
Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Primitive Data
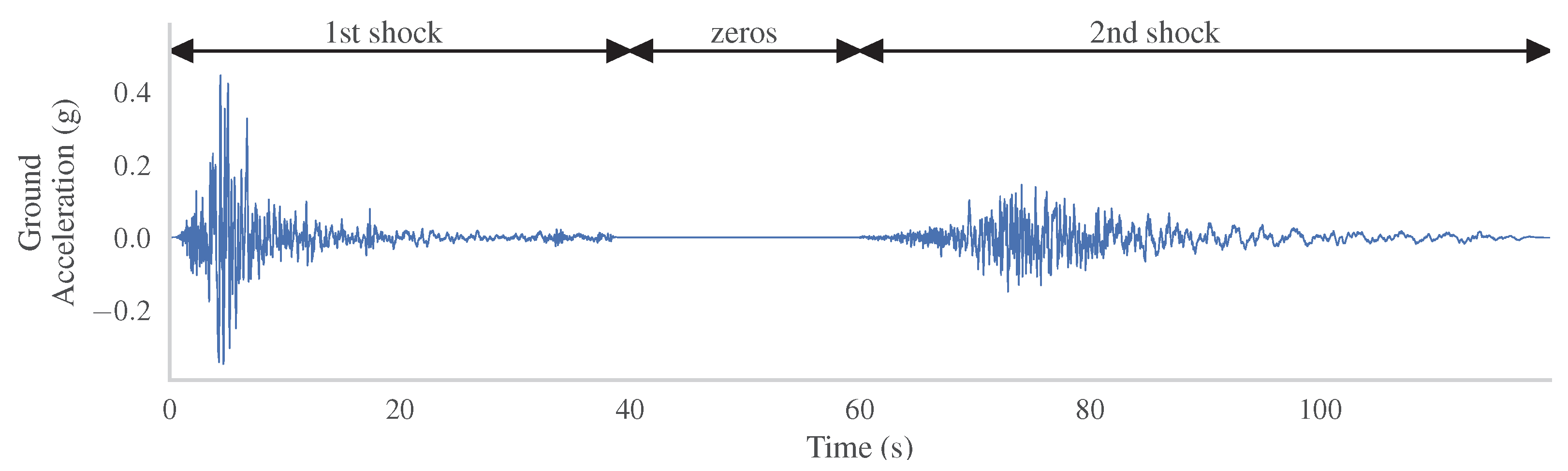
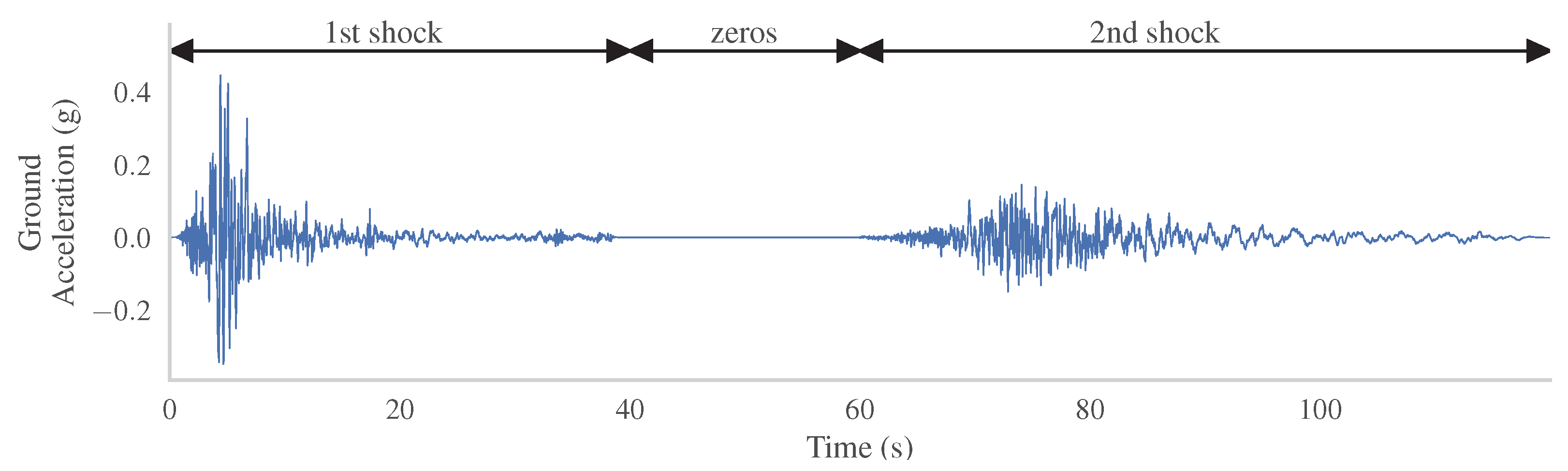
2.1. Ground Motion Records
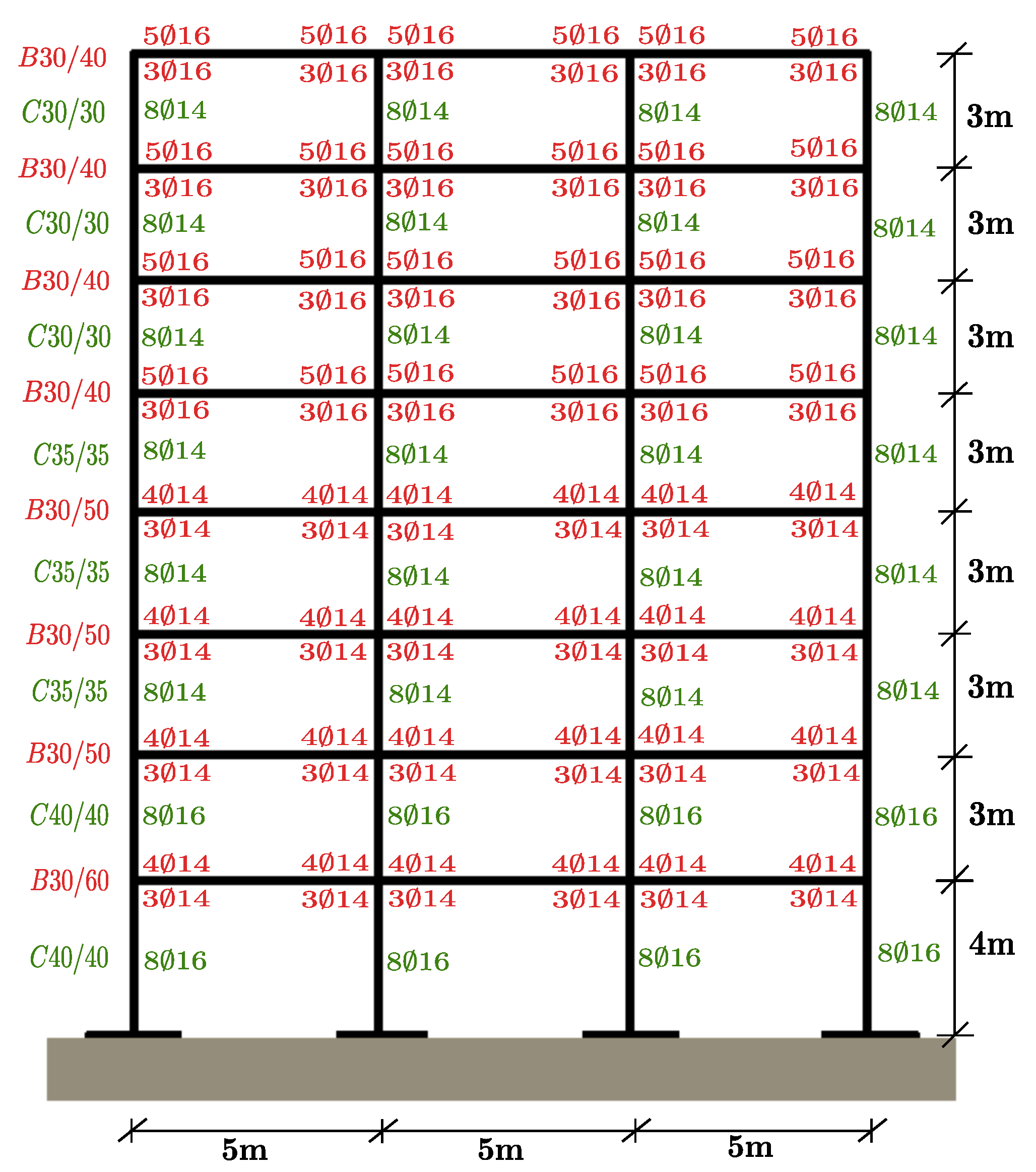
2.2. Reinforced Concrete Structure
3. Features, Targets and Dataset Generation
3.1. Ground Motion IMs
3.2. Damage Indicators
3.3. Dataset Configuration
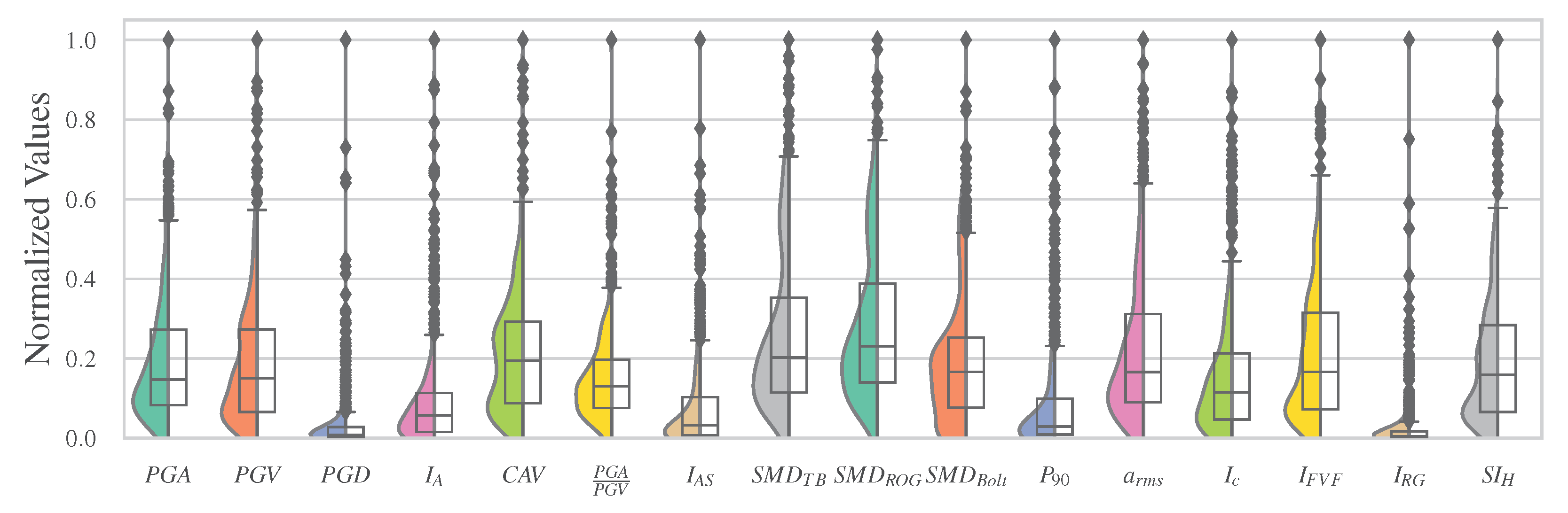
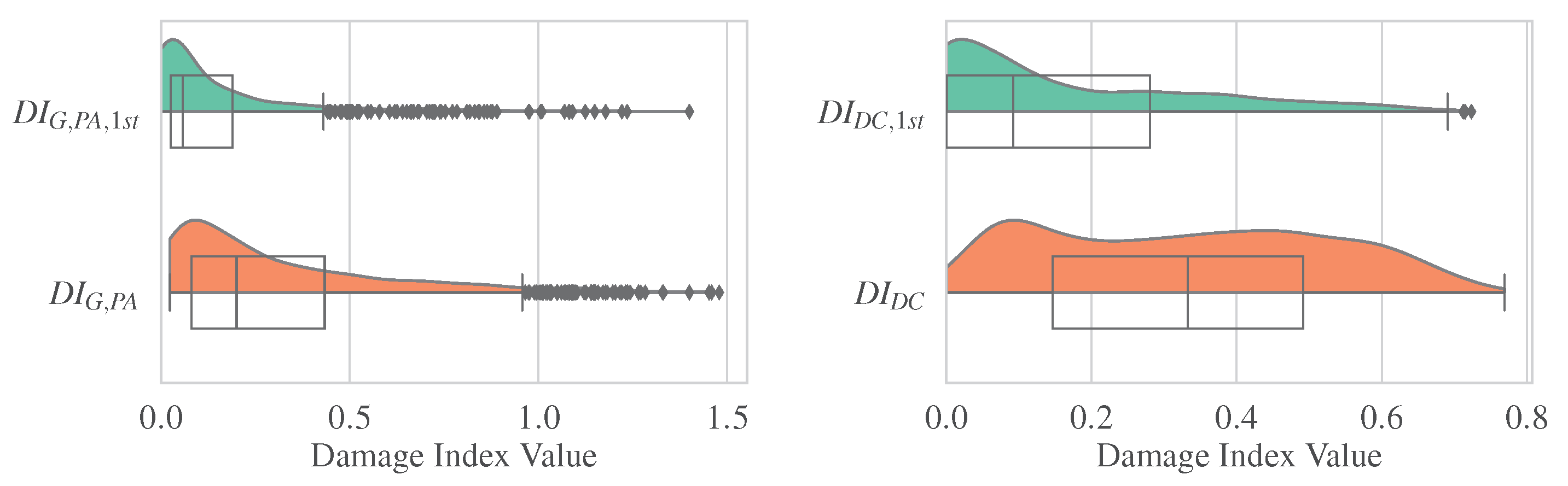
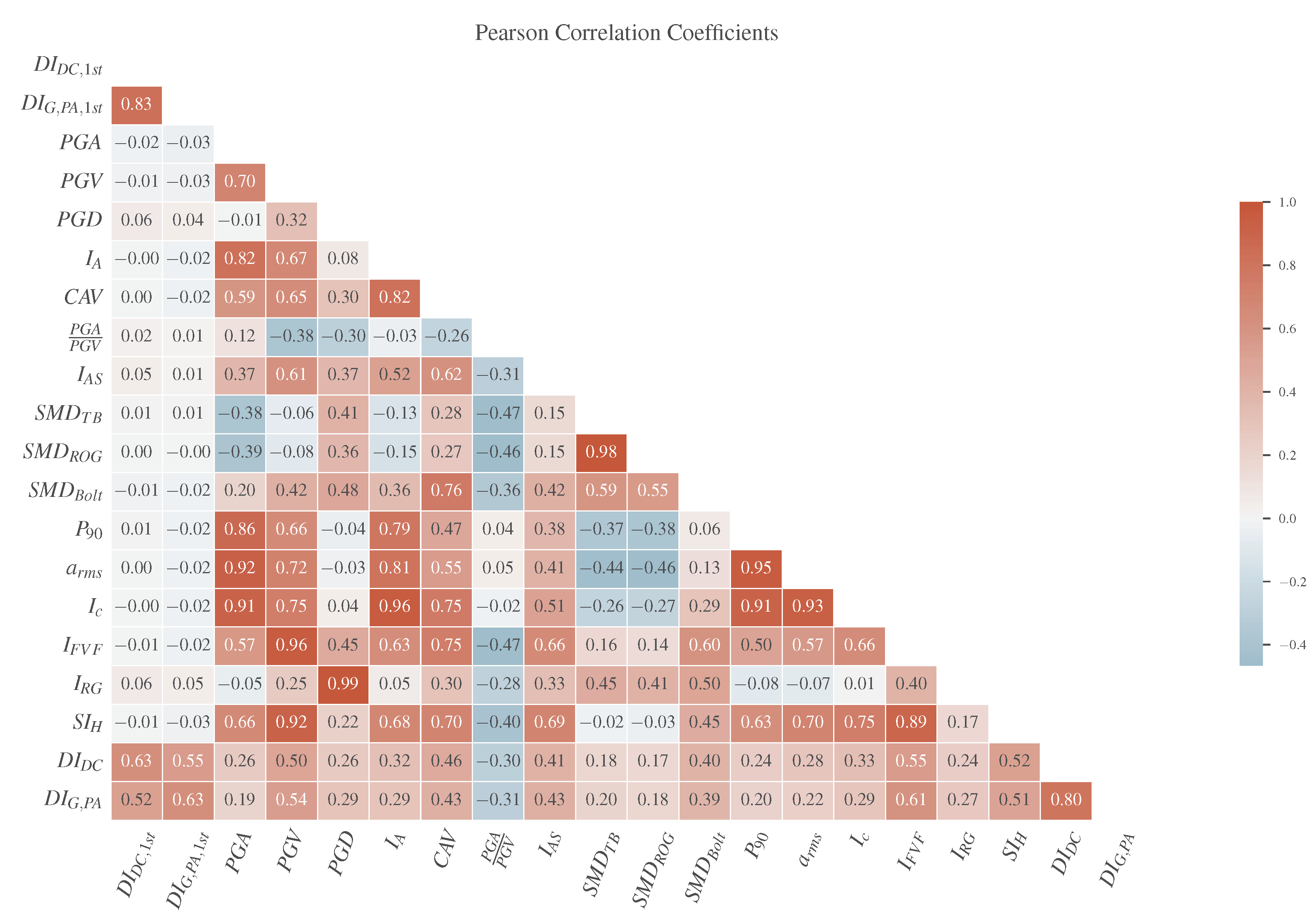
4. Exploratory Data Analysis (EDA)
5. Results
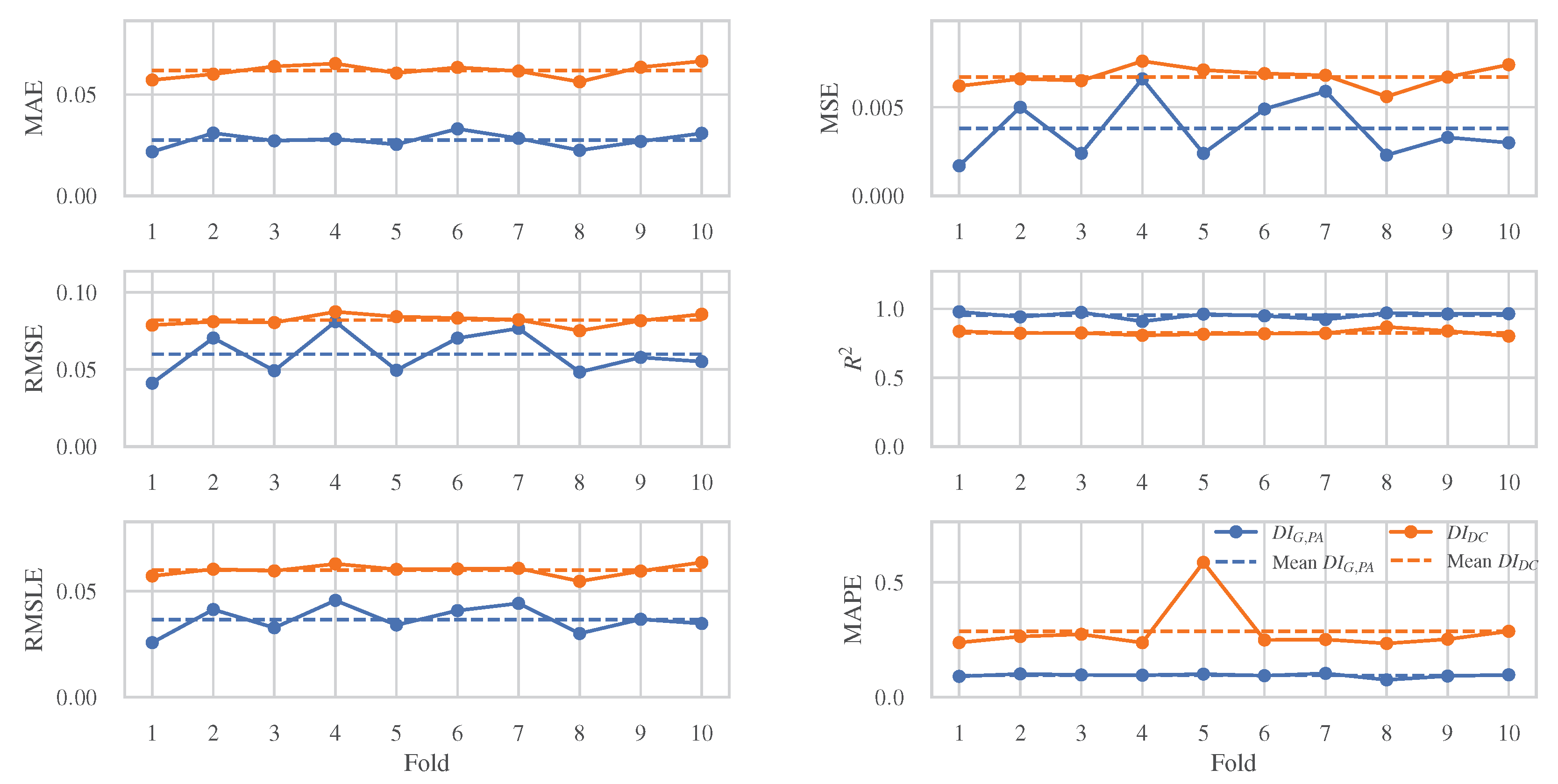
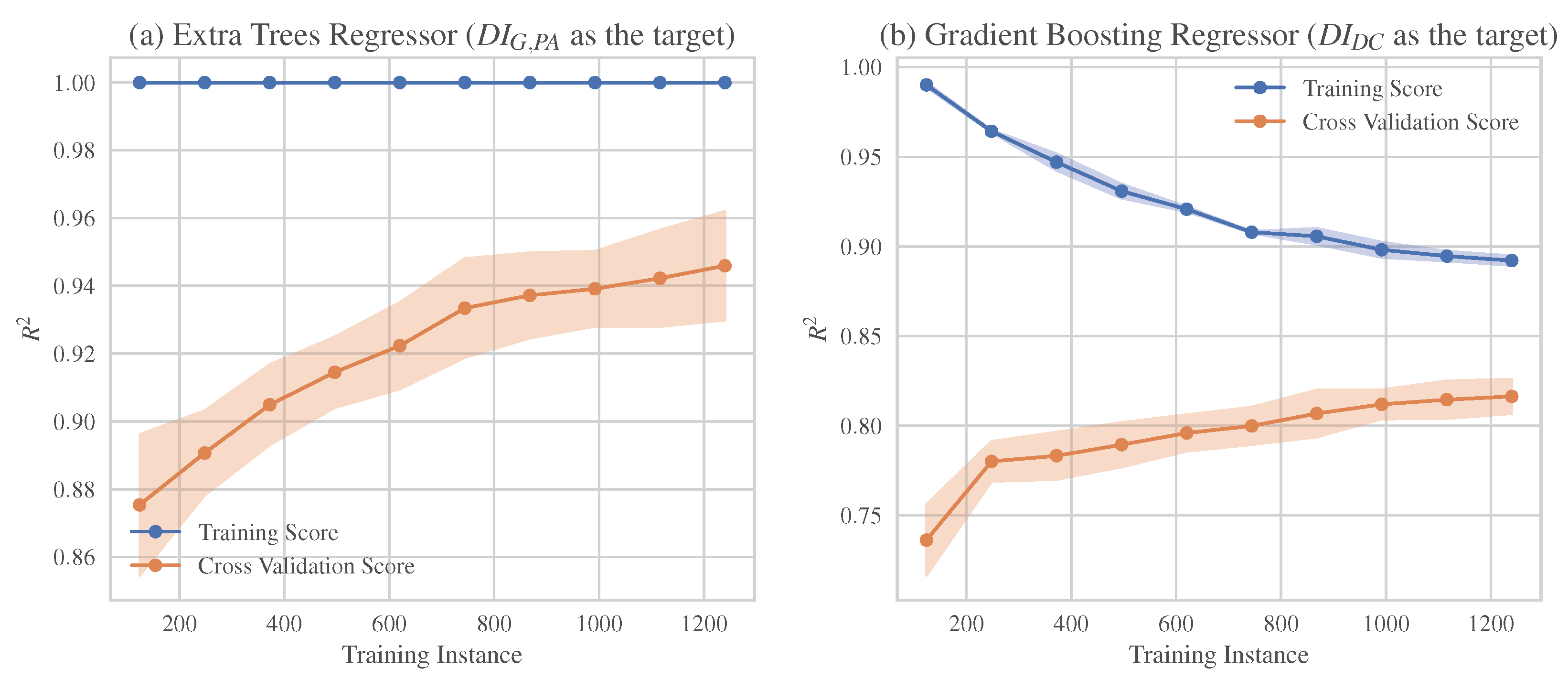
5.1. Comparative Performance Analysis of the Examined MLAs
- Mean absolute error (MAE) is a measure of errors between the estimated and the observed values, and it is given by the following expression:where is the predicted value, the real value of the ith observation and n is the total number of observations;
- Mean square error (MSE):
- Root-mean-squared error (RMSE) calculates the average error between the estimated values and the observed values:
- The coefficient of determination, , expresses the variation in the dependent variable that is predictable from the independent variables:where is the average of the observed values;
- Root-mean-squared-log-error (RMSLE) is an extension of MSE that is used mainly when the predicted values display high deviation:
- Mean absolute percentage error (MAPE) calculates the accuracy, as a ratio, and is defined by the following formulation:
5.2. Evaluation of the MLAs with the Higher Prediction Ability
5.3. Web-Application Development
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| MLA | Machine learning algorithm |
| SDOF | Single degree of freedom |
| RC | Reinforced concrete |
| IM | Intensity measure |
| ANN | Artificial neural network |
| LSTM | Long short term memory |
| CNN | Convolutional neural network |
| NLTHA | Nonlinear time history analysis |
| PGA | Peak ground acceleration |
| PGV | Peak ground velocity |
| PGD | Peak ground displacement |
| Arias intensity | |
| CAV | Cumulative absolute velocity |
| Seismic intensity after Araya and Saragoni | |
| Strong motion duration after Trifunac and Brady | |
| Strong motion duration after Reinoso, Ordaz and Guerrero | |
| Strong motion duration after Bolt | |
| Root-mean-squared of ground acceleration signal | |
| Characteristic intensity | |
| Potential damage measure after Fajfar, Vidic and Fischinger | |
| Intensity measure after Riddel and Garcia | |
| Pseudo-spectrum velocities | |
| Husid diagram | |
| Spectral intensity after Housner | |
| The overall Park and Ang damage index after the first seismic shock (input feature) | |
| The overall Park and Ang damage index after the second seismic shock (target) | |
| DiPasquale and Çakmak damage index after the first seismic shock (input feature) | |
| DiPasquale and Çakmak damage index after the second seismic shock (target) | |
| EDA | Exploratory data analysis |
| PPS | Predictive power score |
| ABR | AdaBoost regressor |
| BR | Bayesian ridge |
| DTR | Decision tree regressor |
| ETR | Extra trees regressor |
| GBR | Gradient boosting regressor |
| KNN | K nearest neighbors regressor |
| LGBM | Light gradient boosting machine |
| LR | Linear regressor |
| MLNN | Multi-layer feed-forward neural network |
| RFR | Random forest regressor |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| cm | s | s | s | cm | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 302.5 | 29.5 | 52.0 | 134.1 | 754.4 | 12.9 | 3.5 | 13.8 | 17.2 | 12.0 | 16.0 | 76.8 | 2301.9 | 53.4 | 143.2 | 91.8 | |
| 247.5 | 24.4 | 124.7 | 186.4 | 516.5 | 8.5 | 5.0 | 10.0 | 11.3 | 10.0 | 26.2 | 63.9 | 2455.5 | 42.1 | 398.7 | 72.8 | |
| min | 32.7 | 1.2 | 0.1 | 0.7 | 28.0 | 1.7 | 0.0 | 0.6 | 1.9 | 0.0 | 0.1 | 7.4 | 55.3 | 1.4 | 0.1 | 2.1 |
| max | 1465.2 | 132.8 | 1314.2 | 1332.4 | 3119.3 | 75.5 | 41.5 | 49.5 | 56.9 | 58.6 | 150.1 | 306.4 | 13,323.4 | 201.8 | 4625.5 | 387.1 |
| Region | 1st Shock | 2nd Shock | Station Code/Name | Component | PGA (g) | PGA (g) | ||
|---|---|---|---|---|---|---|---|---|
| Date | M | Date | M | |||||
| Ancona | 14-06-1972 | 4.2 | 21-06-1972 | 4.0 | ANP | N-S | 0.220 | 0.410 |
| Friuli | 11-09-1976 | 5.8 | 15-09-1976 | 6.1 | BUI | N-S | 0.233 | 0.110 |
| E-W | 0.108 | 0.093 | ||||||
| GMN | N-S | 0.328 | 0.324 | |||||
| E-W | 0.299 | 0.644 | ||||||
| Montenegro | 15-04-1979 | 6.9 | 15-04-1979 | 5.8 | PETO | E-W | 0.304 | 0.089 |
| 24-05-1979 | 6.2 | BAR | N-S | 0.371 | 0.201 | |||
| E-W | 0.360 | 0.267 | ||||||
| HRZ | N-S | 0.215 | 0.066 | |||||
| E-W | 0.254 | 0.076 | ||||||
| ULO | N-S | 0.282 | 0.033 | |||||
| E-W | 0.236 | 0.030 | ||||||
| Imperial Valley | 15-10-1979 | 6.5 | 15-10-1979 | 5.0 | Holtville Post Office | 315 | 0.221 | 0.254 |
| Mammoth Lakes | 25-05-1980 | 6.1 | 25-05-1980 | 5.7 | Convict Creek | 90 | 0.419 | 0.371 |
| Irpinia | 23-11-1980 | 6.9 | 24-11-1980 | 5.0 | BGI | N-S | 0.129 | 0.031 |
| E-W | 0.189 | 0.033 | ||||||
| STR | N-S | 0.224 | 0.018 | |||||
| E-W | 0.320 | 0.032 | ||||||
| Gulf of Corinth | 24-02-1981 | 6.6 | 25-02-1981 | 6.3 | KORA | Trans | 0.296 | 0.121 |
| Logn | 0.240 | 0.121 | ||||||
| Coalinga | 22-07-1983 | 5.8 | 25-07-1983 | 5.2 | Elm (Old CHP) | 90 | 0.519 | 0.677 |
| 0 | 0.341 | 0.481 | ||||||
| Kalamata | 13-09-1986 | 5.9 | 15-09-1986 | 4.8 | KAL1 | Trans | 0.269 | 0.140 |
| Logn | 0.232 | 0.237 | ||||||
| KALA | Trans | 0.296 | 0.152 | |||||
| Logn | 0.216 | 0.334 | ||||||
| Spitak | 07-12-1988 | 6.7 | 07-12-1988 | 5.9 | GUK | N-S | 0.181 | 0.144 |
| E-W | 0.182 | 0.099 | ||||||
| 08-01-1989 | 4.0 | 08-01-1989 | 4.1 | NAB | E-W | 0.206 | 0.217 | |
| Georgia | 03-05-1991 | 5.6 | 03-05-1991 | 5.2 | SAMB | N-S | 0.354 | 0.208 |
| E-W | 0.504 | 0.122 | ||||||
| Erzican | 13-03-1992 | 6.6 | 15-03-1992 | 5.9 | AI 178 ERC MET | N-S | 0.411 | 0.032 |
| E-W | 0.487 | 0.039 | ||||||
| Ilia | 26-03-1993 | 4.7 | 26-03-1993 | 4.9 | PYR1 | Logn | 0.109 | 0.100 |
| Northridge | 17-01-1994 | 6.7 | 17-01-1994 | 5.9 | Moorpark—Fire Station | 90 | 0.193 | 0.139 |
| 180 | 0.291 | 0.184 | ||||||
| 17-01-1994 | 5.2 | Pacoima Kagel Canyon | 360 | 0.432 | 0.053 | |||
| 20-03-1994 | 5.3 | Rinaldi Receiving Station | 228 | 0.874 | 0.529 | |||
| Sepulveda Hospital | 270 | 0.752 | 0.102 | |||||
| Sylmar-Olive Med | 90 | 0.605 | 0.181 | |||||
| Umbria Marche | 26-09-1997 | 5.7 | 26-09-1997 | 6.0 | CLF | N-S | 0.276 | 0.197 |
| E-W | 0.256 | 0.227 | ||||||
| NCR | N-S | 0.395 | 0.502 | |||||
| Kalamata | 13-10-1997 | 6.5 | 18-11-1997 | 6.4 | KRN1 | Trans | 0.119 | 0.071 |
| Logn | 0.118 | 0.092 | ||||||
| Bovec | 12-04-1998 | 5.7 | 31-08-1998 | 4.3 | FAGG | N-S | 0.024 | 0.023 |
| E-W | 0.023 | 0.026 | ||||||
| Azores Islands | 09-07-1998 | 6.2 | 11-07-1998 | 4.7 | HOR | N-S | 0.405 | 0.082 |
| E-W | 0.369 | 0.092 | ||||||
| Izmit | 17-08-1999 | 7.6 | 12-11-1999 | 7.3 | ARC | N-S | 0.210 | 0.007 |
| E-W | 0.132 | 0.007 | ||||||
| ATK | N-S | 0.102 | 0.016 | |||||
| E-W | 0.167 | 0.016 | ||||||
| DHM | N-S | 0.090 | 0.017 | |||||
| E-W | 0.084 | 0.017 | ||||||
| FAT | N-S | 0.181 | 0.034 | |||||
| E-W | 0.161 | 0.024 | ||||||
| KMP | N-S | 0.102 | 0.014 | |||||
| E-W | 0.127 | 0.017 | ||||||
| ZYT | N-S | 0.119 | 0.021 | |||||
| E-W | 0.109 | 0.029 | ||||||
| Athens | 07-09-1999 | 5.9 | 07-09-1999 | 4.3 | SPLB | Trans | 0.324 | 0.059 |
| Logn | 0.341 | 0.071 | ||||||
| Chi-Chi | 20-09-1999 | 7.6 | 20-09-1999 | 6.2 | TCU071 | N-S | 0.651 | 0.382 |
| E-W | 0.528 | 0.193 | ||||||
| TCU129 | N-S | 0.624 | 0.398 | |||||
| E-W | 1.005 | 0.947 | ||||||
| 25-09-1999 | 6.3 | TCU078 | N-S | 0.307 | 0.387 | |||
| E-W | 0.447 | 0.266 | ||||||
| TCU079 | N-S | 0.424 | 0.626 | |||||
| E-W | 0.592 | 0.776 | ||||||
| Duzce | 12-11-1999 | 7.3 | 12-11-1999 | 4.7 | AI 010 BOL | E-W | 0.820 | 0.060 |
| Bingöl | 01-05-2003 | 6.3 | 01-05-2003 | 3.5 | AI 049 BNG | N-S | 0.519 | 0.147 |
| E-W | 0.291 | 0.068 | ||||||
| L Aquila | 06-04-2009 | 6.1 | 07-04-2009 | 5.5 | AQK | N-S | 0.353 | 0.081 |
| E-W | 0.330 | 0.090 | ||||||
| AQV | N-S | 0.545 | 0.146 | |||||
| E-W | 0.657 | 0.129 | ||||||
| AVZ | N-S | 0.069 | 0.021 | |||||
| 09-04-2009 | 5.4 | AQA | N-S | 0.442 | 0.057 | |||
| Darfield | 03-09-2010 | 7.0 | 21-02-2011 | 6.2 | Botanical Gardens | S01W | 0.190 | 0.452 |
| N89W | 0.155 | 0.552 | ||||||
| Cashmere High School | S80E | 0.251 | 0.349 | |||||
| Cathedral College | N26W | 0.194 | 0.384 | |||||
| N64E | 0.233 | 0.478 | ||||||
| Christchurch Hospital | N01W | 0.209 | 0.346 | |||||
| S89W | 0.152 | 0.363 | ||||||
| Emilia | 20-05-2012 | 6.1 | 29-05-2012 | 6.0 | MRN | N-S | 0.263 | 0.294 |
| E-W | 0.262 | 0.222 | ||||||
| 03-06-2012 | 5.1 | 12-06-2012 | 4.9 | T0827 | N-S | 0.490 | 0.585 | |
| E-W | 0.263 | 0.234 | ||||||
| Central Italy | 24-08-2016 | 6.0 | 24-08-2016 | 5.4 | AQK | E-W | 0.050 | 0.010 |
| 26-08-2016 | 4.8 | AMT | N-S | 0.375 | 0.336 | |||
| E-W | 0.867 | 0.325 | ||||||
| 26-10-2016 | 5.4 | 26-10-2016 | 5.9 | CMI | N-S | 0.341 | 0.308 | |
| E-W | 0.720 | 0.651 | ||||||
| CNE | E-W | 0.556 | 0.537 | |||||
| 30-10-2016 | 6.5 | CIT | N-S | 0.052 | 0.213 | |||
| E-W | 0.092 | 0.325 | ||||||
| 26-10-2016 | 5.9 | 30-10-2016 | 6.5 | CLO | N-S | 0.193 | 0.582 | |
| E-W | 0.183 | 0.427 | ||||||
| CNE | N-S | 0.380 | 0.294 | |||||
| MMO | N-S | 0.168 | 0.188 | |||||
| E-W | 0.170 | 0.189 | ||||||
| NOR | E-W | 0.215 | 0.311 | |||||
| 30-10-2016 | 6.5 | 31-10-2016 | 4.2 | T1213 | N-S | 0.867 | 0.185 | |
| E-W | 0.794 | 0.212 | ||||||
| 18-01-2017 | 5.5 | 18-01-2017 | 5.4 | PCB | N-S | 0.586 | 0.561 | |
| E-W | 0.408 | 0.388 | ||||||
| Dodecanese Islands | 08-08-2019 | 4.8 | 30-10-2020 | 7.0 | GMLD | N-S | 0.450 | 0.899 |
| E-W | 0.673 | 0.763 | ||||||
Appendix B
References
- Papadopoulos, G.A.; Agalos, A.; Karavias, A.; Triantafyllou, I.; Parcharidis, I.; Lekkas, E. Seismic and Geodetic Imaging (DInSAR) Investigation of the March 2021 Strong Earthquake Sequence in Thessaly, Central Greece. Geosciences 2021, 11, 311. [Google Scholar] [CrossRef]
- Goda, K.; Taylor, C.A. Effects of aftershocks on peak ductility demand due to strong ground motion records from shallow crustal earthquakes. Earthq. Eng. Struct. Dyn. 2012, 41, 2311–2330. [Google Scholar] [CrossRef]
- Iervolino, I.; Giorgio, M.; Chioccarelli, E. Closed-form aftershock reliability of damage-cumulating elastic-perfectly-plastic systems. Earthq. Eng. Struct. Dyn. 2014, 43, 613–625. [Google Scholar] [CrossRef]
- Yu, X.H.; Li, S.; Lu, D.G.; Tao, J. Collapse capacity of inelastic single-degree-of-freedom systems subjected to mainshock-aftershock earthquake sequences. J. Earthq. Eng. 2020, 24, 803–826. [Google Scholar] [CrossRef]
- Ghosh, J.; Padgett, J.E.; Sánchez Silva, M. Seismic damage accumulation in highway bridges in earthquake-prone regions. Earthq. Spectra. 2015, 31, 115–135. [Google Scholar] [CrossRef] [Green Version]
- Ji, D.; Wen, W.; Zhai, C.; Katsanos, E.I. Maximum inelastic displacement of mainshock-damaged structures under succeeding aftershock. Soil Dyn. Earthq. Eng. 2020, 136, 106248. [Google Scholar] [CrossRef]
- Amadio, C.; Fragiacomo, M.; Rajgelj, S. The effects of repeated earthquake ground motions on the non-linear response of SDOF systems. Earthq. Eng. Struct. Dyn. 2003, 32, 291–308. [Google Scholar] [CrossRef]
- Hatzigeorgiou, G.D.; Beskos, D.E. Inelastic displacement ratios for SDOF structures subjected to repeated earthquakes. Eng. Struct. 2009, 31, 2744–2755. [Google Scholar] [CrossRef]
- Hatzigeorgiou, G.D.; Liolios, A.A. Nonlinear behaviour of RC frames under repeated strong ground motions. Soil Dyn. Earthq. Eng. 2010, 30, 1010–1025. [Google Scholar] [CrossRef]
- Hatzivassiliou, M.; Hatzigeorgiou, G.D. Seismic sequence effects on three-dimensional reinforced concrete buildings. Soil Dyn. Earthq. Eng. 2015, 72, 77–88. [Google Scholar] [CrossRef]
- Hosseinpour, F.; Abdelnaby, A. Effect of different aspects of multiple earthquakes on the nonlinear behavior of RC structures. Soil Dyn. Earthq. Eng. 2017, 92, 706–725. [Google Scholar] [CrossRef]
- Kavvadias, I.E.; Rovithis, P.Z.; Vasiliadis, L.K.; Elenas, A. Effect of the aftershock intensity characteristics on the seismic response of RC frame buildings. In Proceedings of the 16th European Conference on Earthquake Engineering, Thessaloniki, Greece, 18–21 June 2018. [Google Scholar]
- Zhou, Z.; Yu, X.; Lu, D. Identifying Optimal Intensity Measures for Predicting Damage Potential of Mainshock–Aftershock Sequences. Appl. Sci. 2020, 10, 6795. [Google Scholar] [CrossRef]
- Yu, X.; Zhou, Z.; Du, W.; Lu, D. Development of fragility surfaces for reinforced concrete buildings under mainshock-aftershock sequences. Earthq. Eng. Struct. Dyn. 2021, 50, 3981–4000. [Google Scholar] [CrossRef]
- Jeon, J.S.; DesRoches, R.; Lowes, L.N.; Brilakis, I. Framework of aftershock fragility assessment—Case studies: Older California reinforced concrete building frames. Earthq. Eng. Struct. Dyn. 2015, 44, 2617–2636. [Google Scholar] [CrossRef]
- Hosseinpour, F.; Abdelnaby, A. Fragility curves for RC frames under multiple earthquakes. Soil Dyn. Earthq. Eng. 2017, 98, 222–234. [Google Scholar] [CrossRef]
- Abdelnaby, A.E. Fragility curves for RC frames subjected to Tohoku mainshock-aftershocks sequences. J. Earthq. Eng. 2018, 22, 902–920. [Google Scholar] [CrossRef]
- Sun, H.; Burton, H.V.; Huang, H. Machine Learning Applications for Building Structural Design and Performance Assessment: State-of-the-Art Review. J. Build. Eng. 2020, 33, 101816. [Google Scholar] [CrossRef]
- Xie, Y.; Ebad Sichani, M.; Padgett, J.E.; DesRoches, R. The promise of implementing machine learning in earthquake engineering: A state-of-the-art review. Earthq. Spectra 2020, 36, 1769–1801. [Google Scholar] [CrossRef]
- Harirchian, E.; Hosseini, S.E.A.; Jadhav, K.; Kumari, V.; Rasulzade, S.; Işık, E.; Wasif, M.; Lahmer, T. A Review on Application of Soft Computing Techniques for the Rapid Visual Safety Evaluation and Damage Classification of Existing Buildings. J. Build. Eng. 2021, 43, 102536. [Google Scholar] [CrossRef]
- De Lautour, O.R.; Omenzetter, P. Prediction of seismic-induced structural damage using artificial neural networks. Eng. Struct. 2009, 31, 600–606. [Google Scholar] [CrossRef] [Green Version]
- Alvanitopoulos, P.; Andreadis, I.; Elenas, A. Neuro–fuzzy techniques for the classification of earthquake damages in buildings. Measurement 2010, 43, 797–809. [Google Scholar] [CrossRef]
- Morfidis, K.; Kostinakis, K. Seismic parameters’ combinations for the optimum prediction of the damage state of R/C buildings using neural networks. Adv. Eng. Softw. 2017, 106, 1–16. [Google Scholar] [CrossRef]
- Kostinakis, K.; Morfidis, K. Application of Artificial Neural Networks for the Assessment of the Seismic Damage of Buildings with Irregular Infills’ Distribution. In Seismic Behaviour and Design of Irregular and Complex Civil Structures III; Springer: Berlin/Heidelberg, Germany, 2020; pp. 291–306. [Google Scholar] [CrossRef]
- González, J.; Yu, W.; Telesca, L. Earthquake Magnitude Prediction Using Recurrent Neural Networks. Proceedings 2019, 24, 22. [Google Scholar]
- Mangalathu, S.; Burton, H.V. Deep learning-based classification of earthquake-impacted buildings using textual damage descriptions. Int. J. Disaster Risk Reduct. 2019, 36, 101111. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.; Chen, S.; Zheng, J.; Büyüköztürk, O.; Sun, H. Deep long short-term memory networks for nonlinear structural seismic response prediction. Comput. Struct. 2019, 220, 55–68. [Google Scholar] [CrossRef]
- Li, J.; He, Z.; Zhao, X. A data-driven building’s seismic response estimation method using a deep convolutional neural network. IEEE Access 2021, 9, 50061–50077. [Google Scholar] [CrossRef]
- Oh, B.K.; Park, Y.; Park, H.S. Seismic response prediction method for building structures using convolutional neural network. Struct. Control Health Monit. 2020, 27, e2519. [Google Scholar] [CrossRef]
- Thaler, D.; Stoffel, M.; Markert, B.; Bamer, F. Machine-learning-enhanced tail end prediction of structural response statistics in earthquake engineering. Earthq. Eng. Struct. Dyn. 2021, 50, 2098–2114. [Google Scholar] [CrossRef]
- Vrochidou, E.; Bizergianidou, V.; Andreadis, I.; Elenas, A. Assessment and Localization of Structural Damage in r/c Structures through Intelligent Seismic Signal Processing. Appl. Artif. Intell. 2021, 35, 670–695. [Google Scholar] [CrossRef]
- Lazaridis, P.C.; Kavvadias, I.E.; Demertzis, K.; Iliadis, L.; Papaleonidas, A.; Vasiliadis, L.K.; Elenas, A. Structural Damage Prediction Under Seismic Sequence Using Neural Networks. In Proceedings of the 8th ECCOMAS Thematic Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Athens, Greece, 28–30 June 2021. [Google Scholar] [CrossRef]
- Li, Y.; Song, R.; Van De Lindt, J.W. Collapse fragility of steel structures subjected to earthquake mainshock-aftershock sequences. J. Struct. Eng. 2014, 140, 04014095. [Google Scholar] [CrossRef]
- Luzi, L.; Lanzano, G.; Felicetta, C.; D’Amico, M.; Russo, E.; Sgobba, S.; Pacor, F.; ORFEUS Working Group 5. Engineering Strong Motion Database (ESM) (Version 2.0); Istituto Nazionale di Geofisica e Vulcanologia (INGV): Rome, Italy, 2020. [CrossRef]
- Ancheta, T.D.; Darragh, R.B.; Stewart, J.P.; Seyhan, E.; Silva, W.J.; Chiou, B.S.; Wooddell, K.E.; Graves, R.W.; Kottke, A.R.; Boore, D.M.; et al. Peer NGA-West2 Database; Technical Report; Pacific Earthquake Engineering Research Center: Berkeley, CA, USA, 2013. [Google Scholar]
- Valles, R.; Reinhorn, A.M.; Kunnath, S.K.; Li, C.; Madan, A. IDARC2D Version 4.0: A Computer Program for the Inelastic Damage Analysis of Buildings; Technical Report; US National Center for Earthquake Engineering Research (NCEER); University at Buffalo 212 Ketter Hall Buffalo: Buffalo, NY, USA, 1996. [Google Scholar]
- Park, Y.J.; Reinhorn, A.M.; Kunnath, S.K. IDARC: Inelastic Damage Analysis of Reinforced Concrete Frame–Shear–Wall Structures; National Center for Earthquake Engineering Research: Buffalo, NY, USA, 1987. [Google Scholar]
- CEN. EN 1992-1-1 Eurocode 2: Design of Concrete Structures—Part 1-1: General Rules and Rules for Buildings; European Committee for Standardization: Brussels, Belgium, 2005. [Google Scholar]
- Eaton, J.W. GNU Octave and reproducible research. J. Process Control. 2012, 22, 1433–1438. [Google Scholar] [CrossRef]
- Eaton, J.W.; Bateman, D.; Hauberg, S.; Wehbring, R. GNU Octave Version 6.1.0 Manual: A High-Level Interactive Language for Numerical Computations. 2020. Available online: https://octave.org/doc/octave-6.1.0.pdf (accessed on 11 March 2022).
- Kramer, S.L. Geotechnical Earthquake Engineering; Prentice Hall: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Arias, A. A Measure of Earthquake Intensity. Seismic Design for Nuclear Power Plants; Massachusetts Institute of Technology: Cambridge, MA, USA, 1970. [Google Scholar]
- EPRI. Criterion for Determining Exceedance of the Operating Basis Earthquake; Rapport NP-5930 2848-16; Electric Power Research Institute USA: Washington, DC, USA, 1988. [Google Scholar]
- Araya, R.; Saragoni, G.R. Earthquake accelerogram destructiveness potential factor. In Proceedings of the 8th World Conference on Earthquake Engineeringq, San Francisco, CA, USA, 21–28 July 1985; Volume 11, pp. 835–843. [Google Scholar]
- Trifunac, M.D.; Brady, A.G. A study on the duration of strong earthquake ground motion. Bull. Seismol. Soc. Am. 1975, 65, 581–626. [Google Scholar]
- Reinoso, E.; Ordaz, M.; Guerrero, R. Influence of strong ground-motion duration in seismic design of structures. In Proceedings of the 12th World Conference on Earthquake Engineering, Auckland, New Zealand, 30 January–4 February 2000; Volume 1151. [Google Scholar]
- Husid, R. Características de terremotos. Análisis general. Rev. IDIEM 1969, 8, ág-21. [Google Scholar]
- Bolt, B.A. Duration of strong ground motion. In Proceedings of the 5th World Conference on Earthquake Engineering, lRome, Italy, 25–29 June 1973; Volume 292, pp. 25–29. [Google Scholar]
- Fajfar, P.; Vidic, T.; Fischinger, M. A measure of earthquake motion capacity to damage medium-period structures. Soil Dyn. Earthq. Eng. 1990, 9, 236–242. [Google Scholar] [CrossRef]
- Riddell, R.; Garcia, J.E. Hysteretic energy spectrum and damage control. Earthq. Eng. Struct. Dyn. 2001, 30, 1791–1816. [Google Scholar] [CrossRef]
- Housner, G.W. Spectrum intensities of strong-motion earthquakes. In Proceedings of the Symposium on Earthquake and Blast Effects on Structures, Los Angeles, CA, USA, 25–29 June 1952. [Google Scholar]
- Masi, A.; Vona, M.; Mucciarelli, M. Selection of Natural and Synthetic Accelerograms for Seismic Vulnerability Studies on Reinforced Concrete Frames. J. Struct. Eng. 2011, 137, 367–378. [Google Scholar] [CrossRef]
- Lazaridis, P.C.; Kavvadias, I.E.; Vasiliadis, L.K. Correlation between Seismic Parameters and Damage Indices of Reinforced Concrete Structures. In Proceedings of the 4th Panhellenic Conference on Earthquake Engineering and Engineering Seismology, Athens, Greece, 5–7 September 2019. [Google Scholar]
- Papazafeiropoulos, G.; Plevris, V. OpenSeismoMatlab: A new open-source software for strong ground motion data processing. Heliyon 2018, 4, e00784. [Google Scholar] [CrossRef] [Green Version]
- Rossum, G. Python Reference Manual; National Research Institute for Mathematics and Computer Science, Netherlands Organisation for Scientific Research, Amsterdam Science Park: Amsterdam, The Netherlands, 1995. [Google Scholar]
- DiPasquale, E.; Çakmak, A. Detection of seismic structural damage using parameter-based global damage indices. Probabilistic Eng. Mech. 1990, 5, 60–65. [Google Scholar] [CrossRef]
- Park, Y.J.; Ang, A.H.S. Mechanistic seismic damage model for reinforced concrete. J. Struct. Eng. 1985, 111, 722–739. [Google Scholar] [CrossRef]
- Kunnath, S.K.; Reinhorn, A.M.; Lobo, R. IDARC Version 3.0: A Program for the Inelastic Damage Analysis of Reinforced Concrete Structures; Technical Report; US National Center for Earthquake Engineering Research (NCEER), University at Buffalo 212 Ketter Hall Buffalo: Buffalo, NY, USA, 1992. [Google Scholar]
- Park, Y.J.; Ang, A.H.; Wen, Y.K. Damage-limiting aseismic design of buildings. Earthq. Spectra 1987, 3, 1–26. [Google Scholar] [CrossRef]
- Katsanos, E.; Sextos, A. Inelastic spectra to predict period elongation of structures under earthquake loading. Earthq. Eng. Struct. Dyn. 2015, 44, 1765–1782. [Google Scholar] [CrossRef]
- Cook, R.D. Detection of influential observation in linear regression. Technometrics 1977, 19, 15–18. [Google Scholar] [CrossRef]
- Cook, R.D. Influential observations in linear regression. J. Am. Stat. Assoc. 1979, 74, 169–174. [Google Scholar] [CrossRef]
- Gibbons, J.D.; Chakraborti, S. Nonparametric Statistical Inference; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar] [CrossRef]
- Wetschoreck, F.; Krabel, T.; Krishnamurthy, S. 8080labs/Ppscore: Zenodo Release. 2020. Available online: https://zenodo.org/record/4091345#.Yk0mjTURVPY (accessed on 17 December 2021).
- Drucker, H. Improving regressors using boosting techniques. In Proceedings of the Fourteenth International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; Volume 97, pp. 107–115. [Google Scholar]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev./Rev. Int. Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Glantz, S.A.; Slinker, B.K. Primer of Applied Regression & Analysis of Variance; McGraw-Hill, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Minsky, M.; Papert, S.A. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bengfort, B.; Bilbro, R. Yellowbrick: Visualizing the Scikit-Learn Model Selection Process. J. Open Source Softw. 2019, 4, 1075. [Google Scholar] [CrossRef]
- Bengfort, B.; Bilbro, R.; Johnson, P.; Billet, P.; Roman, P.; Deziel, P.; McIntyre, K.; Gray, L.; Ojeda, A.; Schmierer, E.; et al. Yellowbrick v1.3. 2021. Available online: https://zenodo.org/record/4525724#.Yk0p5DURVPY (accessed on 10 January 2022).
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Teixeira, T.; Treuille, A.; Conkling, T.; Kantuni, H.; McGrady, K.; Jonathan, R.; Rosso, E.; Zwitch, R.; Donato, V.; Chen, A.; et al. Streamlit. 0.69. 0. Github. 2020. Available online: https://github.com/streamlit/streamlit (accessed on 7 February 2022).

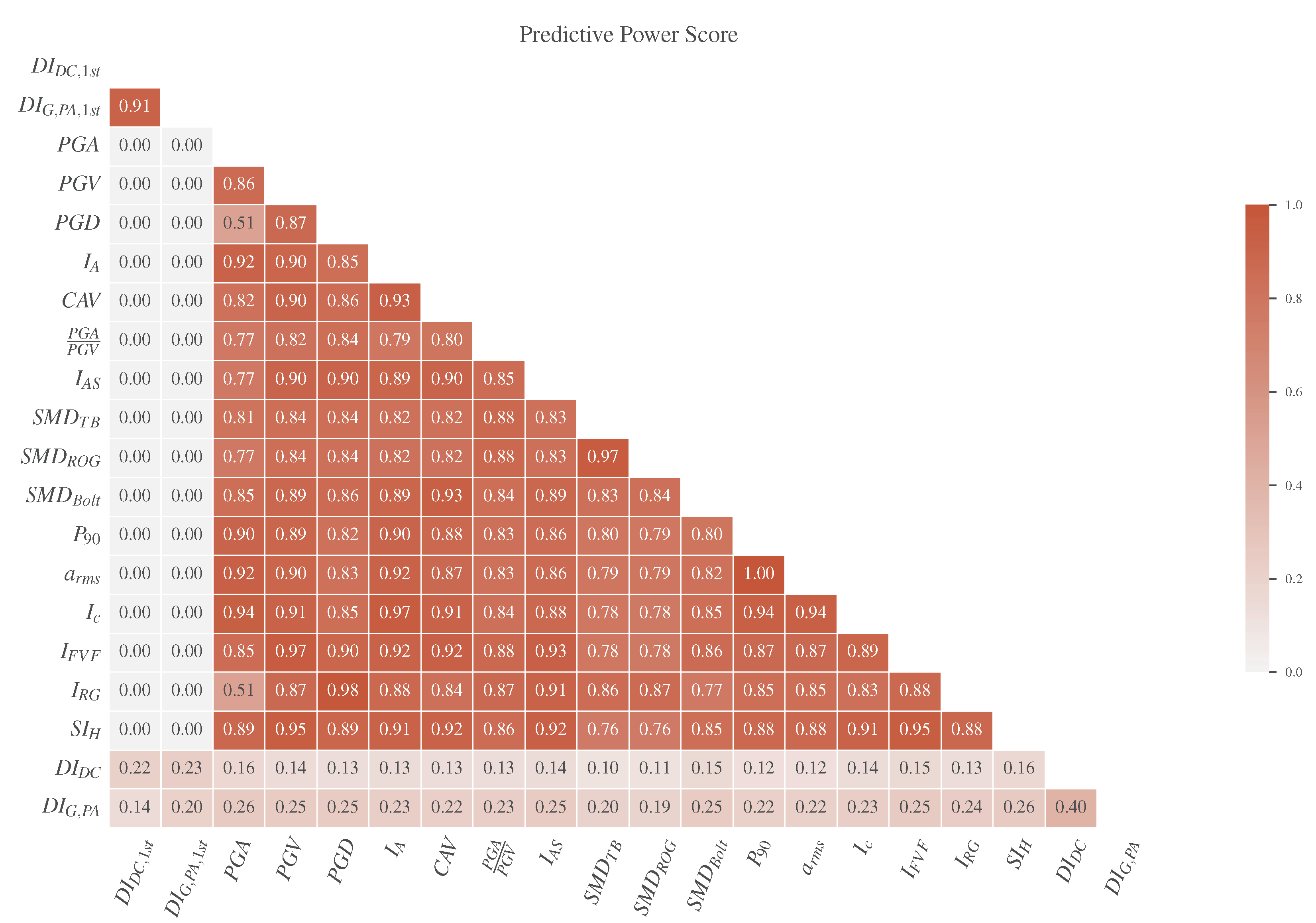


| Num | Name | Expression | Ref. | Num | Name | Expression | Ref. |
|---|---|---|---|---|---|---|---|
| 1 | [41] | 9 | [46] | ||||
| 2 | [41] | 10 | [48] | ||||
| 3 | [41] | 11 | [41] | ||||
| 4 | [42] | 12 | [41] | ||||
| 5 | [41] | 13 | [41] | ||||
| 6 | [41] | 14 | [49] | ||||
| 7 | [44] | 15 | [50] | ||||
| 8 | [45] | 16 | [51] |
| cm | s | s | s | cm | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 299.6 | 29.1 | 49.4 | 131.7 | 738.7 | 13.0 | 3.4 | 13.5 | 16.9 | 11.6 | 15.8 | 76.4 | 2267.1 | 52.4 | 135.1 | 90.4 | |
| 244.1 | 24.2 | 120.6 | 186.2 | 527.0 | 8.6 | 5.0 | 10.0 | 11.3 | 10.0 | 25.9 | 63.5 | 2430.7 | 42.3 | 383.3 | 73.3 | |
| min | 7.4 | 0.8 | 0.0 | 0.2 | 28.0 | 1.7 | 0.0 | 0.5 | 0.7 | 0.0 | 0.0 | 1.8 | 12.5 | 1.4 | 0.1 | 1.5 |
| max | 1465.2 | 148.2 | 1314.2 | 1332.4 | 3354.8 | 75.5 | 41.5 | 49.5 | 56.9 | 58.6 | 170.7 | 326.2 | 13,323.4 | 243.0 | 4625.5 | 457.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lazaridis, P.C.; Kavvadias, I.E.; Demertzis, K.; Iliadis, L.; Vasiliadis, L.K. Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms. Appl. Sci. 2022, 12, 3845. https://doi.org/10.3390/app12083845
Lazaridis PC, Kavvadias IE, Demertzis K, Iliadis L, Vasiliadis LK. Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms. Applied Sciences. 2022; 12(8):3845. https://doi.org/10.3390/app12083845
Chicago/Turabian StyleLazaridis, Petros C., Ioannis E. Kavvadias, Konstantinos Demertzis, Lazaros Iliadis, and Lazaros K. Vasiliadis. 2022. "Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms" Applied Sciences 12, no. 8: 3845. https://doi.org/10.3390/app12083845
APA StyleLazaridis, P. C., Kavvadias, I. E., Demertzis, K., Iliadis, L., & Vasiliadis, L. K. (2022). Structural Damage Prediction of a Reinforced Concrete Frame under Single and Multiple Seismic Events Using Machine Learning Algorithms. Applied Sciences, 12(8), 3845. https://doi.org/10.3390/app12083845