
Performance Analysis of RCU-Style Non-Blocking Synchronization Mechanisms on a Manycore-Based Operating System





Abstract
:1. Introduction
2. Related Work
3. RCU-Style Non-Blocking Synchronous Algorithms
3.1. Read Copy Update (RCU)
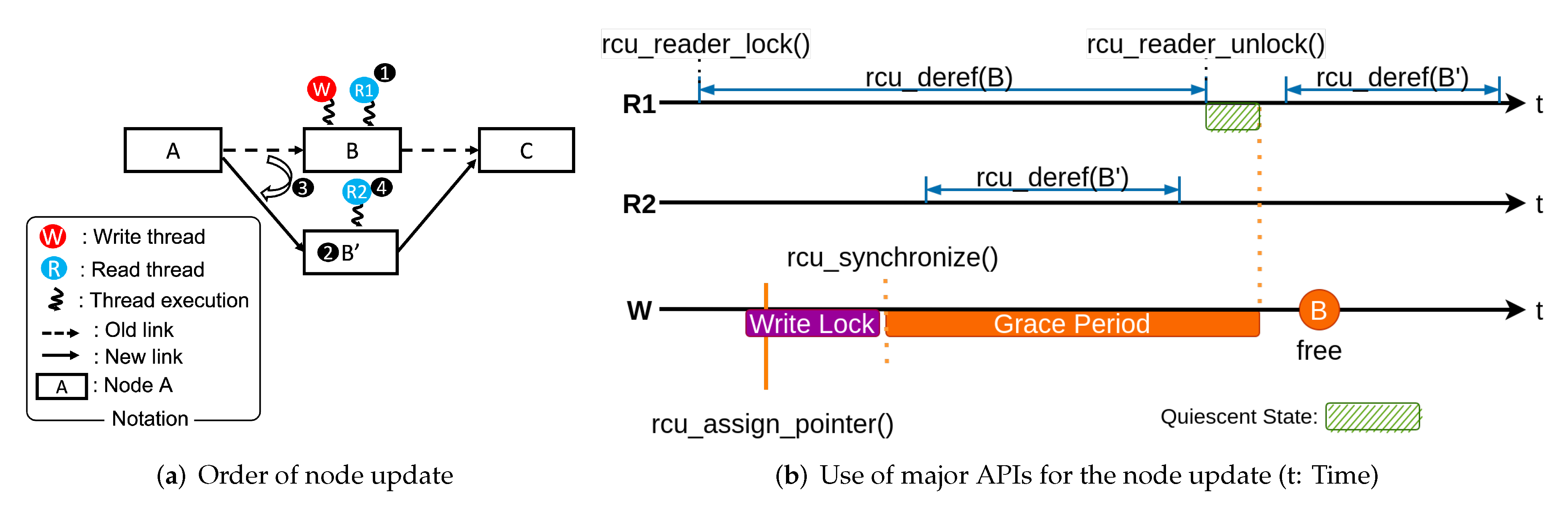
3.1.1. Procedure ofa Node Update
- (1)
- Thread R1 enters the critical section with negligible synchronization overhead, traverses the linked list, and reads node B (❶ in Figure 1a).
- (2)
- Thread W creates a copy of node B, node , and updates the value to change node B (❷). Thread R1 is able to read concurrently without interfering with the node modification operation of thread W.
- (3)
- Thread W updates the next node pointer of node A to node (❸). At this stage, threads that read the original and the copied nodes are split.
- (4)
- Thread R2 reads a new node via node A by traversing the nodes (❹).
- (5)
- Thread W defers memory release until R1 has completed reading node B. Thread W releases node B and completes the update process once it is confirmed that no other thread is accessing node B.
3.1.2. Use of RCU APIs
- rcu_read_lock(), rcu_read_unlock(): APIs that notify the entry and exit of a critical section of reading threads, respectively.
- rcu_assign_pointer() or rcu_assign_ptr(): Used by write threads to apply changes to a node. Used when changing the next pointer of node A to node B’ in the example of Figure 1a (❸).
- rcu_dereference() or rcu_deref(): An API used by threads to read shared data in a critical section. It guarantees the order of operations through memory barriers, compiler directives, etc., to ensure that appropriate values of changed shared data can be read.
- rcu_synchronize(): An API that waits for a critical section of the currently reading threads to exit before safely releasing an original node of the copied node.
- rcu_call(): Non-blocking type API of rcu_synchronize(). An API that releases nodes in a non-blocking manner by registering nodes to be freed and a call back function instead of directly calling rcu_synchronize() if an application does not allow the write thread to be blocked. Frequent calls of rcu_call() may cause memory management problems due to the accumulation of a large number of nodes to be freed [53,54].
3.2. Read Log Update (RLU)
3.2.1. Procedure of a Node Update
- (1)
- When the R1 thread enters the RLU section, it reads global clock, stores it as local clock in R1’s metadata, and reads the latest version node B based on local clock (❶ in Figure 2a).
- (2)
- The thread W creates a new version, , in the log and updates the value to change the value of node B (❷).
- (3)
- Assign global clock + 1 as the update clock of the version (denoted as write clock ❸) and commit the update (other threads can read the version ). At this stage, the thread R1 is still reading node B without interruption from the thread W’s updates.
- (4)
- After that, the thread enters the RLU section and reads the latest version (❹).
- (5)
- The thread W that updated node B waits until all the threads reading node B exit the RLU section. Since the commit of version is complete, threads entering the RLU section cannot read node B.
- (6)
- If it is confirmed that there is no thread reading node B, the thread W overwrites the value of the version to the original node B (❺) and cleans up the version .
3.2.2. Use of RLU APIs
- rlu_reader_lock(), rlu_reader_unlock(): APIs for entering and exiting a RLU section of threads. rlu_reader_lock() reads global clock and stores it as local clock in the thread’s metadata. rlu_reader_unlock() performs a commit for an update and log reclamation.
- rlu_try_lock(): Acquire exclusive rights to modify an object and make a copy in the log.
- rlu_assign_pointer() or rlu_assign_ptr(): Used by write threads to modify a pointer of a node. For instance, it is used to change the next pointer of node A to copy version in Figure 2a.
- rlu_dereference() or rlu_deref(): An API used by threads to read shared data. It guarantees a consistent view of shared objects according to local clock of a thread.
- rlu_free(): An API to logically delete an object.
3.3. Multi-Version Read Log Update (MV-RLU)
3.3.1. Procedure of a Node Update
- (1)
- The local clock is maintained in the thread’s metadata when MV-RLU enters the MV-RLU section in the same way that RLU does.
- (2)
- Thread W1 creates a new version, , in the per-thread log to modify node B and modifies the value (denoted as ❶ in Figure 3a). Similar to RLU, MV-RLU specifies global clock + 1 as the update clock (denoted as write clock in the log of W1 ❷) and commits for the update.
- (3)
- After creating the version , the thread R1 enters the critical section (also known as the MV-RLU section) and reads the version (❸).
- (4)
- Upon request, thread W2 also creates version in the log to modify node B and updates the value (❹). The thread W2 stores the update clock in the log (assuming the write clock is 15 (❺) and commits it.
- (5)
- After that, the thread enters the MV-RLU section and reads the latest valid version based on local clock (❻).
- (6)
- During the above procedure, log reclamation starts when a thread’s log usage exceeds a certain level. It waits until there is no thread reading a version other than the latest version and then overwrites the latest version on the original node (❼). Then, areas that are no longer accessed by threads are recycled in the log by MV-RLU’s garbage collector.
3.3.2. Use of MV-RLU APIs
- mvrlu_reader_lock(), mvrlu_reader_unlock(): APIs used by threads to enter/exit a critical section. mvrlu_reader_lock() begins a MV-RLU section and reads global clock and stores it as local clock in the thread’s metadata. mvrlu_reader_unlock() commits an update of a shared object and finishes an MV-RLU section.
- mvrlu_try_lock(): An API that acquires exclusive rights to modify an object and creates a version in the log.
- mvrlu_try_lock_const(): An optimized form of mvrlu_try_lock() API for objects to be deleted. Objects to be deleted do not need to create a new version in the log, so MV-RLU only has exclusive rights to modify the object.
- mvrlu_assign_pointer() orMV-RLU_assign_ptr(): An API where a write thread performs pointer mutation operations on shared objects.
- mvrlu_dereference() or mvrlu_deref(): An API that traverses for the latest valid version based on local clock on each thread (MV-RLU searches the version with the latest write clock based on local clock while traversing the version chain of Figure 3a).
- mvrlu_free(): An API that performs the logical deletion of objects.
4. Implementation
4.1. Example of API Use of RCU-Style Synchronizations
4.2. RCU-Style Synchronization Libraries
4.3. Benchmarks
5. Performance Evaluation
- Do RCU-style synchronization techniques show performance scalability in a manycore-based operating system?
- How well does each synchronization scheme perform when simultaneously accessing the linked list and hash table, which are representative data structures?
- How does each synchronization mechanism perform according to the read/write ratio of the workload?
5.1. Evaluation Platform
5.2. Configuration
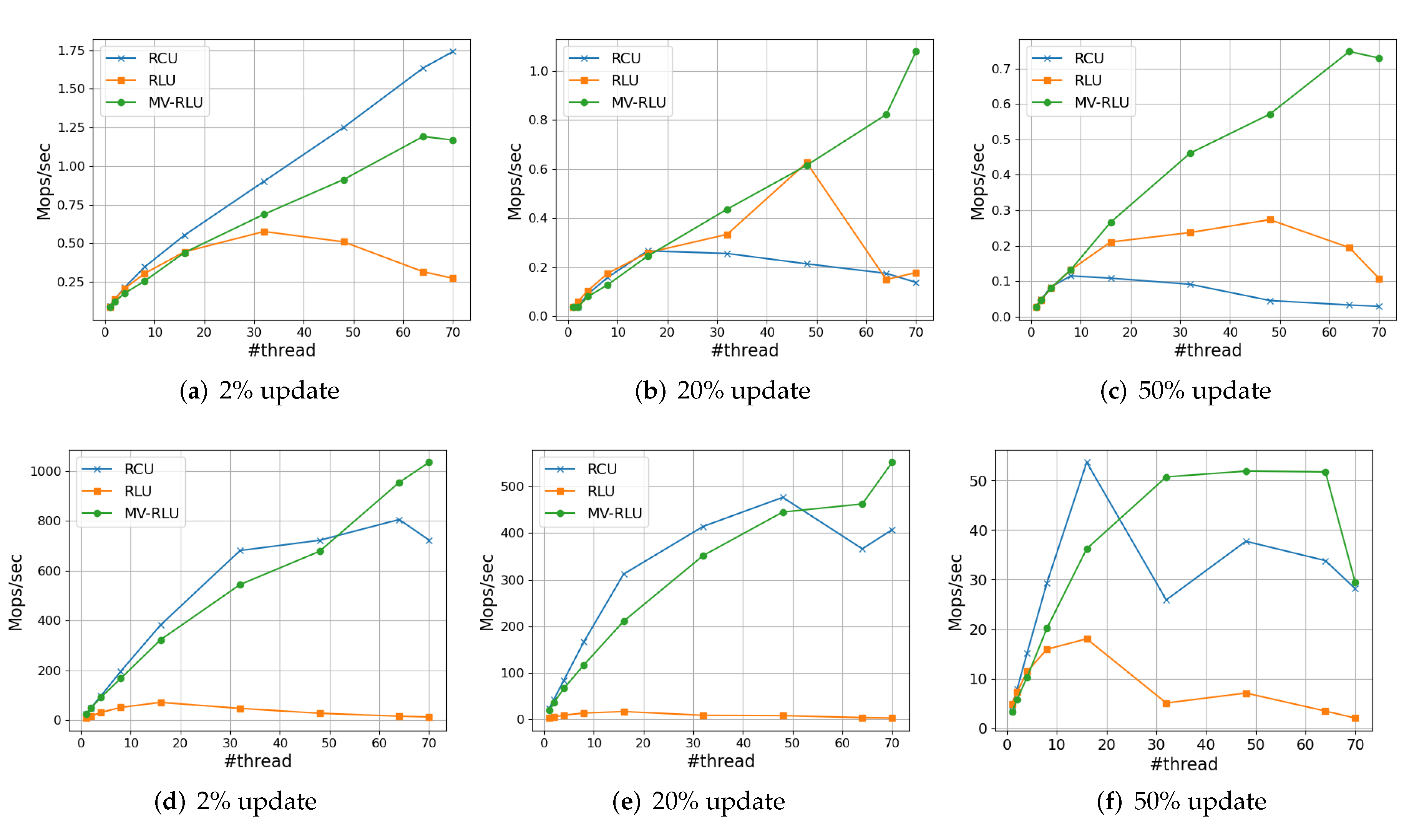
5.3. Performance Results
5.3.1. User-Level Benchmark
5.3.2. Kernel-Level Benchmark
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chuck Moore AMD Corporate Fellow & Technology Group CTO. Data Processing in Exascale-Class Computer Systems; Salishan Conference on High Speed Computing: Gleneden Beach, OR, USA, 2011. [Google Scholar]
- Hill, M.D.; Marty, M.R. Amdahl’s Law in the Multicore Era. IEEE Comput. 2008, 41, 33–38. [Google Scholar] [CrossRef] [Green Version]
- NetworkWorld. Ampere Announces 128-Core Arm Server Processor. 2020. Available online: https://www.networkworld.com/article/3564514/ampere-announces-128-core-arm-server-processor.html (accessed on 3 February 2022).
- Intel. Intel® Xeon® Platinum Processor. 2021. Available online: https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable/platinum.html (accessed on 3 February 2022).
- Supermicro. SuperServer 7089P-TR4T. 2022. Available online: https://www.supermicro.com/en/products/system/7U/7089/SYS-7089P-TR4T.cfm (accessed on 3 February 2022).
- Boyd-Wickizer, S.; Kaashoek, M.F.; Morris, R.; Zeldovich, N. Non-scalable locks are dangerous. In Proceedings of the Linux Symposium, Ottawa Linux Symposium, OLS’12, Ottawa, ON, Canada, 11–13 July 2012; pp. 119–130. [Google Scholar]
- McKenney, P.E. Is Parallel Programming Hard, and, If So, What Can You Do about It? (Release v2021.12.22a). arXiv 2021, arXiv:cs.DC/1701.00854. [Google Scholar]
- Kashyap, S.; Calciu, I.; Cheng, X.; Min, C.; Kim, T. Scalable and Practical Locking with Shuffling. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, SOSP ’19, Huntsville, ON, Canada, 27–30 October 2019; pp. 586–599. [Google Scholar]
- Herlihy, M.; Shavit, N. The Art of Multiprocessor Programming, Revised Reprint, 1st ed.; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2012. [Google Scholar]
- Mellor-Crummey, J.M.; Scott, M.L. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Trans. Comput. Syst. 1991, 9, 21–65. [Google Scholar] [CrossRef]
- Corbet, J. Locks and Qspinlocks. LWN.net. Available online: https://lwn.net/Articles/590243/ (accessed on 3 February 2022).
- Chabbi, M.; Fagan, M.; Mellor-Crummey, J. High Performance Locks for Multi-Level NUMA Systems. In Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP 2015, San Francisco, CA, USA, 7–11 February 2015; pp. 215–226. [Google Scholar]
- Kashyap, S.; Min, C.; Kim, T. Scalable NUMA-Aware Blocking Synchronization Primitives. In Proceedings of the 2017 USENIX Conference on Usenix Annual Technical Conference, USENIX ATC ’17, Santa Clara, CA, USA, 12–14 July 2017; pp. 603–615. [Google Scholar]
- Harris, T.L. A Pragmatic Implementation of Non-Blocking Linked-Lists. In Proceedings of the 15th International Conference on Distributed Computing, DISC ’01, Lisbon, Portugal, 3–5 October 2001; pp. 300–314. [Google Scholar]
- Fomitchev, M.; Ruppert, E. Lock-Free Linked Lists and Skip Lists. In Proceedings of the Twenty-Third Annual ACM Symposium on Principles of Distributed Computing, PODC ’04, St. John’s, NL, Canada, 25–28 July 2004; pp. 50–59. [Google Scholar]
- Herlihy, M.; Luchangco, V.; Moir, M. Obstruction-Free Synchronization: Double-Ended Queues as an Example. In Proceedings of the 23rd International Conference on Distributed Computing Systems, ICDCS ’03, Providence, RI, USA, 19–22 May 2003; p. 522. [Google Scholar]
- Michael, M.M. High Performance Dynamic Lock-Free Hash Tables and List-Based Sets. In Proceedings of the Fourteenth Annual ACM Symposium on Parallel Algorithms and Architectures, SPAA ’02, New York, NY, USA, 10–13 August 2002; pp. 73–82. [Google Scholar]
- Hart, T.; McKenney, P.; Brown, A. Making lockless synchronization fast: Performance implications of memory reclamation. In Proceedings of the 20th IEEE International Parallel Distributed Processing Symposium, Rhodes Island, Greece, 25–29 April 2006; p. 10. [Google Scholar]
- Hart, T.E.; McKenney, P.E.; Brown, A.D.; Walpole, J. Performance of Memory Reclamation for Lockless Synchronization. J. Parallel Distrib. Comput. 2007, 67, 1270–1285. [Google Scholar] [CrossRef] [Green Version]
- Wikipedia. Non-Blocking Algorithm. 2021. Available online: https://en.wikipedia.org/wiki/Non-blocking_algorithm (accessed on 3 February 2022).
- McKenney, P.E.; Fernandes, J.; Boyd-Wickizer, S.; Walpole, J. RCU Usage In the Linux Kernel: Eighteen Years Later. SIGOPS Oper. Syst. Rev. 2020, 54, 47–63. [Google Scholar] [CrossRef]
- McKenney, P. What Is RCU, Fundamentally? 2007. Available online: https://lwn.net/Articles/262464/ (accessed on 3 February 2022).
- Desnoyers, M.; McKenney, P.E.; Stern, A.S.; Dagenais, M.R.; Walpole, J. User-Level Implementations of Read-Copy Update. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 375–382. [Google Scholar] [CrossRef] [Green Version]
- Matveev, A.; Shavit, N.; Felber, P.; Marlier, P. Read-Log-Update: A Lightweight Synchronization Mechanism for Concurrent Programming. In Proceedings of the 25th Symposium on Operating Systems Principles, SOSP ’15, Monterey, CA, USA, 4–7 October 2015; pp. 168–183. [Google Scholar]
- Kim, J.; Mathew, A.; Kashyap, S.; Ramanathan, M.K.; Min, C. MV-RLU: Scaling Read-Log-Update with Multi-Versioning. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’19, Providence, RI, USA, 13–17 April 2019; pp. 779–792. [Google Scholar]
- Arbel, M.; Attiya, H. Concurrent Updates with RCU: Search Tree as an Example. In Proceedings of the 2014 ACM Symposium on Principles of Distributed Computing, PODC ’14, Paris, France, 15–18 July 2014; pp. 196–205. [Google Scholar]
- Mckenney, P.E.; Walpole, J. Exploiting Deferred Destruction: An Analysis of Read-Copy-Update Techniques in Operating System Kernels. Ph.D. Thesis, Oregon Health & Science University, Portland, OR, USA, 2004. [Google Scholar]
- McKenney, P.E.; Desnoyers, M.; Jiangshan, L. User-Space RCU; LWN.net. Available online: https://lwn.net/Articles/573424/ (accessed on 3 February 2022).
- Clements, A.T.; Kaashoek, M.F.; Zeldovich, N. Scalable Address Spaces Using RCU Balanced Trees. In Proceedings of the Seventeenth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS XVII, London, UK, 3–7 March 2012; pp. 199–210. [Google Scholar]
- Clements, A.T.; Kaashoek, M.F.; Zeldovich, N.; Morris, R.T.; Kohler, E. The Scalable Commutativity Rule: Designing Scalable Software for Multicore Processors. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, SOSP ’13, Farminton, PA, USA, 3–6 November 2013; pp. 1–17. [Google Scholar]
- Magnusson, P.S.; Landin, A.; Hagersten, E. Queue Locks on Cache Coherent Multiprocessors. In Proceedings of the 8th International Symposium on Parallel Processing, Cancún, Mexico, 1 April 1994; pp. 165–171. [Google Scholar]
- Luchangco, V.; Nussbaum, D.; Shavit, N. A Hierarchical CLH Queue Lock; Euro-Par’06; Springer: Dresden, Germany, 2006; pp. 801–810. [Google Scholar]
- Dice, D.; Kogan, A. BRAVO: Biased Locking for Reader-Writer Locks. In Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference, USENIX ATC ’19, Renton, WA, USA, 10–12 July 2019; pp. 315–328. [Google Scholar]
- Fraser, K.; Harris, T. Concurrent Programming without Locks. ACM Trans. Comput. Syst. 2007, 25, 5-es. [Google Scholar] [CrossRef]
- Michael, M.M. Safe Memory Reclamation for Dynamic Lock-Free Objects Using Atomic Reads and Writes. In Proceedings of the Twenty-First Annual Symposium on Principles of Distributed Computing, PODC ’02, Monterey, CA, USA, 21–24 July 2002; pp. 21–30. [Google Scholar]
- Preshaing, J. An Introduction to Lock-Free Programming. 2012. Available online: https://preshing.com/20120612/an-introduction-to-lock-free-programming/ (accessed on 3 February 2022).
- DPDK. RCU Library. 2019. Available online: https://doc.dpdk.org/guides/prog_guide/rcu_lib.html (accessed on 3 February 2022).
- Wikipedia. Read-Copy-Update. 2021. Available online: https://en.wikipedia.org/wiki/Read-copy-update (accessed on 3 February 2022).
- Zhan, Y.; Porter, D.E. Versioned Programming: A Simple Technique for Implementing Efficient, Lock-Free, and Composable Data Structures. In Proceedings of the 9th ACM International on Systems and Storage Conference, SYSTOR ’16, Haifa, Israel, 6–8 June 2016. [Google Scholar]
- Wikipedia. List of Database Using MVCC. 2021. Available online: https://en.wikipedia.org/wiki/List_of_databases_using_MVCC (accessed on 3 February 2022).
- Diaconu, C.; Freedman, C.; Ismert, E.; Larson, P.A.; Mittal, P.; Stonecipher, R.; Verma, N.; Zwilling, M. Hekaton: SQL Server’s Memory-Optimized OLTP Engine. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, SIGMOD ’13, New York, NY, USA, 22–27 June 2013; pp. 1243–1254. [Google Scholar]
- Lim, H.; Kaminsky, M.; Andersen, D.G. Cicada: Dependably Fast Multi-Core In-Memory Transactions. In Proceedings of the 2017 ACM International Conference on Management of Data, SIGMOD ’17, Chicago, IL, USA, 14–19 May 2017; pp. 21–35. [Google Scholar]
- Park, S.; McKenney, P.E.; Dufour, L.; Yeom, H.Y. An HTM-Based Update-Side Synchronization for RCU on NUMA Systems. In Proceedings of the Fifteenth European Conference on Computer Systems, EuroSys ’20, Heraklion, Greece, 27–30 April 2020. [Google Scholar]
- Boyd-Wickizer, S.; Chen, H.; Chen, R.; Mao, Y.; Kaashoek, F.; Morris, R.; Pesterev, A.; Stein, L.; Wu, M.; Dai, Y.; et al. Corey: An Operating System for Many Cores. In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation, OSDI’08, San Diego, CA, USA, 8–10 December 2008; pp. 43–57. [Google Scholar]
- Baumann, A.; Barham, P.; Dagand, P.E.; Harris, T.; Isaacs, R.; Peter, S.; Roscoe, T.; Schüpbach, A.; Singhania, A. The Multikernel: A New OS Architecture for Scalable Multicore Systems. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, SOSP ’09, Big Sky, MT, USA, 11–14 October 2009; pp. 29–44. [Google Scholar]
- Park, Y.; Van Hensbergen, E.; Hillenbrand, M.; Inglett, T.; Rosenburg, B.; Ryu, K.D.; Wisniewski, R.W. FusedOS: Fusing LWK Performance with FWK Functionality in a Heterogeneous Environment. In Proceedings of the 2012 IEEE 24th International Symposium on Computer Architecture and High Performance Computing, NW Washington, DC, USA, 24–26 October 2012; pp. 211–218. [Google Scholar]
- Wentzlaff, D.; Agarwal, A. Factored Operating Systems (Fos): The Case for a Scalable Operating System for Multicores. SIGOPS Oper. Syst. Rev. 2009, 43, 76–85. [Google Scholar] [CrossRef]
- Clements, A.T.; Kaashoek, M.F.; Zeldovich, N.; Morris, R.T.; Kohler, E. The Scalable Commutativity Rule: Designing Scalable Software for Multicore Processors. ACM Trans. Comput. Syst. 2015, 32, 1–47. [Google Scholar] [CrossRef]
- Bhat, S.S.; Eqbal, R.; Clements, A.T.; Kaashoek, M.F.; Zeldovich, N. Scaling a File System to Many Cores Using an Operation Log. In Proceedings of the 26th Symposium on Operating Systems Principles, SOSP ’17, Shanghai, China, 28–31 October 2017; pp. 69–86. [Google Scholar]
- Cox, R.; Kaashoek, M.F.; Morris, R.T. Xv6, a Simple Unix-Like Teaching Operating System. Available online: https://pdos.csail.mit.edu/6.828/2021/xv6.html (accessed on 3 February 2022).
- Wikipedia. Readers-Write Lock. 2021. Available online: https://en.wikipedia.org/wiki/Readers%E2%80%93writer_lock (accessed on 3 February 2022).
- Mckenney, P.; Slingwine, J. Read-copy update: Using execution history to solve concurrency problems. Parallel Distrib. Comput. Syst. 1998, 509518. [Google Scholar]
- McKenney, P.E.; Boyd-Wickizer, S.; Walpole, J. FAQ for “RCU Usage in the Linux Kernel: One Decade Later”. Available online: https://pdos.csail.mit.edu/6.S081/2020/lec/rcu-faq.txt (accessed on 3 February 2022).
- kernel.org. What Is RCU? Available online: https://www.kernel.org/doc/Documentation/RCU/whatisRCU.txt (accessed on 3 February 2022).
- McKenney, P. Hierarchical RCU. 2008. Available online: https://lwn.net/Articles/305782/ (accessed on 3 February 2022).
- Fraser, K. Practical lock-freedom. In Technical Report UCAM-CL-TR-579; University of Cambridge, Computer Laboratory: Cambridge, UK, 2004. [Google Scholar]
- Github. RLU. Available online: https://github.com/rlu-sync/rlu (accessed on 3 February 2022).
- Github. MV-RLU. Available online: https://github.com/cosmoss-vt/mv-rlu (accessed on 3 February 2022).
- Denis-Courmont, R. Xv6, a Simple Unix-like Teaching Operating System. Available online: https://www.remlab.net/op/futex-condvar.shtml (accessed on 3 February 2022).
- Kashyap, S.; Min, C.; Kim, K.; Kim, T. A Scalable Ordering Primitive for Multicore Machines. In Proceedings of the Thirteenth EuroSys Conference, EuroSys ’18, Porto, Portugal, 23–26 April 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RW-Lock [51] | RCU [38] | RLU [24] | MV-RLU [25] | ||
|---|---|---|---|---|---|
| Policy | lock-based | lock and non-blocking | non-blocking | non-blocking | |
| Concurrency | R-R | • | • | • | • |
| R-W | × | • | • | • | |
| W-W | × | × | ▴ | ▴ | |
| Design factor | concurrent R, mutual exclusive W | concurrent R, single W | concurrent R, multiple W | concurrent R, multiple W w/o blocking wait | |
| API usage difficulty | low | high | medium | medium | |
| Main performance overhead | lock and unlock, mutual exclusion of W | serialized execution of W with a lock, wait for memory reclamation | blocking wait for log reclamation | version chain traversal | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, C.; Choi, E.; Han, M.; Lee, S.; Kim, J. Performance Analysis of RCU-Style Non-Blocking Synchronization Mechanisms on a Manycore-Based Operating System. Appl. Sci. 2022, 12, 3458. https://doi.org/10.3390/app12073458
Kim C, Choi E, Han M, Lee S, Kim J. Performance Analysis of RCU-Style Non-Blocking Synchronization Mechanisms on a Manycore-Based Operating System. Applied Sciences. 2022; 12(7):3458. https://doi.org/10.3390/app12073458
Chicago/Turabian StyleKim, Changhui, Euteum Choi, Mingyun Han, Seongjin Lee, and Jaeho Kim. 2022. "Performance Analysis of RCU-Style Non-Blocking Synchronization Mechanisms on a Manycore-Based Operating System" Applied Sciences 12, no. 7: 3458. https://doi.org/10.3390/app12073458
APA StyleKim, C., Choi, E., Han, M., Lee, S., & Kim, J. (2022). Performance Analysis of RCU-Style Non-Blocking Synchronization Mechanisms on a Manycore-Based Operating System. Applied Sciences, 12(7), 3458. https://doi.org/10.3390/app12073458