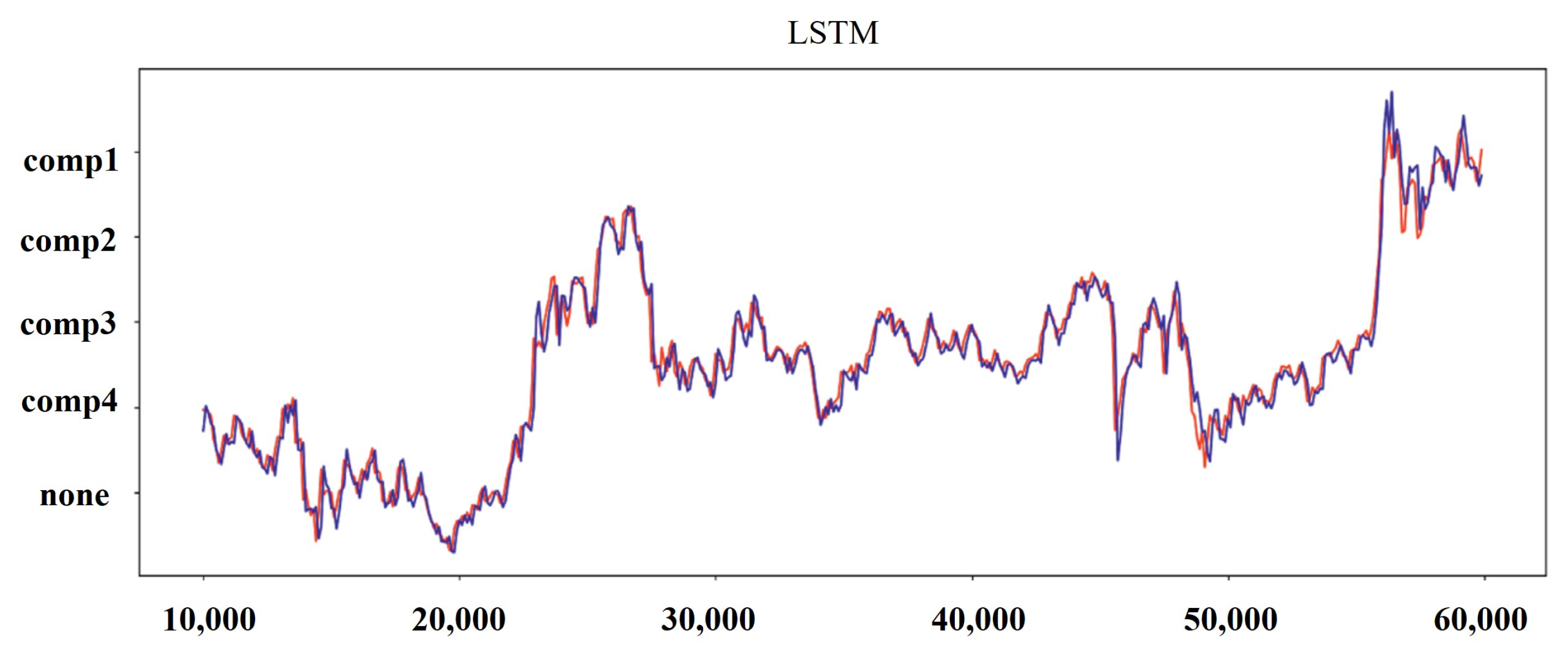
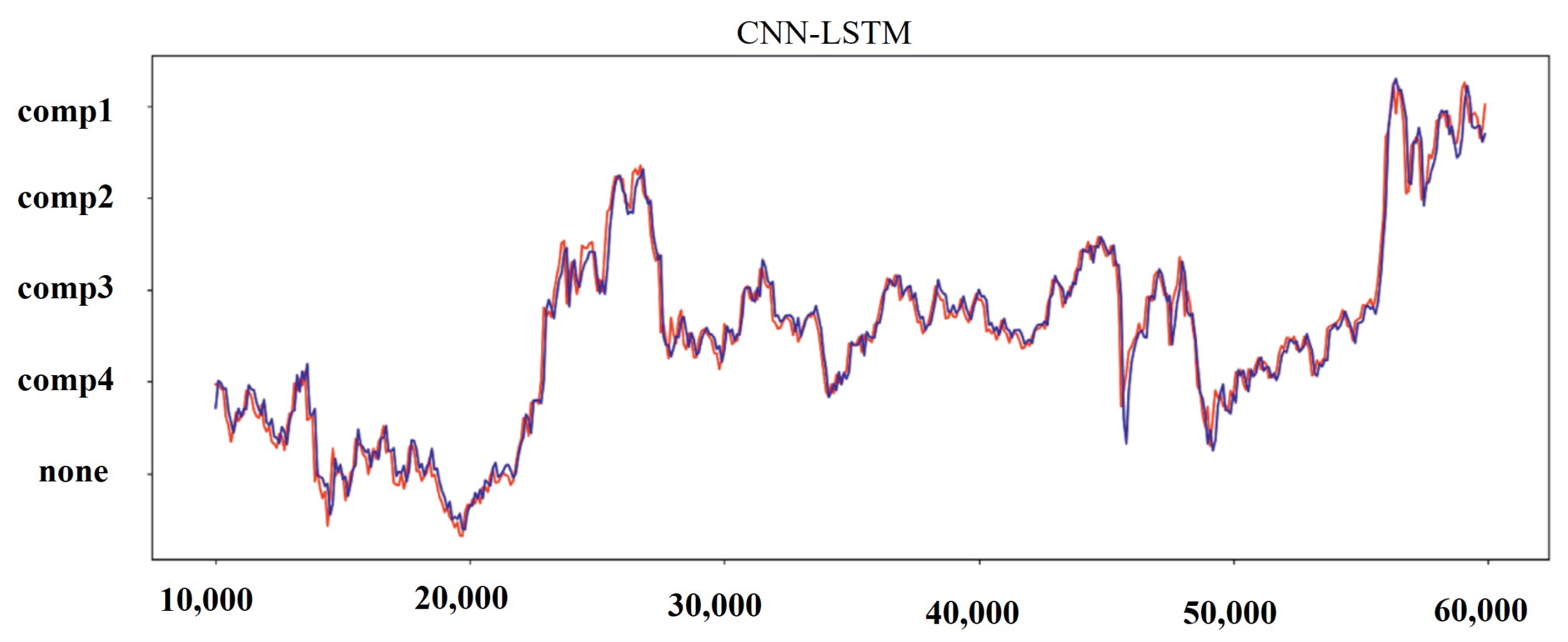
Results
7. Lessons Learned
8. Discussion
9. Conclusions and Future Direction
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A survey of predictive maintenance: Systems, purposes and approaches. arXiv 2019, arXiv:1912.07383. [Google Scholar]
- Wiboonrat, M. Human Factors Psychology of Data Center Operations and Maintenance. In Proceedings of the 2020 6th International Conference on Information Management (ICIM), London, UK, 27–29 March 2020; pp. 167–171. [Google Scholar]
- Gong, X.; Qiao, W. Current-based mechanical fault detection for direct-drive wind turbines via synchronous sampling and impulse detection. IEEE Trans. Ind. Electron. 2014, 62, 1693–1702. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Braglia, M. The analytic hierarchy process applied to maintenance strategy selection. Reliab. Eng. Syst. Saf. 2000, 70, 71–83. [Google Scholar] [CrossRef]
- Sudharsan, B.; Salerno, S.; Nguyen, D.D.; Yahya, M.; Wahid, A.; Yadav, P.; Breslin, J.G.; Ali, M.I. Tinyml benchmark: Executing fully connected neural networks on commodity microcontrollers. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 883–884. [Google Scholar]
- Dekker, R. Applications of maintenance optimization models: A review and analysis. Reliab. Eng. Syst. Saf. 1996, 51, 229–240. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, K.-A.; Do, P.; Grall, A. Multi-level predictive maintenance for multi-component systems. Reliab. Eng. Syst. Saf. 2015, 144, 83–94. [Google Scholar] [CrossRef]
- Mobley, R.K. An Introduction to Predictive Maintenance; Elsevier: Amsterdam, The Netherlands, 2002. [Google Scholar]
- Namuduri, S.; Narayanan, B.N.; Davuluru, V.S.P.; Burton, L.; Bhansali, S. Deep learning methods for sensor based predictive maintenance and future perspectives for electrochemical sensors. J. Electrochem. Soc. 2020, 167, 037552. [Google Scholar] [CrossRef]
- Ur Rehman, M.H.; Ahmed, E.; Yaqoob, I.; Hashem, I.A.T.; Imran, M.; Ahmad, S. Big data analytics in industrial IoT using a concentric computing model. IEEE Commun. Mag. 2018, 56, 37–43. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Remadna, I.; Terrissa, S.L.; Zemouri, R.; Ayad, S. An overview on the deep learning based prognostic. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies IC_ASET), Hammamet, Tunisia, 22–25 March 2018. [Google Scholar]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, D.; Yan, R.; Mao, K.; Shen, F.; Wang, J. Machine health monitoring using local feature-based gated recurrent unit networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Dasgupta, S.; Osogami, T. Nonlinear dynamic Boltzmann machines for time-series prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Jain, A.; Kumar, A.M. Hybrid neural network models for hydrologic time series forecasting. Appl. Soft Comput. 2007, 7, 585–592. [Google Scholar] [CrossRef]
- Lade, P.; Ghosh, R.; Srinivasan, S. Manufacturing analytics and industrial internet of things. IEEE Intell. Syst. 2017, 32, 74–79. [Google Scholar] [CrossRef]
- Monostori, L.; Márkus, A.; Van Brussel, H.; Westkämpfer, E. Machine learning approaches to manufacturing. CIRP Ann. 1996, 45, 675–712. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Yahya, M.; Shah, J.A.; Warsi, A.; Kadir, K.; Khan, S.; Izani, M. Real time elbow angle estimation using single RGB camera. arXiv 2018, arXiv:1808.07017. [Google Scholar]
- Bengio, Y. Learning Deep Architectures. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Dyer, C.; Ballesteros, M.; Ling, W.; Matthews, A.; Smith, N.A. Transition-based dependency parsing with stack long short-term memory. arXiv 2015, arXiv:1505.08075. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Dong, X.; Qian, L.; Huang, L. Short-term load forecasting in smart grid: A combined CNN and K-means clustering approach. In Proceedings of the 2017 IEEE international conference on big data and smart computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 119–125. [Google Scholar]
- Vos, K.; Peng, Z.; Jenkins, C.; Shahriar, M.R.; Borghesani, P.; Wang, W. Vibration-based anomaly detection using LSTM/SVM approaches. Mech. Syst. Signal Process. 2022, 169, 108752. [Google Scholar] [CrossRef]
- Zhao, H.; Yang, X.; Chen, B.; Chen, H.; Deng, W. Bearing fault diagnosis using transfer learning and optimized deep belief network. Meas. Sci. Technol. 2022, 33, 6. [Google Scholar] [CrossRef]
- Tagawa, Y.; Maskeliūnas, R.; Damaševičius, R. Acoustic Anomaly Detection of Mechanical Failures in Noisy Real-Life Factory Environments. Electronics 2021, 10, 2329. [Google Scholar] [CrossRef]
- Mabkhot, M.M.; Al-Ahmari, A.M.; Salah, B.; Alkhalefah, H. Requirements of the smart factory system: A survey and perspective. Machines 2018, 6, 23. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Wan, J.; Shu, L.; Li, P.; Mukherjee, M.; Yin, B. Smart factory of industry 4.0: Key technologies, application case, and challenges. IEEE Access 2017, 6, 6505–6519. [Google Scholar] [CrossRef]
- Yahya, M.; Breslin, J.G.; Ali, M.I. Semantic Web and Knowledge Graphs for Industry 4.0. Appl. Sci. 2021, 11, 5110. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Luo, C.; Zhang, Z.; Li, J.; Ren, S.; Zeng, Y. Minority oversampling for imbalanced time series classification. Knowl.-Based Syst. 2022, 108764. [Google Scholar] [CrossRef]
- Fulcher, B.D. Feature-based time-series analysis. In Feature Engineering for Machine Learning and Data Analytics; CRC Press: Boca Raton, FL, USA, 2018; pp. 87–116. [Google Scholar]
- Kingma, P.D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
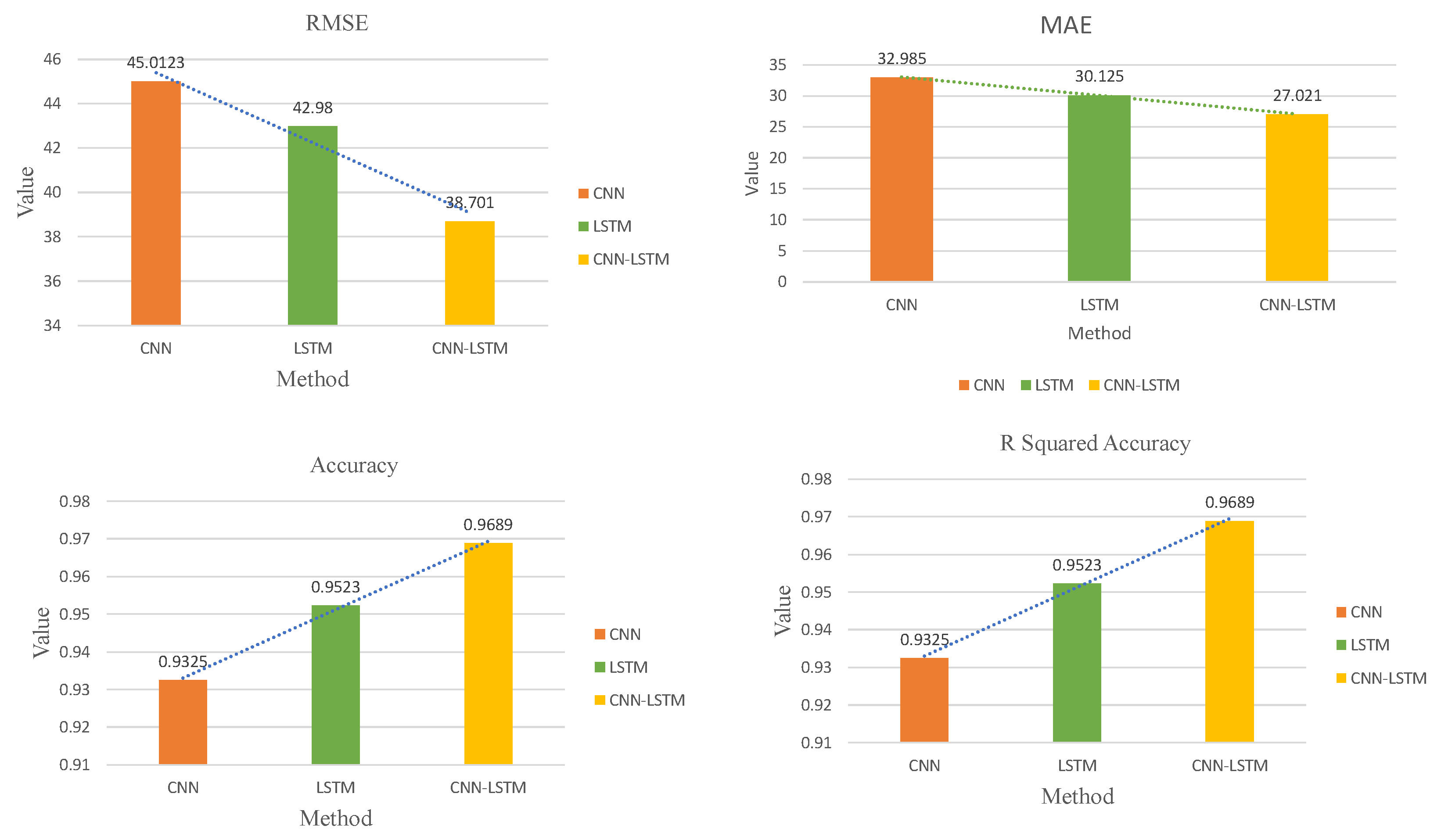{kind=link}
{kind=link}
{kind=link}
| Data Source | Description |
|---|---|
| Telemetry | Time-series data of voltage, rotation, pressure, and vibration measurements recorded in real time from 100 machines and averaged across every hour throughout 2015. |
| Errors | Non-breaking errors that machines throw while in operation. |
| Maintenance | Scheduled and unscheduled records corresponding to inspection and failures of different components. |
| Machines | Includes machine summary such as model, age, and years in service. |
| Failures | Records of the replacements due to failures. |
| Datetime | MachineID | ErrorID |
|---|---|---|
| 2015-01-03 07:00:00 | 1 | error1 |
| 2015-01-03 20:00:00 | 1 | error3 |
| 2015-01-04 06:00:00 | 1 | error5 |
| 2015-01-10 15:00:00 | 1 | error4 |
| 2015-01-22 10:00:00 | 1 | error4 |
| 2015-01-12 14:00:00 | 2 | error4 |
| 2015-05-30 20:00:00 | 2 | error5 |
| 2015-11-20 23:00:00 | 3 | error1 |
| Training Set | Validation | Test Set |
|---|---|---|
| 70% | 10% | 20% |
| Parameters | Value |
|---|---|
| Convolutional layer filters | 64 |
| Convolutional kernel size | 1 |
| Convolutional layer activation function | ReLU |
| Convolutional layer padding | Same |
| Pooling layer pool size | 1 |
| Pooling layer padding | Same |
| Pooling layer activation function | ReLU |
| Number of LSTM hidden cells | 128 |
| Number of skip connections | 2 |
| LSTM activation function | tanh |
| Batch size | 32 |
| Loss function | RMSE, MAE |
| Learning rate | 0.0001 |
| Epochs | 100 |
| Hyperparameters | LSTM | CNN | CNN-LSTM |
|---|---|---|---|
| Model Nodes | 3 | 64 | 64 |
| Batch Size | 32 | 32 | 32 |
| Optimizer | ADAM | SGD | ADAM |
| Learning Rate | 0.001 | 0.001 | 0.001 |
| Training Data | 70% | 70% | 70% |
| Validation Data | 10% | 10% | 10% |
| Test Data | 20% | 20% | 20% |
| Method | MAE | RMSE | R-Squared Accuracy |
|---|---|---|---|
| CNN | 32.985 | 45.012 | 0.932 |
| LSTM | 30.125 | 42.98 | 0.952 |
| CNN-LSTM | 27.021 | 38.701 | 0.968 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wahid, A.; Breslin, J.G.; Intizar, M.A. Prediction of Machine Failure in Industry 4.0: A Hybrid CNN-LSTM Framework. Appl. Sci. 2022, 12, 4221. https://doi.org/10.3390/app12094221
Wahid A, Breslin JG, Intizar MA. Prediction of Machine Failure in Industry 4.0: A Hybrid CNN-LSTM Framework. Applied Sciences. 2022; 12(9):4221. https://doi.org/10.3390/app12094221
Chicago/Turabian StyleWahid, Abdul, John G. Breslin, and Muhammad Ali Intizar. 2022. "Prediction of Machine Failure in Industry 4.0: A Hybrid CNN-LSTM Framework" Applied Sciences 12, no. 9: 4221. https://doi.org/10.3390/app12094221
APA StyleWahid, A., Breslin, J. G., & Intizar, M. A. (2022). Prediction of Machine Failure in Industry 4.0: A Hybrid CNN-LSTM Framework. Applied Sciences, 12(9), 4221. https://doi.org/10.3390/app12094221