1. Introduction
Since the 4th Industrial Revolution, the smartization of the manufacturing industry using information and knowledge has been rapidly growing. Computer numerical control (CNC) [
1], machining center tool (MCT), and injection molding machines are typical production equipment applied to smart factories. Various sensors are installed and operated in the factory for detecting defects and maintaining the production facility. It is possible to build a monitoring system using data gathered from sensors. Sensors are used for predictive preservation of production machines, optimization of manufacturing processes, and real-time abnormality detection using applying data analysis [
2], machine learning [
3,
4,
5,
6] and deep learning [
7,
8,
9] technology. According to these changes, various research studies have been conducted in academia based on sensor data. Data collected from the sensor data [
10,
11,
12,
13,
14] are stacked up as big data and stored in a data center at the manufacturing site or in a cloud environment. Owing to the rapidly growing computing power the analyze of big data has recently been in the spotlight.
However, there is a fatal problem with sensor data gathered from manufacturing facilities. The state of big data from most of the manufacturing facilities is more imbalanced than that of normal data. Furthermore, it is not easy to gather abnormal data unless the equipment intentionally fails because the tools are replaced periodically based on the experience of expert workers.
To solve the class imbalance of data, research studies have been conducted to detect outliers in data by learning only normal data. However, previous studies have focused on the correlation between the time of occurrence of the abnormality in all data, and the reasons of the abnormality. To detect abnormalities in CNC machines, the most representative machine tools in the manufacturing industry, have various data such as physical properties information of raw materials, vibration of motors, and discharge of lubricants. These data are applied as elements of abnormal detection [
15,
16]. Owing to the nature of the time series, data is continuously gathered and stored by time. Most big data processed for analysis after storage, consumes considerable time and effort to pre-process time series data. Therefore, the detection of abnormalities in the product unit takes precedence before focusing data on abnormalities and factors that affect their occurrence. In this study, class imbalance was resolved and approached as a computing architecture for data storage methods and data classification. This study focused on product-level collection and analysis, data-oriented collection, and analysis. In addition, we aim to detect the problem state, which is abnormality, during processing of each single product, not to classification the reason of processing problem state.
The data used in this study utilizes sensor data collected by CNC. Many studies have been conducted on abnormality detection for CNC predictive preservation [
17,
18]. However, related studies have only performed abnormality detection for the entire collected data. To apply it to the real field, product-oriented data storage and abnormality detection are required rather than, the entire data. The contributions of the study are as follows: A new architecture using the SSA [
19] technique and the unsupervised deep learning model [
20] is proposed. It also increases the usability of big data collected from smart factories through new proposals on how to store data.
The validity of the storage and analysis methods of CNC data is verified through experiments. It also applies and compares various proposed techniques to improve class imbalance and demonstrates the performance of the proposed classification model. In addition, an experiment was conducted to confirm the effectiveness of the proposed architecture to determine whether the architecture could record valid performance when applied in practice. The experiment was conducted based on sensor data collected at the real site and utilized vibration data from the CNC machine. After the experiment, the characteristics of the proposed architecture and considering it, areas that are good to be applied.
Our contributions through this paper are as follows.
For the smartization of small and medium-sized manufacturing industries that are do not have the latest facilities, we propose an architecture for data collection methods and classification.
A deep learning classification technique based on the SSA technique is proposed.
Through the proposed classification technique, “product with data” can be achieved within a smart factory.
“Product with data” refers to a group of data generated in product units, not data collected for one day or data for each process unit. The composition of this paper is as follows. First,
Section 2 describes previous studies. Recent research trends and previous related studies are presented along with abnormal detection studies using CNC data, problems of class imbalance data, and previous studies to solve them.
Section 3 introduces the configuration of the data classification architecture to be proposed in this paper. Along with the overall structure, the expected effects of the detailed components of each structure are introduced in detail.
Section 4 presents the results of the applicability and experiments on the propositions to be proven in this study. Finally,
Section 5 summarizes the contents of the thesis, introduces future research, and concludes the thesis.
2. Related Work
2.1. Smart Factory and Big Data
Automation production facilities associated with smart factories contain numerous sensors, and diverse data are collected through programmable logic controller (PLC). Some data are used for data analysis, however, there are also highly volatile data such as information displayed on indicators installed in production facilities. When the torque overload caused by over-insertion of the machine instrument exceeds the threshold, you will be notified, and the machine view of the defect assessment and load cell installed on the conveyor will also operate offline. Various values can be generated by accumulating processing analysis in real time only with data that is instantly discarded. If a typical big data analysis is the process of finding meaningful things by applying various algorithms to vast amounts of data accumulated over a long period of time is a common big data analysis [
21], smart factory data processing focuses on notifying production sites of more real-time analysis [
22]. Analog data such as temperature, humidity, concentration, pressure, and weight are directly or indirectly related to product quality maintenance and can reduce costs through mutual correlation analysis. Machine facilities can be predicted and preserved through analysis techniques such as machine learning and AI algorithms, which provide important data for maintenance cost and energy saving, using data such as facility load patterns and vibration frequencies of existing sensors. For this data analysis, it is necessary to focus on the quality of the collected data. It is not a big data analysis method that accumulates and analyzes data, but a data state generated when collecting data in real time. Only then can the value of data used in smart factories be increase.
2.2. CNC Machine
CNC machines are widely used in manufacturing facilities to manufacture products according to the desired shape and conditions by entering predefined commands [
23]. The operating principle of CNC begins with direct coding through a CNC machine or PC with a CNC programming application. The program or order transmitted and executed to the CNC machine performs the process according to the program and the desired form. Depending on the process, various methods are used, and the types of data collected are different. The collected data is representative of vibration, temperature, speed, power, current, and noise. Various research studies have been conducted to detect abnormalities in the mechanical system of CNC machines. According to previous studies, vibration, power, and noise data are typical data used to prove the cause of failure of CNC machines. A previous researches using motor vibration data of production facilities proposed a technique to solve the imbalance from collected data and detect outliers based on the encoder-decoder-encoder generator based on the generative adversarial network (GAN) model [
18].
Figure 1 is an actual picture of the CNC machine at the field site where actual data were collected. Two-way processing is performed on this machine. The way of machining that roughly processes the surface is rough machining and fine machining to match the calculated dimensions.In this study, vibration data generated during process are used as a bundle of all machining.
2.3. Edge Intelligence
Edge Intelligence (EI) is a concept that defines the communication, computing, and storage capabilities of a specific infrastructure closest to the local unit user of a distributed network. Previous studies introduced the word “Edge Intelligence” [
24]. “Edge” is an actual location representation in which data is generated and processed. In other words, the edge is the location of the control and computing devices. According to a recent study, devices equipped with small computers are changing to internet of things (IoT) and industrial internet of things (IIoT). These devices work with the addition of AI functions. Edge Intelligence performs edge computing in the analysis performed on AI and ML models. The intelligent edge generally breaks the existing client-server model, and the server has the ability to process, analyze, and protect data [
25]. Edge Intelligence has three main entities: connection, computing, and control [
26]. This Edge Intelligence allows manufacturing systems to refine and classify data to the cloud without additional connections. In addition, Edge Intelligence Devices (EID) interconnect a range of workers, managers, smart facilities, robots, and sensors, and enables extensive connections such as smart factories. Hyper-connected Edge Intelligence systems can collect, manage, analyze, and store large amounts of data through distributed computing. This local computing unit can be combined with a cloud system to improve or replace computing performance. Edge computing is mainly performed by a data collector in a production facility or by an edge server (or IIoT gateway). This feature applies to specific business services that require control of the insights calculated by these local units and may extend to the cloud.
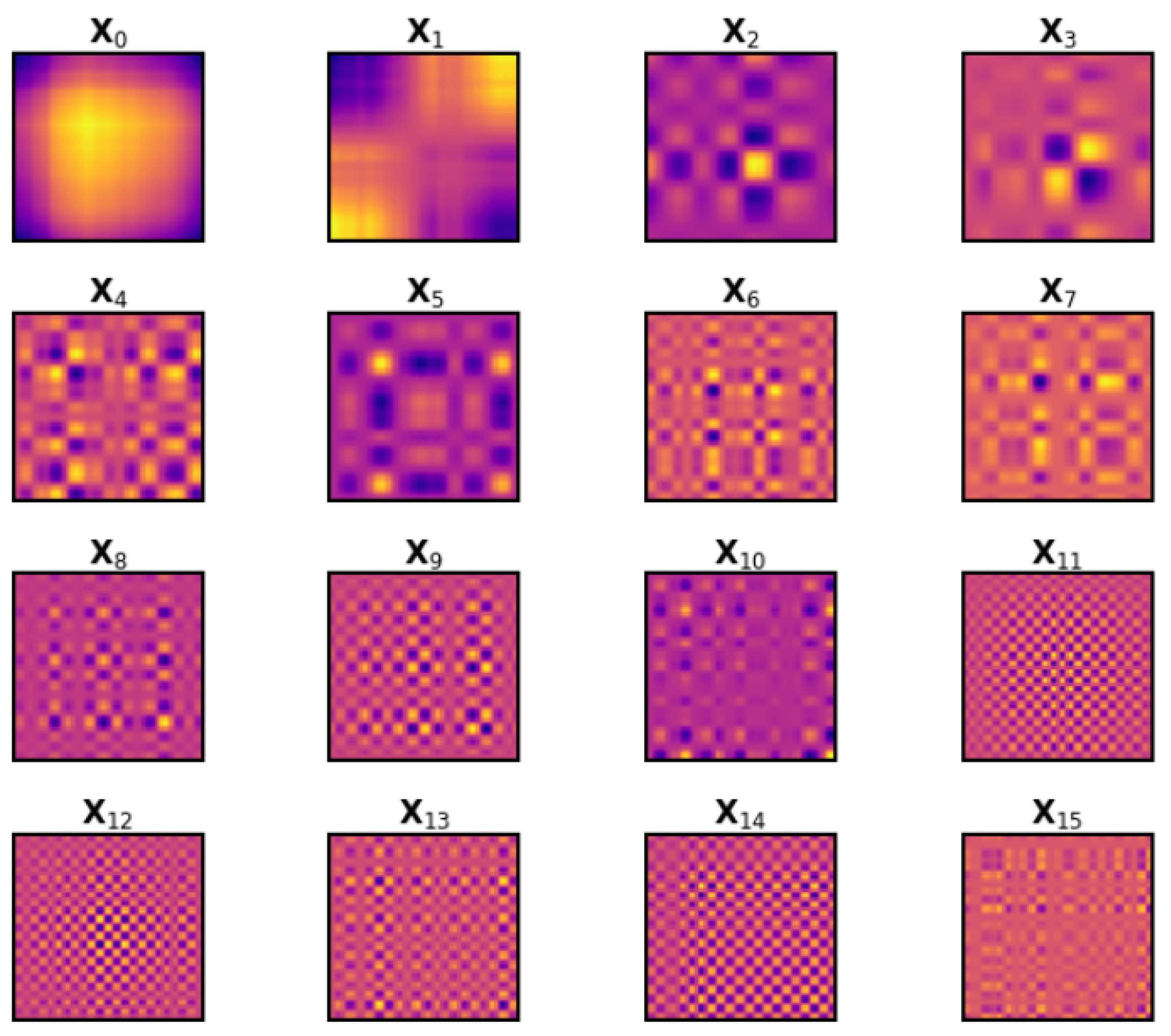
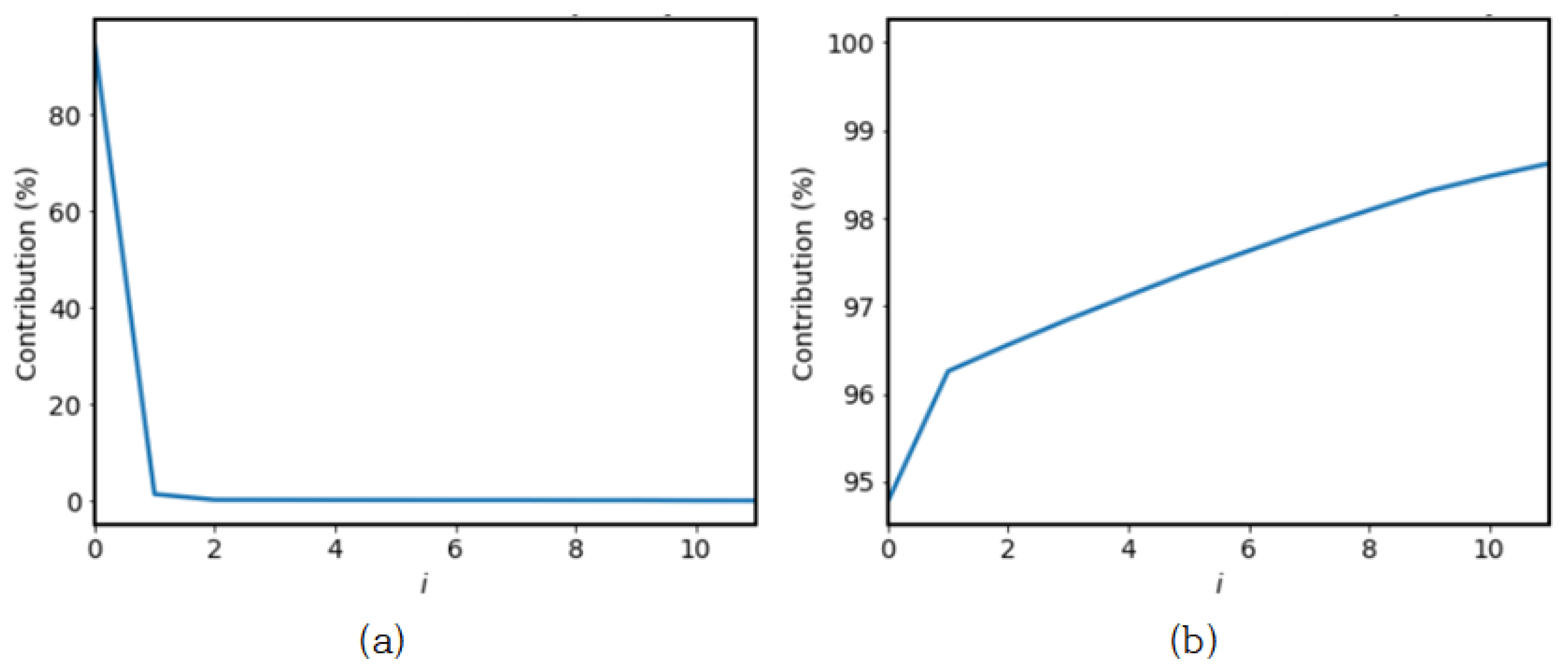
2.4. Singular Spectrum Analysis
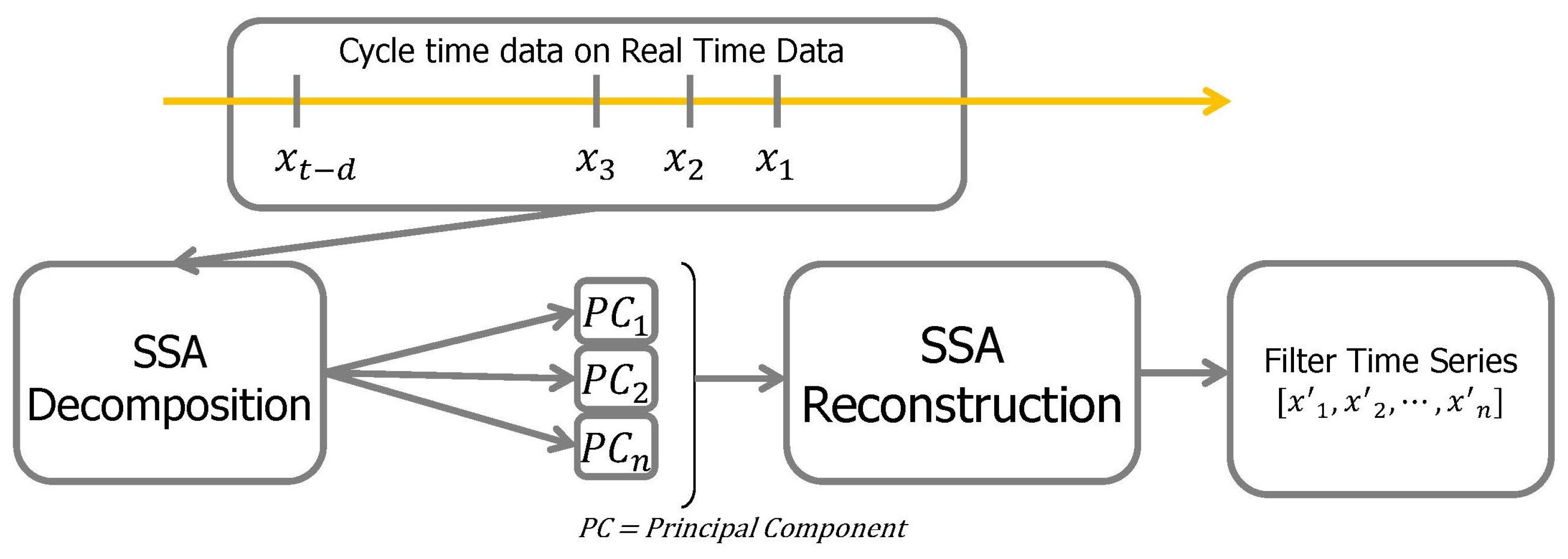
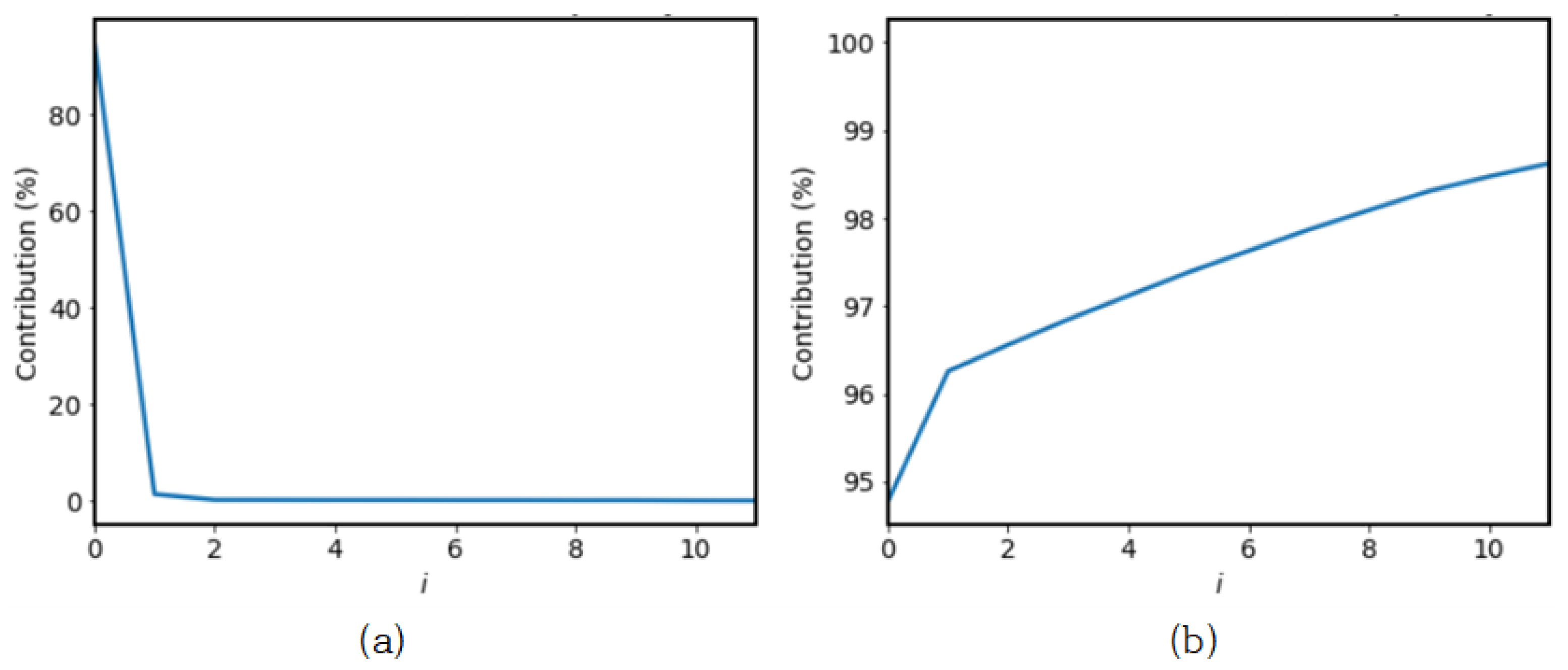
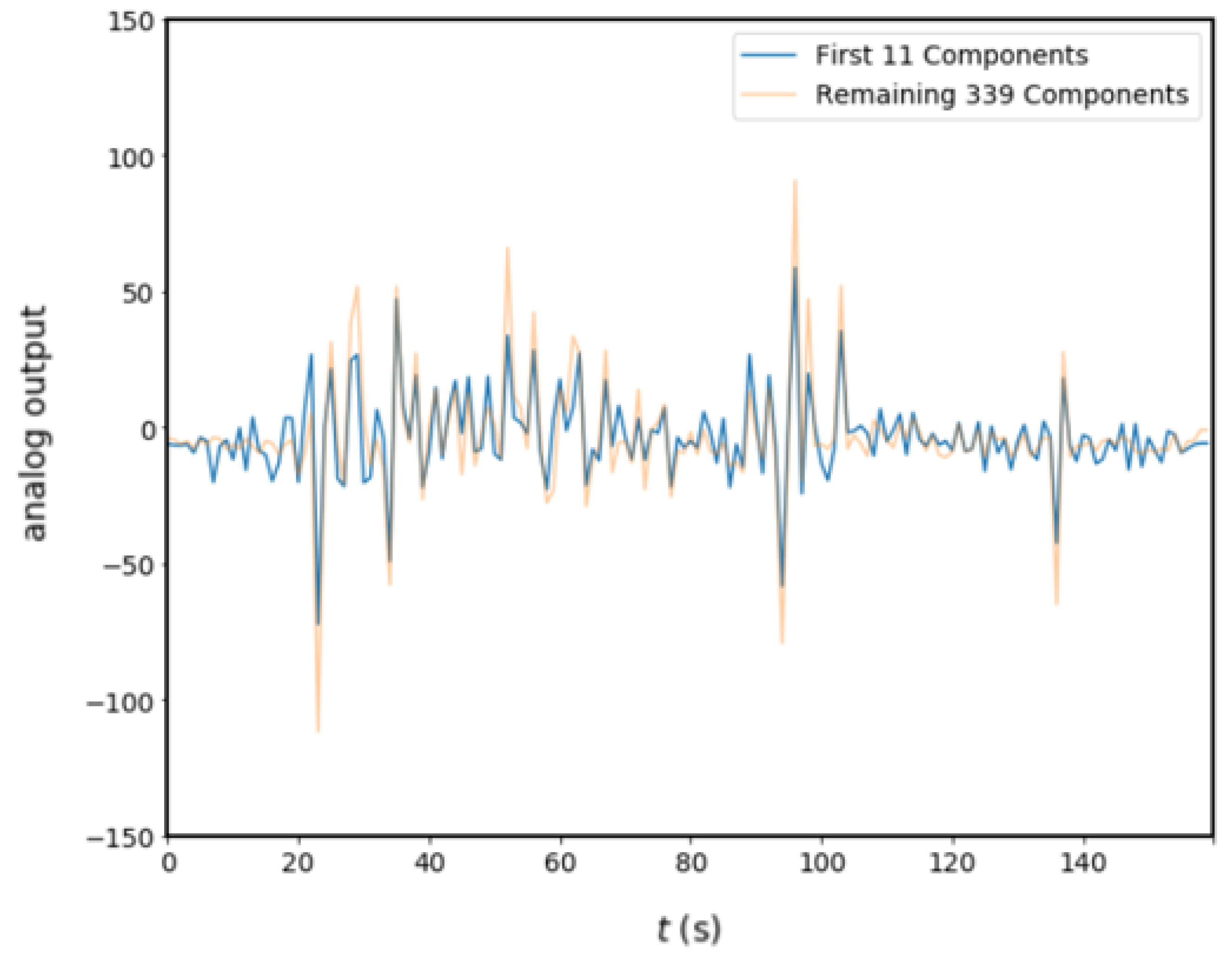
SSA is a time series analysis and prediction technique. Based on Karhunen-Loeve transformation theory, this technique combines classical time series analysis, multivariate statistics, multivariate geometry, dynamic systems, and signal processing elements. SSA aims to decompose the original series into a slow-changing trend, component decomposition such as vibration components, and the sum of a few interpretable components such as noise. This is based on the singular value decomposition (SVD) of a specific matrix configured on the time series [
27,
28,
29]. Components with vibration are first extracted, and then meaningful components are selected for reconstruction. In summary, the algorithm consists of embedding, single value decomposition, grouping, and reconstruction.The process of SSA, the data is rearranged by decomposing the input data into principal components (PCs) and grouping PCs. This process briefly shown in
Figure 2.
2.4.1. Embedding
The first step of SSA is to map time series data
F to a multidimensional delay vector [
28,
30]. The integer value
L is set to the window length, which is
. When
, the window length is obtained by the sub-series
. This window moves along the time series, forming a column vector
for each sub-column.
is defined as follows.
For Equation (
1), the vector of each row forms an L-trajectory matrix, a time series of
. The matrix formed is as follows. This matrix is called the Hankel matrix.
represents the number of columns of the trajectory matrix, the column of X is called the L-lagged vector, and the row is called the K-lagged vector.
2.4.2. Decomposition
The second step in SSA is decomposition. The Trajectory matrix is decomposed using SVD. It is classified into three categories that constitute
X.
U is the unit matrix of
containing the left-specific vector orthogonal set of
X as a column.
is an
rectangular diagonal matrix containing an
X value of
L, and is aligned with the largest and smallest values. Finally,
V in Equation (
3) is a
unit matrix including an orthogonal set of right-specific vectors of
X. The equation for
X is as follows:
Using a SVD equation for the Trajectory matrix is expressed as follows:
Here, represents to the i-th singular value, and and are vectors representing the i-th column of U and V, respectively. is the rank of the trajectory matrix. It is the i-th elementary matrix. , and Vi denotes the i-th eigentriple of the SVD.
2.4.3. Grouping and Reconstruction
Because the time series is uniquely determined in the Hankel matrix, the equation below defines time series
F as the sum of the components
. After grouping these components and classifying them into trends, periodicity, or noise. The equation for grouping is as follows:
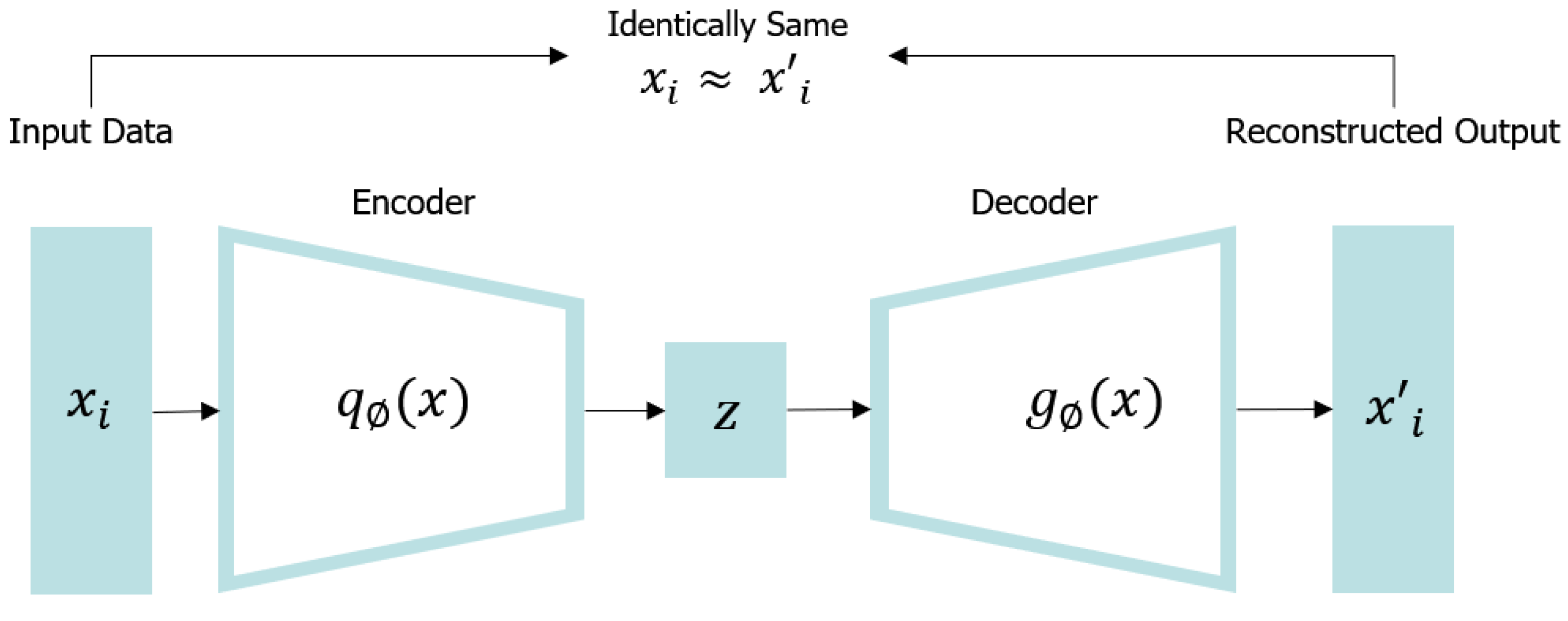
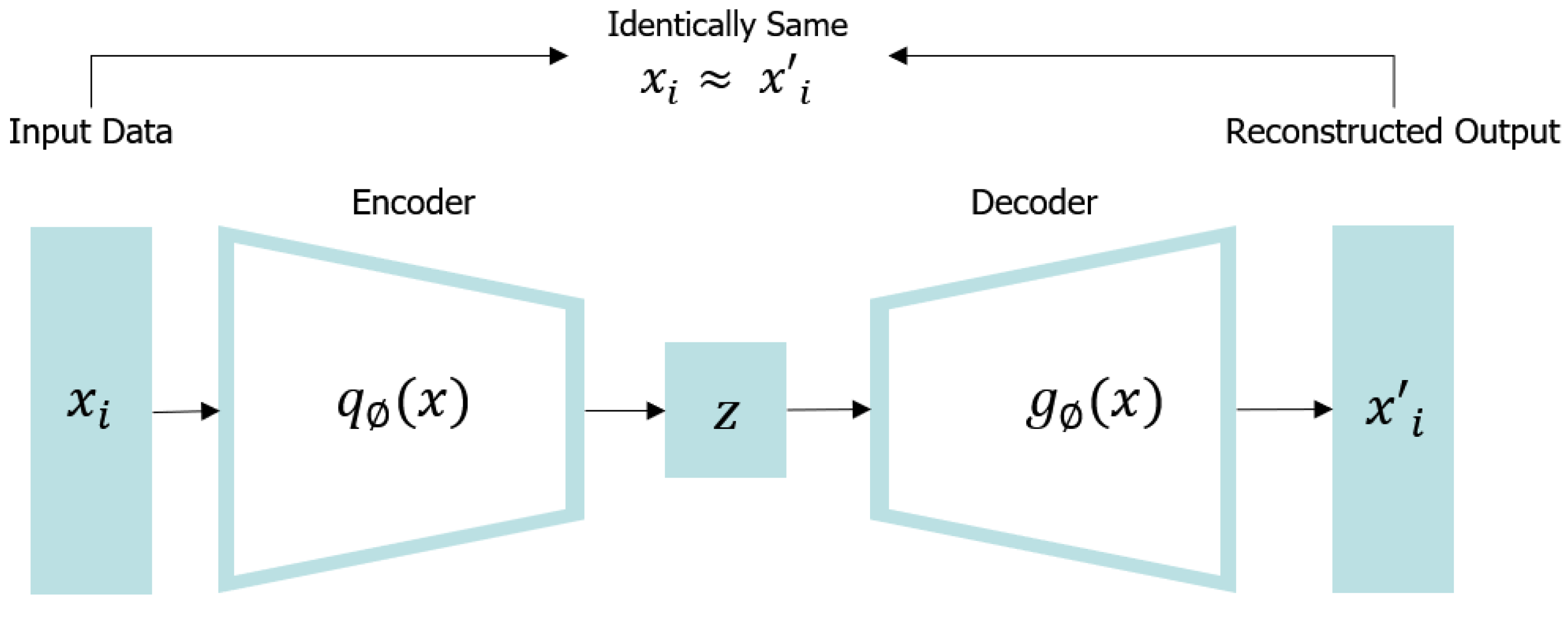
2.5. Autoencoder
An autoencoder [
31] is a neural network that compares input and output as shown in
Figure 3. It makes it a difficult neural network by limiting the network in many ways. For example, the number of neurons in the hidden layer is smaller than that of the input layer, thereby compressing (reducing) data. There are various types of autoencoders, and there is also a model that learns a network to restore the original input after adding noise to the input data. Because the under complete autoencoder cannot copy the input into the output as it is by a low-dimensional hidden layer, the output must learn to include some details from the input. Through this learning, the under complete autoencoder allows to learn the most important characteristics from input data. These constraints prevent the autoencoder from simply copying the input directly into the output and allow it to learn how to efficiently regenerate data.
The encoder, also referred to as a cognitive network, converts an input into an internal expression. The decoder, also referred to as a generative network, converts an internal expression into an output. The encoding operation maps the input data to and the decoding operation reconstructs the input at the latent layer z. It may appear impractical to simply reconstruct input data, however, practical useful characteristics can be obtained by applying some restrictions to autoencoders to obtain so that input data can only be approximate.
In the encoding step, a hidden layer representation of the mapping
for a given input data set
x can be obtained, and the details are as follows.
In the decoding step, the output data
can be reconstructed using the
function for the hidden layer, and the specific expression is as follows:
Here, S is the activation function, is the parameter set of the encoder, and is the parameter set of the decoder. In addition, autoencoder completes learning by minimizing the reconstruction error between and .
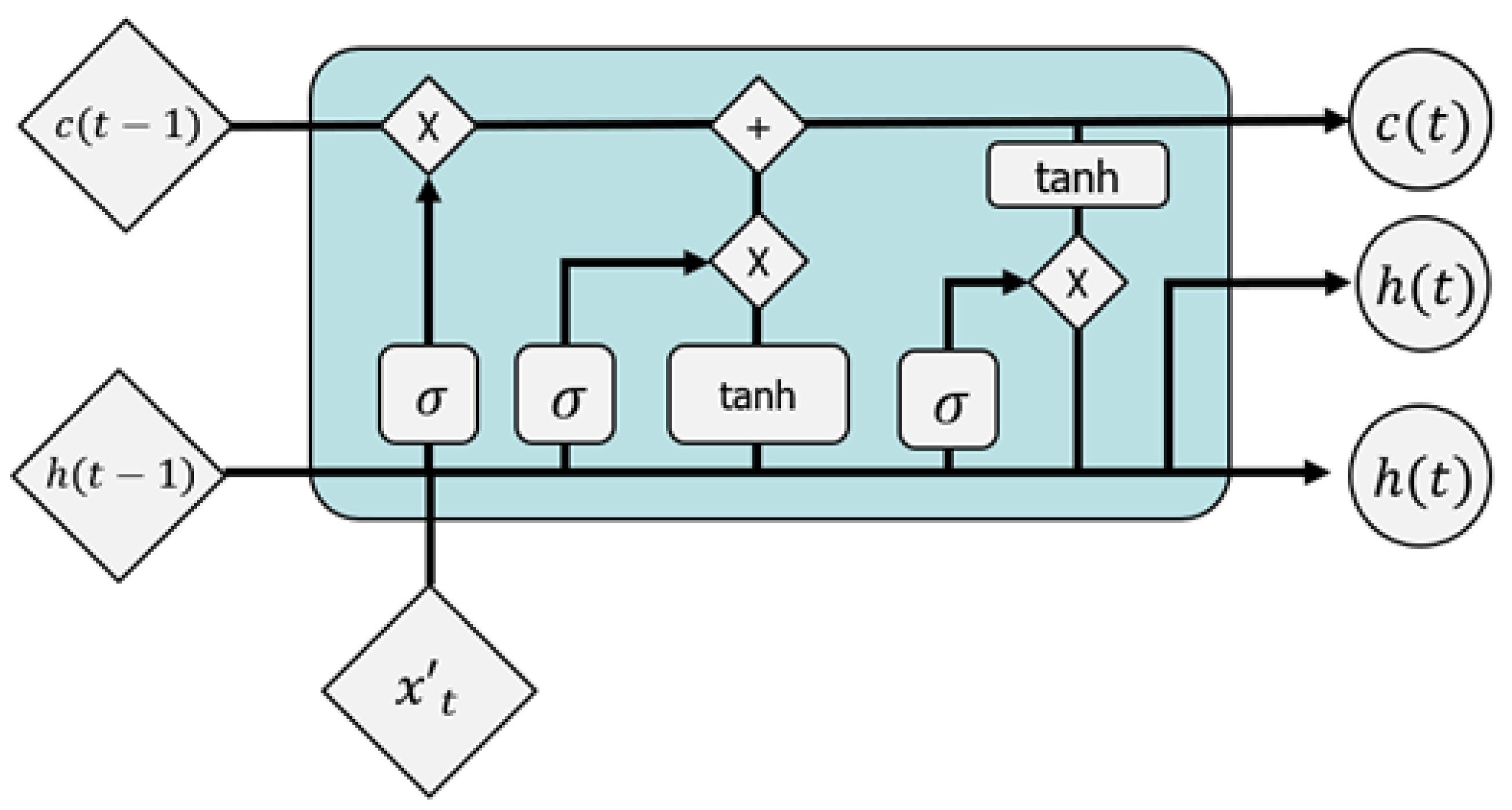
2.6. Long Short-Term Memory
Long short-term memory (LSTM) is a special type of RNN and can perform learning that must have a long dependence period. This model was introduced by Hochreiter and Schmidhuber (1997). All RNNs have the same form as chains that repeat the natural network module. The loop uses the same network repeatedly but allows information to be transferred to different stages. RNN is useful for delivering previous information to the current node, however, one disadvantage is that learning is not smooth when using old historical information. In a basic RNN, this repeated module has a very simple structure. For example, one layer of tanh layer is mentioned. LSTM has the same chain-like structure, but each repeating module has a different structure. Rather than a simple natural network layer, four layers are designed to exchange information with each other in a special way.
The inability to reflect past events in the network was a major drawback of the existing neural network. LSTM that improves these shortcomings. LSTM may effectively model time series data [
32,
33]. Although it is impossible for existing RNNs to learn from the distant past, LSTM can learn from past events and process both high-frequency and low-frequency signals. The advantage of LSTM is that it shows excellent performance in time series data processing. In addition, the information transfer of the previous cell, which is one in the RNN, is added to the output, enabling short-term and long-term memory. This efficient process briefly shown in
Figure 4.
W denotes a weight for connecting the input to the LSTM cell, and
denotes a vector input for the current time point
t.
U represents a weight connecting the previous memory cell state with the LSTM cell,
P represents a diagonal weight matrix,
T represents
non-linearity, and
b represents a deflection value. The relevant expressions and main architectures are shown below.
3. SSA-CAE Based Abnormal Data Classification Techniques in Edge Intelligence Device
3.1. Architecture of SSA-CAE Based Abnormal Data Classification Techniques in Edge Intelligence Device
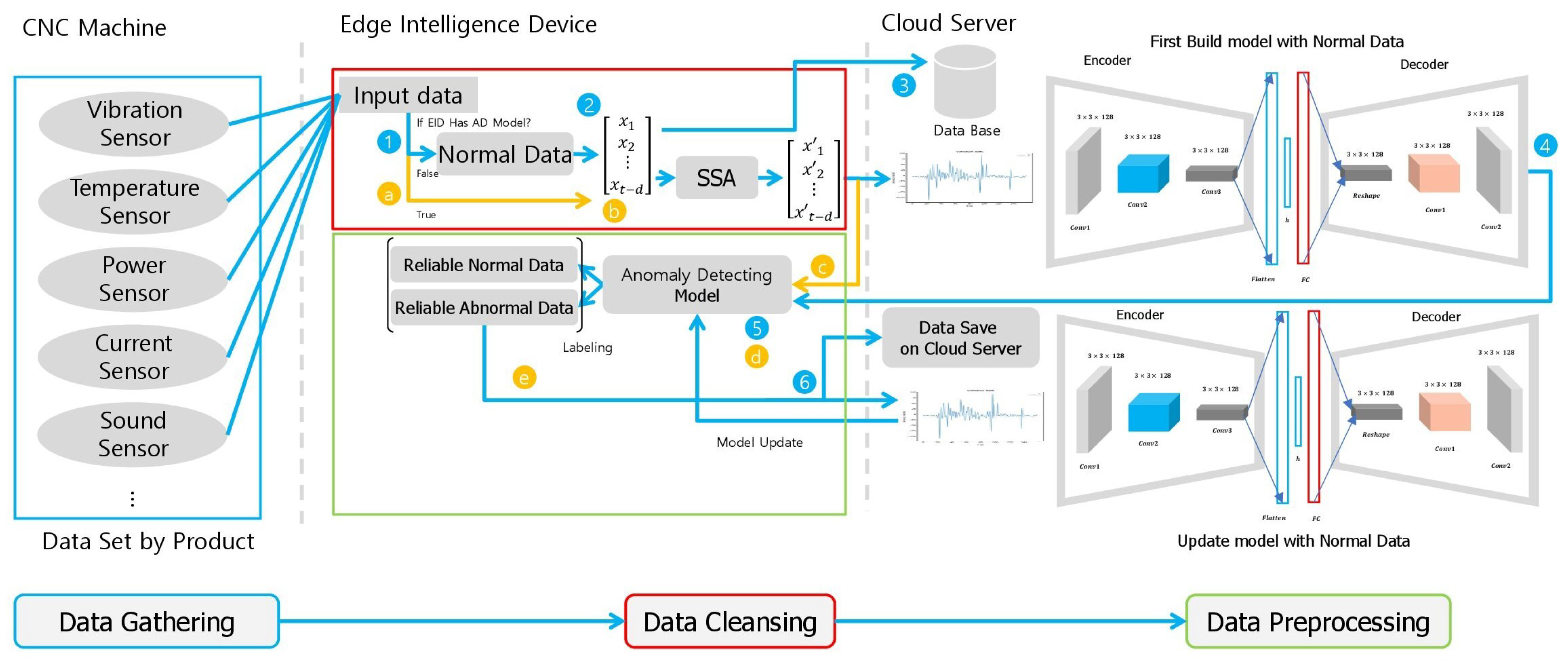
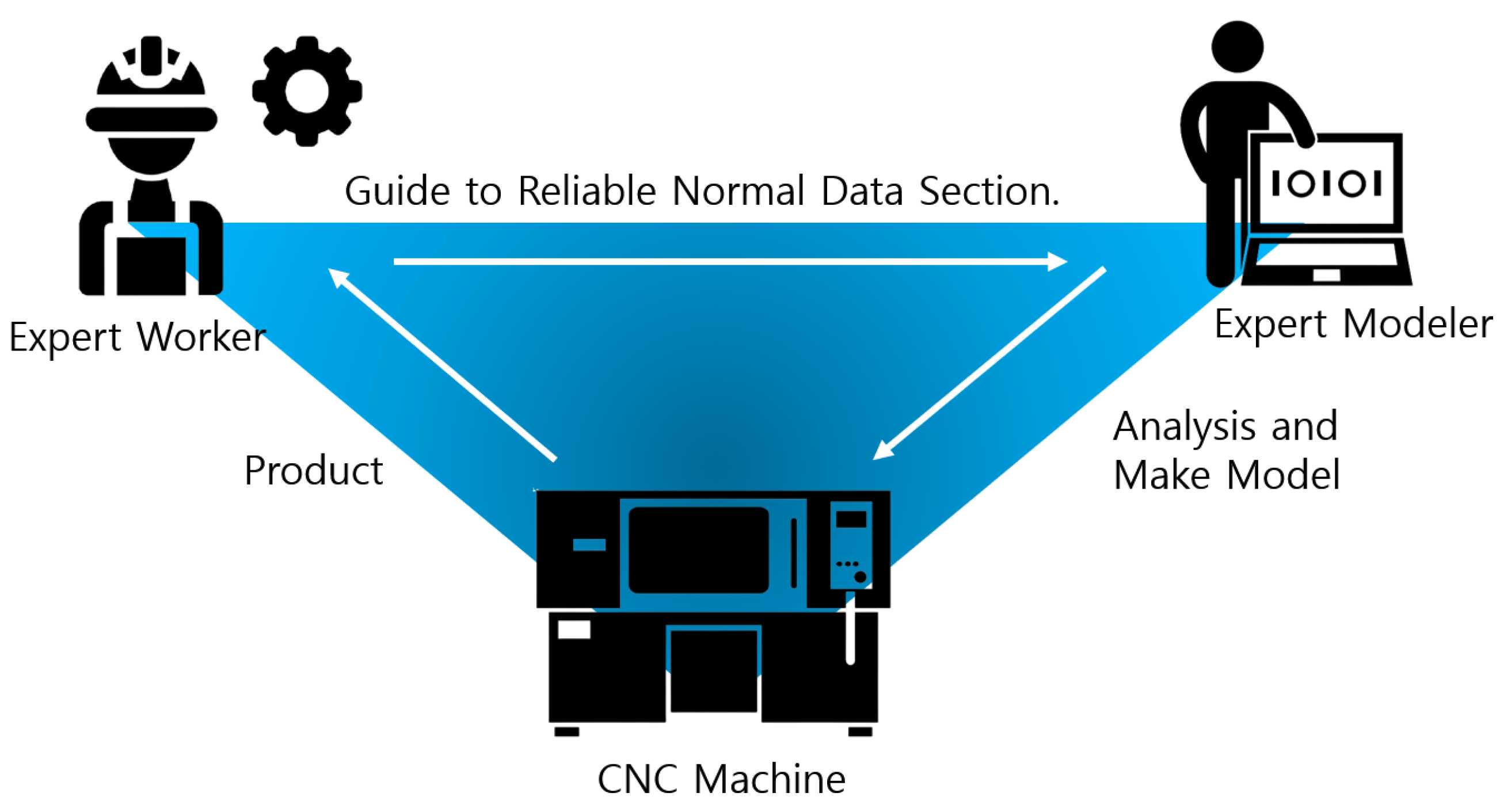
In this paper, we propose a data classification method using the SSA technique and a deep learning technique that is an effective data storage method for data analysis. The structure of the proposed architecture is divided into two spaces in computing space and, with a total of three spaces.
The structure of the entire architecture can be observed in
Figure 5. The space where CNC machine and EID are installed is defined as edge computing space, and cloud server is defined as cloud computing space. Data is collected from the PLC or through sensors directly connected to the Edge Intelligence Device. When collecting data, Edge Intelligence Device receives the CNC machine’s work end point from the PLC and obtains calculates a difference between the previous end point and the most recent end point. Time series data collected by each sensor is sliced into product units by matching the start and end time of the collected time series data. This sliced data is divided into raw data and data processed with the singular spectrum algorithm and stored in the cloud. To create a classification model only with normal data, information on the normal section suitable for the judgment of field expert worker deliver to the modeler.
The judgment of field experts is based on the know-how on the number of processing of CNC machines. In this paper, data based on the judgment of field experts are defined as reliable normal data because one worker is not placed in one machine in the field and the criteria for determining the normal state are different for each worker.
The modeling operator performs deep learning modeling based on processing data stored in the cloud. The created model is stored in the form of an API in the EID in the cloud, and the stored classification model distinguishes the normal state and abnormal state of data for each product unit. The normal data classification process and the modeling process required for modeling are briefly shown in
Figure 6.
3.2. Data Reconstruction Using Singular Spectrum Analysis
As discussed in previous studies, SSA can be reclassified and reconstructed by decomposing the characteristics of data. It is impossible to apply all types of data generated within the smart factory. Processing data using vision sensors is not suitable for utilization purposes. In addition, if multivariate data are processed at the same time, this analysis technique will be inapplicable.
Therefore, this paper focuses on data of one type of data collected in units of products. In
Section 4, the experiment was conducted using vibration data. The role of SSA in the proposed architecture is to reduce noise in data collected in the field and to improve modeling performance through periodic component extraction and reconstruction.
Owing to the different characteristics of analog data such as vibration data and voice data, data experts for each data type should analyze the SVD status and input reconstruction information for key components based on the data processed by EID. In general, it is decomposed into trends, predicted values, and noise values of data through the main components generated in the embedding stage of the Singular Spectrum. The rest of the trends and predictions except for noise values are reclassified and reconstructed into noise-reduced data to help the deep learning model analyze actual abnormal values.
3.3. Data Classification Method through Deep Learning Model
A convolutional autoencoder (CAE) is a variation of the convolutional neural network used as a tool for unsupervised learning of convolutional filters. In general, it is applied to image reconstruction tasks to minimize reconstruction errors by learning optimal filters. It can be applied to all inputs to extract functions that have completed learning about this task. The convolutional autoencoder is a general-purpose function extractor different from a general autoencoder that does not consider a 2D image structure.
In an autoencoder, an image must be rolled into a single vector and a network must be built according to the constraints on the number of inputs. Therefore, the number of data sets used in this experiment averaged 160, which is about 2 min and 40 s of data. To match the number of inputs, the 36 most preceding arrays of 160 were expanded at the end of the array and applied in two dimensions.
The vibration signal, which served as an input value, is a one-dimensional signal of
, the size of the input data was set to
. The feature map was identified through the convolution kernel and maxpooling is used for down sampling. The sigmoid function was used as an activation function, and Adam was used as an optimization function. The detailed architecture of CAE can be found in
Table 1.
5. Conclusions
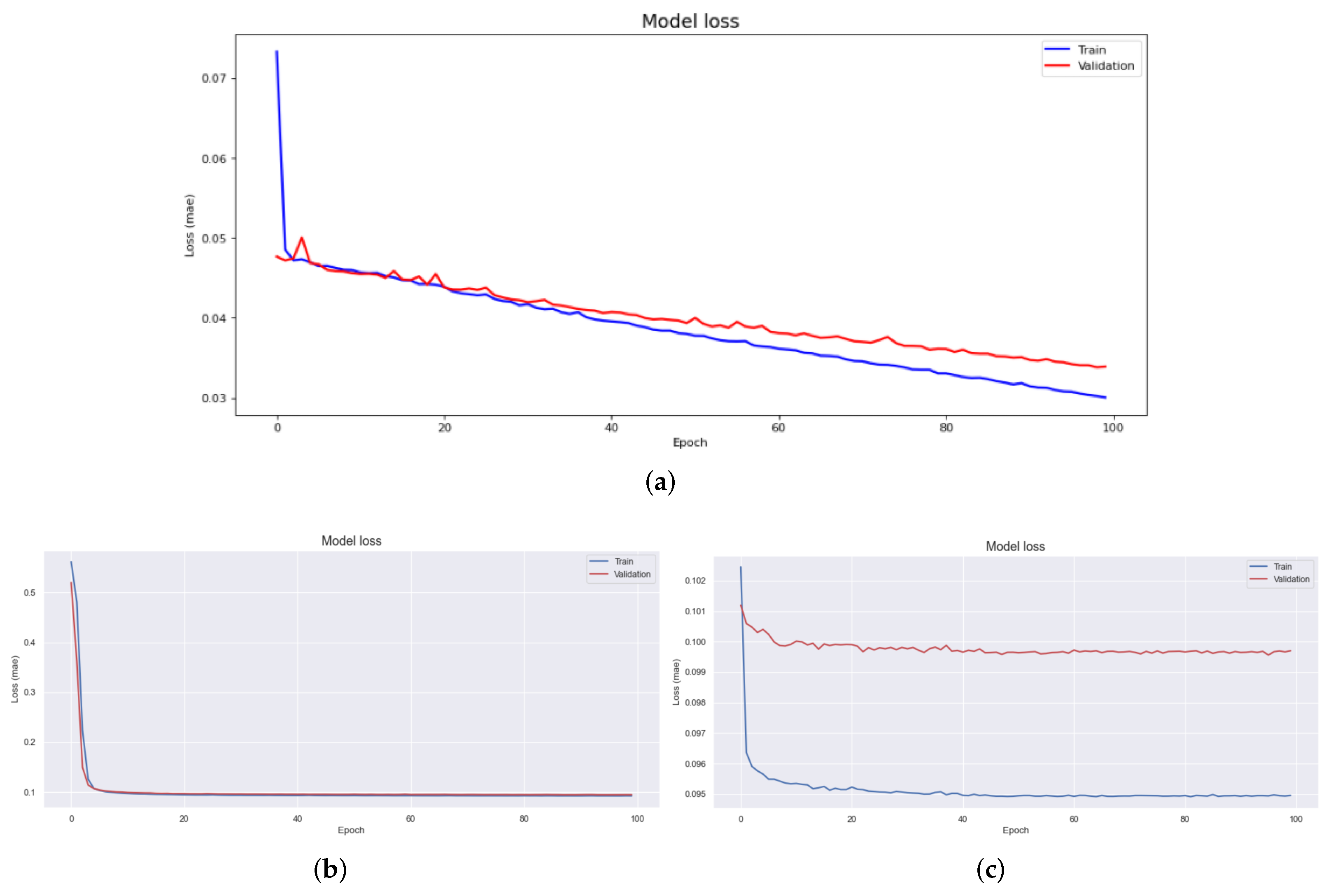
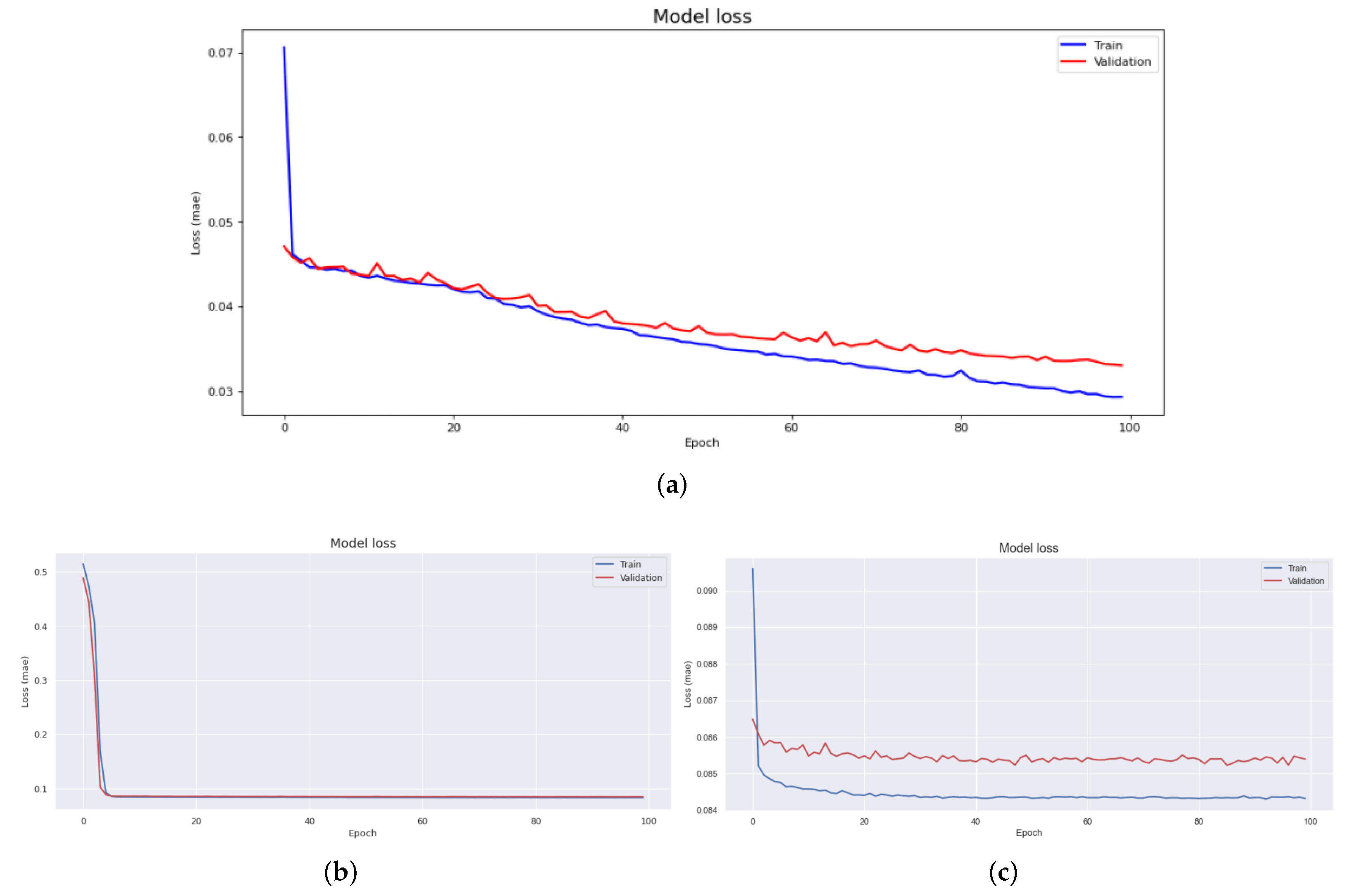
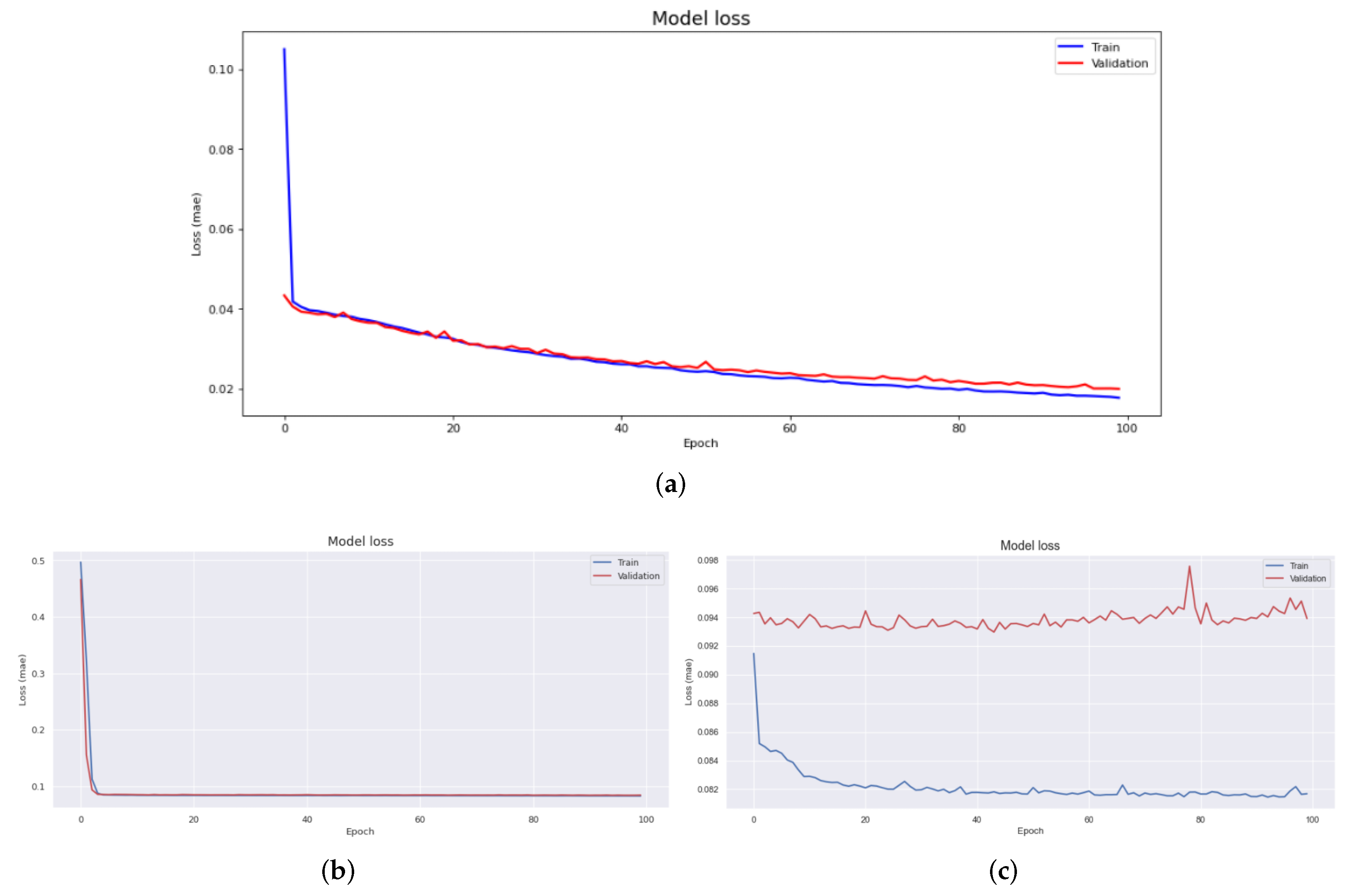
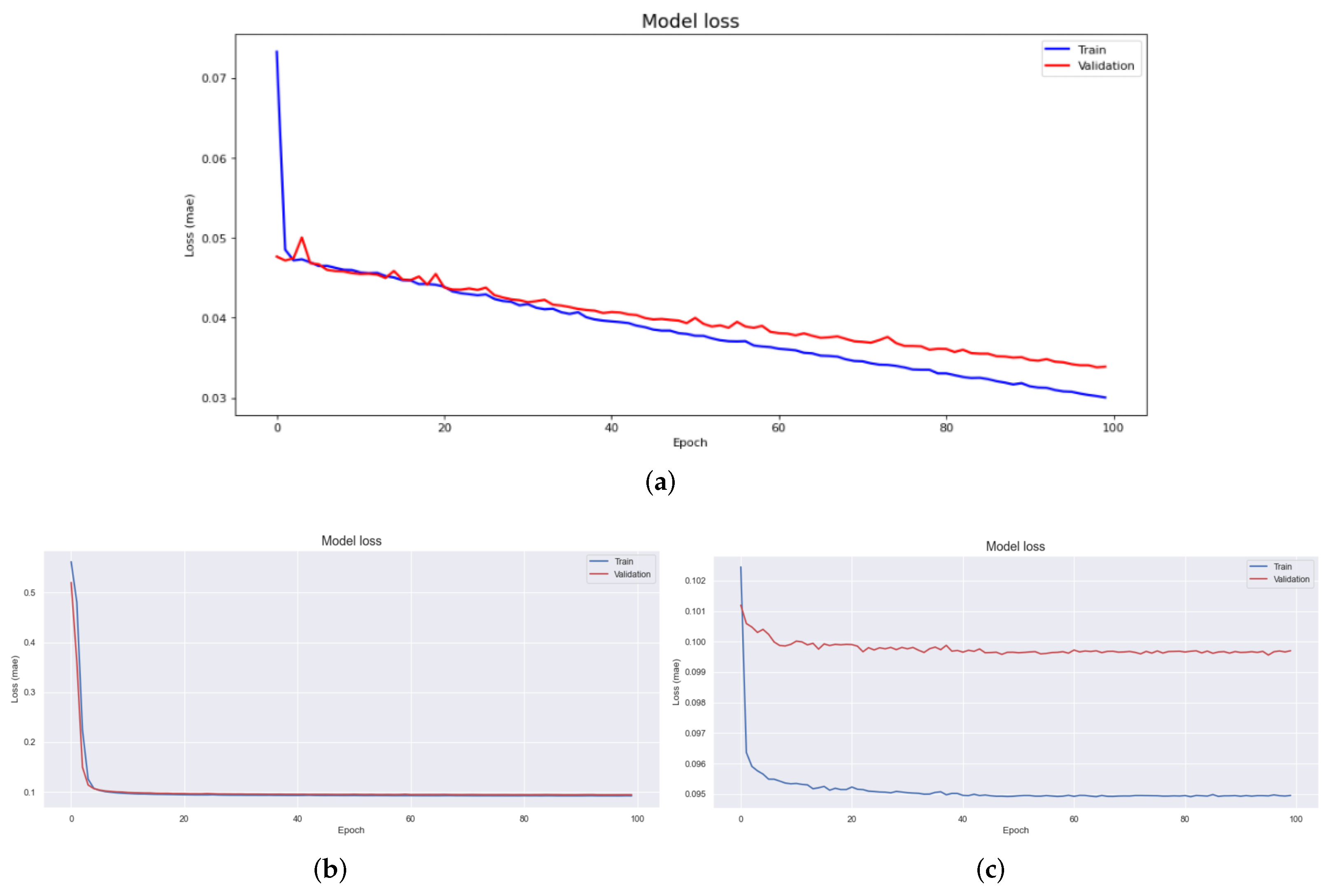
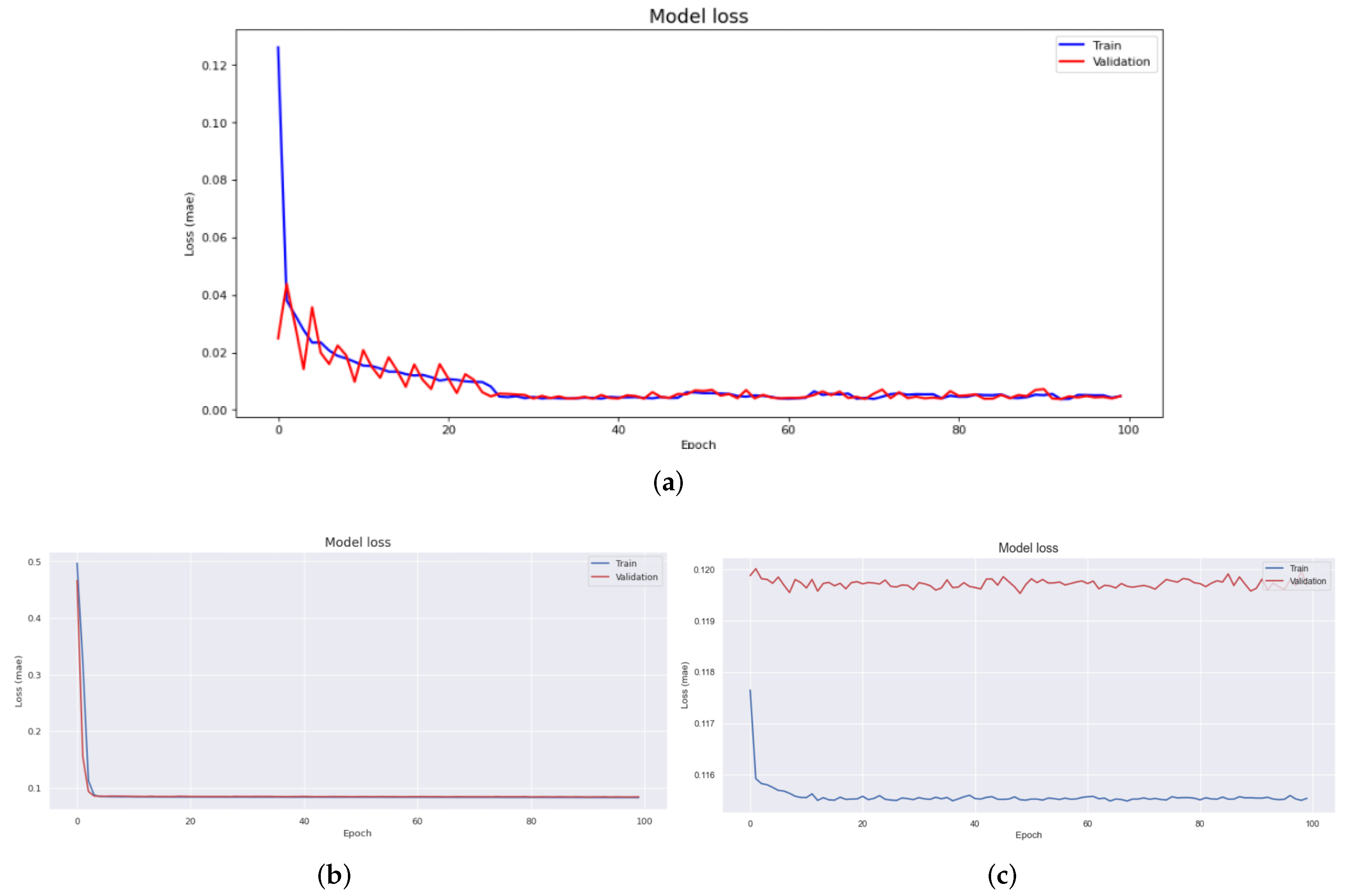
Data pre-processing is a very important task in data analysis. In particular, in machine learning and deep learning, pre-processing of data is a very common and important problem that must be addressed. To this end, techniques and libraries for automatic pre-processing have been studied and developed. The contribution of this paper is that, first, it proposes a big data storage method that can be used for smart factories. By systematizing data separation, “Product with Data” can be configured through product-level storage rather than previous storage methods. In addition, in the analysis, it is the basis for detailed research on data divided by units without pre-processing. Second, in previous studies, a labeling architecture for class imbalance occurring in the manufacturing industry was proposed by combining the data regeneration model and the deep learning model. This study puts a structural distinction between the edge and cloud in a way focused on computing rather than a model-oriented learning method, allowing model learning to be learned in the cloud and model performance to be performed in edge. In order to confirm whether these contributions have practical utility value, this study experimented with noise reduction and abnormal data set classification of data using data collected in the actual field, and verified the effect by proposing an effective classification architecture.
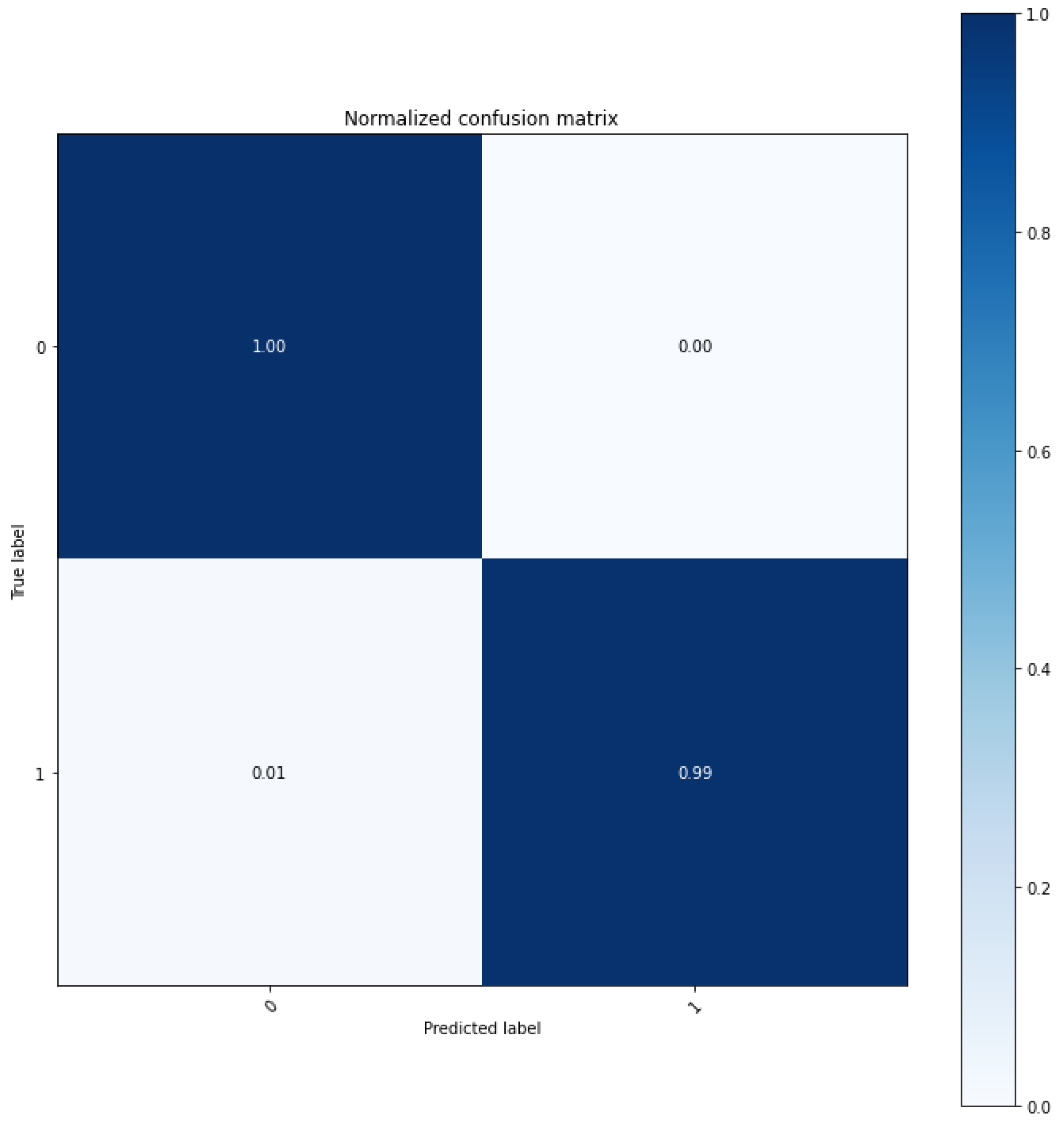
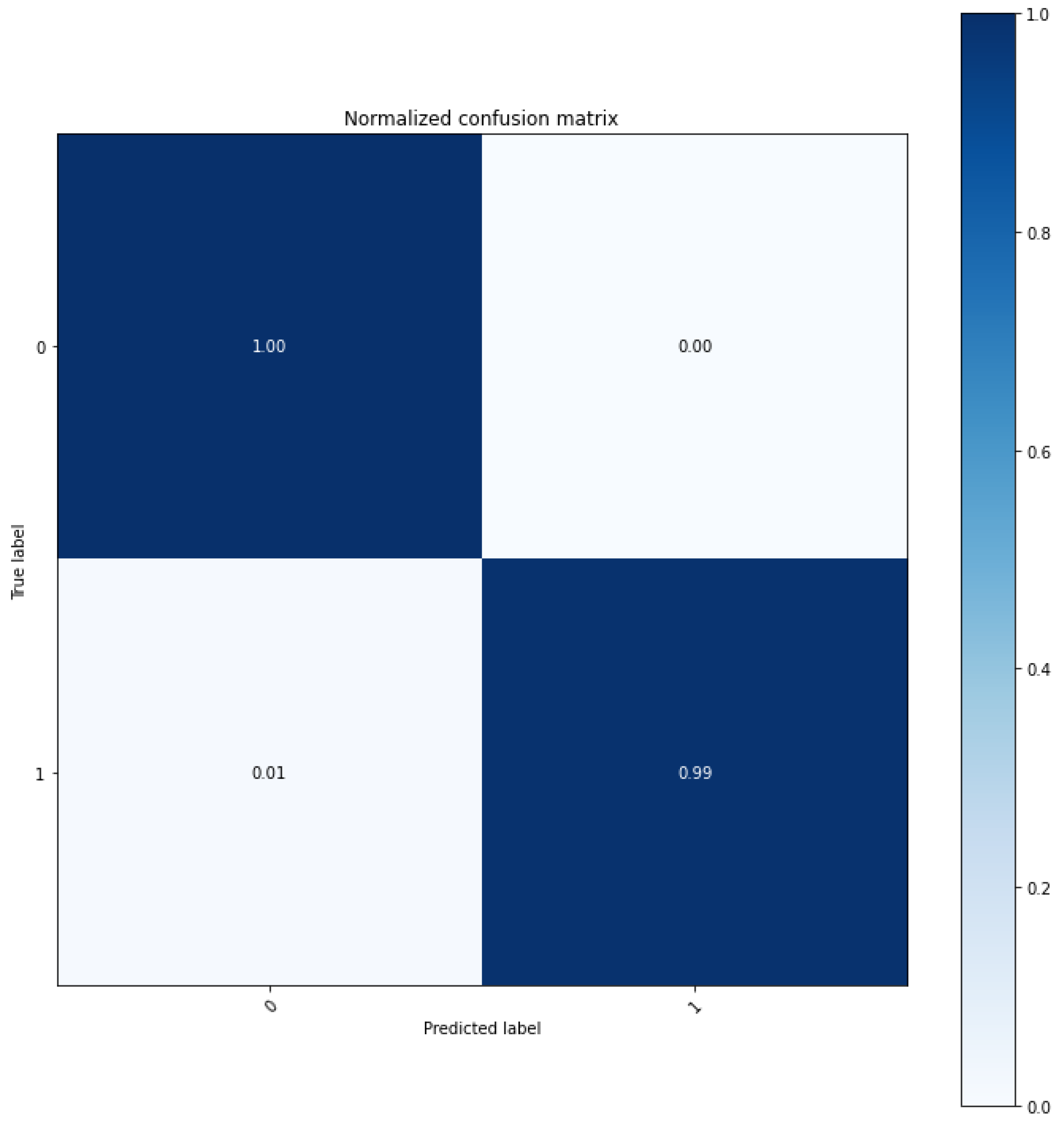
We demonstrated the excellence of the SSA technique for regenerative performance by using other transformation techniques, such as Fourier transform and wavelet transform techniques, as a control group to verify the performance of data collected at industrial sites. LSTM, a short- and long-term memory technique, was added, to the two controls, the autoencoder based convolutional autoencoder, and an unsupervised learning model. According to the experimental results, the experimental results applying CAE showed a difference more than 0.2 RMSE value compared to other results. In addition, MAE showed a difference almost 0.08. Therefore SSA-CAE showed a further improved modeling, and of classification was confirmed. It represents one error out of a total of 100 products.
Further research in the future may consider to apply according to the type of data collected in the field. To this end, the change and demonstration of the Edge Intelligence Device used in the experiment confirm the its applicability to other types of data. Further studies can also be conducted to determine whether classification rate results can be expected using additional studies on unsupervised learning other than the proposed SSA-CAE.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}