
A Human Location Prediction-Based Routing Protocol in Mobile Crowdsensing-Based Urban Sensor Networks



Abstract
:1. Introduction
- First, we design a RNN-based model for human location prediction. Using the predicted information, the packet delivery predictability is proposed and used for relay selection.
- Second, we propose a forwarding algorithm based on the HLP and social strength. There are two phases in the proposed forwarding algorithm. In the first phase, a limited number of copies of the packet are quickly spread throughout the network. In the second phase, packet delivery predictability and social relationships are used to select optimal relay nodes, with the goal of maximizing the , minimizing the , and reducing the .
- Third, using the UB dataset [17], we conduct various experiments to validate the proposed routing protocol. The , , and are used to evaluate network performance. The simulation results demonstrate that the HLPRP can outperform existing routing protocols.
2. Related Work
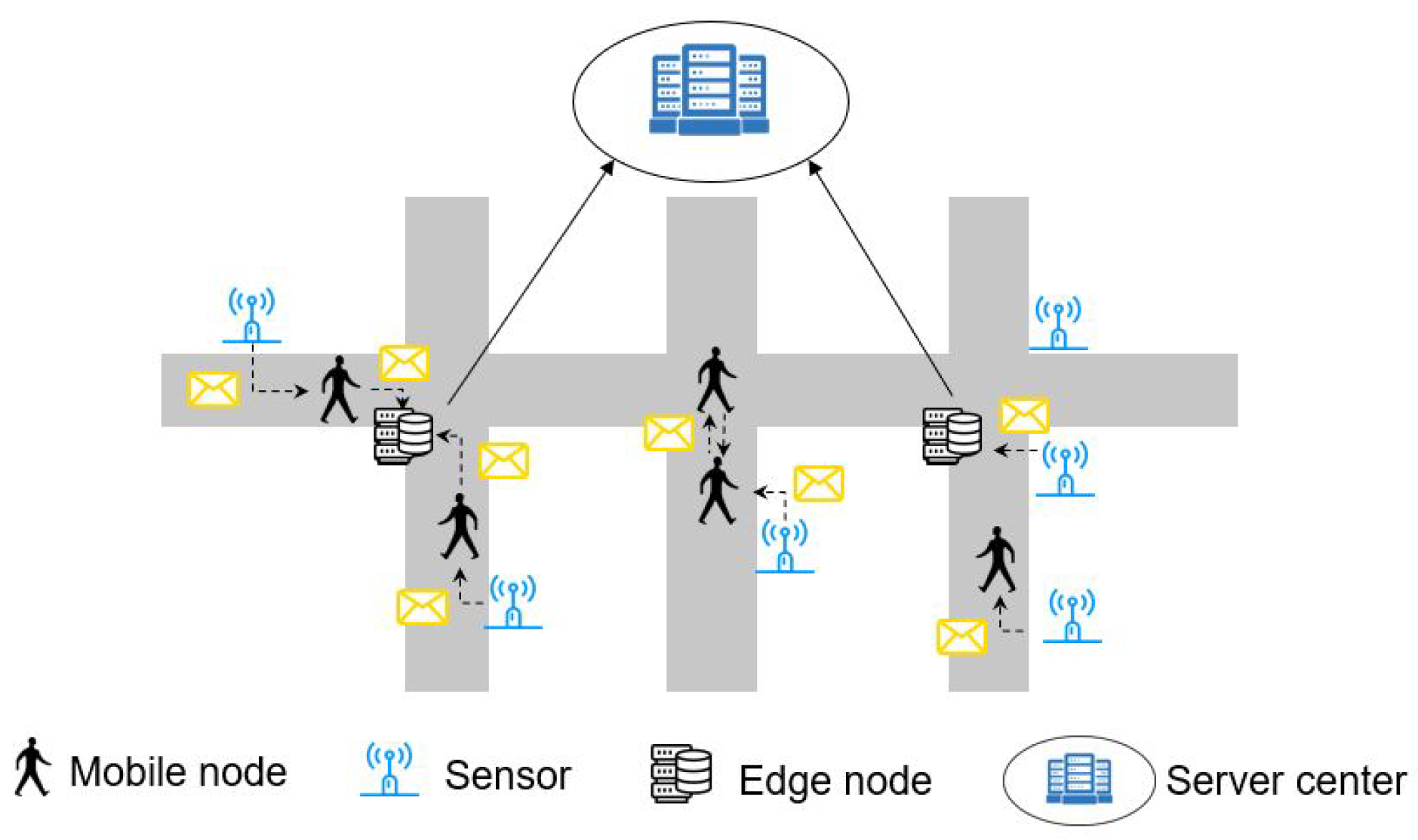
3. Network Model and Problem Definition
- Mobile nodes (mobile users): Mobile nodes collect data, such as temperature, images of traffic conditions, and videos of accidents, using the sensors embedded in their smart devices (e.g., camera, microphone, positioning sensor, temperature sensor), and send to edge nodes. They can walk or be in a vehicle to move around the area. When mobile users are in contact with other people or sensors, they can exchange data between them and transmit data to the destination.
- Sensors: Sensors are deployed in specific locations to collect data, such as air quality, radioactivity, noise levels, and humidity levels. When sensors and destinations (edge nodes) are not directly connected, the sensors must relay packets to mobile users to transfer them to the destinations.
- Edge nodes: Edge nodes are located in particular locations to gather and preprocess collected data from sensors and mobile users. Then, edge nodes send processed data to the server center.
- The server center: The server center receives data from edge nodes and uses the received data for urban-sensing applications.
4. The Proposed Routing Algorithm
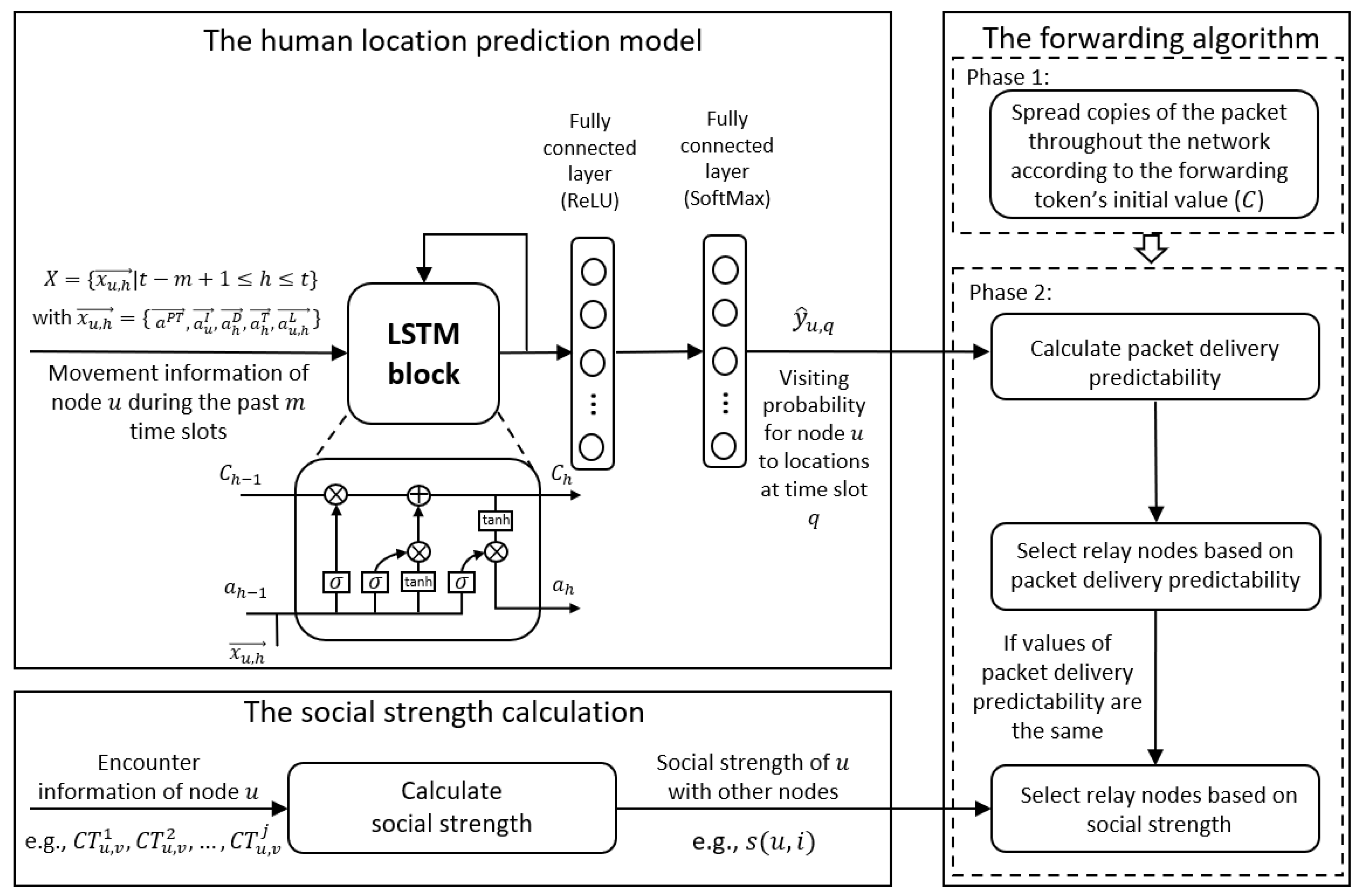
4.1. Human Location Prediction (HLP) Model
4.2. Packet Delivery Predictability
4.3. Social Strength
4.4. Forwarding Algorithm
| Algorithm 1 The forwarding algorithm |
|
5. Evaluation Results
5.1. Dataset
5.2. Simulation Setup
5.3. The Results of the Proposed Human Location Prediction Model
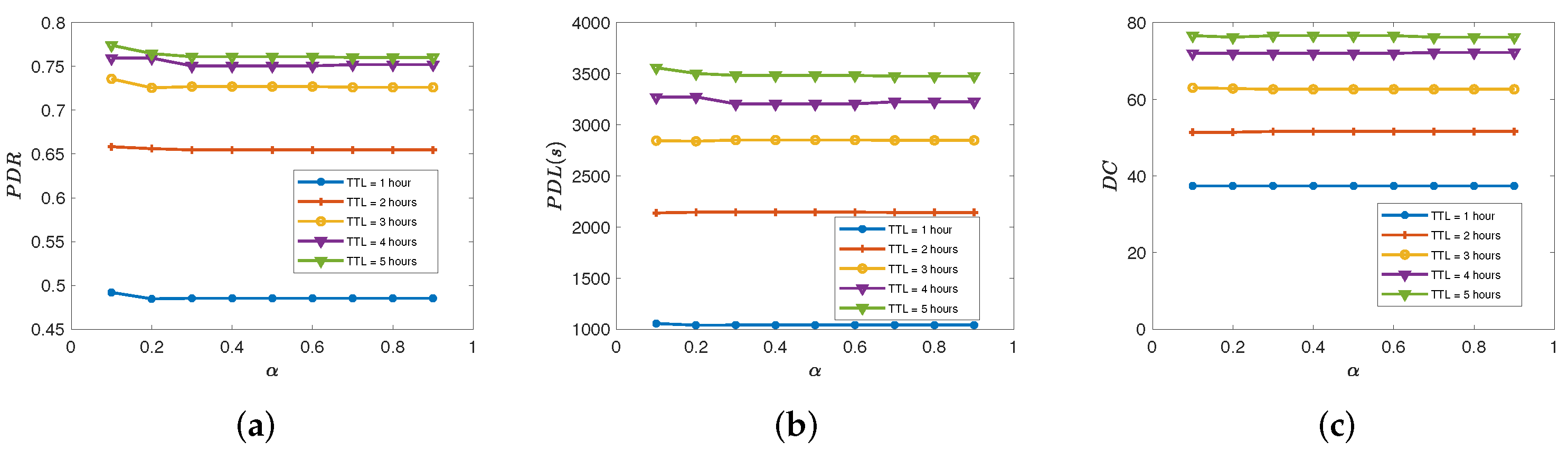
5.4. Effects of on the Performance of the Proposed Routing Protocol
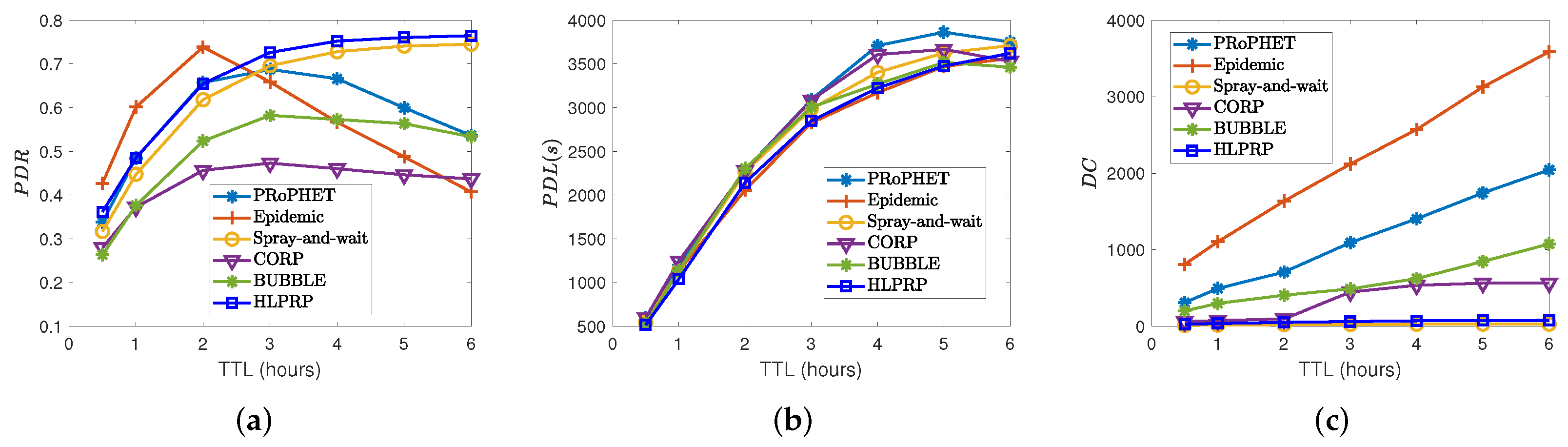
5.5. Effects of Packet TTL on Routing Protocol Performance
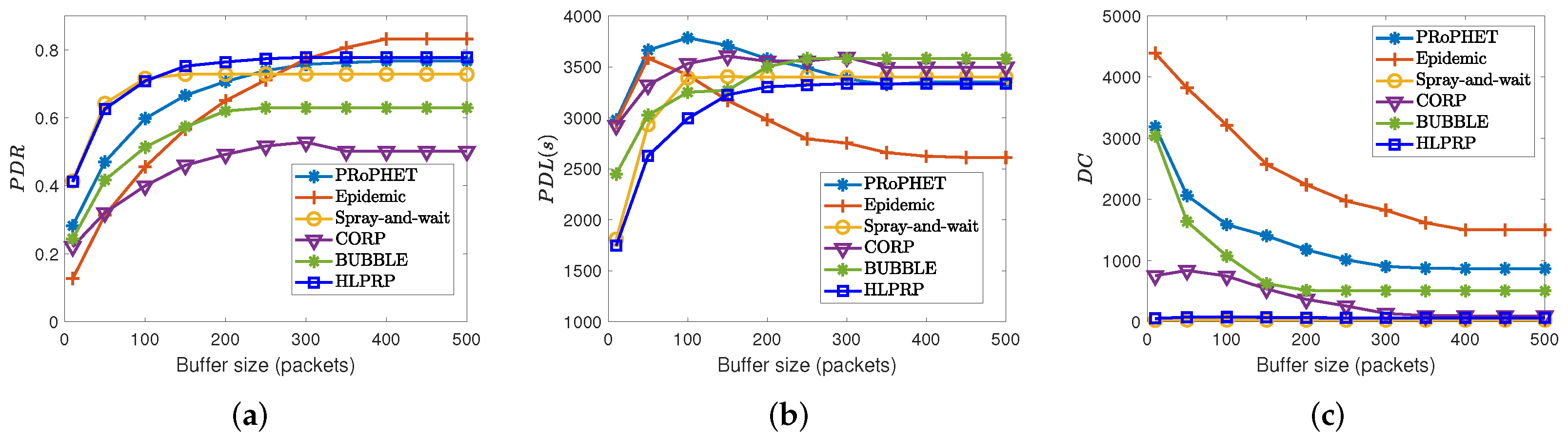
5.6. Effects of Buffer Size on Routing Protocol Performance
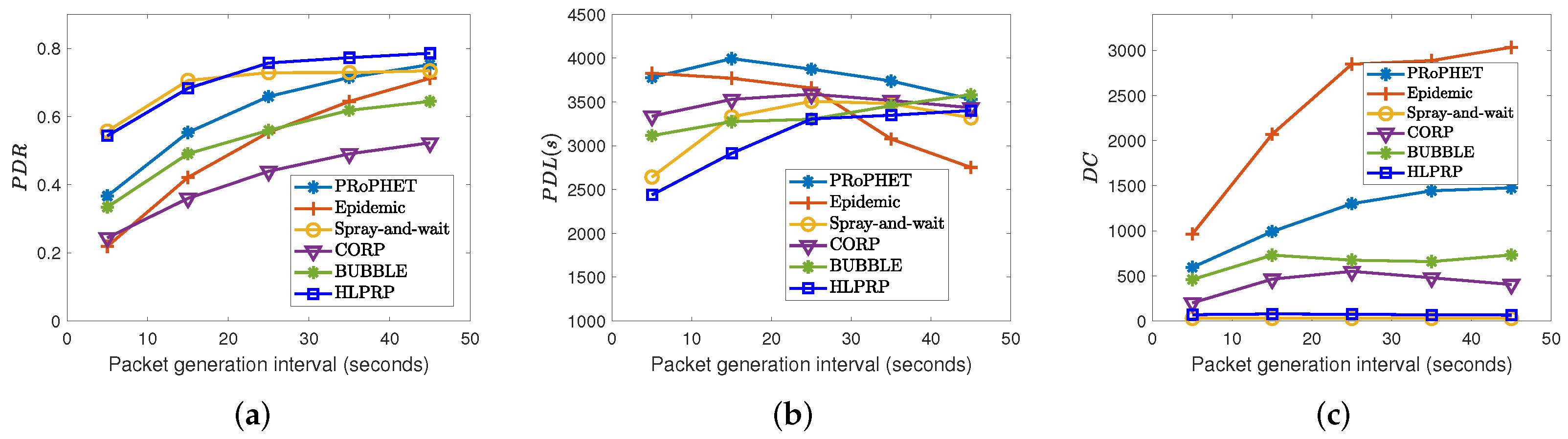
5.7. Effects of the Packet Generation Interval on Routing Protocol Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Capponi, A.; Fiandrino, C.; Kantarci, B.; Foschini, L.; Kliazovich, D.; Bouvry, P. A Survey on Mobile Crowdsensing Systems: Challenges, Solutions, and Opportunities. IEEE Commun. Surv. Tutor. 2019, 21, 2419–2465. [Google Scholar] [CrossRef] [Green Version]
- Boubiche, D.E.; Imran, M.; Maqsood, A.; Shoaib, M. Mobile crowd sensing—Taxonomy, applications, challenges, and solutions. Comput. Hum. Behav. 2019, 101, 352–370. [Google Scholar] [CrossRef]
- Liu, Y.; Kong, L.; Chen, G. Data-Oriented Mobile Crowdsensing: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2849–2885. [Google Scholar] [CrossRef]
- Wu, D.; Xiao, T.; Liao, X.; Luo, J.; Wu, C.; Zhang, S.; Li, Y.; Guo, Y. When Sharing Economy Meets IoT: Towards Fine-Grained Urban Air Quality Monitoring through Mobile Crowdsensing on Bike-Share System. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Jiang, F.; Sun, Y.; Sha, J. Crowd Sensing Urban Healthy Street Monitoring Based on Mobile Positioning System. Mob. Inf. Syst. 2021, 2021, 9394063. [Google Scholar] [CrossRef]
- Ali, A.; Qureshi, M.A.; Shiraz, M.; Shamim, A. Mobile crowd sensing based dynamic traffic efficiency framework for urban traffic congestion control. Sustain. Comput. Inform. Syst. 2021, 32, 100608. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhu, H.; Zhou, B.; Lu, C.; Sun, M.; Ma, X.; Fan, X.; Wang, C.; Chen, L. CrowdPatrol: A Mobile Crowdsensing Framework for Traffic Violation Hotspot Patrolling. IEEE Trans. Mob. Comput. 2021. [Google Scholar] [CrossRef]
- Kutsarova, V.; Matskin, M. Combining Mobile Crowdsensing and Wearable Devices for Managing Alarming Situations. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 538–543. [Google Scholar]
- Vahdat, A.; Becker, D. Epidemic Routing for Partially-Connected Ad Hoc Networks; Technical Report CS-2000-06; Duke University: Durham, NC, USA, 2000. [Google Scholar]
- Garg, P.; Kumar, H.; Johari, R.; Gupta, P.; Bhatia, R. Enhanced Epidemic Routing Protocol in Delay Tolerant Networks. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 396–401. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Spray and Wait: An Efficient Routing Scheme for Intermittently Connected Mobile Networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-tolerant Networking, Philadelphia, PA, USA, 26 August 2005; pp. 252–259. [Google Scholar]
- Duong, D.V.A.; Yoon, S. An Efficient Probabilistic Routing Algorithm Based on Limiting The Number of Replications. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence, Jeju Island, Korea, 16–18 October 2019; pp. 562–564. [Google Scholar] [CrossRef]
- Lindgren, A.; Doria, A.; Schelén, O. Probabilistic Routing in Intermittently Connected Networks. In Service Assurance with Partial and Intermittent Resources; Springer: Berlin/Heidelberg, Germany, 2004; pp. 239–254. [Google Scholar]
- Haoran, S.; Muqing, W.; Yanan, C. A Community-Based Opportunistic Routing Protocol in Delay Tolerant Networks. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018; pp. 296–300. [Google Scholar]
- Duong, D.V.A.; Kim, D.Y.; Yoon, S. TSIRP: A Temporal Social Interactions-Based Routing Protocol in Opportunistic Mobile Social Networks. IEEE Access 2021, 9, 72712–72729. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Qiao, C.; Koutsonikolas, D.; Challen, G. CRAWDAD Dataset Buffalo/Phonelab-Wifi (v. 2016-03-09). 2016. Available online: https://crawdad.org/buffalo/phonelab-wifi/20160309 (accessed on 24 August 2021).
- Ahmed, M.; Goyal, S.; Singh, S.; Gupta, J. An improved Spray and Wait routing protocol for Delay Tolerant Network. In Proceedings of the 2019 2nd IEEE Middle East and North Africa COMMunications Conference (MENACOMM), Manama, Bahrain, 19–21 November 2019; pp. 1–6. [Google Scholar]
- Abdajbar, A.N.; Mohamed, K.S.; Alias, M.Y. Link Budget Based Optimised Link State Routing Protocol in Flying Ad-hoc Networks. In Proceedings of the 2019 IEEE Conference on Sustainable Utilization and Development in Engineering and Technologies (CSUDET), Penang, Malaysia, 7–9 November 2019; pp. 261–264. [Google Scholar]
- Arnous, R.; El-kenawy, E.S.M.T.; Saber, M. A Proposed Routing Protocol for Mobile Ad Hoc Networks. Int. J. Comput. Appl. 2019, 975, 8887. [Google Scholar] [CrossRef]
- Wang, G.; Wang, J.; Wang, B. An adaptive spray and wait routing algorithm based on capability of node in DTN. J. Inf. Comput. Sci. 2014, 11, 1975–1982. [Google Scholar] [CrossRef]
- Lenando, H.; Alrfaay, M. Epsoc: Social-based epidemic-based routing protocol in opportunistic mobile social network. Mob. Inf. Syst. 2018, 2018, 6462826. [Google Scholar] [CrossRef] [Green Version]
- Raghav, N.; Kumar, A. Routing Strategy based on Centrality in Opportunistic Networks. In Proceedings of the 2019 6th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 13–15 March 2019; pp. 922–926. [Google Scholar]
- Yim, J.; Ahn, H.; Ko, Y.B. The betweenness centrality based geographic routing protocol for unmanned ground systems. In Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam, 4–6 January 2016; pp. 1–4. [Google Scholar]
- Bulut, E.; Szymanski, B.K. Exploiting Friendship Relations for Efficient Routing in Mobile Social Networks. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 2254–2265. [Google Scholar] [CrossRef]
- Hui, P.; Crowcroft, J.; Yoneki, E. BUBBLE Rap: Social-Based Forwarding in Delay-Tolerant Networks. IEEE Trans. Mob. Comput. 2011, 10, 1576–1589. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Zheng, L.; Yan, L.; Zhang, H. Probabilistic routing algorithm based on transmission capability of nodes in DTN. In Proceedings of the 2017 11th IEEE International Conference on Anti-counterfeiting, Security, and Identification, Xiamen, China, 27–29 October 2017; pp. 146–149. [Google Scholar]
- Vanitha, N. Binary Spray and wait routing Protocol with controlled replication for DTN based Multi-Layer UAV Ad-hoc network Assisting VANET. Turkish J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 276–2782. [Google Scholar]
- Kuronuma, Y.; Suzuki, H.; Koyama, A. An Adaptive DTN Routing Protocol Considering Replication State. In Proceedings of the 2017 31st International Conference on Advanced Information Networking and Applications Workshops, Taipei, Taiwan, 27–29 March 2017; pp. 421–426. [Google Scholar]
- Kaur, H.; Kaur, H. An enhanced spray-copy-wait DTN routing using optimized delivery predictability. In Computer Communication, Networking and Internet Security; Springer: Berlin, Germany, 2017; pp. 603–610. [Google Scholar]
- Bonino, D.; Alizo, M.T.D.; Pastrone, C.; Spirito, M. WasteApp: Smarter waste recycling for smart citizens. In Proceedings of the 2016 International Multidisciplinary Conference on Computer and Energy Science (SpliTech), Split, Croatia, 13–15 July 2016; pp. 1–6. [Google Scholar]
- Basta, N.; ElNahas, A.; Grossmann, H.P.; Abdennadher, S. A Framework for Social Tie Strength Inference in Vehicular Social Networks. In Proceedings of the 2019 Wireless Days (WD), Manchester, UK, 24–26 April 2019; pp. 1–8. [Google Scholar]
- Li, C.; Jiang, F.; Wang, X.; Shen, B. Optimal relay selection based on social threshold for D2D communications underlay cellular networks. In Proceedings of the 2016 8th International Conference on Wireless Communications Signal Processing (WCSP), Yangzhou, China, 13–15 October 2016; pp. 1–6. [Google Scholar]
- Moradi, S.; Mohasefi, J.B.; Mahdipour, E. MSN-CDF: New community detection framework to improve routing in mobile social networks. Int. J. Commun. Syst. 2021, 34, e4989. [Google Scholar] [CrossRef]
- Gagniuc, P.A. Markov Chains: From Theory to Implementation and Experimentation; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Keränen, A.; Ott, J.; Kärkkäinen, T. The ONE Simulator for DTN Protocol Evaluation. In Proceedings of the SIMUTools ’09: Proceedings of the 2nd International Conference on Simulation Tools and Techniques, Rome, Italy, 2–6 March 2009. [Google Scholar]
- Shi, J.; Meng, L.; Striegel, A.; Qiao, C.; Koutsonikolas, D.; Challen, G. A walk on the client side: Monitoring enterprise Wifi networks using smartphone channel scans. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| Input vector of user u in time slot h | |
| One-hot vector: the next time slot for prediction of the user’s location | |
| One-hot vector: the ID of mobile user u | |
| One-hot vector: the day of the week of time slot h | |
| One-hot vector: presents time slot h | |
| One-hot vector: the location of user u in time slot h | |
| Output vector |
| Notation | Meaning |
|---|---|
| The packet delivery predictability between node u and node v in time slot t | |
| The social strength between node u and node v | |
| The degree centrality of node u | |
| The forwarding token of node u for packet p | |
| The set of neighboring nodes of node u |
| Parameter | Value |
|---|---|
| Simulation duration | 9 h |
| Number of edge nodes | 5 |
| Number of sensors | 50 |
| Number of mobile users with movement history | 50 |
| Number of mobile users without movement history | 100 |
| Transmission rate | 2 Mbps |
| Packet generation interval | 25–30 s |
| Buffer size | 150 packets |
| Packet TTL | 4 h |
| Packet size | 500 bytes |
| Initial value of forwarding token (C) | 64 |
| Prediction Model | Time Slot | Time Slot | Time Slot | Time Slot | Average |
|---|---|---|---|---|---|
| The proposed HLP model | 0.6102 | 0.5907 | 0.5735 | 0.5555 | 0.5831 |
| The Markov model | 0.6030 | 0.5636 | 0.5338 | 0.5097 | 0.5535 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van Anh Duong, D.; Yoon, S. A Human Location Prediction-Based Routing Protocol in Mobile Crowdsensing-Based Urban Sensor Networks. Appl. Sci. 2022, 12, 3898. https://doi.org/10.3390/app12083898
Van Anh Duong D, Yoon S. A Human Location Prediction-Based Routing Protocol in Mobile Crowdsensing-Based Urban Sensor Networks. Applied Sciences. 2022; 12(8):3898. https://doi.org/10.3390/app12083898
Chicago/Turabian StyleVan Anh Duong, Dat, and Seokhoon Yoon. 2022. "A Human Location Prediction-Based Routing Protocol in Mobile Crowdsensing-Based Urban Sensor Networks" Applied Sciences 12, no. 8: 3898. https://doi.org/10.3390/app12083898
APA StyleVan Anh Duong, D., & Yoon, S. (2022). A Human Location Prediction-Based Routing Protocol in Mobile Crowdsensing-Based Urban Sensor Networks. Applied Sciences, 12(8), 3898. https://doi.org/10.3390/app12083898