
Unsupervised Driving Situation Detection in Latent Space for Autonomous Cars

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
3. Preliminaries
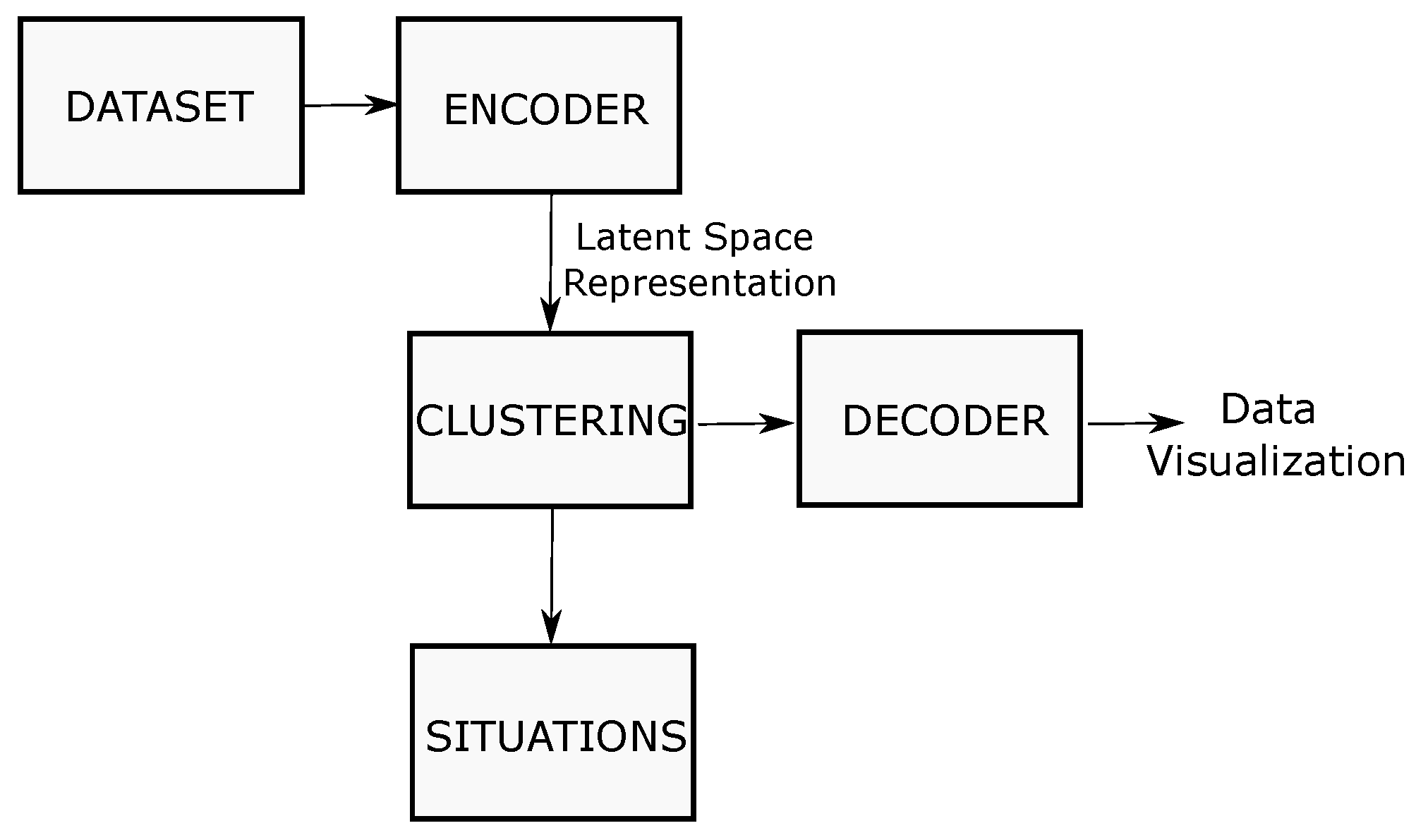
4. Solution Proposed
4.1. Driving Situations
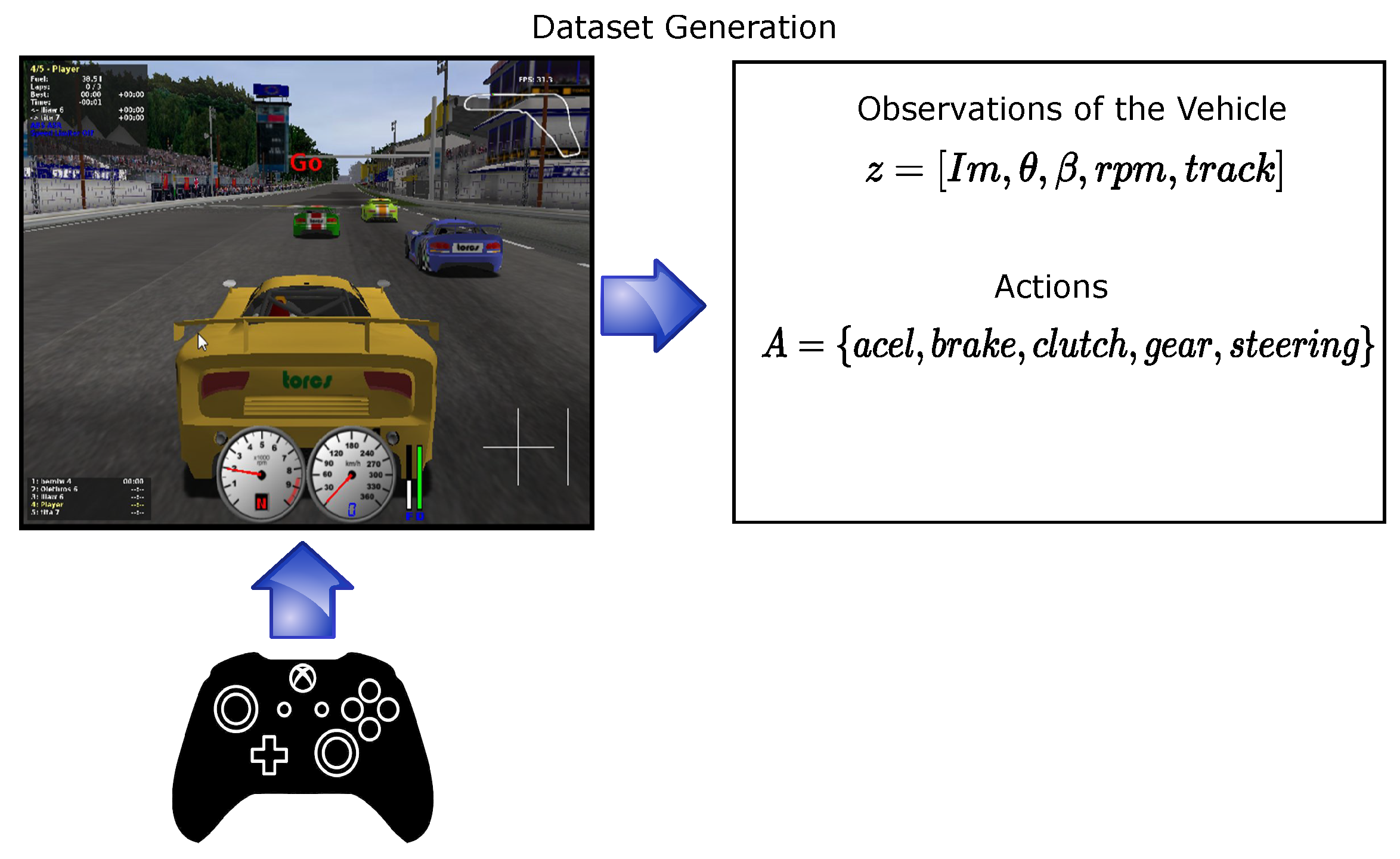
4.1.1. Dataset Collection
4.1.2. Encoding
4.1.3. Clustering
4.1.4. Defining the Number of Driving Situations
4.1.5. Decoder
4.2. Driving Policy Creation
5. Experiments
5.1. Data Clustering
Visualization of the Data Using t-SNE and the Decoder Output
5.2. Global Driving Policy vs. Driving Situation Policies
Policies Training
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van, N.D.; Sualeh, M.; Kim, D.; Kim, G.W. A hierarchical control system for autonomous driving towards urban challenges. Appl. Sci. 2020, 10, 3543. [Google Scholar] [CrossRef]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixao, T.M.; Mutz, F.; et al. Self-driving cars: A survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Buehler, M.; Iagnemma, K.; Singh, S. The DARPA Urban Challenge: Autonomous Vehicles in City Traffic; Springer: Berlin/Heidelberg, Germany, 2009; Volume 56. [Google Scholar]
- Jo, K.; Kim, J.; Kim, D.; Jang, C.; Sunwoo, M. Development of autonomous car—Part II: A case study on the implementation of an autonomous driving system based on distributed architecture. IEEE Trans. Ind. Electron. 2015, 62, 5119–5132. [Google Scholar] [CrossRef]
- Galceran, E.; Cunningham, A.G.; Eustice, R.M.; Olson, E. Multipolicy decision-making for autonomous driving via changepoint-based behavior prediction: Theory and experiment. Auton. Robot. 2017, 41, 1367–1382. [Google Scholar] [CrossRef]
- Somani, A.; Ye, N.; Hsu, D.; Lee, W.S. DESPOT: Online POMDP planning with regularization. Adv. Neural Inf. Process. Syst. 2013, 26, 1772–1780. [Google Scholar]
- Bandyopadhyay, T.; Won, K.S.; Frazzoli, E.; Hsu, D.; Lee, W.S.; Rus, D. Intention-aware motion planning. In Algorithmic Foundations of Robotics X; Springer: Berlin/Heidelberg, Germany, 2013; pp. 475–491. [Google Scholar]
- Brechtel, S.; Gindele, T.; Dillmann, R. Probabilistic decision-making under uncertainty for autonomous driving using continuous POMDPs. In Proceedings of the 17th international IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 392–399. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Rodríguez-Hernandez, E.; Vasquez-Gomez, J.I.; Herrera-Lozada, J.C. Flying through gates using a behavioral cloning approach. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 1353–1358. [Google Scholar]
- Farag, W.; Saleh, Z. Behavior cloning for autonomous driving using convolutional neural networks. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhier, Bahrain, 18–20 November 2018; pp. 1–7. [Google Scholar]
- Ly, A.O.; Akhloufi, M. Learning to drive by imitation: An overview of deep behavior cloning methods. IEEE Trans. Intell. Veh. 2020, 6, 195–209. [Google Scholar] [CrossRef]
- Sharma, S.; Tewolde, G.; Kwon, J. Behavioral cloning for lateral motion control of autonomous vehicles using deep learning. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 0228–0233. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. Real-time growth stage detection model for high degree of occultation using DenseNet-fused YOLOv4. Comput. Electron. Agric. 2022, 193, 106694. [Google Scholar] [CrossRef]
- Okumura, B.; James, M.R.; Kanzawa, Y.; Derry, M.; Sakai, K.; Nishi, T.; Prokhorov, D. Challenges in perception and decision making for intelligent automotive vehicles: A case study. IEEE Trans. Intell. Veh. 2016, 1, 20–32. [Google Scholar] [CrossRef]
- Mihály, A.; Farkas, Z.; Gáspár, P. Multicriteria Autonomous Vehicle Control at Non-Signalized Intersections. Appl. Sci. 2020, 10, 7161. [Google Scholar] [CrossRef]
- Aeberhard, M.; Rauch, S.; Bahram, M.; Tanzmeister, G.; Thomas, J.; Pilat, Y.; Homm, F.; Huber, W.; Kaempchen, N. Experience, results and lessons learned from automated driving on Germany’s highways. IEEE Intell. Transp. Syst. Mag. 2015, 7, 42–57. [Google Scholar] [CrossRef]
- Burgard, W.; Fox, D.; Thrun, S. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005; Volume 1. [Google Scholar]
- Ulbrich, S.; Maurer, M. Probabilistic online POMDP decision making for lane changes in fully automated driving. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 2063–2067. [Google Scholar]
- Zhou, Z.; Zhong, Y.; Liu, X.; Li, Q.; Han, S. DC-MMD-GAN: A New Maximum Mean Discrepancy Generative Adversarial Network Using Divide and Conquer. Appl. Sci. 2020, 10, 6405. [Google Scholar] [CrossRef]
- Ratner, E.; Hadfield-Menell, D.; Dragan, A.D. Simplifying reward design through divide-and-conquer. arXiv 2018, arXiv:1806.02501. [Google Scholar]
- Wang, L.; Zhang, J.; Wang, O.; Lin, Z.; Lu, H. Sdc-depth: Semantic divide-and-conquer network for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 541–550. [Google Scholar]
- Kim, J.; Moon, J.; Ryu, J.; Lee, G. Bioinspired Divide-and-Conquer Design Methodology for a Multifunctional Contour of a Curved Lever. Appl. Sci. 2021, 11, 6015. [Google Scholar] [CrossRef]
- Singh, S.; Jaakkola, T.; Littman, M.L.; Szepesvári, C. Convergence results for single-step on-policy reinforcement-learning algorithms. Mach. Learn. 2000, 38, 287–308. [Google Scholar] [CrossRef] [Green Version]
- Munos, R.; Stepleton, T.; Harutyunyan, A.; Bellemare, M.G. Safe and efficient off-policy reinforcement learning. arXiv 2016, arXiv:1606.02647. [Google Scholar]
- Satopaa, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “kneedle” in a haystack: Detecting knee points in system behavior. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011; pp. 166–171. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Wymann, B.; Espié, E.; Guionneau, C.; Dimitrakakis, C.; Coulom, R.; Sumner, A. Torcs, the Open Racing Car Simulator. Software. 2000. Available online: http://torcs.sourceforge.net (accessed on 4 February 2022).
- Koubâa, A. Robot Operating System (ROS); Springer: Berlin/Heidelberg, Germany, 2017; Volume 1. [Google Scholar]
- Xie, P.; Deng, Y.; Zhou, Y.; Kumar, A.; Yu, Y.; Zou, J.; Xing, E.P. Learning latent space models with angular constraints. In Proceedings of the International Conference on Machine Learning, PMLR, Sunday, August, 6–11 August 2017; pp. 3799–3810. [Google Scholar]
- Yaguchi, Y.; Shiratani, F.; Iwaki, H. Mixfeat: Mix feature in latent space learns discriminative space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shi, W.; Zeng, W. Genetic k-means clustering approach for mapping human vulnerability to chemical hazards in the industrialized city: A case study of Shanghai, China. Int. J. Environ. Res. Public Health 2013, 10, 2578–2595. [Google Scholar] [CrossRef]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Walpole, R.E.; Myers, R.H.; Myers, S.L.; Ye, K. Probability and Statistics for Engineers and Scientists; Macmillan: New York, NY, USA, 1993; Volume 5. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Elements | Observations | Range |
|---|---|---|
| Image | ||
| The angle between car direction and the direction of track axis | ||
| Gear | {−1, 0, …, 6} | |
| Number of rotations per minute of the car engine | ||
| Distance between the car and the track axis |
| Elements | Actions of the Car | Range |
|---|---|---|
| Accelerator pedal | [0, 1] | |
| Break pedal | [0, 1] | |
| Clutch pedal | [0, 1] | |
| Gear | {−1, 0, …, 6} | |
| Steering wheel angle |
| Data | Size |
|---|---|
| Input image size | |
| Latent space representation |
| Situation | Number of Examples |
|---|---|
| Situation 1 | 2863 |
| Situation 2 | 3097 |
| Situation 3 | 1918 |
| Situation 4 | 1767 |
| Situation 5 | 1279 |
| Situation 6 | 1367 |
| Situation 7 | 2250 |
| Hyperparameter | Value |
|---|---|
| Input Size | |
| Activation Function | ReLU |
| Optimizer | ADAM |
| Learning Rate | 0.001 |
| Loss Function | MSE |
| Epochs | 100 |
| Driving Policy | Score | MSE |
|---|---|---|
| End-to-end | 0.33626 | 0.05766 |
| PilotNet | −0.12808 | 0.05310 |
| AutoPilot | 0.22819 | 0.05117 |
| Our Policy Division | 0.53147 | 0.00897 |
| Policy | Score | MSE |
|---|---|---|
| Policy 1 | 0.62678 | 0.00598 |
| Policy 2 | 0.60072 | 0.00740 |
| Policy 3 | 0.68023 | 0.00325 |
| Policy 4 | 0.62420 | 0.00516 |
| Policy 5 | 0.61522 | 0.00658 |
| Policy 6 | 0.27024 | 0.01942 |
| Policy 7 | 0.30292 | 0.01505 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Hernández, E.; Vasquez, J.I.; Duchanoy Martínez, C.A.; Taud, H. Unsupervised Driving Situation Detection in Latent Space for Autonomous Cars. Appl. Sci. 2022, 12, 3635. https://doi.org/10.3390/app12073635
Rodríguez-Hernández E, Vasquez JI, Duchanoy Martínez CA, Taud H. Unsupervised Driving Situation Detection in Latent Space for Autonomous Cars. Applied Sciences. 2022; 12(7):3635. https://doi.org/10.3390/app12073635
Chicago/Turabian StyleRodríguez-Hernández, Erick, Juan Irving Vasquez, Carlos Alberto Duchanoy Martínez, and Hind Taud. 2022. "Unsupervised Driving Situation Detection in Latent Space for Autonomous Cars" Applied Sciences 12, no. 7: 3635. https://doi.org/10.3390/app12073635
APA StyleRodríguez-Hernández, E., Vasquez, J. I., Duchanoy Martínez, C. A., & Taud, H. (2022). Unsupervised Driving Situation Detection in Latent Space for Autonomous Cars. Applied Sciences, 12(7), 3635. https://doi.org/10.3390/app12073635